Paper Review: InceptionNeXt: When Inception Meets ConvNeXt
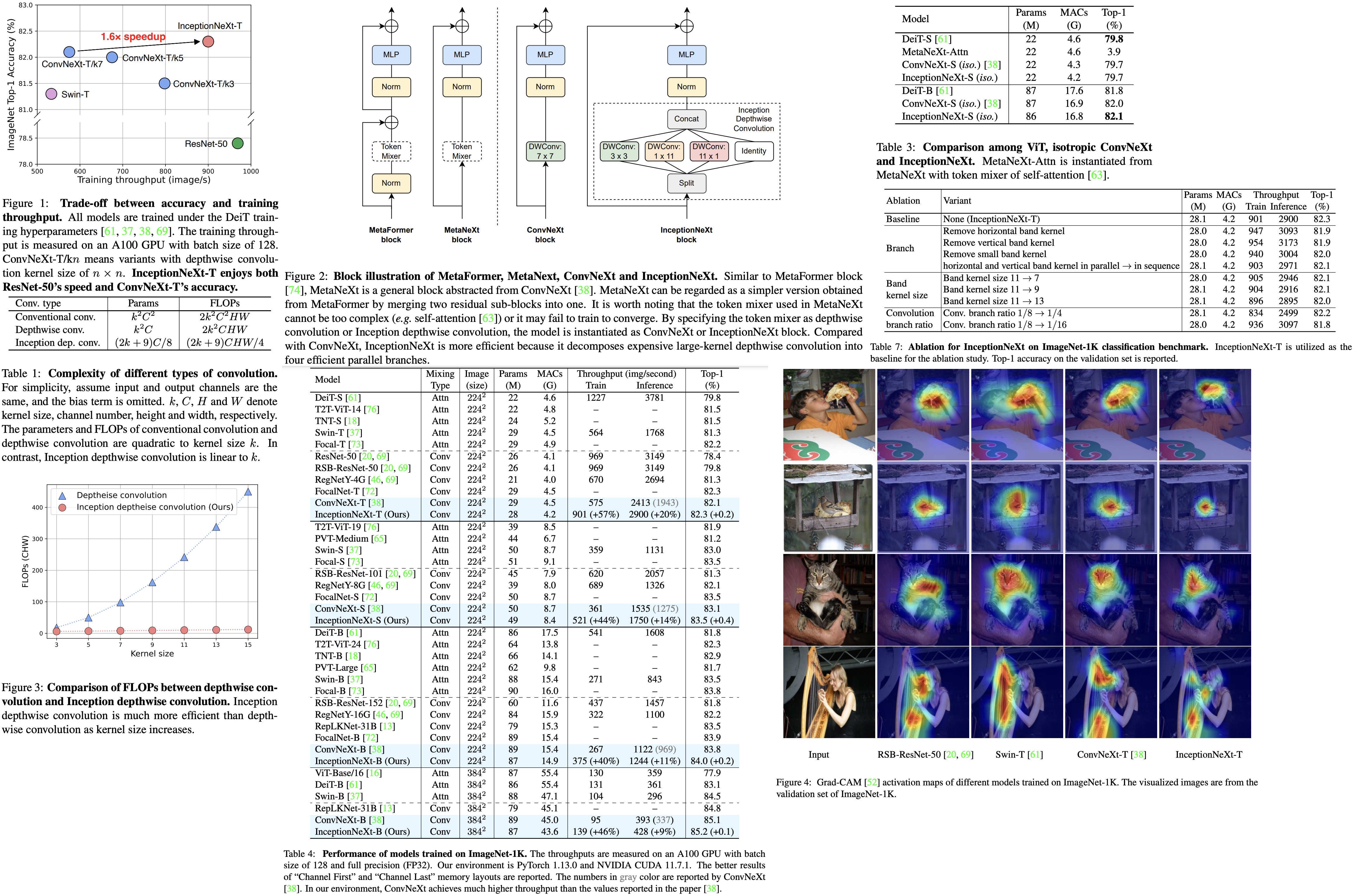
The authors address the issue of large-kernel-based CNN models being slow and inefficient, despite their improved performance. They propose InceptionNeXt, a series of networks that decompose large-kernel depthwise convolution into four parallel branches along channel dimensions, inspired by Inceptions. This new approach retains high performance while significantly increasing training throughput. InceptionNeXt-T, for example, achieves 1.6x higher training throughput than ConvNeXt-T and a 0.2% top-1 accuracy improvement on ImageNet1K. The authors believe InceptionNeXt can serve as an economical baseline for future architecture design, reducing carbon footprint.
The approach
MetaNeXt
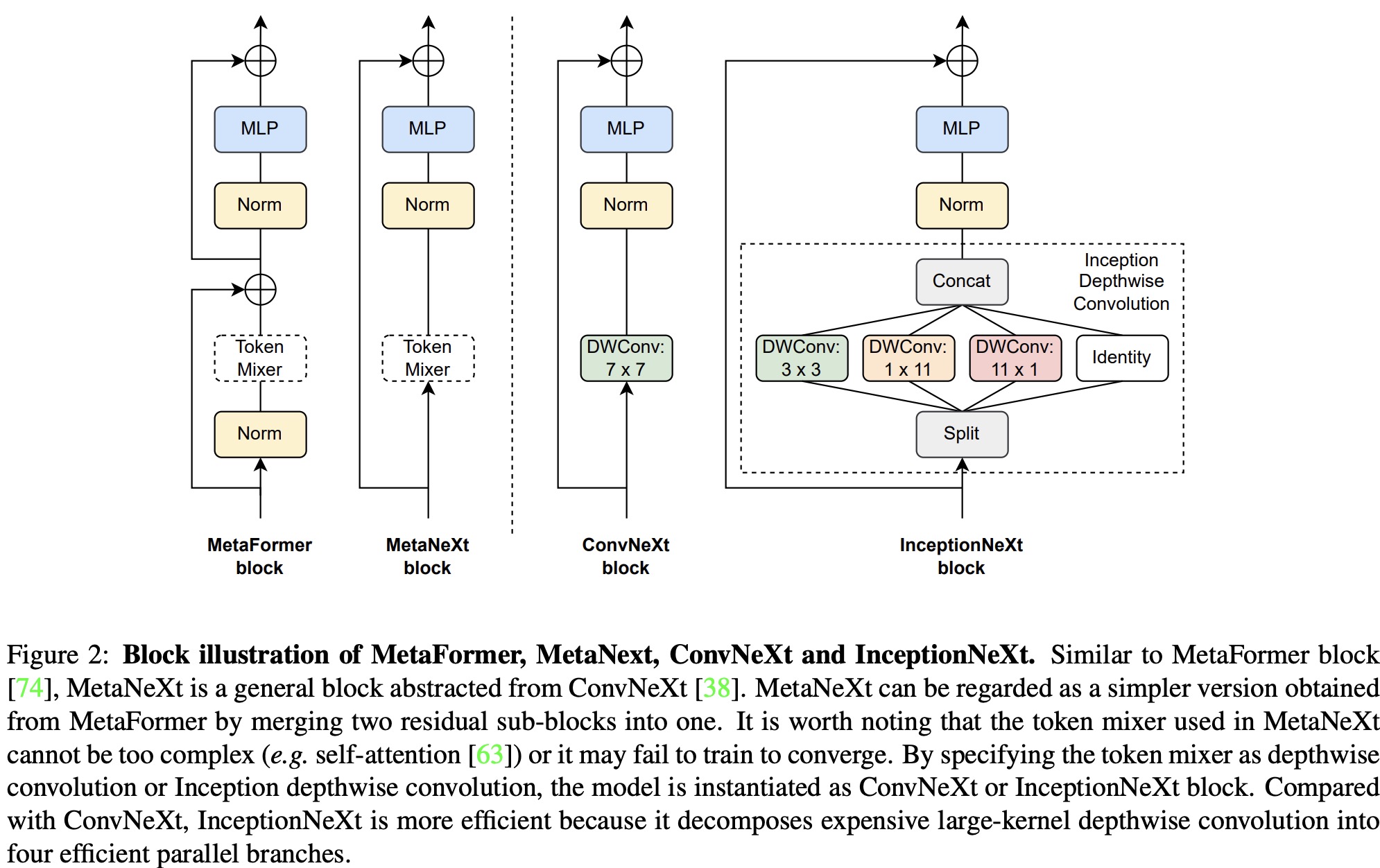
MetaNeXt Block is an abstraction of the ConvNeXt block. The input is first processed by a depthwise convolution, acting as a token mixer for spatial information interaction. Following normalization, the output is fed into an MLP module consisting of two fully-connected layers with an activation function in between. The process also incorporates shortcut connections.
The MetaNeXt block shares similarities with the MetaFormer block, such as the token mixer and MLP modules. However, a key difference lies in the number of shortcut connections: MetaNeXt has one, while MetaFormer has two. MetaNeXt can be seen as a simplified version of MetaFormer, merging two residual sub-blocks and resulting in a higher speed. This simplification comes at the cost of a limitation: the token mixer component in MetaNeXt cannot be as complicated (e.g., Attention) as in MetaFormer.
Inception depthwise convolution
class InceptionDWConv2d(nn.Module):
""" Inception depthweise convolution
"""
def __init__(self, in_channels, square_kernel_size=3, band_kernel_size=11, branch_ratio=0.125):
super().__init__()
gc = int(in_channels * branch_ratio) # channel numbers of a convolution branch
self.dwconv_hw = nn.Conv2d(gc, gc, square_kernel_size, padding=square_kernel_size // 2, groups=gc)
self.dwconv_w = nn.Conv2d(gc, gc, kernel_size=(1, band_kernel_size), padding=(0, band_kernel_size // 2), groups=gc)
self.dwconv_h = nn.Conv2d(gc, gc, kernel_size=(band_kernel_size, 1), padding=(band_kernel_size // 2, 0), groups=gc)
self.split_indexes = (in_channels - 3 * gc, gc, gc, gc)
def forward(self, x):
x_id, x_hw, x_w, x_h = torch.split(x, self.split_indexes, dim=1)
return torch.cat((x_id, self.dwconv_hw(x_hw), self.dwconv_w(x_w), self.dwconv_h(x_h)), dim=1)
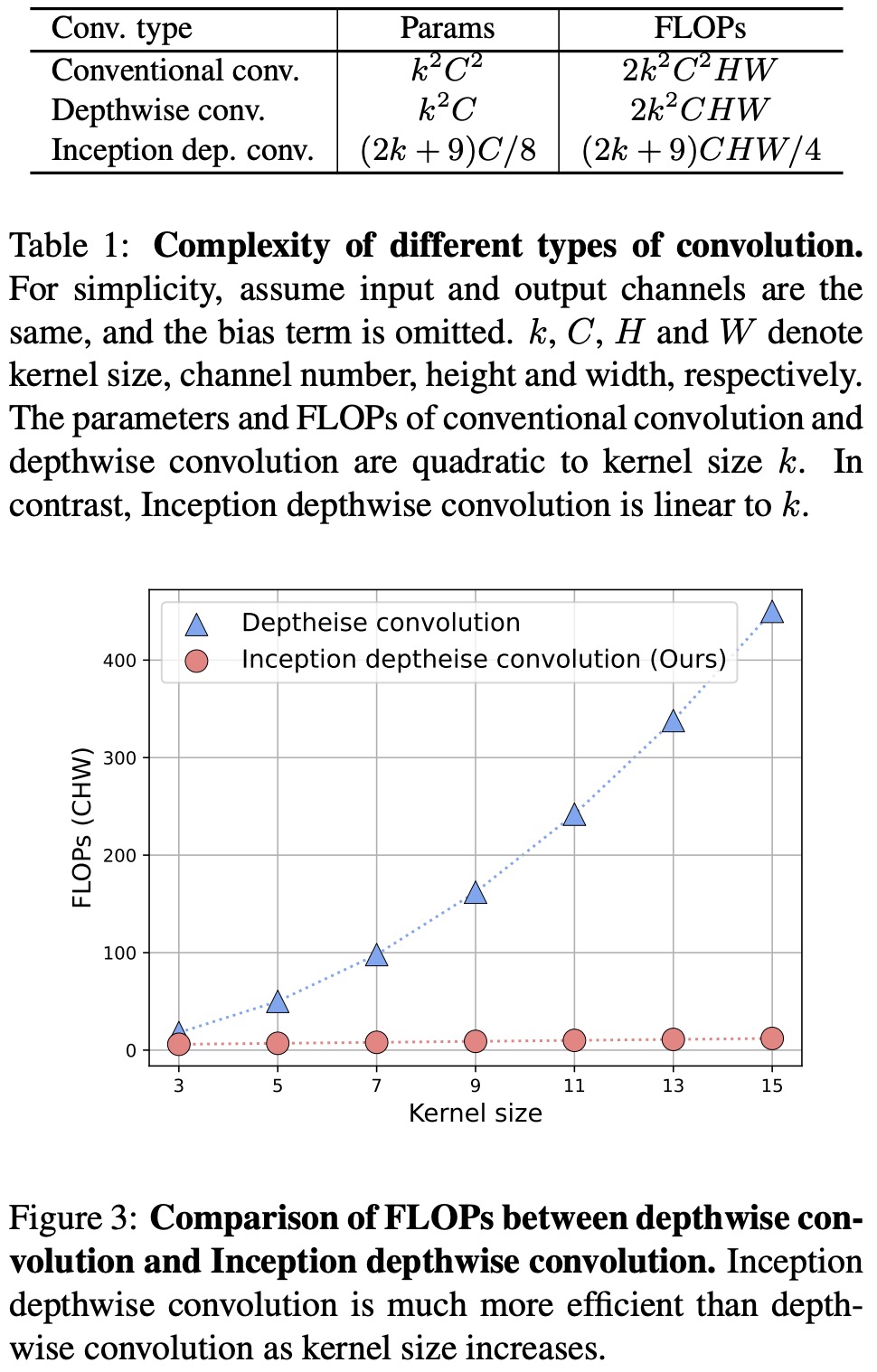
The authors leave partial channels unchanged (identity mapping) and split input into four groups along the channel dimension. The splitting inputs are then fed into different parallel branches. Inspired by Inception v3, large kernels are decomposed into 1 × kw and kh × 1 kernels. The outputs from each branch are concatenated.
Inception depthwise convolution is more efficient than conventional and depthwise convolutions in terms of parameter numbers and FLOPs, as it consumes parameters and FLOPs linearly with both channel and kernel size. This approach results in a faster and more efficient model while preserving performance.
InceptionNeXt
The authors build a series of models called InceptionNeXt based on the InceptionNeXt block, mainly following the ConvNeXt architecture. InceptionNeXt adopts a 4-stage framework, with the numbers of stages being [3, 3, 9, 3] for small size and [3, 3, 27, 3] for base size. Batch Normalization is used to improve speed. Unlike ConvNeXt, InceptionNeXt uses an MLP ratio of 3 in stage 4 and moves the saved parameters to the classifier, reducing some FLOPs (e.g., 3% for base size).
Results
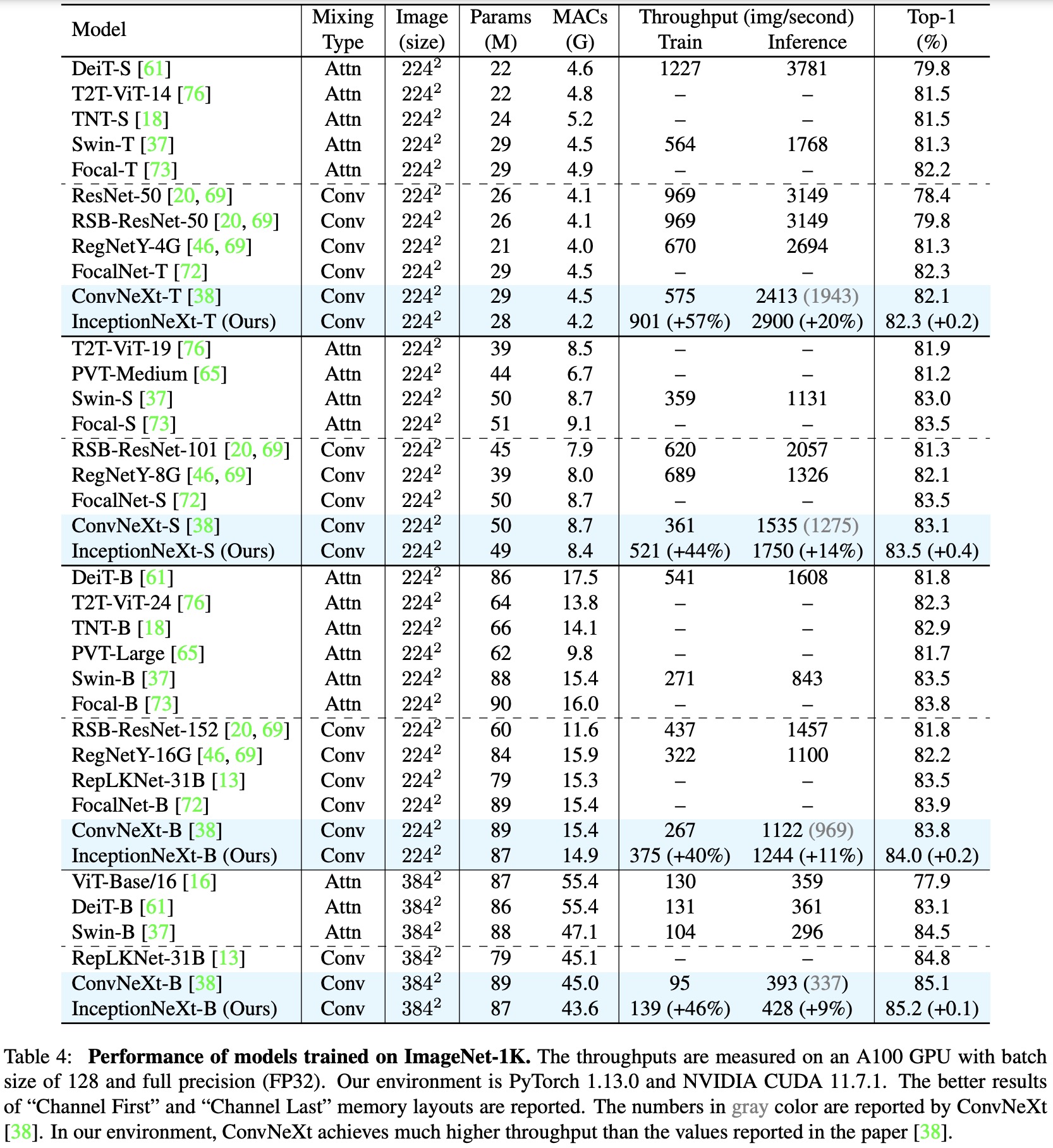
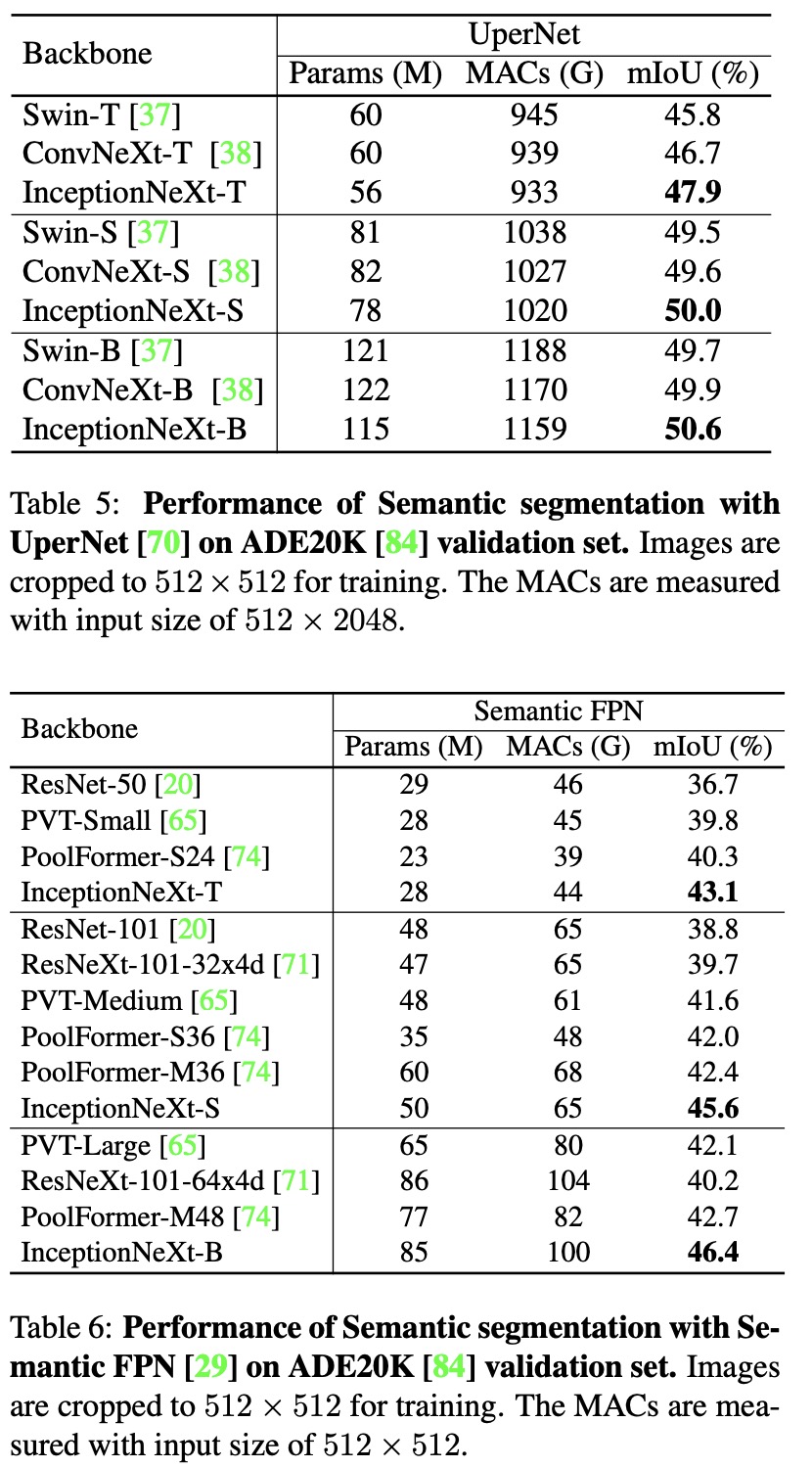
InceptionNeXt is compared to various state-of-the-art models, both attention-based and convolution-based. It achieves highly competitive performance while maintaining higher speed. InceptionNeXt consistently outperforms ConvNeXt in terms of top-1 accuracy and throughput. For example, InceptionNeXt-T has both ResNet-50’s speed and ConvNeXt-T’s accuracy. When fine-tuned at higher resolutions, InceptionNeXt maintains promising performance.
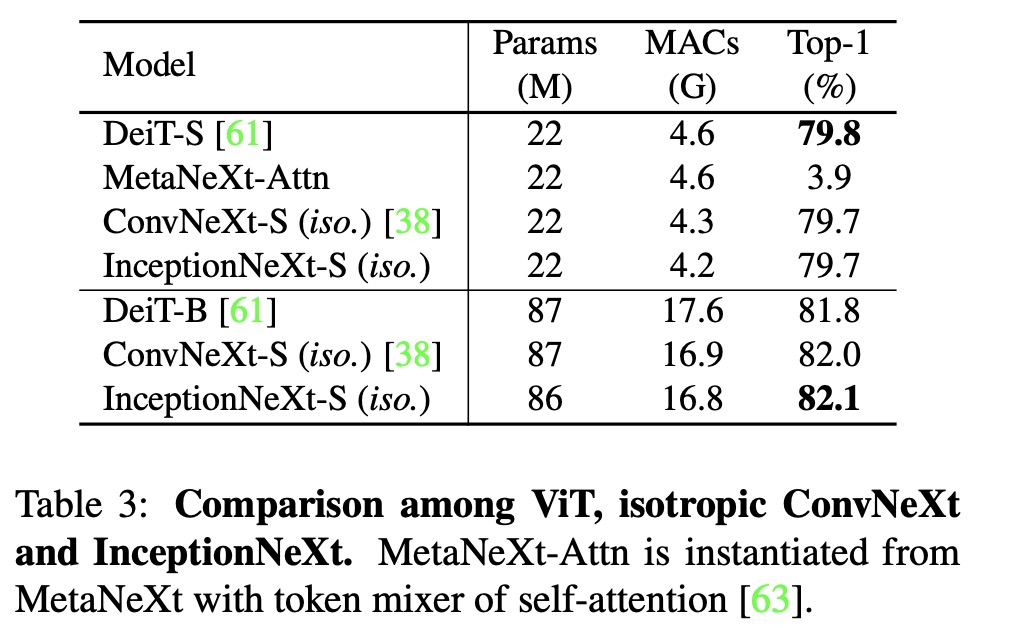
InceptionNeXt also performs well with the isotropic architecture, showing good generalization across different frameworks. However, the MetaNeXt-Attn model, which uses self-attention as a token mixer, fails to converge and achieves low accuracy. This suggests that the token mixer in MetaNeXt cannot be too complex, or the model may not be trainable.
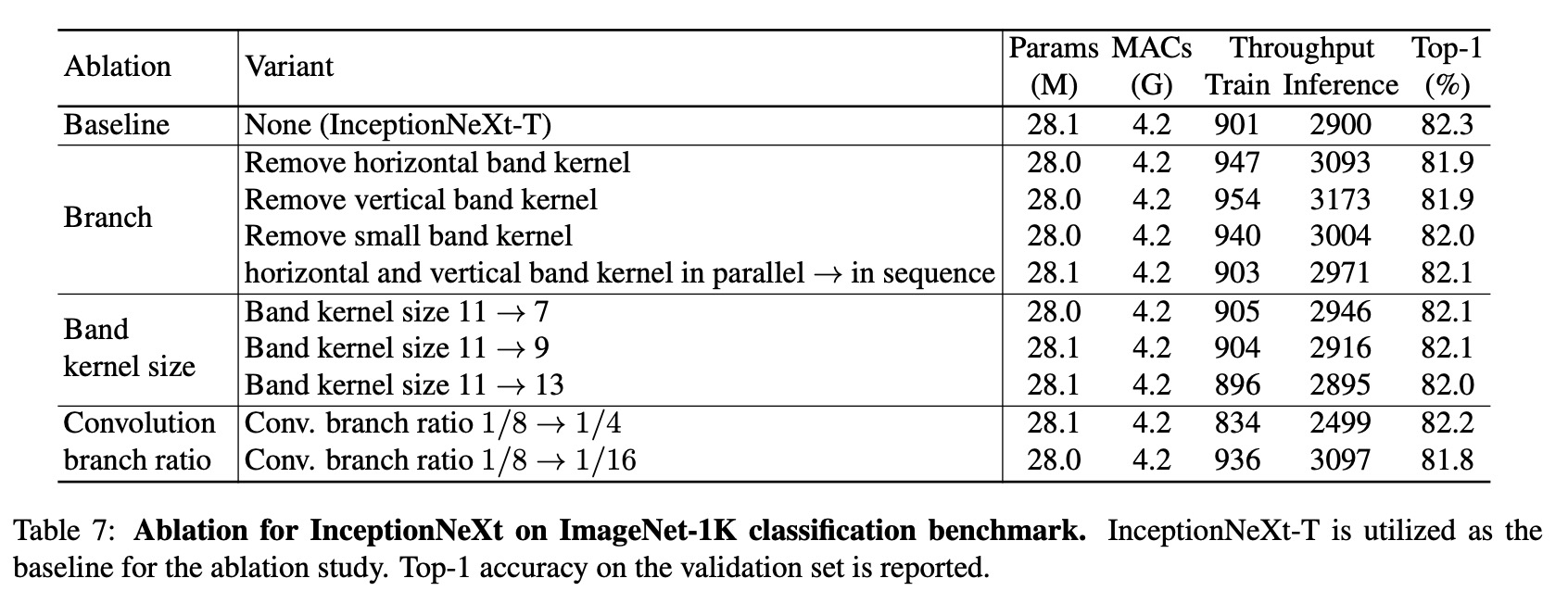
Ablations:
- Inception depthwise convolution has four branches, including three convolutional branches and identity mapping. Removing either the horizontal or vertical band kernel branch significantly reduces performance, highlighting their importance for enlarging the receptive field. Removing the 3x3 small square kernel branch can achieve up to 82.0% top-1 accuracy with higher throughput, suggesting a simplified version of InceptionNeXt without this kernel could be used for faster model speed.
- For the band kernel, Inception v3 mostly uses them sequentially, which can achieve similar performance and even slightly speed up the model. The authors believe that the parallel method for band kernels would be faster with better optimization and adopt it by default.
- The performance of InceptionNeXt improves when the band kernel size increases from 7 to 11 but drops at size 13, possibly due to optimization difficulty. To keep it simple, the authors set the default band kernel size to 11.
- As for the convolution branch ratio, performance doesn’t improve when the ratio increases from 1/8 to 1/4, but it drops significantly when it decreases to 1/16, likely due to limited token mixing. Therefore, the default convolution branch ratio is set to 1/8.