Paper Review: InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
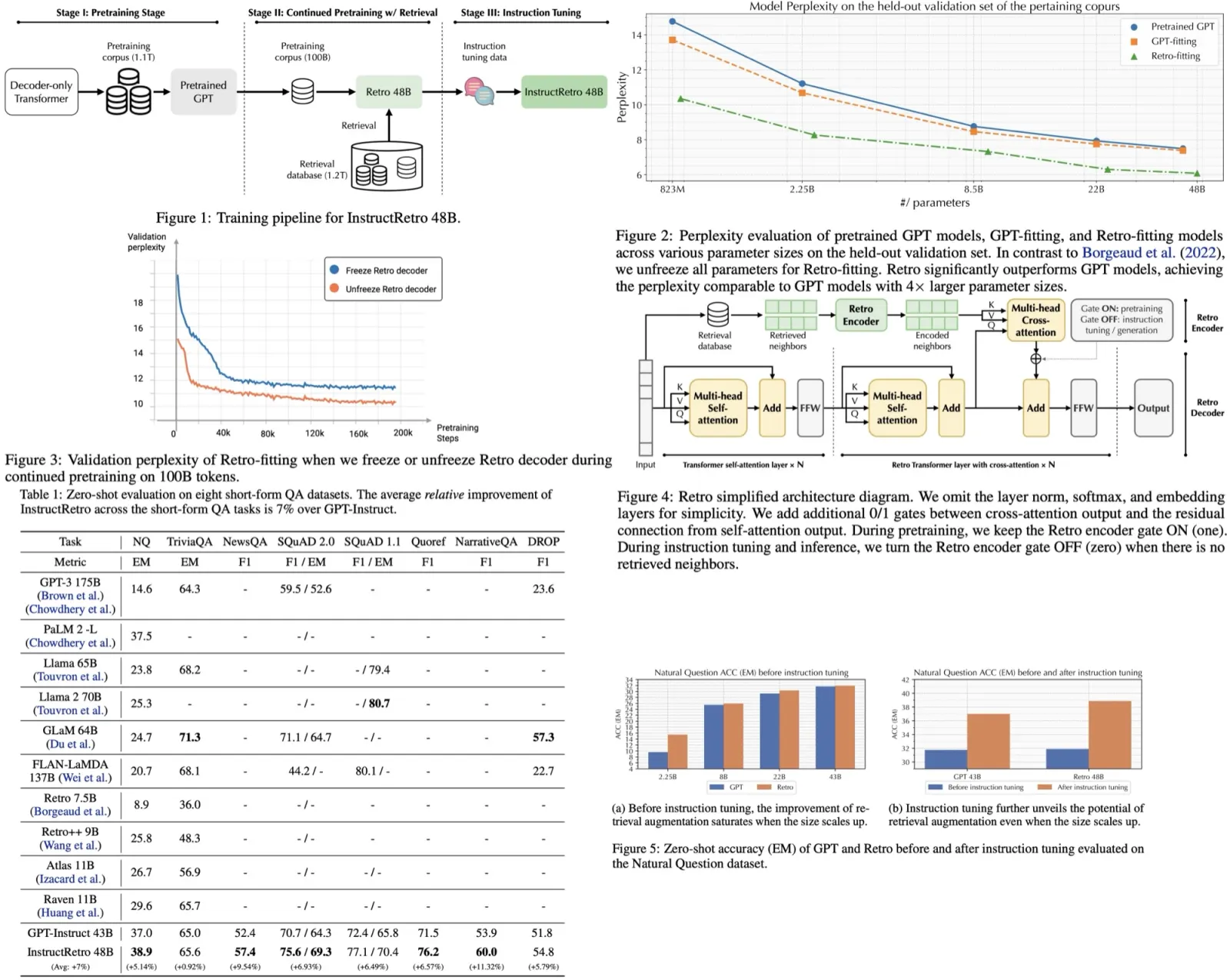
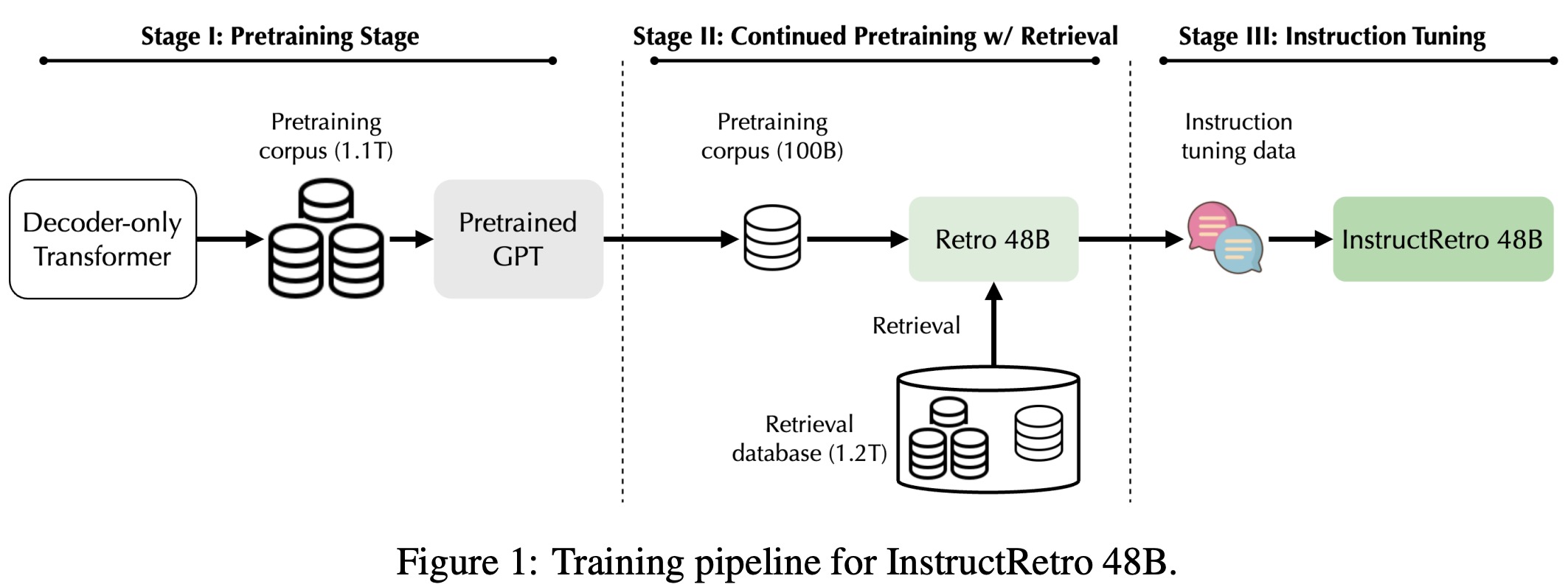
Retro 48B is the largest language model pretrained with a retrieval mechanism before instruction tuning. It evolved from the 43B GPT model by further pretraining on an additional 100 billion tokens using the Retro augmentation method, which retrieves from 1.2 trillion tokens. Retro 48B significantly outperforms the original 43B GPT in perplexity. After instruction tuning, InstructRetro shows a 7% average improvement over the GPT model in short-form question answering tasks and 10% in long-form tasks. Interestingly, removing the encoder from InstructRetro’s architecture and using only its decoder achieves similar results, suggesting that retrieval pretraining enhances the decoder’s context processing capabilities for question answering.
Continued pretraining of GPT with retrieval
Preliminaries of retro
Retro is a language model that uses retrieval augmentation, sharing similarities with GPT models but differing in its inclusion of a Retro encoder. This encoder excels at encoding features from external knowledge bases. Additionally, Retro employs chunk-wise cross-attention in its decoder to effectively integrate information from the Retro encoder, setting it apart from other encoder-decoder architectures like T5 and Atlas. The model’s design was influenced by the success of scaling decoder-only models like ChatGPT and GPT-4.
The Retro encoder uses a two-layer bidirectional transformer to convert external database retrievals into dense features. The retrieval database has 1.2 trillion tokens from an English corpus, excluding a 1% validation set. The database operates as a key-value system, with keys being BERT embeddings and values being token chunks. The database consists of 19 billion chunks, each with 64 tokens.
Retro’s design involves splitting input tokens into sequences of chunks. These chunks then retrieve nearest neighbor chunks from the database, using them to guide the generation of subsequent chunks. This approach ensures causality and limits the generation to the nearest neighbors (top-2) of the previous chunk.
Retro-fitting: continued pertaining with retrieval
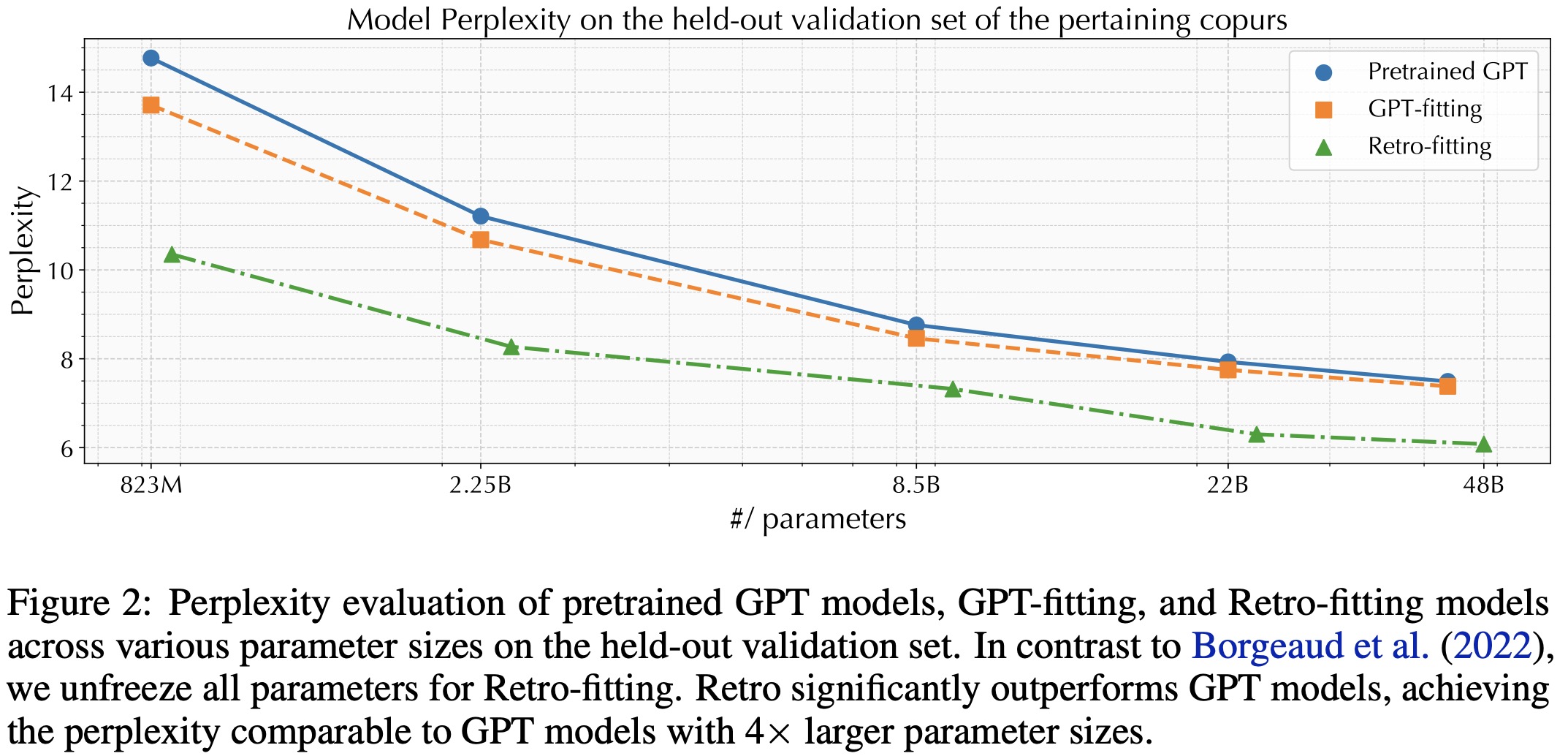
Scaling up Retro faces challenges due to its extensive retrieval database and high pertaining cost. To address these, the Faiss index is used for fast nearest neighbor searches, and retro-fitting techniques are employed to utilize pretrained GPT parameters, reducing computational expenses.
- The Faiss index clusters dense embeddings, uses Hierarchical Navigable Small World graphs for faster querying, and encodes embeddings with product quantization to save memory. This setup achieves a query speed of 4ms per chunk on a DGX-A100 node.
- Retro’s decoder is initialized from pretrained GPT models, while its encoder and cross-attention are randomly initialized.
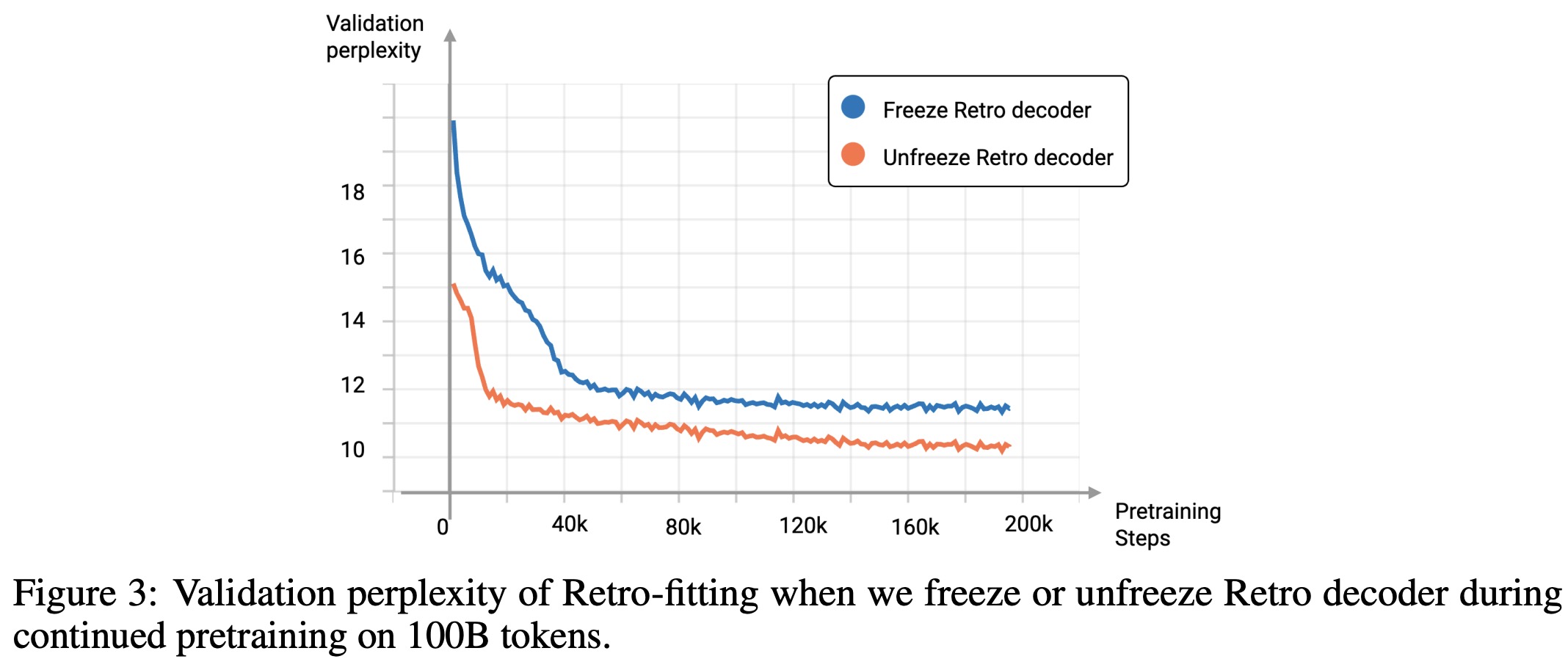
- Unlike previous studies that kept the decoder parameters constant, this work unfreezes them, resulting in faster convergence and improved validation perplexity. This method of “Retro-fitting” is contrasted with “GPT-fitting”, where only GPT models are continued in pretraining.
- Base GPT models of varying sizes, from 823M to 43B parameters, are pretrained with the Transformer architecture and the Sentence Piece tokenizer.
- Perplexity evaluations show that, after continued pretraining, Retro consistently outperforms GPT and GPT-fitting, even achieving better results than GPT models with four times more parameters.
Instruction tuning
Instruction tuning methods primarily use supervised fine-tuning on a mix of datasets or reinforcement learning with human feedback. The authors emphasize supervised instruction tuning for Retro due to limited open-source human feedback data. For instruction tuning, a variety of datasets are used, including SODA (a social dialogue dataset), ELI5 (a long-form QA dataset), Self-Instruct and Unnatural Instructions (LLM-generated instructions), FLAN and Chain-of-thought datasets, as well as private and public conversational datasets like OpenAssistant and Dolly. All data is formatted conversationally with three roles: “system”, “assistant”, and “user”. The “system” sets the tone, while the “user” and “assistant” roles provide questions and answers. In total, 128K high-quality samples are used for instruction tuning.
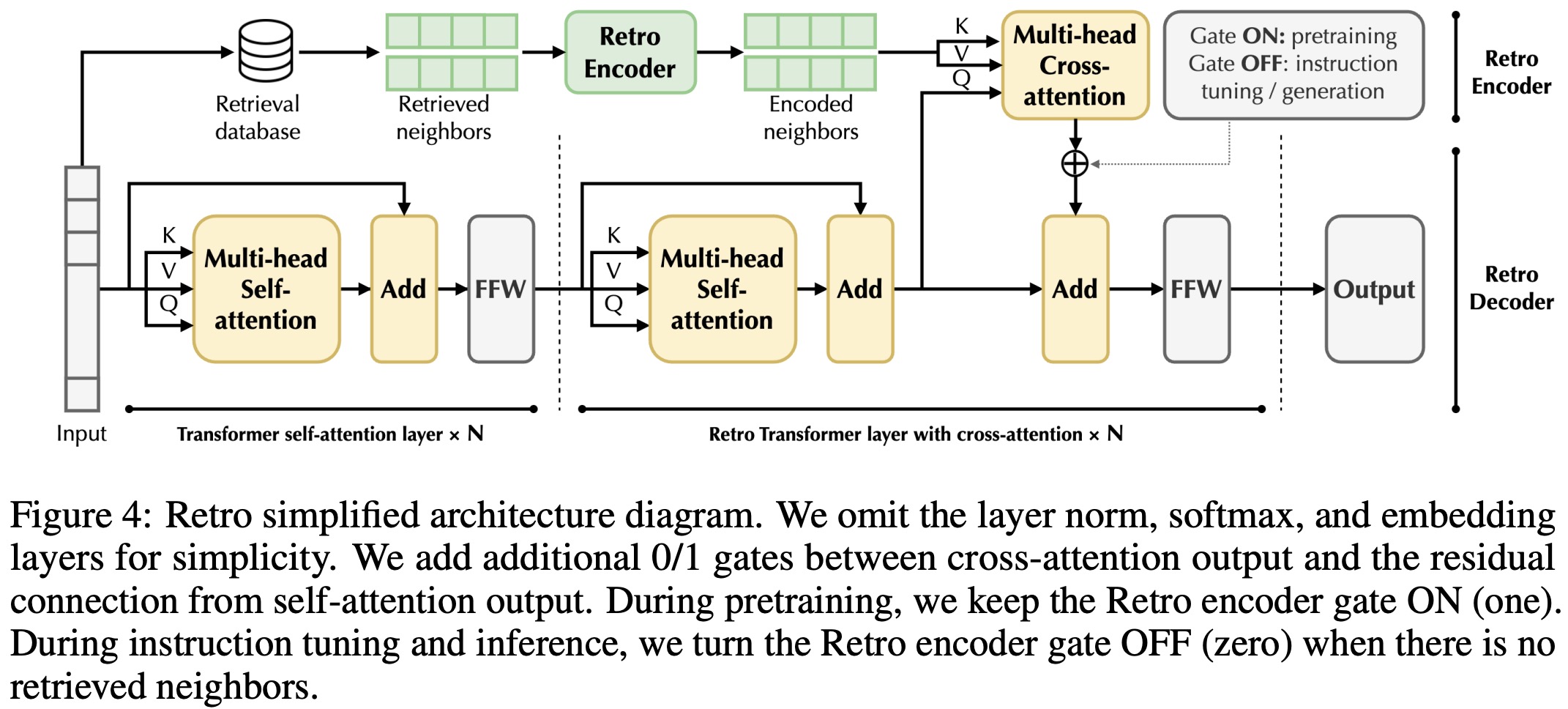
During training, multi-turn conversations between the user and the assistant are used as context, but the loss is applied only to the assistant’s last response, using standard language modeling loss with teacher forcing. Instruction tuning is especially effective with large models, so it’s applied to GPT-fitting 43B and Retro 48B, resulting in “GPT-Instruct 43B” and “InstructRetro 48B”.
While Retro shares many features with GPT, it differs in needing to retrieve nearest neighbors for input instructions. Since this retrieval can produce noisy neighbors from high-quality instruction data, a manual gating mechanism is used to skip cross-attention when neighbors aren’t available. This ensures only the decoder backbone weights are updated. This approach trains Retro to work both with and without retrieval, enhancing its generalization.
Experiments
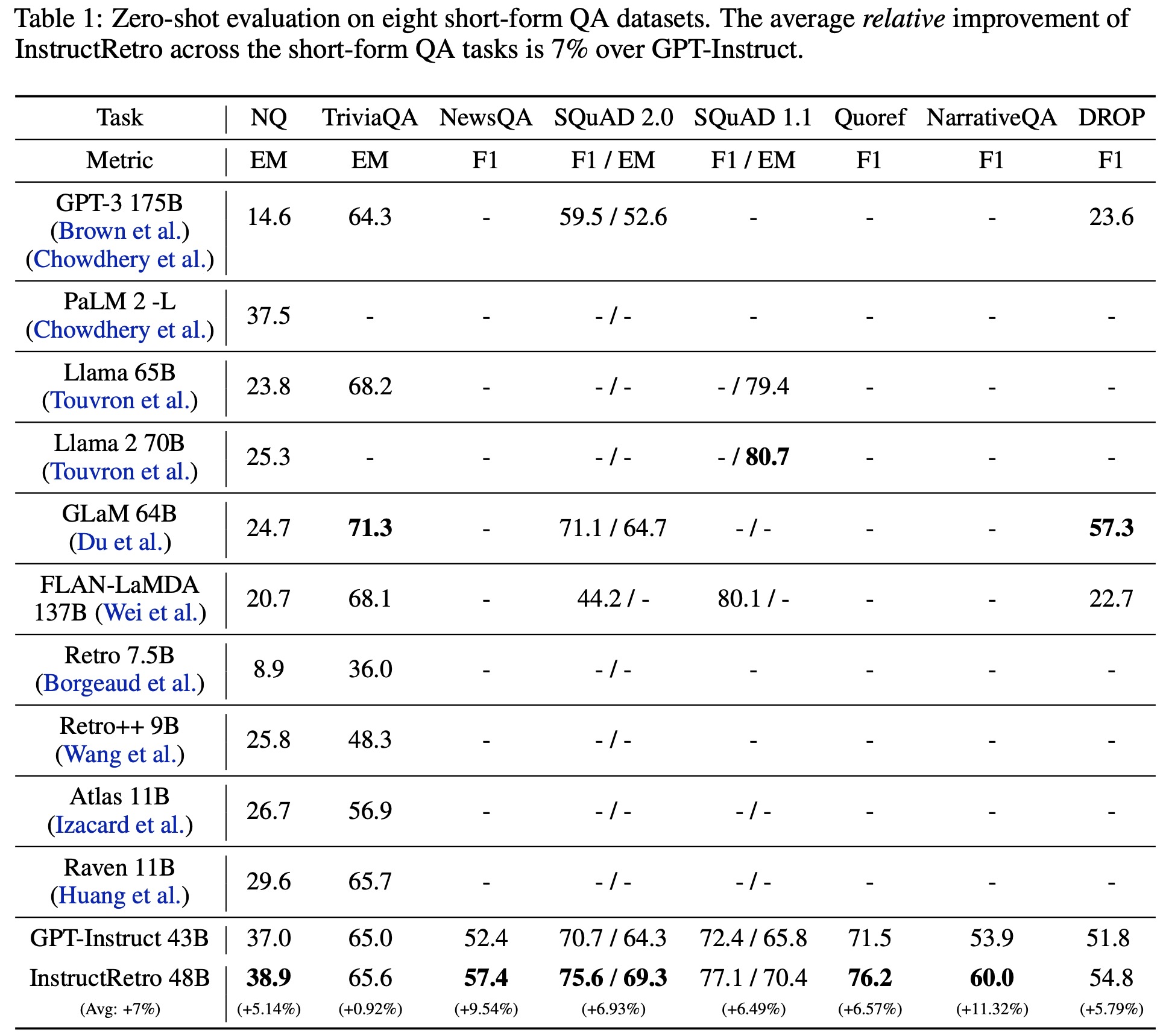

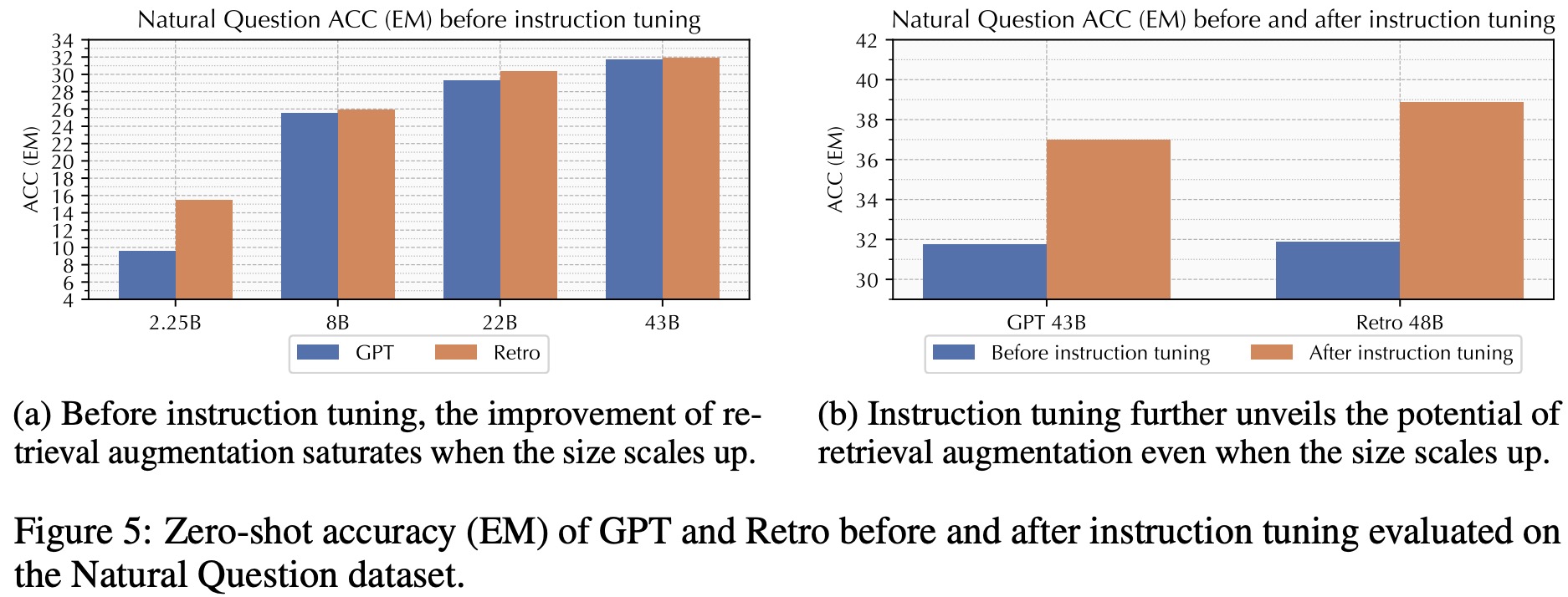
- In a zero-shot evaluation across eight short-form QA datasets and four open-ended long-form QA datasets, InstructRetro consistently outperforms GPT-Instruct in accuracy. The datasets represent real-world applications such as IT support chatbots. The average improvement of InstructRetro in short-form datasets is around 7%, and it even surpasses other state-of-the-art LLMs in performance. Its improvement is even more pronounced in long-form datasets, with a 10% accuracy increase over GPT-Instruct, emphasizing the benefits of retrieval-augmented pretraining.
- Ablation studies show that both retrieval-augmented pretraining and instruction tuning were essential for maximizing the potential of retrieval-augmented LLMs. While Retro performed better than GPT in zero-shot accuracy for smaller models, the performance of both models began to plateau as parameters increased. Instruction tuning helped overcome this plateau, particularly benefiting InstructRetro, which excels at utilizing retrieved context.
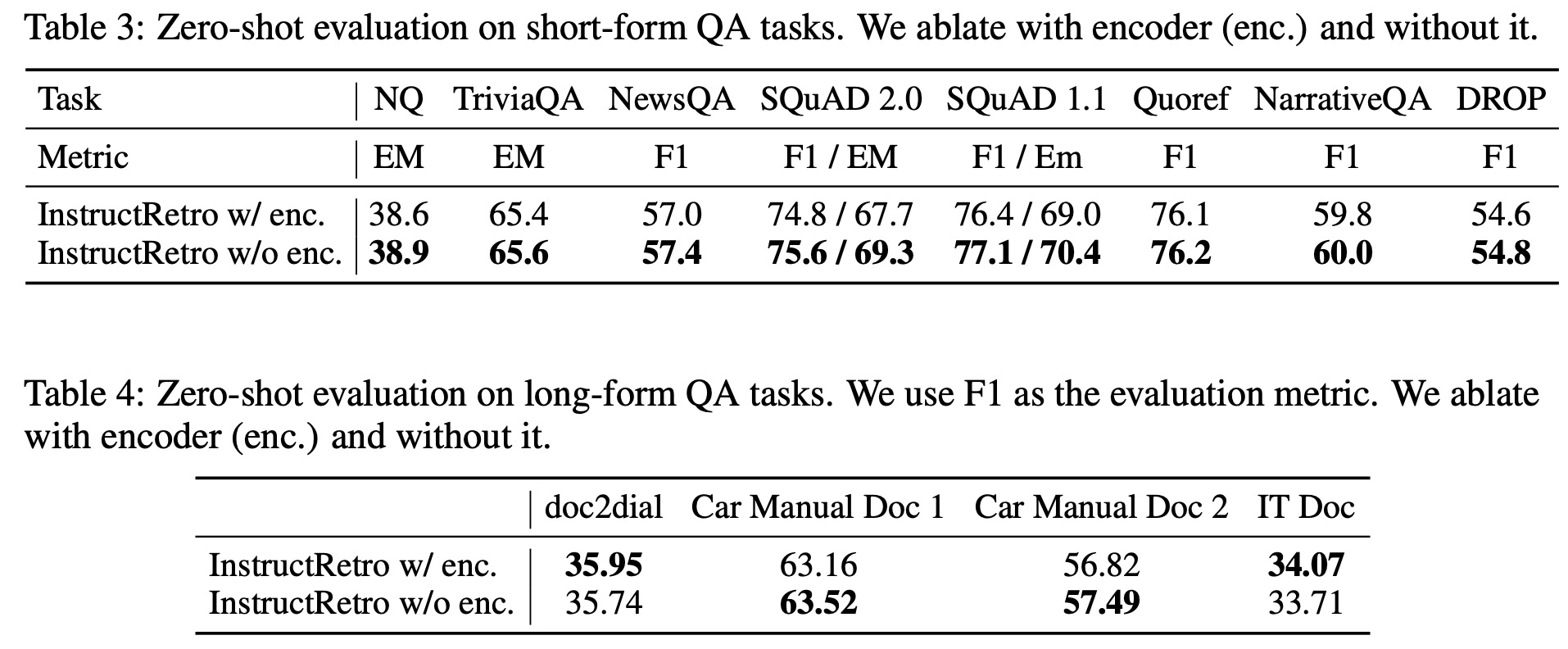
- Additionally, while the Retro encoder is used during retrieval-augmented pretraining, it’s disabled during instruction tuning. An ablation study comparing performance with and without the Retro encoder showed negligible differences in accuracy. Interestingly, bypassing the Retro encoder during evaluation yielded marginally better results.