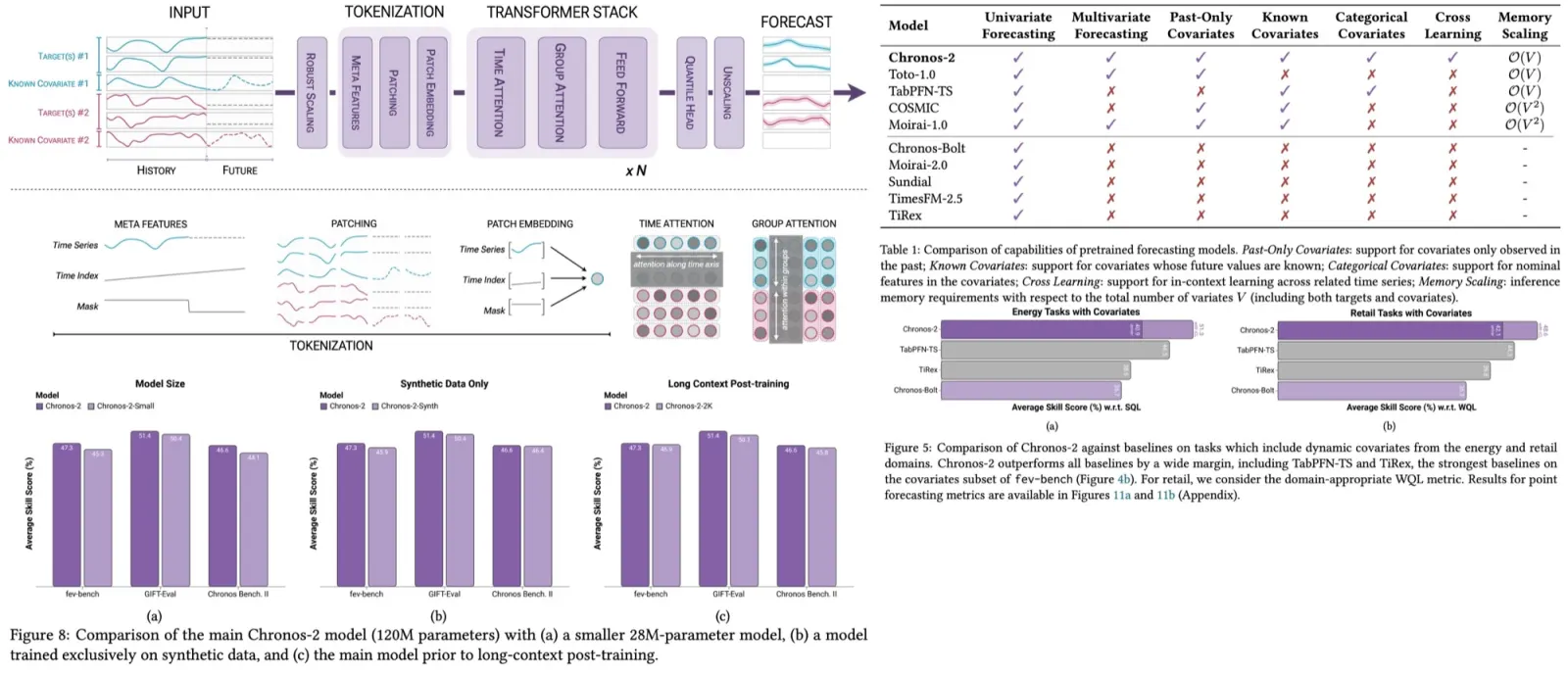
Paper Review: Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting
Lag-Llama is a new foundation model designed for univariate probabilistic time series forecasting, using a decoder-only transformer architecture with lags as covariates. It is pretrained on a diverse corpus of time series data from various domains, showcasing exceptional zero-shot generalization capabilities. When fine-tuned on small subsets of new datasets, Lag-Llama achieves superior performance, surpassing previous deep learning methods and setting new benchmarks in time series forecasting.
Probabilistic Time Series Forecasting
In univariate time series modelling the dataset comprises of one or more time series, each sampled at discrete time points, with the goal of predicting the future values. Instead of using the entire history of each time series for prediction, a fixed context window is used to learn an approximation of the distribution of the next values, incorporating covariates. Predictions are made through an autoregressive model, leveraging the chain rule of probability, and are conditioned on learned neural network parameters.
Lag-LLama
Tokenization: Lag Features

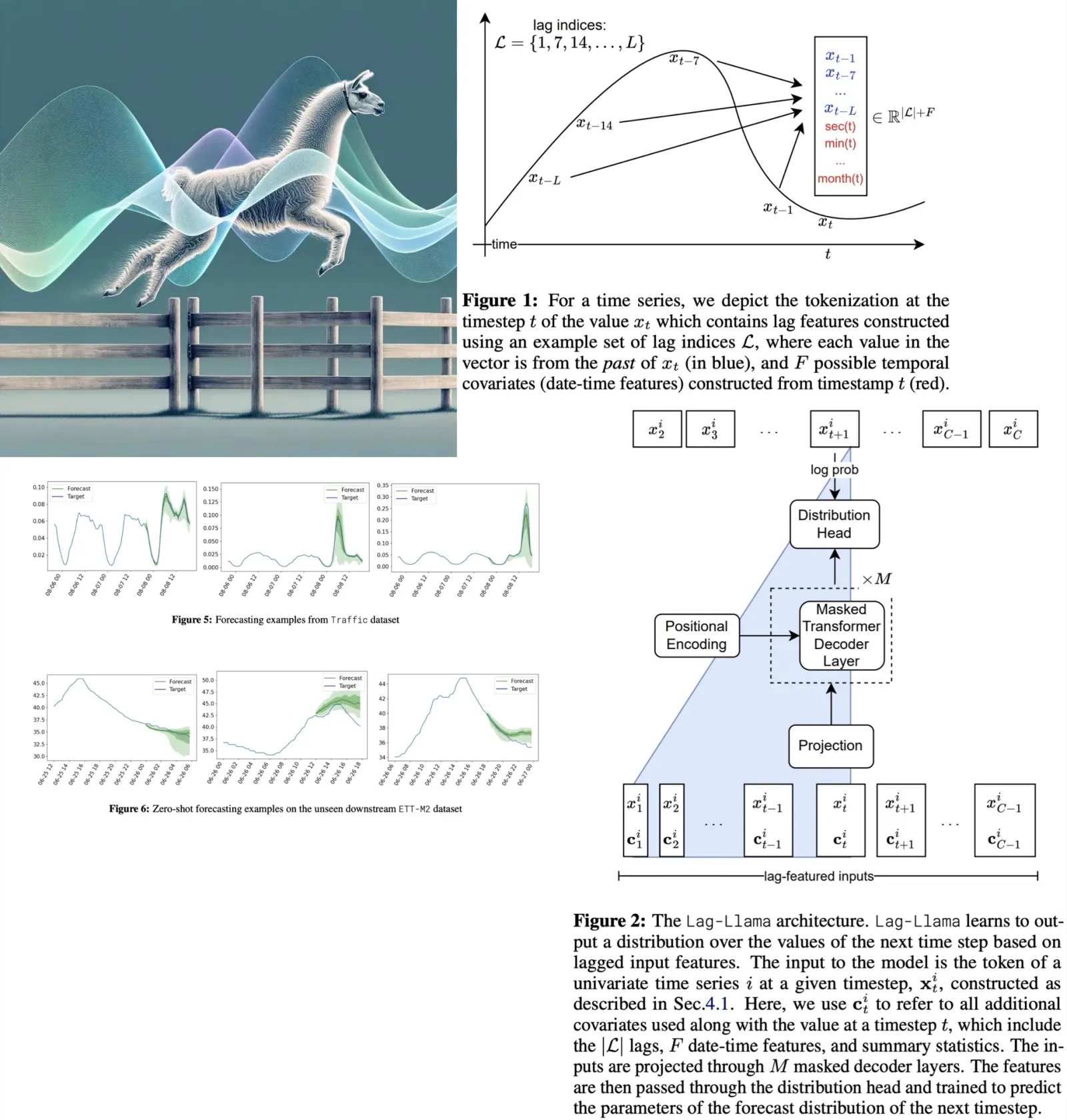
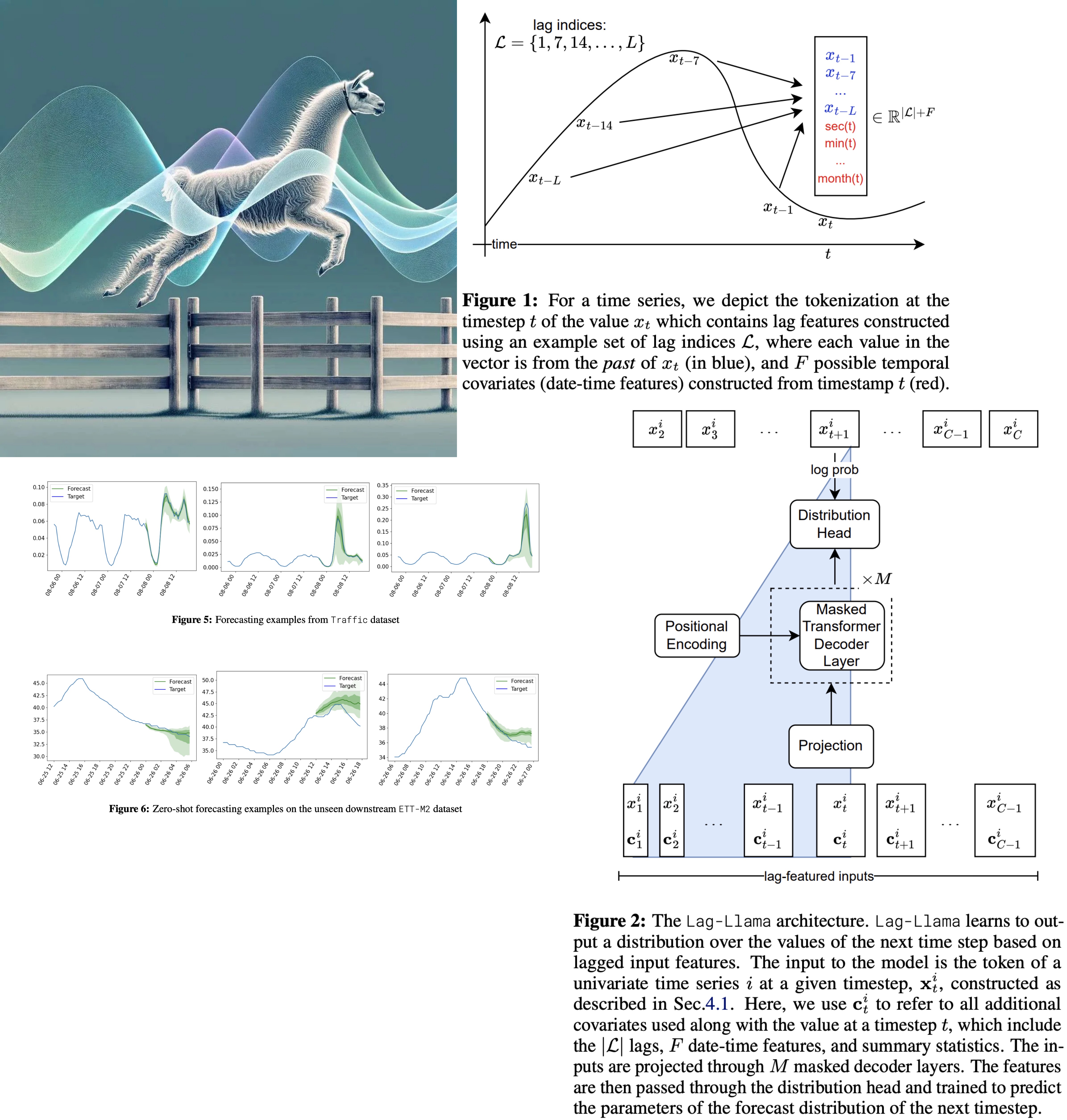
The tokenization process for Lag-Llama involves generating lagged features from prior time series values using specified lag indices that include quarterly, monthly, weekly, daily, hourly, and by the second. These lag indices create a vector for each time value, where each element corresponds to the value at a specific lag. Date-time features across different frequencies, from second-of-minute to quarter-of-year, are integrated to provide supplementary information and help the model understand the frequency of the time series. The resulting tokens comprise the size of the lag indices plus the number of date-time features. However, a limitation of this approach is the need for a context window that is at least as large as the number of lags used (by definition).
Lag-Llama Architecture
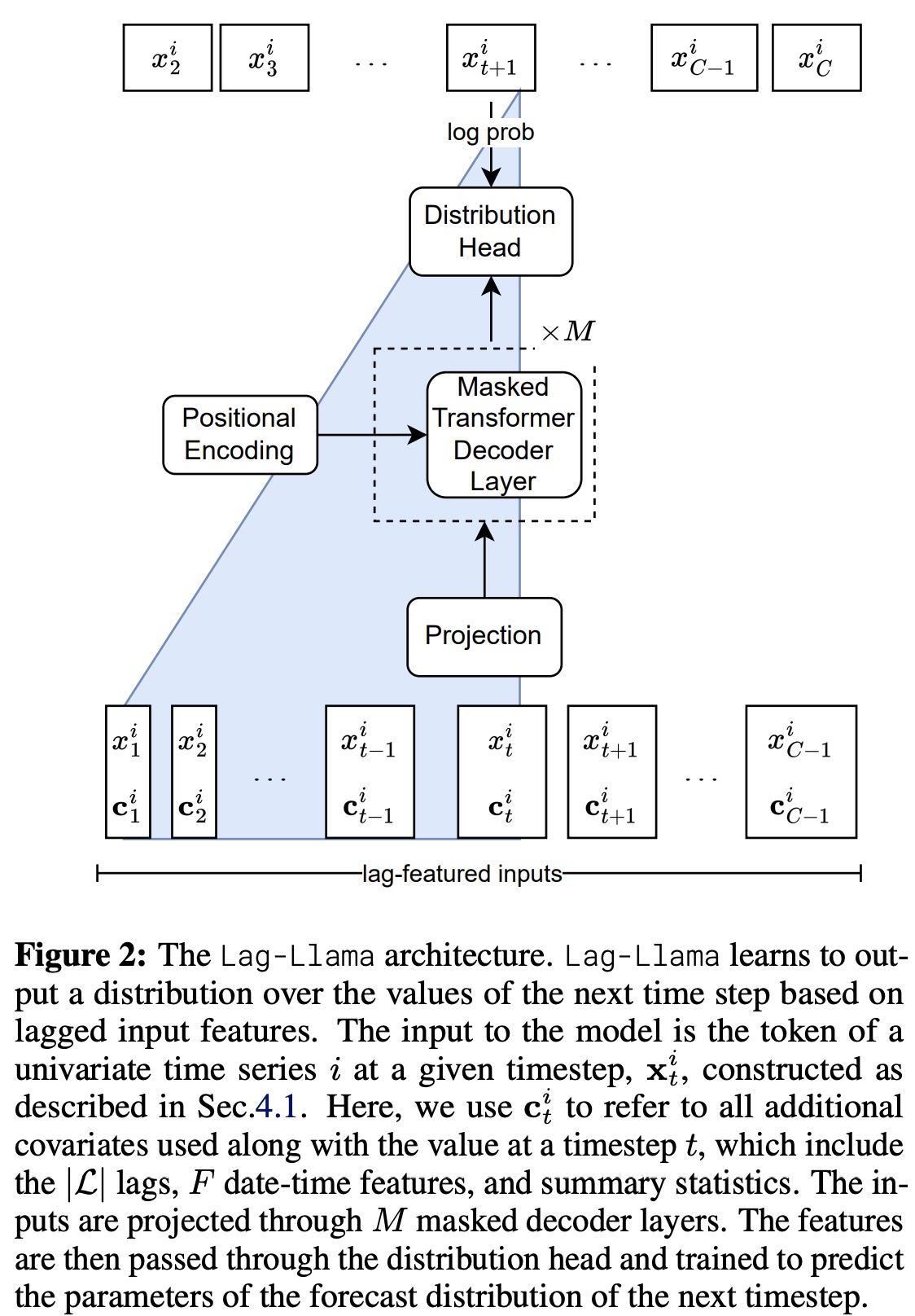
Lag-Llama uses a decoder-only transformer architecture, based on LLaMA, designed for univariate time series forecasting. The model processes sequences by first tokenizing them along with covariates into a sequence of tokens, which are then mapped to a hidden dimension suitable for the attention module. It incorporates pre-normalization techniques like RMSNorm and Rotary Positional Encoding to enhance its attention mechanism, aligning with the practices of the LLaMA architecture. The transformer layers, which are causally masked to prevent future information leakage, output the parameters of the forecast distribution for the next time step. The model’s training objective is to minimize the negative log-likelihood of this predicted distribution across all time steps.
For predictions, Lag-Llama takes a feature vector from a time series, generating a distribution for the next time point through greedy autoregressive decoding. This process allows for the simulation of multiple future trajectories up to a predefined prediction horizon. From these simulations, uncertainty intervals can be calculated, aiding in downstream decision-making and evaluation against held-out data.
The final component of Lag-Llama is the distribution head, a layer that translates the model’s learned features into parameters of a specific probability distribution. In their experiments, the creators adopted a Student’s t-distribution, configuring the distribution head to output its three parameters: degrees of freedom, mean, and scale, with special adjustments to maintain the positivity of these parameters.
To handle the diversity in numerical magnitudes across different time series datasets during pretraining, Lag-Llama employs a scaling heuristic. For each univariate window, it calculates the mean and variance of the time series within the window and standardizes the time series data by subtracting the mean and dividing by the variance. Additionally, the mean and variance are included as time-independent covariates (summary statistics) alongside each token to inform the model about the input data’s statistical properties.
Furthermore, the model adopts a Robust Standardization: normalizing the time series by subtracting the median and scaling by the Interquartile Range, making the preprocessing step more robust to extreme values in the data.
During training, the authors use stratified sampling and augmentation technics Freq-Mix and Freq-Mask.
Experiments
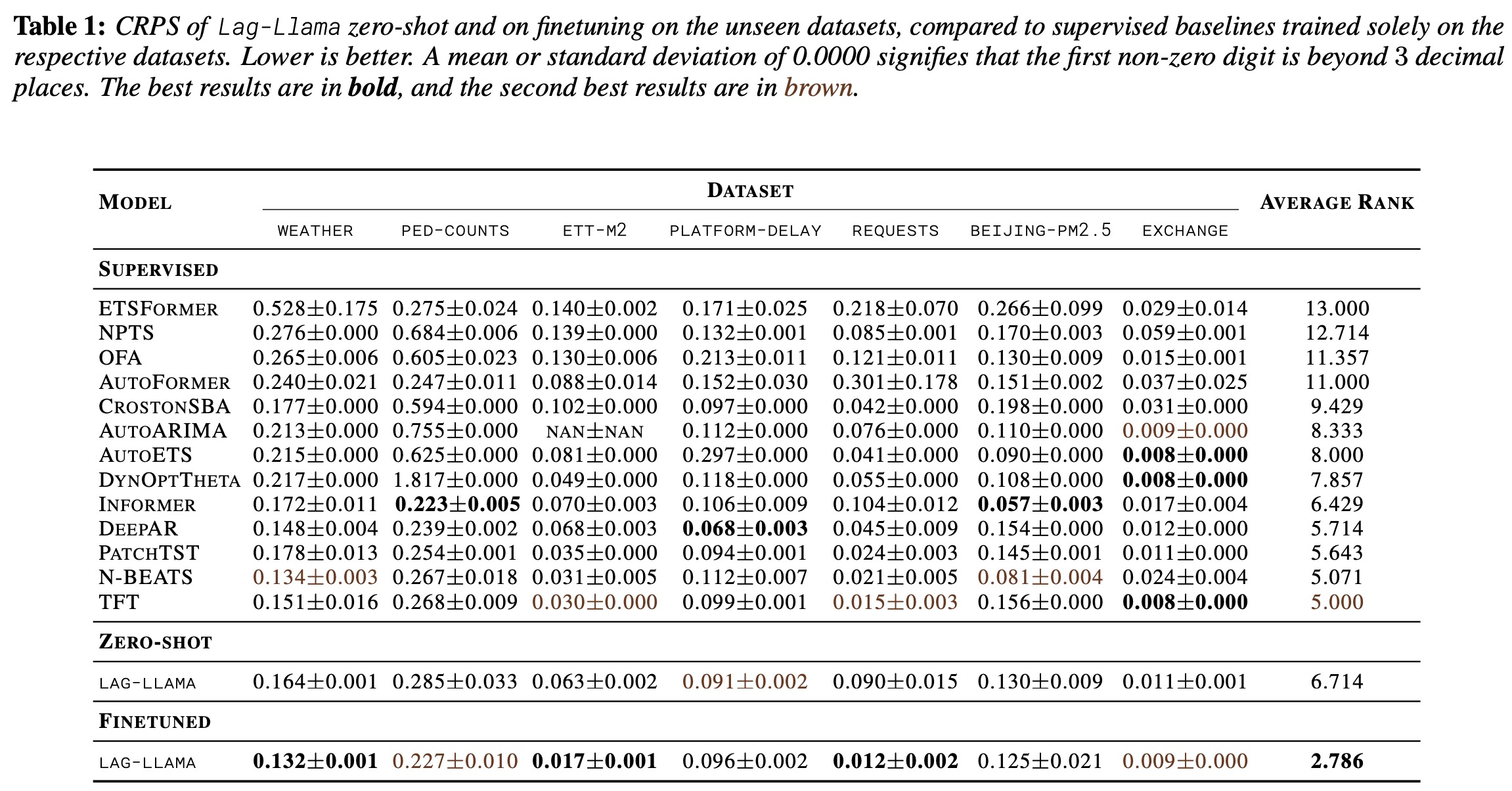
Lag-Llama demonstrates strong performance in time series forecasting, comparing favorably with supervised baselines across unseen datasets in both zero-shot and fine-tuned settings. In the zero-shot scenario, it matches the performance of all baselines with an average rank of 6.714. Fine-tuning further enhances its capabilities, leading to state-of-the-art performance in three of the used datasets and significantly improved performance in others, achieving the best average rank of 2.786. This performance underscores Lag-Llama’s potential as a go-to method for diverse datasets without prior data knowledge, fulfilling a foundational model’s key requirement.
The experiments suggest that at scale, decoder-only transformers may outperform other architectures in time series forecasting, mirroring observations from the NLP community regarding the impact of inductive bias.
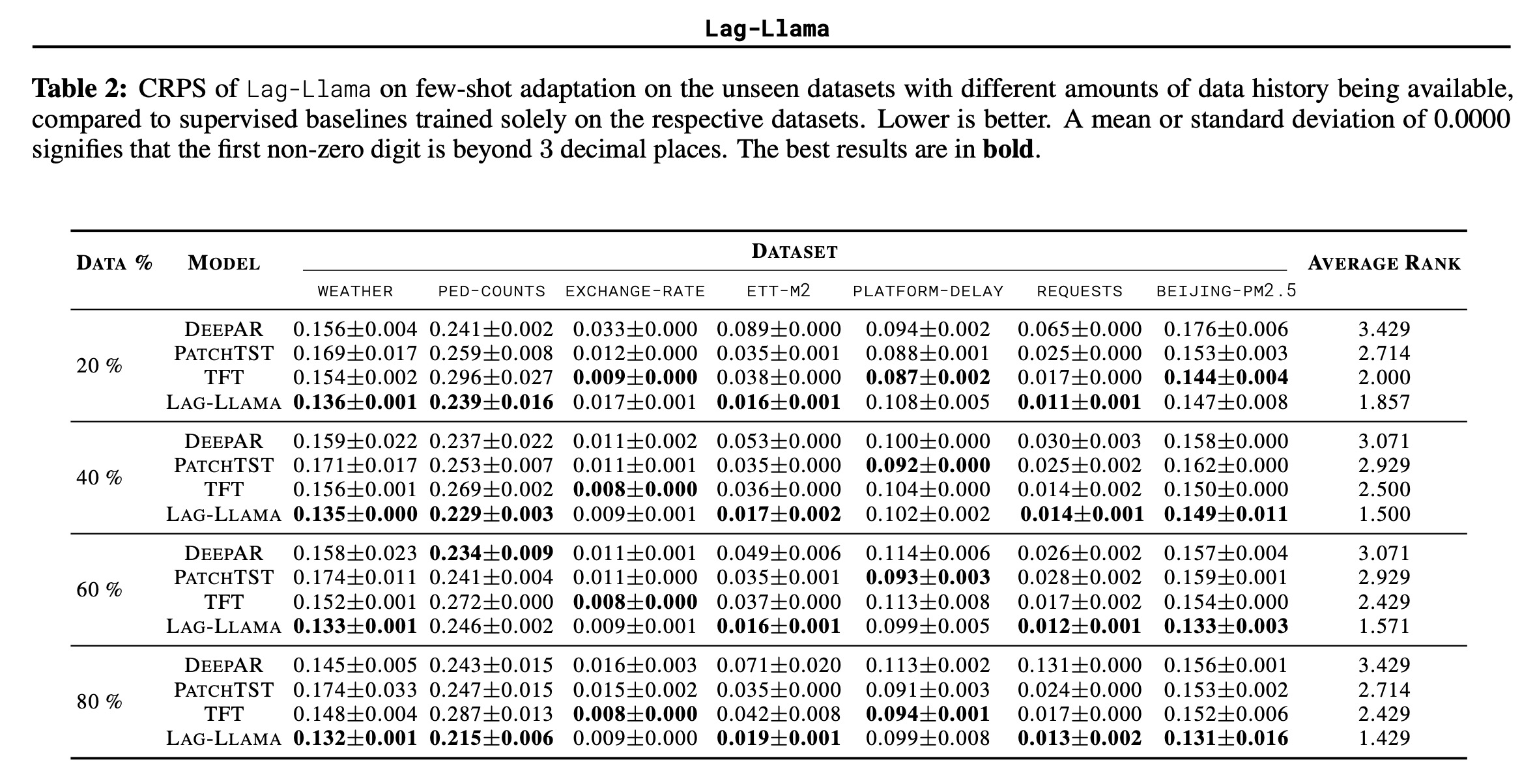
Lag-Llama was also evaluated on its ability to adapt to different amounts of historical data, with experiments conducted using only the last 20%, 40%, 60%, and 80% of the data from training sets. Lag-Llama was fine-tuned and consistently achieved the best average rank across all levels of available history, showcasing its strong adaptation capabilities. As the volume of available history increased, so did Lag-Llama’s performance, widening the performance gap between it and baseline models.
However, it’s noted that in the exchange-rate dataset, which represented a new domain and frequency not seen during pretraining, Lag-Llama was frequently outperformed by the TFT model, suggesting that Lag-Llama benefits from more historical data in scenarios where the dataset is significantly different from the pretraining corpus.
paperreview deeplearning llm timeseries