Paper Review: LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models

This work focuses on developing a high-quality text-to-video generative model using a pre-trained text-to-image model as a foundation. The goal is to create visually realistic, temporally coherent videos and maintain the creative generation capabilities of the T2I model. The proposed solution is LaVie, a video generation framework that utilizes cascaded video latent diffusion models, including a base T2V model, a temporal interpolation model, and a video super-resolution model.
The study has two main insights:
- Simple temporal self-attentions with rotary positional encoding effectively capture the temporal correlations in video data.
- Joint image-video fine-tuning is crucial for achieving high-quality and creative results.
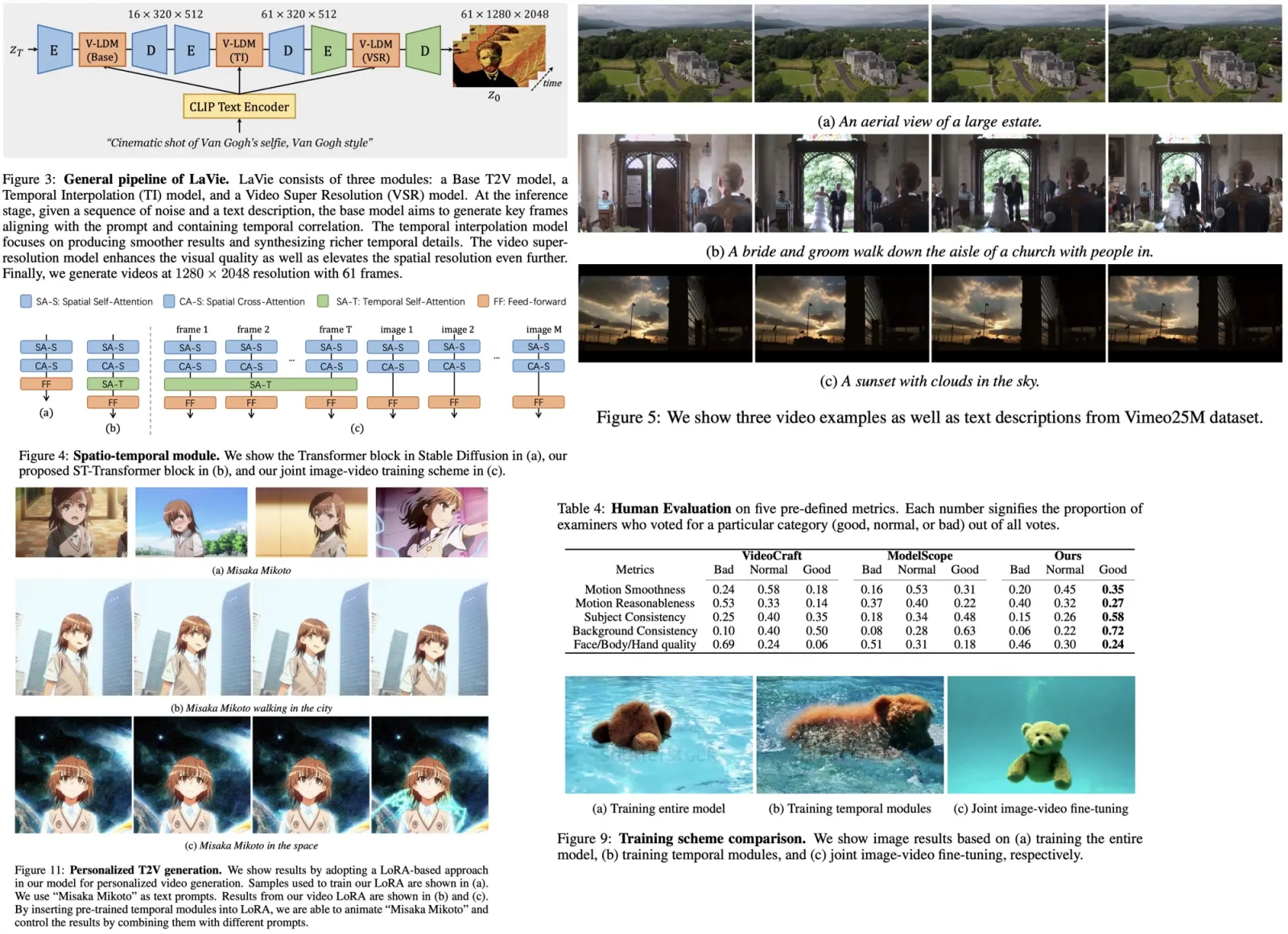
A diverse video dataset, Vimeo25M, consisting of 25 million text-video pairs, is introduced to improve LaVie’s performance, focusing on quality, diversity, and aesthetic appeal. LaVie has demonstrated superior performance quantitatively and qualitatively in extensive experiments and has proven versatile in long video generation and personalized video synthesis applications.
Approach

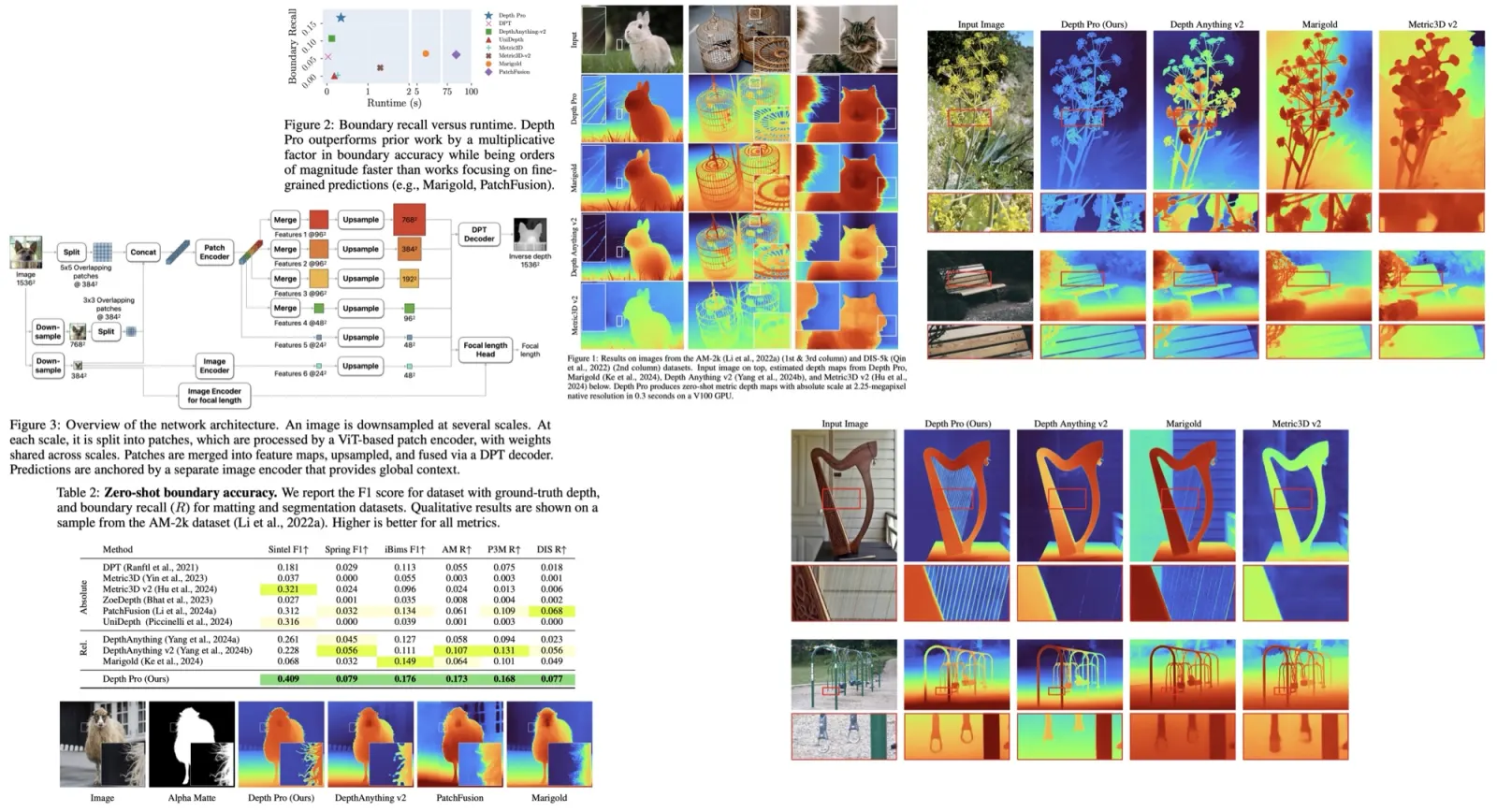
LaVie framework is a cascaded system designed for generating videos based on text descriptions using Video Latent Diffusion Models. It consists of three distinct networks:
- A Base T2V model generates short, low-resolution key frames.
- A Temporal Interpolation model interpolates these short videos to increase the frame rate.
- A Video Super Resolution model synthesizes high-definition videos from low-resolution ones.
Each model is trained individually, with text inputs serving as conditioning information. During the inference stage, LaVie, given latent noises and a textual prompt, can generate a 61-frame video with a resolution of 1280×2048 pixels.
Base T2V Model
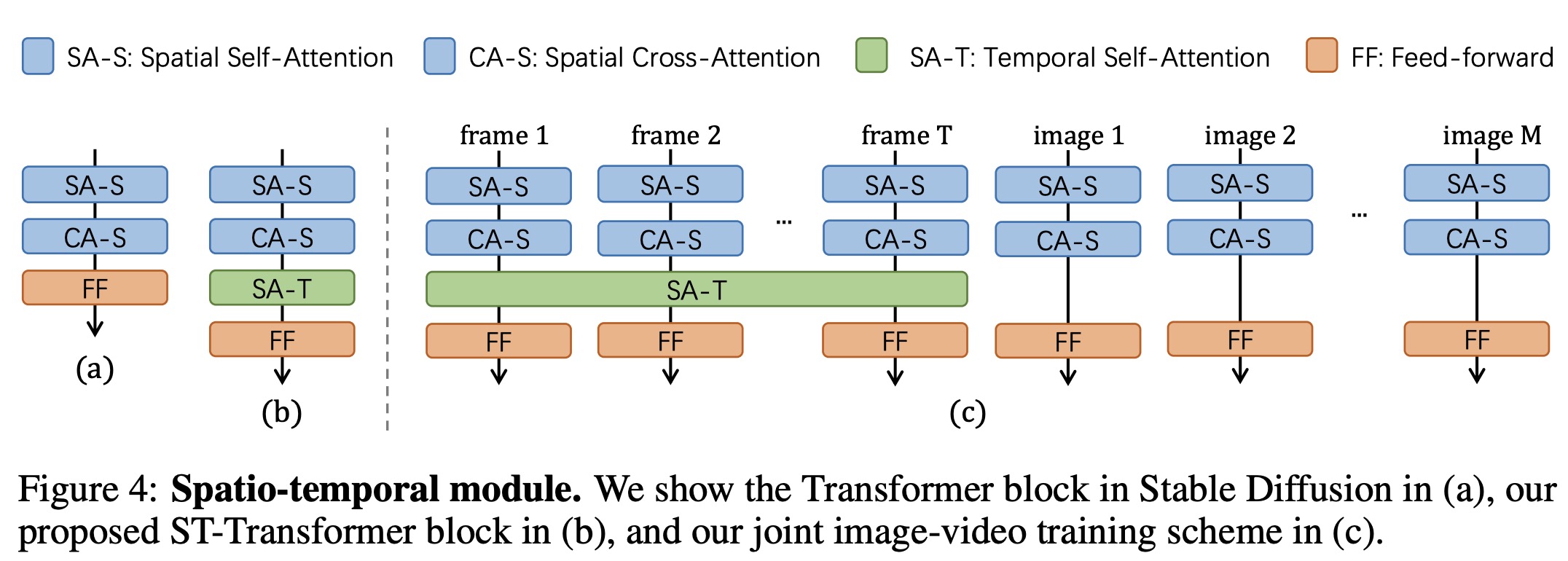
The original Latent Diffusion Model LDM, a 2D UNet, is modified by inflating each 2D convolutional layer to include an additional temporal dimension, creating a pseudo-3D convolutional layer. This modification introduces an extra temporal axis to the input tensor. Additionally, the original transformer block is extended to a Spatio-Temporal Transformer by adding a temporal attention layer after each spatial layer, incorporating Rotary Positional Encoding to integrate the temporal attention layer. This approach is simpler and more effective than previous methods, avoiding the introduction of an additional Temporal Transformer.
The base model aims to generate high-quality key frames that preserve diversity and capture the compositional nature of videos, synthesizing videos aligned with creative prompts. However, fine-tuning solely on video datasets leads to catastrophic forgetting, causing the model to forget previous knowledge rapidly. To counter this, a joint fine-tuning approach using both image and video data is applied. Images are concatenated along the temporal axis to form a T-frame video, and the model is trained to optimize the objectives of both T2I and T2V tasks.
This method significantly improves video quality and successfully transfers various concepts from images to videos, including different styles, scenes, and characters. The resulting base model, without modifying the architecture of LDM and jointly trained on both image and video data, is capable of handling both T2I and T2V tasks, demonstrating the generalizability of the proposed design.
Temporal Interpolation Model
The base T2V model is extended by introducing a temporal interpolation network to enhance the smoothness and detail of the generated videos. A diffusion UNet is trained specifically to quadruple the frame rate of the base video, taking a 16-frame base video and producing an upsampled 61-frame output.
During training, base video frames are duplicated to match the target frame rate and concatenated with noisy high-frame-rate frames, which are then fed into the diffusion UNet. The UNet is trained with the objective of reconstructing noise-free high-frame-rate frames, enabling it to learn denoising and generate interpolated frames. At inference time, base video frames are concatenated with randomly initialized Gaussian noise, and the diffusion UNet removes this noise, generating 61 interpolated frames.
This approach is distinct as each frame generated through interpolation replaces the corresponding input frame, differing from conventional methods where input frames remain unchanged during interpolation. The diffusion UNet is also conditioned on the text prompt, serving as additional guidance for the temporal interpolation process and enhancing the overall quality and coherence of the generated videos.
Video super-resolution model
To elevate the visual quality and spatial resolution of the generated videos, a VSR model is integrated into the video generation pipeline. This model involves training an LDM upsampler to increase the video resolution to 1280×2048. A pre-trained diffusion-based image ×4 upscaler is leveraged as a prior, and it is adapted to process video inputs in 3D by incorporating an additional temporal dimension within the diffusion UNet. This adaptation includes the introduction of temporal layers, such as temporal attention and a 3D convolutional layer, to enhance temporal coherence in the generated videos.
The diffusion UNet, considering additional text descriptions and noise levels as conditions, allows for flexible control over the texture and quality of the enhanced output. The focus is on fine-tuning the inserted temporal layers in the V-LDM while the spatial layers in the pre-trained upscaler remain fixed. The model undergoes patchwise training on 320 × 320 patches, utilizing the low-resolution video as a strong condition, preserving its intrinsic convolutional characteristics and allowing for efficient training on patches with the capability to process inputs of arbitrary sizes.
Experiments



Qualitative Evaluation:
- LaVie successfully synthesized diverse content, demonstrating strong spatial and temporal concept combination capabilities, e.g., synthesizing actions like “Yoda playing guitar.”
- Compared to three state-of-the-art models, LaVie showed superior visual fidelity and effective style capture, attributed to the initialization from a pretrained LDM and joint image-video fine-tuning.
Quantitative Evaluation:
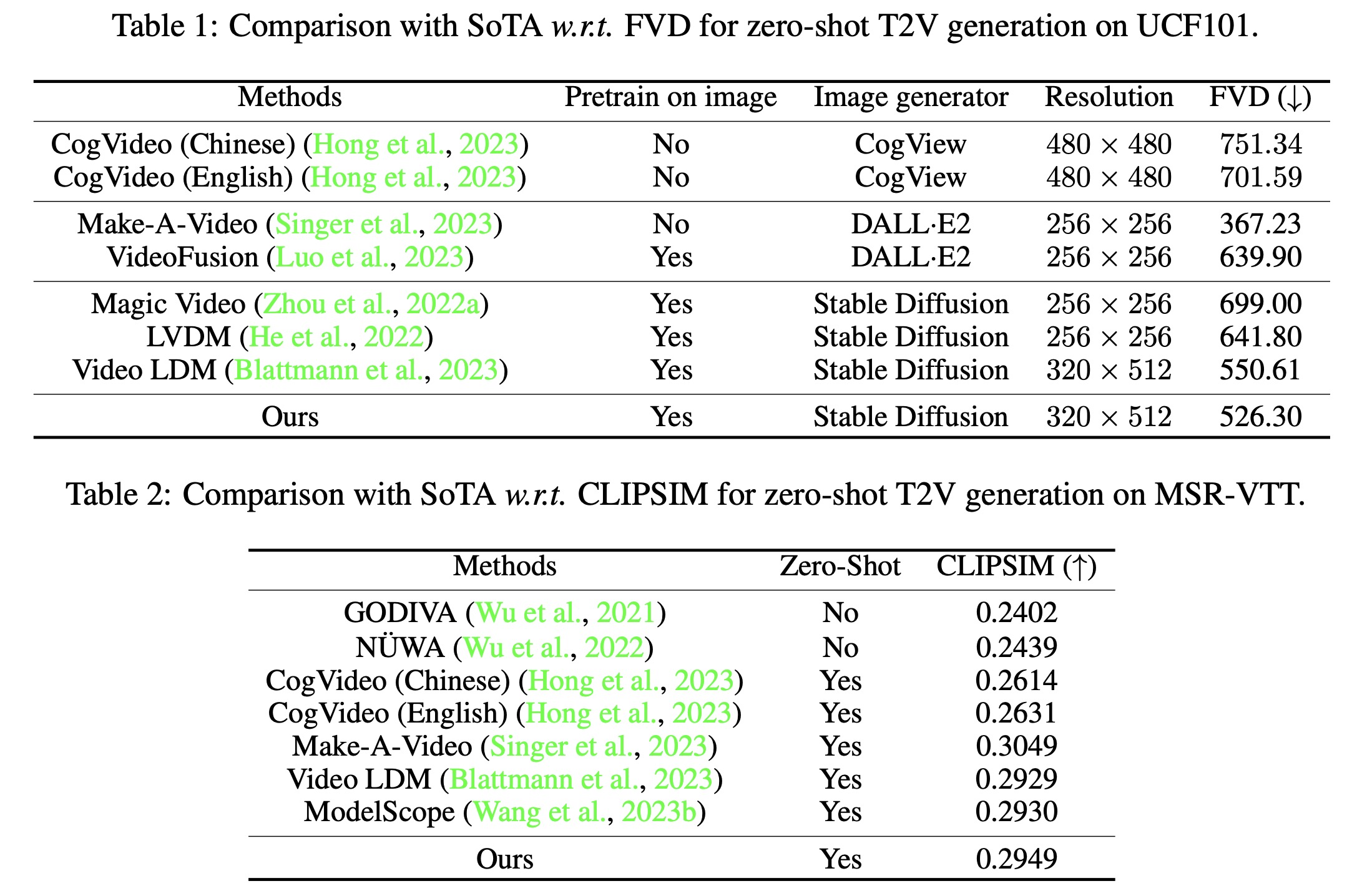
- LaVie was evaluated on UCF101 and MSR-VTT datasets, demonstrating superior performance in most cases.
- The model outperformed all baseline methods on the UCF-101 dataset, using a smaller training dataset and direct class names as text prompts.
- On the MSR-VTT dataset, LaVie showed superior or competitive performance in text-video semantic similarity, highlighting the effectiveness of the proposed training scheme and the Vimeo25M dataset.
Human Evaluation:
- 30 human raters assessed the videos on various metrics, including motion smoothness, subject consistency, and face, body, and hand quality. LaVie surpassed the other approaches in preference among human raters, but all models faced challenges in achieving satisfactory scores in motion smoothness and producing high-quality face, body, and hand visuals.
More applications

For long video generation, a simple recursive method is introduced to extend the generation of videos beyond a single sequence. This involves incorporating the first frame of a video into the input layer of a UNet and fine-tuning the base model to utilize the last frame of the generated video as a conditioning input during inference.

Additionally, the versatility of LaVie is demonstrated through its adaptation for personalized T2V generation. This is achieved by integrating a personalized image generation approach, such as LoRA, and fine-tuning the spatial layers of the model using LoRA on self-collected images while the temporal modules are kept frozen. This adaptation allows LaVie to synthesize personalized videos based on various prompts, creating scenes where specific characters are depicted in novel places.
Limitations

While LaVie has achieved notable success in general text-to-video generation, it does have certain limitations, particularly in multi-subject generation and hands generation. The models face challenges in generating scenes with more than two subjects, often mixing appearances instead of generating distinct individuals. This issue is not unique to LaVie and has been observed in other models like the T2I model. A potential solution could be replacing the current language model, CLIP, with a model that has a more robust language understanding, like T5, to enhance the model’s comprehension and representation of complex language descriptions and mitigate subject mixing in multi-subject scenarios.
Additionally, generating high-quality, realistic representations of human hands is a persistent challenge, with the model often struggling to depict the correct number of fingers. To address this, a potential solution involves training the model on a larger and more diverse dataset containing videos with human subjects, allowing the model to be exposed to a wider range of hand appearances and variations and enabling it to generate more realistic and anatomically correct hands.
paperreview deeplearning cv diffusion