Paper Review: LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Code and checkpoints are available here (not published at the moment of writing this review).
An interesting paper from Microsoft.
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
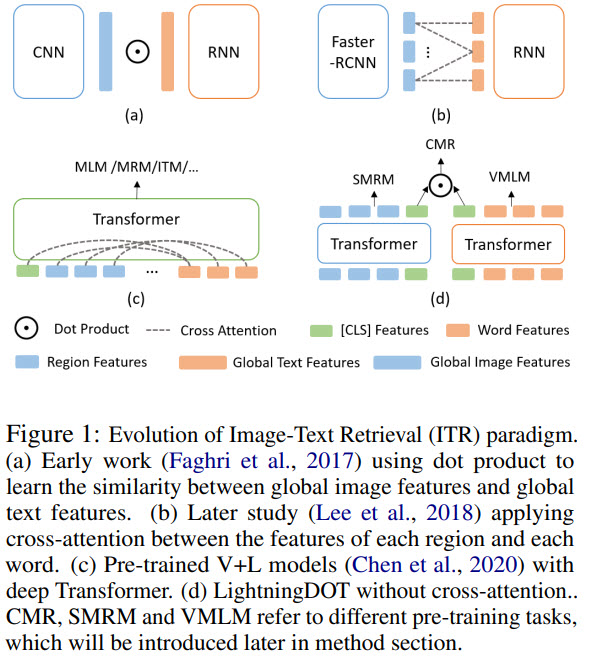
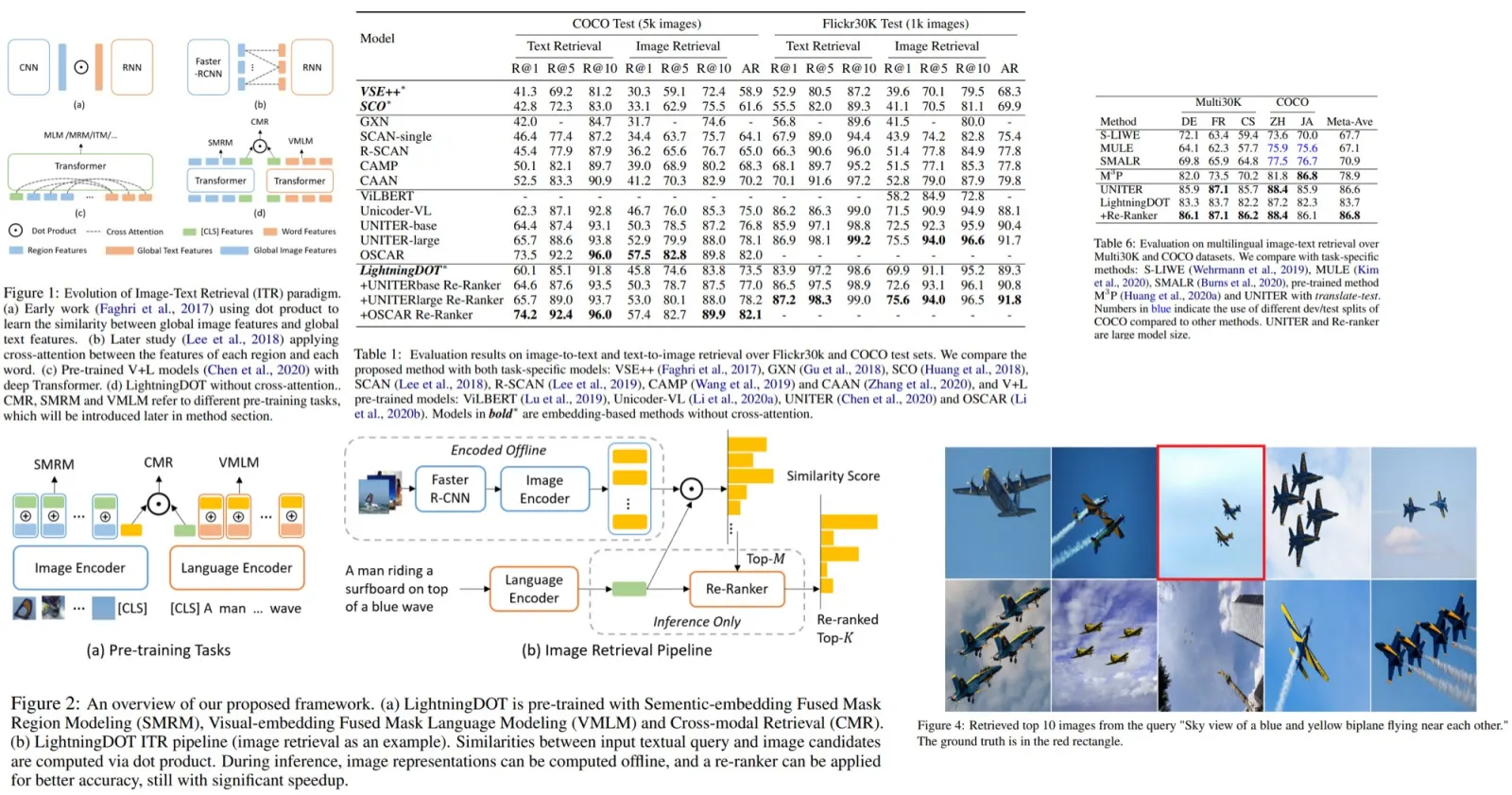
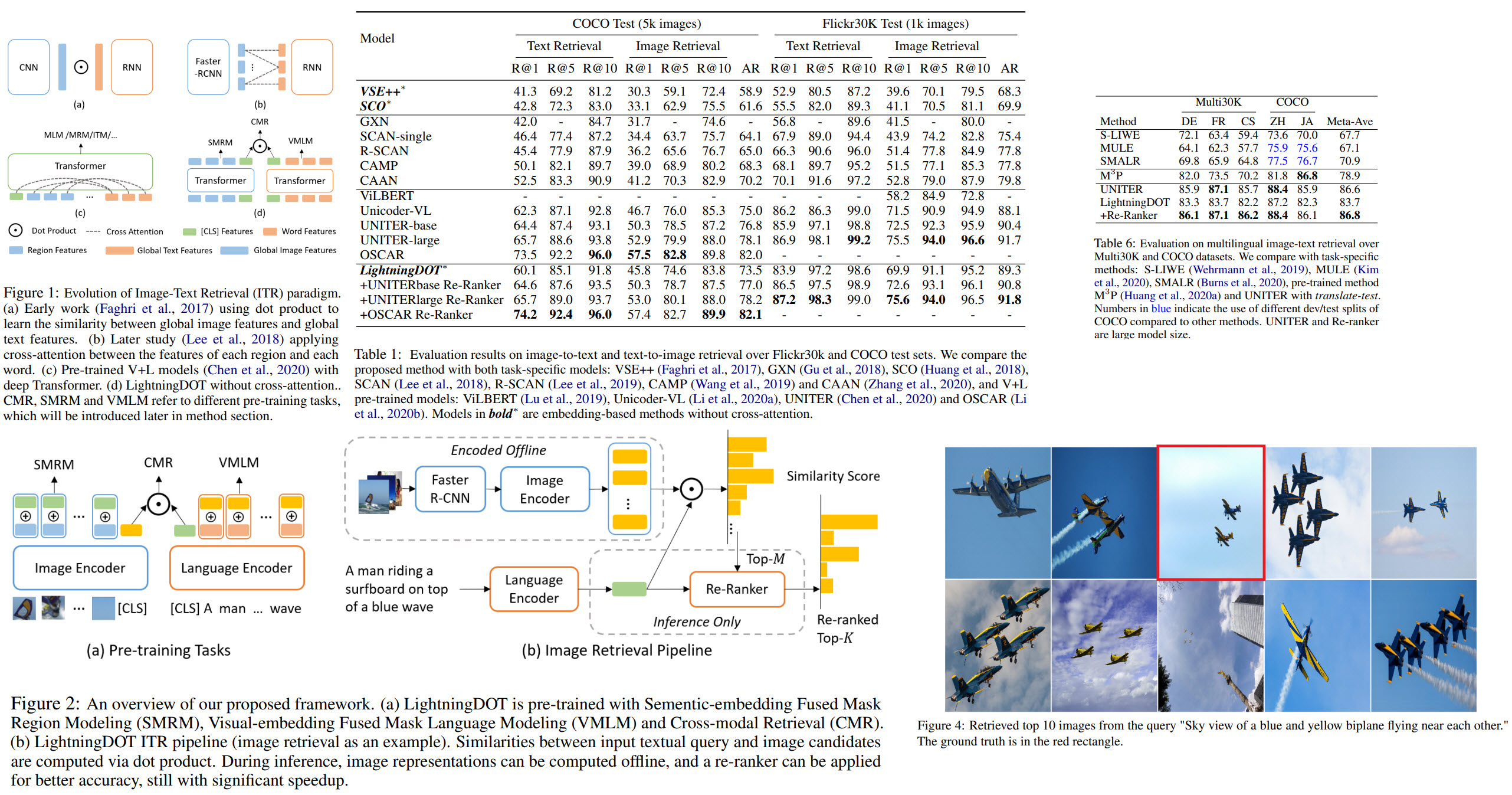
Traditional ITR (Image-Text Retrieval) approaches use ranking over visual-semantic embedding matching or deep cross-modal fusion with an attention mechanism. In the earlier works, images and texts were encoded separately, and the similarity between them was calculated by the dot product.
Nowadays, vision-and-language (V+L) pre-trained models (ViLBERT, UNITER) have better performance. They learn joint text and image embeddings and use cross-modal attention. Even though this attention improves model performance, inference speed suffers due to the size of the models.
For example, the UNITER model takes 48 seconds to make an inference on a text query from the COCO dataset (wow, that’s really slow).
Thus, the authors of the paper have decided that reverting to dot-product should increase the inference speed. To compensate for this simpler method, they use the [CLS] token in both encoders, which transfers the learned embeddings from the other modality.
Also, thanks to this approach, it is possible to precalculate image and text embeddings offline.
For model training three learning objectives are used: VMLM (Visual-embedding fused MLM), SMRM (Semantic-embedding fused MRM), CMR (cross-modal retrieval).
Furthermore, after making an inference, we can use any other model for re-ranking.
LightningDOT Framework
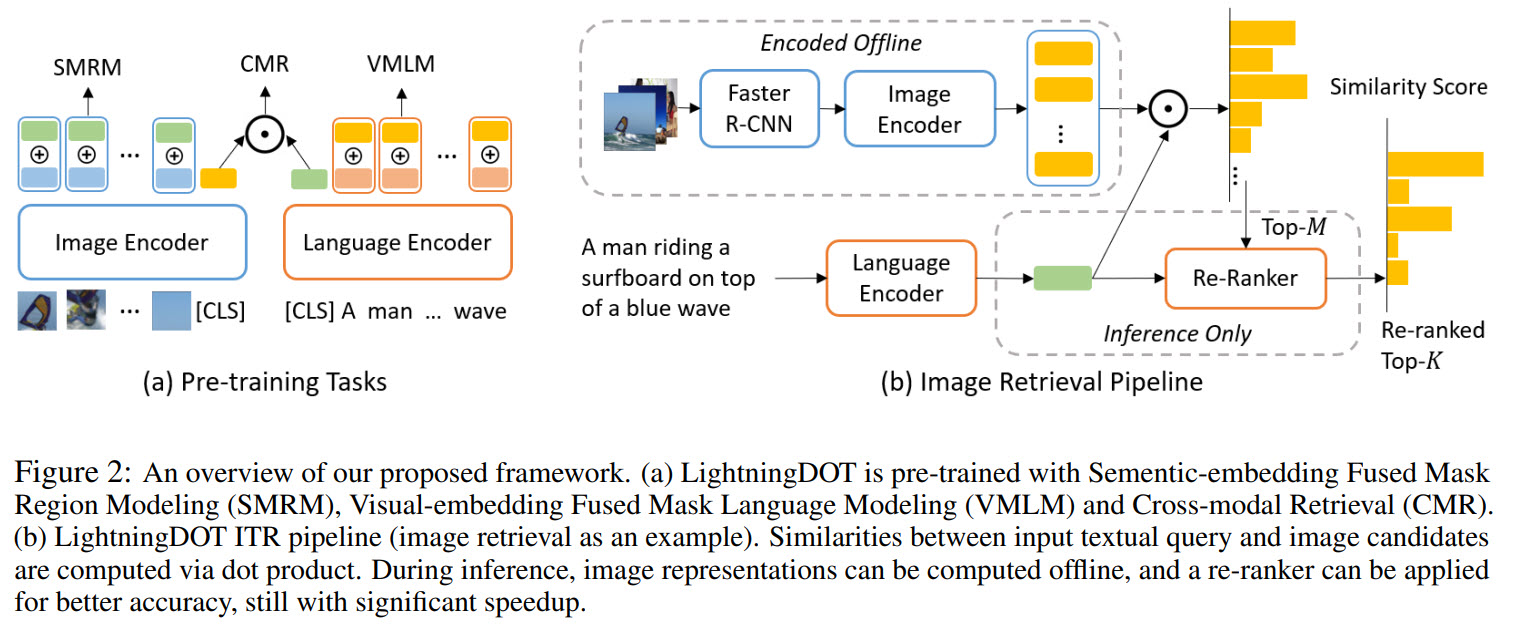
Pre-training
We have a dataset of paired images and texts. Region features are extracted from images using a pre-trained Faster-RCNN. Texts are tokenized like in BERT (30k BPE vocabulary is used). The first image token is regarded as a global image representation, the first text token - as a global text representation.
Visual-embedding Fused Masked Language Modeling (VMLM)
MLM - masking 15% of words are masked, and the model tries to predict them. In VMLM, a paired image (or, to be more precise, the global image representation) is used as an additional input to the model.
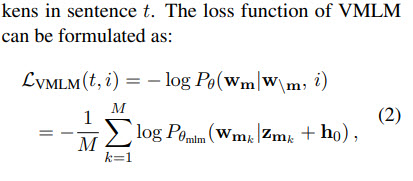
Semantic-embedding Fused Masked Region Modeling (SMRM)
The idea of MRM is similar to MLM - a part of the image is masked, and the model tries to reconstruct it. Global text representation is added to the learning objective.
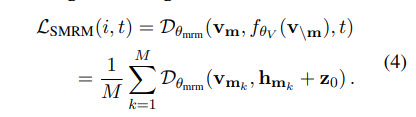
Cross-modal Retrieval Objective (CMR)
This objective uses the paired information between an image and a text: the model is optimized to promote a high similarity score for a matched image-sentence pair.
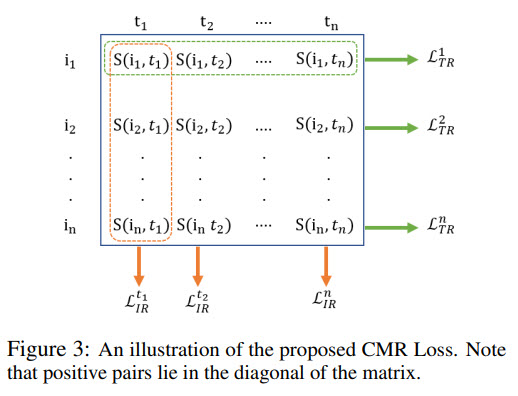
A bi-directional variant of contrastive loss is used here.

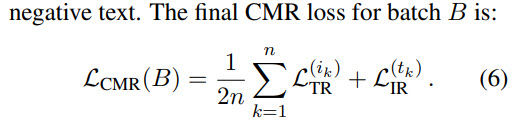
For finetuning only CMR loss is used.
Real-time inference
The authors describe text-to-image retrieval. Text retrieval is done symmetrically.
Offline Feature Extraction
The image encoder extracts features from all images; a global representation is cached into an index.
Online Retrieval
The text query is encoded using the language encoder, then a similarity score to all image embeddings is calculated. Top K images are selected using FAISS.
Re-ranking
Now that we have top K results, we can re-rank them using a stronger retrieval model. This model will be slower, but it re-ranks not all data in the database, but only K results, so it is okay. After the model we have new M top results.
Experiments
Dataset and metrics
For pre-training they use data as in UNITER: 4.2 mln images with 9.5 mln captures, including COCO, VG, Conceptual Captions, and SBU captions.
For evaluation they use Flickr30k and COCO.
Performance is measured by Recall @ K. Additionally, they use AR metric - an average of all R@K.
Results
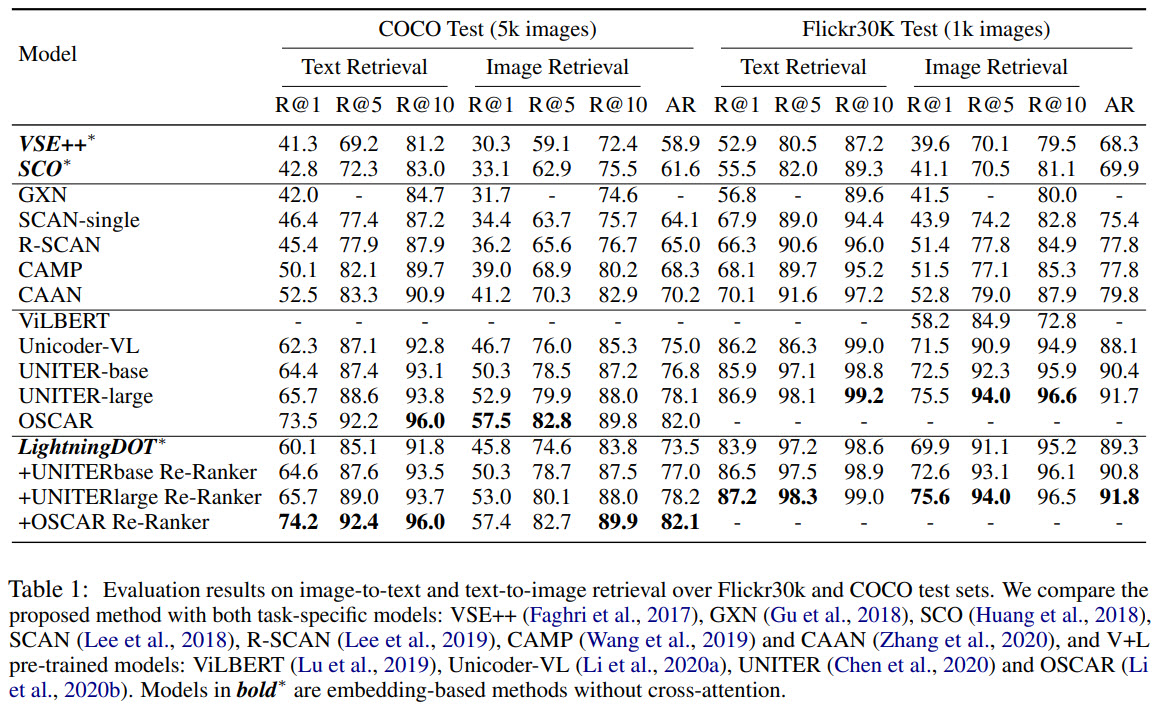
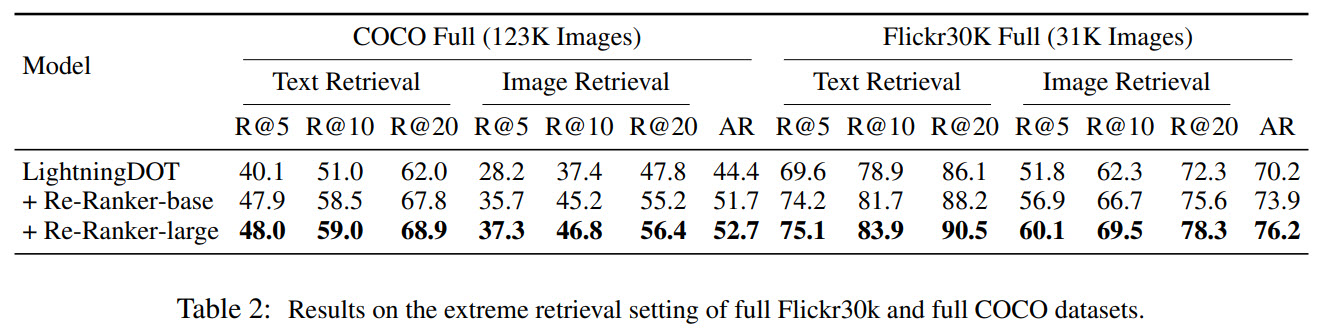
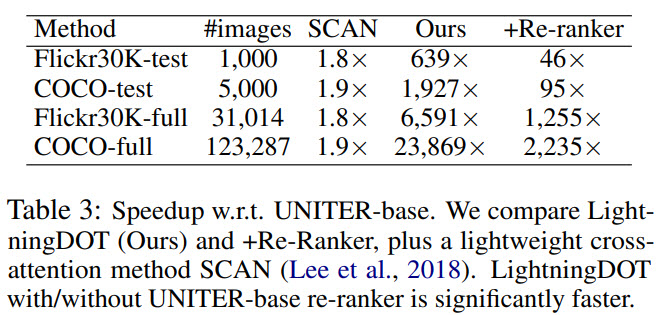
LightningDOT is better than most models - it has lower metrics than models with cross-attention, but the inference speed is much higher.
Ablation
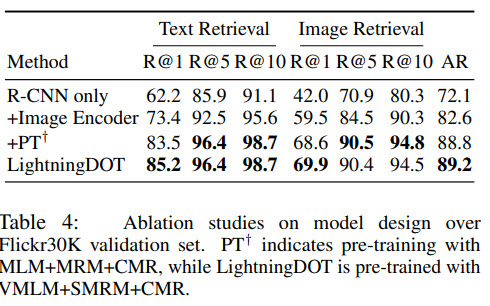
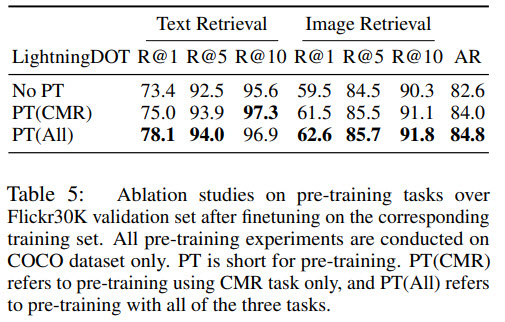
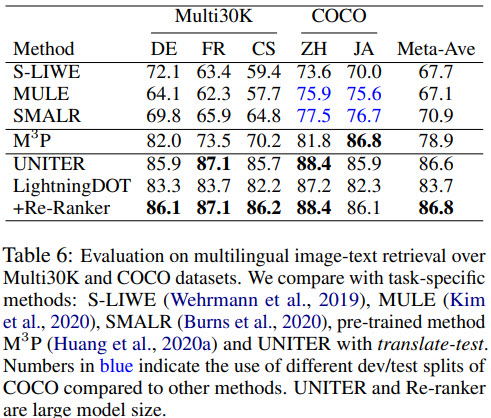
Multilingual Image-Text Retrieval
Some examples of the results




I think this is a fascinating paper, and I’m glad that there is successful research on improving big models’ speed on such tasks.
paperreview pretraining realtime ranking deeplearning