Paper Review: LiRank: Industrial Large Scale Ranking Models at LinkedIn
LiRank is a large-scale ranking framework developed by LinkedIn that incorporates state-of-the-art modeling architectures and optimization techniques, including Residual DCN, Dense Gating, and Transformers. It introduces novel calibration methods and uses deep learning-based explore/exploit strategies, along with model training and compression techniques like quantization and vocabulary compression for efficient deployment.
Applied to LinkedIn’s Feed, Jobs Recommendations, and Ads CTR prediction, LiRank has led to significant performance improvements: a 0.5% increase in member sessions for the Feed, a 1.76% rise in qualified job applications, and a 4.3% boost in Ads CTR.
Large ranking models
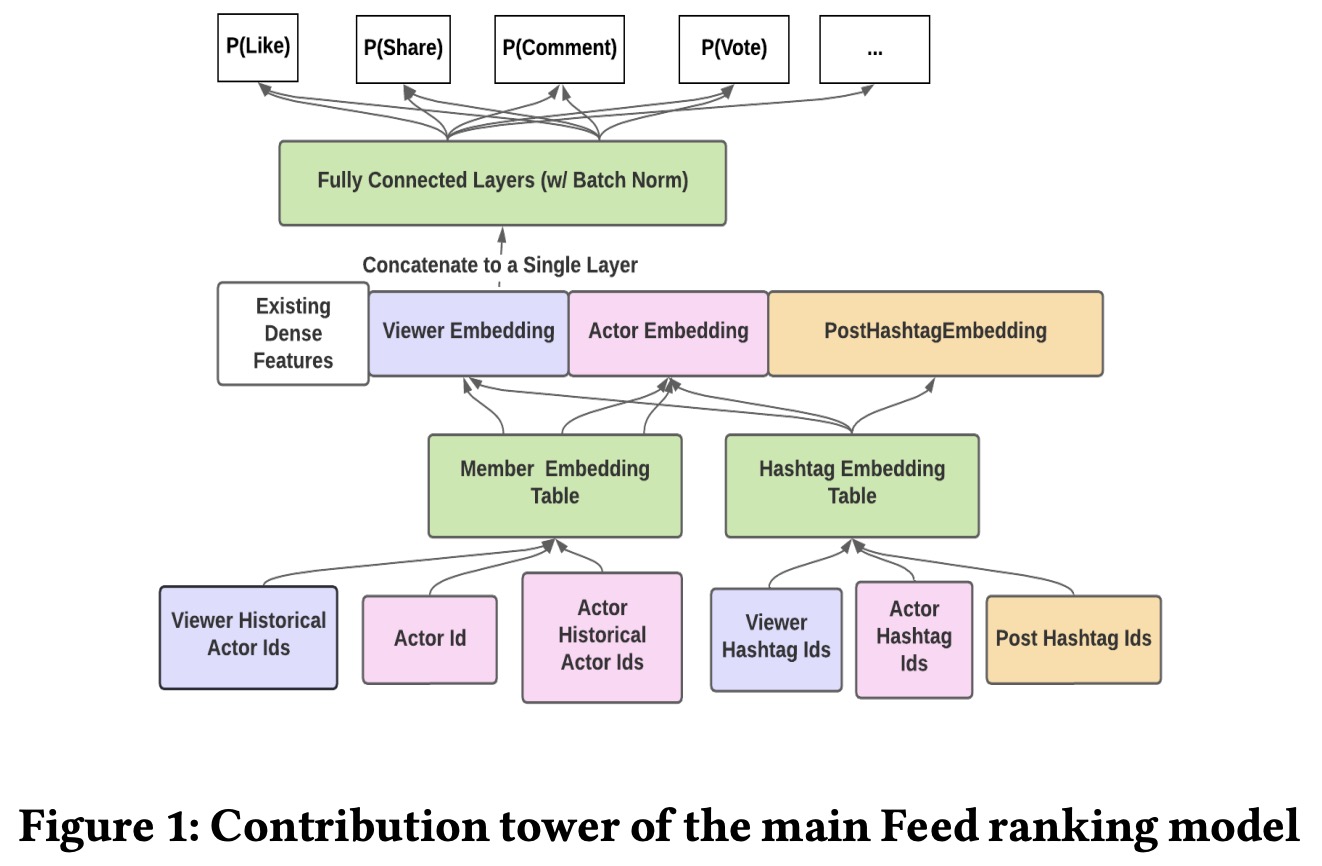
Feed Ranking Model. The primary Feed ranking model at LinkedIn uses a point-wise approach to predict the likelihood of various actions (like, comment, share, vote, click, and long dwell) for each member and candidate post pair. These predictions are linearly combined to calculate the final score of a post.
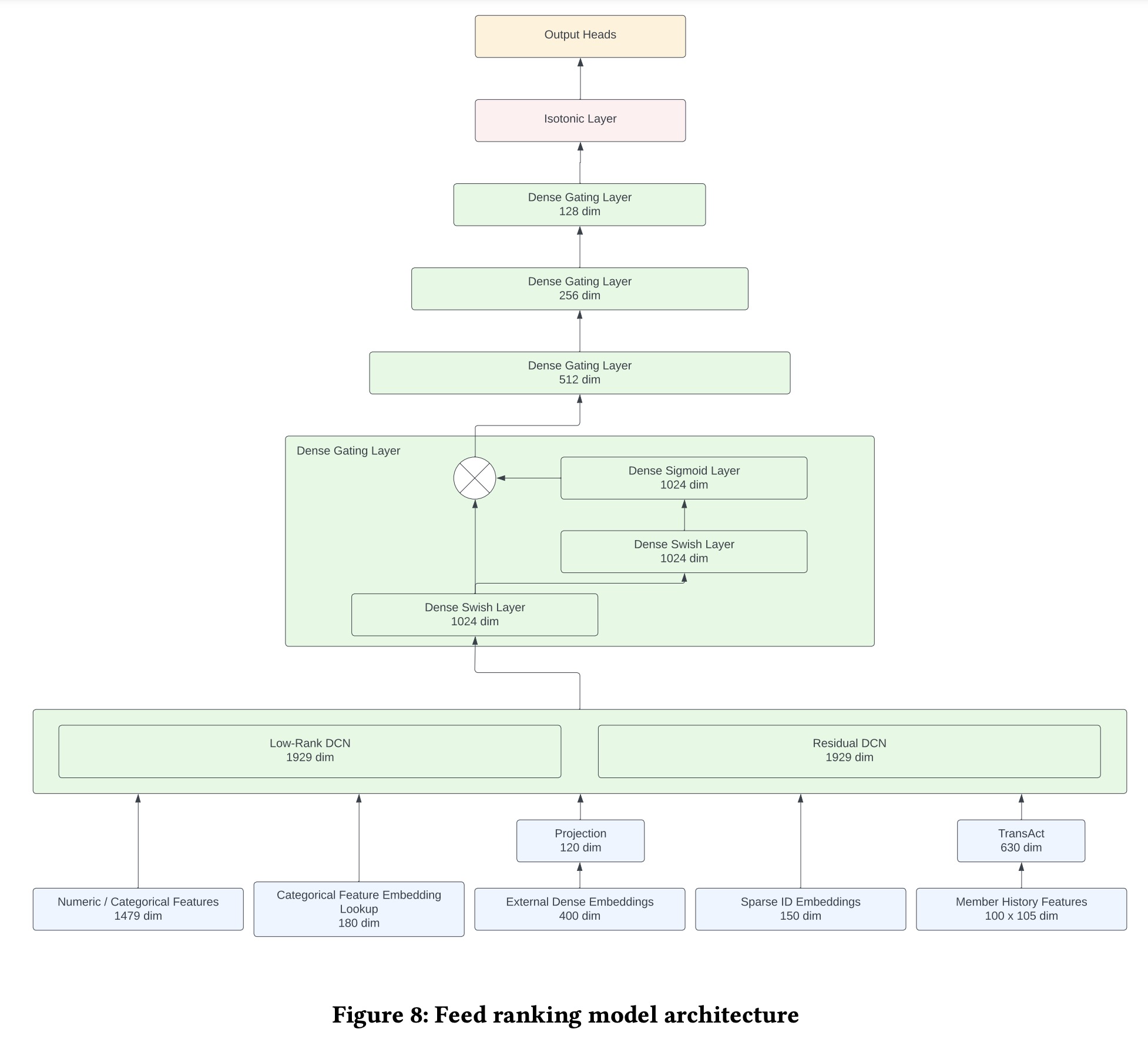
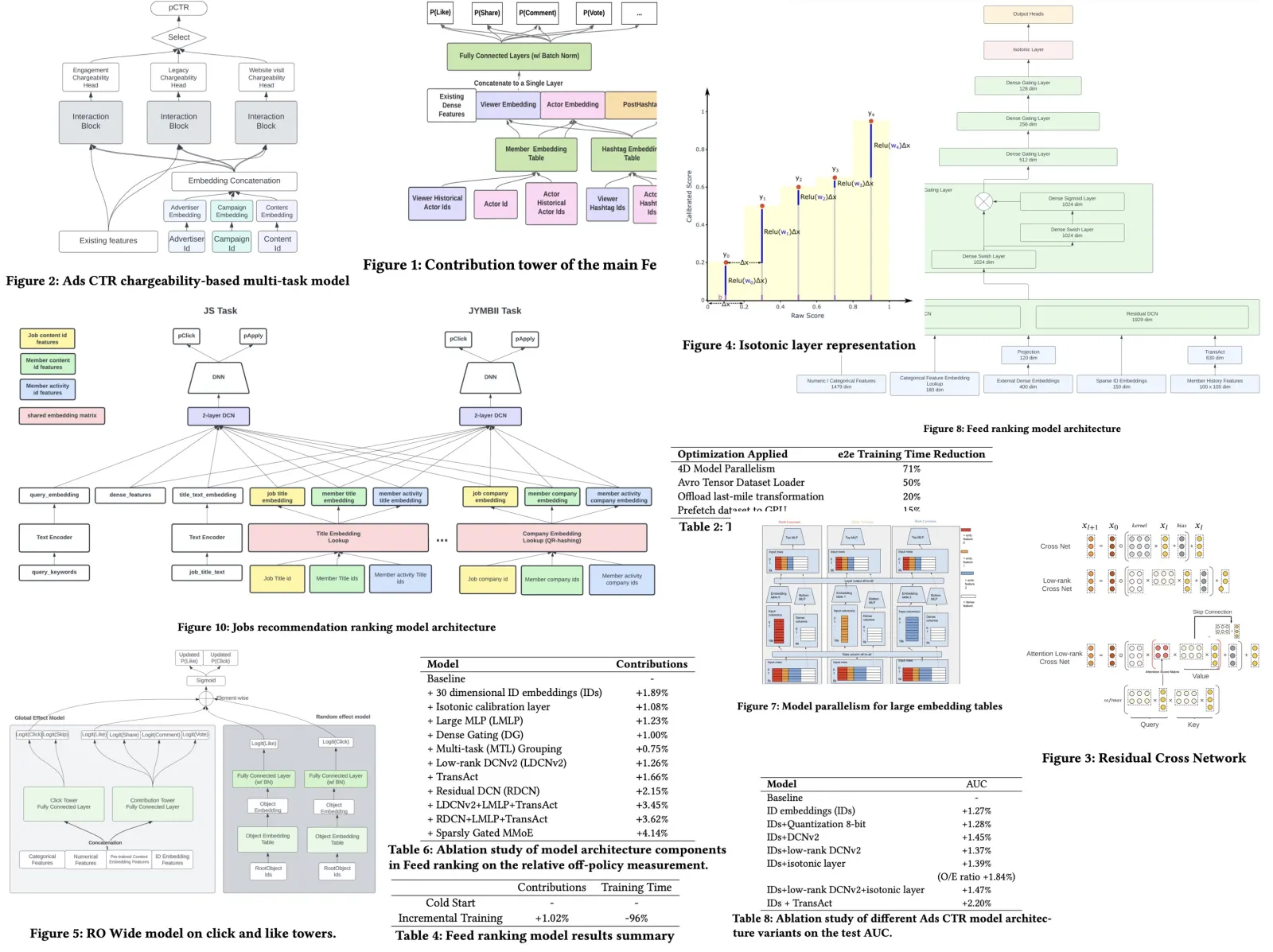
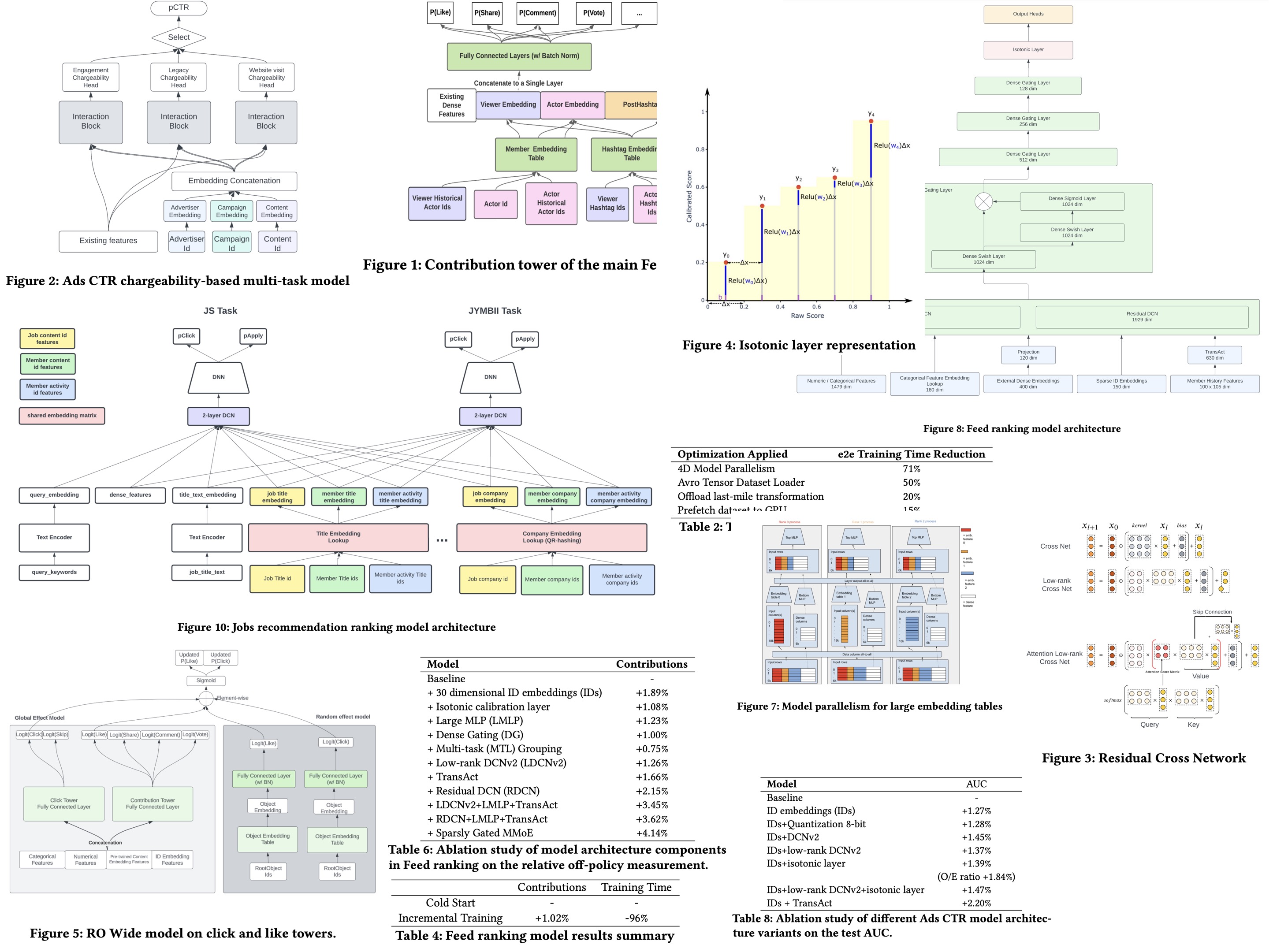
The model is built on a TensorFlow multi-task learning architecture with two main components: a click tower for click and long dwell probabilities, and a contribution tower for contribution actions and related predictions. Both towers use the same normalized dense features and multiple fully-connected layers, while sparse ID embedding features are converted into dense embeddings via lookup in specific embedding tables.
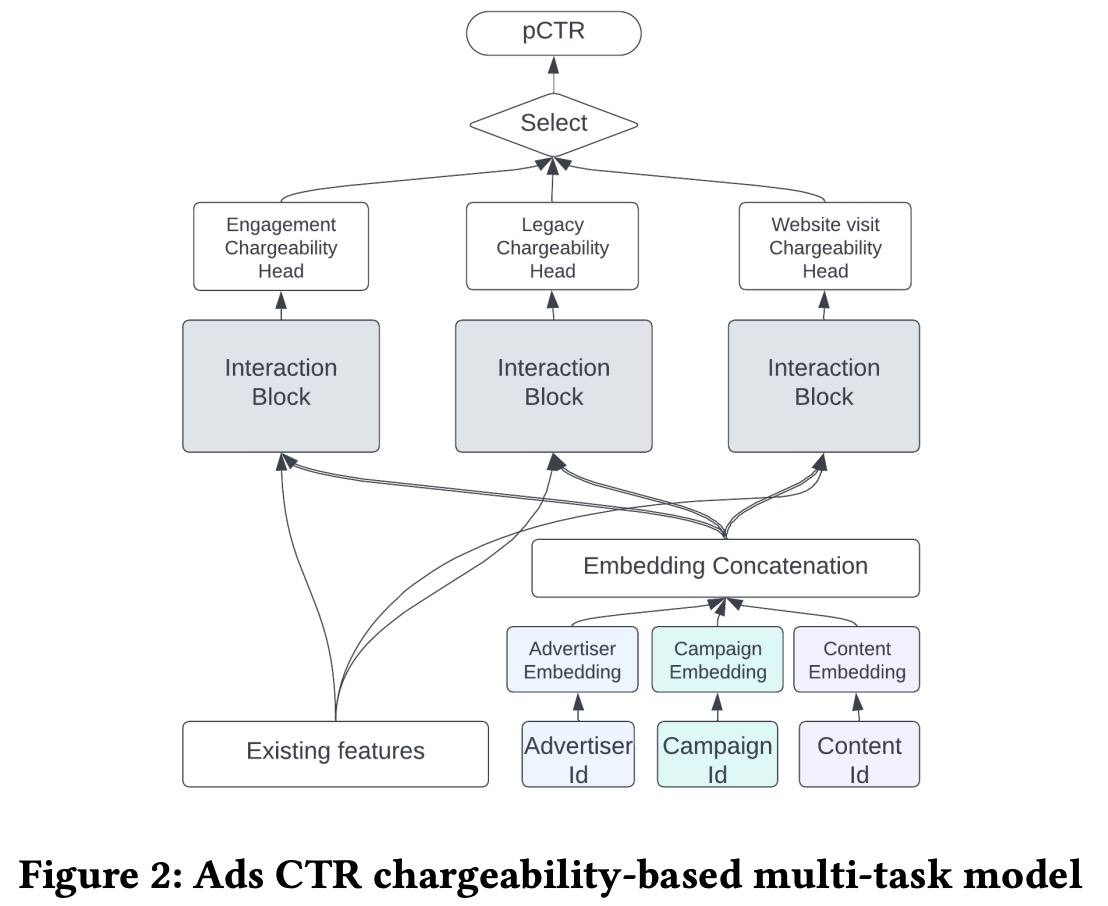
Ads CTR Model. The ads selection uses a click-through-rate prediction model to estimate the likelihood of members clicking on recommended ads, which then informs ad auction decisions. Advertisers can define what constitutes a chargeable click, with some counting social interactions like ‘likes’ or ‘comments’ and others only considering visits to the ad’s website. The CTR prediction model is an MTL model with three heads for different chargeability categories, grouping similar chargeable actions together. Each head uses independent interaction blocks, including MLP and DCNv2. The model incorporates traditional features from members and advertisers, as well as ID features to represent advertisers, campaigns, and advertisements.
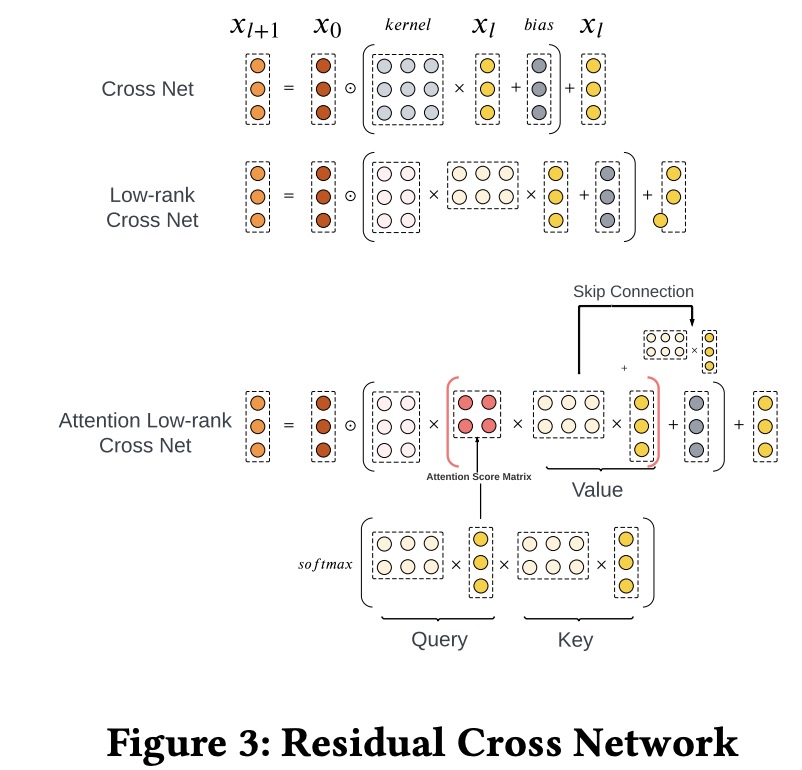
Residual DCN. To enhance feature interaction capture, DCNv2 was utilized. To manage the high parameter count from DCNv2’s large feature input dimension, the authors replaced the weight matrix with two low-rank matrices and reduced input feature dimension through embedding-table look-ups, achieving nearly a 30% reduction in parameters. Additionally, the cross-network of DCNv2 was improved by introducing an attention mechanism with a low-rank approximation.
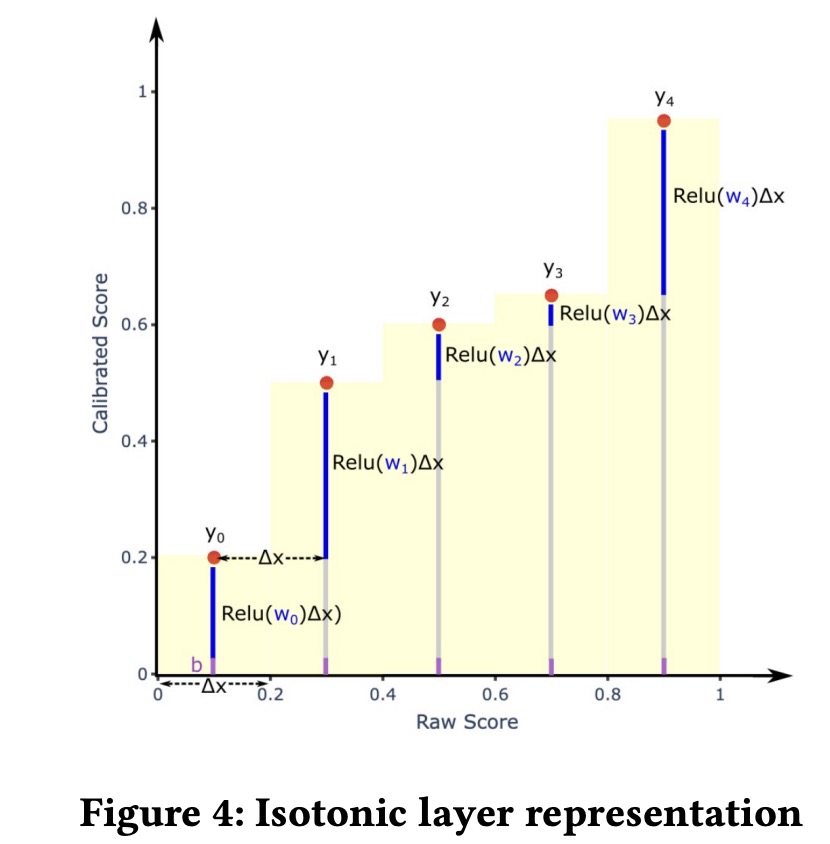
Isotonic Calibration Layer in DNN. Model calibration is essential for ensuring that estimated class probabilities accurately reflect real-world occurrences, critical for applications like Ads pricing based on CTR. Traditional calibration methods like Platt scaling and isotonic regression face challenges with deep neural networks due to parameter space constraints and scalability issues with multiple features. To overcome these, a customized isotonic regression layer, designed to integrate directly with deep neural networks, was developed. This layer, trainable within the network, uses a piece-wise fitting approach to bucketize predicted values and assigns trainable weights to each bucket, updated during training. The isotonic property is maintained through non-negative weights, ensured by the ReLU activation function. For calibration with multiple features, weights are combined with an embedding representation of calibration features, enhancing the model’s calibration capability.
Dense Gating and Large MLP. Personalized embeddings were added to global models to facilitate interactions among dense features, including multi-dimensional count-based and categorical features, by flattening these into a single dense vector and combining them with embeddings for processing in MLP layers. Increasing the width of MLP layers was found to enhance model performance by enabling more complex interactions, with the largest tested configuration being an MLP with 4 layers, each 3500 units wide, showing gains primarily when personalized embeddings were used. Additionally, a gating mechanism inspired by Gate Net was introduced to hidden layers to regulate information flow, enhancing learning with minimal additional computational cost and consistently improving online performance.
Incremental Training. Large-scale recommender systems need to frequently update to include new content like Ads, news feed updates, and job postings. The authors use incremental training, which not only initializes weights from the previous model but also adds an informative regularization term based on the difference between the current and previous model weights, adjusted by a forgetting factor. To further mitigate catastrophic forgetting, both the initial cold start model and the prior model are used for weight initialization and regularization, introducing a new parameter called cold weight to balance the influence of the initial and previous models.
Member History Modeling. To capture member interactions with content on the platform, a method involving historical interaction sequences for each member is used, where item embeddings are combined with action embeddings and the embedding of the item being evaluated. This combined data is processed by a two-layer Transformer-Encoder, with the max-pooling token serving as a feature in the ranking model. Additionally, the last five steps of the sequence are flattened, concatenated, and used as extra input features to enhance the model’s information. To minimize latency, experiments were conducted with shorter sequences and reduced dimensions of the feed-forward network within the Transformer. While longer sequences can increase relevance, the additional training and serving time does not justify their use.
Explore and Exploit. The authors predict values using the last layer’s weights and input, then applying Bayesian linear regression to obtain the posterior probability of the weights, which is fed into Thompson Sampling. This approach does not require independently training a model for the last layer’s representation but updates the posterior probability of weights incrementally after each offline training period.
Dwell Time Modeling. To better understand member behavior and preferences on LinkedIn, a ‘long dwell’ signal was introduced to detect passive content consumption, addressing the challenge of capturing passive but positive engagement. Direct or logarithmic prediction of dwell time was found unsuitable due to data volatility, and static thresholds for defining ‘long dwell’ lacked adaptability and consistency, potentially biasing towards content with inherently longer dwell times. To overcome these issues, a binary classifier was developed to predict whether the time spent on a post exceeds a certain percentile, with specific percentiles adjusted based on contextual features like ranking position, content type, and platform. This approach allows for dynamic adjustment of long-dwell thresholds, capturing evolving user preferences and reducing bias and noise.
Training scalability

To enhance the scalability of training large ranking models, several optimization techniques were used, resulting in significant reductions in training time:
- 4D Model Parallelism: Utilizing Horovod for scaling synchronous training across multiple GPUs, a 4D model parallelism approach was implemented in TensorFlow to distribute large embedding tables across different processes. This method reduced gradient synchronization time by facilitating feature exchange via an all-to-all communication pattern, leading to a reduction in training time from 70 hours to 20 hours.
- Avro Tensor Dataset Loader: An optimized TensorFlow Avro reader was implemented and open-sourced, achieving up to 160x faster performance than existing readers. Optimizations included removing unnecessary type checks, fusing I/O operations, and auto-balancing threads, which halved the end-to-end training time.
- Offloading Last-mile Transformation to Asynchronous Data Pipeline: By moving non-training related data transformations to a separate model and executing them asynchronously with background I/O threads, the overall training time was reduced by 20%. This approach also streamlined the integration of transformed data into the training process.
- Prefetching Dataset to GPU: To address the overhead of CPU to GPU memory copying, especially with larger batch sizes, a customized TensorFlow dataset pipeline and Keras Input Layer were used to prefetch data to the GPU in parallel before the next training step, optimizing the use of GPU resources during training.
Experiments
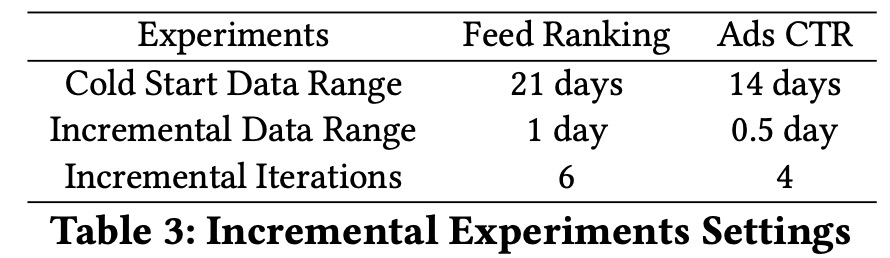
Incremental training was applied to both Feed ranking and Ads CTR models, showing significant improvements in metrics and reductions in training time after tuning parameters.

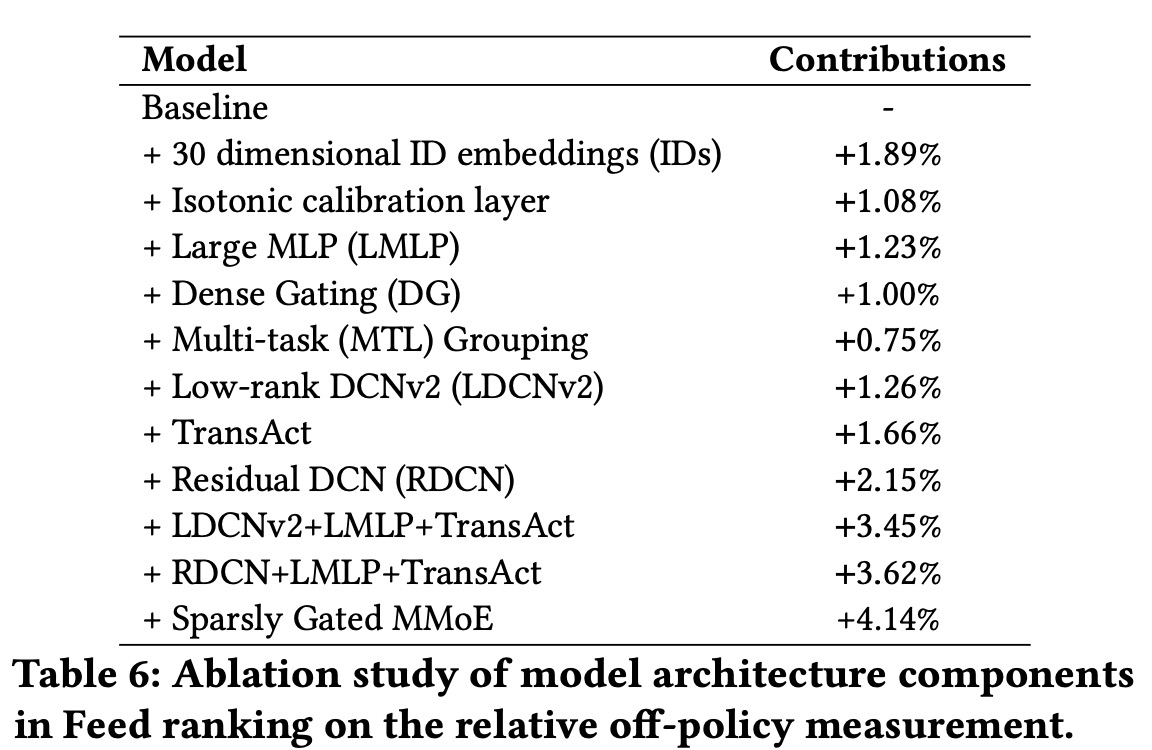
For Feed ranking, an offline “replay” metric was used to compare models by estimating the online contribution rate (likes, comments, re-posts) through a pseudo-random ranking method. This method allowed for unbiased offline comparison of models, with various production modeling techniques like Isotonic calibration, low-rank DCNv2, and others leading to a 0.5% relative increase in member sessions.
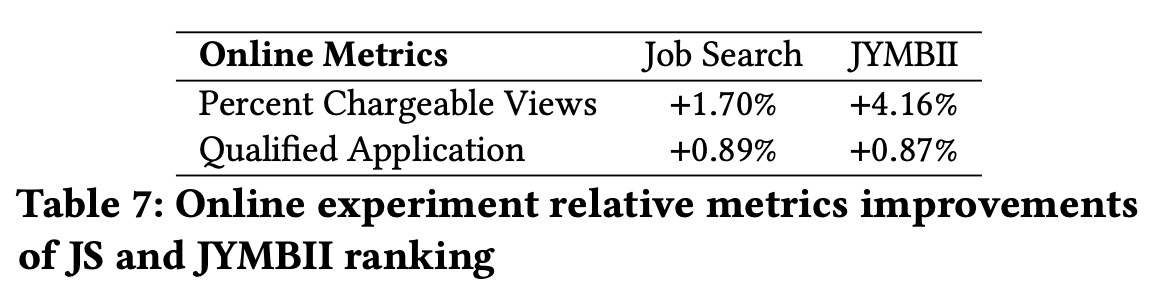
In Jobs Recommendations, embedding dictionary compression and task-specific DCN layers were used without performance loss, achieving significant offline AUC lifts for Job Search and JYMBII models. This resulted in a 1.76% improvement in Qualified Applications in online A/B testing.

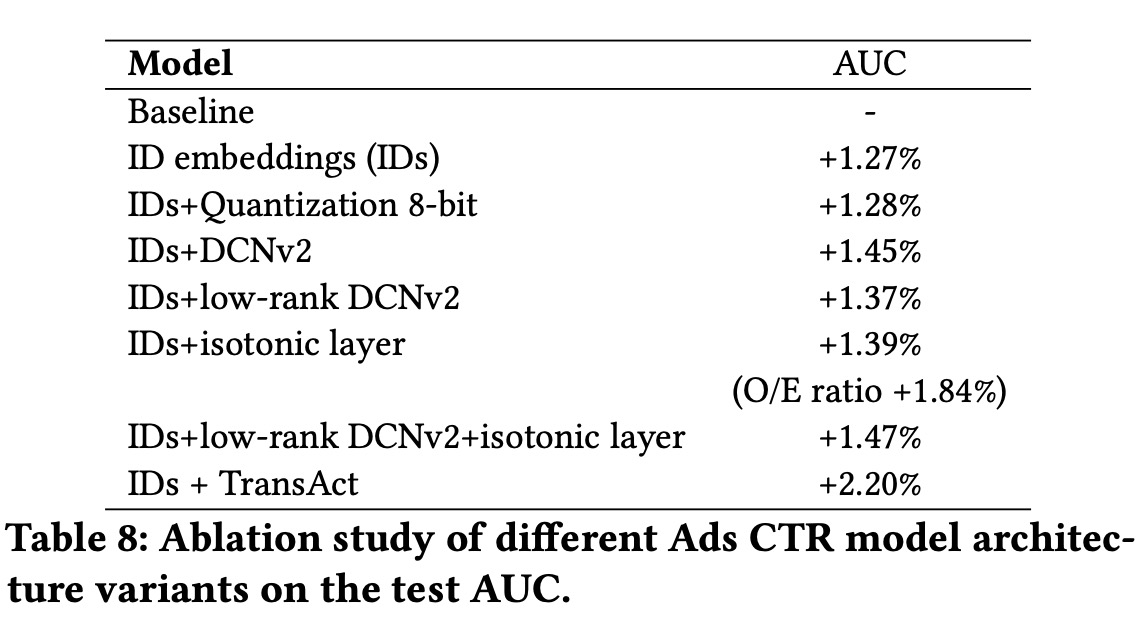
For Ads CTR, incremental improvements were made using techniques like ID embeddings, Quantization, and Isotonic calibration, among others, following a multilayer perceptron baseline model. These techniques led to a 4.3% relative improvement in CTR in online A/B tests.
Deployment lessons
Scaling up Feed Training Data Generation. To manage the increased volume of training data from scaling up to use 100% of sessions, two major optimizations were implemented. First, the data pipeline was adjusted to explode only post features and keys before joining with the labels dataset, and then adding session-level features in a subsequent join. This approach reduced the overall shuffle write size by 60%. Second, tuning Spark compression further reduced shuffle write size by 25%.
Model Convergence with DCNv2. Initial experiments with DCNv2 showed a high divergence rate. To stabilize training, the learning rate warm-up period was increased from 5% to 50% of training steps, which not only resolved instability issues but also enhanced offline relevance gains. Batch normalization was applied to numeric input features, and it was discovered that the model was under-fitting at the current number of training steps. However, increasing training steps was impractical for production. Instead, tripling the learning rate, given the extended warm-up period, effectively closed the gap in relevance metrics without extending training duration.
Additionally, optimization strategies varied across models. While Adam was effective in general, models with many sparse features performed better with AdaGrad. Learning rate warm-up and gradient clipping were particularly useful for larger batch sizes, improving model generalization. The practice of increasing the learning rate proportionally with batch size, without exceeding 60% of total training steps, was found to enhance generalization across different settings and mitigate generalization gaps at larger batch sizes.
paperreview deeplearning recommender