Paper Review: LISA: Reasoning Segmentation via Large Language Model

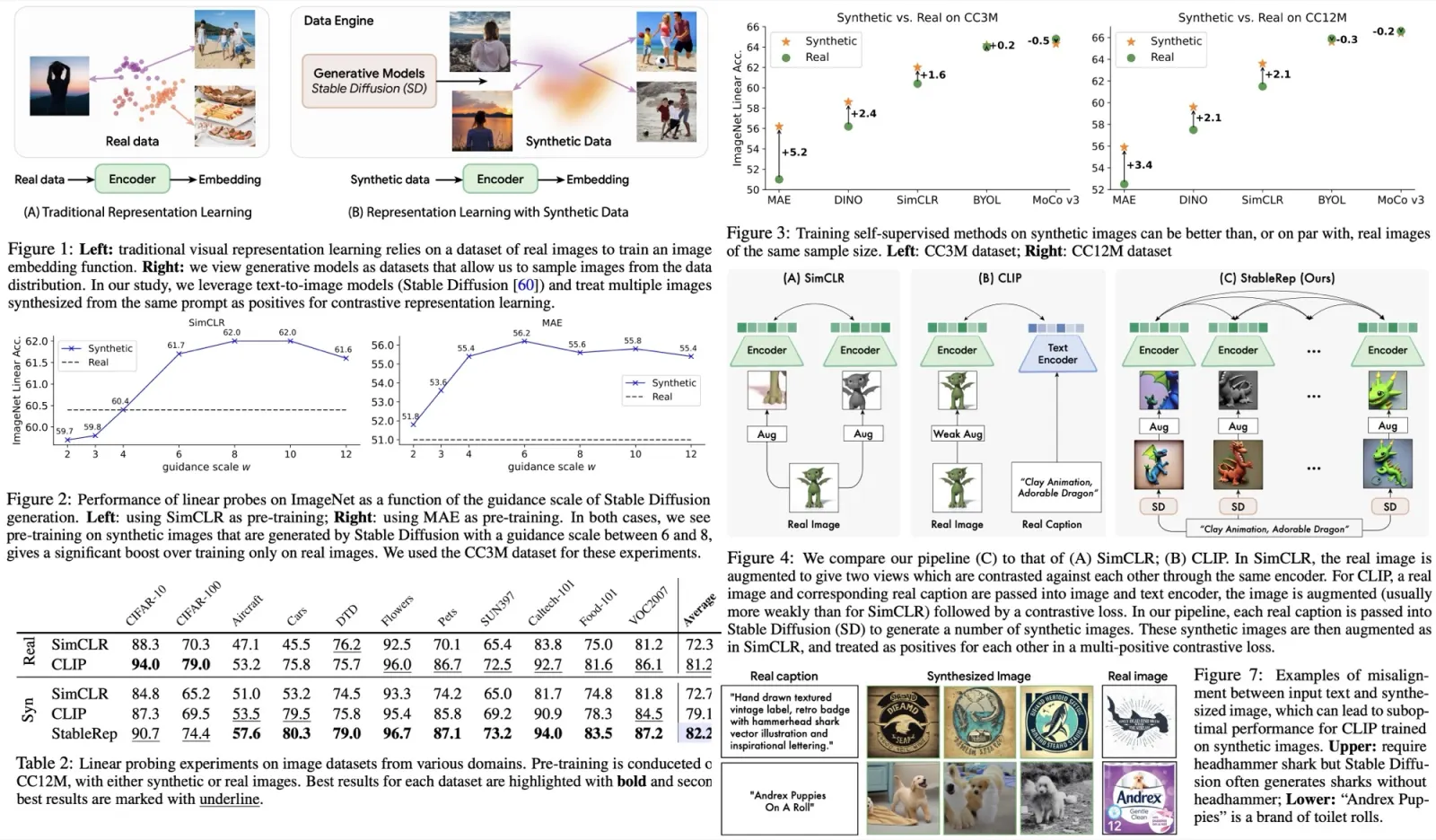
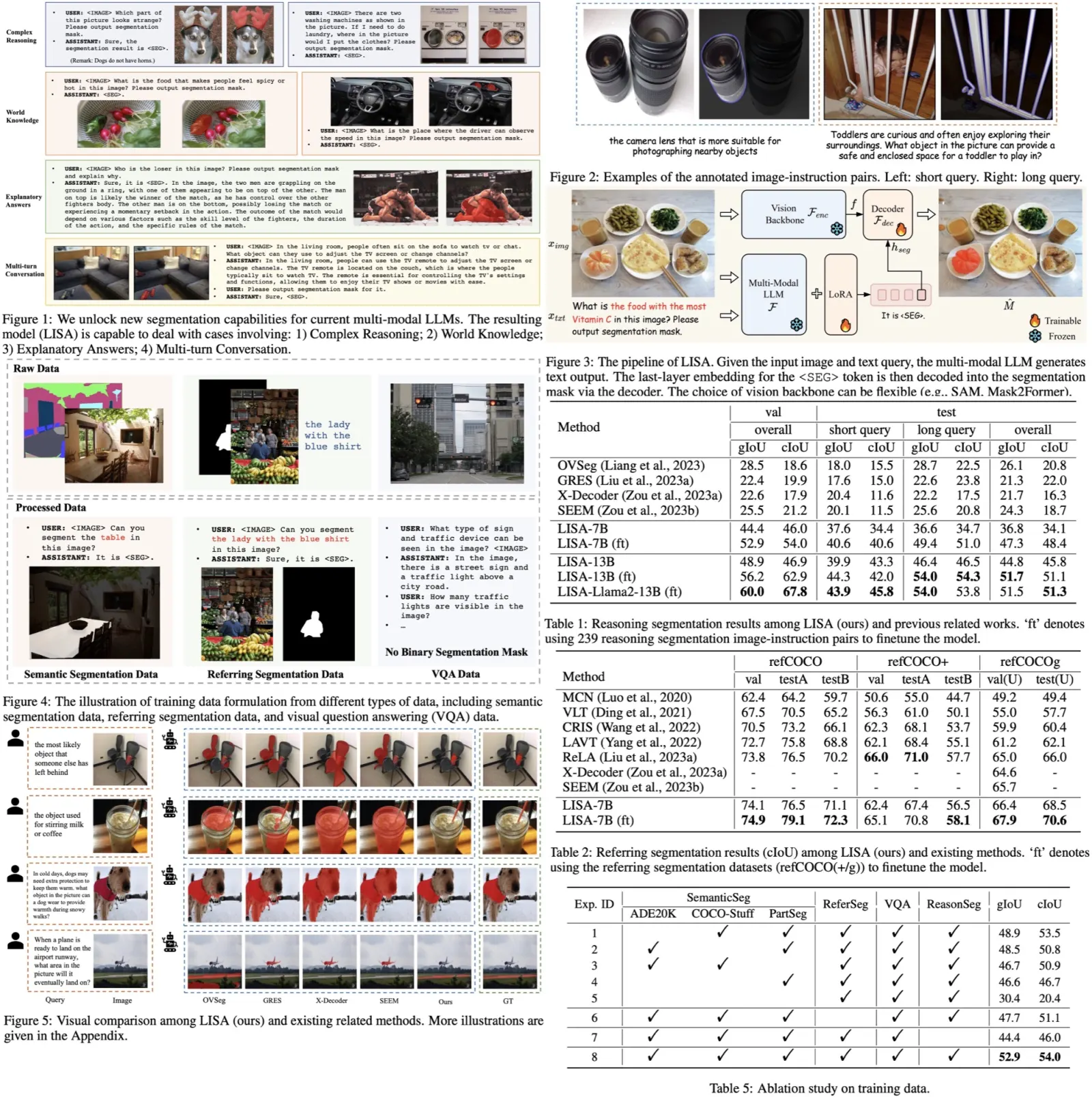
This research introduces a new visual recognition task called “reasoning segmentation” to allow perception systems to interpret complex and implicit user instructions rather than relying on explicit ones. The aim is to produce a segmentation mask based on intricate query text. A benchmark with over a thousand image-instruction pairs, which require advanced reasoning and world knowledge, has been established for evaluation.
The study presents “LISA” (Language Instructed Segmentation Assistant), a model evolved from LLM with enhanced segmentation abilities. This is achieved by adding a
Reasoning segmentation

The “reasoning segmentation” task aims to produce a binary segmentation mask for a given image based on an implicit text instruction. While similar to the existing “referring segmentation” task, reasoning segmentation is more challenging due to the complexity of the query text, which may involve intricate expressions or longer sentences requiring advanced reasoning or world knowledge.
To evaluate this new task, a benchmark ReasonSeg is established. Images for the benchmark are sourced from OpenImages and ScanNetv2, and are annotated with implicit text instructions and high-quality target masks. These text instructions are of two types: short phrases and long sentences. The ReasonSeg dataset contains a total of 1218 image-instruction pairs, partitioned into training (239 pairs), validation (200 pairs), and testing (779 pairs) sets.
Lisa
Architecture
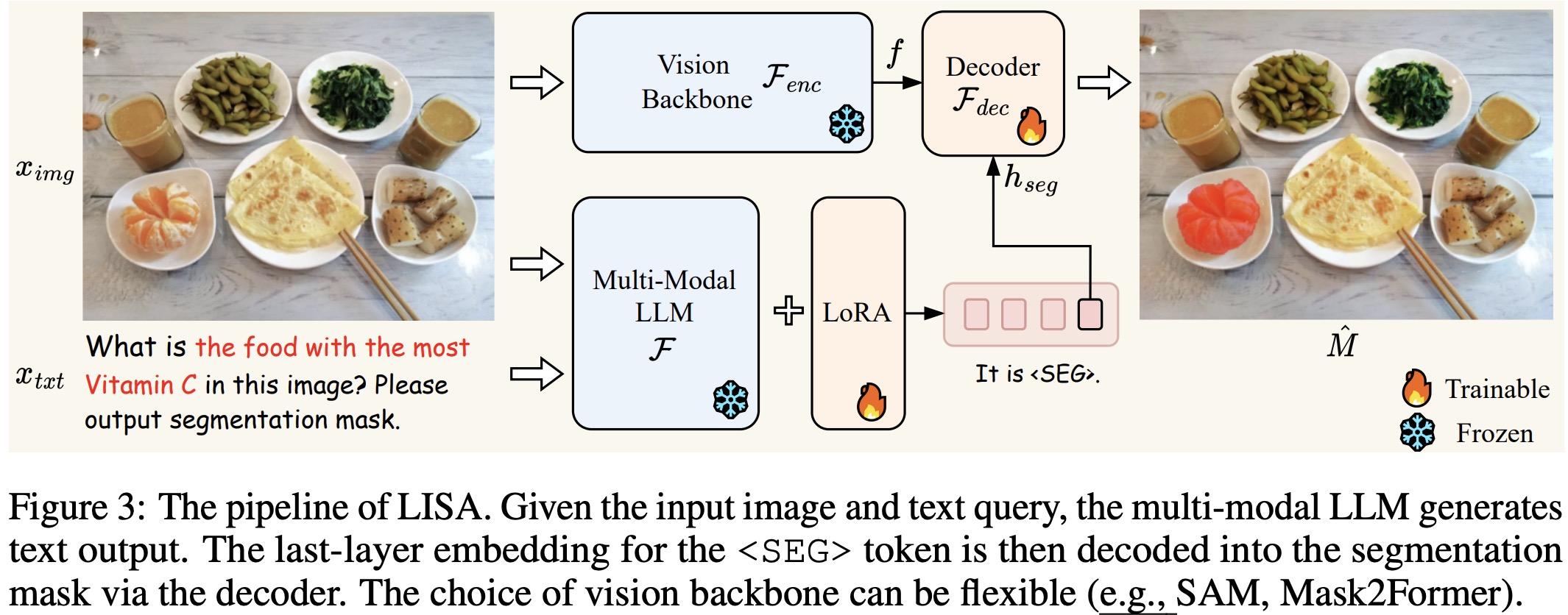
Current multi-modal LLMs like LLaVA, Flamingo, BLIP-2, and Otter can process both image and text inputs but can’t directly produce segmentation masks. VisionLLM tried to resolve this by converting segmentation masks into text-like polygon sequences. However, this approach is computationally intensive and may not generalize well without vast data and resources.
To address these challenges, this paper introduces the “embedding-as-mask” paradigm within the multi-modal LLM framework. This approach adds a new token,
The training of this model involves two primary objectives: a text generation loss (auto-regressive cross-entropy) and a segmentation mask loss (BCE and DICE).
Training data

The training data for the LISA model consists of three types of datasets:
- Semantic Segmentation Dataset: This includes images and their multi-class labels. Templates are used to convert these into question-answer pairs that fit the visual question answering format (
USER: <IMAGE> Can you segment the {CLASS NAME} in this image? ASSISTANT: It is <SEG>.). Datasets like ADE20K, COCO-Stuff, and LVIS-PACO are used. - Vanilla Referring Segmentation Dataset: These datasets have an image and a short, explicit description of the target object. Templates are again used to convert these into question-answer pairs (
USER: <IMAGE> Can you segment {description} in this image? ASSISTANT: Sure, it is <SEG>.). Datasets like refCOCO, refCOCO+, refCOCOg, and refCLEF are used. - Visual Question Answering Dataset: To maintain the model’s original VQA capabilities, the LLaVA-Instruct-150k dataset is included, which was generated by GPT-4.
Notably, the training set doesn’t include any samples that require complex reasoning for segmentation, focusing only on explicit queries. Despite this, LISA shows strong zero-shot capabilities on the ReasonSeg benchmark.
Experiments
The models are trained on 8 NVIDIA 24G 3090 GPU using deepspeed.
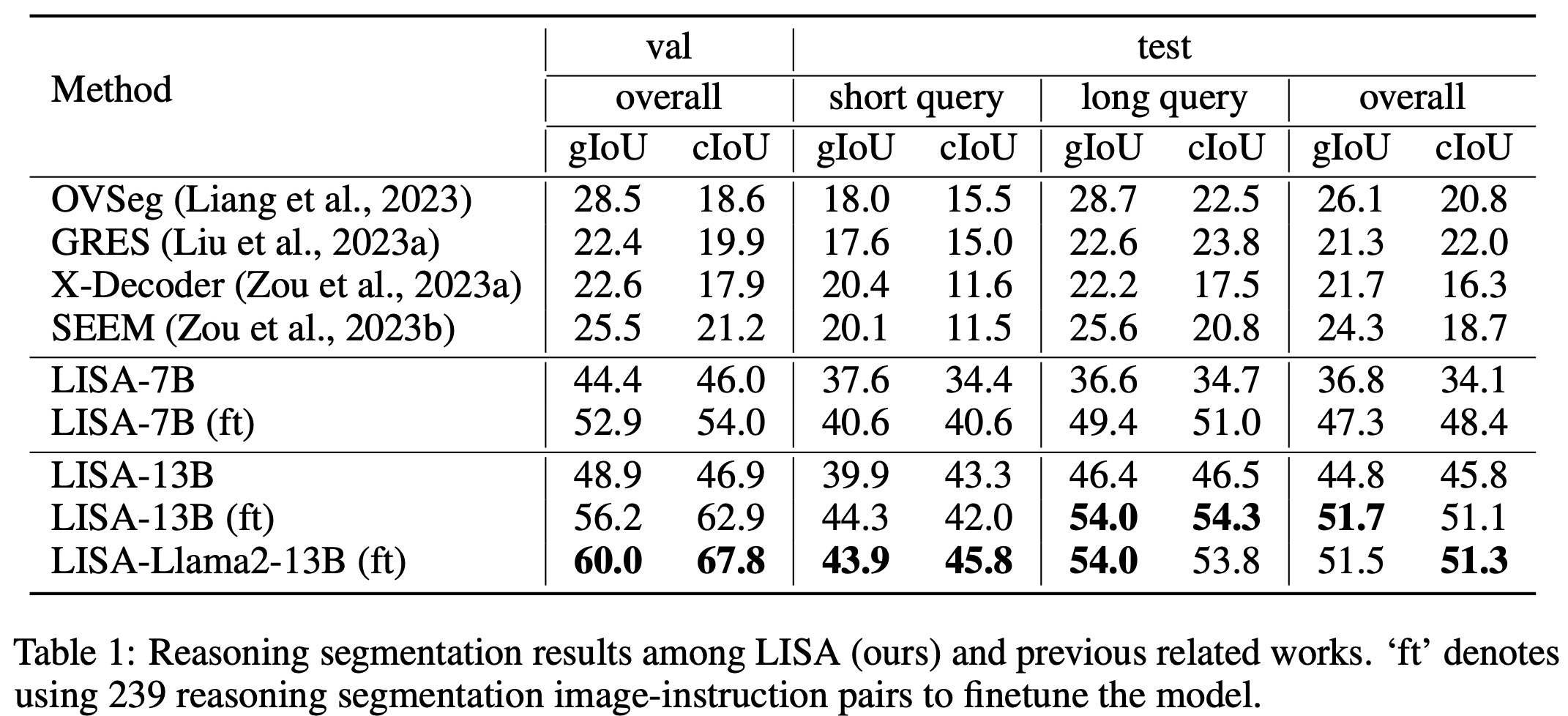

- LISA outperforms existing models by more than 20% in gIoU for tasks involving complex reasoning. This demonstrates that LISA can handle both explicit and implicit queries effectively.
- The 13B variant of LISA significantly outperforms the 7B version, especially for long-query scenarios. This indicates that further improvements could come from even more powerful multi-modal large language models.
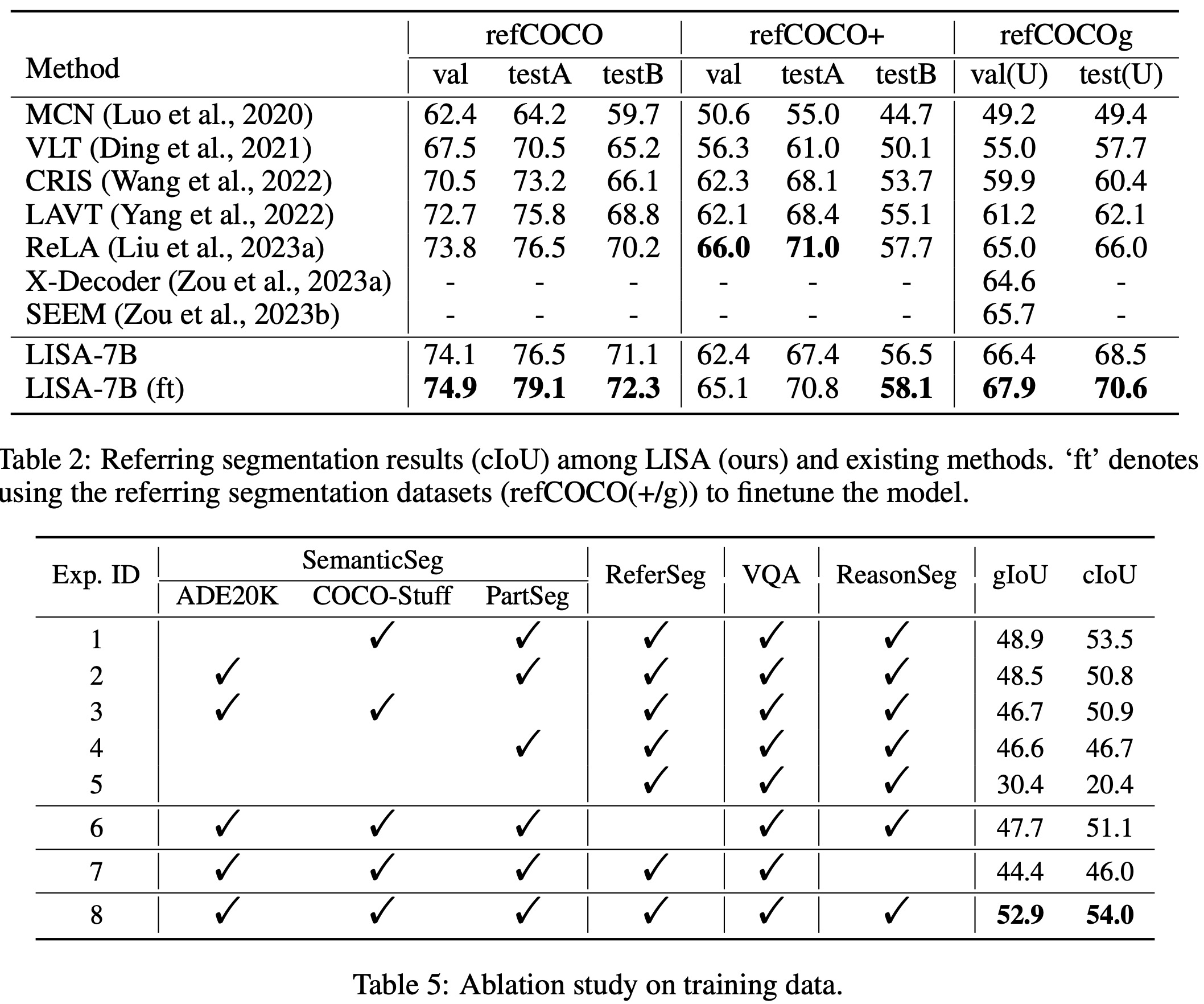
- LISA also excels in standard referring segmentation tasks, achieving state-of-the-art results across various benchmarks like refCOCO, refCOCO+, and refCOCOg.
Ablations:
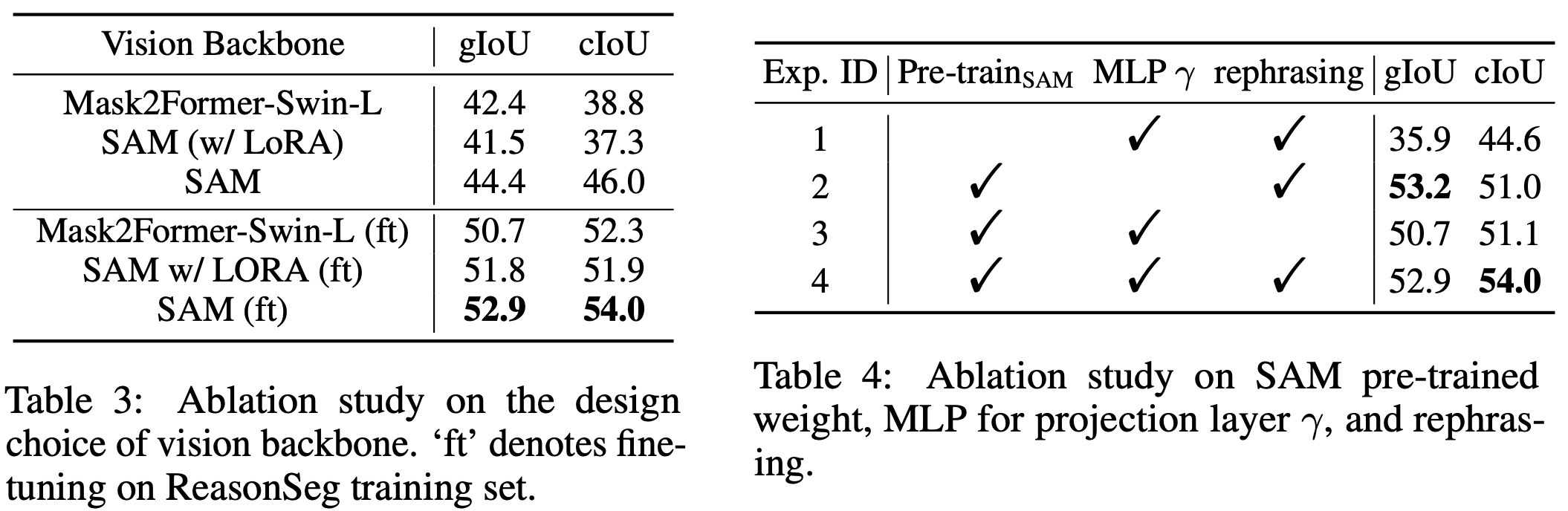
- The choice of vision backbone is flexible; both SAM and Mask2FormerSwin-L performed well. However, SAM performed better possibly due to being trained on a richer dataset.
- Fine-tuning SAM led to inferior performance compared to using it as a frozen backbone. Also, initializing with SAM’s pre-trained weights significantly improved performance.
- Using an MLP instead of linear projection yielded slightly lower gIoU but higher cIoU.
- Semantic segmentation datasets were found to be crucial for training as they provide a wealth of ground-truth binary masks.
- Using GPT-3.5 to rephrase text instructions during fine-tuning increased performance by 2.2% in gIoU and 2.9% in cIoU.