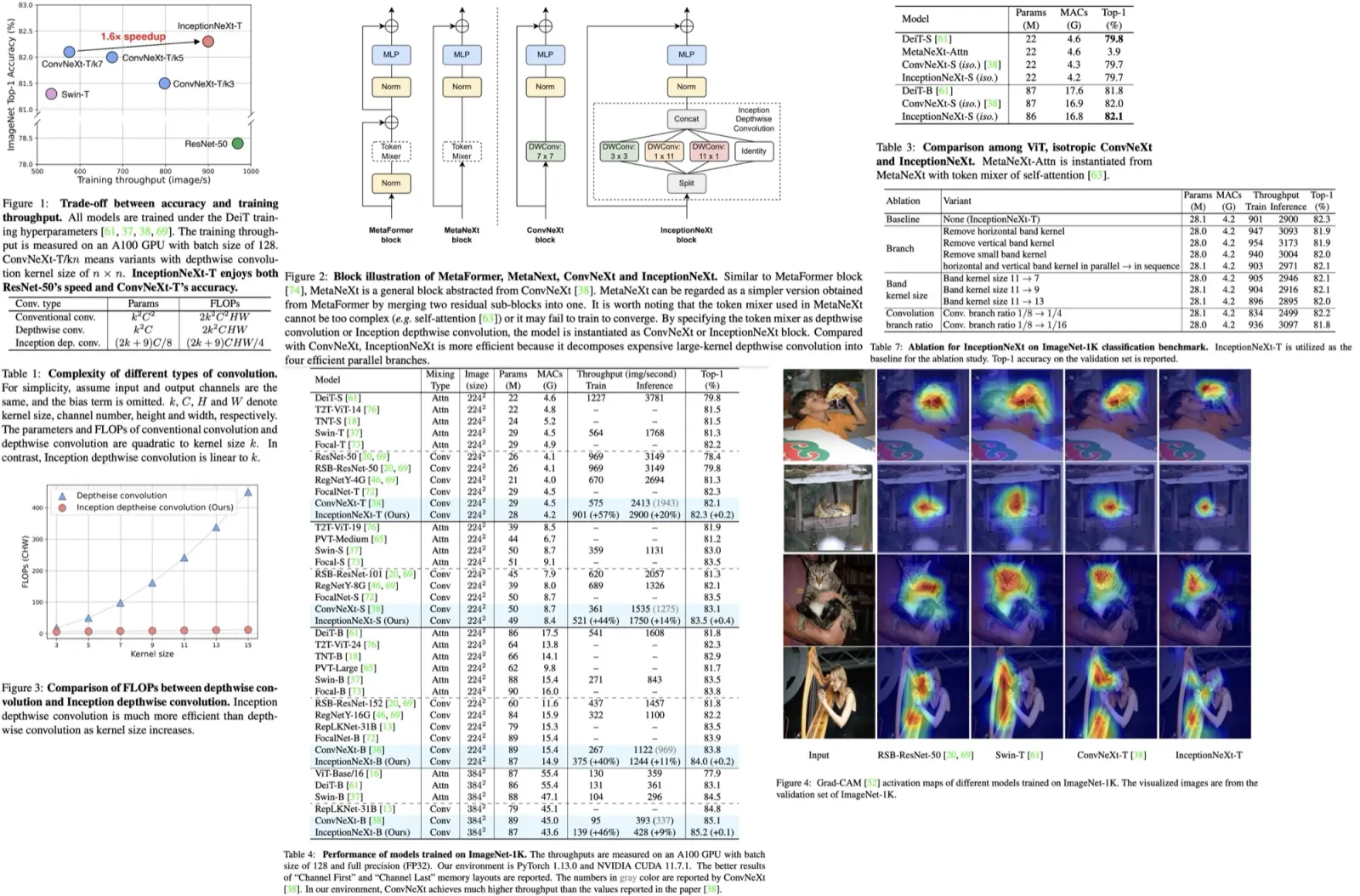
Paper Review: YOLOv10: Real-Time End-to-End Object Detection
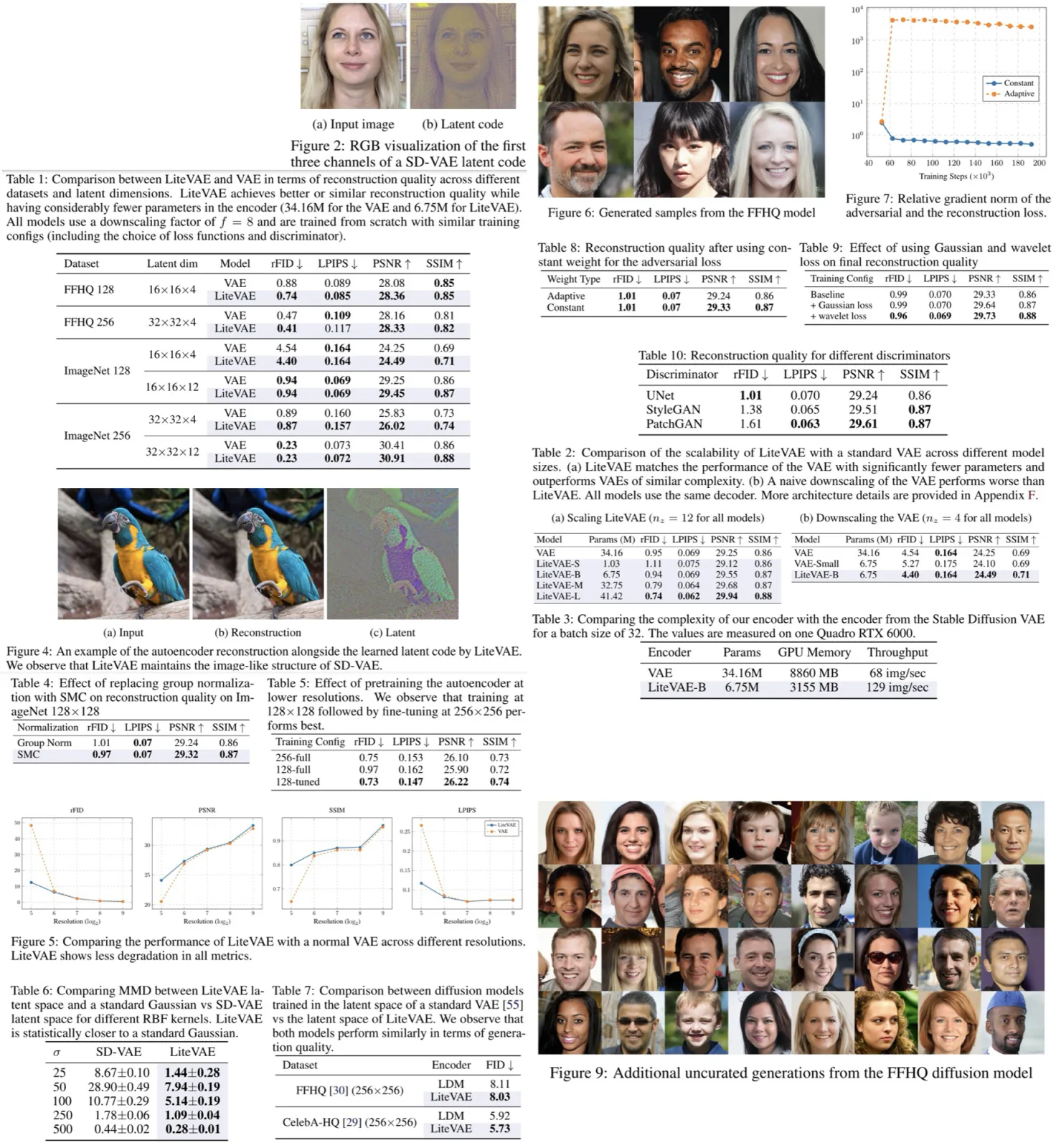
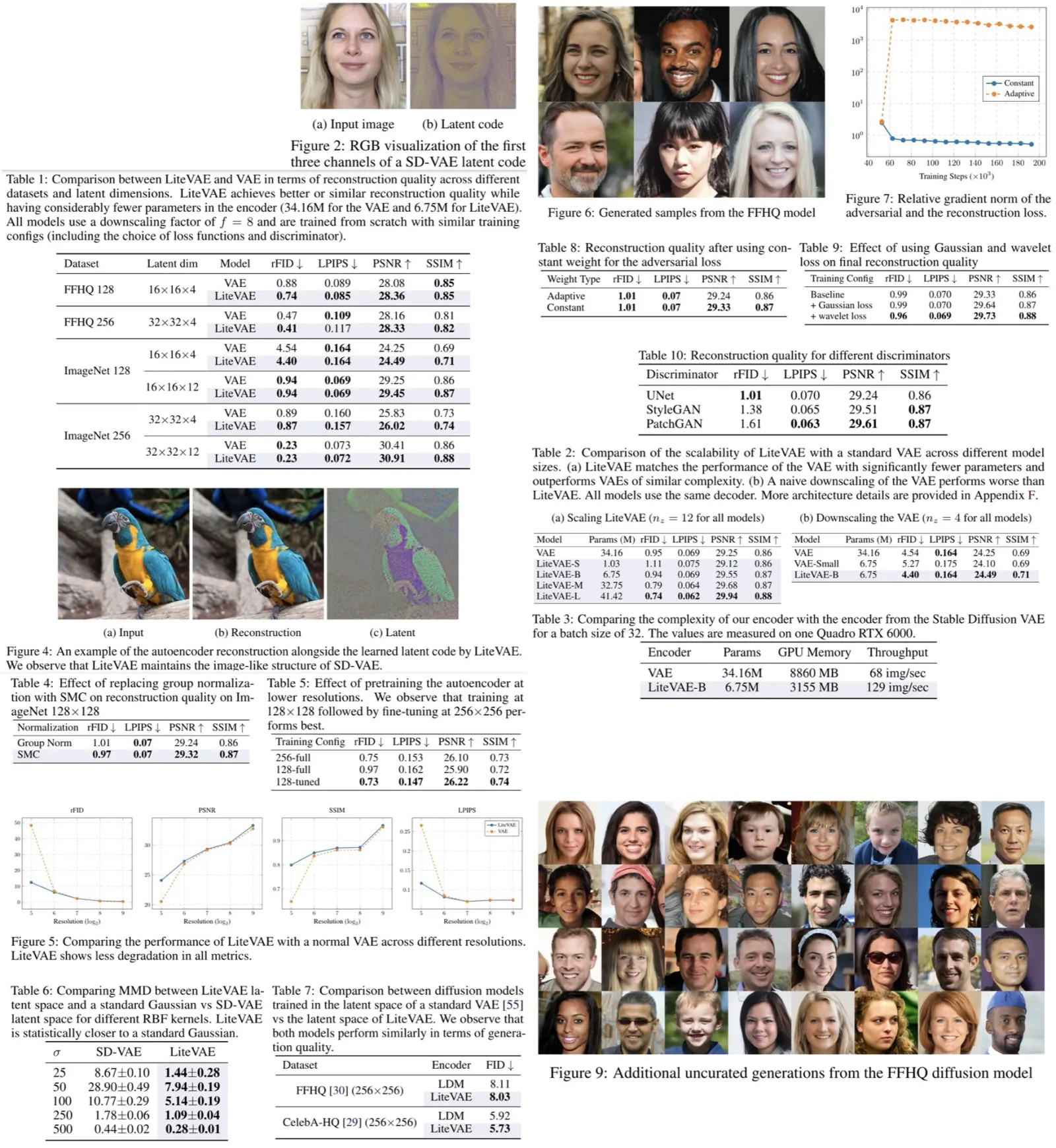
LiteVAE, a family of autoencoders for latent diffusion models, leverages the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders without sacrificing output quality. Several enhancements to training methodologies and decoder architecture improve training dynamics and reconstruction quality. The base LiteVAE model matches the quality of established VAEs with a six-fold reduction in encoder parameters, resulting in faster training and lower GPU memory requirements. The larger LiteVAE model outperforms VAEs of similar complexity across metrics such as rFID, LPIPS, PSNR, and SSIM.
Background
Deep autoencoders consist of an encoder network that maps an image to a latent representation and a decoder that reconstructs the image from this latent code. Specifically, given an input image, convolutional autoencoders seek a latent vector such that the reconstructed image closely approximates the original. The training process involves a reconstruction loss between the input and reconstructed images and a regularization term on the latent representation. Typically, the reconstruction loss is a combination of L1 and perceptual losses, while the regularization term is enforced via KL divergence. The regularization helps structure the latent space for applications like generative modeling. Additionally, adversarial loss can be used, where a discriminator differentiates real images from reconstructions to achieve more photorealistic outputs.
Wavelet transforms are a signal processing technique that extracts spatial-frequency information from input data using a combination of low-pass and high-pass filters. For 2D signals, the transform decomposes an image into a low-frequency sub-band and three high-frequency sub-bands, capturing horizontal, vertical, and diagonal details. Each sub-band is half the size of the original image. Multi-resolution analysis is achieved by iteratively applying the wavelet transform to the low-frequency sub-band at each level.
The approach
Model design
- Wavelet Processing: Each image is processed via a multi-level discrete wavelet transform to obtain wavelet coefficients at three levels, achieving an 8× downsampling.
- Feature Extraction and Aggregation: The wavelet coefficients are processed via a feature-extraction module to compute multiscale feature maps, which are then combined via a feature-aggregation module using a UNet-based architecture.
- Image Reconstruction: A decoder network processes the latent code to compute the reconstructed image.
The model is trained end-to-end, using lightweight networks for feature extraction and aggregation.
Self-Modulated Convolution

Intermediate feature maps learned by the decoder are often imbalanced. To address this, LiteVAE uses self-modulated convolution SMC instead of group normalization. SMC allows convolution layers to learn corresponding scales for each feature map, balancing feature maps and improving reconstruction quality.
Training Improvements
- Training Resolution: LiteVAE is pretrained at a lower 128×128 resolution, followed by fine-tuning at 256×256, reducing compute requirements while maintaining reconstruction quality.
- Improved Adversarial Setup: A UNet-based model replaces the PatchGAN discriminator for pixel-wise discrimination. The adaptive weight for adversarial loss update is removed for more stable training.
- Additional Loss Functions: Two high-frequency reconstruction loss terms are introduced: Charbonnier loss between high-frequency DWT sub-bands and L1 loss between Gaussian-filtered images, enhancing reconstruction quality.
Experiments
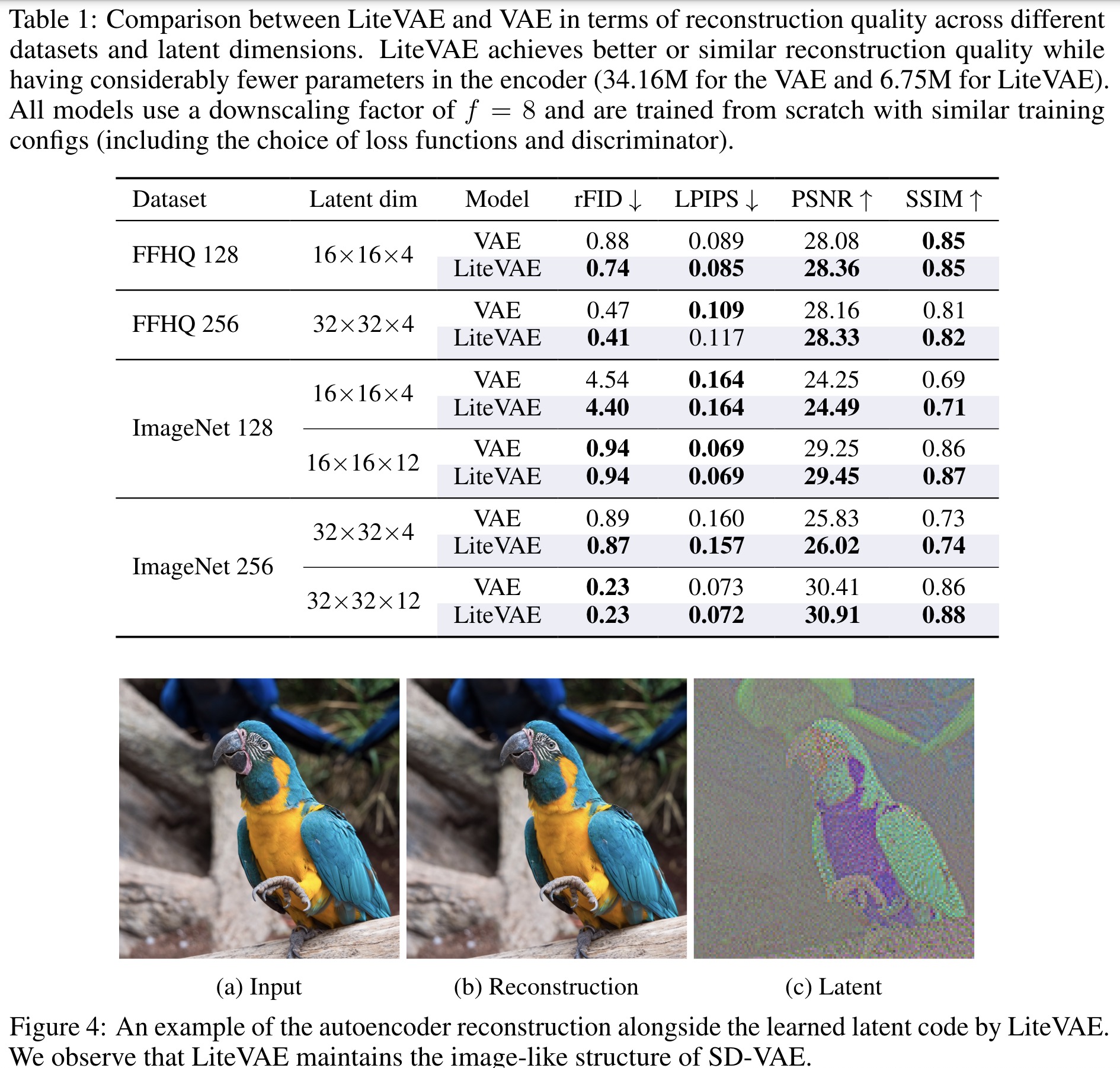
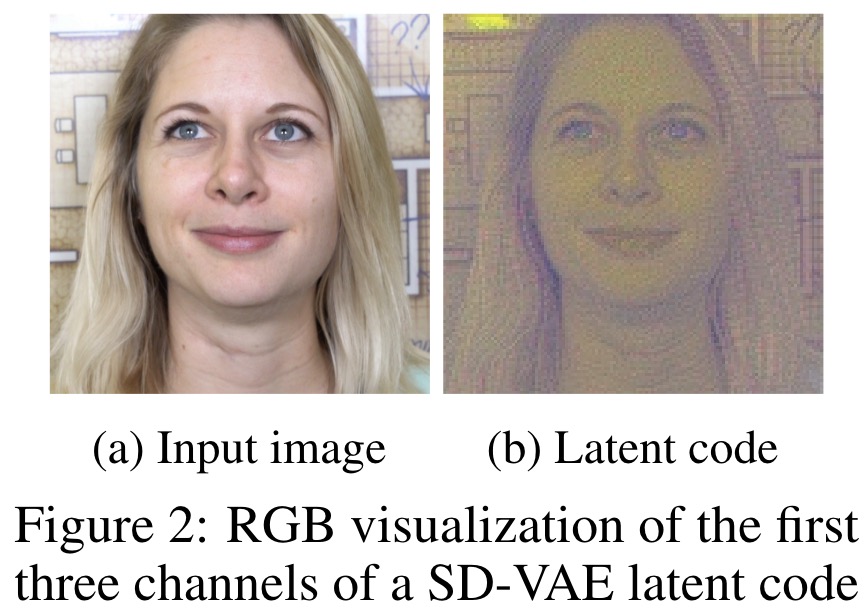
The LiteVAE model demonstrates significant improvements over standard VAEs in terms of performance, efficiency, and scalability across various datasets and latent dimensions. It achieves comparable or better reconstruction quality while using approximately one-sixth of the encoder parameters, leading to faster training and lower GPU memory usage. The latent representations learned by LiteVAE maintain an image-like structure, similar to those in SD-VAE.
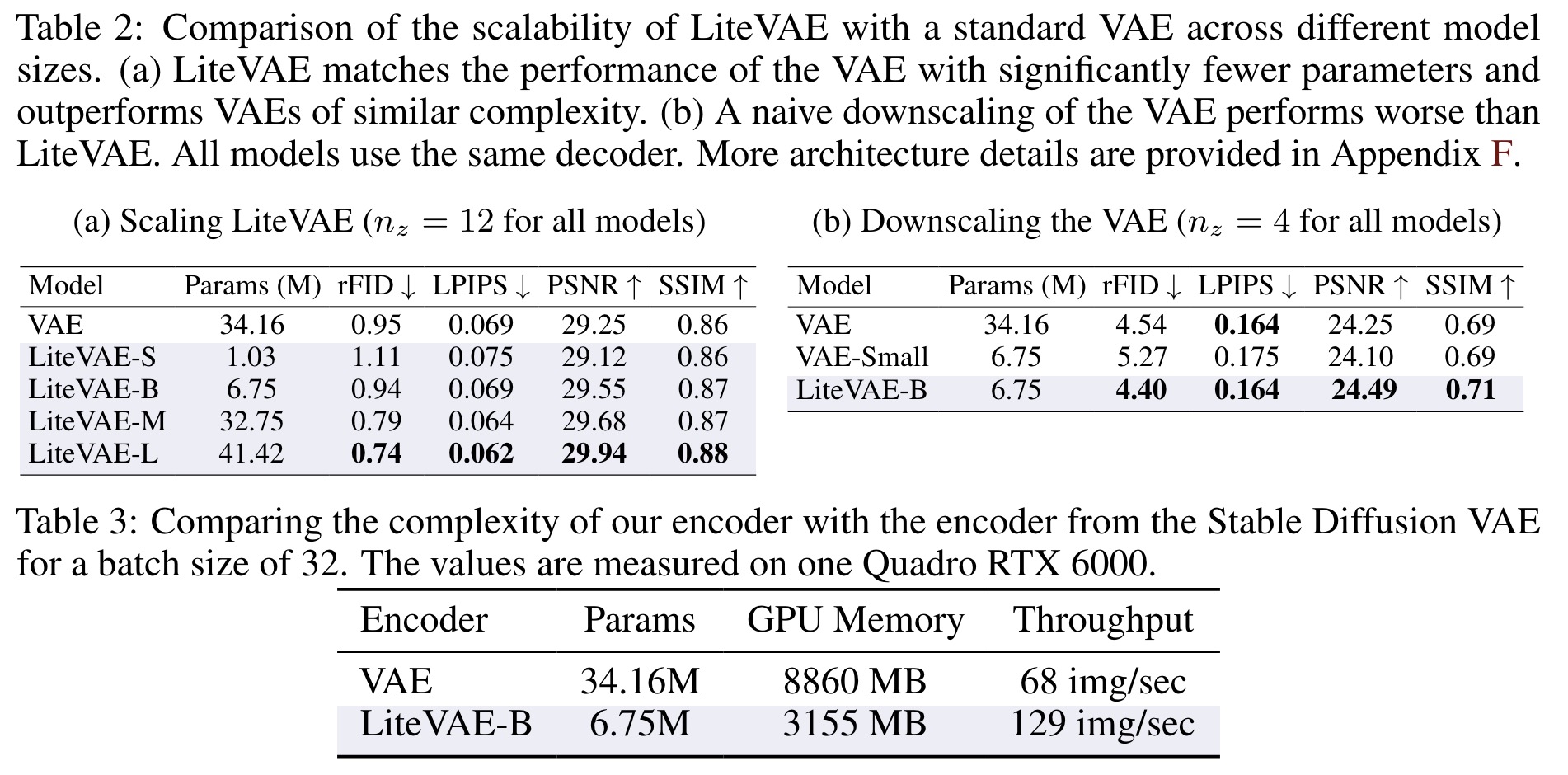
As the complexity of the LiteVAE model increases, the reconstruction performance improves, and the larger models outperform standard VAEs of similar complexity across all metrics. This scalability advantage is attributed to the wavelet processing step, which provides the encoder with a rich initial representation.
In terms of computational cost, LiteVAE-B requires significantly less GPU memory and nearly doubles the throughput compared to the Stable Diffusion VAE encoder. This efficiency allows for larger batch sizes during training, enhancing hardware utilization for diffusion training.
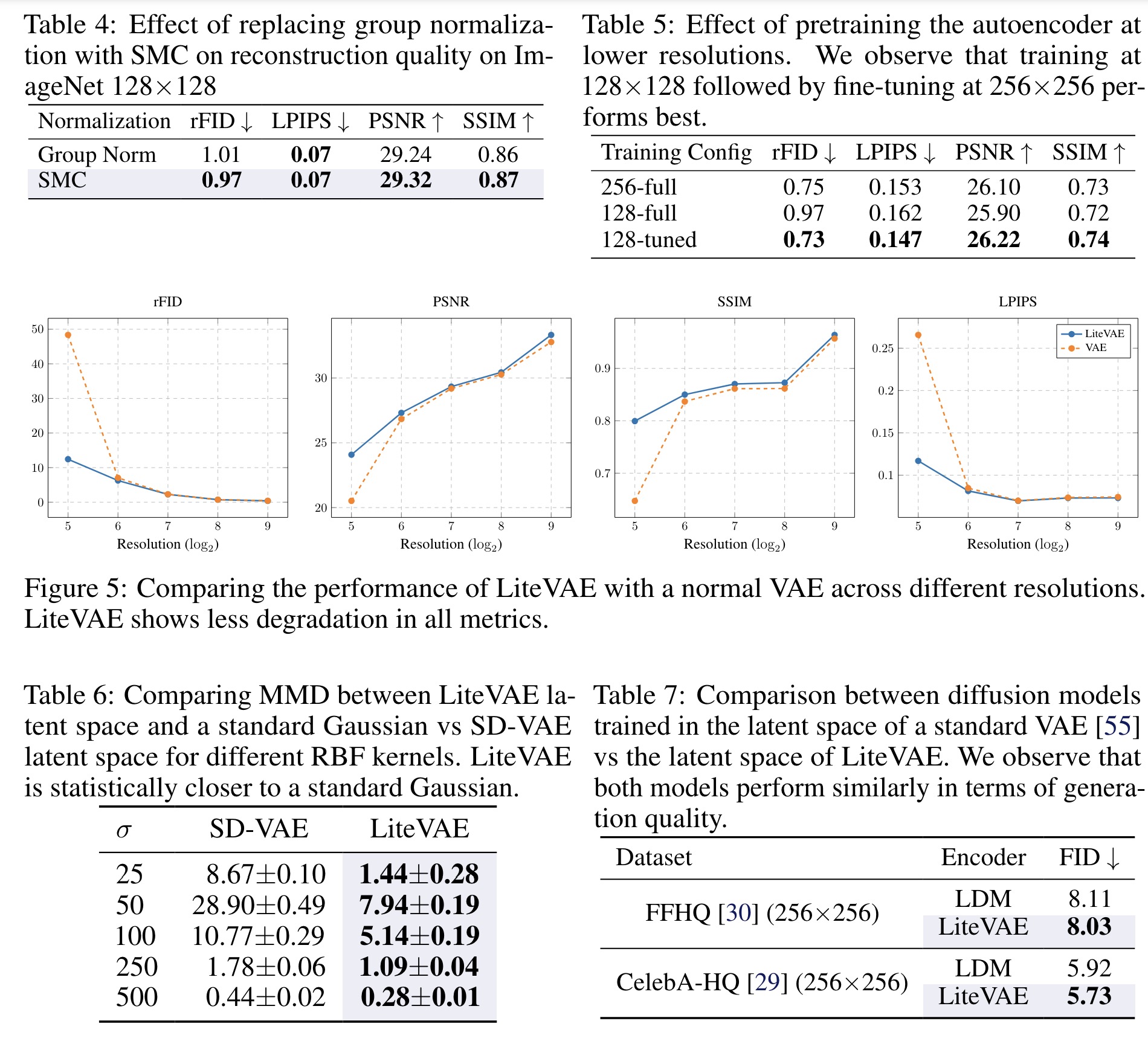
Removing group normalization in the decoder and replacing it with SMC leads to more balanced feature maps and better reconstruction quality. Pretraining LiteVAE at a lower resolution and fine-tuning at a higher resolution results in a model that slightly outperforms one trained entirely at the higher resolution, while significantly reducing the overall training time.
LiteVAE is less prone to performance degradation at different resolutions compared to standard VAEs, due to its ability to learn more scale-independent features from multi-resolution wavelet coefficients. The latent space of LiteVAE closely resembles that of Gaussian noise, making it well-suited for diffusion models, which need to transition from Gaussian noise to the latent space.
In experiments with diffusion models trained on the FFHQ and CelebA-HQ datasets, the performance of LiteVAE-based models was similar to or slightly better than standard VAE-based latent diffusion models.
Ablation studies
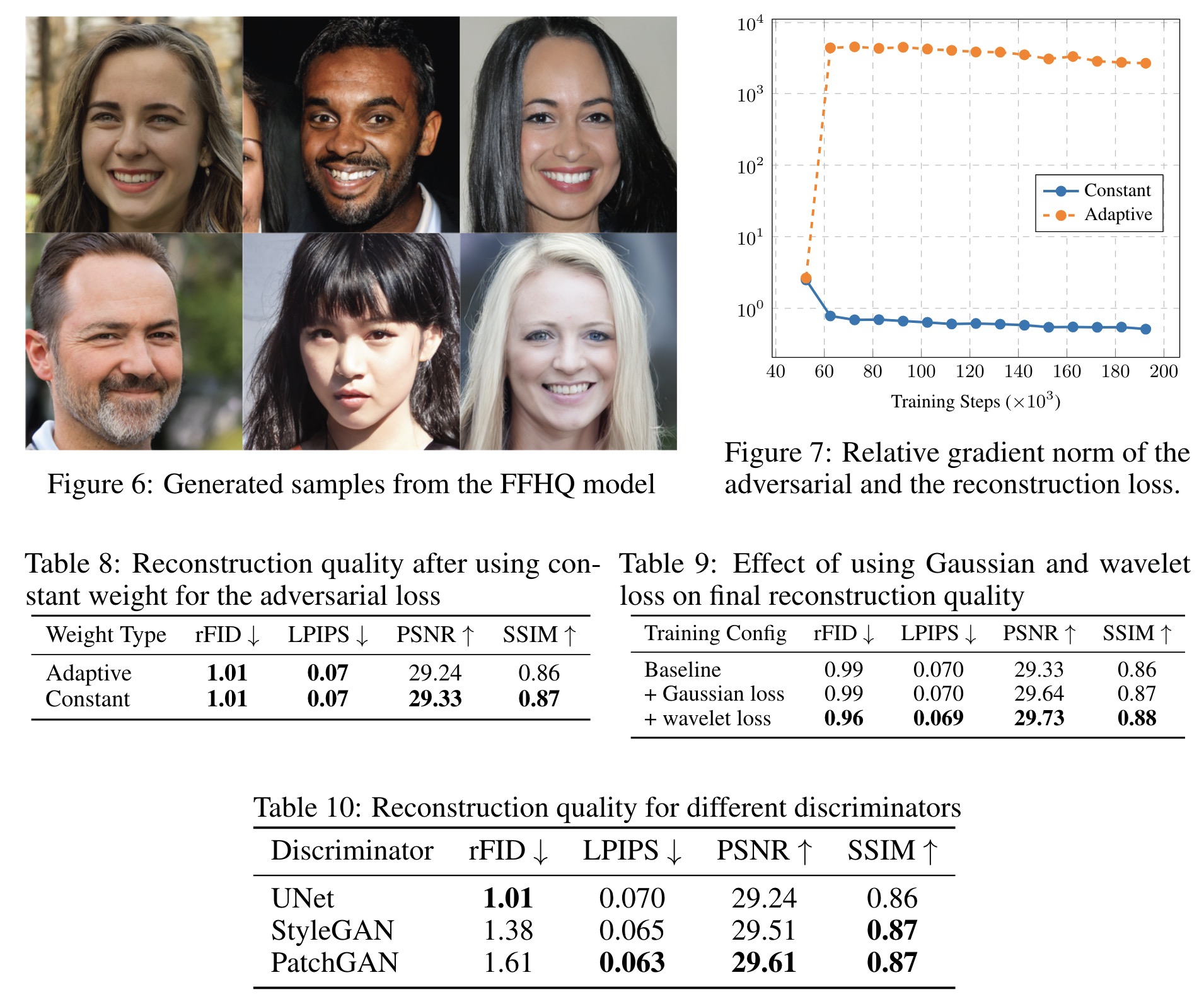
- Removing the adaptive weight for the adversarial loss and using a constant weight improves metrics slightly and leads to more stable training. This adaptive weight causes imbalanced gradient ratios, especially in mixed-precision scenarios.
- Adding high-frequency losses based on Gaussian filtering and wavelet transform consistently improves reconstruction metrics.
- Using a UNet-based discriminator outperforms PatchGAN and StyleGAN discriminators in terms of rFID and provides more stable training across different runs and hyperparameters while maintaining comparable performance for other metrics.