Paper Review: Llama 2: Open Foundation and Fine-Tuned Chat Models

The authors of the work present Llama 2, an assortment of pretrained and fine-tuned large language models (LLMs) with sizes varying from 7 billion to 70 billion parameters. The fine-tuned versions, named Llama 2-Chat, are specifically designed for dialogue applications. These models surpass the performance of existing open-source chat models on most benchmarks, and according to human evaluations for usefulness and safety, they could potentially replace closed-source models. The authors also detail their approach to fine-tuning and safety enhancements for Llama 2-Chat to support the community in further developing and responsibly handling LLMs.
Pretraining
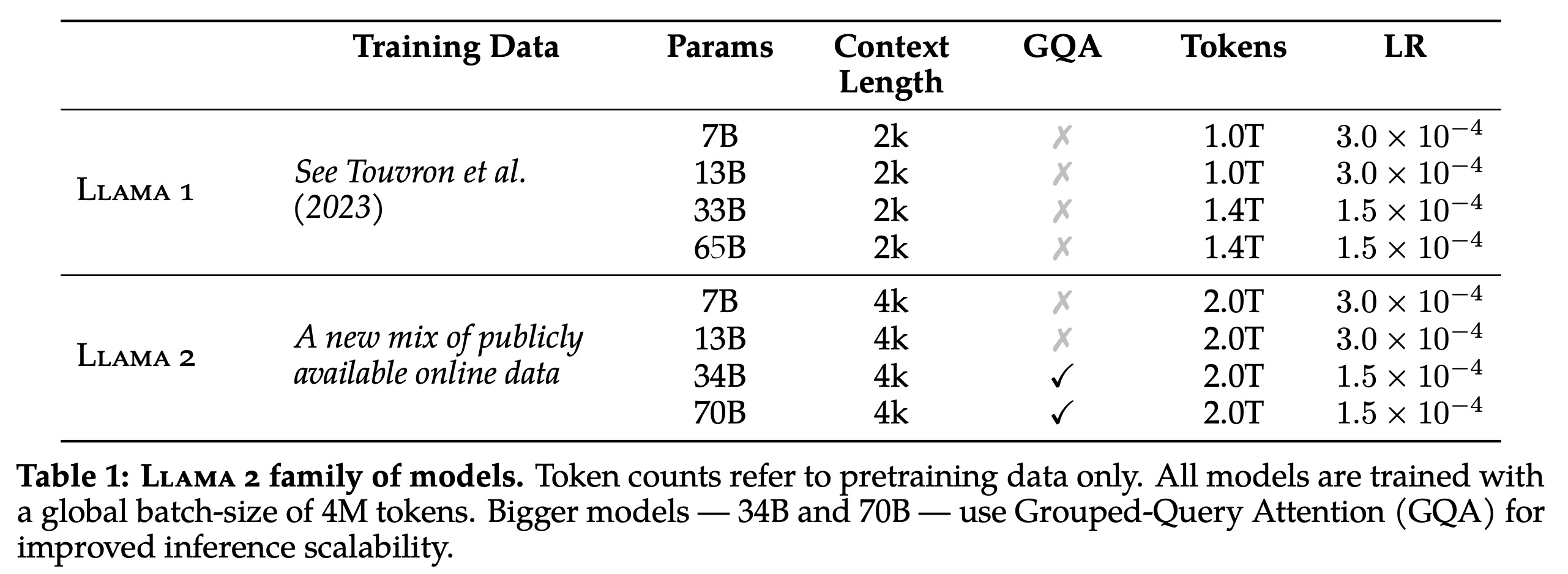
The authors developed the Llama 2 model family starting from the pretraining methodology of Llama, which utilizes an optimized auto-regressive transformer. They implemented several modifications for improved performance, including enhanced data cleaning, updated data mixes, training on 40% more total tokens, and doubling the context length. They also incorporated grouped-query attention (GQA) to enhance the inference scalability for their larger models.
Pretraining Data
The authors utilized a novel mix of data from publicly accessible sources to train the Llama 2 models, excluding any data from Meta’s products or services. They made efforts to erase data from certain sites known for harboring large amounts of personal information about private individuals. They trained the models on 2 trillion tokens of data, believing this amount provided a beneficial performance-cost balance. They also up-sampled the most factual sources to boost knowledge and reduce instances of false information generation or “hallucinations”.
Llama 2 Pretrained Model Evaluation
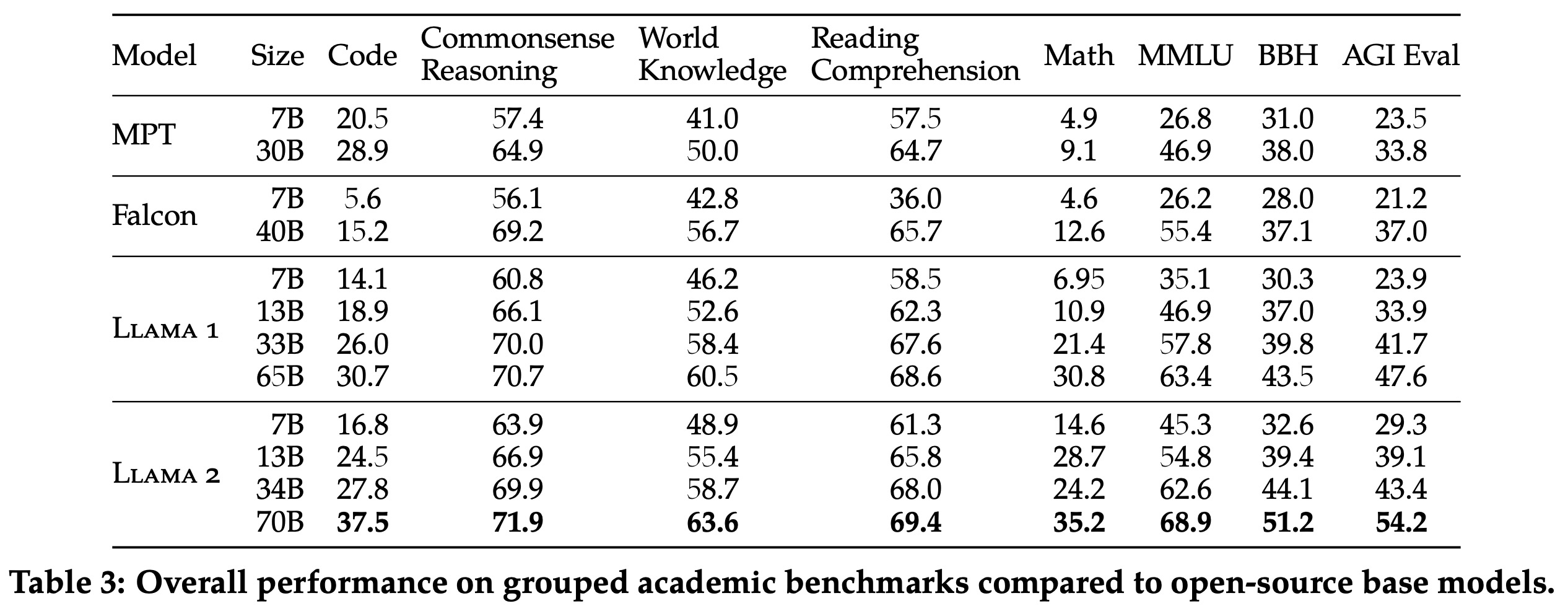
Llama 2 models significantly outperform their Llama 1 counterparts:
- The 70 billion-parameter Llama 2 model notably improves results on the MMLU and BBH benchmarks by roughly 5 and 8 points, respectively, when compared to the 65 billion-parameter Llama 1 model.
- Llama 2 models with 7 billion and 30 billion parameters outdo MPT models of similar size in all categories except code benchmarks.
- In comparison with Falcon models, Llama 2’s 7 billion and 34 billion parameter models outperform the 7 billion and 40 billion parameter Falcon models in all benchmark categories.
- Moreover, the Llama 2 70B model surpasses all open-source models.
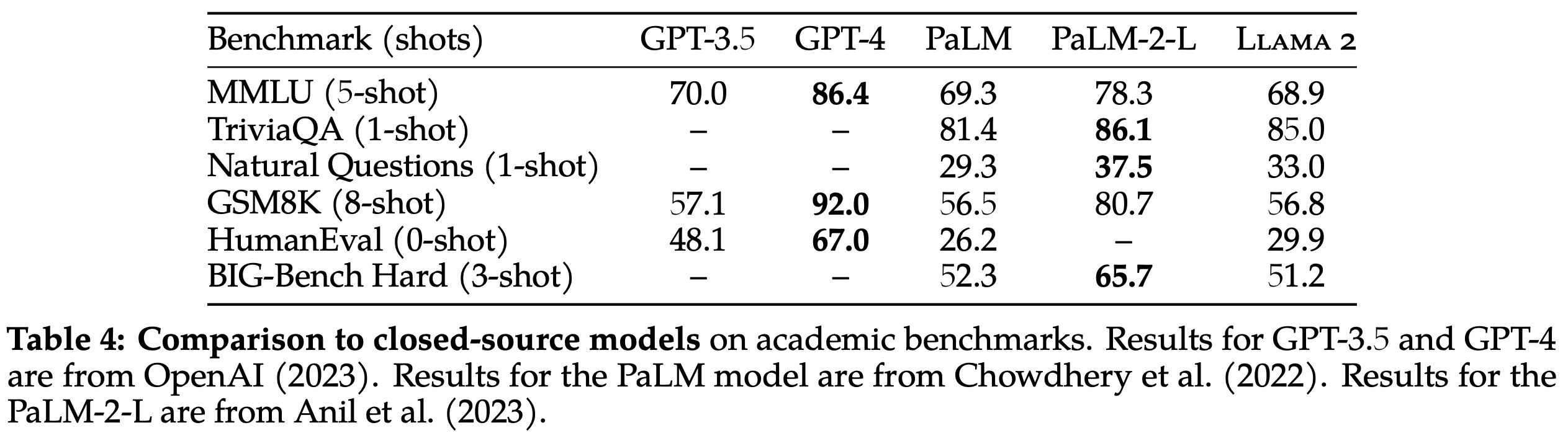
Comparatively, the Llama 2 70B model performs similarly to the closed-source GPT-3.5 (OpenAI, 2023) on the MMLU and GSM8K benchmarks but shows a significant deficit on coding benchmarks. It matches or exceeds the performance of PaLM (540 billion parameters) on nearly all benchmarks. However, there remains a substantial performance gap between the Llama 2 70B model and both GPT-4 and PaLM-2-L.
Fine-tuning
Supervised Fine-Tuning (SFT)

The authors initiated the Supervised Fine-Tuning (SFT) phase using publicly available instruction tuning data like in Llama. However, they observed that many third-party SFT data sources lacked diversity and quality, particularly for aligning Large Language Models (LLMs) towards dialogue-style instructions. Therefore, they prioritized collecting several thousand high-quality SFT data examples, and found that using fewer but better-quality examples led to notable performance improvements.
The authors discovered that tens of thousands of SFT annotations were enough to achieve high-quality results, and ceased after collecting 27,540 annotations. They highlighted the significant impact of different annotation platforms and vendors on model performance, emphasizing the need for data checks even when sourcing annotations from vendors. A manual examination of a set of 180 examples showed that model outputs were often competitive with those handwritten by human annotators, suggesting the value in shifting more annotation efforts to preference-based annotation for Reinforcement Learning from Human Feedback (RLHF).
In fine-tuning, each sample consisted of a prompt and an answer, concatenated together with a special token used to separate the segments. The authors used an autoregressive objective and zeroed-out the loss on tokens from the user prompt, meaning they only backpropagated on answer tokens.
Human Preference Data Collection
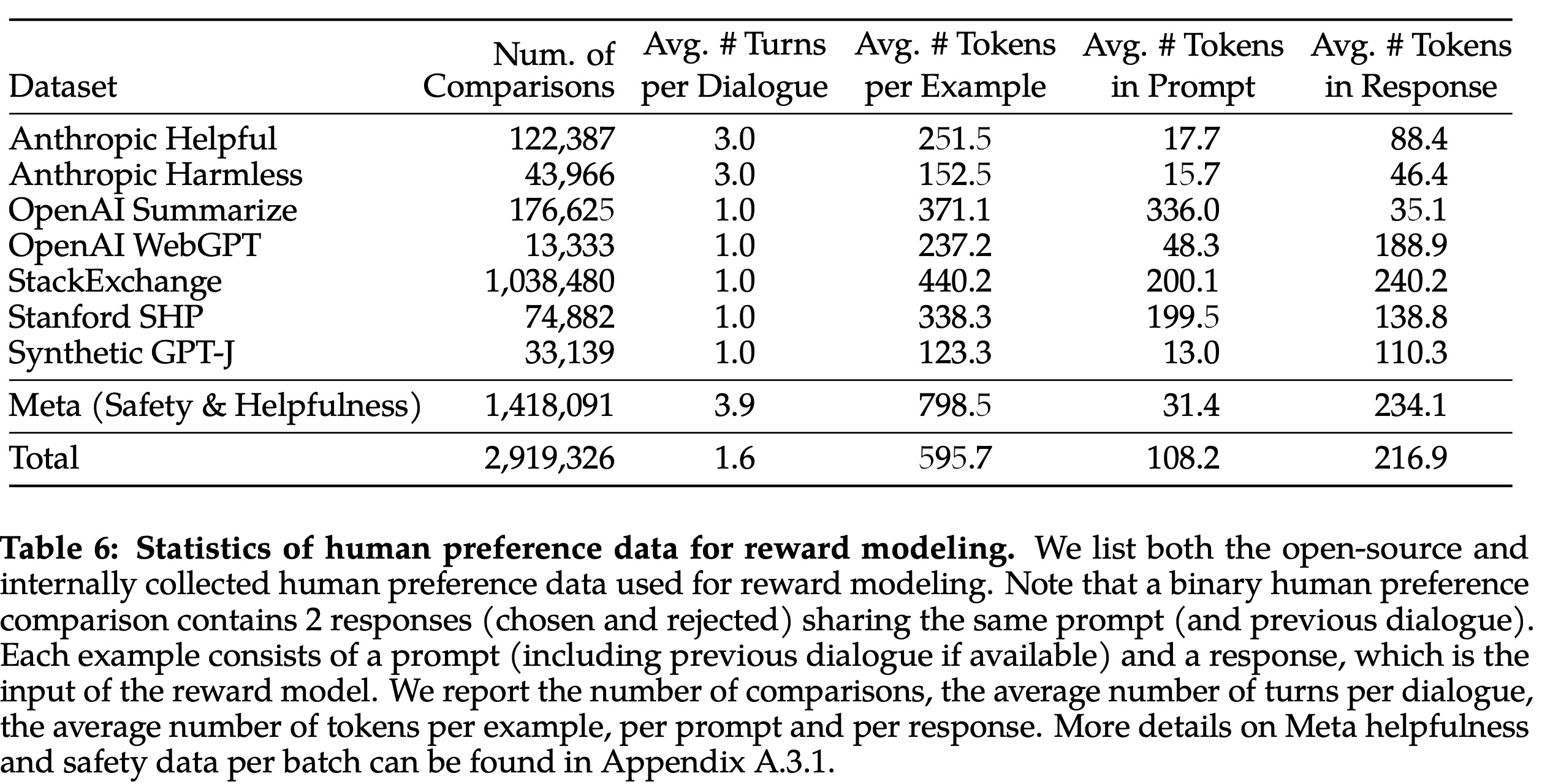
The authors used a binary comparison protocol to collect human preference data for reward modeling in order to maximize the diversity of prompts. Annotators were tasked with writing a prompt and choosing between two model responses based on set criteria. These responses were sampled from two different model variants and varied by temperature hyperparameter. Annotators also had to rate their preference for the chosen response over the alternative (significantly better, better, slightly better, or negligibly better/ unsure.).
The focus of these preference annotations was on “helpfulness” and “safety”. The authors define “helpfulness” as how well Llama 2-Chat responses fulfil users’ requests, and “safety” as whether responses comply with their safety guidelines. Separate guidelines were provided for each focus area.
During the safety stage, model responses were categorized into three groups: 1) the preferred response is safe and the other is not, 2) both responses are safe, and 3) both responses are unsafe. No examples where the chosen response was unsafe and the other safe were included.
Human annotations were collected in weekly batches. As more preference data was collected, their reward models improved, allowing the authors to train progressively better versions of Llama 2-Chat. As improvements shifted the model’s data distribution, the authors collected new preference data using the latest Llama 2-Chat iterations to keep the reward model up-to-date and accurate.
The authors collected over 1 million binary comparisons, referred to as Meta reward modeling data. Compared to existing open-source datasets, their preference data has more conversation turns and is, on average, longer.
Reward Modeling
The authors developed a reward model that inputs a model response and corresponding prompt and outputs a score indicating the quality (e.g., helpfulness, safety) of the generated response. These scores can then be used as rewards to optimize the Llama 2-Chat model for better alignment with human preferences.
They trained two separate reward models: one optimized for helpfulness (Helpfulness RM) and another for safety (Safety RM). These models were initialized from pre-trained chat model checkpoints, ensuring knowledge transfer and preventing discrepancies such as favoring hallucinations.
To train the reward model, pairwise human preference data was converted into a binary ranking label format. The model was trained to ensure that the chosen response scored higher than its counterpart. To leverage the four-point preference rating scale, they added a margin component to the loss to help the model assign more distinct scores to responses that have more differences.
The authors combined their new data with existing open-source preference datasets to form a larger training dataset.
Reward Model Results
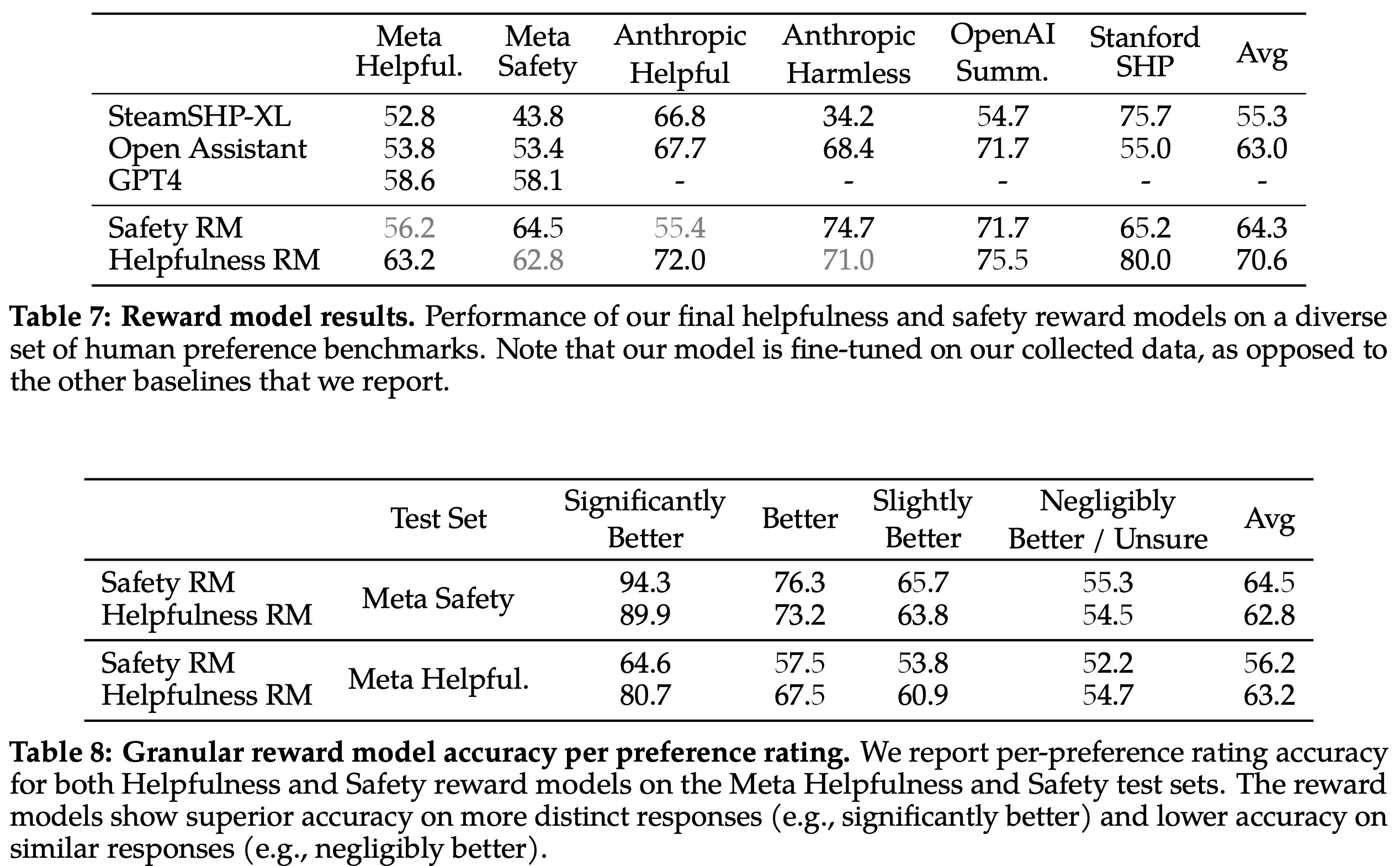
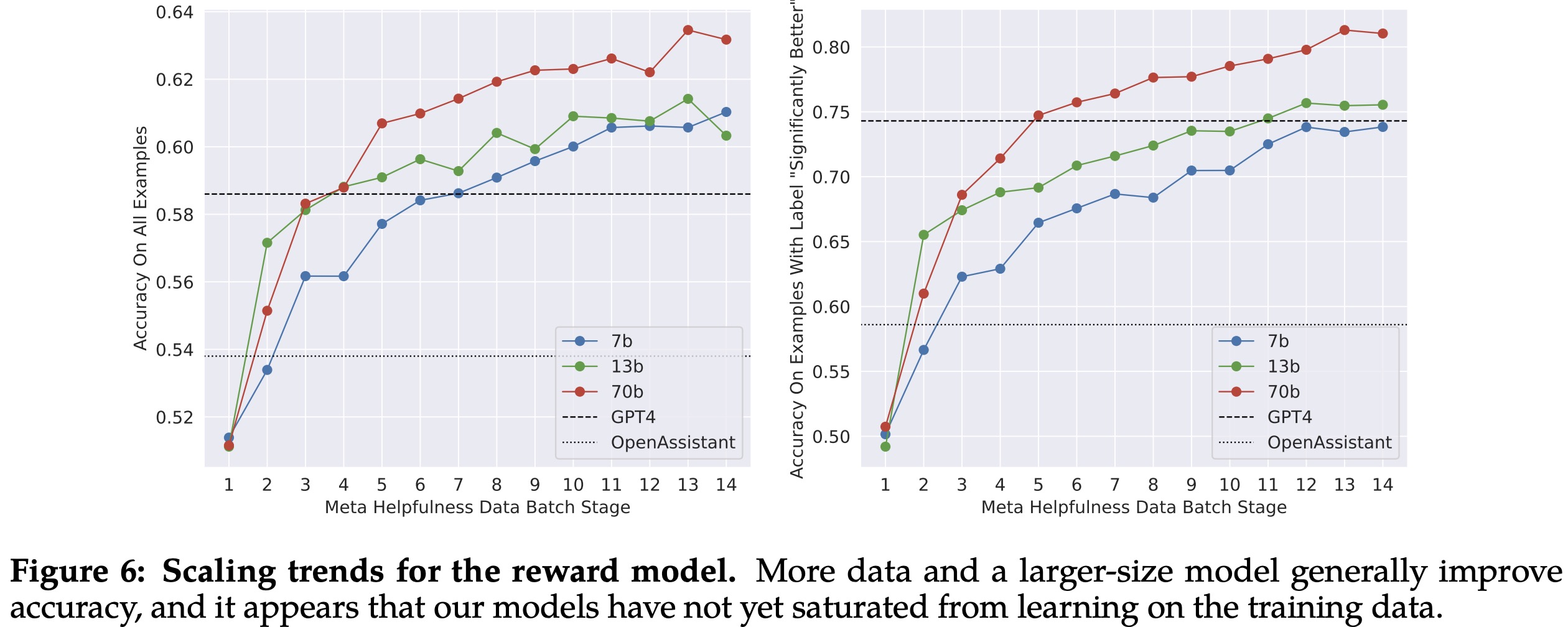
The authors evaluated their reward models on a test set held out from each batch of human preference annotation data. They compared their models with publicly available alternatives, including SteamSHP-XL, the Open Assistant reward model, and GPT-4. Their models performed the best, particularly on the corresponding internal test sets.
The authors noted a tension between the goals of helpfulness and safety, and suggested this might be why their separate models performed best on their own domain. A single model that aims to perform well on both aspects would need to differentiate between better responses and distinguish safe prompts from adversarial ones.
When scoring by preference rating, accuracy was superior for “significantly better” test sets, and it degraded as comparisons became more similar. The authors pointed out that accuracy on more distinct responses is key to improving Llama 2-Chat’s performance.
In terms of scaling trends, the authors found that larger models provided better performance for similar volumes of data, and performance had not plateaued with the current volume of annotated data. The authors concluded that improving the reward model’s accuracy could directly improve Llama 2-Chat’s performance, as the ranking task of the reward is unambiguous.
Iterative Fine-Tuning
Two main algorithms were used for RLHF fine-tuning: Proximal Policy Optimization (PPO), standard in RLHF literature, and Rejection Sampling fine-tuning, where they selected the best output from sampled model responses for a gradient update. The differences between the two algorithms lie in breadth (K samples for a given prompt in Rejection Sampling) and depth (in PPO the sample is a function of the updated model policy from the previous step, in RS all outputs are sampled. In iterative training the differences are less pronounced).
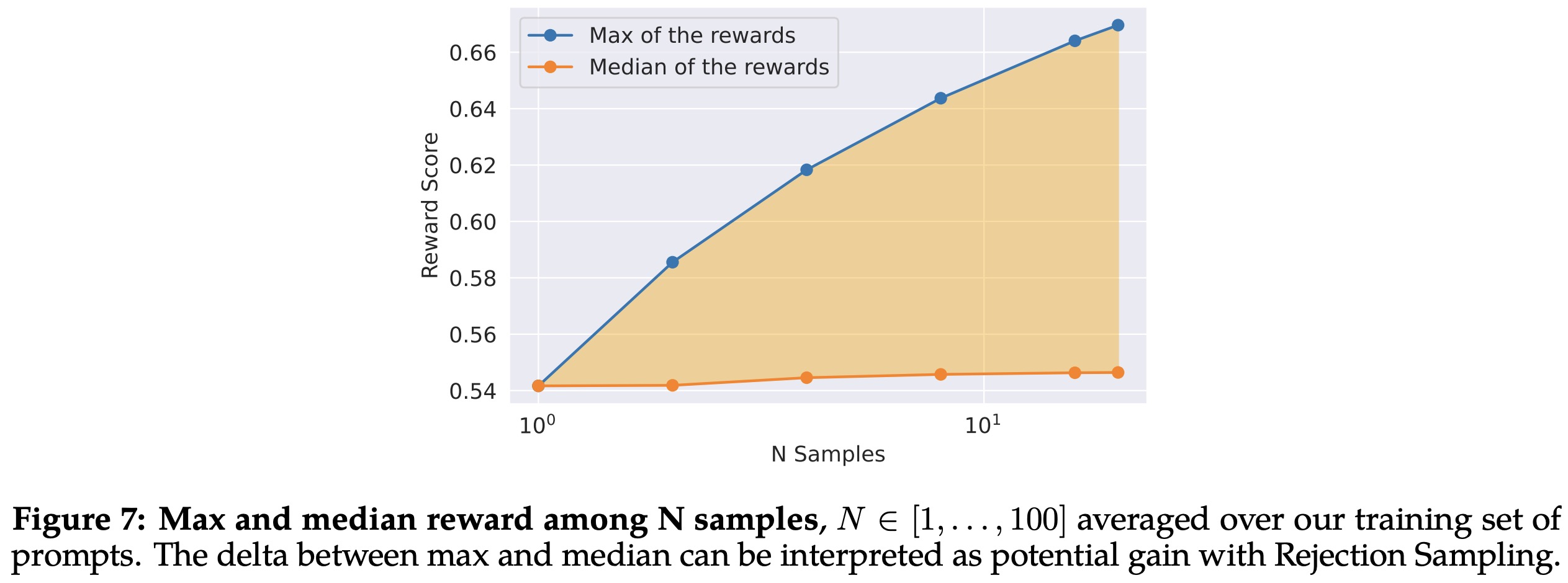
Rejection Sampling fine-tuning was performed only with the largest 70B Llama 2-Chat, with smaller models fine-tuned on the sampled data from the larger model. Over iterations, the authors adjusted their strategy to include top-performing samples from all prior iterations, leading to significant performance improvements.
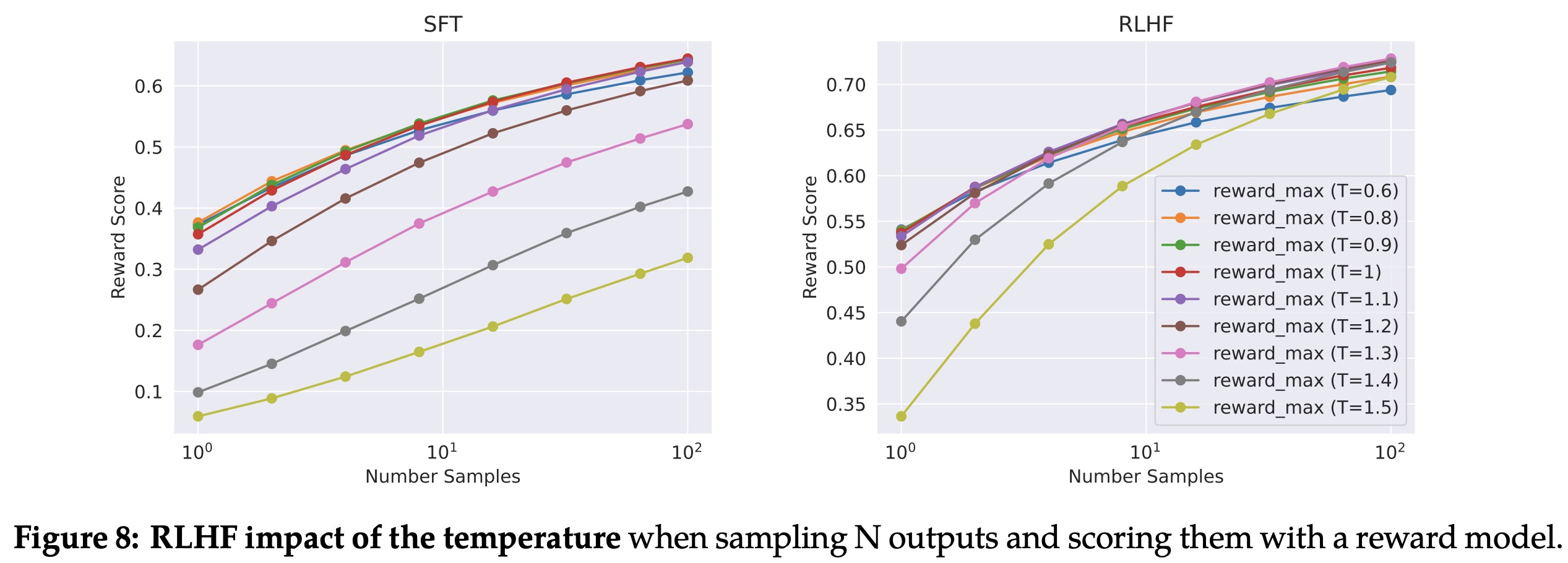
The authors illustrate the benefit of Rejection Sampling in two ways. They show the delta between the maximum and median curves can be interpreted as the potential gain of fine-tuning on the best output. They also found that the optimal temperature for generating diverse samples isn’t constant during iterative model updates.
After RLHF (V4), the authors sequentially combined Rejection Sampling and PPO fine-tuning. For PPO, they iteratively improved the policy by sampling prompts and generations from the policy and used the PPO algorithm to achieve the objective. They also added a penalty term for diverging from the original policy, as it’s helpful for training stability and to reduce reward hacking.
System Message for Multi-Turn Consistency
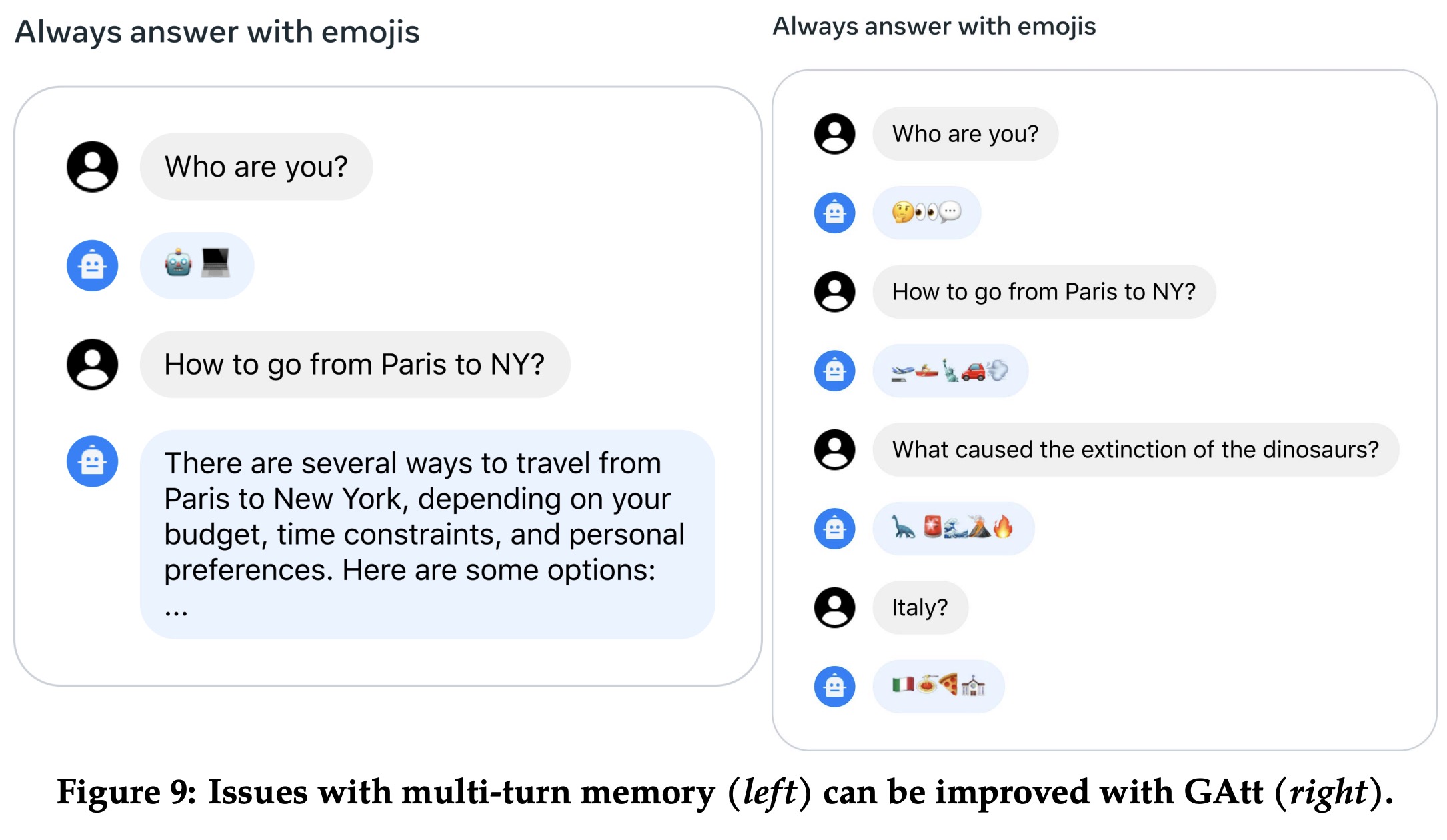
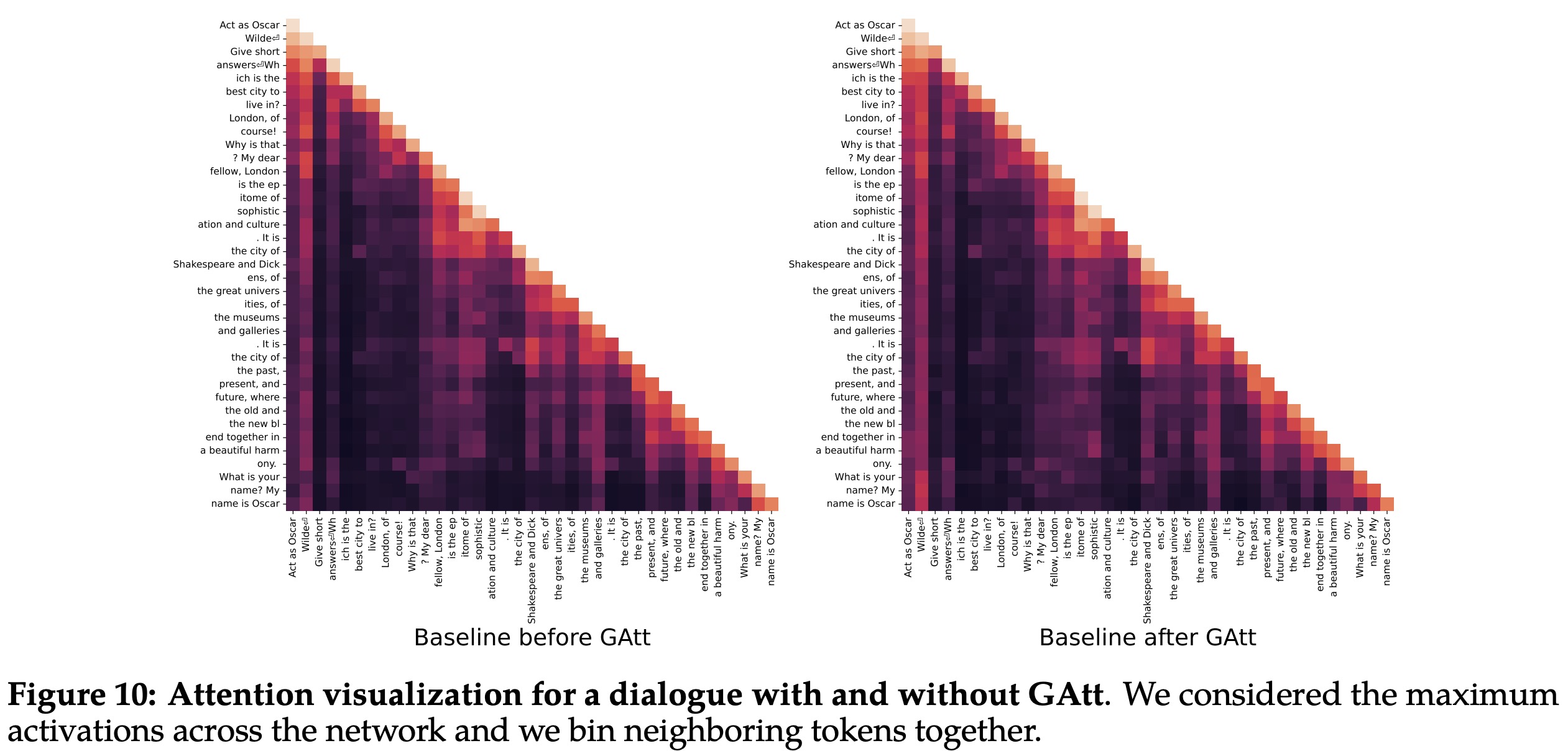
The authors proposed Ghost Attention (GAtt), a technique designed to help AI remember initial instructions throughout a dialogue. This method, which builds on the concept of Context Distillation, introduces an instruction that needs to be followed throughout the conversation and is appended to all user messages in a synthetic dialogue dataset. During training, the instruction is only kept in the first turn and the loss is set to zero for all tokens from prior turns. This strategy was applied to a range of synthetic constraints including hobbies, language, and public figures. The implementation of GAtt helped maintain attention towards initial instructions over a larger part of the dialogue.
GAtt managed to ensure consistency even over 20+ turns, until the maximum context length was reached. While this initial implementation has been beneficial, the authors believe there is potential for further enhancement and iteration on this technique.
RLHF Results
Model-Based Evaluation
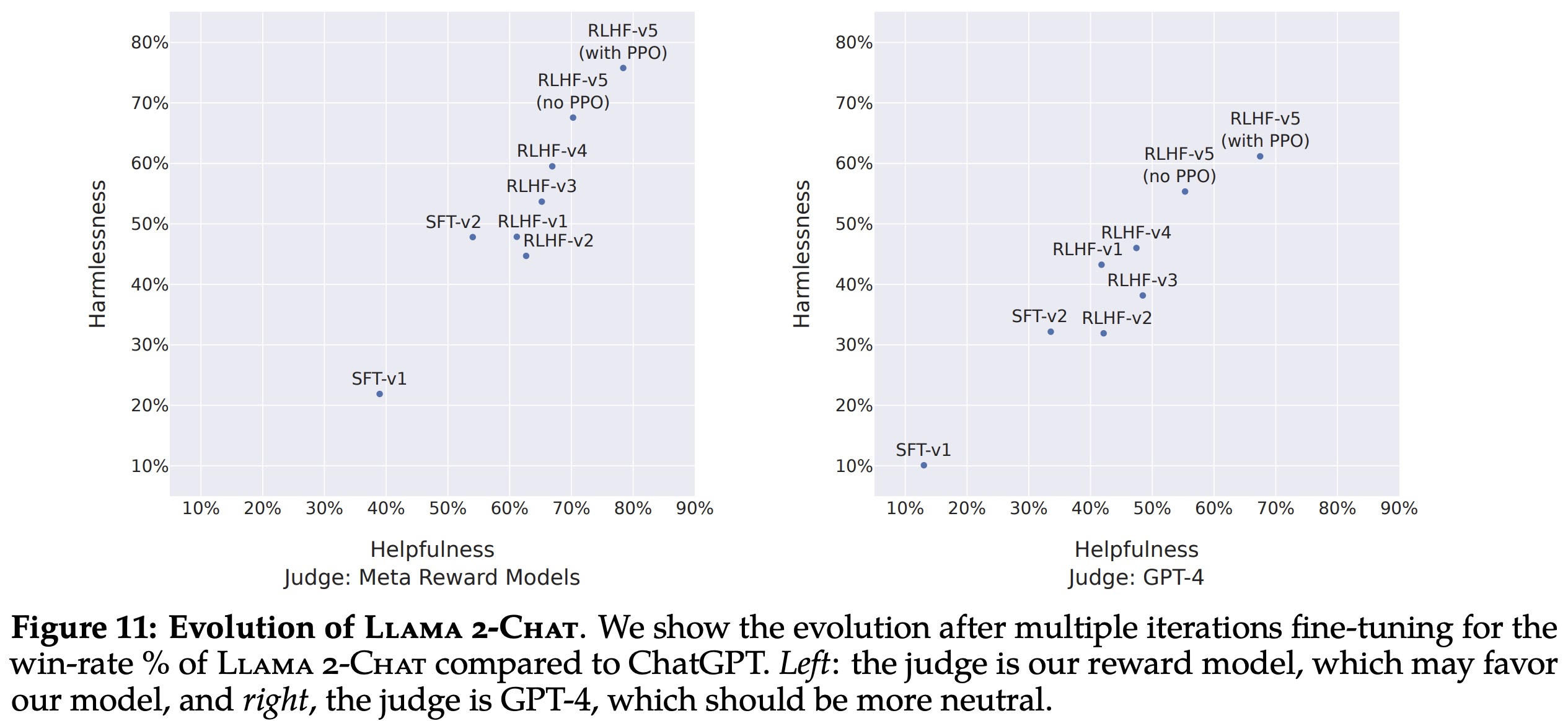
Evaluating large language models (LLMs) like Llama 2-Chat is a complex problem. While human evaluation is considered the gold standard, it is not always scalable and may present complications. As a solution, the authors first used reward models to measure improvement in iterations of their Reinforcement Learning from Human Feedback (RLHF) model versions, and later confirmed these findings with human evaluations.
To test the reward model’s reliability, the authors collected a test set of prompts and had them judged by human annotators. The results indicated that the reward models were generally well-aligned with human preferences, validating their use as a point-wise metric.
However, to prevent possible divergence from human preferences, the authors also utilized a more general reward model trained on diverse open-source Reward Modeling datasets. They hypothesize that iterative model updates may help maintain alignment with human preferences.
In a final check to ensure no regression between new and old models, both models were used in the next annotation iteration for comparison.
The authors’ models were shown to outperform ChatGPT in both safety and helpfulness after RLHF-V3. For fair comparison, final results were also assessed using GPT-4. This resulted in Llama 2-Chat still showing a win-rate of over 60% against ChatGPT, although the advantage was less pronounced.
Human Evaluation
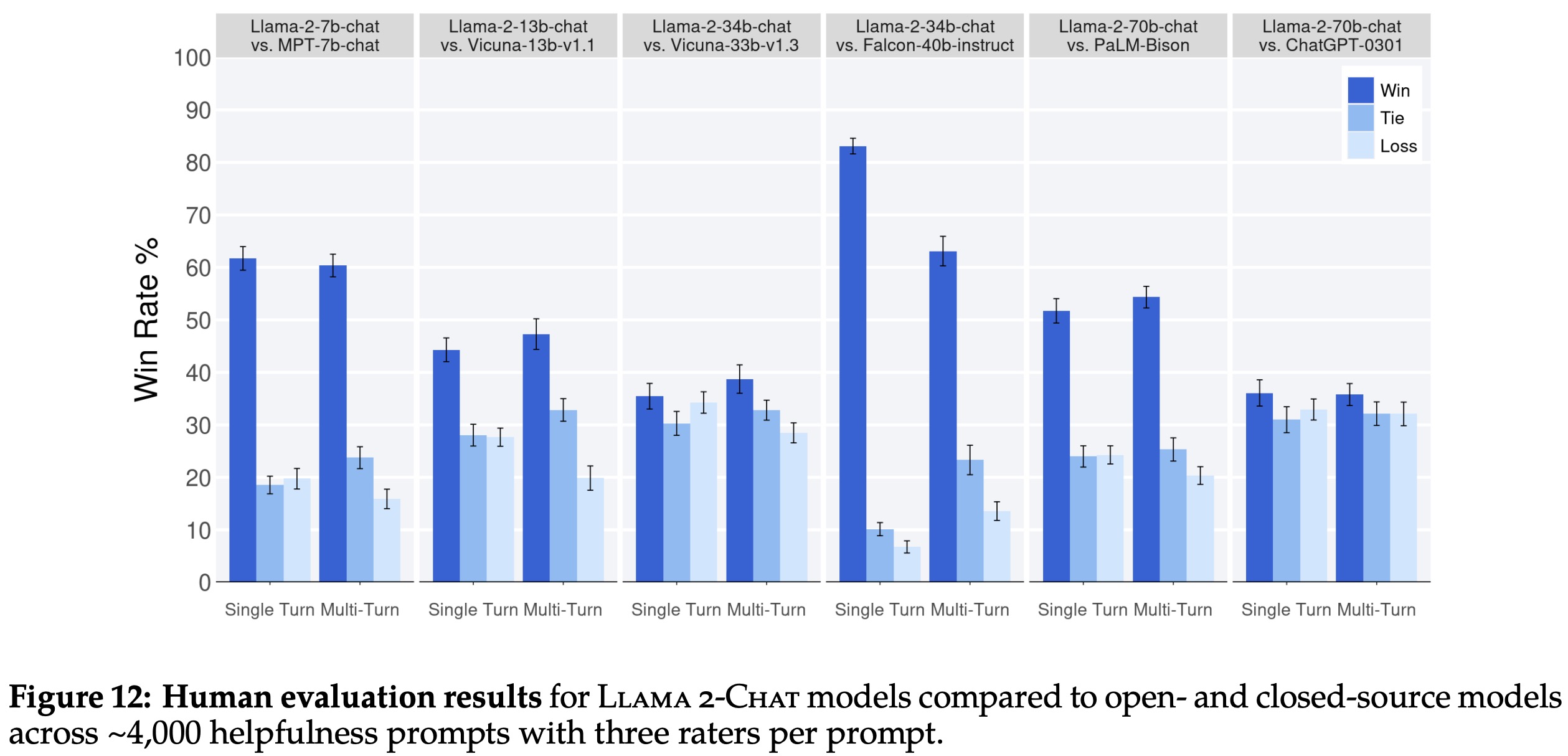
Human evaluations are often considered the gold standard for evaluating dialogue models, and the researchers used this method to assess the Llama 2-Chat models’ helpfulness and safety. The models were compared to open-source models like Falcon and MPT MosaicML as well as closed-source models like ChatGPT and PaLM using over 4,000 single and multi-turn prompts.
The results showed that Llama 2-Chat models significantly outperformed open-source models on both single turn and multi-turn prompts, with the Llama 2-Chat 34B model winning over 75% against comparably sized models. The largest Llama 2-Chat model was also competitive with ChatGPT.
Three different annotators independently evaluated each model generation comparison to ensure inter-rater reliability (IRR), which was measured using Gwet’s AC1/2 statistic. Depending on the model comparison, the AC2 score varied between 0.37 and 0.55.
However, the authors acknowledge that human evaluations have certain limitations. For instance, while the 4,000 prompt set is large by research standards, it doesn’t cover all possible real-world usage scenarios. The prompt set lacked diversity and didn’t include any coding- or reasoning-related prompts. Evaluations focused on the final generation of a multi-turn conversation, not the entire conversation experience. Finally, the subjective and noisy nature of human evaluations means results could vary with different prompts or instructions.
Safety
Safety in Pretraining
The authors discuss the pretraining data used for the Llama 2-Chat model and the steps taken to pretrain it responsibly. They didn’t use any user data and excluded certain sites that contain large amounts of personal information. They also aimed to minimize their carbon footprint and avoided additional filtering that could result in demographic erasure. However, the authors warn the model should be deployed only after significant safety tuning.
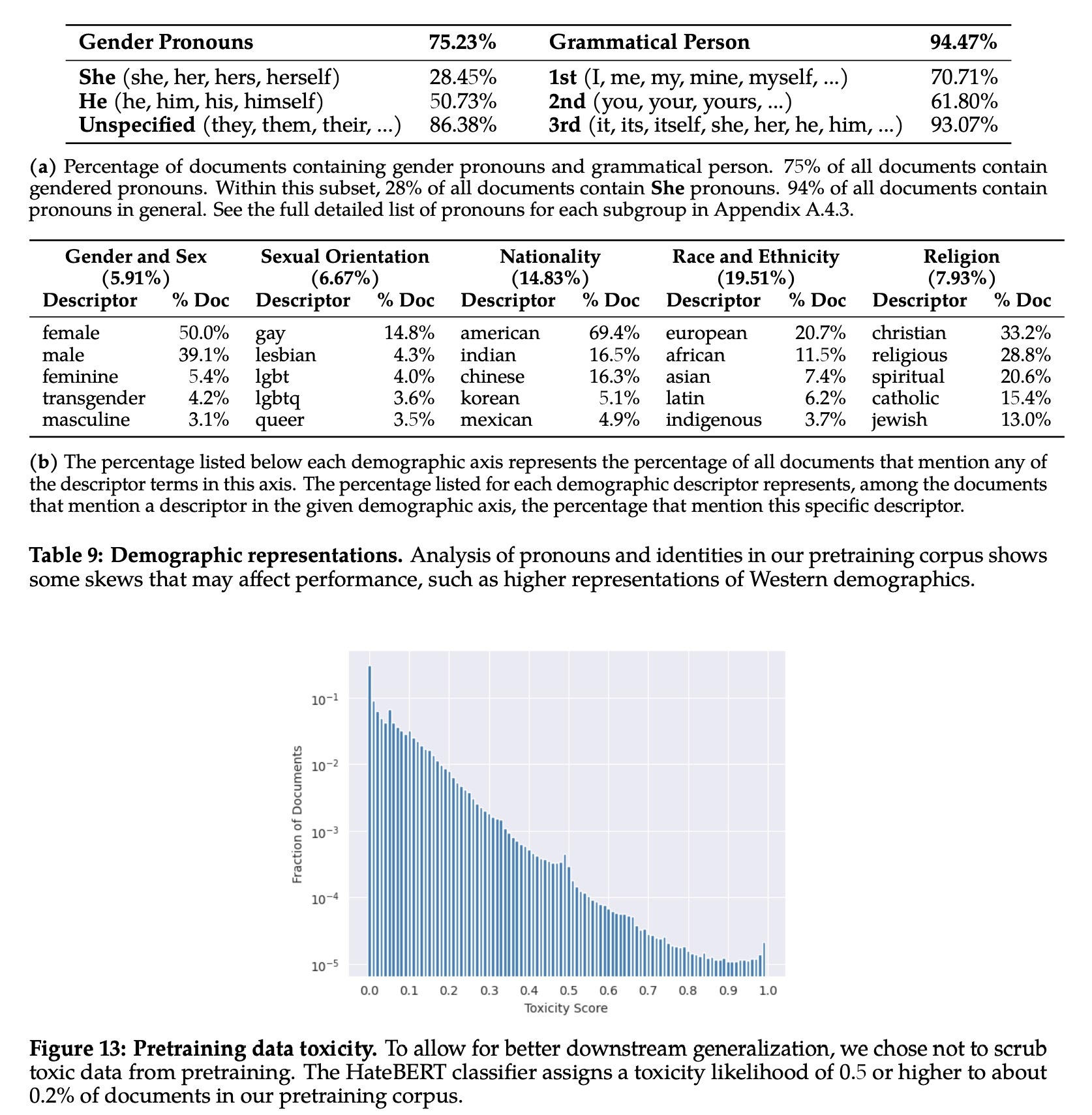
The demographic representation in the training data was analyzed, revealing an overrepresentation of “he” pronouns compared to “she” pronouns, which might lead to more frequent usage of “he” in the model’s outputs. The top demographic identity terms related to religion, gender, nationality, race and ethnicity, and sexual orientation all showed a Western skew.
The authors found a small amount of toxicity in the pretraining data, which may affect the output of the model. They also identified English as the dominant language in the training data, suggesting the model might not work as effectively with other languages.
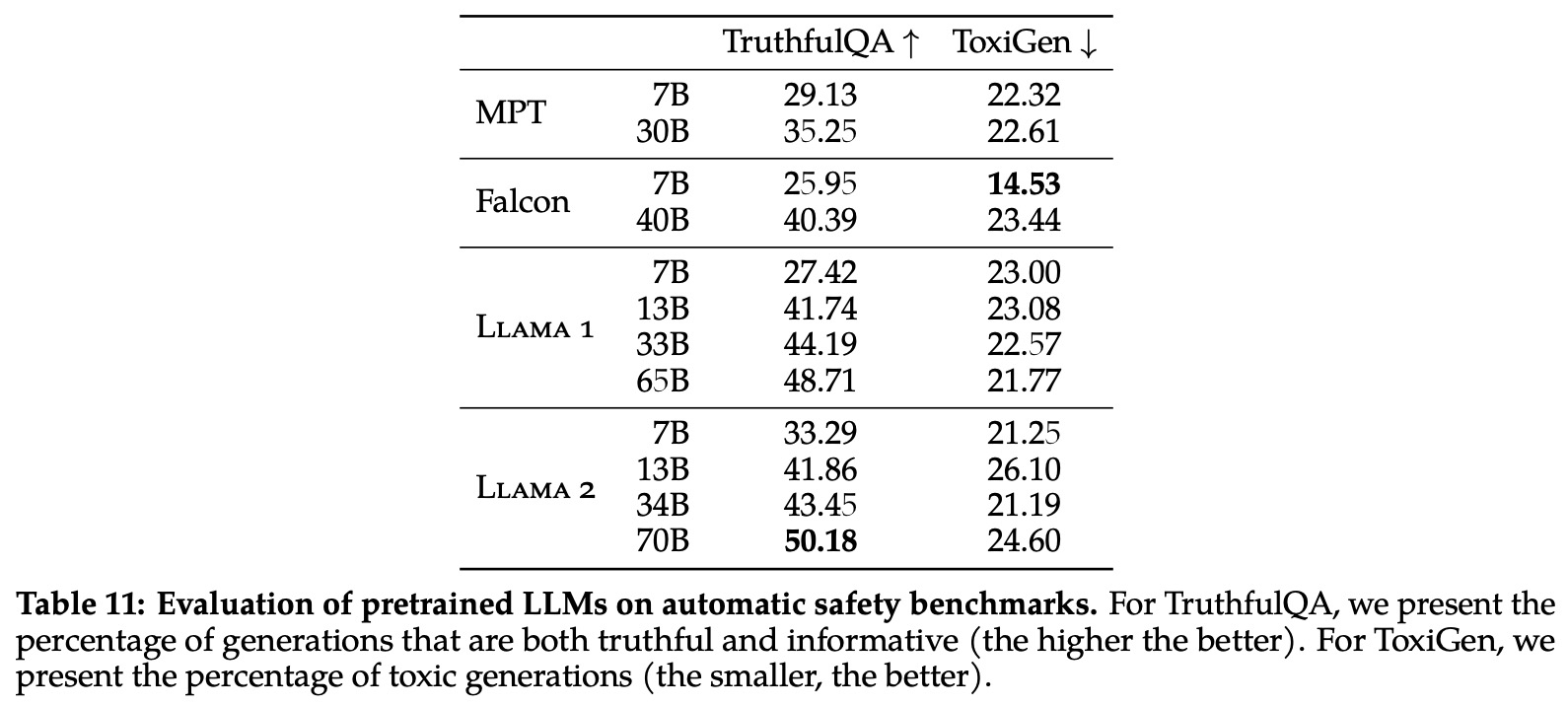
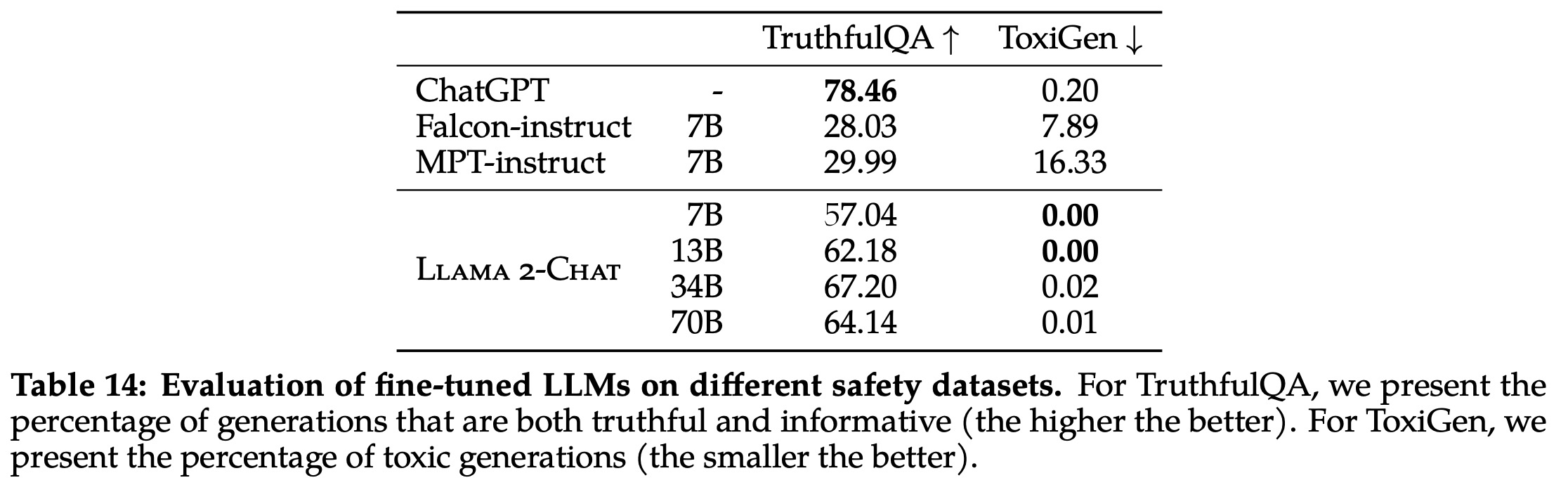
The safety capabilities of Llama 2 were tested using three automatic benchmarks: TruthfulQA for truthfulness, ToxiGen for toxicity, and BOLD for bias. Compared to its predecessor, Llama 2 demonstrated increased truthfulness and decreased toxicity. However, the 13B and 70B versions of Llama 2 exhibited increased toxicity, potentially due to larger pretraining data or different dataset mixes. While the authors noted an increase in positive sentiment for many demographic groups, they emphasized the need for additional safety mitigations before deployment and more comprehensive studies of the model’s real-world impact.
Safety Fine-Tuning

The authors discuss fine-tuning approach of a language model called Llama 2-Chat, outlining its techniques, safety categories, annotation guidelines, and methods to mitigate safety risks.
- Supervised Safety Fine-Tuning: Here, the team starts with adversarial prompts and safe demonstrations, included in the general supervised fine-tuning process. This helps align the model with safety guidelines early on.
- Safety RLHF (Reinforcement Learning from Human Feedback): This method integrates safety into the general RLHF pipeline, which involves training a safety-specific reward model and gathering more adversarial prompts for better fine-tuning.
- Safety Context Distillation: In this step, the model is refined by generating safer responses and distilling the safety context into the model. This is done using a targeted approach to choose if context distillation should be used for each sample.
Safety categories identified are illicit and criminal activities, hateful and harmful activities, and unqualified advice. To cover different varieties of prompts, they use risk categories and attack vectors, such as psychological manipulation, logic manipulation, syntactic manipulation, semantic manipulation, and others.
For fine-tuning, prompts and demonstrations of safe model responses are gathered and used following the established guidelines. The model’s ability to write nuanced responses improves through RLHF.
The research team also found that adding an additional stage of safety mitigation does not negatively impact model performance on helpfulness. However, with more safety data mixed in model tuning, the model does answer certain questions in a more conservative manner, leading to an increase in the rate of false refusals (where the model refuses to answer legitimate prompts due to irrelevant safety concerns).
Lastly, context distillation is used to encourage the model to associate adversarial prompts with safer responses, and this context distillation only occurs on adversarial prompts to prevent the degradation of model performance. The safety reward model decides whether to use safety context distillation or not.
Red Teaming
The researches discusses the application of red teaming as a proactive method of identifying potential risks and vulnerabilities in Language Learning Models (LLMs). These efforts involve more than 350 professionals from diverse fields such as cybersecurity, election fraud, legal, civil rights, software engineering, machine learning, and creative writing. The red teaming exercises focused on various risk categories, like criminal planning, human trafficking, privacy violations, etc., as well as different attack vectors. Some findings indicated that early models often failed to recognize and handle problematic content appropriately, but iterative improvements helped mitigate these issues.
Post-exercise, the data collected was analyzed thoroughly, considering factors like dialogue length, risk area distribution, and the degree of risk. This information was used for model fine-tuning and safety training. The effectiveness of these red teaming exercises was measured using a robustness factor, defined as the average number of prompts that would trigger a violating response from the model per person per hour. For instance, on a 7B model, the robustness improved significantly over several red teaming iterations and model refinements.
The red teaming efforts continue to be a valuable tool in improving model safety and robustness, with new candidate releases consistently reducing the rate of prompts triggering violating responses. As a result, on average, there was a 90% rejection rate model over model.
Safety Evaluation of Llama 2-Chat
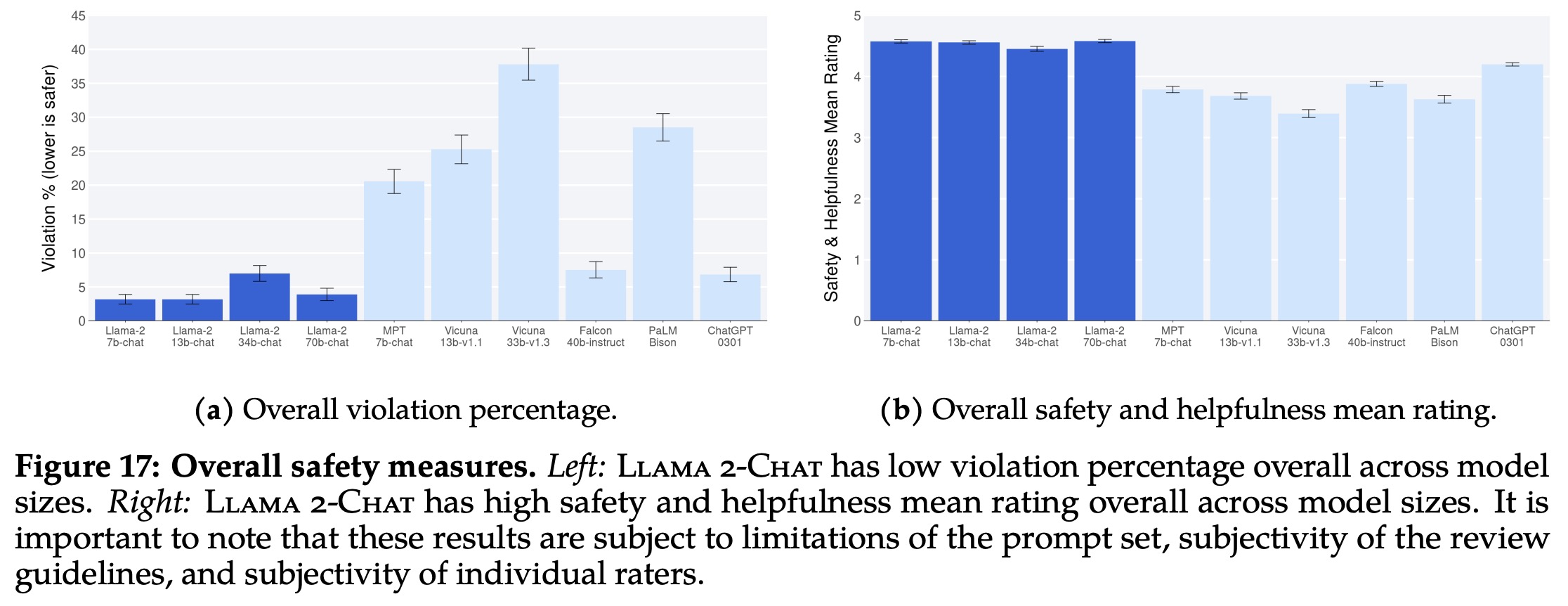
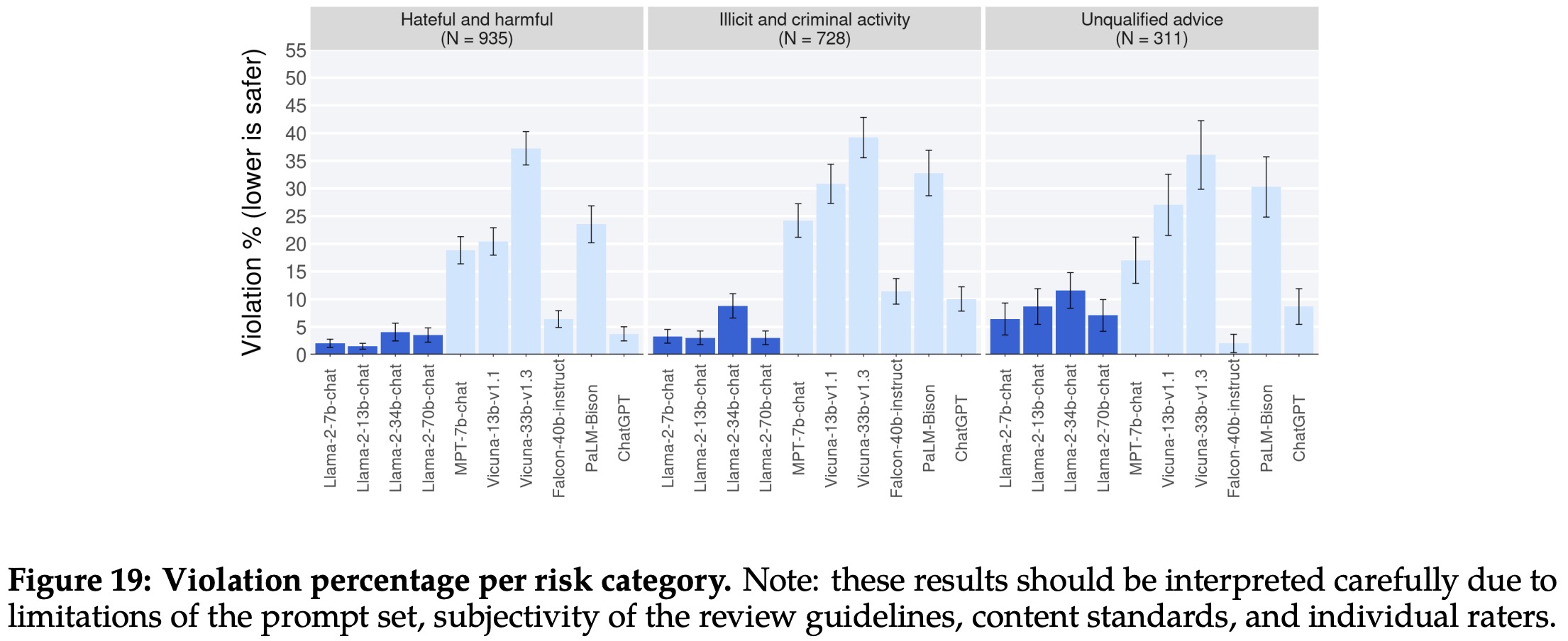
The authors used human evaluation method to assess the safety of Language Learning Models (LLMs), specifically involving around 2,000 adversarial prompts. The responses to these prompts were assessed by raters on a five-point Likert scale, with 5 being the safest and most helpful, and 1 indicating severe safety violations. A rating of 1 or 2 was considered as a violation.
The violation percentage served as the primary evaluation metric, with mean rating as supplementary. Three annotators assessed each example, with a majority vote determining if a response was violating safety guidelines. Inter-rater reliability (IRR), measured using Gwet’s AC1/2 statistic, indicated a high degree of agreement among annotators. The IRR scores varied depending on the model being evaluated.
The overall violation percentage and safety rating of various LLMs showed that Llama 2-Chat performed comparably or better than others. It is important to note that the evaluations are influenced by factors such as prompt set limitations, review guidelines’ subjectivity, content standards, and individual raters’ subjectivity.
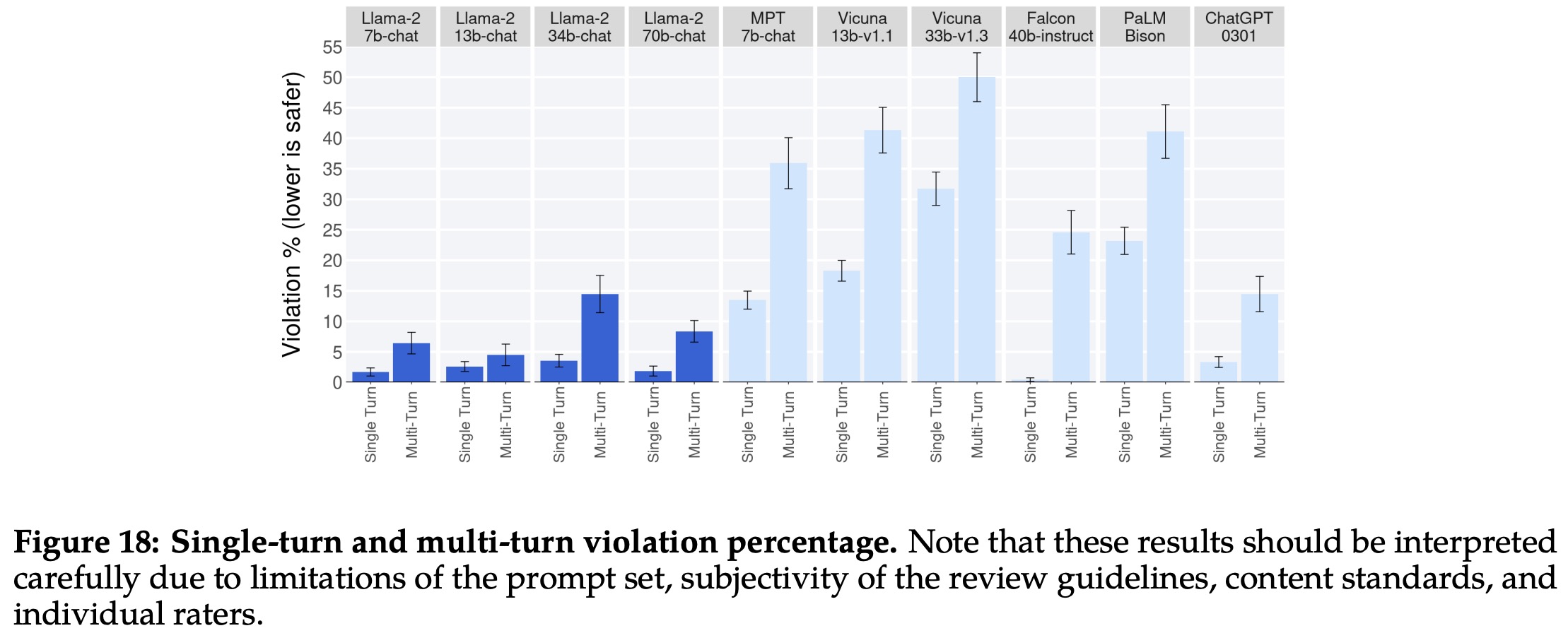
There was a trend observed that multi-turn conversations were more likely to induce unsafe responses across all models. However, Llama 2-Chat still performed well, particularly in multi-turn conversations.
In terms of truthfulness, toxicity, and bias, fine-tuned Llama 2-Chat showed great improvements over the pre-trained model. It showed the lowest level of toxicity among all compared models. Moreover, Llama 2-Chat showed increased positive sentiment for many demographic groups after fine-tuning. In-depth analyses and results of truthfulness and bias were provided in the appendix.
Discussions
Learnings and Observations

- The findings suggest that reinforcement learning was particularly effective in the tuning process due to its cost and time efficiency. The success of RLHF (Reinforcement Learning from Human Feedback) hinges on the synergistic relationship it creates between humans and LLMs during the annotation process. Notably, RLHF helps overcome the limitations of supervised fine-tuning and can lead to superior writing abilities in LLMs.
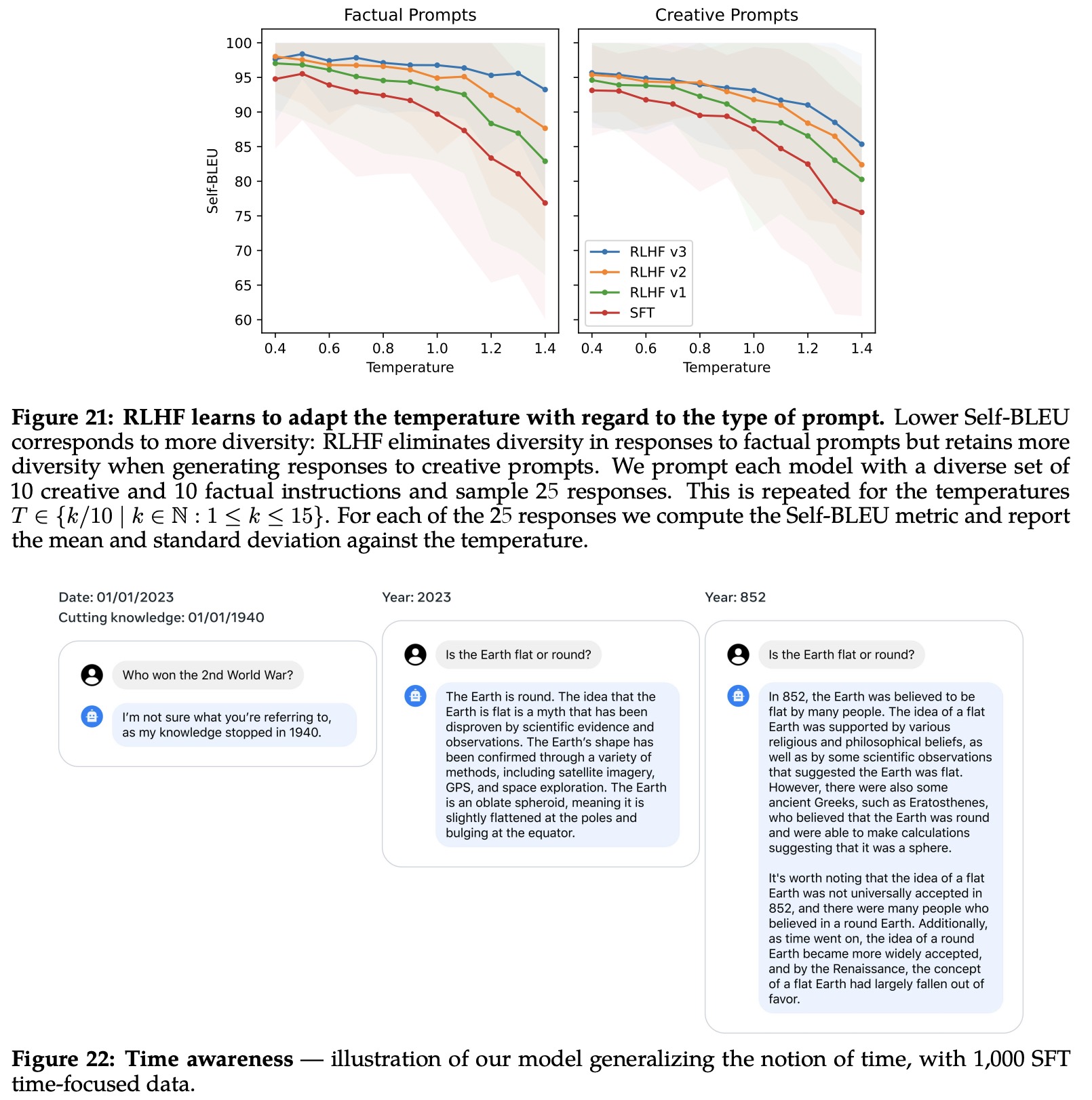
- An interesting phenomenon related to RLHF was observed - dynamic re-scaling of temperature contingent upon the context. For creative prompts, increased temperature continues to generate diversity across RLHF iterations. However, for factual prompts, despite the rising temperature, the model learns to provide consistent responses.
- The Llama 2-Chat model also demonstrated robust temporal organization abilities, which suggests LLMs might have a more advanced concept of time than previously thought.
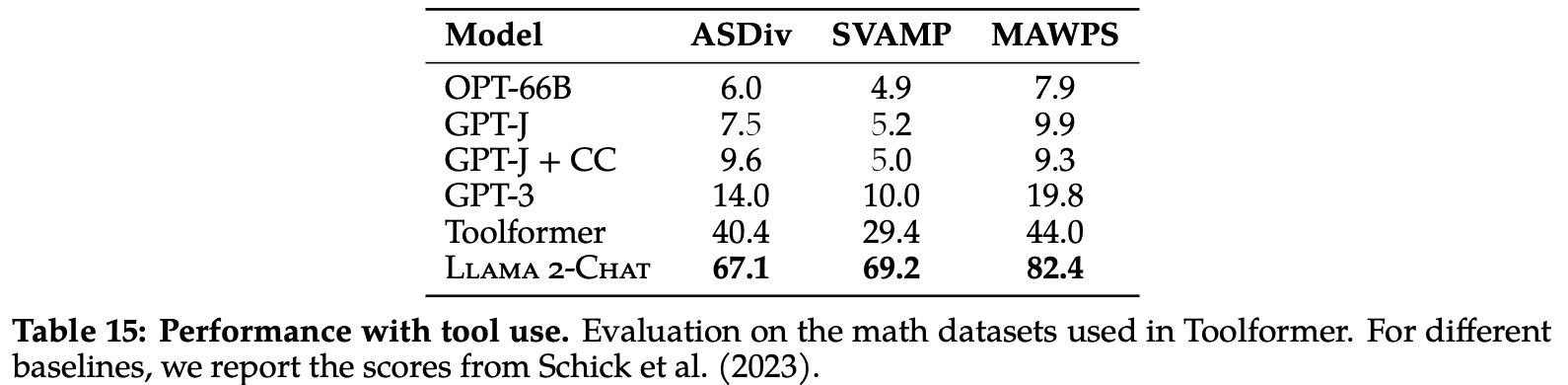
- An intriguing finding is the emergence of tool use in LLMs, which emerged spontaneously in a zero-shot context. Even though tool-use was not explicitly annotated, the model demonstrated the capability to utilize a sequence of tools in a zero-shot context. While promising, LLM tool use can also pose safety concerns and requires further research and testing.