Paper Review: Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency

Loopy is an end-to-end audio-only conditioned video diffusion model for human video generation. It avoids using additional spatial signals that can limit natural motion, unlike previous methods. Loopy introduces inter- and intra-clip temporal modules and an audio-to-latents module to learn natural motion patterns and enhance the correlation between audio and portrait movement. This eliminates the need for predefined spatial motion templates (used to constrain motion during inference). Experiments show Loopy outperforms recent audio-driven portrait diffusion models, producing more lifelike and high-quality videos in various scenarios.
The approach
Framework
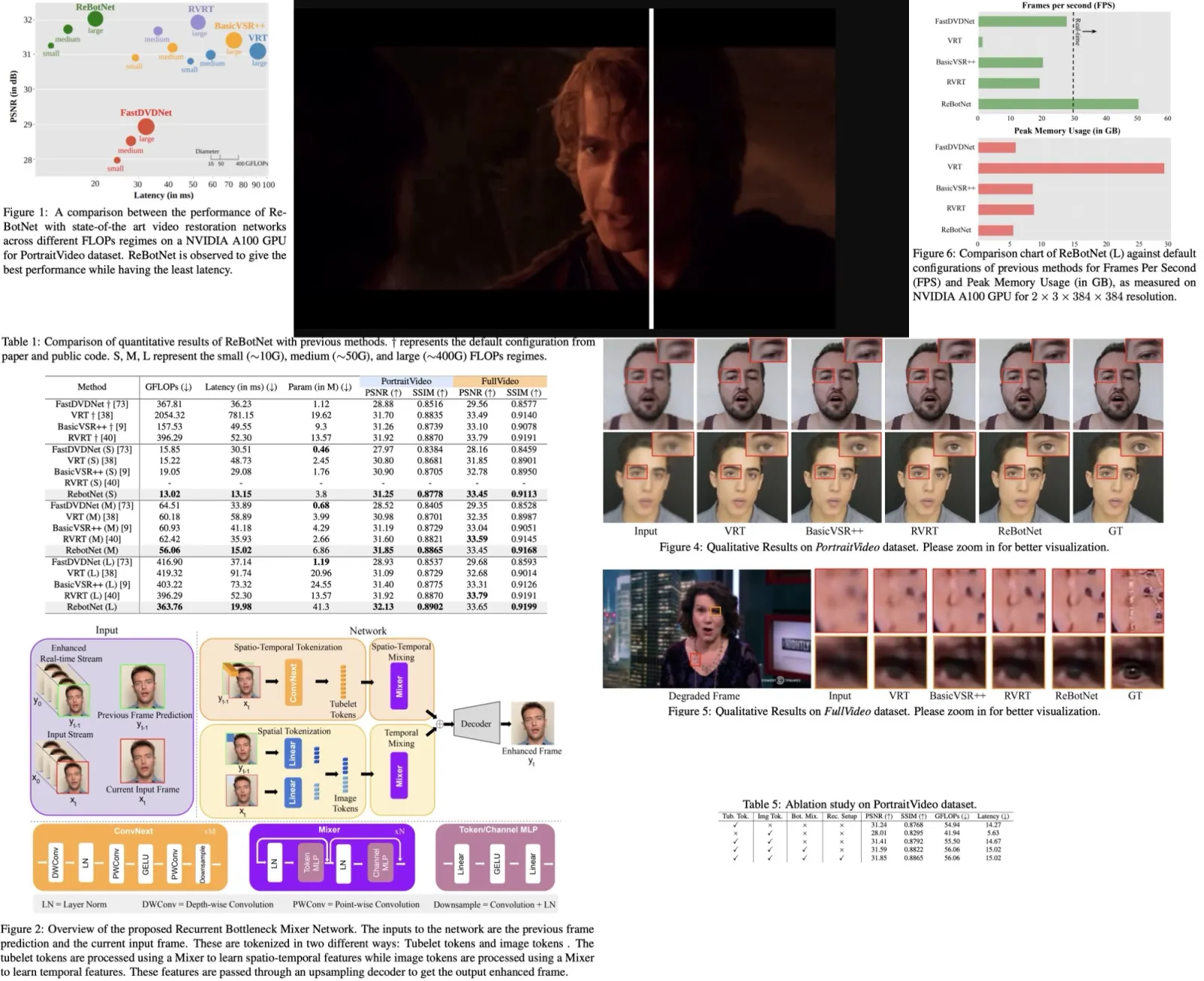
Loopy builds upon Stable Diffusion and its initialization weights. Unlike the original SD, which processes a single image, Loopy takes sequences representing video clips as an input. Additionally, the inputs include reference latents, audio embeddings, motion frames and timestamp. The denoising network uses a Dual U-Net architecture, adding a reference net module that incorporates reference image features and motion frames for more accurate temporal and spatial attention computations, enhancing the overall generation process.
Inter/Intra- Clip temporal layers design
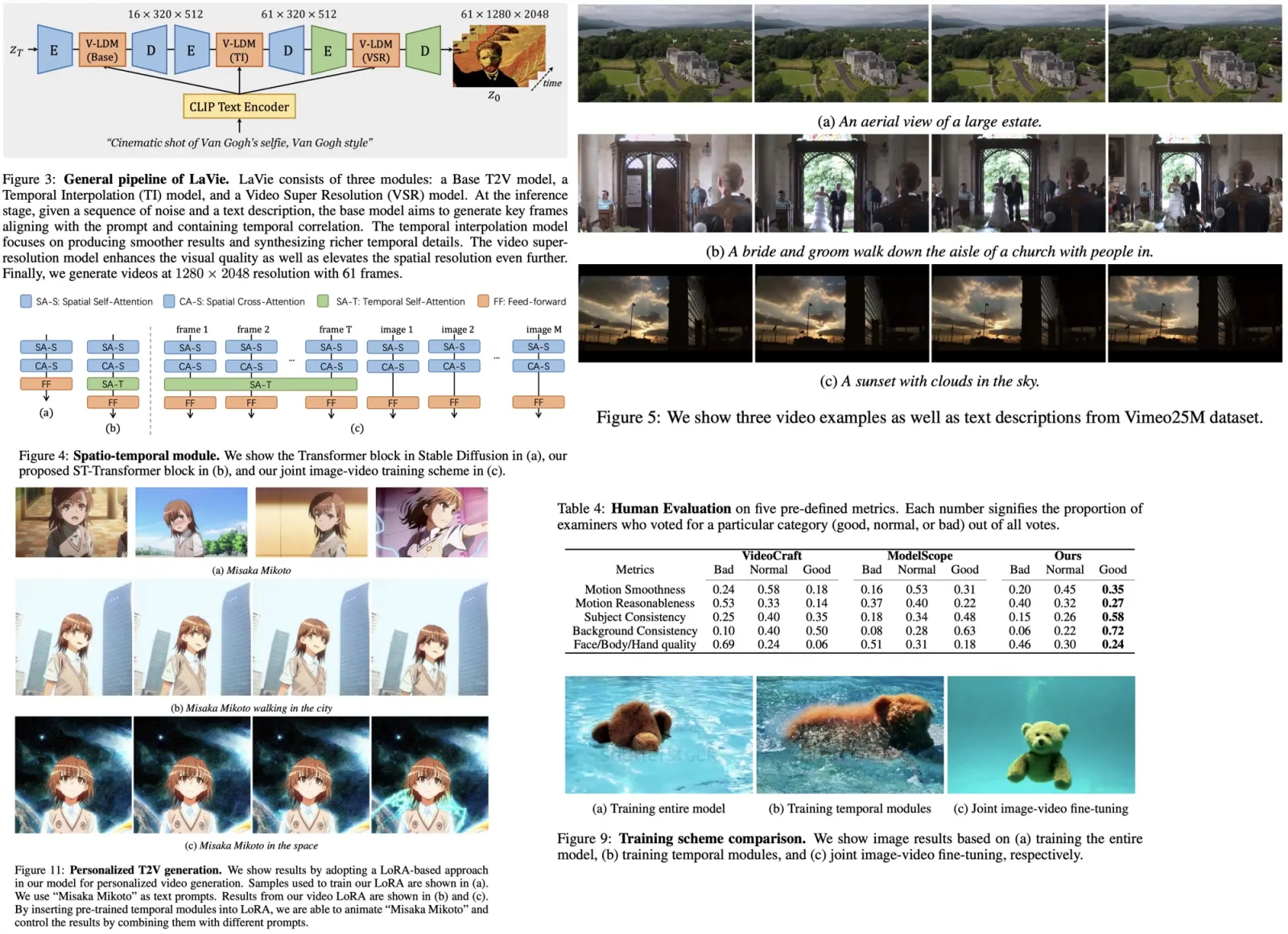
Unlike existing methods that use a single temporal layer for both motion frame latents and noisy latents, Loopy employs two separate temporal layers. The inter-clip temporal layer in Loopy processes motion frames from preceding clips using a reference network, extracting features and concatenating them with those from the denoising U-Net along the temporal dimension. Learnable temporal embeddings are added to distinguish between different latents, and self-attention is applied to these concatenated tokens. After that, the intra-clip temporal layer processes only the features from the noisy latents of the current clip.
To enhance motion modeling, a temporal segment module is introduced, which segments the motion frames into multiple parts and extracts representative frames to expand the temporal range covered by the inter-clip layer. This segmentation uses two hyperparameters: stride (number of frames per segment) and expand ratio (length of frames in each segment).
Audio Condition Module
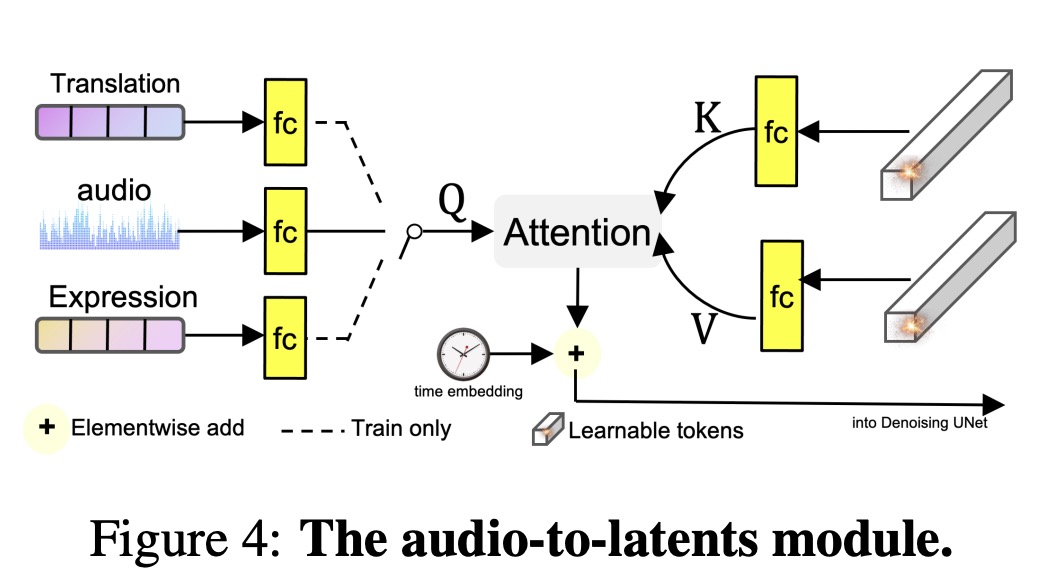
For the audio condition, Loopy uses wav2vec for audio feature extraction, obtaining multi-scale audio features by concatenating hidden states from each wav2vec layer. For each video frame, it combines audio features from two preceding and two succeeding frames to create a 5-frame audio embedding. In each residual block, cross-attention is applied using noisy latents as the query and audio embeddings as the key and value, producing an attended audio feature that is added to the noisy latents.
The Audio-to-Latents module is then introduced to map conditions, including audio and other facial movement-related features, into a shared motion latents space. The module uses learnable embeddings and attention computation to create new motion latents, which replace the input condition for further processing. During training, input conditions for this module are sampled from audio embeddings, landmarks, motion variance, and expression variance. During testing, only audio is used to generate motion latents. By transforming audio embeddings into motion latents, the model enhances control over portrait motion, enabling a more direct influence on the resulting movements.
Training strategies
Loopy uses condition masking and dropout strategies to improve learning and control during training. Various conditions, including the reference image (cref), audio features (caudio), preceding frame motion (cmf), and motion latents (cml), contain overlapping information. To address this, caudio and motion latents are randomly masked to all-zero features with a 10% probability. For cref and cmf, conflicting relationships are managed through dropout: cref has a 15% chance of being dropped, which also results in dropping motion frames to avoid artifacts. Additionally, motion frames have an independent 40% chance of being masked.
Loopy’s training follows a two-stage process. In the first stage, the model is trained without temporal layers and the audio condition module, focusing on pose variations at the image level. In the second stage, initialized with parameters from the first stage, the inter-/intra-clip temporal layers and the audio condition module are added for full training.

During inference, Loopy performs class-free guidance using multiple conditions. Three inference runs are executed with variations in condition masking to control the final output’s adherence to the reference image and alignment with audio.
Experiments
The model is trained on 24 Nvidia A100 GPUs.
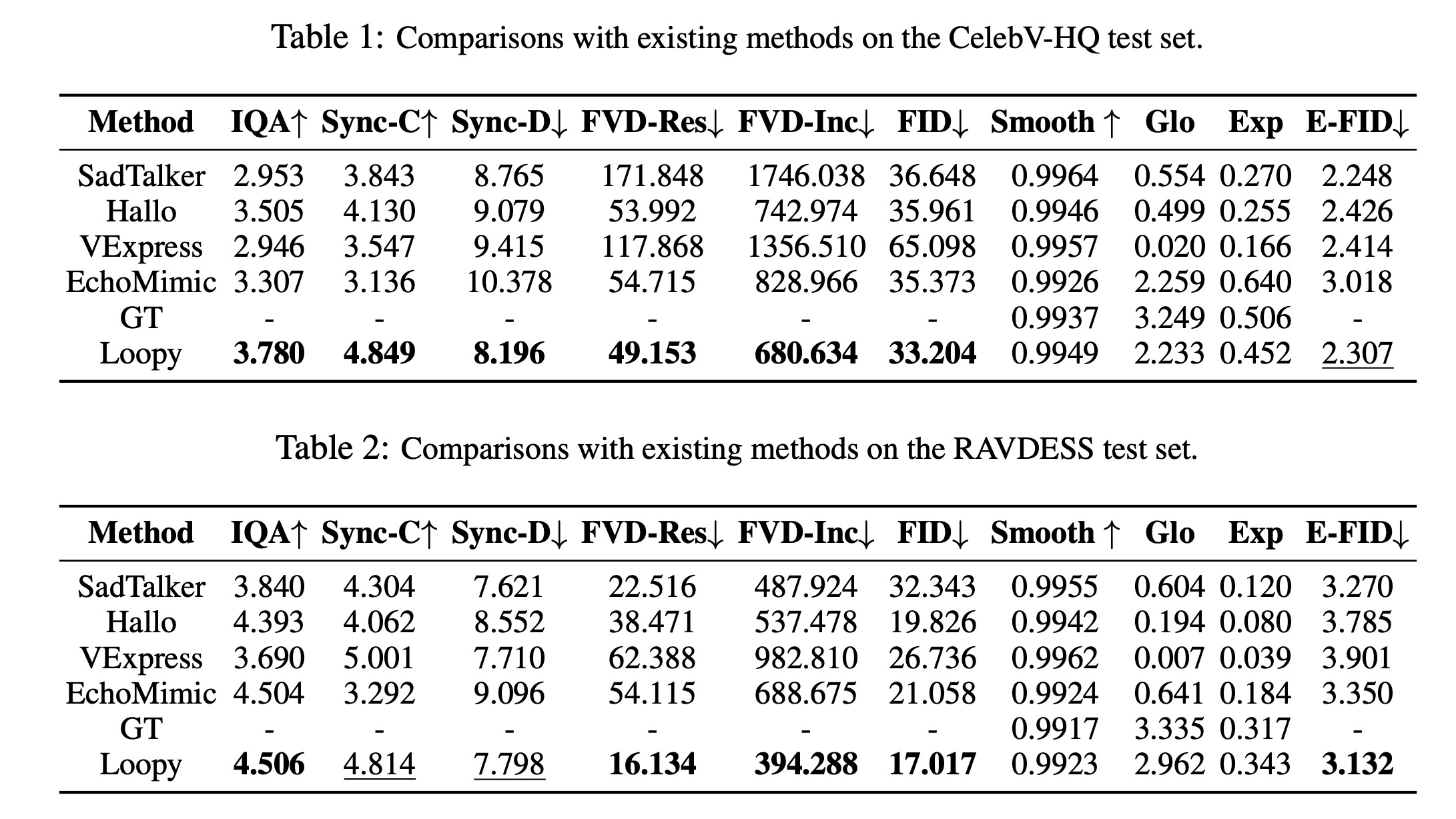
On the CelebV-HQ dataset, which includes videos with diverse settings, poses, and speaking styles, Loopy significantly outperforms other methods in most metrics. While its motion-related metrics aren’t always the best, they closely match the ground truth in smoothness and dynamic expression. Loopy also excels in video synthesis quality and lip-sync accuracy.
On the RAVDESS dataset, which tests emotional expression in high-definition talking scenes, Loopy outperforms other methods in the E-FID metric and is closer to the ground truth in motion dynamics. Though its lip-sync accuracy is slightly behind VExpress, Loopy captures more dynamic motion, unlike VExpress’s more static results.
In open-set scenarios involving various input styles (real people, anime, crafts) and audio types (speech, singing, rap, emotional audio), Loopy consistently outperforms other methods, showcasing its robustness across different contexts.
Ablation studies
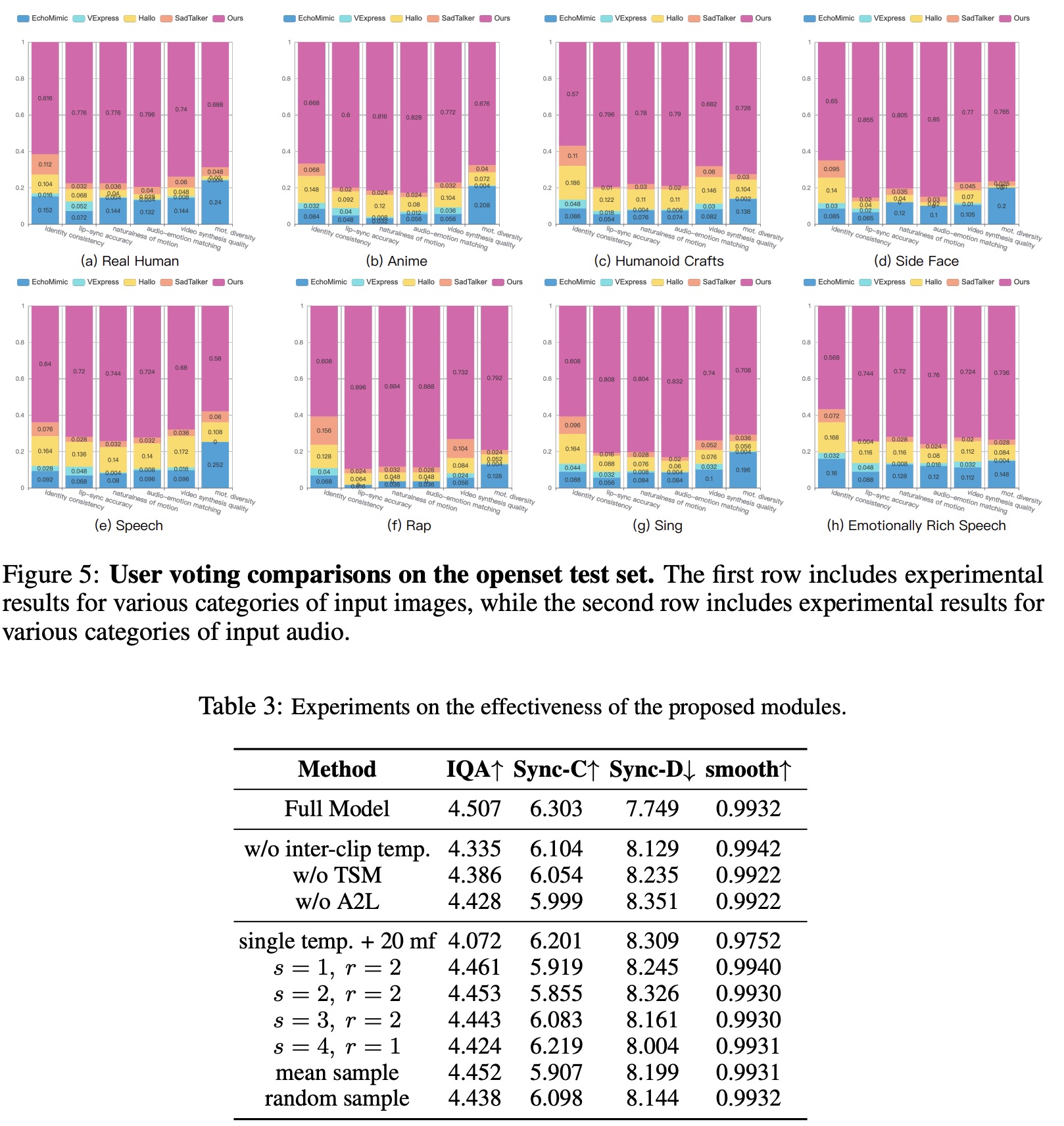
The authors analyzed the impact of Loopy’s two key components: the inter/intra-clip temporal layer and the audio-to-latents module. For the inter/intra-clip temporal layer, experiments showed that removing the dual temporal layer design and using a single layer, or removing the temporal segment module, degraded performance. The dual temporal layer improves temporal stability and image quality, while the temporal segment module enables the model to capture long-term motion dependencies, enhancing expressiveness and stability.
For the audio-to-latents module, its removal reduced overall visual and motion quality because the module incorporates spatial conditions during training, providing clearer motion guidance and aiding model convergence.
The authors also investigated the impact of long-term temporal dependency. Extending motion frame length to 20 with a single temporal layer enhanced motion dynamics but degraded image quality. However, in the full model, adding inter/intra-clip temporal layers improved results. Increasing stride allowed better cross-clip modeling, while a larger expand ration provided broader temporal coverage, leading to better performance. The uniform sampling strategy for motion frames in the temporal segment module proved most effective, as it offers stable interval information, aiding the learning of long-term motion.