Paper Review: Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Monarch Mixer (M2) is a new architecture designed to scale sub-quadratically with the help of Monarch matrices in both sequence length and model dimension, addressing the quadratic scaling challenges of Transformer models.
In BERT-style modeling, M2 achieves comparable results to BERT with fewer parameters and 9.1x higher throughput at sequence length 4k. On ImageNet, M2 surpasses ViT-b’s accuracy with half the parameters. For GPT-style modeling, a unique perspective on Monarch matrices based on multivariate polynomial evaluation and interpolation is introduced to maintain causality without a quadratic bottleneck, allowing M2 to match GPT-style Transformer performance, suggesting high-quality results can be achieved without attention or MLPs.
Monarch Mixer
Monarch Matrices
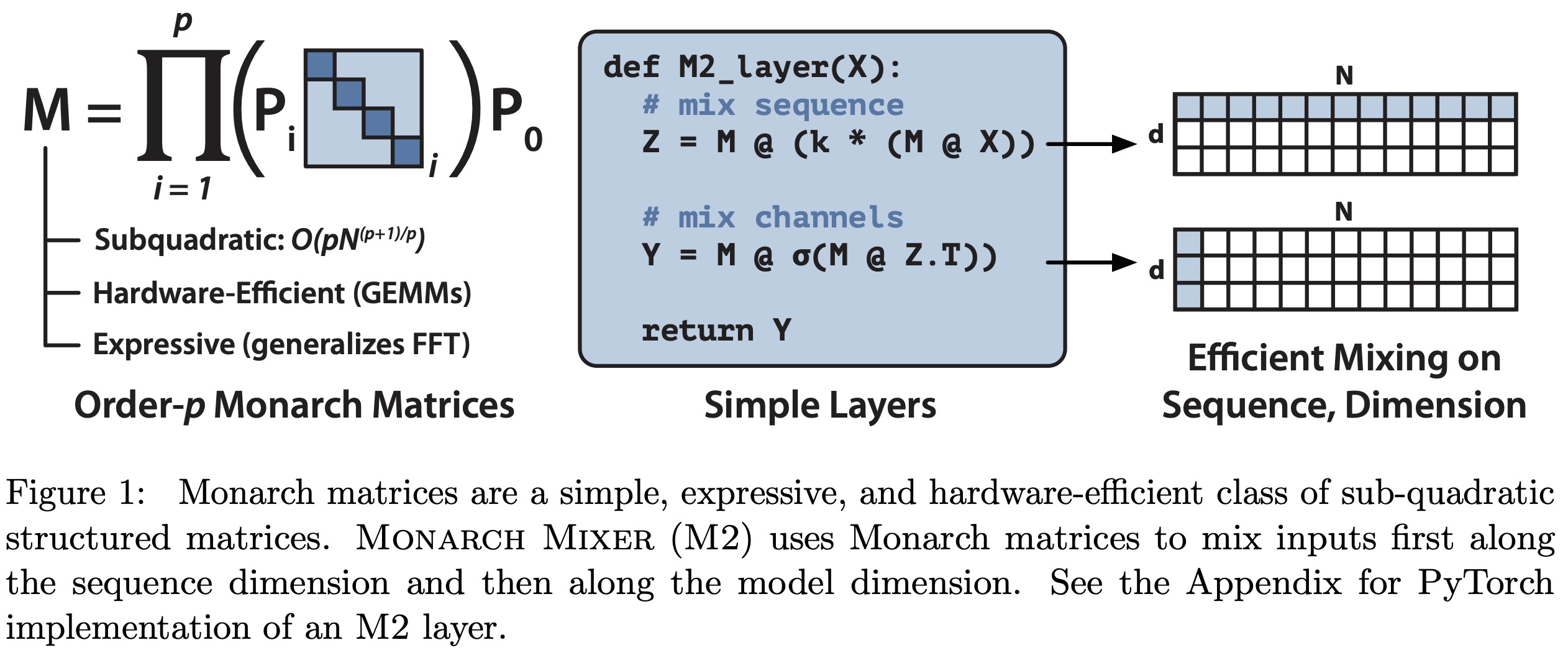
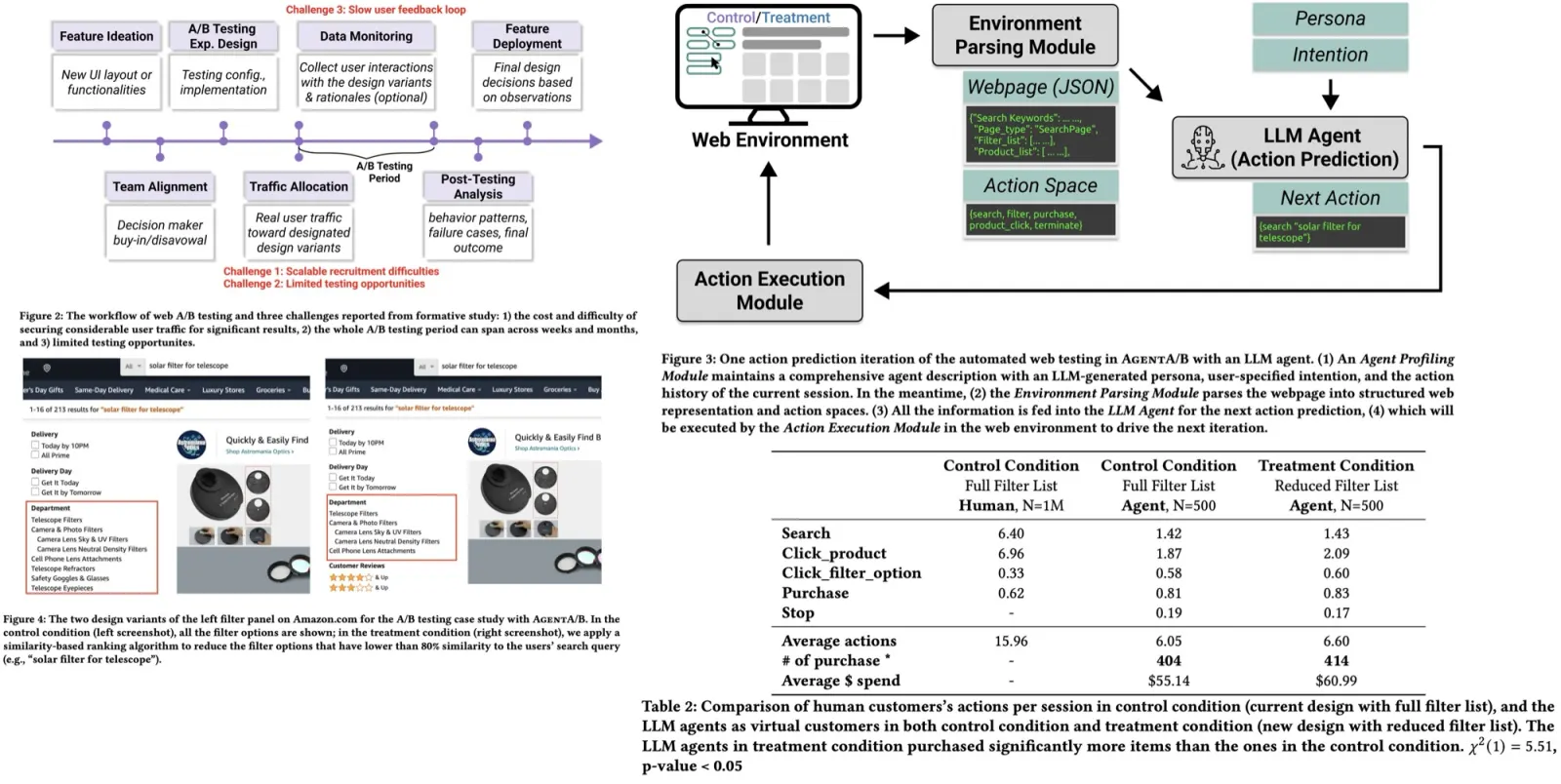
Monarch matrices are structured matrices that are both hardware-efficient and expressive, capable of representing various linear transforms, including convolutions, Toeplitz-like transforms, low-displacement rank transforms, and orthogonal polynomials. While direct GPU implementation of these transforms can be inefficient, using Monarch decompositions interleaves matrix multiplications with tensor permutations, enhancing efficiency.

The definition of a Monarch matrix involves permutations and block-diagonal matrices.
Monarch Mixer Architecture
Monarch Mixer uses Monarch matrices and elementwise operations to create sub-quadratic architectures. In this approach, each layer is seen as a series of mixing operations across both the sequence and model dimension axes. The input to each layer is a sequence of embeddings, and it outputs another sequence, with parameters denoting sequence length and model dimension.
Using order-2 Monarch matrices, the Mixer can construct expressive architectures, such as convolutional blocks with sparse MLPs. These are constructed by mixing along both the sequence and embedding axes. If the first matrix is set to the Discrete Fourier Transform and the second matrix to its inverse, the operations correspond to convolutions in frequency space. Additionally, the Mixer can mimic an MLP where dense matrices are substituted with Monarch matrices.
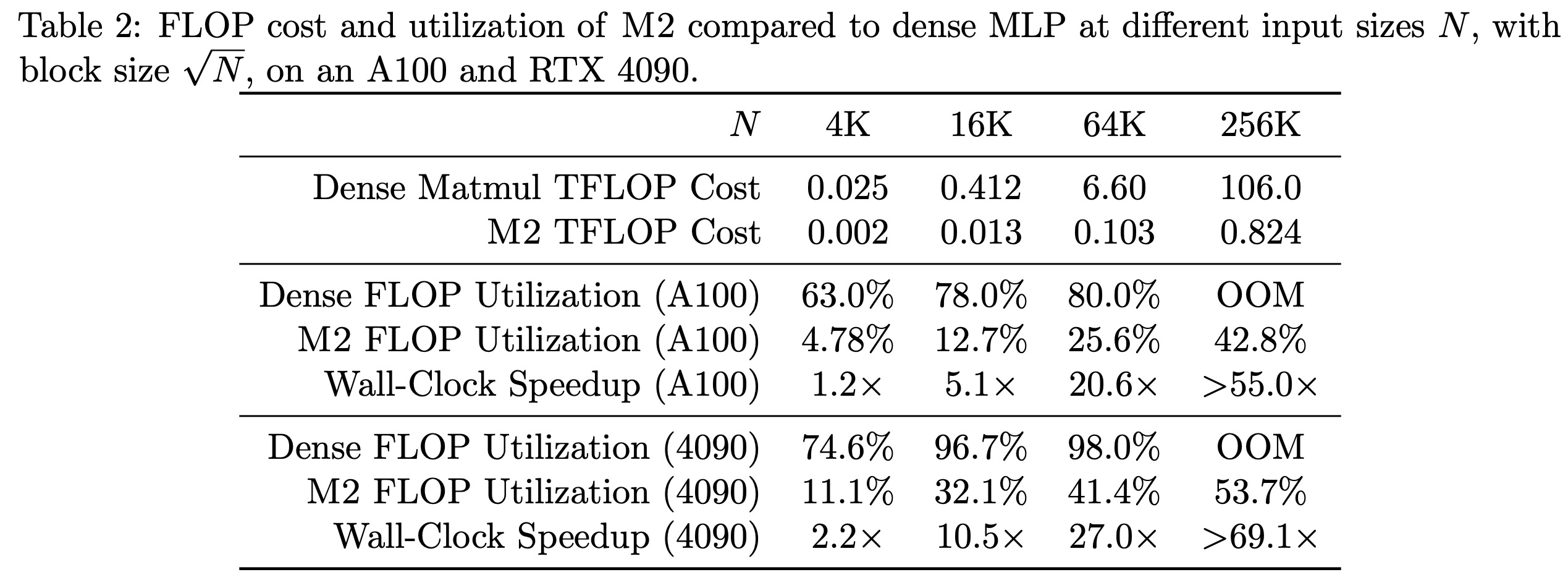
Experiments
Non-Causal Language Modeling
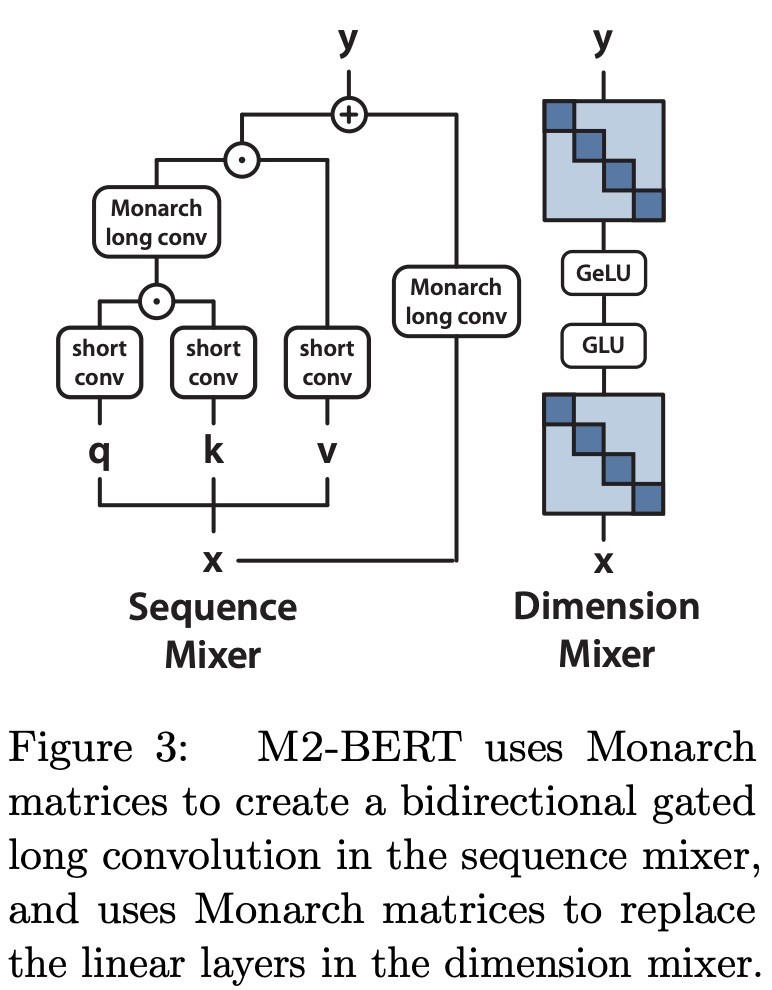
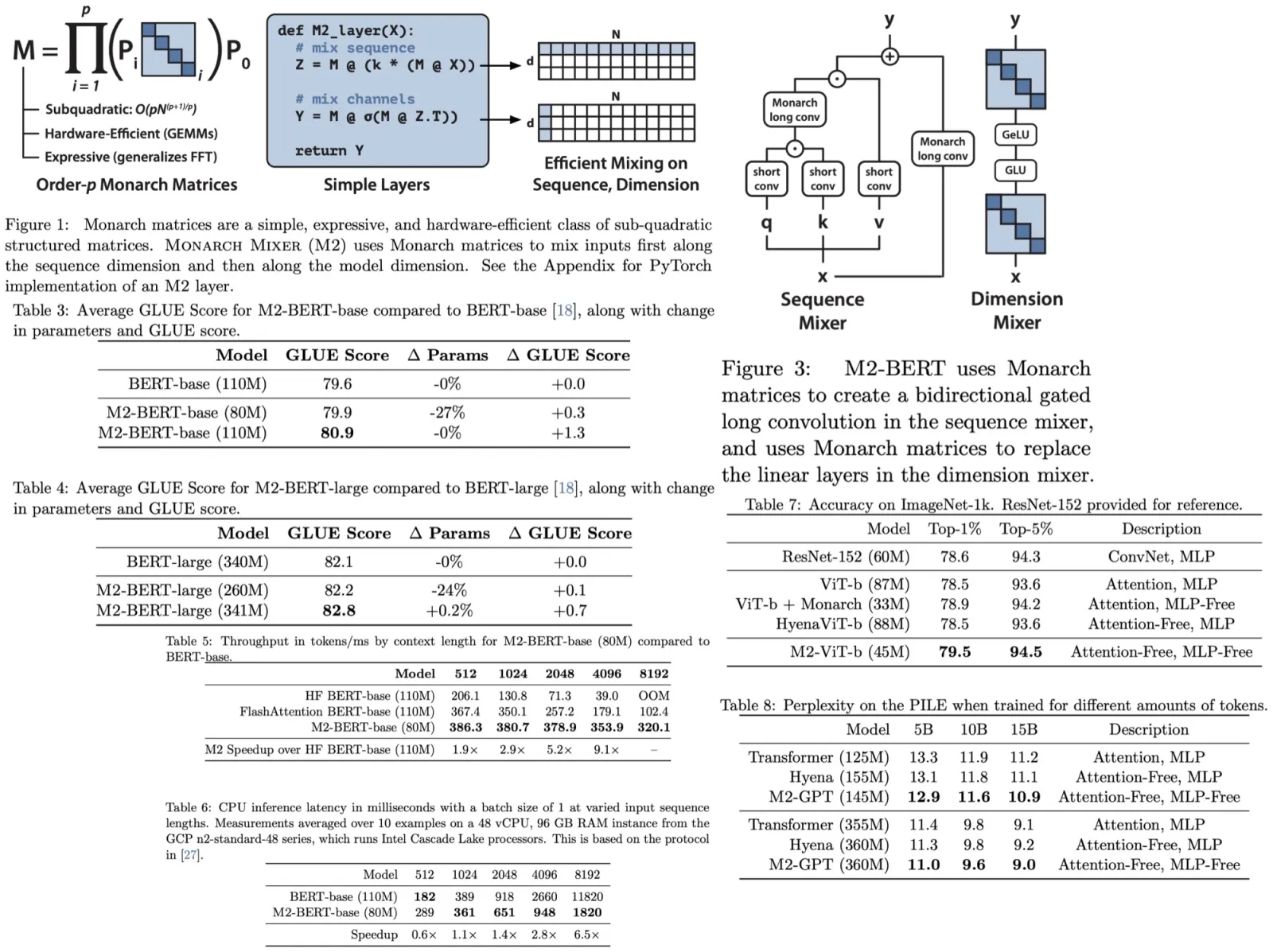
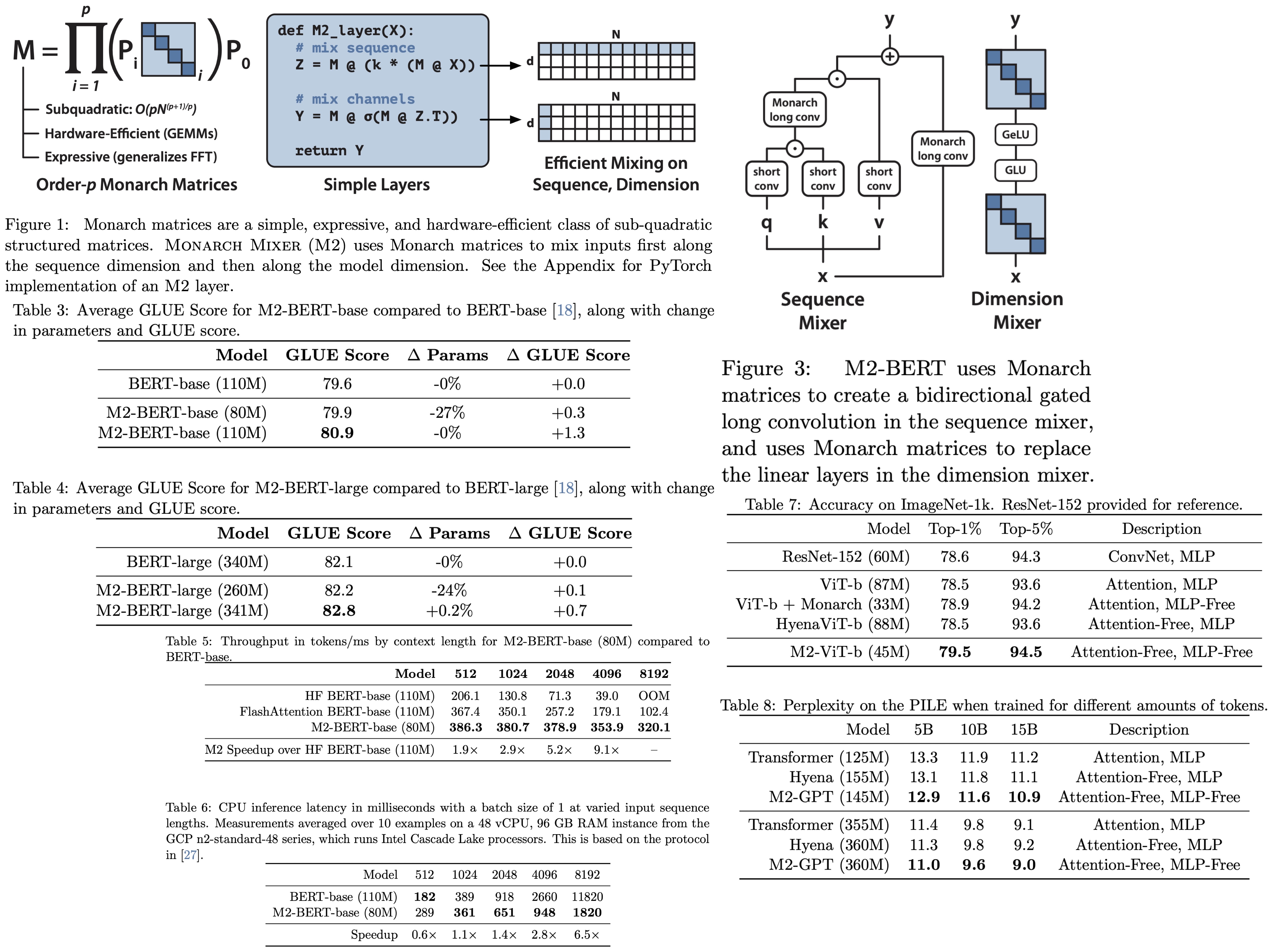
M2-BERT is designed to be a direct substitute for BERT-style language models. M2-BERT is trained using masked language modeling on the C4 dataset with the bert-base-uncased tokenizer. The core idea is to start with a traditional Transformer structure and replace attention mechanisms and MLPs with M2 layers. Within the sequence mixer, attention is replaced by bidirectional gated convolutions and a residual convolution. These convolutions are achieved by setting Monarch matrices to DFT and inverse DFT forms. Additionally, short depthwise convolutions are added post-projections. In the dimension mixer, dense matrices in MLPs are substituted with learned block-diagonal matrices. Models of M2-BERT, both base and large versions, are pretrained, with sizes mirroring the standard BERT-base and BERT-large models.
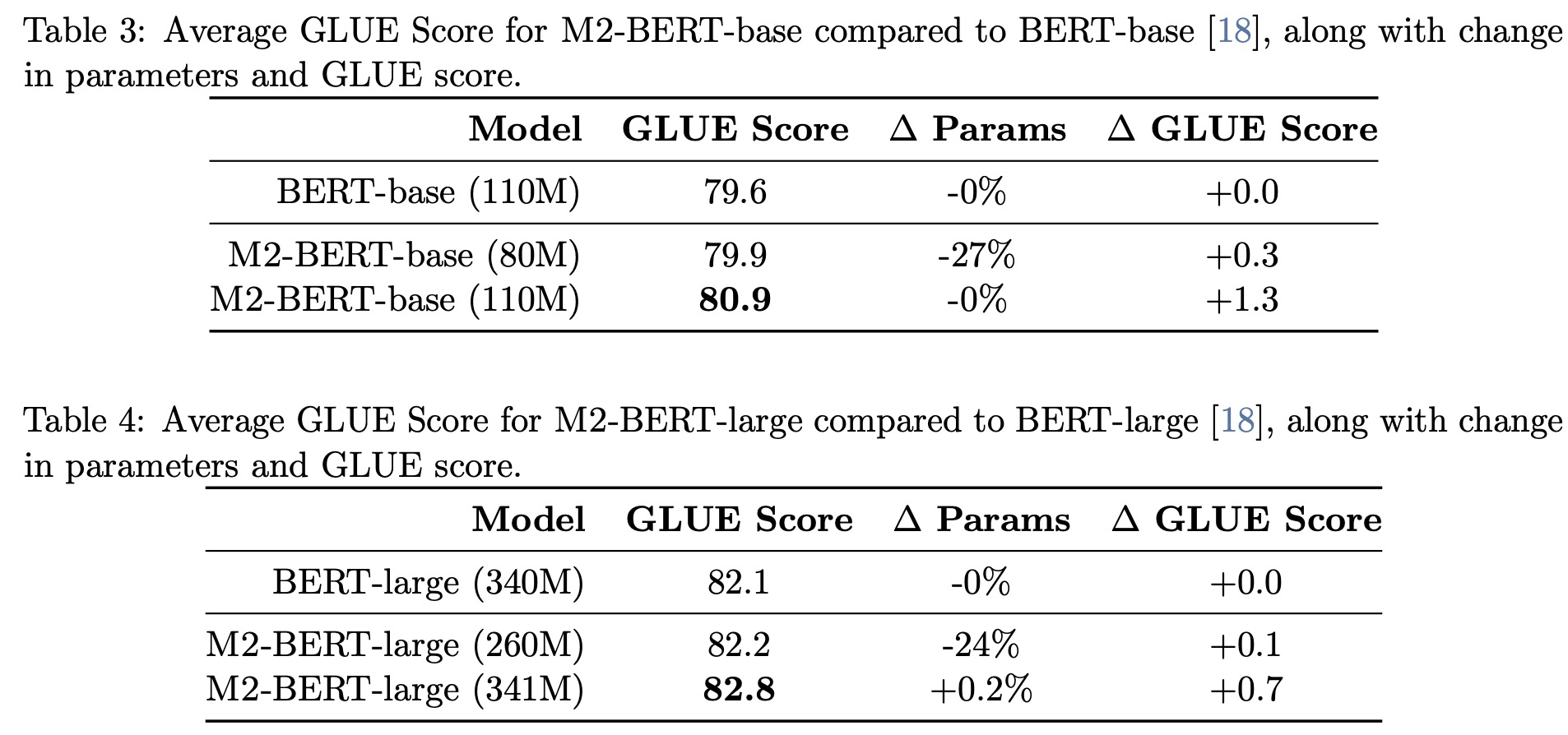
- Downstream GLUE Scores: M2-BERT-base matches BERT-base’s GLUE score quality using 27% fewer parameters. When parameter-matched, it outperforms BERT-base by 1.3 points. M2-BERT-large equals BERT-large’s performance with 24% fewer parameters and surpasses it by 0.7 points when parameters are matched.
- GPU Throughput by Sequence Length: M2-BERT-base showcased higher throughput than even the highly-optimized BERT versions. It achieved up to 9.1× faster throughput than a regular HuggingFace BERT implementation at a sequence length of 4K.
- CPU Inference Latency: Starting from sequences of length 1K, M2-BERT-base began to show a speed advantage over BERT-base, reaching up to 6.5× faster at a sequence length of 8K. The potential for even better CPU performance exists with further optimization and IO-aware principles.
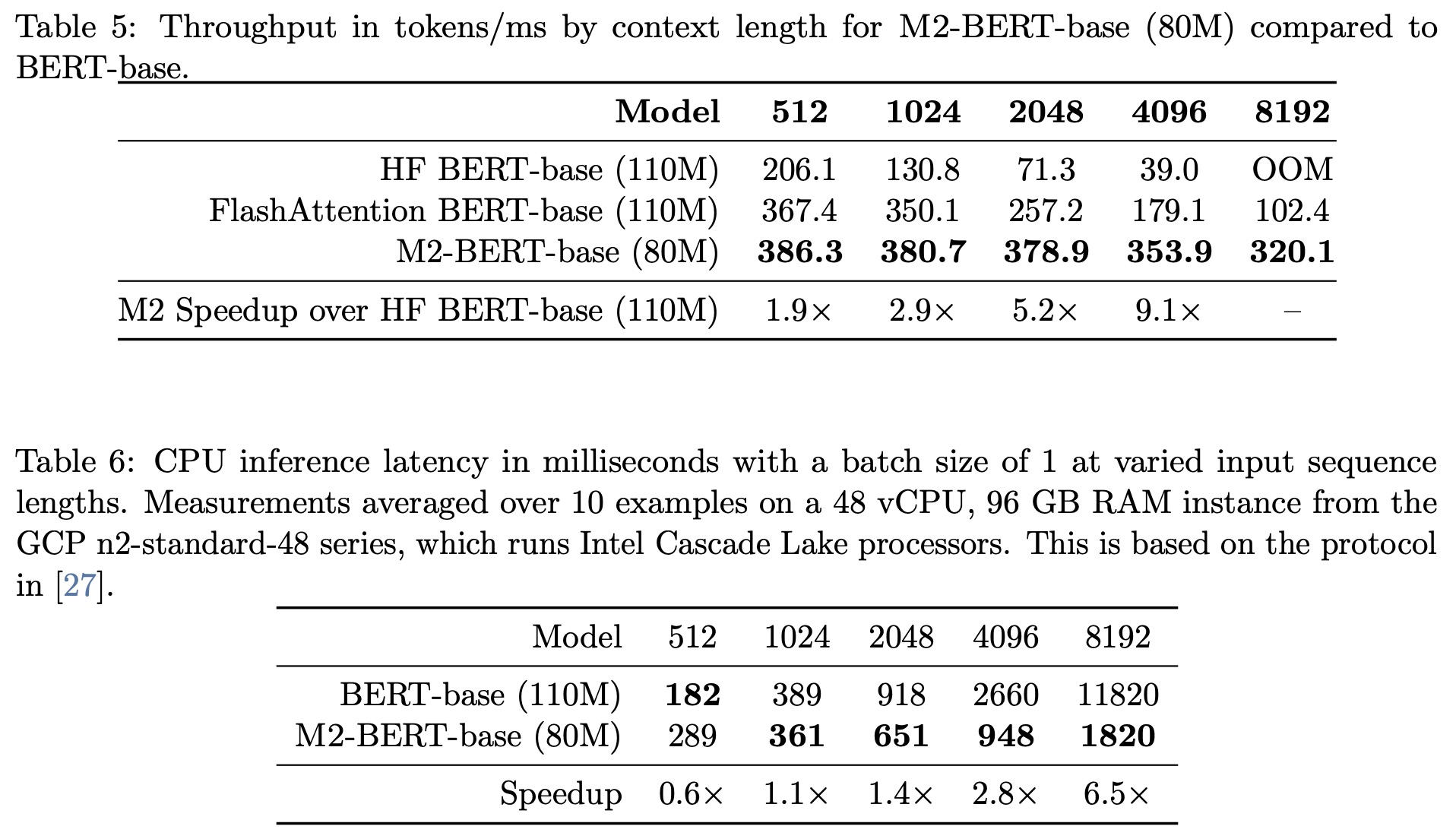
Image Classification and Causal Language Modeling
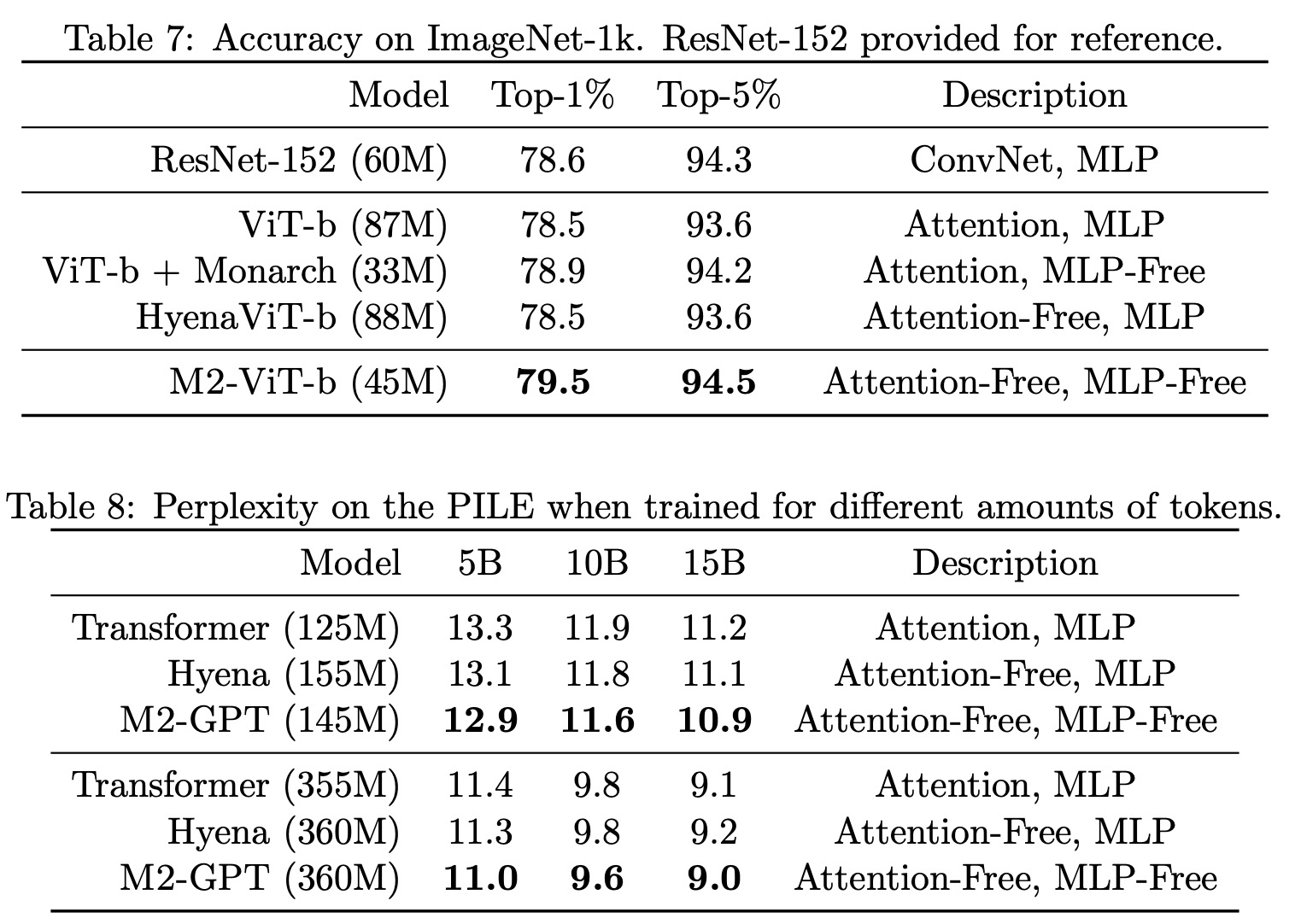
- M2-ViT is based on HyenaViT-b but replaces long convolutions with the M2 operator, with Monarch matrices set to DFT and inverse DFT forms. The MLP blocks in HyenaViT-b are replaced with block-diagonal matrices, similar to the approach in M2-BERT. Monarch Mixer outperforms other models, including ViT-b and HyenaViT-b, on ImageNet-1k, using only half the parameters of the original ViT-s model.
- The sequence mixer in M2-GPT incorporates a convolutional filter from Hyena and shares parameters across multiple heads from H3. The architecture replaces the FFT with the causal parameterization of the M2 operator and entirely removes MLP layers, making it both attention- and MLP-free. M2-GPT, despite lacking attention and MLP components, surpasses both Transformers and Hyena in terms of perplexity during pretraining. This suggests the potential of alternative architectures to Transformers in causal language modeling.