Paper Review: The effectiveness of MAE pre-pretraining for billion-scale pretraining
This paper challenges the conventional pretrain-then-finetune approach widely used in visual recognition tasks in computer vision. The authors propose an extra pre-pretraining phase that employs a self-supervised technique, MAE (Masked Autoencoder), to initialize the model. Contrary to the previous belief that MAE only scales with model size, they discover it also scales with the size of the training dataset. Hence, their MAE-based pre-pretraining strategy can be utilized for training foundation models as it scales with both the model and data size. This approach consistently enhances model convergence and downstream transfer performance across various scales of models and datasets.
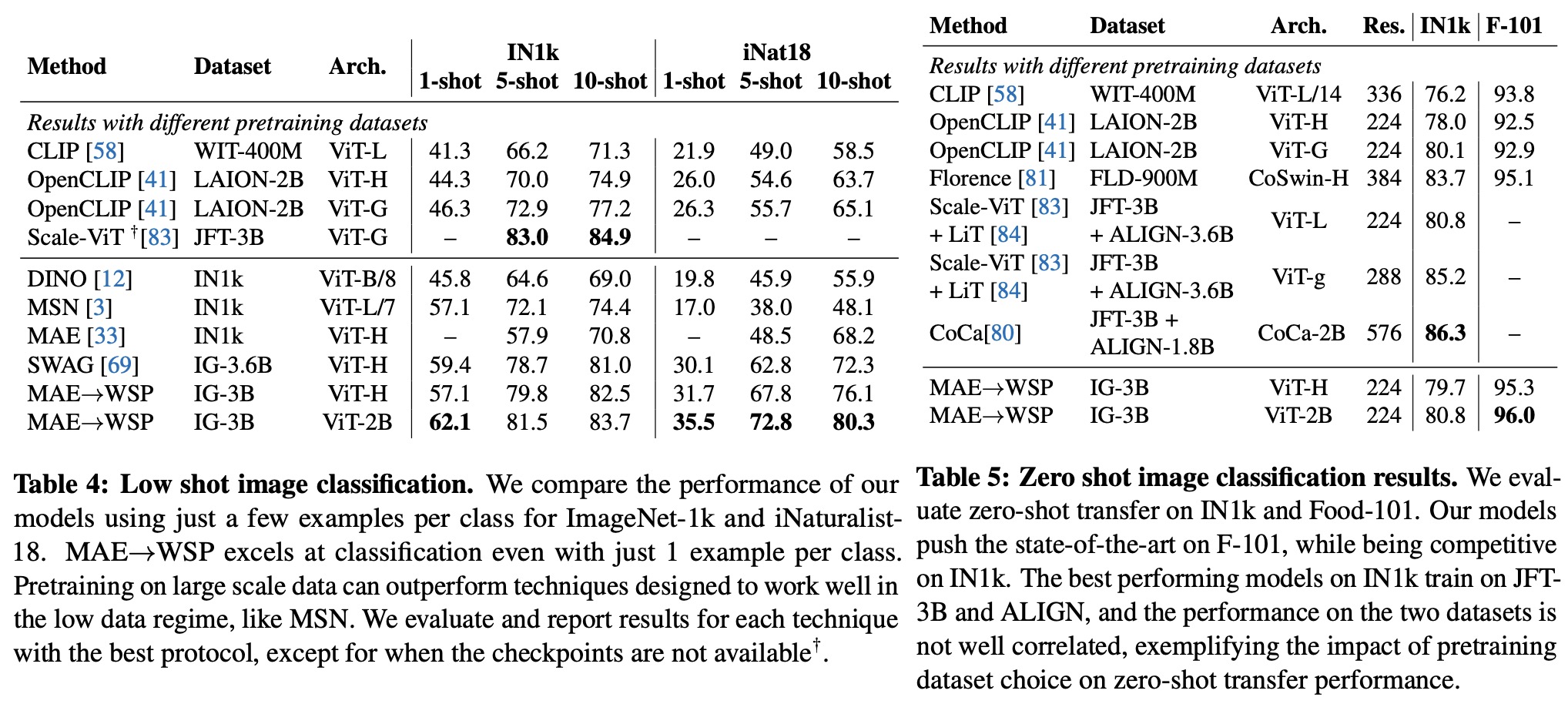
The authors assessed the efficacy of their pre-pretraining method on 10 distinct visual recognition tasks, including image classification, video recognition, object detection, and low-shot and zero-shot recognition. Their largest model sets new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Their research underscores the significant role model initialization plays, even in web-scale pretraining involving billions of images.
Setup
The researchers conducted their experiments using the Vision Transformer (ViT) architecture as the visual encoder. This architecture combines minimal vision-specific inductive biases with a standard transformer framework and has proven useful in various visual and multimodal recognition tasks. They trained ViT models of different scales, from ViT-B (86M parameters) to ViT-6.5B (6.5B parameters).
Their pre-pretraining technique, Masked Autoencoder (MAE), learns visual representations from image datasets without using labels. In this method, 75% of an image is randomly masked, and the model is trained to reconstruct the masked input image by minimizing pixel reconstruction error. With the ViT architecture, the MAE only needs to process the 25% unmasked image patches, making it highly efficient.
The researchers also used weakly-supervised pretraining (WSP), which utilizes images with associated ‘weak’ supervision, typically text information. This information is converted into a discrete set of labels, and then a multi-label classification loss is used to train models.
The researchers’ approach of MAE→WSP first pretrains the encoder using the MAE self-supervised method with images only. This pre-pretraining stage is computationally efficient due to MAE’s masking technique. Following this, the encoder is pretrained using both the image and associated weak supervision, outperforming the use of either strategy in isolation.
Experiments
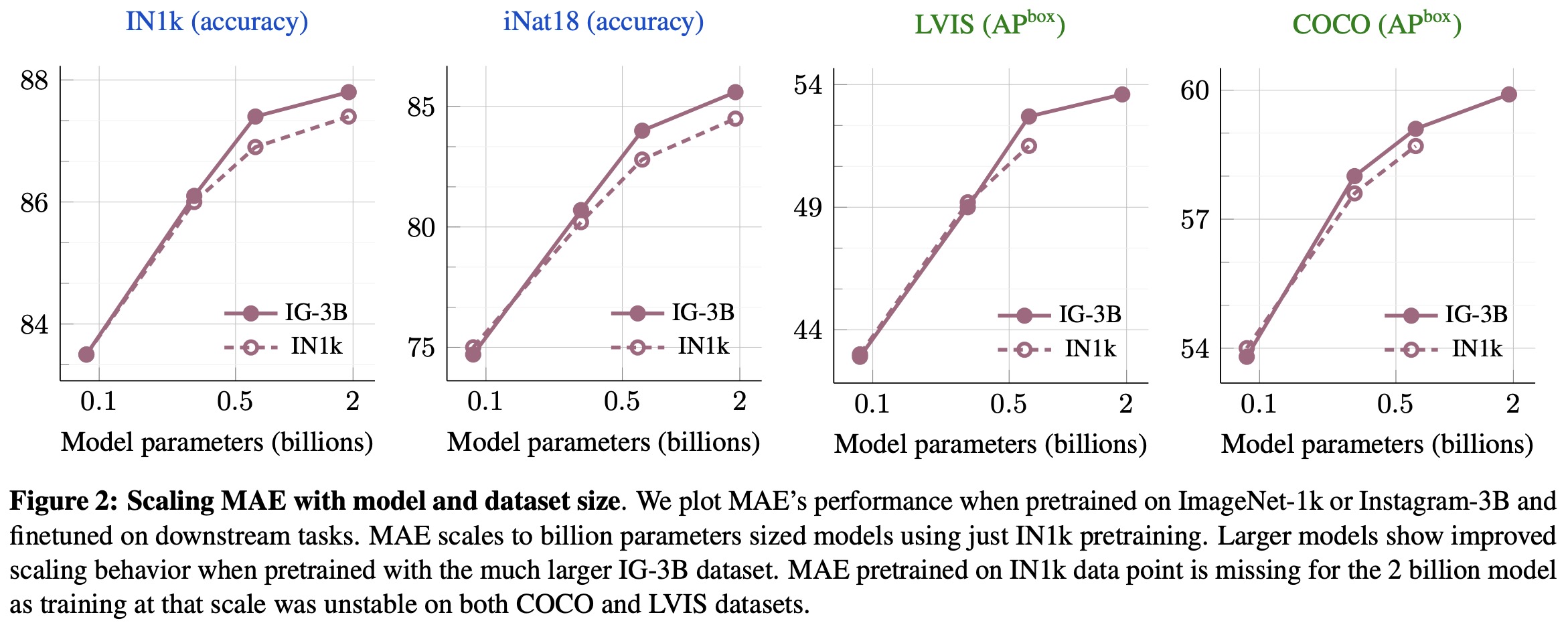
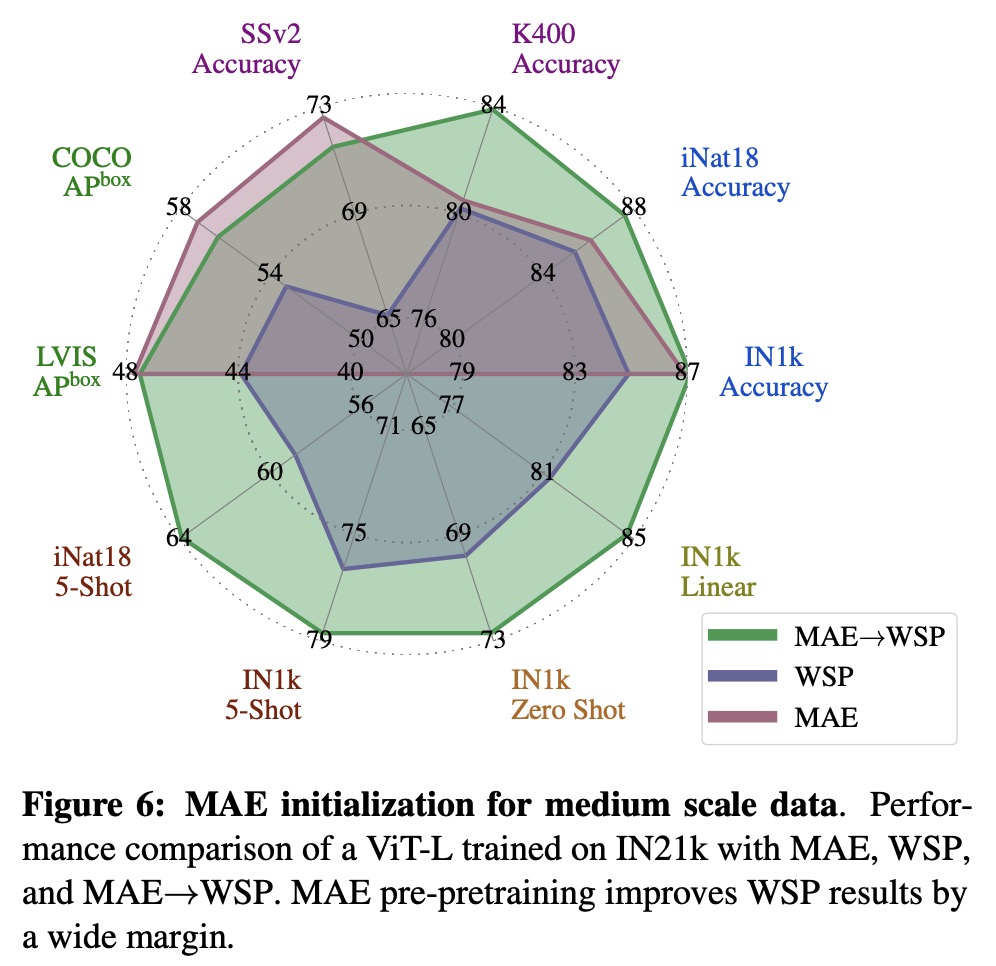
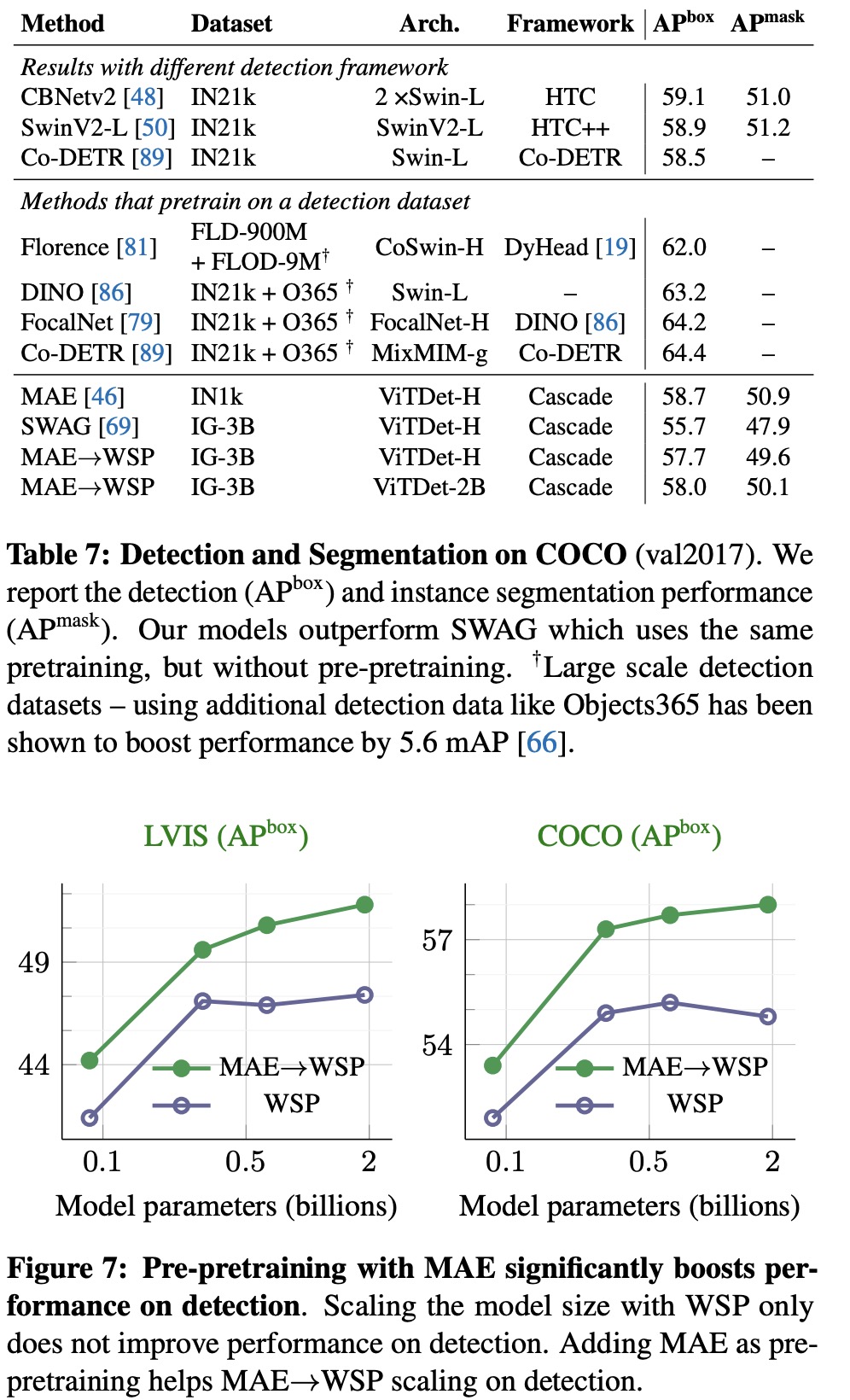
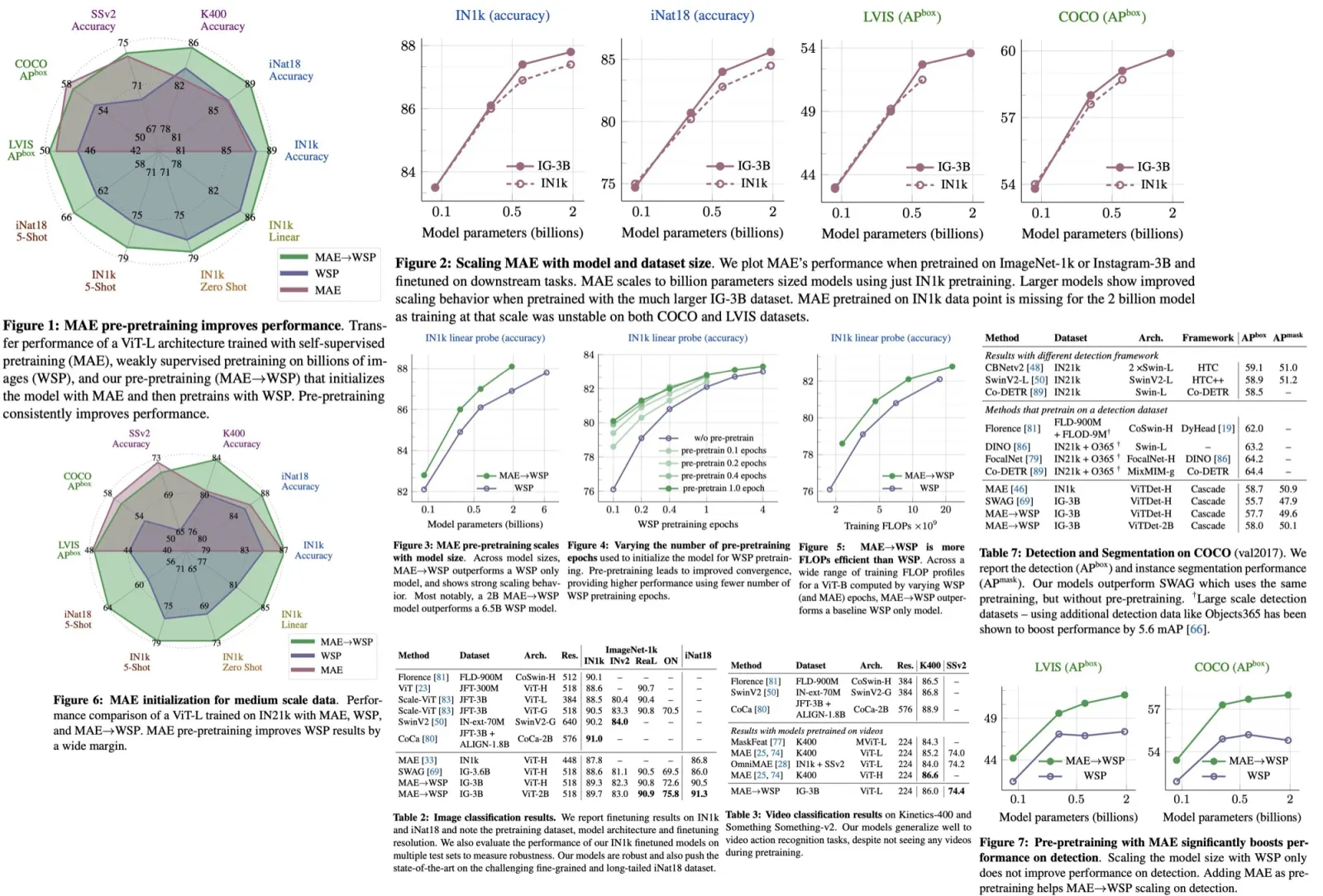
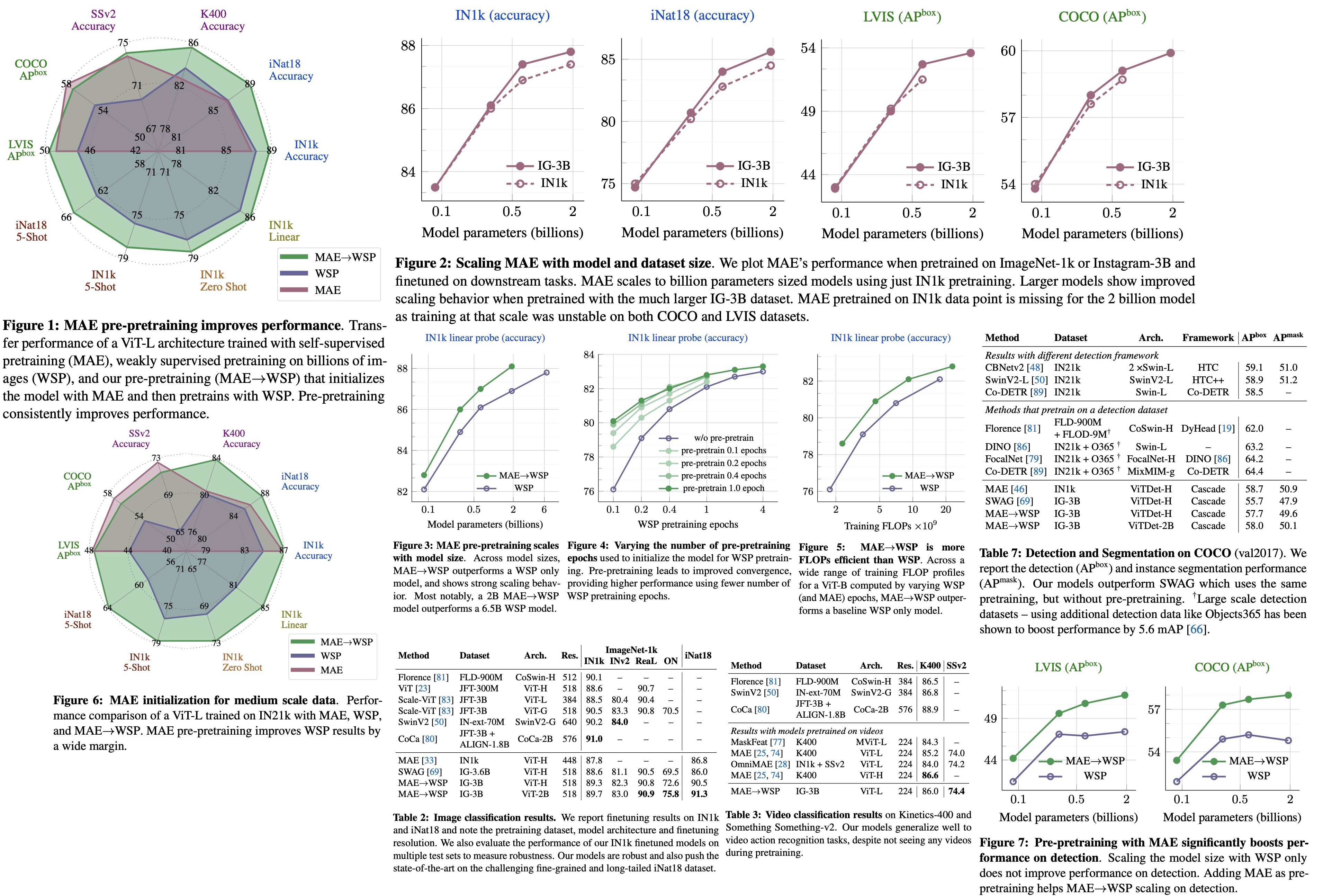
MAE performs strongly on tasks like object detection and full finetuned image classification, but struggles with tasks where the model is not finetuned, such as linear classifiers, zero-shot, or low-shot classification - tasks where WSP performs better. However, the combined MAE→WSP approach outperforms either of the two methods on most evaluations, including image classification, video recognition, zero-shot evaluation, and object detection, among others.
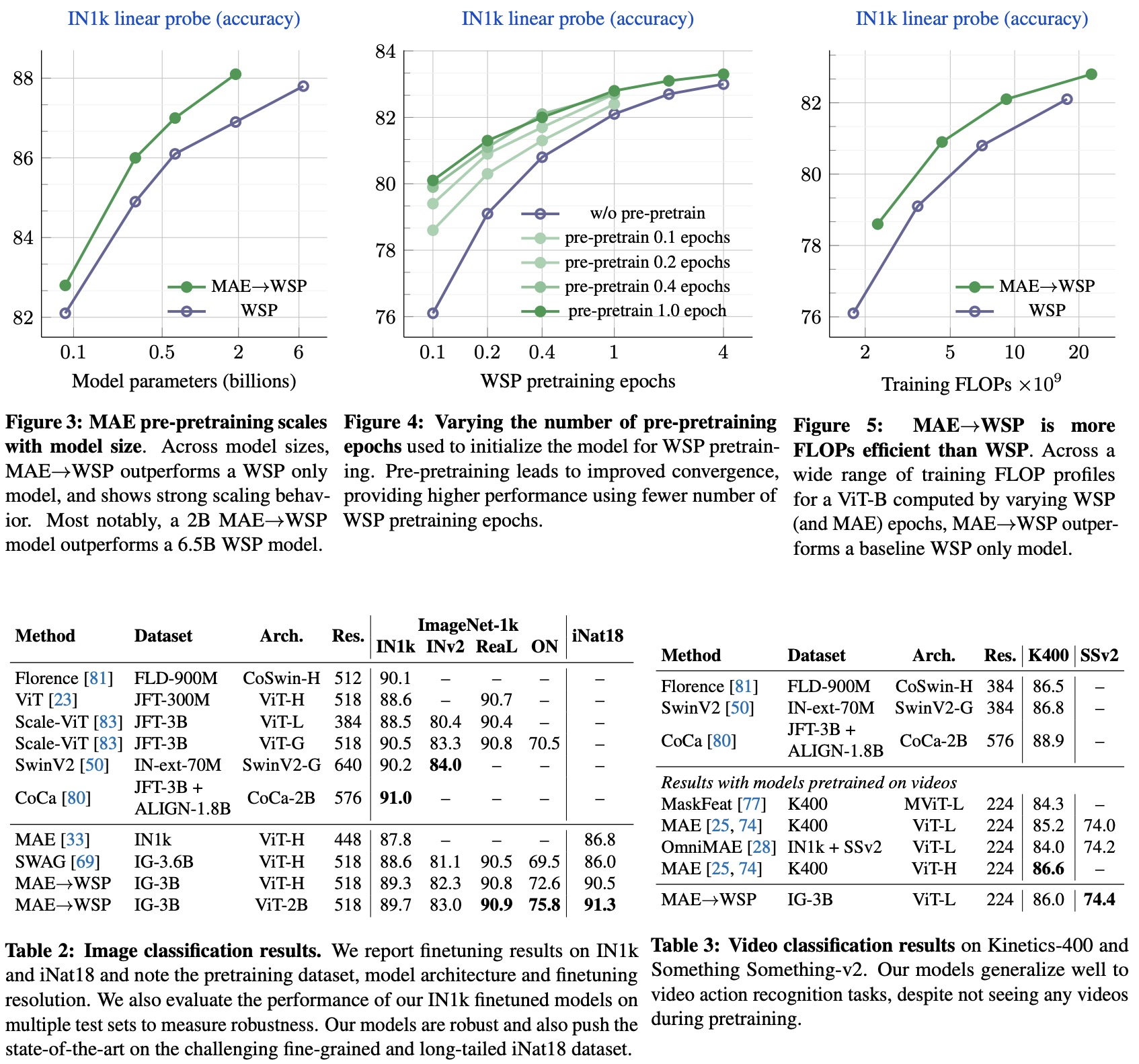
- An ablation study examining the effects of pre-pretraining versus random initialization for different model sizes shows that MAE pre-pretraining consistently outperforms the WSP baseline across all model sizes, from 86M to 2B parameters. The performance improvement increases for larger model sizes, indicating the promise of pre-pretraining as it scales with model sizes. Notably, a 2B MAE→WSP model outperforms a larger 6.5B WSP model.
- Pre-pretraining improves results over standard pretraining and yields significant gains with fewer WSP pretraining epochs. Even a small amount of pre-pretraining for 0.1 epochs shows improvement. The gains reach saturation at 1 epoch of pre-pretraining and remain stable even after 4 epochs of WSP, demonstrating the value of pre-pretraining at scale.
- When comparing training FLOPs, MAE→WSP achieves better transfer performance compared to WSP and is up to 2× more efficient. This training efficiency holds over a large 10× compute window.