Paper Review: Meta-Transformer: A Unified Framework for Multimodal Learning

The Meta-Transformer is a new framework for multimodal learning designed to process and relate information from multiple modalities like natural language, images, point clouds, audio, video, time series, and tabular data, despite the inherent gaps among them. It utilizes a frozen encoder to extract high-level semantic features from input data transformed into a shared token space, requiring no paired multimodal training data. The framework consists of a unified data tokenizer, a modality-shared encoder, and task-specific heads for various downstream tasks. It represents the first effort to perform unified learning across 12 different modalities with unpaired data. Experiments show that it can handle a wide range of tasks from fundamental perception to practical application and data mining.
Meta-Transformer
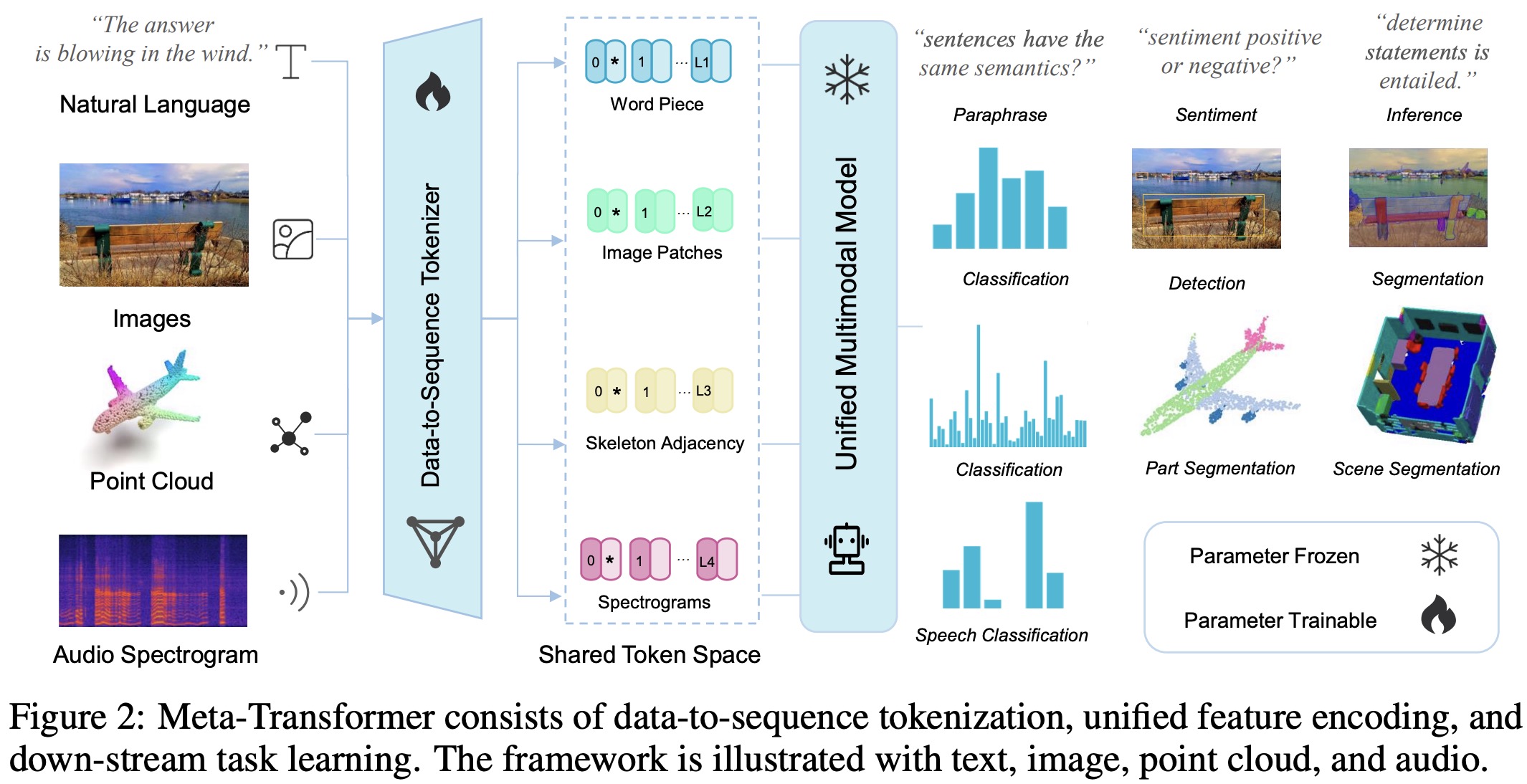
Data-to-Sequence Tokenization
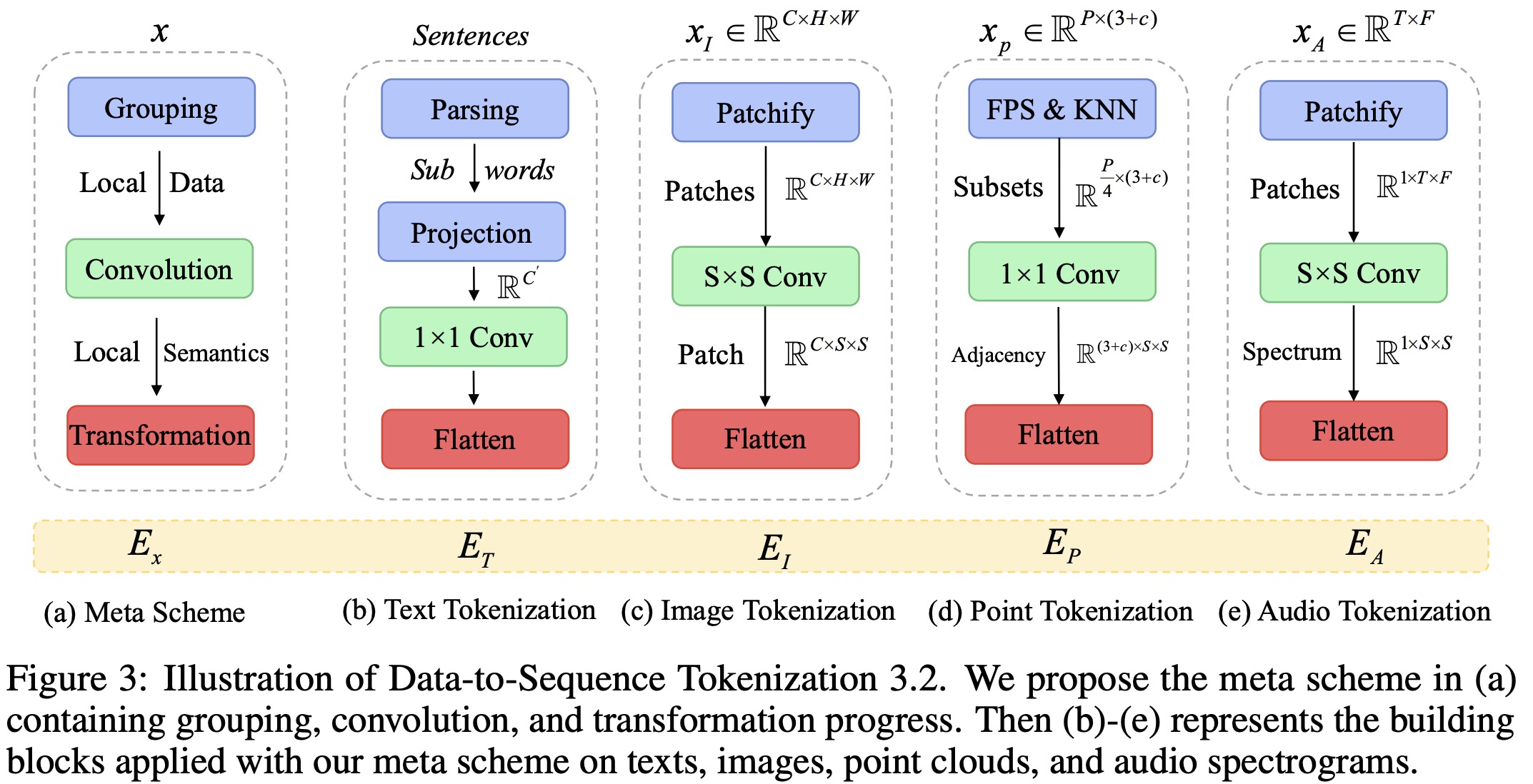
The researchers have proposed a meta-tokenization scheme that converts data from different modalities (like text, images, point clouds, and audio) into token embeddings within a shared space.
- For natural language, they used WordPiece embeddings with a 30,000 token vocabulary, which segments words into subwords and transforms each input text into a set of token embeddings.
- For images, they reshaped the image into a sequence of flattened 2D patches, and then utilized a projection layer to project the embedding dimension. This operation is also used for infrared images, while linear projection is used for hyperspectral images. They replace 2D convolution layers with 3D convolution for video recognition.
- For point clouds, they convert them from raw input space to token embedding space by using Farthest Point Sampling (FPS) operation to sample a representative skeleton of original point clouds with a fixed sampling ratio. They then use K-Nearest Neighbor (KNN) to group neighboring points and construct an adjacency matrix to capture structural information about 3D objects and scenes.
- For audio spectrograms, the audio waveform is pre-processed using a log Mel filterbank and the Hamming window to split the wave into intervals. The spectrogram is then split into patches from time and frequency dimensions, which are then flattened into token sequences.
Unified Encoder
After transforming the raw inputs from various modalities to token embeddings, the researchers employ a unified transformer encoder with frozen parameters to encode these tokens. The encoder, based on the ViT model, is pretrained on the LAION-2B dataset with contrastive learning to improve its general token encoding ability. For text understanding, they use the pretrained text tokenizer from CLIP to convert sentences into subwords and then into word embeddings.
In what the authors refer to as “modality-agnostic learning”, a learnable token (xCLS) is added to the start of the token embeddings sequence. The final hidden state of this token acts as a summary representation of the input sequence, often used for recognition tasks. To account for positional information, position embeddings are added to the token embeddings.
The transformer encoder, which consists of multiple stacked multi-head self-attention layers and MLP blocks, processes these embedded sequences. The authors note that adding more sophisticated 2D-aware position embeddings does not significantly improve image recognition performance.
Experiments
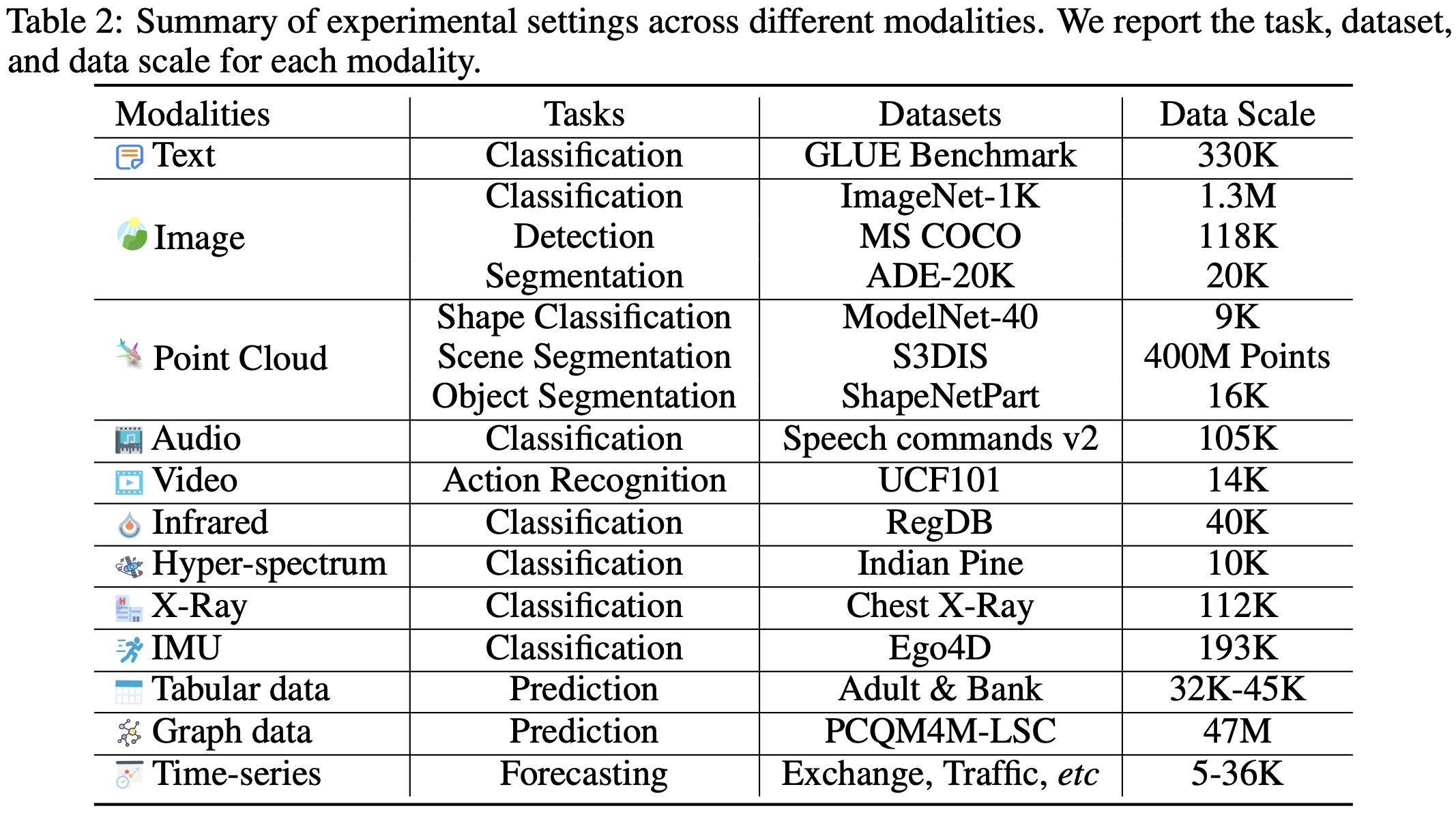
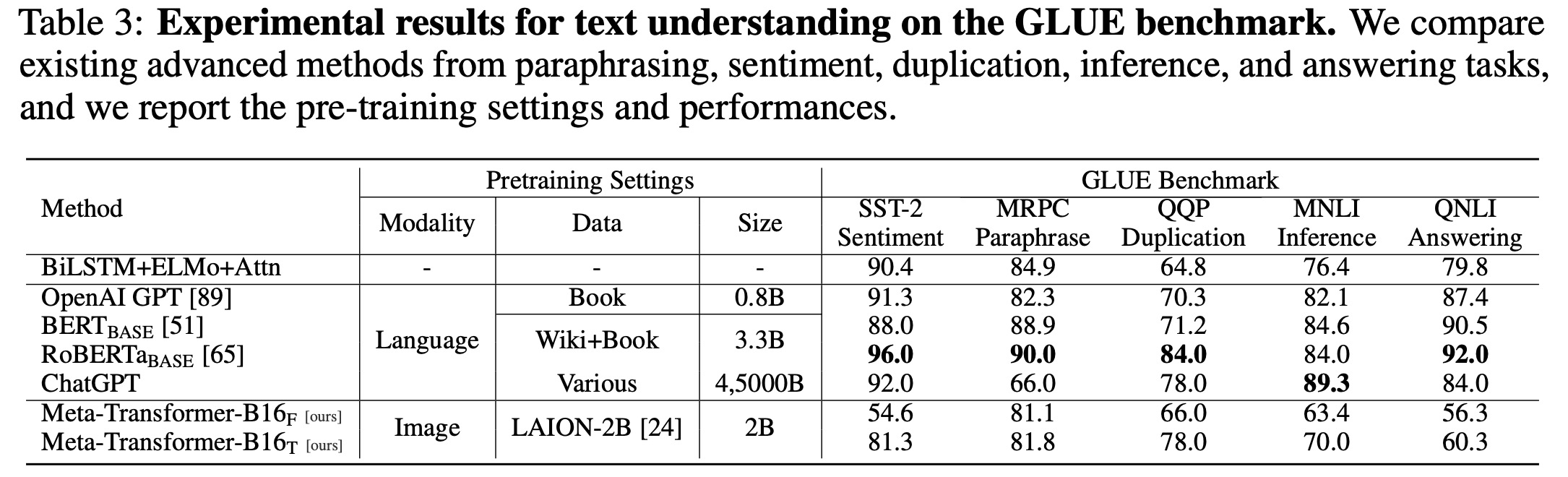
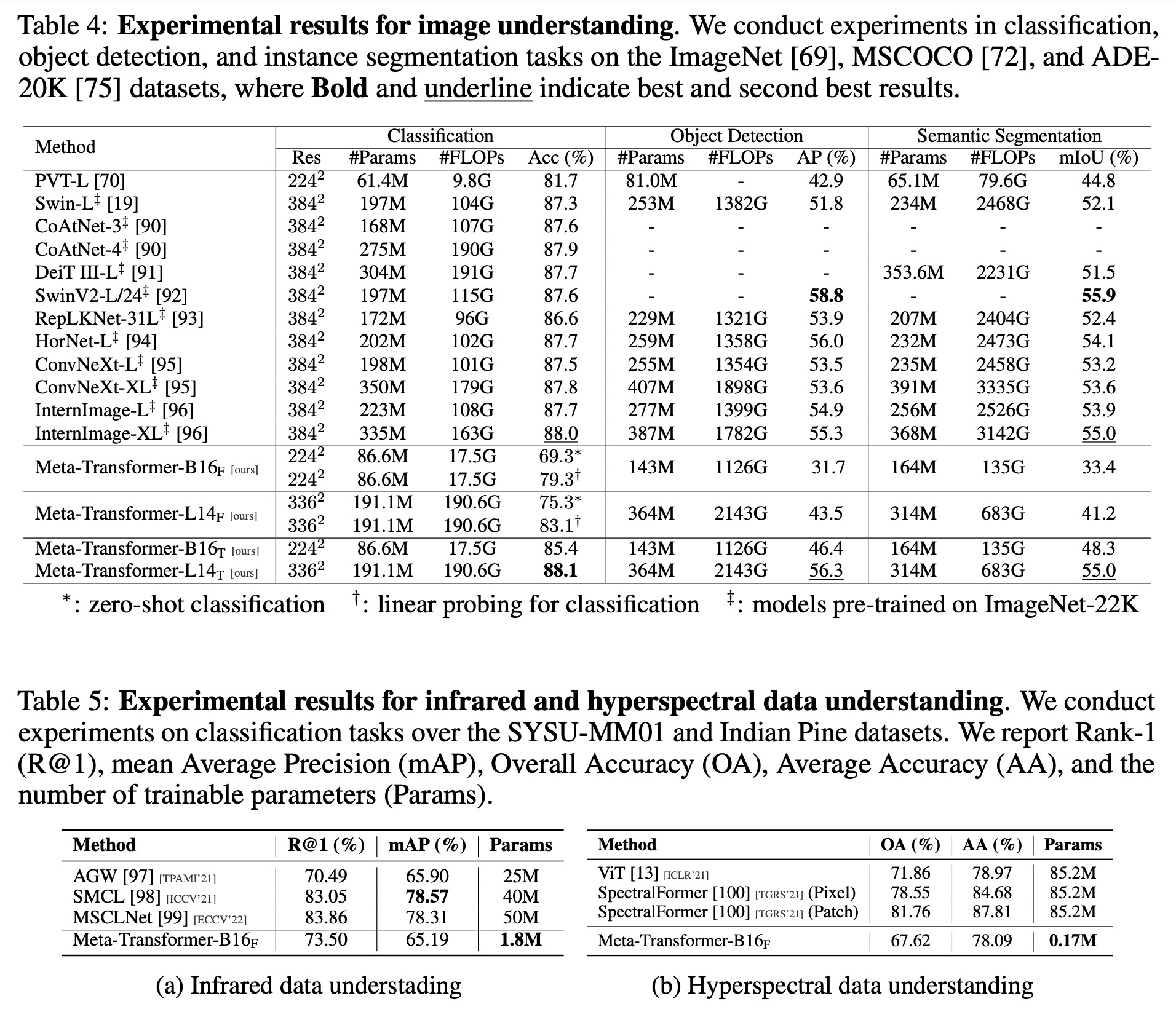
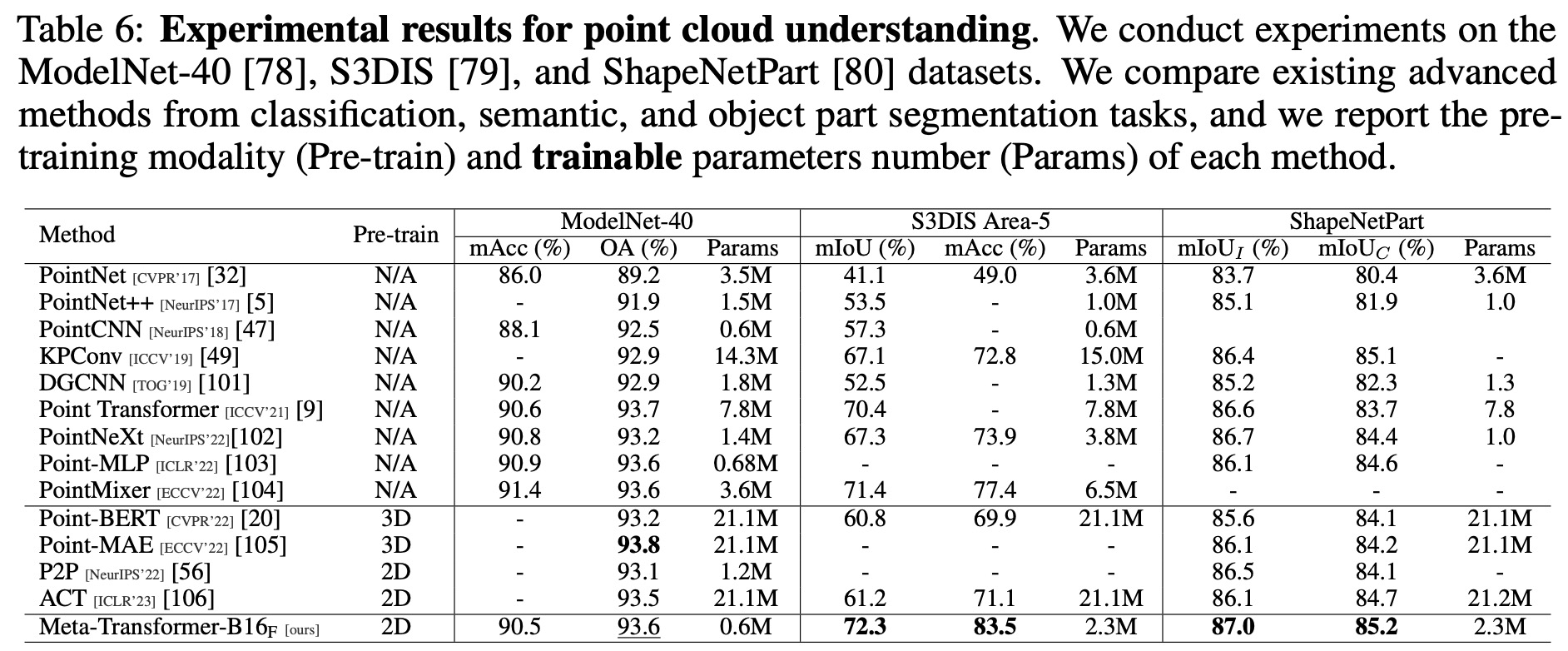
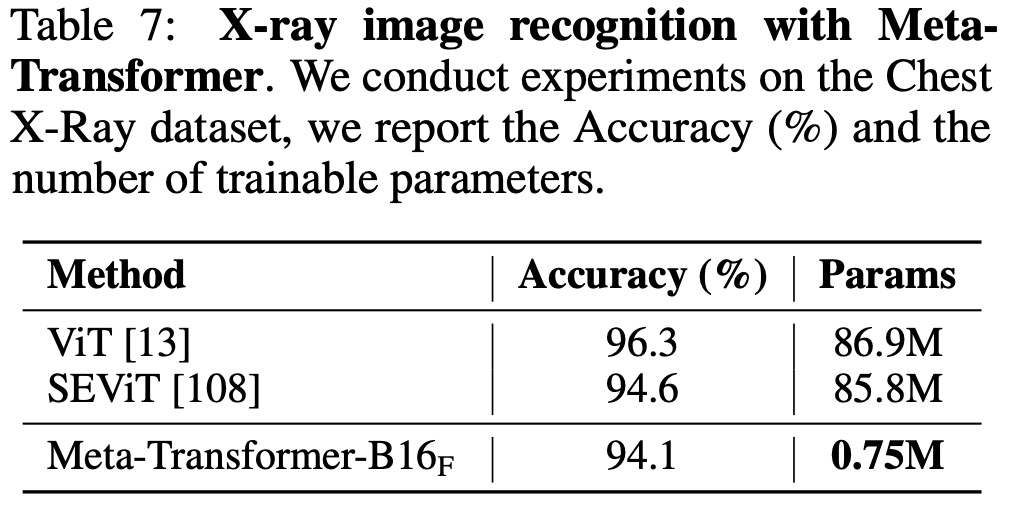
The Meta-Transformer model demonstrates competitive performance in various language and image understanding tasks, despite not always outperforming other advanced methods.
- In text understanding tasks tested on the GLUE benchmark, the Meta-Transformer scored relatively well in sentiment, paraphrasing, duplication, inference, and answering tasks. Although it didn’t perform as well as models like BERT, RoBERTa, and ChatGPT, it showed promise in understanding natural language, especially after fine-tuning.
- On image understanding tasks, the Meta-Transformer outperformed models such as Swin Transformer series and InternImage in several areas. It delivered strong results in zero-shot image classification when combined with the CLIP text encoder. It also outperformed other models in object detection and semantic segmentation tasks, showcasing its proficiency in image understanding.
- The Meta-Transformer also proved effective in handling infrared and hyperspectral image recognition tasks, as tested on the RegDB and Indian Pine datasets respectively. Despite not topping the leaderboard, the Meta-Transformer’s results were competitive and showcased potential for handling challenges associated with infrared images and hyperspectral images.
- In terms of X-Ray image processing, Meta-Transformer achieved a competitive performance of 94.1% accuracy, suggesting its utility in medical image analysis as well.
- In point cloud understanding tasks, Meta-Transformer demonstrates competitive performance on the ModelNet-40, S3DIS, and ShapeNetPart datasets. Notably, it achieves high accuracy scores with fewer trainable parameters compared to other models, underlining its efficiency in this area.
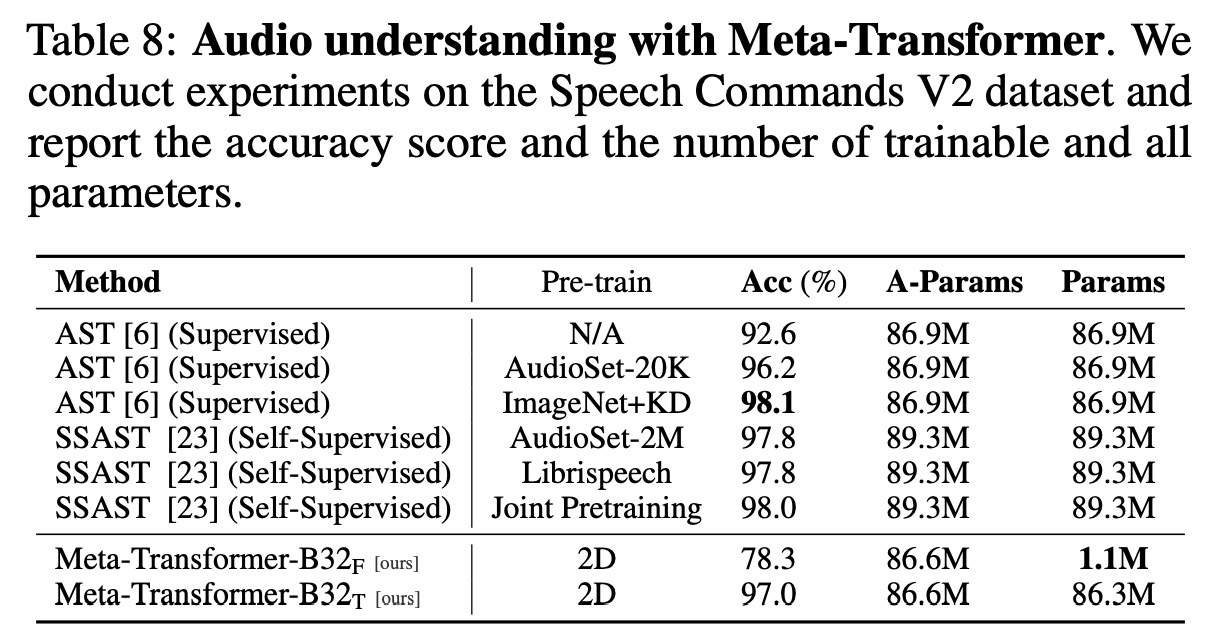
- In audio recognition tasks, the Meta-Transformer competes favorably with existing audio transformer models like AST and SSAST, reaching a high accuracy of 97.0% when tuning the parameters. Despite its strong performance, models like AST, when pre-trained on ImageNet and supplemented with Knowledge Distillation (KD), reach a slightly higher accuracy, but with many more trainable parameters.
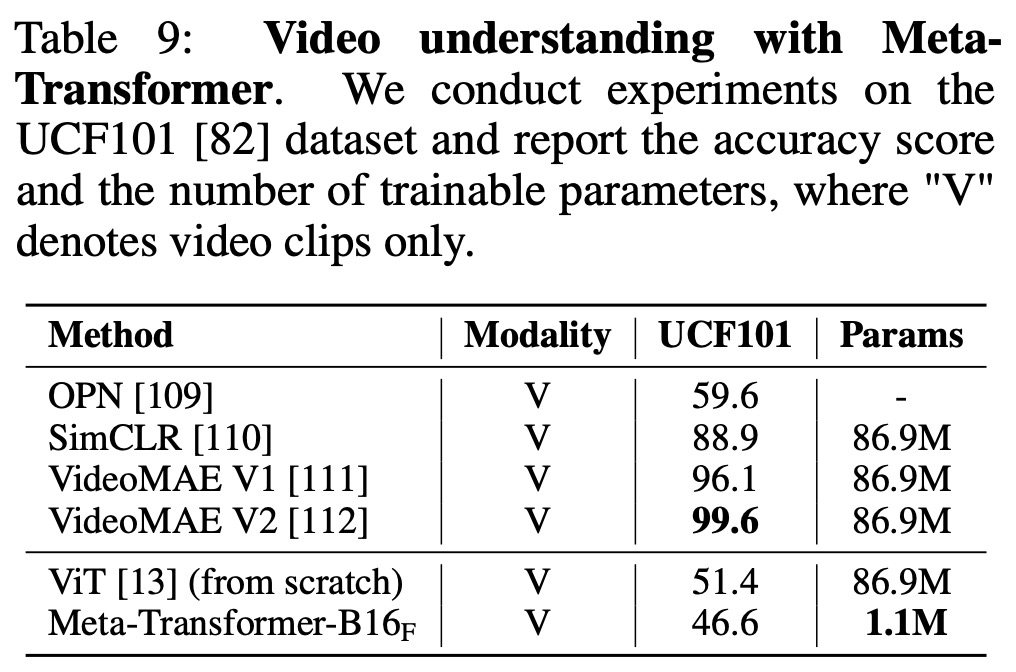
- In video understanding tasks, the Meta-Transformer does not outperform other state-of-the-art methods in terms of accuracy, as tested on the UCF101 dataset. However, it stands out for its significantly fewer trainable parameters, indicating potential benefits of unified multi-modal learning and lower architectural complexity.
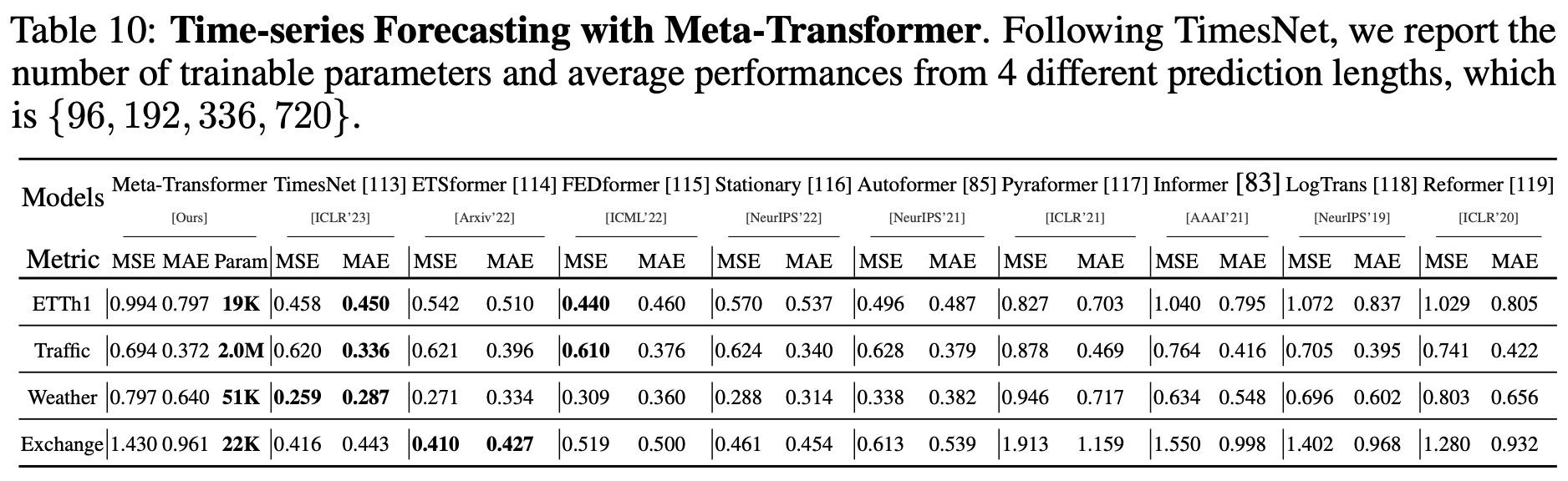
- In time-series forecasting tasks, the Meta-Transformer outperforms several existing methods on benchmarks like ETTh1, Traffic, Weather, and Exchange datasets, while requiring very few trainable parameters.
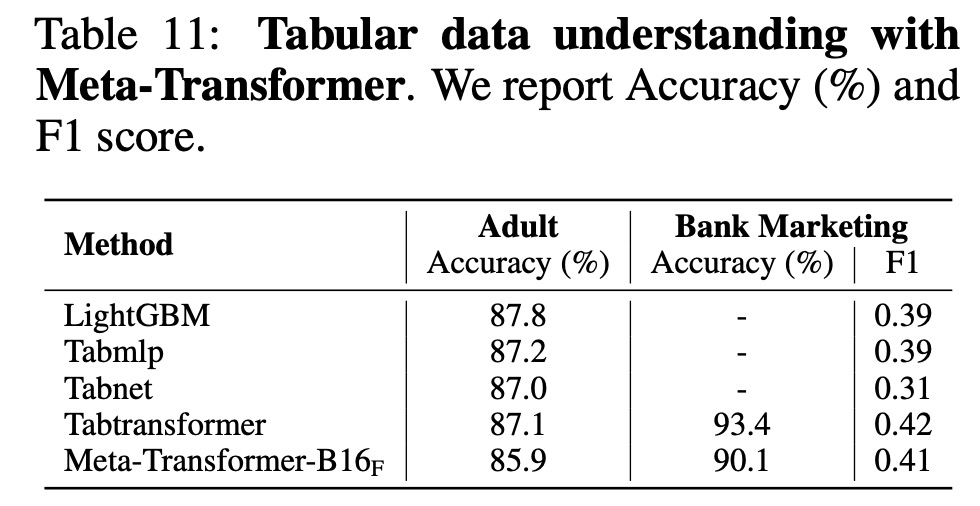
- In tabular data understanding tasks, Meta-Transformer exhibits strong performance on the Adult Census and Bank Marketing datasets. It outperforms other models on the Bank Marketing dataset, suggesting its potential for understanding complex datasets.
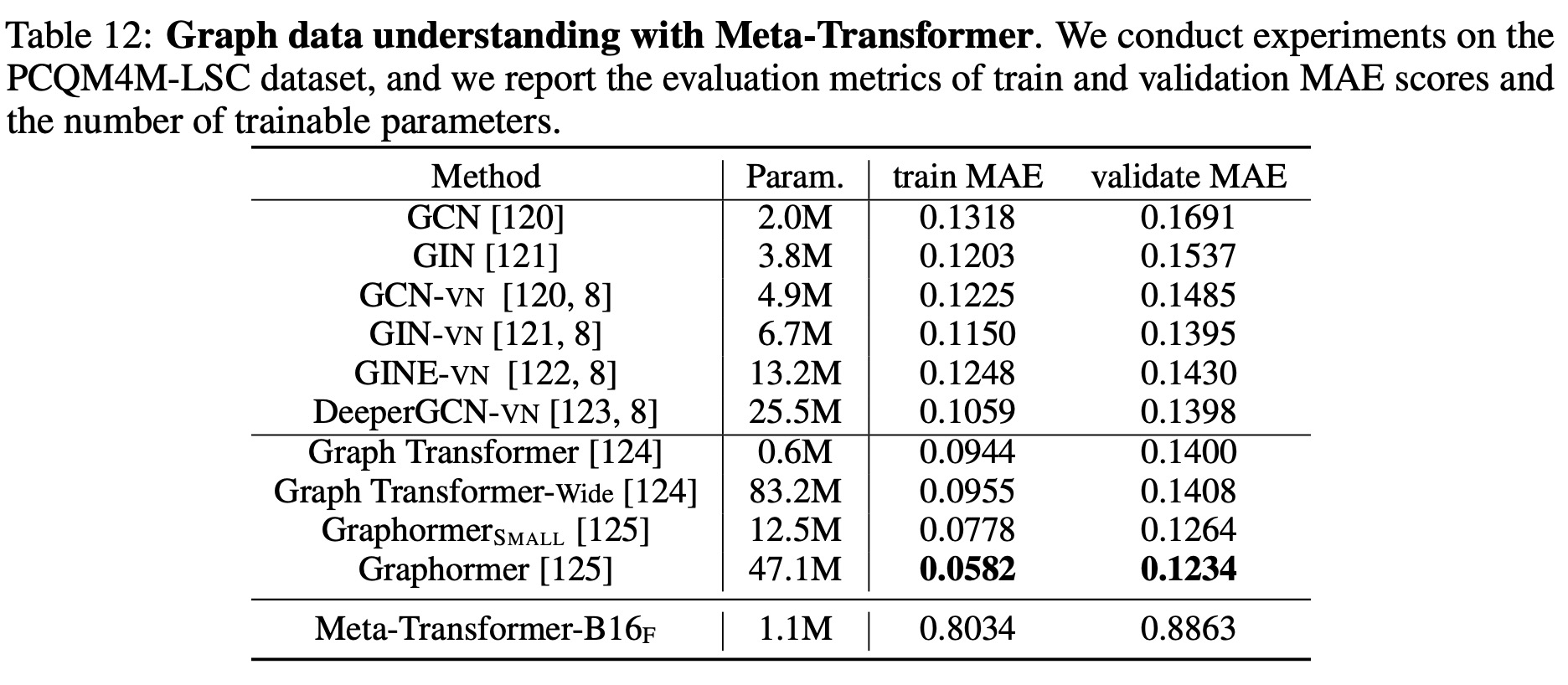
- In graph understanding tasks on the PCQM4M-LSC dataset, the current Meta-Transformer architecture demonstrates limited capability for structural data learning, with Graphormer model outperforming it. Further improvements in this area are anticipated.
- In classification tasks on the Ego4D dataset, the Meta-Transformer achieves an accuracy of 73.9%. Overall, these findings highlight the Meta-Transformer’s versatility and effectiveness across different domains.
One of the main limitations is computational complexity: O(n^2 x D).
paperreview deeplearning nlp transformer cv multimodal