Paper Review: Deep Learning for Day Forecasts from Sparse Observations
MetNet-3 is a neural network designed for weather forecasting, capable of making predictions with high temporal (up to every 2 minutes) and spatial (1 km) resolution. Trained using atmospheric observations, it forecasts various conditions such as precipitation, wind, temperature, and dew point up to 24 hours in advance. Its key feature is a densification technique that ensures accurate forecasts even from sparse data.
MetNet-3 outperforms leading Numerical Weather Prediction models. It is operational and integrated into Google Search, marking a significant advancement in observation-based neural weather models.
The approach
Dataset
MetNet-3’s training involves input-output data pairs consisting of various weather-related inputs and corresponding outputs. The inputs include radar data (precipitation rate and type) from the past 90 minutes, sparse weather station reports from the past 6 hours, GOES satellite images, assimilated weather state, geographical coordinates, altitude information, and current time. Outputs correspond to future radar precipitation estimates, ground weather station measurements (like temperature, dew point, pressure, wind speed, and direction), and assimilated weather state, the latter being used only to improve model training.
The data covers July 2017 to September 2022, divided into training, validation, and test datasets without overlap. To increase training samples, linear interpolation is used when exact lead time observations are unavailable. Targets are randomly sampled spatially across CONUS, with surface variable measurements from weather stations mapped to 4 km by 4 km pixels.
Model
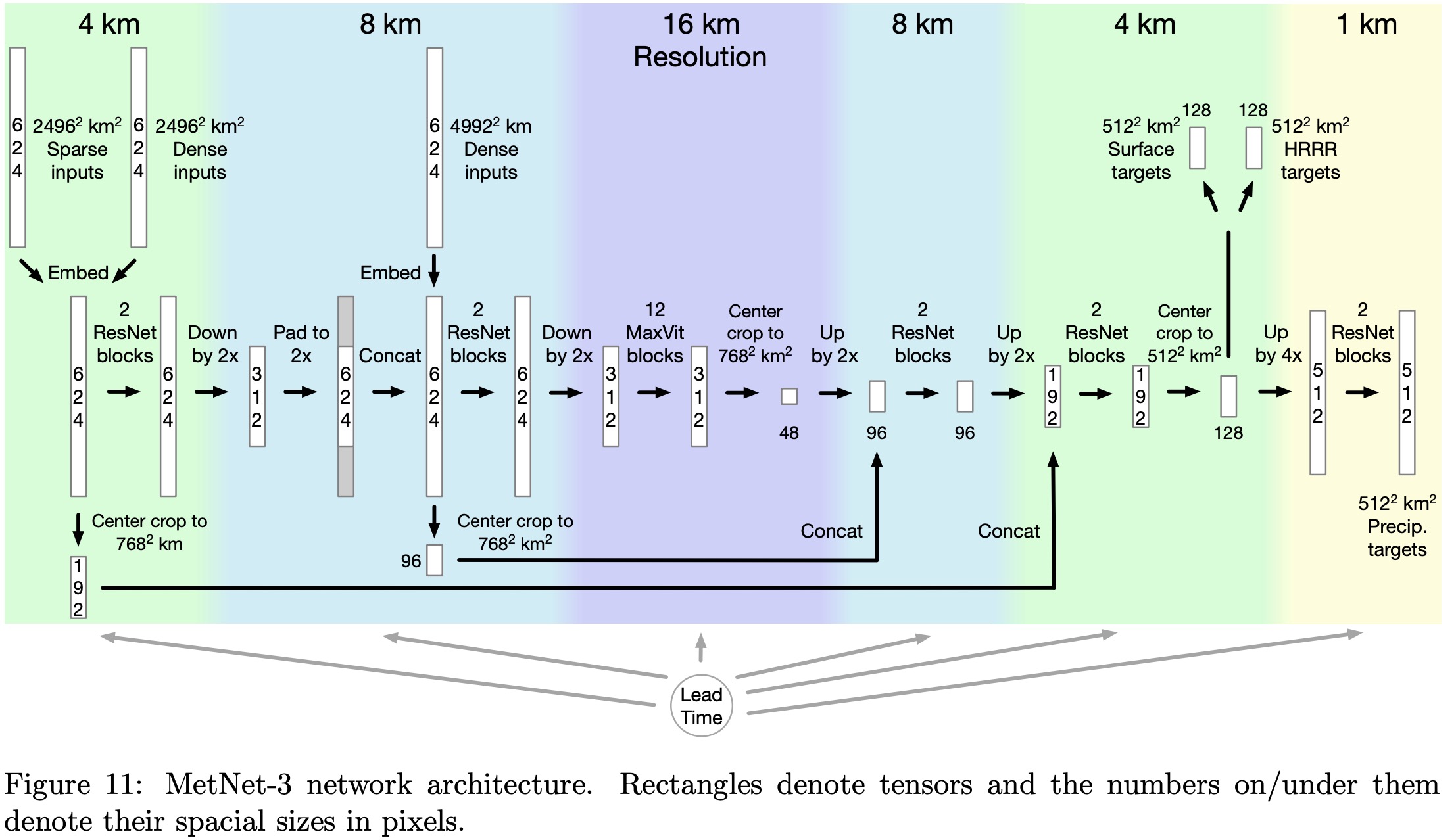
Unlike traditional methods that manually select and prepare topographical data like sea-land masks, MetNet-3 utilizes topographical embeddings.
The process involves a grid of embeddings with a 4 km stride, where each grid point is linked to 20 scalar parameters. For every input example, the topographical embedding of each input pixel’s center is calculated by bilinearly interpolating the embeddings from the grid. These embedding parameters are trained alongside other model parameters.
MetNet-3 uses two types of inputs for weather prediction: high-resolution, small-context inputs covering an area of 2496 km by 2496 km at 4 km resolution, and low-resolution, large-context inputs spanning 4992 km by 4992 km at 8 km resolution.
Initially, the data goes through a U-Net backbone, which includes applying convolutional ResNet blocks and downsampling to 8 km resolution. The internal representation is then padded to match the size of the low-resolution inputs and further processed with additional ResNet blocks and downsampling to 16 km resolution.
For handling long-range interactions, necessary for longer lead times close to 24 hours, the model uses a modified version of the MaxVit network, which focuses on both local neighborhood and global gridded attention. The MaxVit architecture is adapted by removing MLP sub-blocks, adding skip connections, and using normalized keys and queries in its attention mechanism.
Finally, the network performs a series of upsampling and cropping steps, resulting in detailed predictions. For ground weather variables, it outputs a categorical distribution over 256 bins each at a 4 km resolution. For precipitation rates and hourly accumulation, the model further upsamples to 1 km resolution, providing predictions in 512 bins for each pixel.
The lead time for weather forecasting is encoded using a one-hot embedding, which covers a range from 0 to 24 hours, with 2-minute intervals, represented as indices from 0 to 721. These indices are then transformed into a continuous 32-dimensional representation. This embedding is used both as an additive and multiplicative factor to the model inputs and to the hidden representations before each activation function or self-attention block.
Training
MetNet-3 is trained using cross-entropy loss for its primary weather forecasting outputs, and MSE loss for deterministic predictions of the HRRR assimilated state.
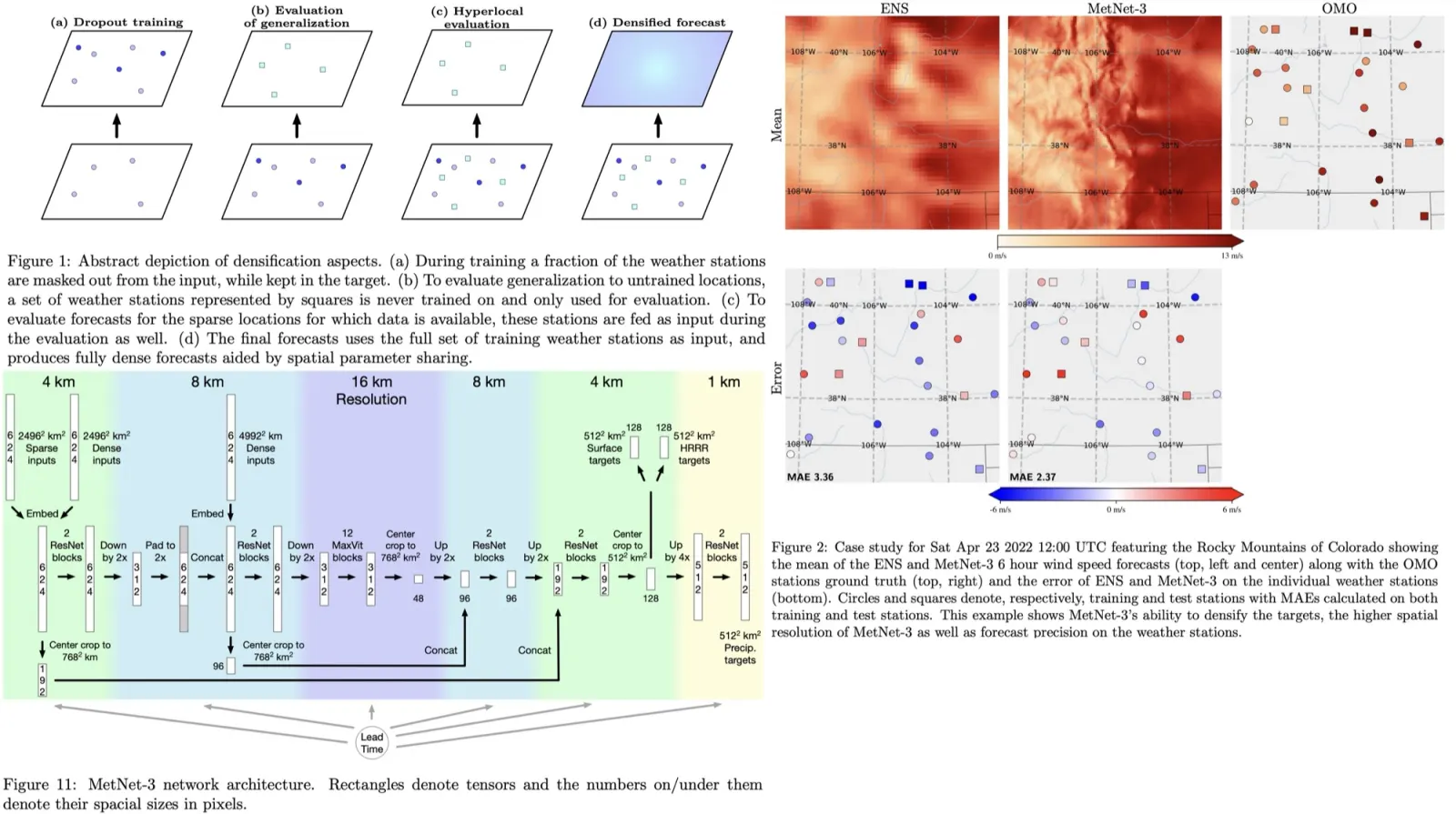
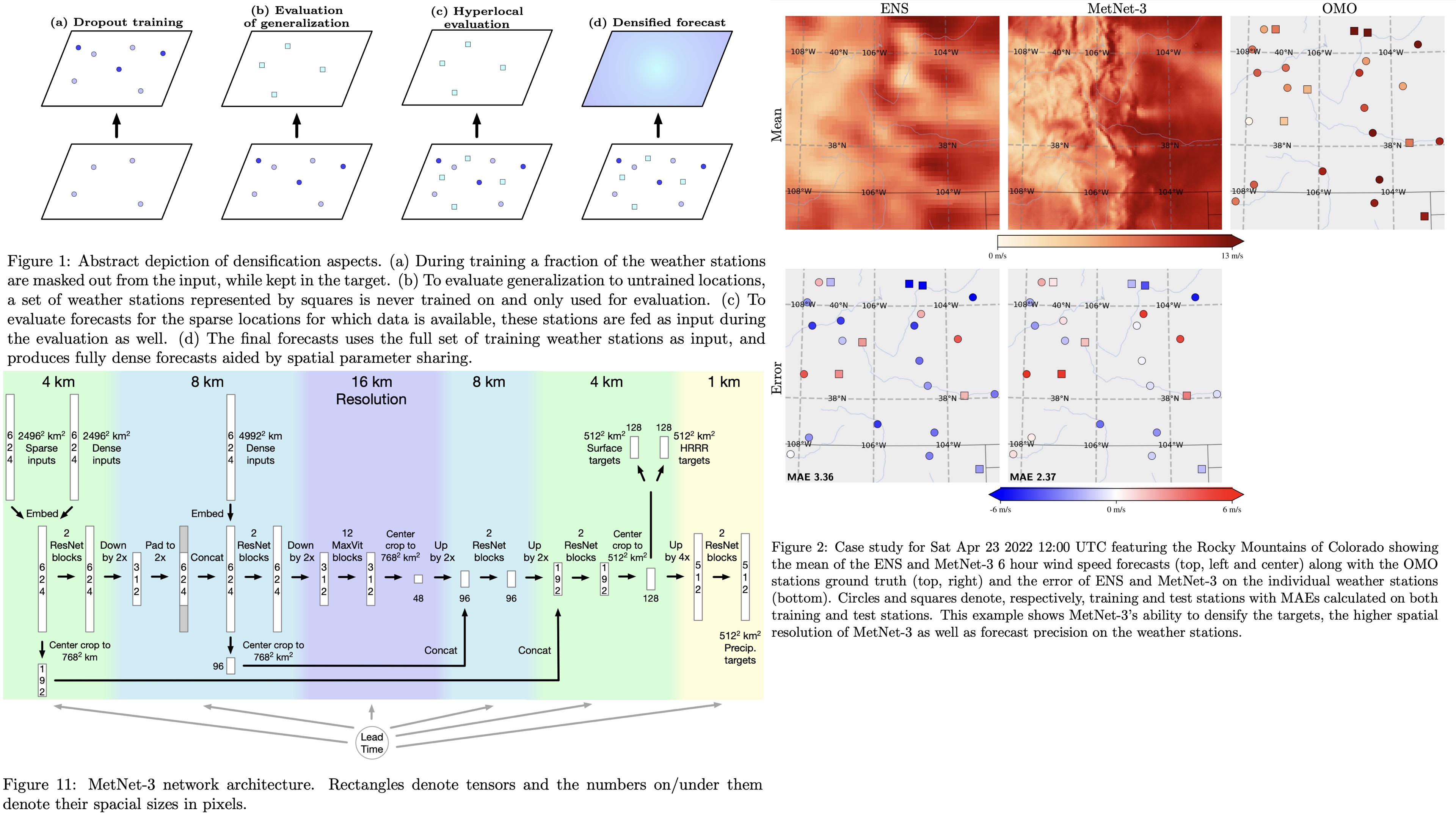
To enable the model to generalize to all locations, despite having ground truth data only at sparse weather station locations, MetNet-3 uses a densification strategy. This involves randomly masking out each weather station with a 25% probability during training, ensuring the model learns to predict variables even in the absence of direct input data from those locations. Additionally, there’s a trade-off between the quality of precipitation and ground variable forecasts. To address this, two separate models are trained: one specializing in precipitation and another, fine-tuned with a higher weight on ground variable loss, for ground forecasts.
The model is trained on 512 TPUv3 cores for 7 days.
Experiments
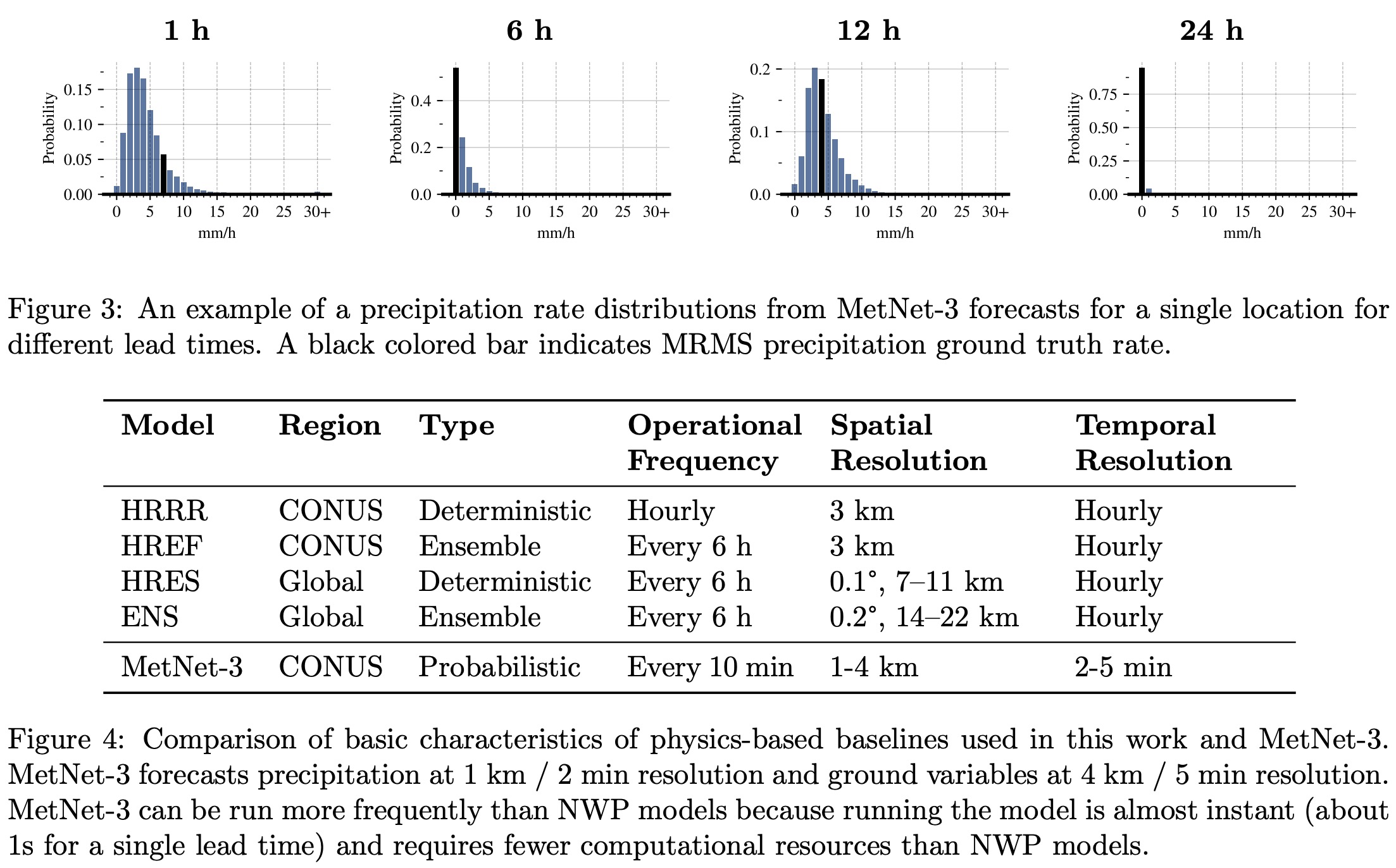
The evaluation of MetNet-3 focuses on several weather variables over the CONUS area (Continental United States), including instantaneous and hourly precipitation, surface temperature and dewpoint, and wind speed and direction at different altitudes.
MetNet-3 uses a densification process to enhance the sparse data from these weather stations. Unlike Numerical Weather Prediction models (NWPs) that use ensemble forecasts to model uncertainty, MetNet-3 outputs a marginal probability distribution for each variable at each location, providing detailed information beyond the mean.
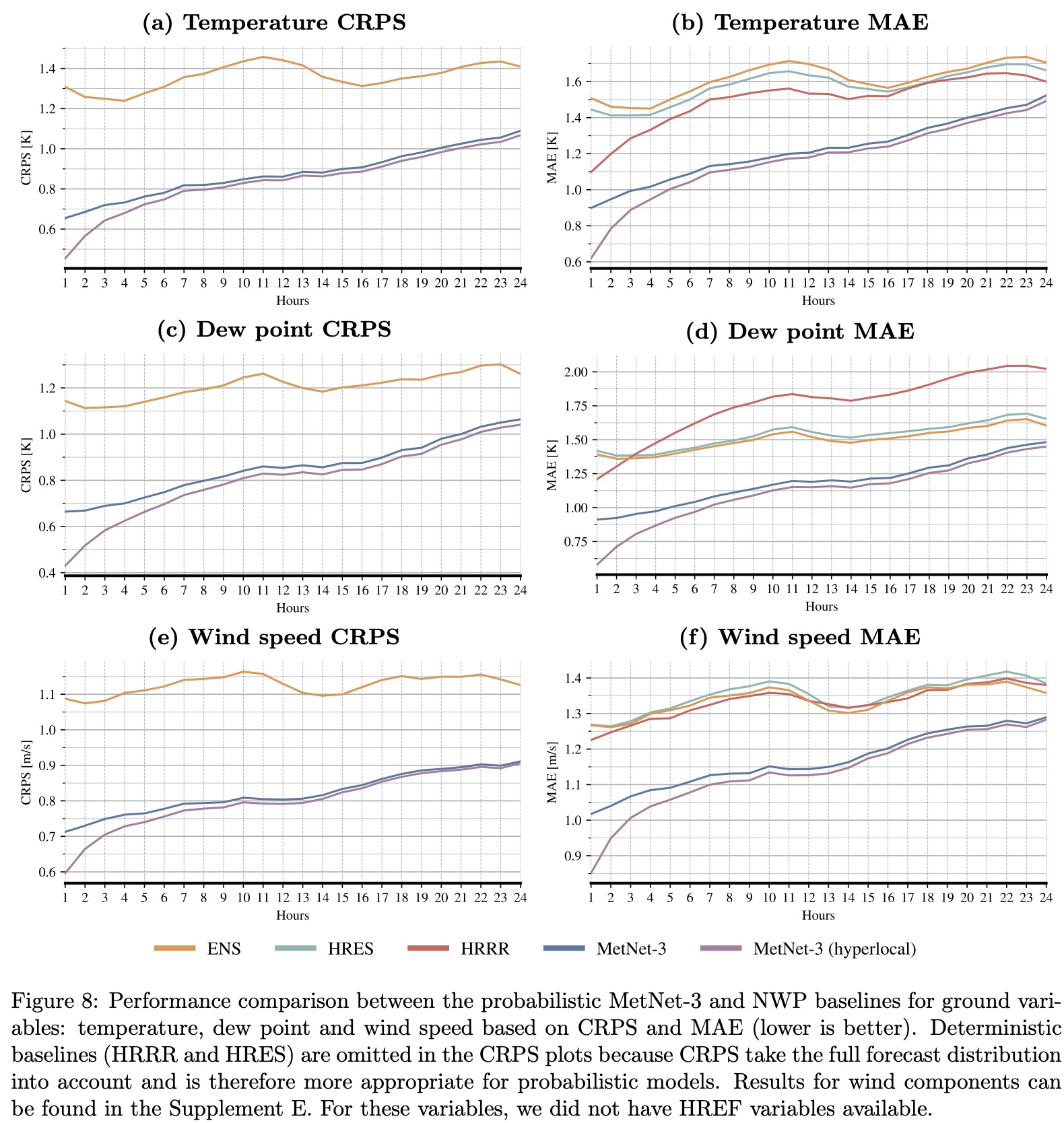
The comparison uses metrics such as Continuous Ranked Probability Score (CRPS), Critical Success Index (CSI), and Mean Absolute Error (MAE). CRPS is especially relevant for comparing ensemble models like ENS and HREF, as it measures the accuracy of the full output distribution across all possible rates or amounts. This metric is a key one in developing and evaluating probabilistic forecasts.
Precipitation
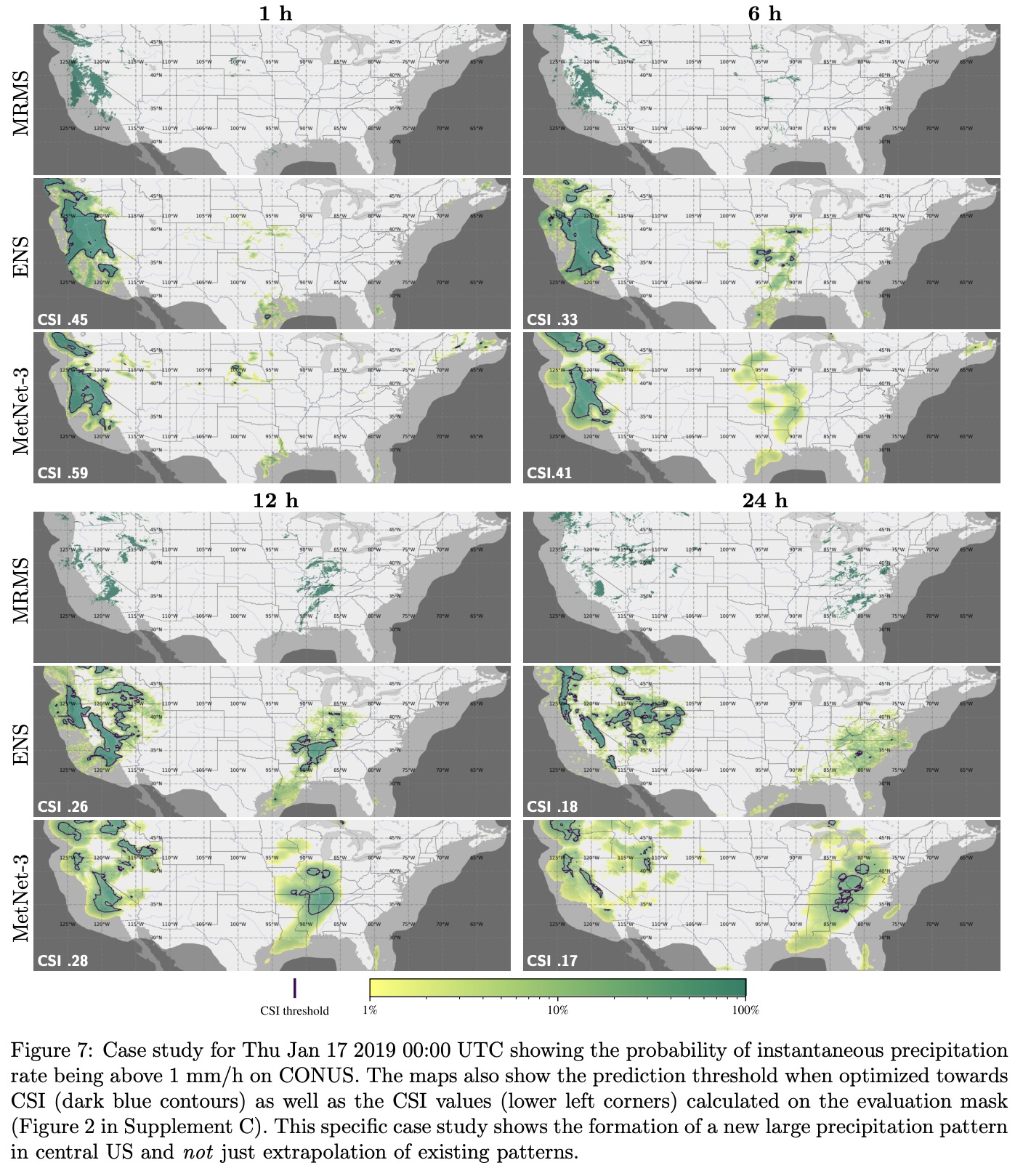
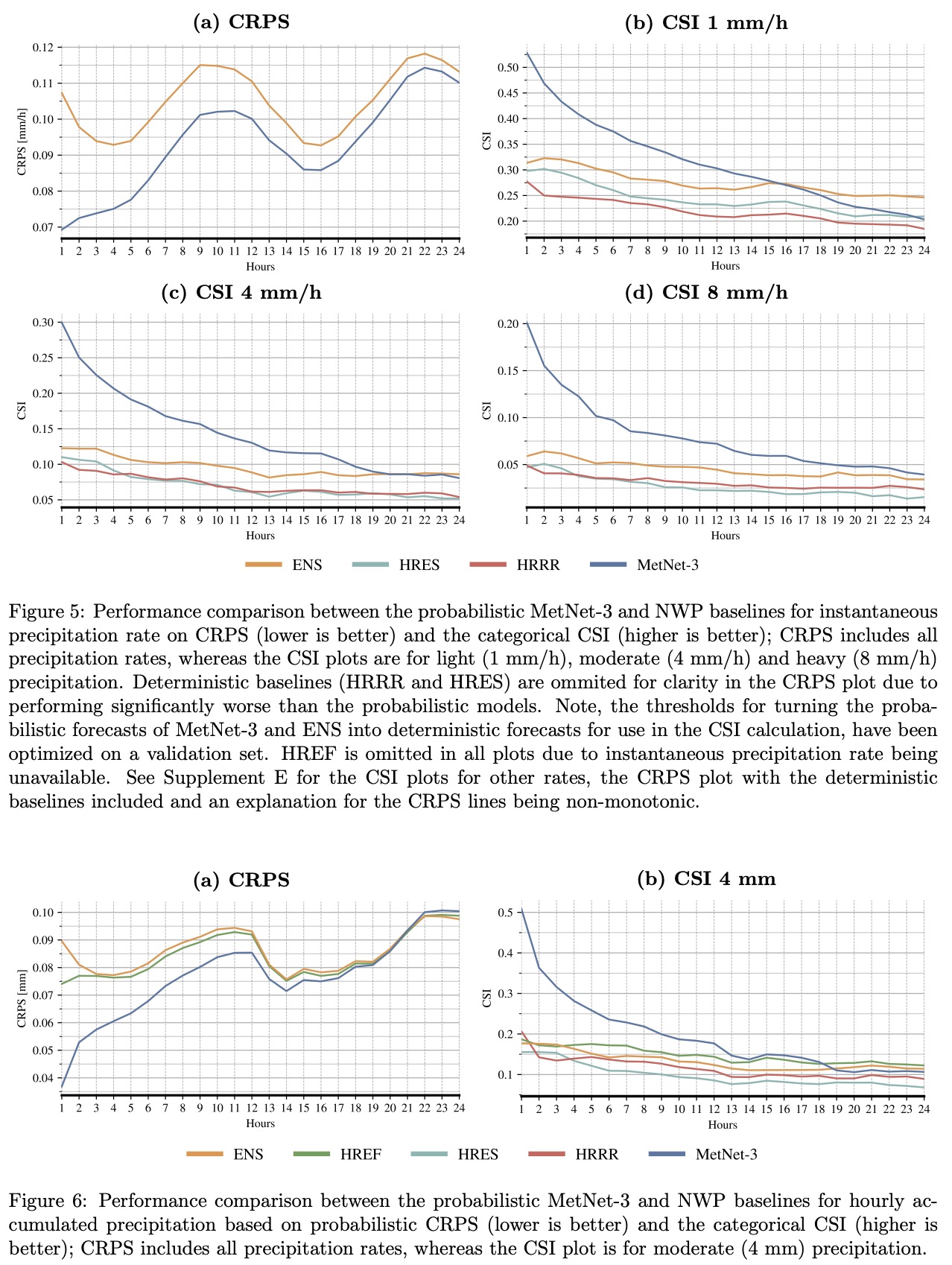
MetNet-3 demonstrates superior performance in weather forecasting compared to the European Centre for Medium-Range Weather Forecasts’ ensemble forecast (ENS). Specifically, MetNet-3 achieves a higher CRPS than ENS for forecasting the rate of instantaneous precipitation across a 24-hour lead time.
For light precipitation (1 mm/h), MetNet-3 outperforms ENS for the first 15 hours of lead time. For heavy precipitation (8 mm/h), it maintains this advantage over the entire 24-hour lead time range.
Additionally, MetNet-3 surpasses both ENS and the High Resolution Ensemble Forecast in predicting hourly accumulated precipitation up to 19 hours ahead, as measured by CRPS.
Sparse Surface Variables
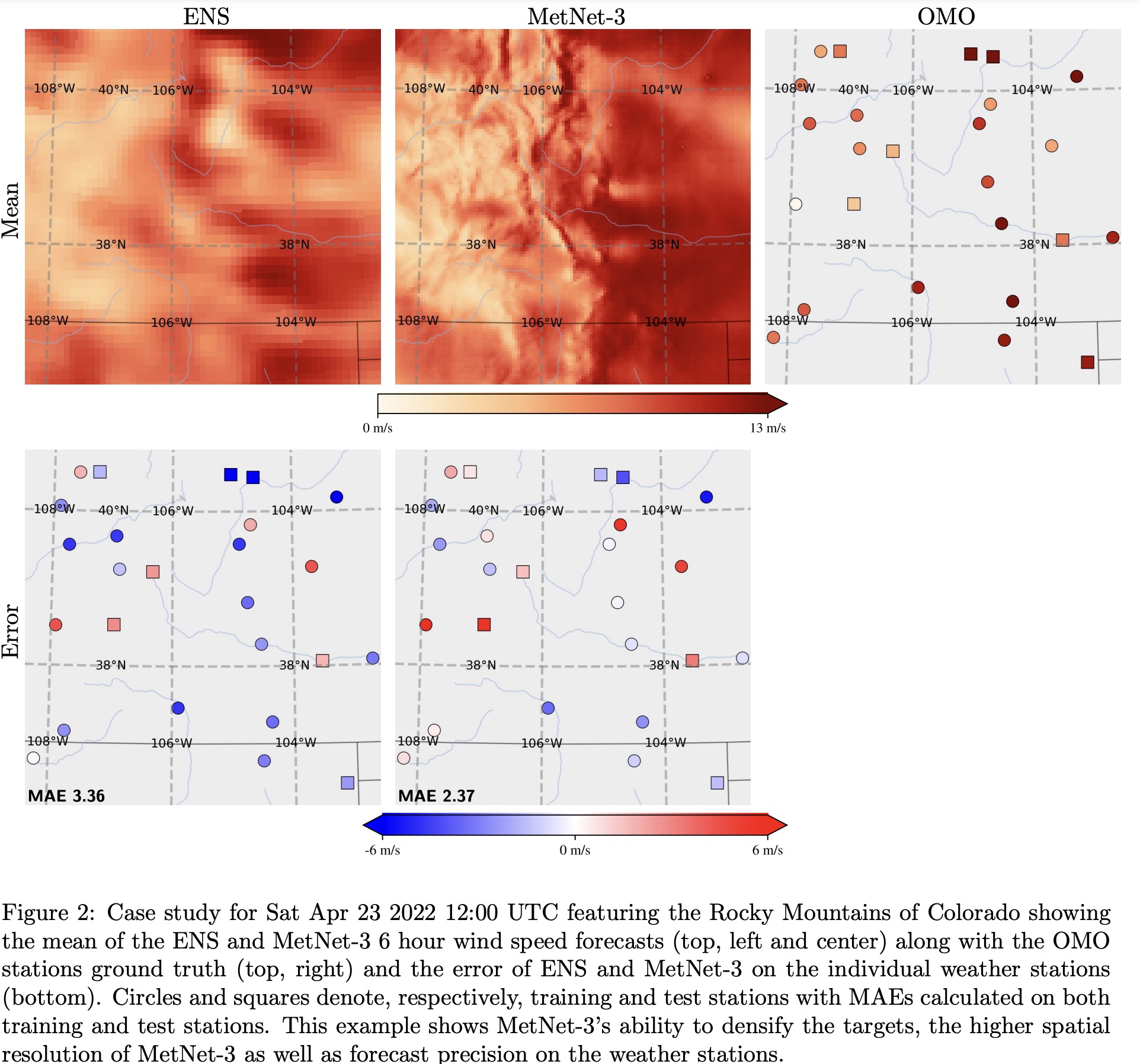
Training MetNet-3 to predict weather accurately across all locations in CONUS is challenging due to the sparse distribution of ground truth data, available only from 942 weather stations. To ensure comprehensive performance, MetNet-3 employs a densification procedure and evaluates its predictions using a hold-out set of 20% of weather stations that are not used in training.
For surface variables, MetNet-3 uses a discretized approach with a Softmax layer and categorical loss for prediction. It achieves better CRPS and MAE for all surface variables across a 24-hour lead time compared to ENS. The CRPS results indicate that MetNet-3 effectively models the full forecast distribution, outperforming ENS’s best scores achieved at a shorter lead time of 1 hour.
Case studies demonstrate that most observed values fall within MetNet-3’s 80% confidence interval.
MetNet-3 also shows significantly better results in terms of MAE compared to both multi-member and single-member baseline models. For instance, the accuracy of MetNet-3’s 20-hour temperature forecast is comparable to a 5-hour forecast from the best-performing baseline.