Paper Review: Mistral 7B

Mistral 7B is designed for high performance and efficiency. It surpasses the 13B Llama 2 in all benchmarks and outdoes the 34B Llama 1 in reasoning, math, and code generation. Mistral 7B uses grouped-query attention for quick inference and sliding window attention for handling long sequences at a lower cost.
Mistral 7B – Instruct, fine-tuned for following directions, outperforms the Llama 2 13B Chat model in both human and automated tests.
Architecture

Mistral 7B uses a transformer architecture. Key changes from the Llama model include:
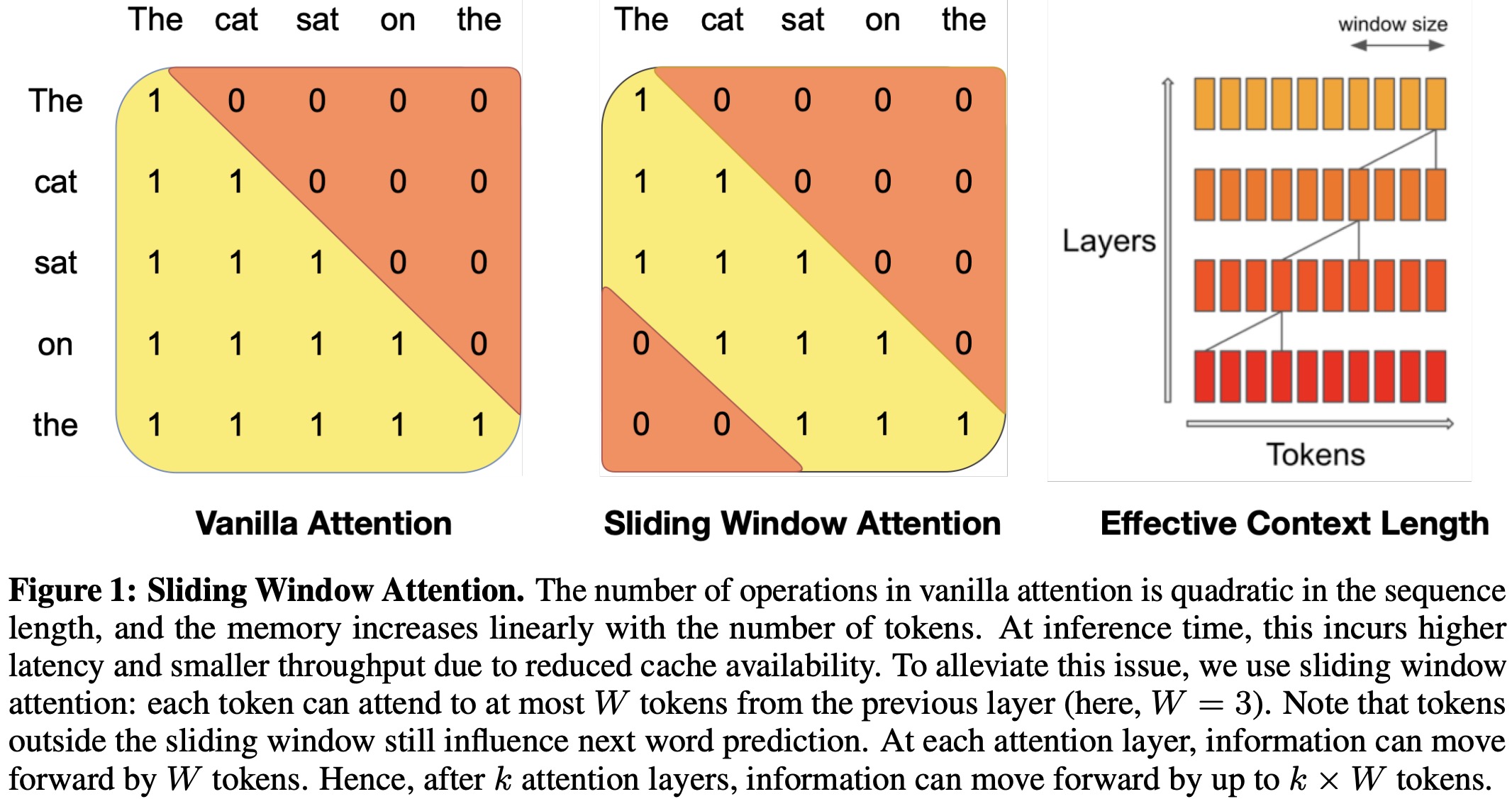
- Sliding Window Attention (SWA): This method allows the model to attend to information beyond a set window size by leveraging the stacked layers of a transformer. With a window size of 4096, it can theoretically attend to around 131K tokens. This approach, combined with modifications to FlashAttention and xFormers, offers a 2x speed boost over standard attention mechanisms.
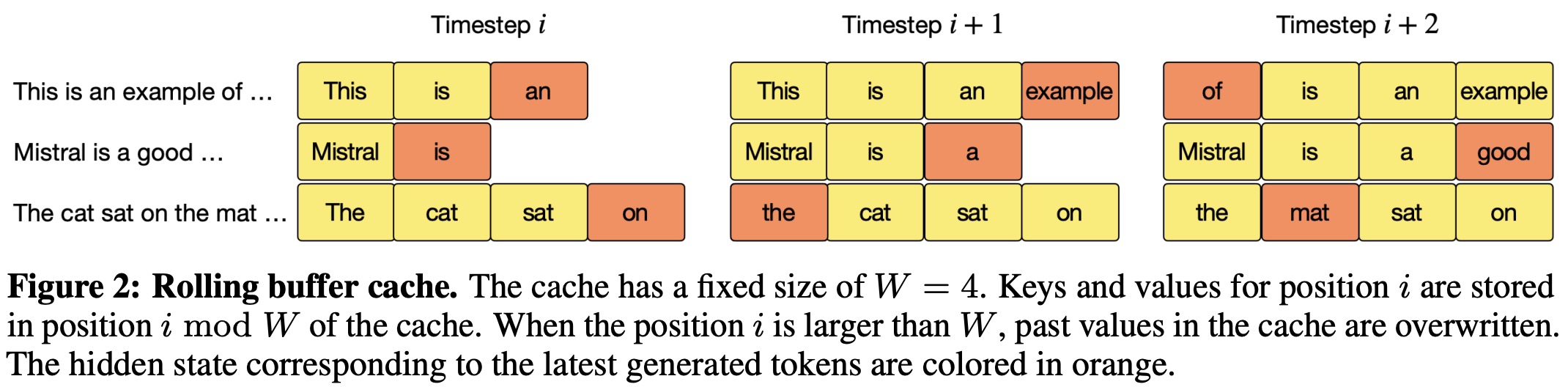
- Rolling Buffer Cache: This feature limits cache size using a rolling buffer. The cache has a fixed size, and as new data is added, older data is overwritten once the cache exceeds its size. This method reduces cache memory usage by 8x for sequences of 32k tokens without compromising model quality.
- Pre-fill and Chunking: When generating sequences, the model predicts tokens sequentially since each token depends on the previous ones. However since prompts are known beforehand, the cache can be pre-filled with them. If a prompt is too long, it’s divided into chunks, and the cache is filled chunk by chunk. The attention mask operates over both the cache and the chunk.
Results
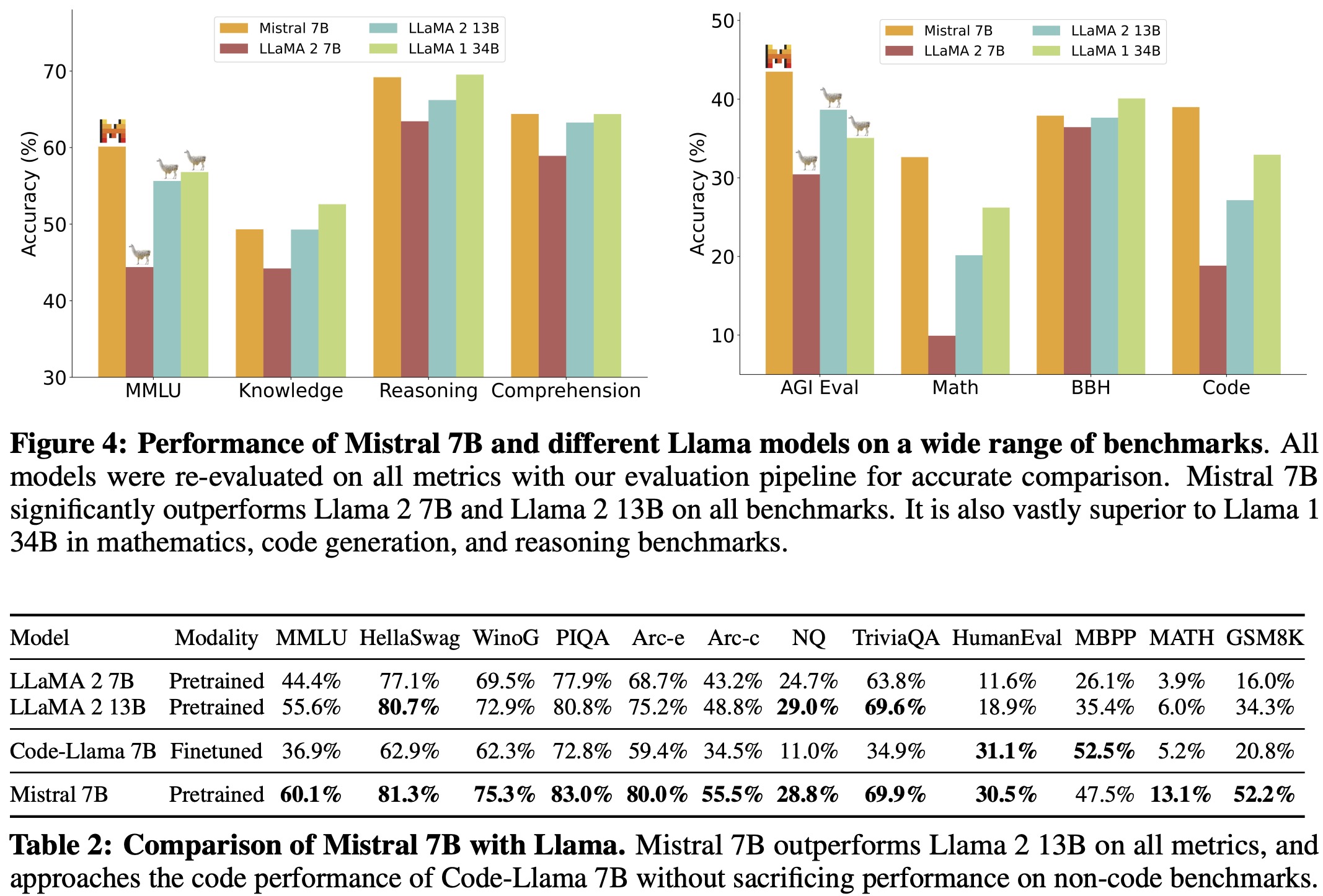
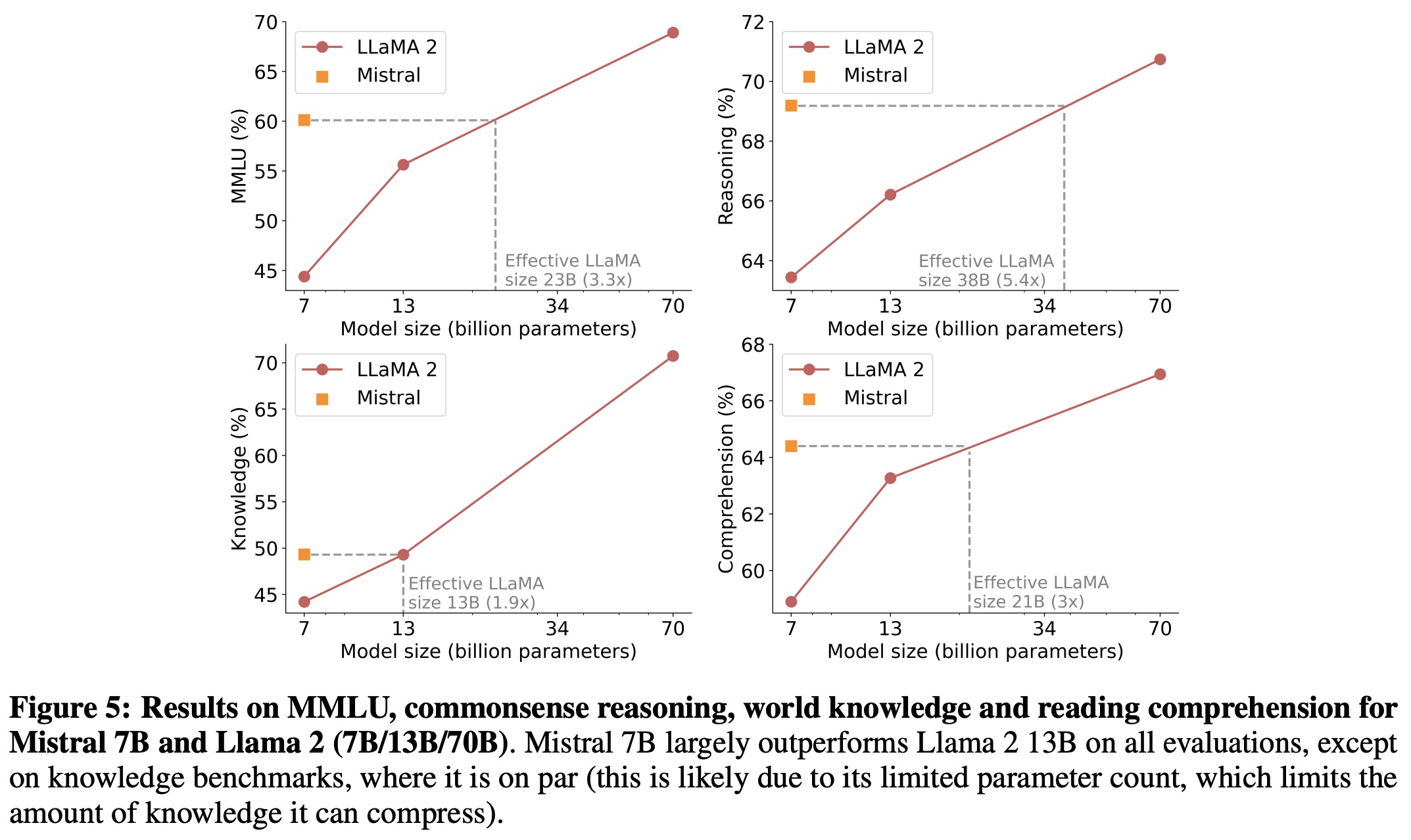
- Mistral 7B’s efficiency was compared to the Llama 2 by calculating “equivalent model sizes.” In tests on reasoning, comprehension, and STEM reasoning, Mistral 7B performed as well as a Llama 2 that’s over 3 times its size. However, in Knowledge benchmarks, Mistral 7B’s performance was equivalent to a Llama 2 model that’s 1.9 times its size, likely because its smaller parameter count limits the knowledge it can store.
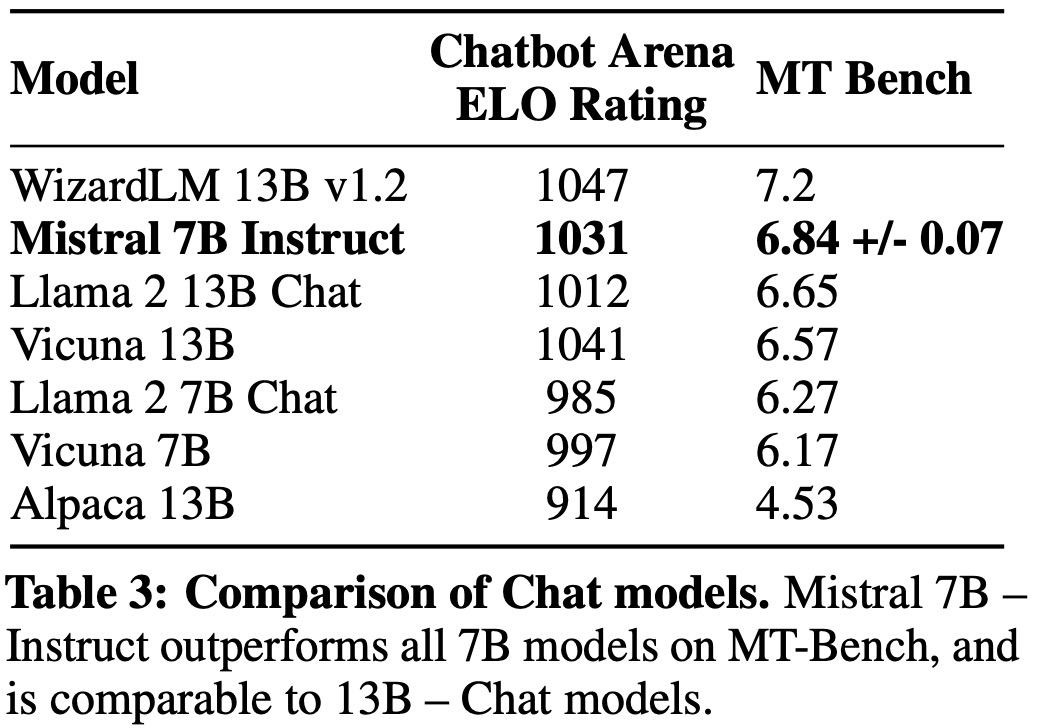
- Mistral 7B was fine-tuned on public instruction datasets from the Hugging Face repository to assess its generalization capability. The resulting model, Mistral 7B – Instruct, showed superior performance to other 7B models on MT-Bench and was on par with 13B – Chat models. An independent human evaluation was done on https://llmboxing.com/leaderboard, where participants compared responses from two models. As of October 6, 2023, Mistral 7B’s outputs were preferred 5020 times, while Llama 2 13B was chosen 4143 times.
Adding guardrails for front-facing applications

AI guardrails are crucial for user-facing applications. Mistral 7B can enforce output constraints and perform detailed content moderation to ensure quality content. A system prompt is introduced to guide the model in generating answers within set boundaries, similar to Llama 2:
Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity
When tested with unsafe prompts, the model declined to answer 100% of harmful questions using the system prompt. For example, when asked about terminating a Linux process, Mistral 7B provided a correct answer with the system prompt activated, while Llama 2 did not. Without the prompt, both models answered correctly.
Mistral 7B – Instruct can also act as a content moderator, classifying content as acceptable or categorizing it under illegal activities, hateful content, or unqualified advice. A self-reflection prompt allows Mistral 7B to classify content, achieving 99.4% precision and 95.6% recall. This capability can be applied to various scenarios, such as moderating social media comments or monitoring brands online, allowing users to filter content based on specific needs.
paperreview deeplearning llm nlp