Paper Review: MMS: Scaling Speech Technology to 1000+ languages

The Massively Multilingual Speech (MMS) project aims to significantly broaden the language coverage of speech technology, which is currently limited to about 100 languages out of over 7,000 spoken worldwide. The project utilizes a new dataset derived from publicly available religious texts and maximizes self-supervised learning. Through this, the authors have developed pre-trained wav2vec 2.0 models for 1,406 languages, a multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for an equivalent number of languages, and a language identification model for 4,017 languages. In experiments, the multilingual speech recognition model demonstrated a remarkable improvement, reducing the word error rate by more than half compared to Whisper on 54 languages of the FLEURS benchmark, despite being trained on considerably less labeled data.
Dataset Creation

Paired Data for 1,107 Languages (MMS-lab)
The speech data and transcriptions for 1,107 languages were obtained by aligning New Testament texts procured from online sources. The process involves:
- Downloading and preprocessing both the speech audio and text data.
- Implementing a scalable alignment algorithm designed to force align lengthy audio files with text for over 1,000 languages.
- Initial Data Alignment: Training an initial alignment model using existing multilingual speech datasets covering 8,000 hours of data in 127 languages, which is then used to align data for all languages.
- Improved Data Alignment: Training a second alignment model on the newly aligned data with high confidence from the original alignment model, generating alignments again. The new alignment model supports 1,130 languages and 31,000 hours of data.
- Final data filtering: Removing low-quality samples for each language using a cross-validation procedure. A monolingual ASR model is trained on half of the aligned data to transcribe the other half, retaining only high-quality transcription samples.
- Partitioning the data into training, development, and test portions.
Data Source
The Massively Multilingual Speech (MMS) project utilizes the MMS-lab dataset, derived from recordings of people reading the New Testament in different languages, sourced from Faith Comes By Hearing, goto.bible, and bible.com.
The MMS-lab-U dataset comprises 1,626 audio recordings in 1,362 languages, totaling 55,000 hours. Out of these, both text and audio are available for 1,306 recordings in 1,130 languages, comprising 49,000 hours, which form the primary focus of MMS-lab.
This data is handled differently depending on the task: for language identification, differing recordings are merged; for speech synthesis, one recording per dialect/script is chosen; for automatic speech recognition, all recordings within the same script/dialect are combined and treated as different languages.
A considerable number of the recordings feature background music (referred to as drama recordings). In the final MMS-lab dataset, 38% of languages are solely represented by a drama recording and 11% have both drama and non-drama recordings. Background music is removed during pre-processing for speech synthesis.
Data Pre-processing
The original audio files in the MMS-lab dataset, available in MP3 stereo format with a 22/24/44 kHz sampling rate, were converted to a single channel with a 16 kHz sampling rate.
Text normalization was achieved through a generic pipeline designed to work well across all languages in the dataset. The process involved applying NFKC normalization and lower casing all characters to ensure consistent character encoding. HTML tags such as “>” and “nbsp;” were removed, along with punctuation marks.
For recordings with a high rate of brackets in the text (at least 3% of verses), the team manually checked whether the text in the brackets was spoken in the audio. In many instances, it was not, leading to the removal of the brackets and the enclosed text.
Scalable Forced Alignment
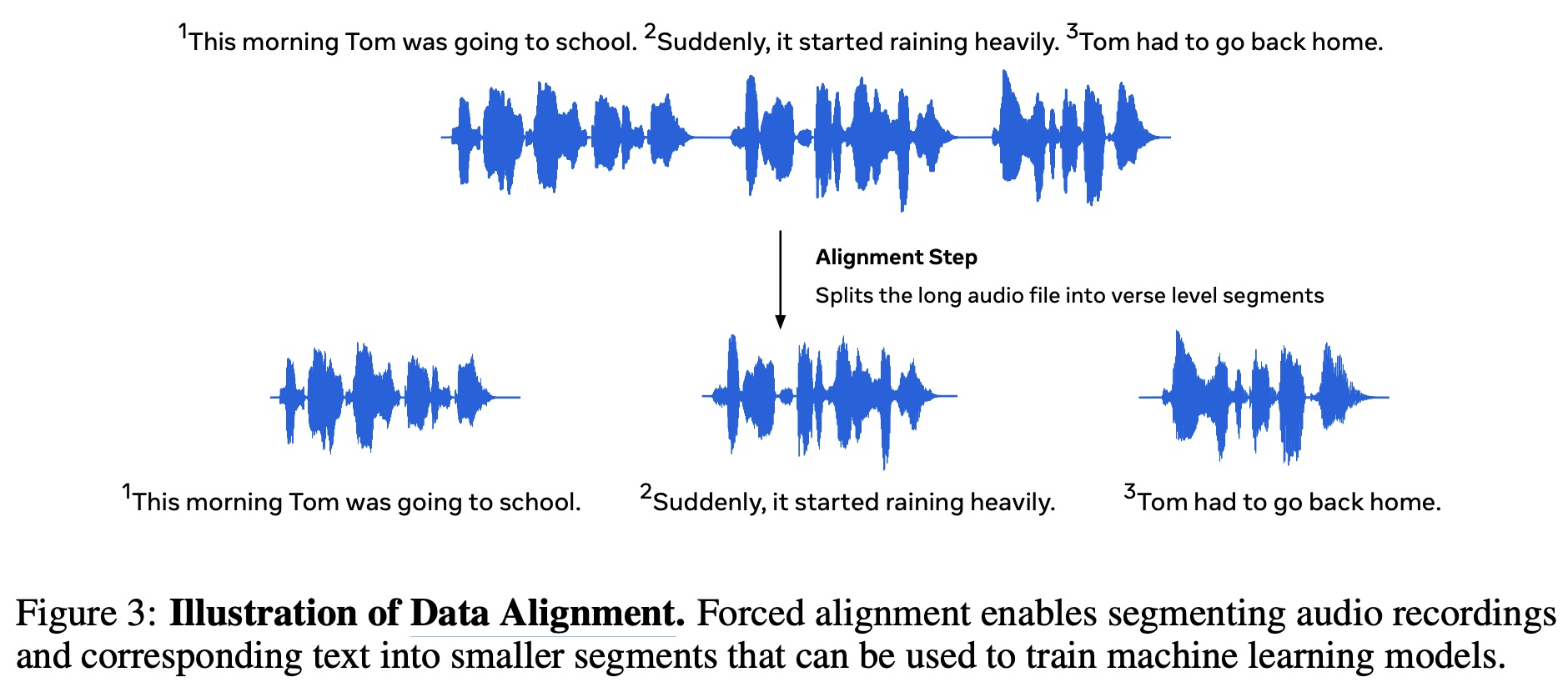
The original chapter recordings, up to 43 minutes long, were too lengthy for direct use by machine learning algorithms due to their computational complexity. To mitigate this, the data was segmented into smaller units or verses, averaging about 12 seconds in duration, through forced alignment. This process identifies the parts of the audio that correspond with specific parts of the text.
Posterior probabilities for alignment were generated by chunking the audio files into 15-second segments, using an acoustic model trained with Connectionist Temporal Classification (CTC).
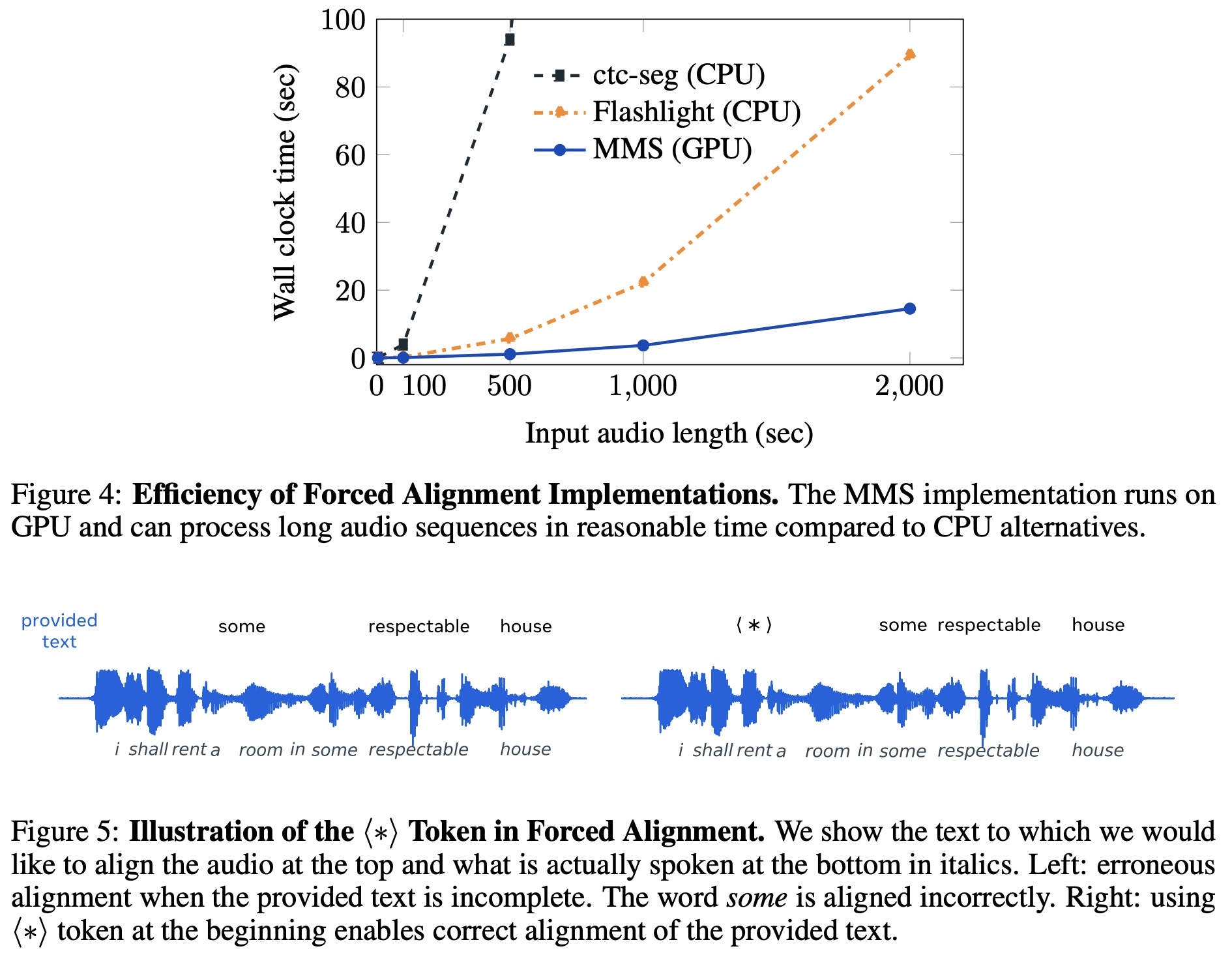
Forced alignment was then performed to find the most likely path in the posterior probabilities for a given audio sequence and its transcription. However, CPU versions of the Viterbi algorithm used for this were slow, especially for long recordings. As a solution, a GPU version was implemented to compute the Viterbi path in a more memory-efficient way, enabling faster alignment for lengthy audio sequences.
To handle noisy transcripts, a star token (⟨∗⟩) was introduced to map audio segments where there was no good text alternative. This was used at the start of each chapter’s text data and to replace numerical digits, significantly improving alignment accuracy.
Data Alignment

To conduct forced alignment in languages without existing datasets or acoustic models, a multilingual acoustic model is used. This model is trained on the FLEURS dataset and CommonVoice 8.0, covering 127 languages in total. It leverages fine-tuning of XLS-R, a speech recognition system, using 8K hours of data.
The text data is represented via the uroman transliteration tool, which translates various writing scripts into a Latin script representation. Initially, X-SAMPA was considered, but uroman was selected for its similar quality results and easier interpretability.
To further refine alignments, a new alignment model is trained using high-quality samples. These samples are selected based on a score representing the difference between the probability of the forced alignment path and the probability of greedy decoding from the alignment model, normalized by the length of the audio. This model, which spans 23K hours in 1,130 languages, is then used to regenerate verse-level alignments for the data.
Final Data Filtering
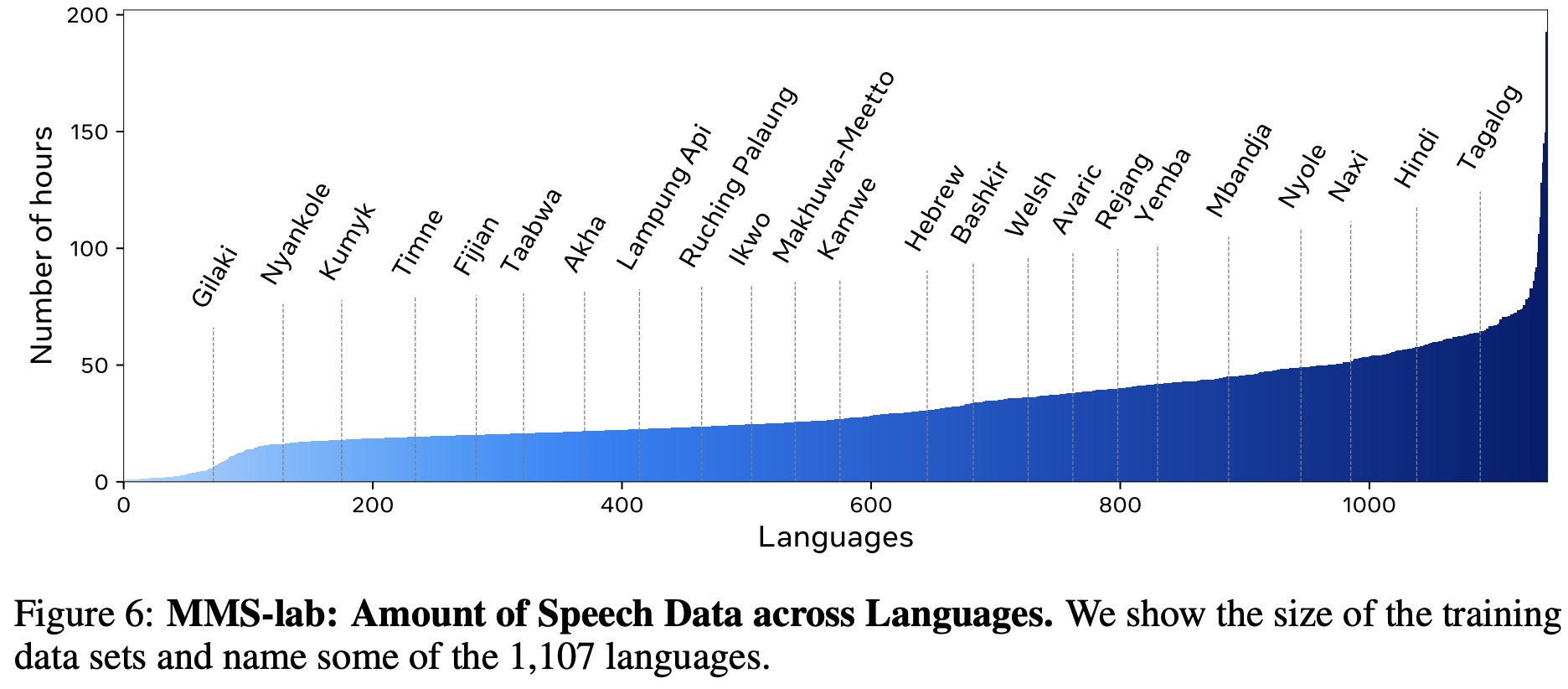
After creating improved alignments, a final data filtering step is performed to remove low-quality samples. This is done by training monolingual automatic speech recognition (ASR) models on half of the aligned samples for each recording, and then measuring the performance on the remaining half. Samples with a character error rate (CER) above 10% are removed, eliminating about 1.7% of all samples across all languages. In order to ensure the overall quality of recordings, those with a CER over 5% on the development set are also removed. After these filtering processes, a total of 1,239 recordings covering 1,107 languages are retained.
Unpaired Data for 3,809 Languages (MMS-unlab)
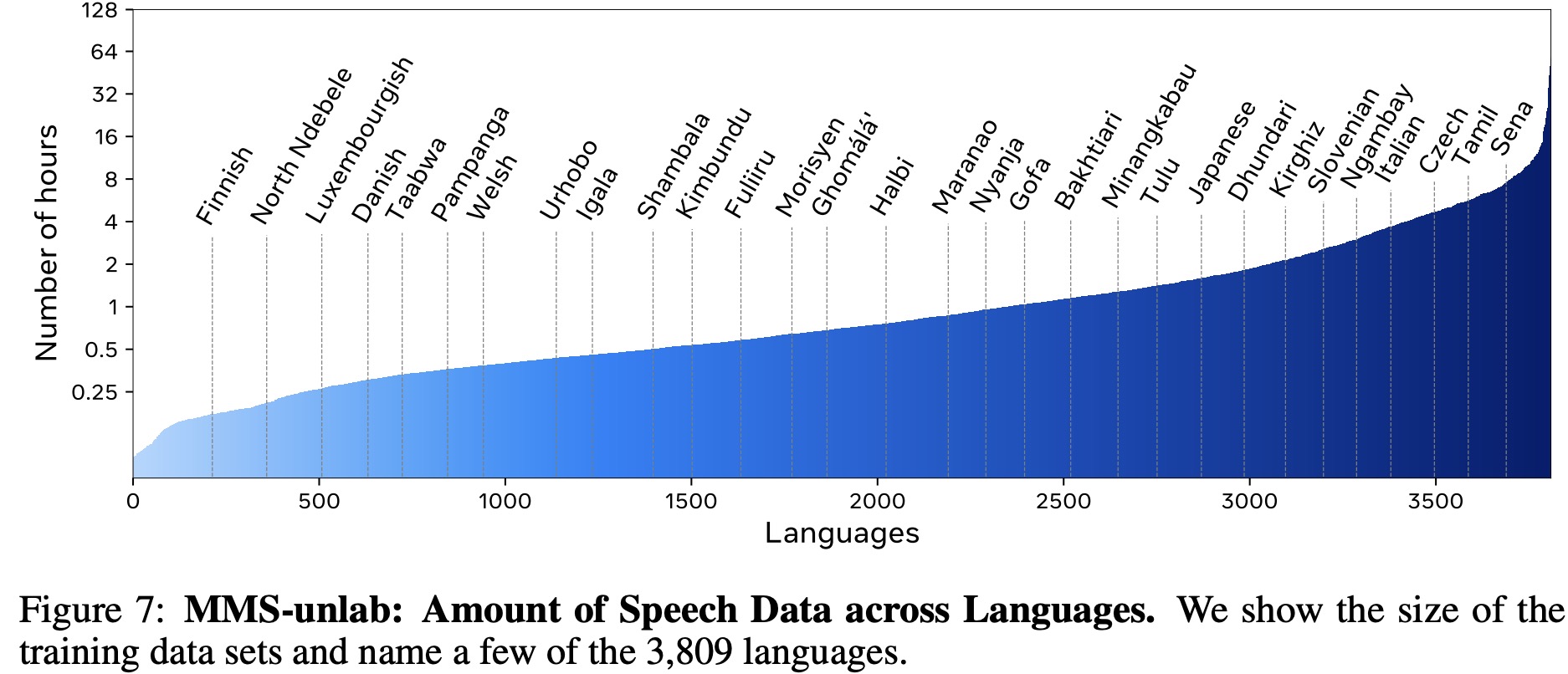
The dataset is sourced from Global Recordings Network, which provides Bible stories, evangelistic messages, scripture readings, and songs in over 6,255 languages and dialects. However, no text transcriptions are provided. The data is grouped by language, merging dialects of the same language, resulting in a total of 3,860 languages and 9,345 hours of audio. The audio files are pre-processed by converting them to a single channel with a 16kHz sample rate. The inaSpeechSegmenter, a CNN-based audio segmentation model, is then used to identify speech, music, noise, and silence in the audio. Speech segments separated by short instances of music or noise are joined, and non-speech segments are discarded. The speech segments are randomly split into lengths between 5.5 and 30 seconds to facilitate downstream model training, mirroring the average sample length of other datasets such as FLEURS.
Cross-lingual Self-supervised Speech Representation Learning
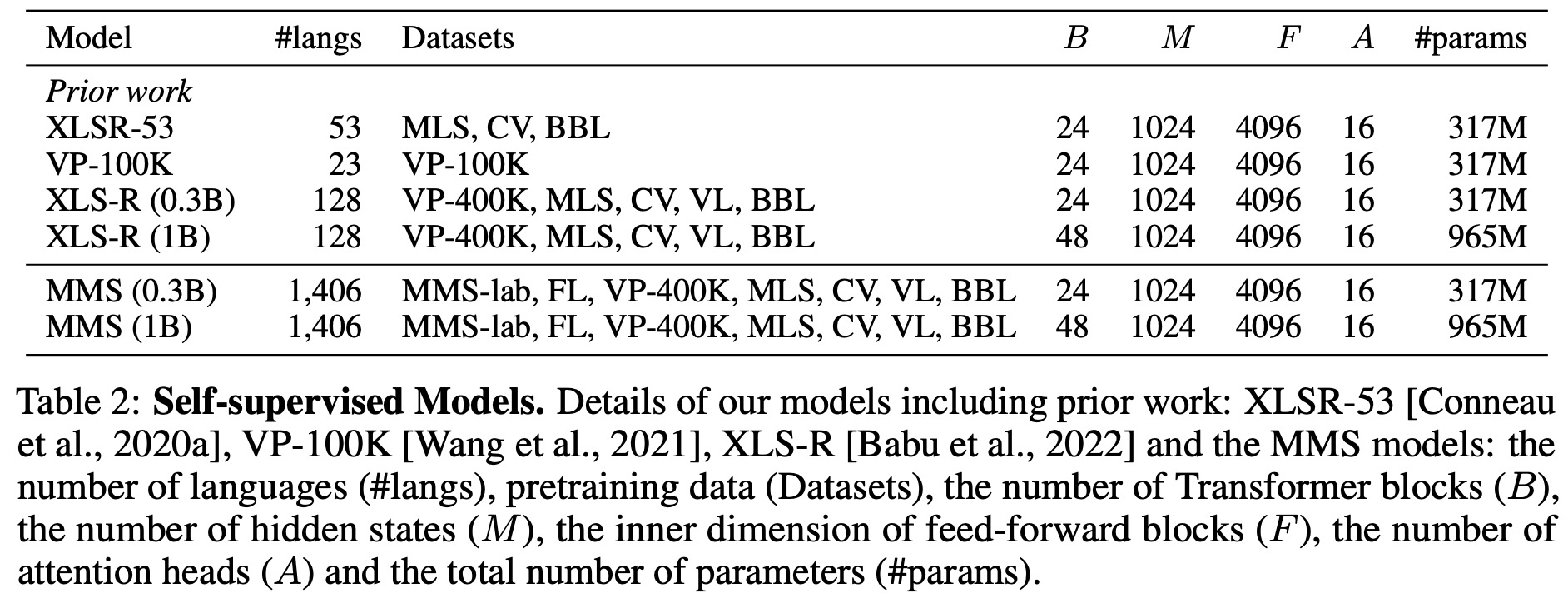
The researchers use wav2vec models, specifically wav2vec 2.0, which were pretrained on multilingual data. Wav2vec models are used to learn self-supervised speech representations from unlabeled speech data, with the derived models then employed for downstream speech tasks either through fine-tuning or unsupervised learning. Wav2vec 2.0 can construct speech recognition models with minimal labeled data or even none at all. Its basic architecture involves a convolutional feature encoder that maps raw audio to latent speech representations and a Transformer that outputs context representations.
During training, the feature encoder representations are discretized using a quantization module, and the model is trained by solving a contrastive task over masked feature encoder outputs. The XLSR and XLS-R versions of wav2vec 2.0 are trained on multiple languages from different datasets to acquire cross-lingual representations. To balance training data, two data sampling steps are employed that control the trade-off between high-resource and low-resource languages during pretraining.
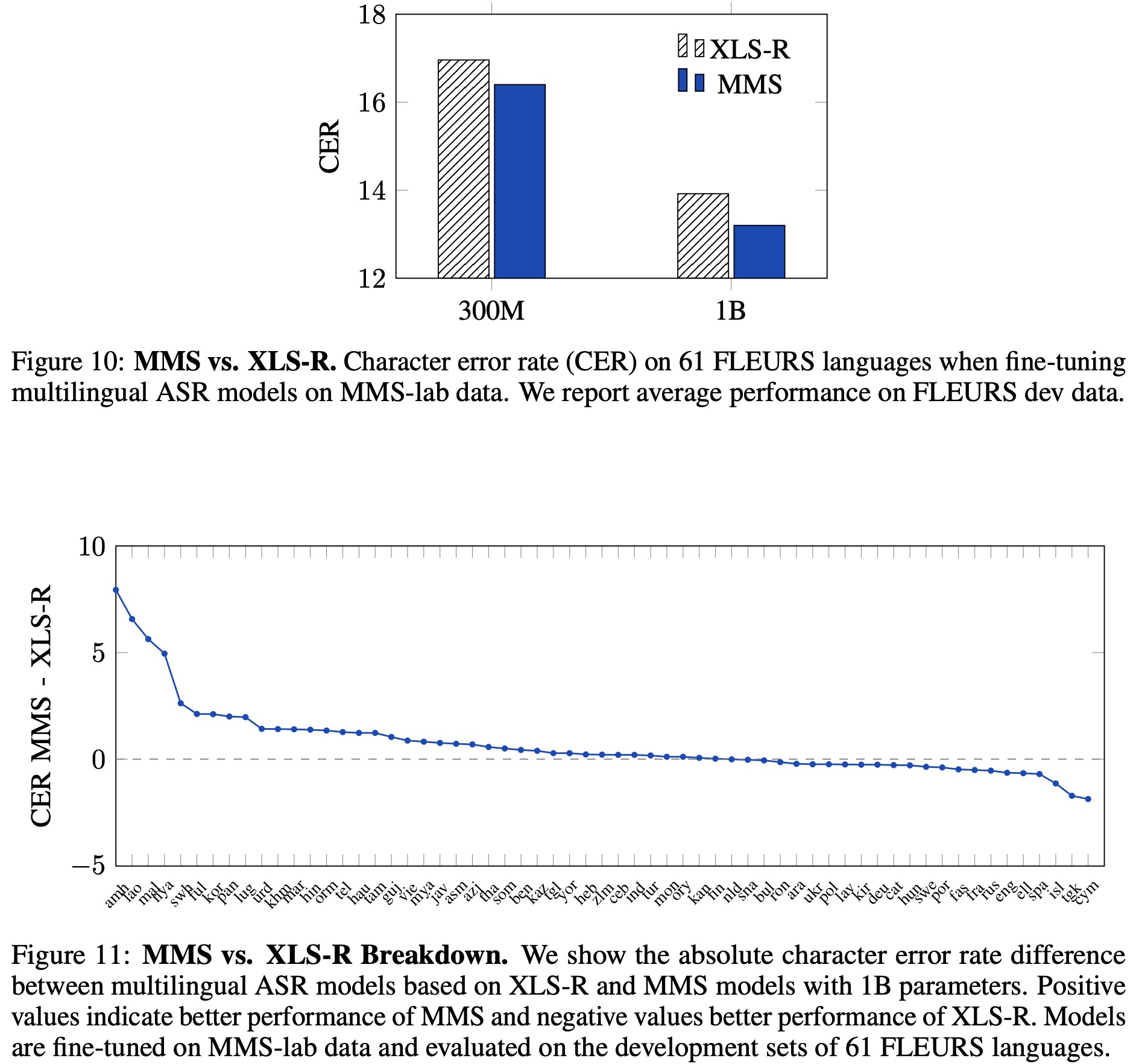
The researchers compared their Multilingual Multispeaker (MMS) models to the XLS-R models by fine-tuning both for automatic speech recognition on the 61 languages of the FLEURS benchmark, for which MMS-lab provides training data. Results showed that the MMS models outperformed XLS-R, with a lower average character error rate (CER) for both the 300B and 1B model sizes. More capacity improved performance for both models.
MMS pre-trained on more than ten times the number of languages as XLS-R, resulting in notably better performance on low-resource languages like Amharic, Lao, and Malayalam. Also, MMS’s pre-training data included languages that showed improvement, such as Chewa, Fulah, and Oromo. However, the focus on low-resource languages resulted in a slight performance drop in some high-resource languages like English and Spanish, with other languages like Tajik and Welsh also underperforming.
Automatic Speech Recognition
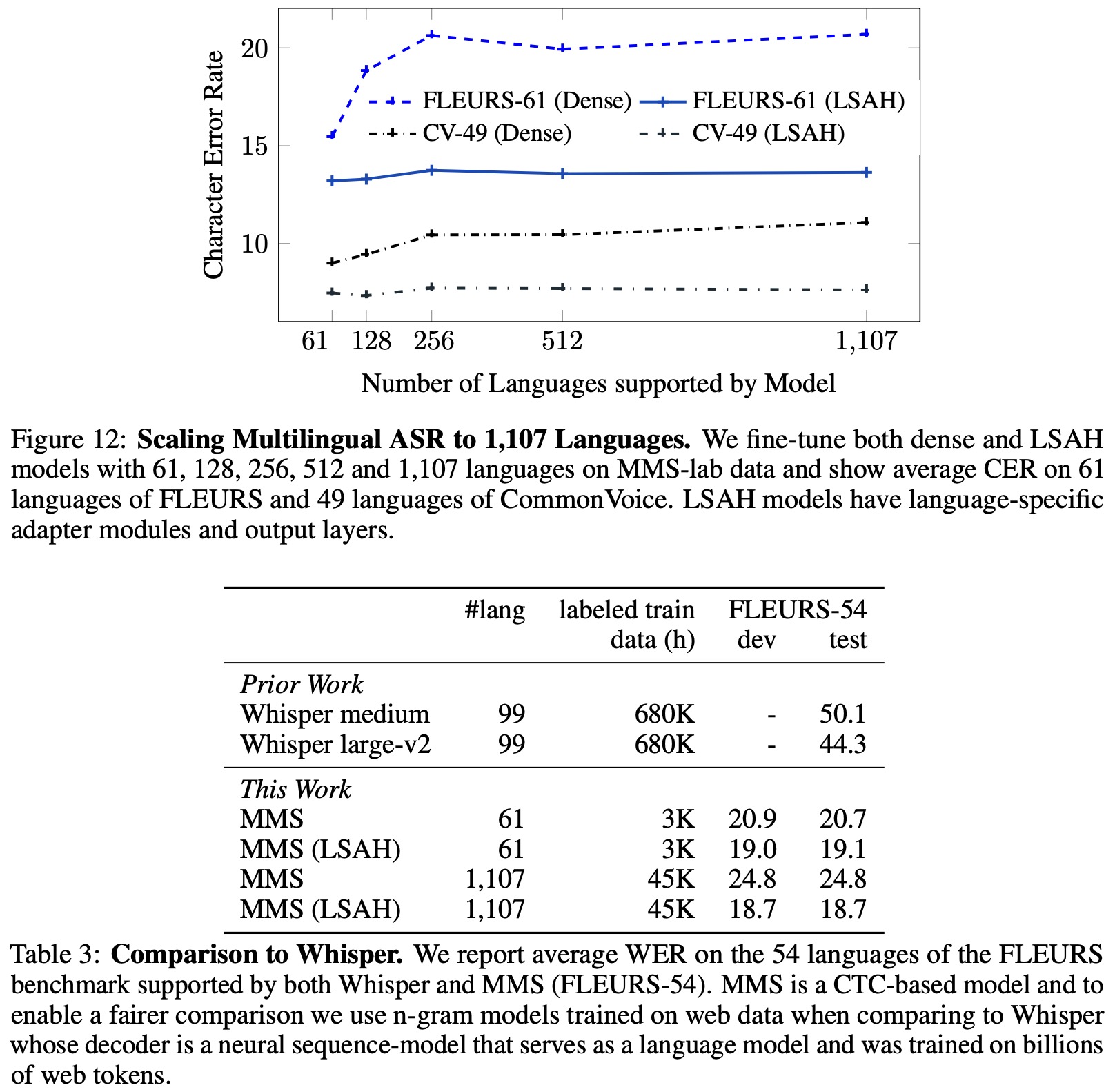
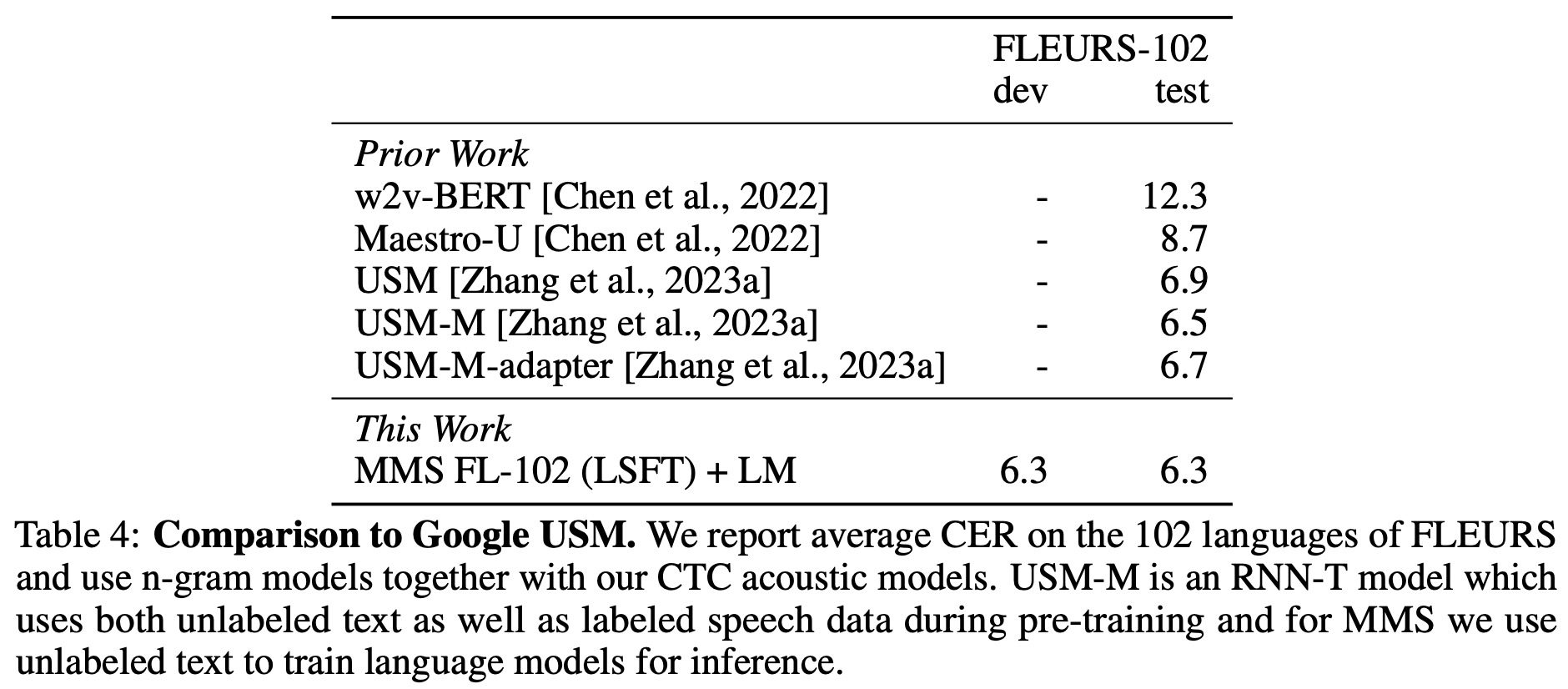
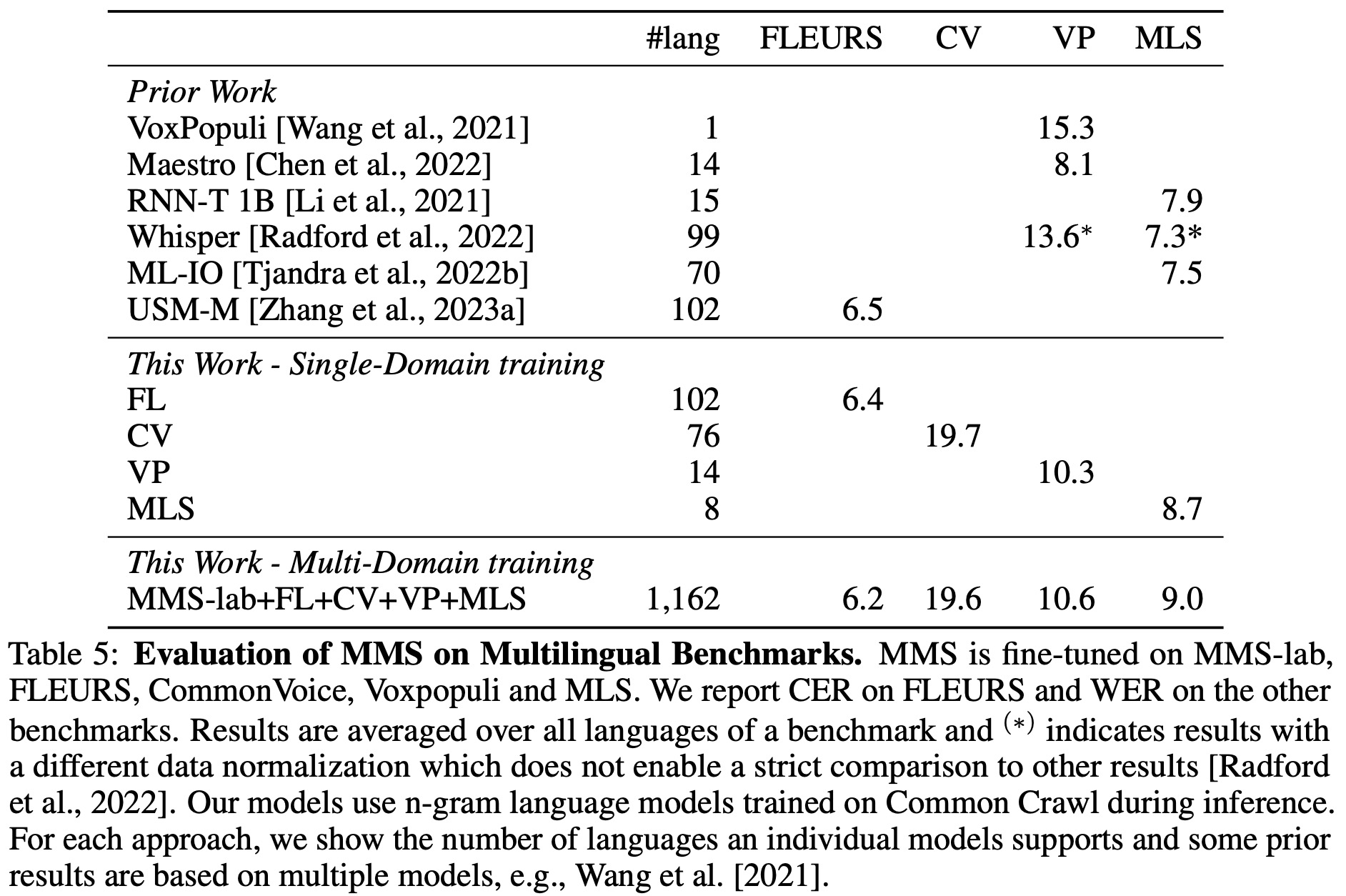
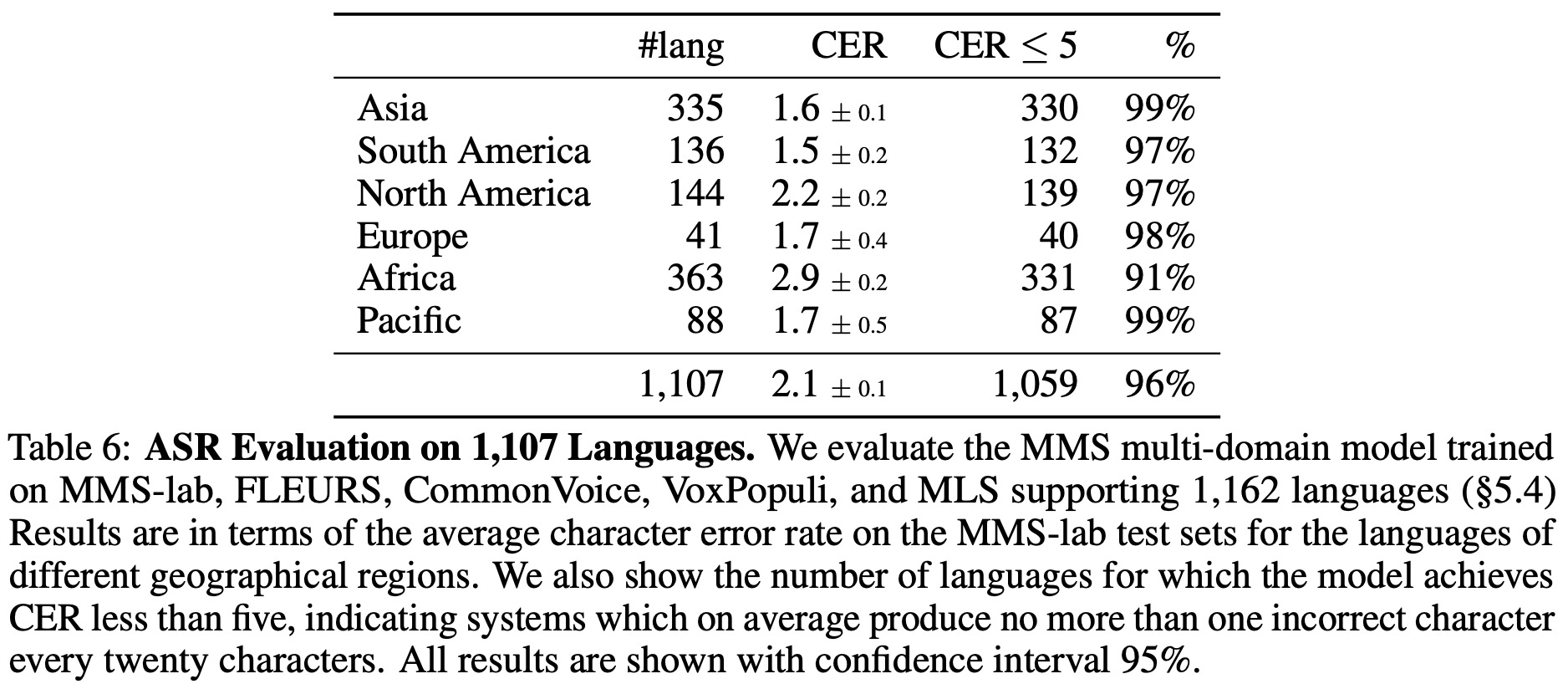
The researchers fine-tuned their pre-trained Multilingual Multispeaker (MMS) models using labeled data for multilingual speech recognition. A linear layer was added to the model to output transcriptions, mapping to an output vocabulary composed of letters from the labeled training data of all languages under consideration. The entire model was then fine-tuned with the Connectionist Temporal Classification (CTC) criterion.
In addition to training dense models, which share all parameters across languages, they also added language-specific adapter modules. These were introduced at every block of the transformer, specifically after the last feed-forward block. The adapter module consists of a LayerNorm layer, a downward linear projection followed by a ReLU activation, and an upward linear projection, with the inner dimension of the projections being 16.
Adding an adapter for each language increased the number of parameters by about 2%. The team then carried out a second stage of fine-tuning for each language, introducing a randomly initialized linear layer mapping to the specific output vocabulary of a language in addition to the language-specific adapter, and fine-tuned these additional parameters on the labeled data of the respective language.
- The results showed that dense models without language-specific parameters saw an increase in Character Error Rate (CER) as the number of languages increased, due to confusion between languages. However, using language-specific parameters mitigated this issue, resulting in minimal degradation in performance.
- MMS reduced the word error rate of Whisper by a relative 58% while supporting over 11 times the number of languages and requiring less labeled training data.
- Next, the MMS model was compared with Google’s Universal Speech Model (USM), which is trained on extensive proprietary YouTube audio. The MMS model performed very competitively compared to USM, despite differences in architecture and data usage.
- The researchers then utilized multi-domain training, fine-tuning the pre-trained MMS model on multiple datasets to support 1,162 languages. This multi-domain model performed competitively across several benchmarks, outperforming previous works and single-domain baselines for FLEURS and CommonVoice, while it was slightly worse for VoxPopuli and MLS.
- Finally, the multi-domain model trained on various datasets was evaluated on all 1,107 languages’ test sets in MMS-lab, measuring character error rate across six geographical regions. The model met a quality threshold (CER ≤ 5) for 96% of the languages, indicating broad, high-quality language coverage.
Language Identification
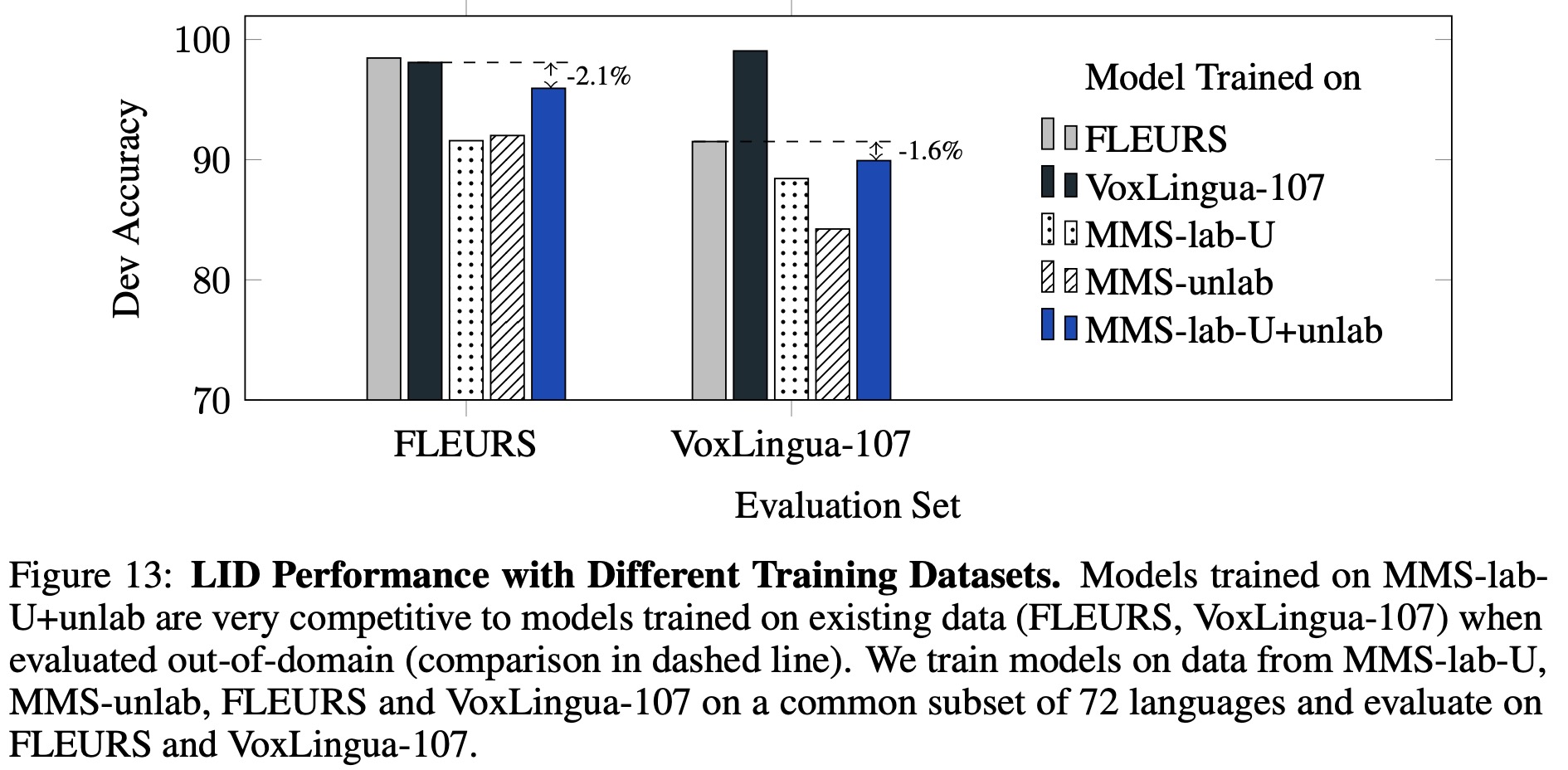
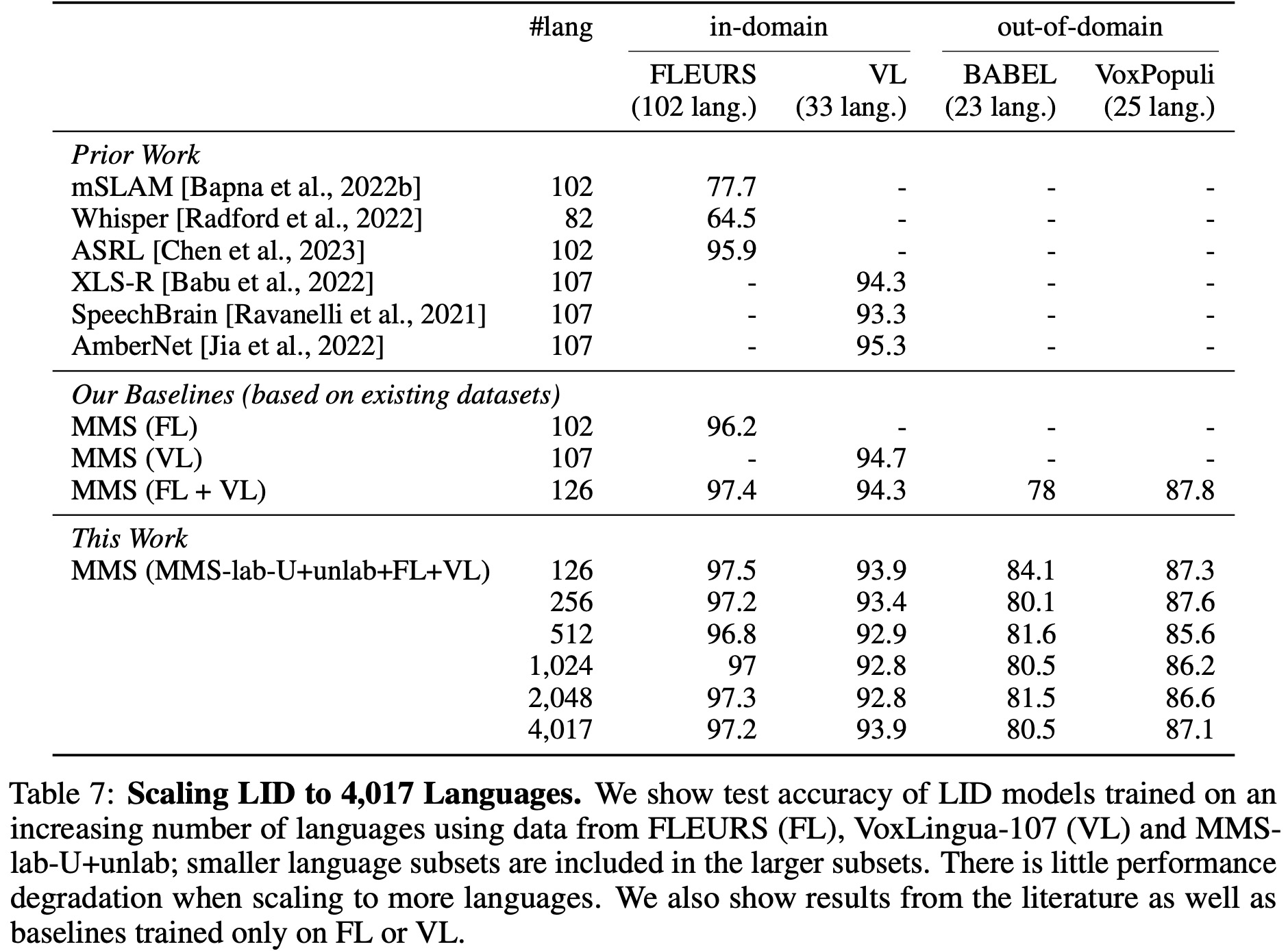
Language Identification (LID) is the task of determining which language is spoken in a given utterance. LID is crucial for multilingual speech recognition and for mining speech data from the web. However, the most diverse public datasets only span about 100 languages.
- The authors first evaluated the effectiveness of training LID models on MMS-lab-U and MMS-unlab data compared to existing LID training data. They found that while existing in-domain training data performed best, MMS-lab-U and MMS-unlab enabled good quality LID models with a slight drop in performance.
- Next, the researchers expanded language identification from about 100 languages to 4,017 languages by combining MMS-lab-U, MMS-unlab, FLEURS, and VoxLingua-107 data. They found that as they added more languages, there was only a small drop in performance. The expanded model even outperformed some baseline models trained only on specific datasets, demonstrating the potential of scaling LID to thousands of languages without significantly compromising accuracy.
Speech Synthesis
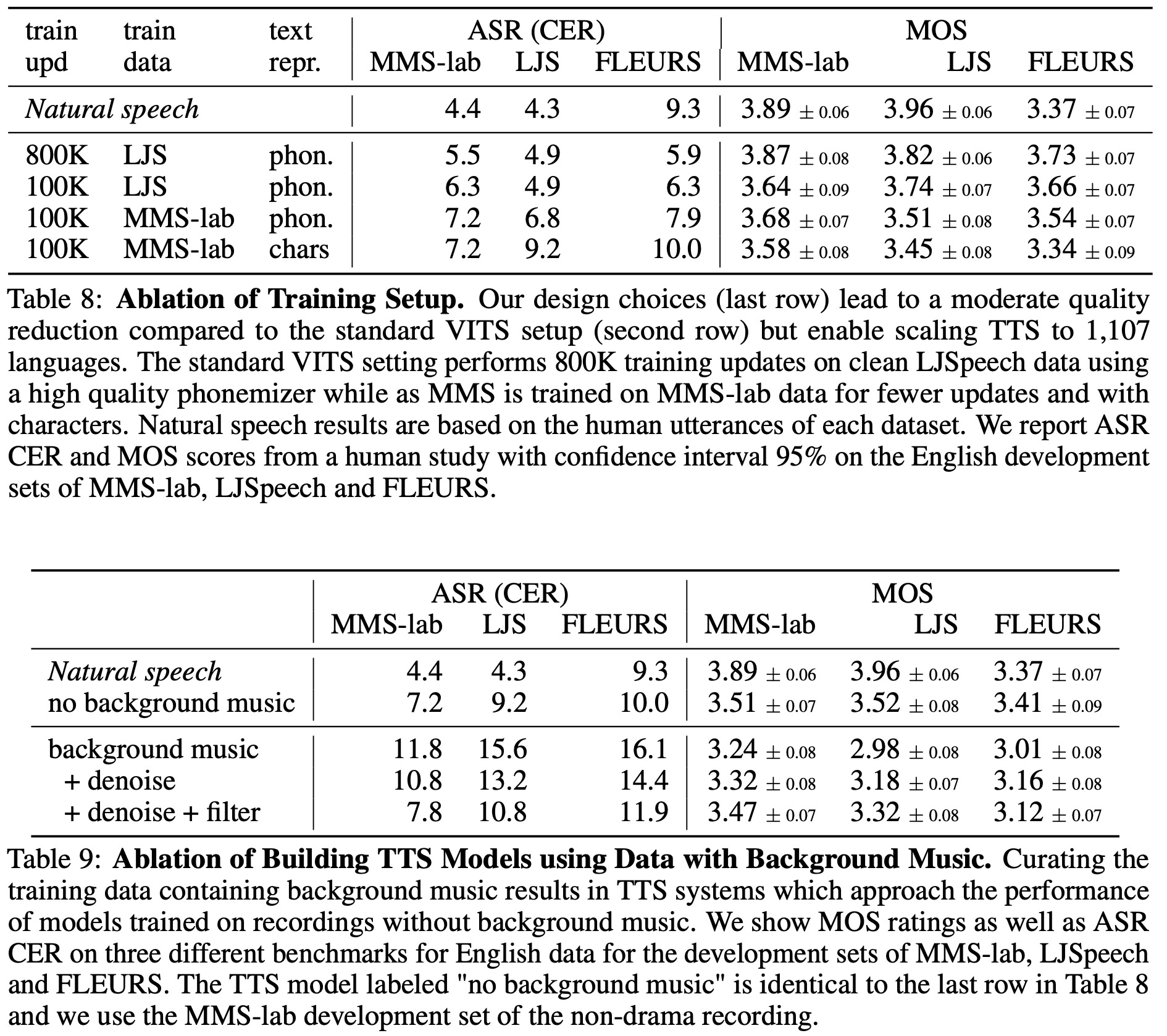
The authors discuss scaling a state-of-the-art Text-to-Speech (TTS) model, VITS, from three languages to 1,107 languages. VITS generates speech from text sequences and uses a flow-based sub-network and a text encoder to generate audio features. The waveform is then decoded using a stack of transposed convolutional layers adapted from HiFi-GAN. The model is trained end-to-end with losses derived from variational lower bound and adversarial training.
The authors train separate VITS models for each language, mostly using the same hyperparameters as in the original VITS model but training each model for fewer steps. This decreases the quality slightly but reduces training time significantly.
For training data, the authors use the MMS-lab dataset, which provides paired speech and text data. They ensure that only a single recording is used for each language, choosing based on which recording achieves the lowest Character Error Rate (CER) in an out-of-domain evaluation set.
Instead of using grapheme-to-phoneme tools that rely on lexicons, the authors represent input text as individual letters for languages with a small vocabulary. For languages with 200 or more characters, they use a uroman encoding.
Finally, the authors take steps to improve the quality of their TTS models by using a denoiser model to remove background music from drama recordings and removing utterances that likely contain multiple speakers. This is achieved by detecting and removing utterances with high variance in pitch.
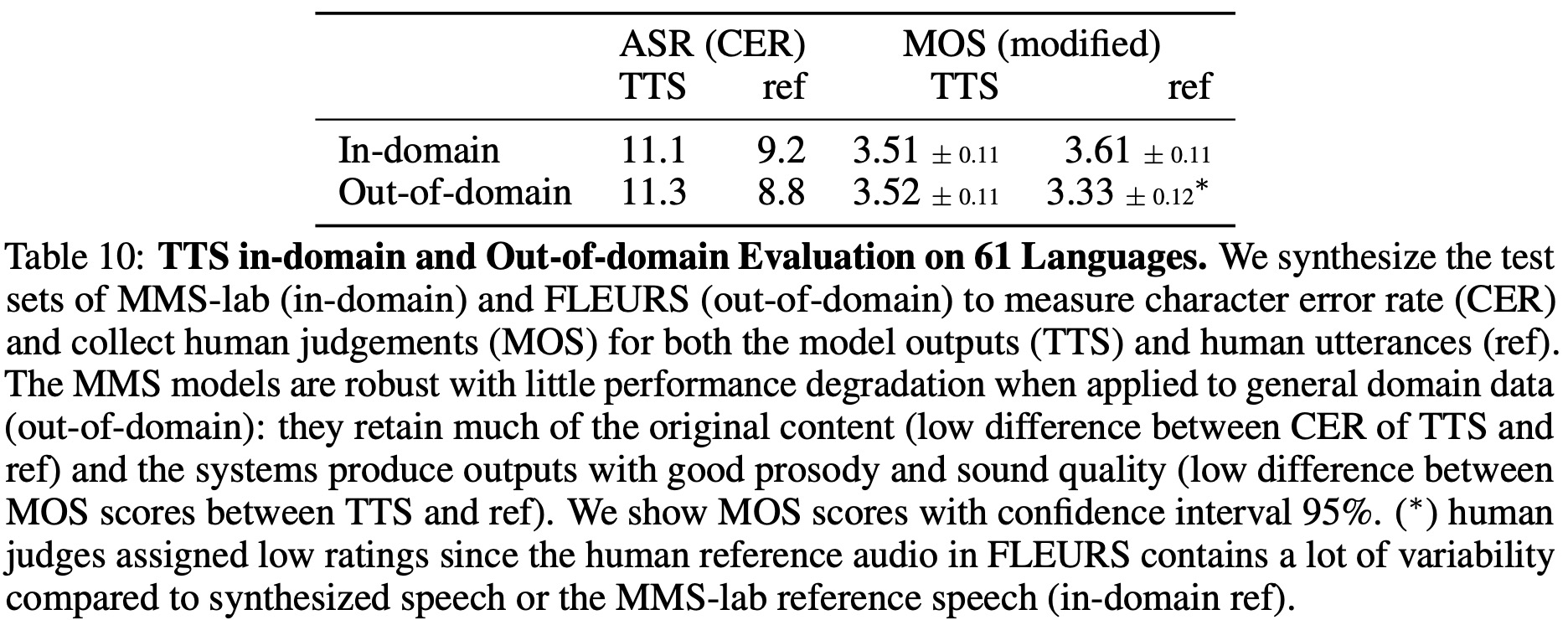
Experiments shows that the models are robust to domain shift, with only a slight increase in Character Error Rate (CER) when evaluated out-of-domain. The Mean Opinion Score (MOS), a measure of perceived quality, is nearly identical for in-domain and out-of-domain evaluations. The authors conclude that TTS models trained on MMS-lab data perform well out-of-domain. However, the quality of sound is slightly lower compared to human utterances, particularly for out-of-domain data where the noise level is high.
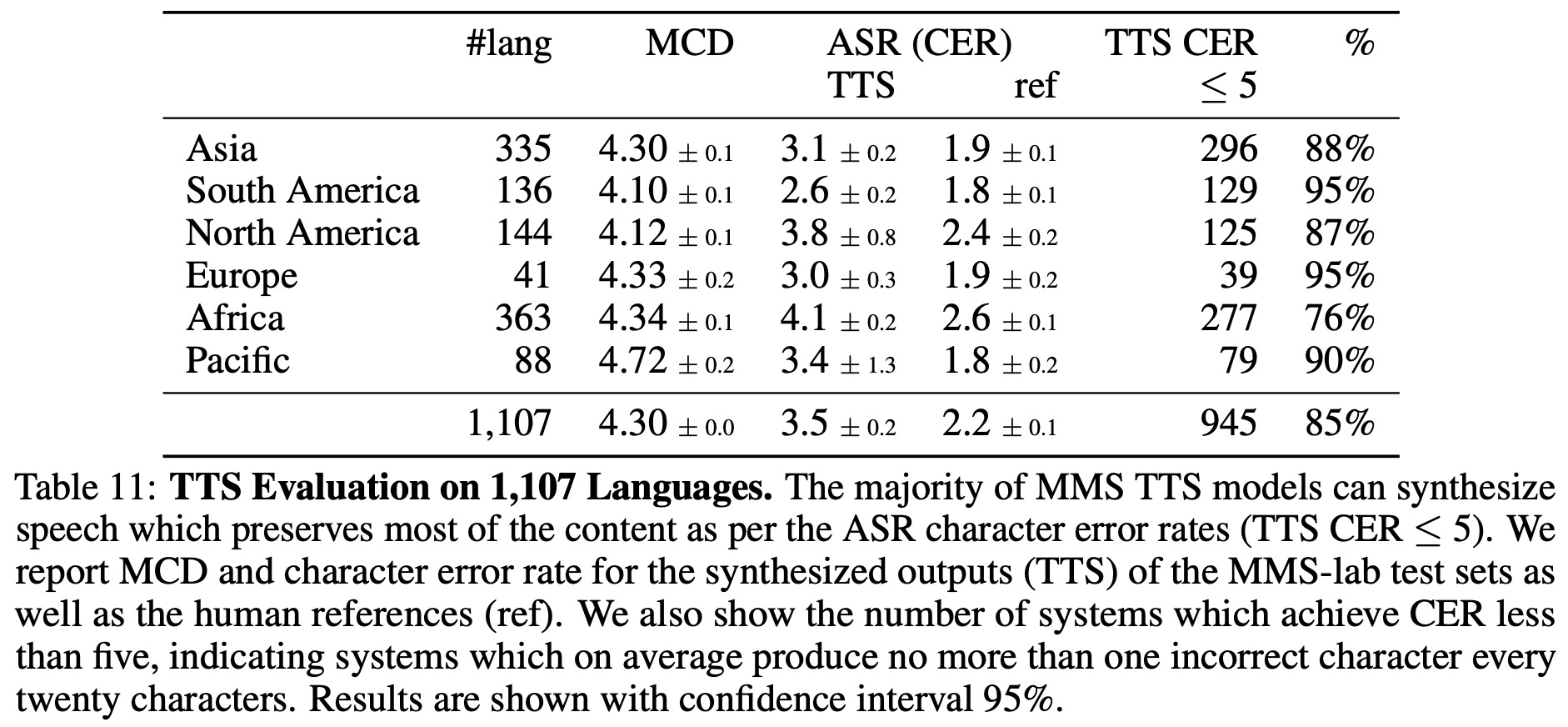
Finally, the authors train models for all languages in the MMS-lab dataset. They focus on in-domain evaluation because finding out-of-domain evaluation data for such a large number of languages is challenging. The results show that approximately 85% of the 1,107 languages meet the CER quality threshold of ≤ 5. The highest rates of quality are achieved by South American and European languages (95%), and the lowest by African languages (76%). This variation is partly attributed to differences in writing scripts.
Bias Analysis and Ethical Considerations
The authors explore potential gender and content bias in the models trained on MMS-lab data.
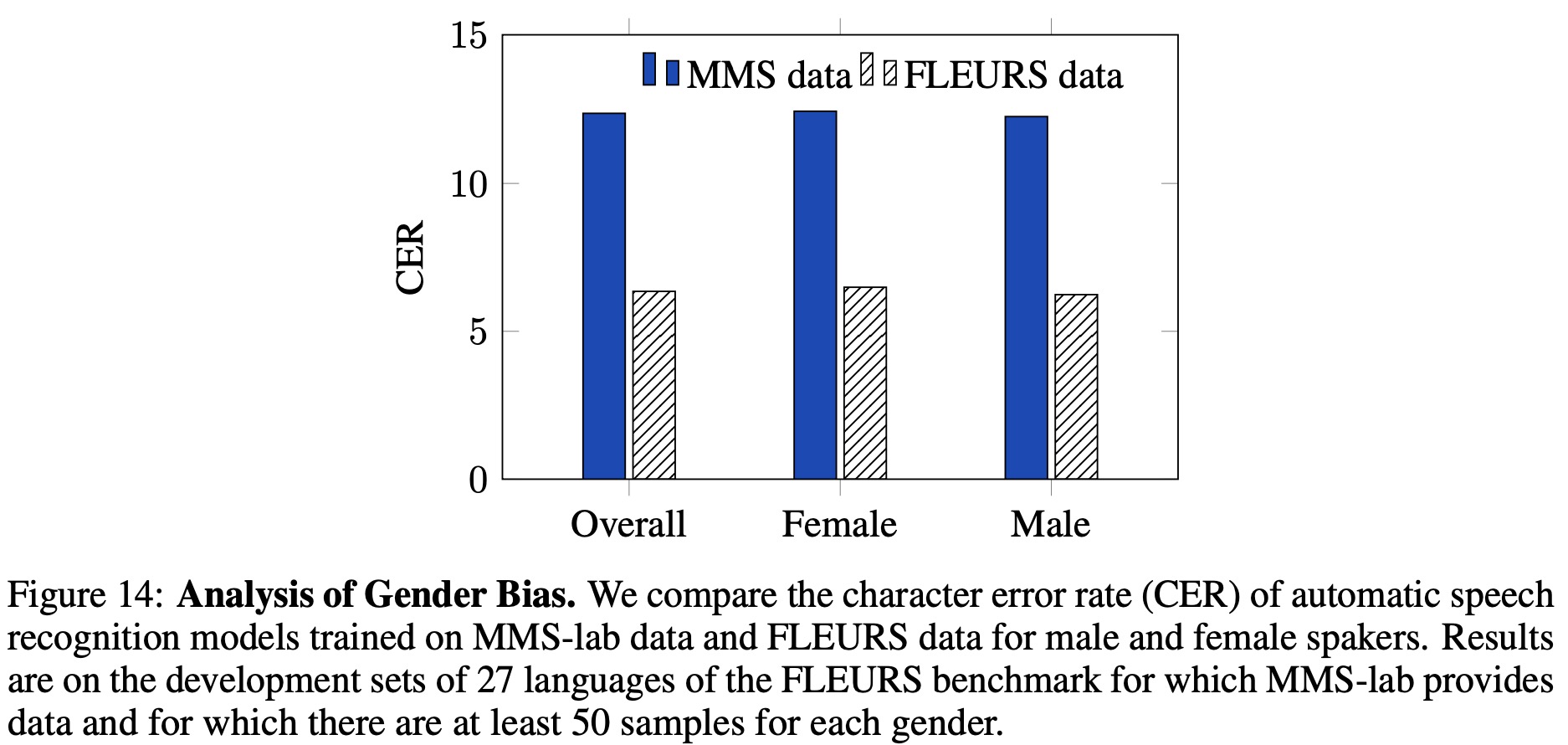
In terms of gender bias, they evaluate models on the FLEURS development set, which includes speaker gender metadata. The character error rate across 27 languages is similar for both genders, although there can be significant differences within a specific language. There doesn’t seem to be a consistent gender bias, as error rates are higher for male speakers in 14 languages and for female speakers in 13 languages. The authors conclude that their models exhibit similar gender bias to models trained on general domain data.
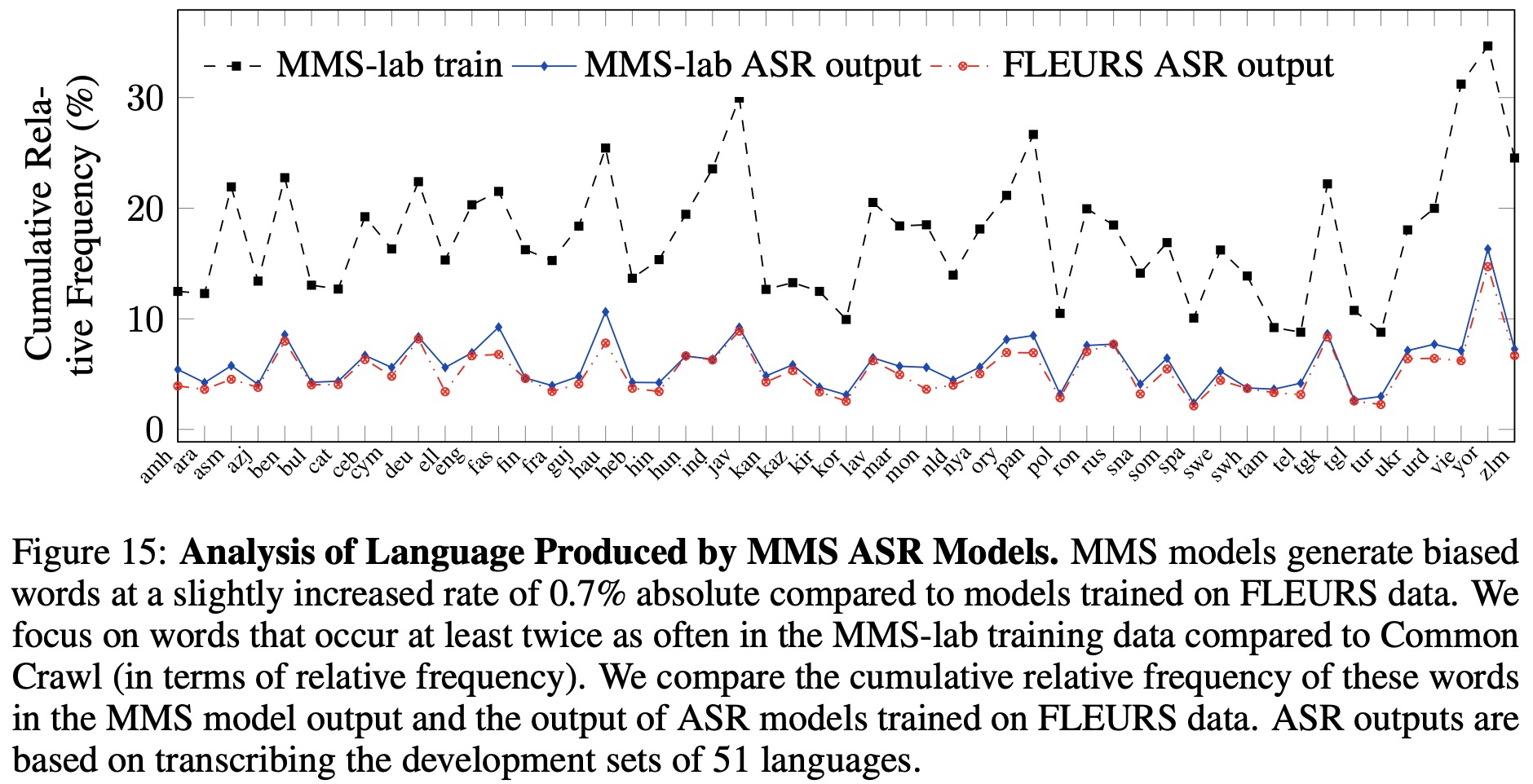
Regarding content bias, the authors devise an automatic procedure to identify potentially biased words in each language, comparing the frequency of these words in MMS-lab data to their frequency in a general domain corpus (Common Crawl). Models trained on MMS-lab data and FLEURS are tasked to transcribe the FLEURS development set. They find that the rate of potentially biased words is lower in the output of MMS models compared to the training data, indicating a mild bias. However, for many languages, MMS models generate these words at the same rate as the FLEURS models.
Finally, they note that their method of identifying biased words has low precision but does capture words which are likely more used in religious contexts. For languages with the largest discrepancies, they consult with native speakers to verify the nature of the biased words.
paperreview deeplearning audio pytorch speechrecognition tts speech