Paper Review: NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
This paper presents NaturalSpeech 2, an upgraded text-to-speech (TTS) system designed to better capture the diversity and nuances of human speech, including different speaker identities, prosodies, styles, and even singing. The new system addresses the shortcomings of existing TTS systems, such as unstable prosody, word skipping/repetition, and poor voice quality. It uses a neural audio codec with residual vector quantizers to obtain quantized latent vectors, and a diffusion model to generate these vectors based on text input.
A novel feature of NaturalSpeech 2 is its speech prompting mechanism which enhances its zero-shot learning capabilities, crucial for diverse speech synthesis. This mechanism also aids in-context learning in the diffusion model and the duration/pitch predictor.
The system has been scaled to large datasets comprising 44,000 hours of speech and singing data. The evaluation shows that NaturalSpeech 2 significantly outperforms previous TTS systems in terms of prosody/timbre similarity, robustness, and voice quality in a zero-shot setting. Interestingly, it also demonstrates the ability to perform zero-shot singing synthesis from just a speech prompt.
Preface
Traditional text-to-speech (TTS) models, which are trained on speaker-limited and recording-studio datasets, fail to adequately capture the diversity of speaker identities, prosodies, and styles in human speech due to a lack of data diversity. The paper suggests using large-scale corpora to train TTS models to learn these diversities, which could allow these models to generalize to unseen scenarios via few-shot or zero-shot technologies.
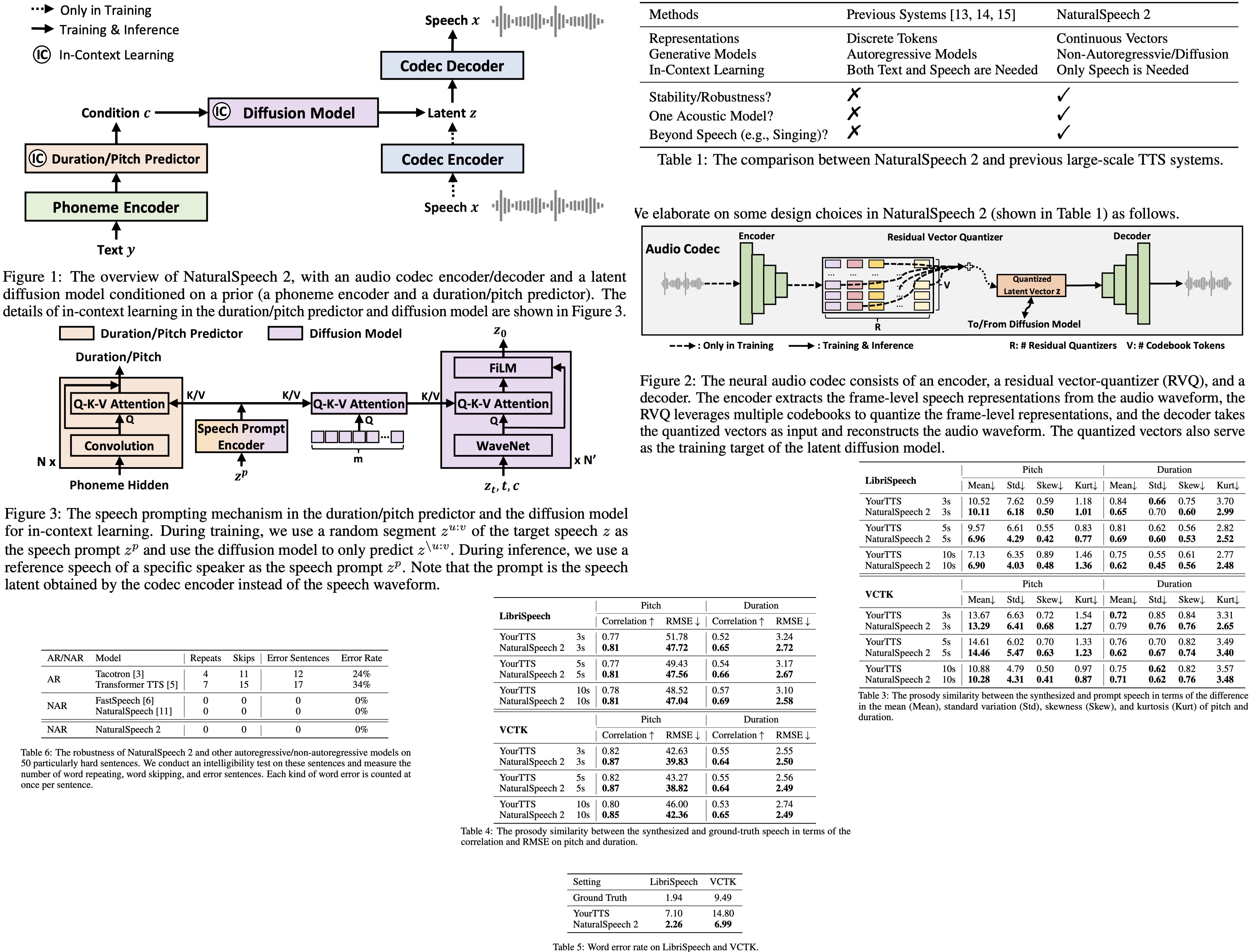
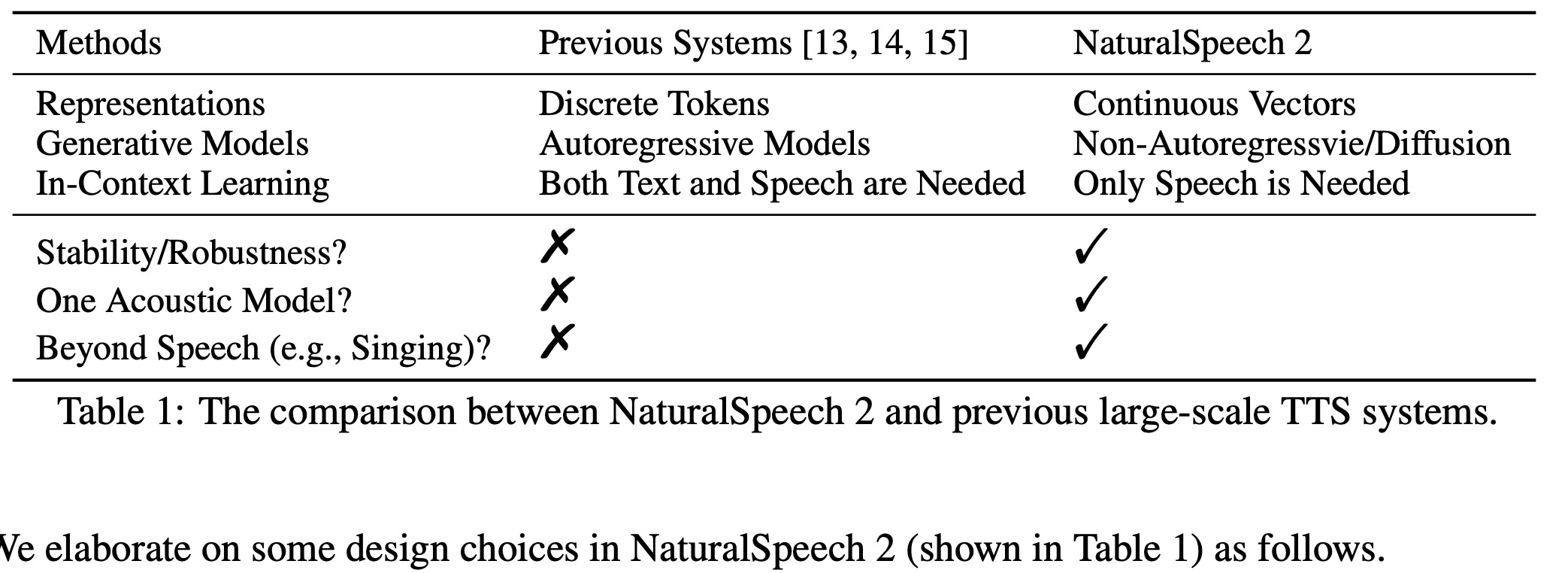
Current large-scale TTS systems typically quantize continuous speech waveforms into discrete tokens and then model these tokens with autoregressive language models. This approach suffers from several limitations. First, the sequence of speech tokens is usually very long (a 10-second speech could have thousands of tokens), leading to error propagation and unstable speech outputs in the autoregressive models.
Second, there’s a trade-off between the codec and language model. A codec with token quantization, such as VQ-VAE or VQ-GAN, usually results in a low bitrate token sequence. While this simplifies language model generation, it also leads to the loss of high-frequency, fine-grained acoustic details. Conversely, some methods use multiple residual discrete tokens to represent a speech frame, which significantly increases the length of the token sequence if flattened, thus posing a challenge for language modeling.
NaturalSpeech 2
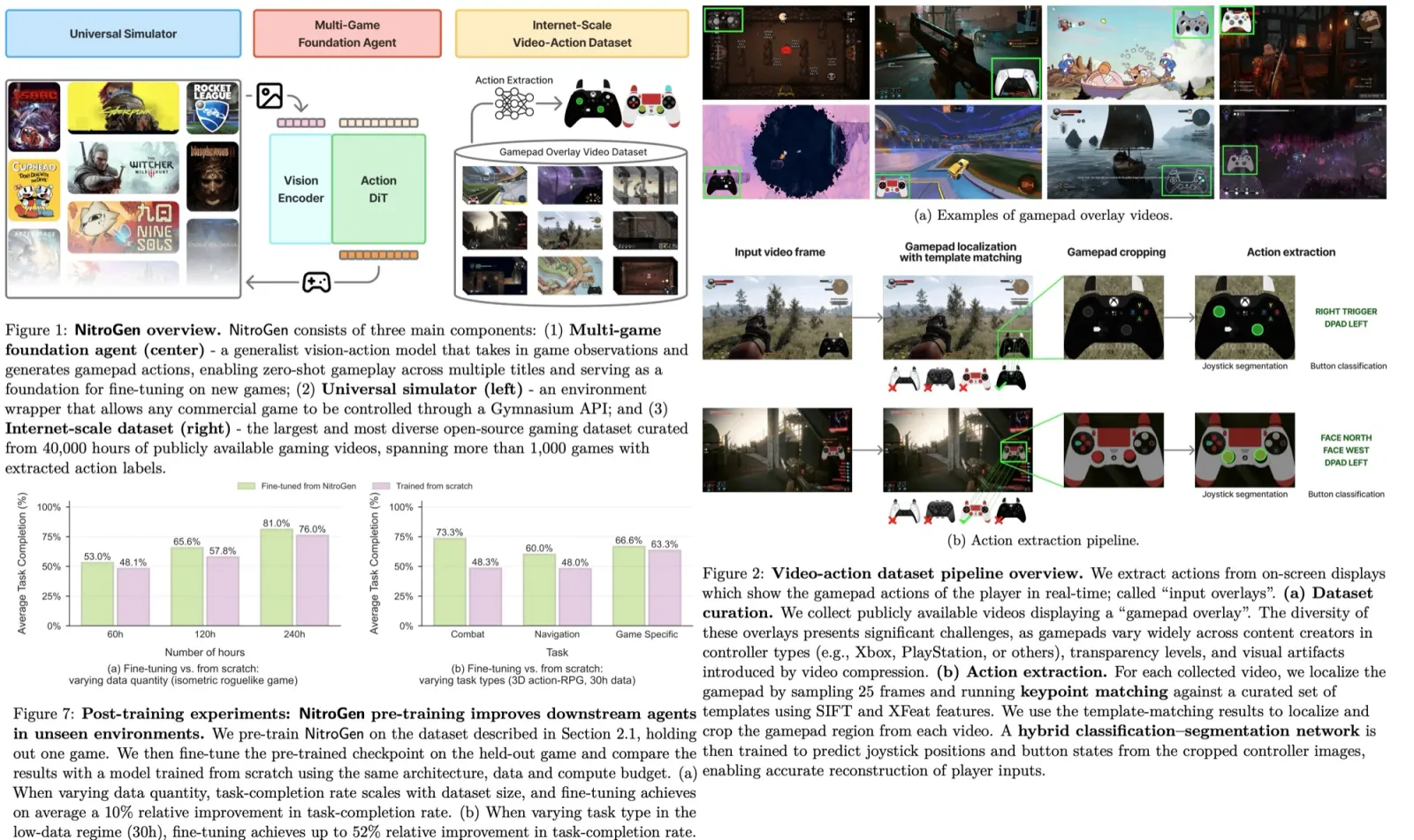
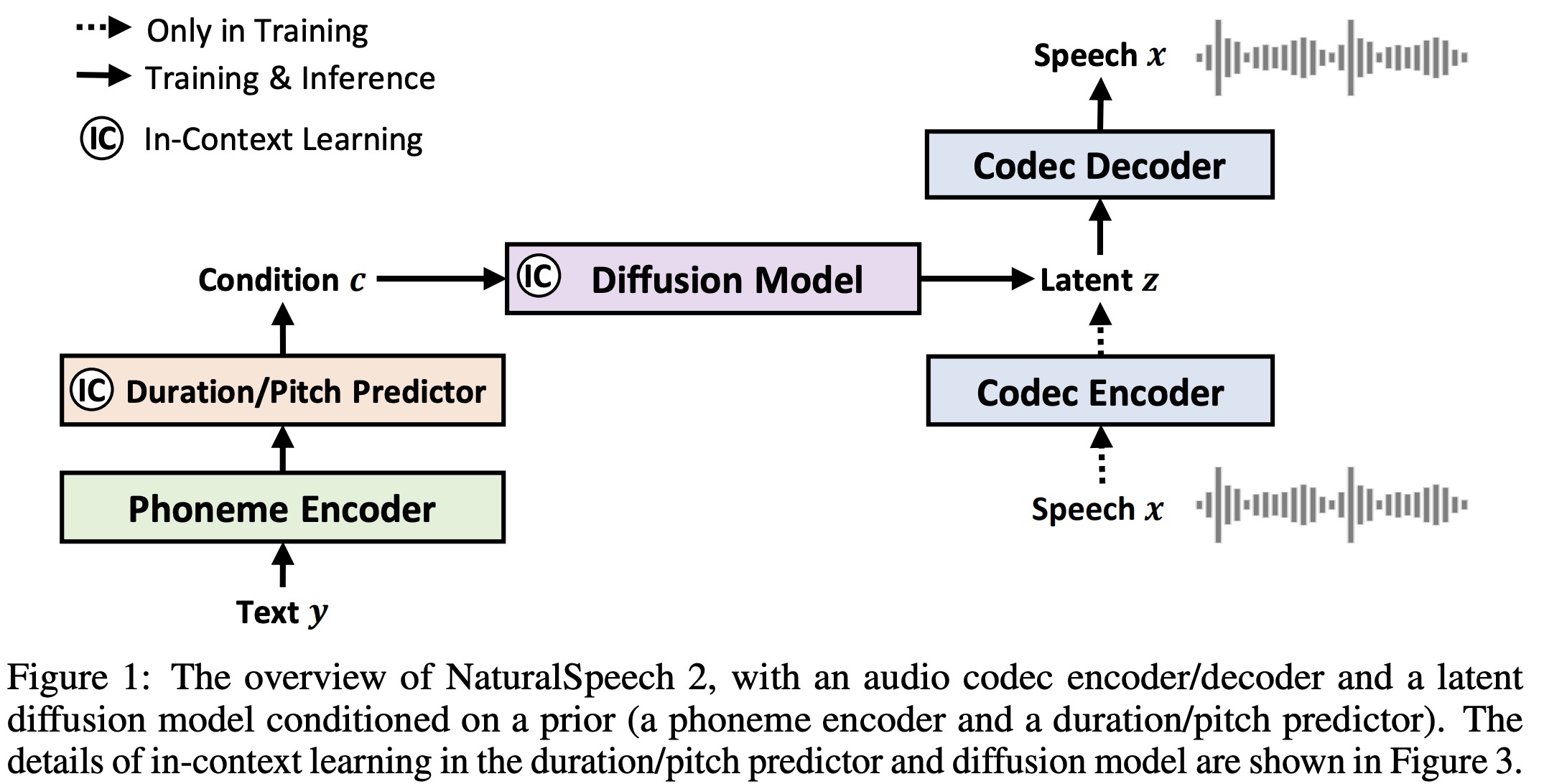
In NaturalSpeech 2, a neural audio codec is first trained to convert a speech waveform into a sequence of latent vectors using a codec encoder, and then reconstruct the speech waveform from these latent vectors using a codec decoder. After training the audio codec, the codec encoder is used to extract the latent vectors from the speech in the training set. These vectors are then used as targets for the latent diffusion model, which is conditioned on prior vectors obtained from a phoneme encoder, a duration predictor, and a pitch predictor.
During the inference process, the latent diffusion model is first used to generate the latent vectors from the text/phoneme sequence. These latent vectors are then converted into a speech waveform using the codec decoder.
The following are the key design choices made in the development of the NaturalSpeech 2:
Neural Audio Codec with Continuous Vectors
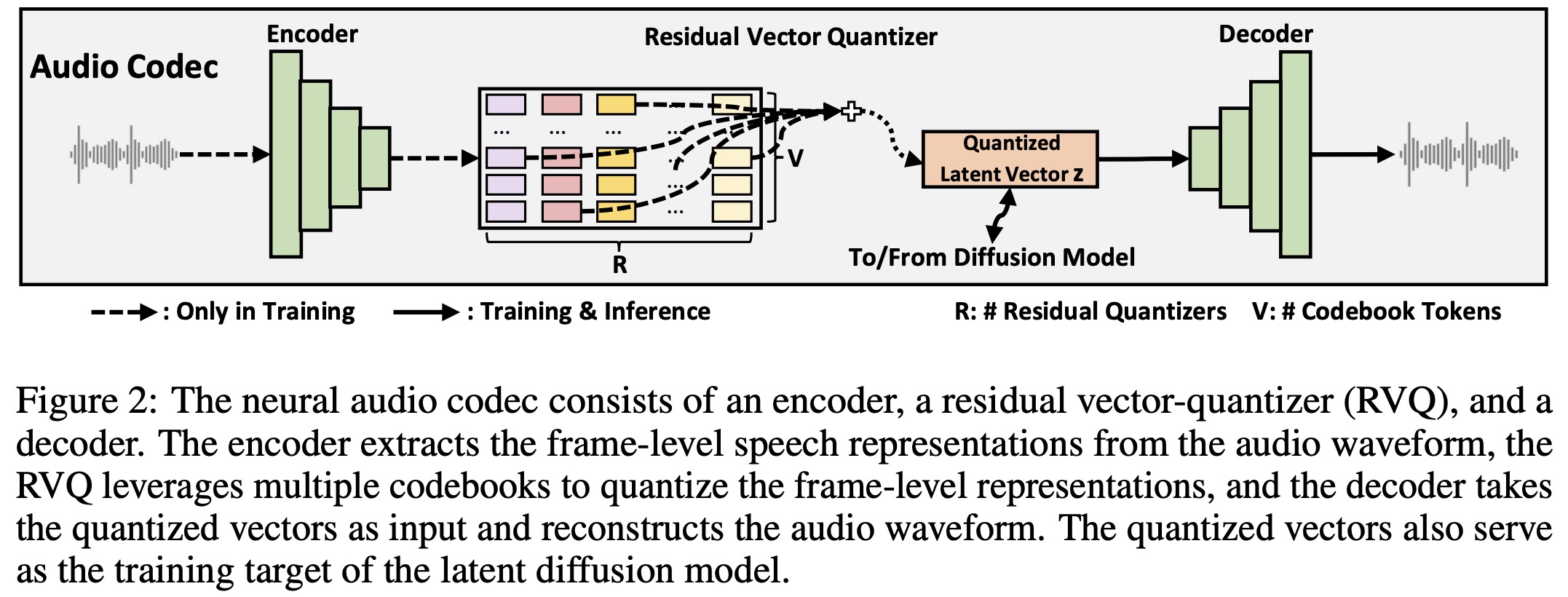
The NaturalSpeech 2 system uses a neural audio codec to convert speech waveforms into continuous vectors rather than discrete tokens. This method offers several benefits:
- Continuous vectors have a lower compression rate and higher bitrate than discrete tokens, ensuring high-quality audio reconstruction.
- Each audio frame contains just one vector, unlike discrete quantization, which uses multiple tokens. This means the length of the hidden sequence doesn’t increase.
The neural audio codec consists of an audio encoder, a residual vector-quantizer (RVQ), and an audio decoder:
- The audio encoder uses convolutional blocks with a total downsampling rate of 200 for 16kHz audio, which means each frame corresponds to a 12.5ms speech segment.
- The RVQ converts the output of the audio encoder into multiple residual vectors. The sum of these vectors is used as the training target of the diffusion model.
- The audio decoder mirrors the audio encoder’s structure, generating the audio waveform from the quantized vectors.
In practice, for regularization and efficiency, the system uses residual vector quantizers with a large number of quantizers and codebook tokens to approximate the continuous vectors. This approach has two benefits:
- During the training of latent diffusion models, it is not necessary to store memory-costly continuous vectors. Instead, the system stores the codebook embeddings and quantized token IDs used to derive the continuous vectors.
- When predicting continuous vectors, an additional regularization loss on discrete classification can be added based on these quantized token IDs.
Latent Diffusion Model with Non-Autoregressive Generation
The authors use a diffusion model (instead of an autoregressive model) to predict the quantized latent vector conditioned on the text sequence. This is achieved through a prior model consisting of a phoneme encoder, duration predictor, and pitch predictor to provide more informative hidden vectors.
Diffusion process is described using a stochastic differential equation (SDE). The forward SDE transforms the latent vectors into Gaussian noises. The reverse SDE transforms the Gaussian noise back into data. An ordinary differential equation (ODE) can also be considered in the reverse process. A neural network is used to estimate the score or the gradient of the log-density of noisy data.
In this formulation, the neural network is based on WaveNet, which takes the current noisy vector, the time step, and the condition information as input and predicts the data. This approach results in better speech quality. The loss function to train the diffusion model includes a data loss term, a score loss term, and a cross-entropy loss based on a residual vector-quantizer (RVQ).
The prior model consists of a phoneme encoder and duration/pitch predictors. The phoneme encoder has several Transformer encoder layers, modified to use a convolutional network. Both the duration and pitch predictors share the same model structure, with different model parameters. During training, the ground-truth duration and pitch information are used as the learning target. The ground-truth duration is used to expand the hidden sequence from the phoneme encoder, and then the ground-truth pitch information is added to the frame-level hidden sequence to get the final condition information. During inference, the corresponding predicted duration and pitch are used.
Speech Prompting for In-Context Learning
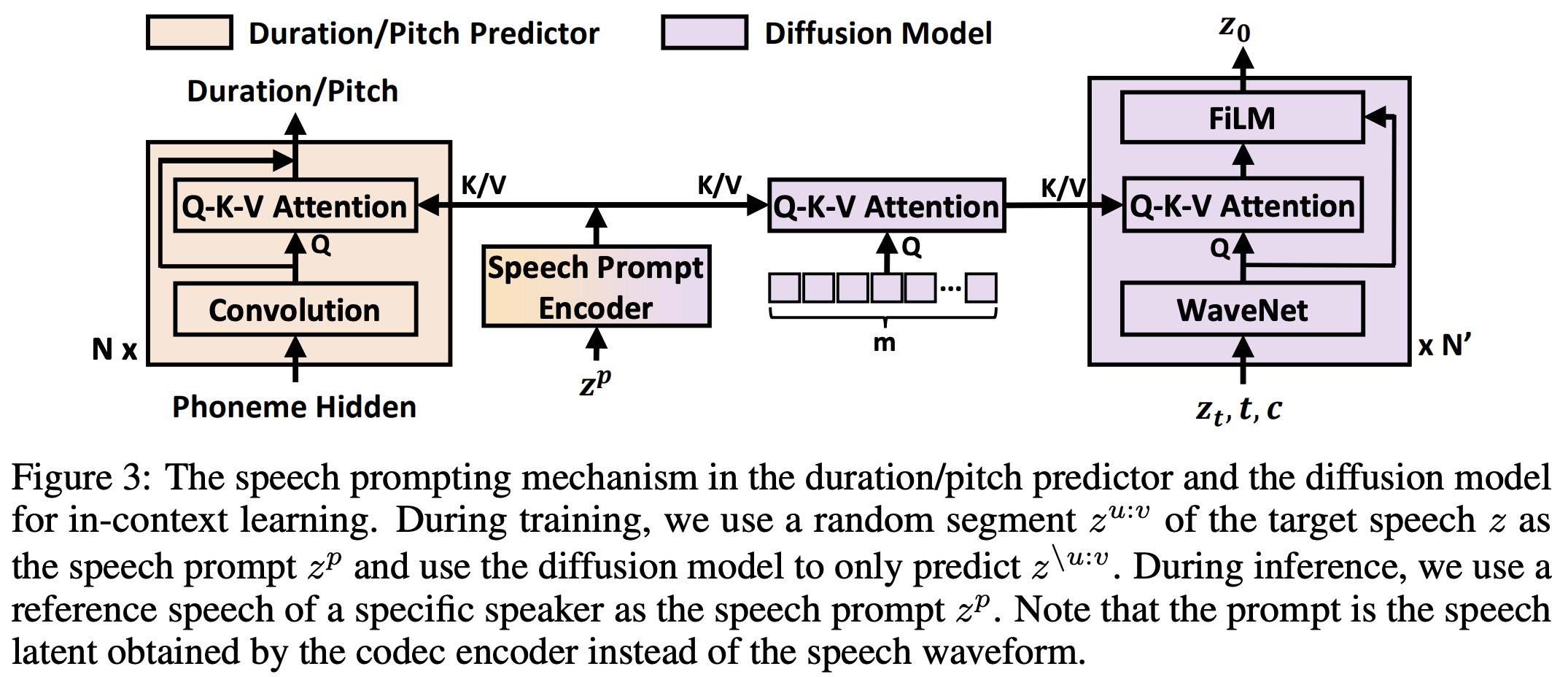
The authors have designed a speech prompting mechanism to encourage in-context learning for improved zero-shot generation. This mechanism prompts the duration/pitch predictor and the diffusion model to follow the diverse information present in the speech prompt, such as speaker identities.
For a given speech latent sequence, a segment is randomly cut out to serve as the speech prompt, while the remaining segments form a new sequence that acts as the learning target for the diffusion model. A Transformer-based prompt encoder is used to process the speech prompt and generate a hidden sequence.
Two different strategies are employed to leverage this hidden sequence for the duration/pitch predictor and the diffusion model:
For the duration and pitch predictors, a Query-Key-Value (Q-K-V) attention layer is inserted into the convolution layer. The hidden sequence of the convolution layer serves as the query, and the key and value come from the hidden sequence generated by the prompt encoder.
For the diffusion model, two attention blocks are designed rather than directly attending to the hidden sequence from the prompt encoder (which might reveal excessive detail and impact generation). In the first block, randomly initialized embeddings are used as the query sequence to attend to the prompt hidden sequence, yielding a hidden sequence of a specified length. The second block uses the hidden sequence from the WaveNet layer as the query and the results of the first attention block as the key and value. The results of the second attention block serve as conditional information for a FiLM layer, which performs an affine transform on the hidden sequence of the WaveNet in the diffusion model.
Connection to NaturalSpeech
NaturalSpeech 2 is an enhanced version of the NaturalSpeech series. Although both versions aim to synthesize natural voices, their focuses are different. NaturalSpeech 1 emphasizes speech quality, working mainly with single-speaker, recording-studio datasets to produce voices comparable to human recordings. On the other hand, NaturalSpeech 2 concentrates on speech diversity, exploring zero-shot synthesis capabilities using large-scale, multi-speaker, and in-the-wild datasets.
In terms of architecture, NaturalSpeech 2 retains key components from NaturalSpeech 1, such as the encoder and decoder for waveform reconstruction, and the prior module (phoneme encoder, duration/pitch predictor). However, it introduces several significant enhancements described above.
Experiments
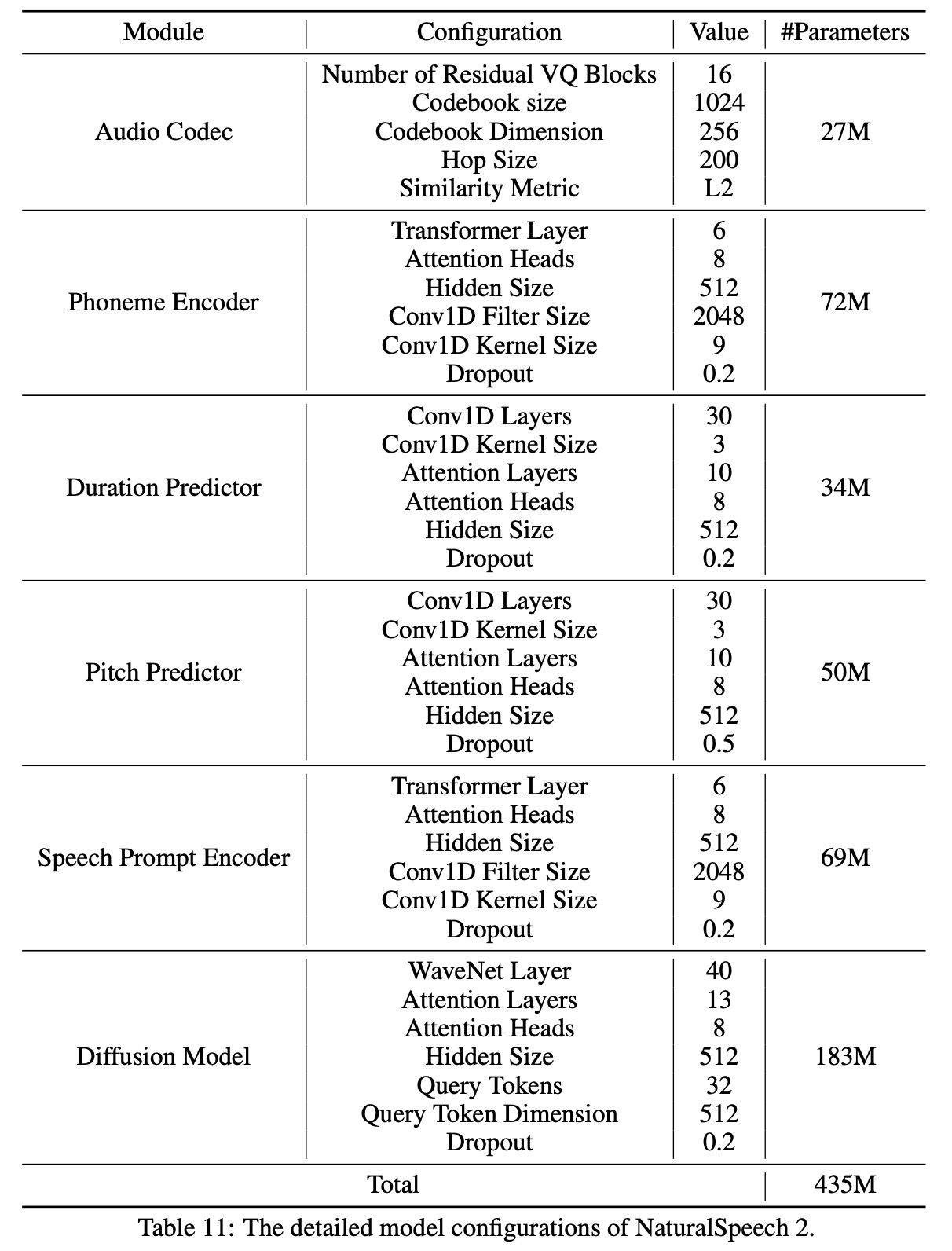
The audio codec of NaturalSpeech 2 was trained using 8 NVIDIA TESLA V100 16GB GPUs, with a batch size of 200 audios per GPU for 440K steps. The diffusion model was trained on 16 NVIDIA TESLA V100 32GB GPUs, with a batch size of 6K frames of latent vectors per GPU for 300K steps.
Evaluation Metrics
Objective metrics:
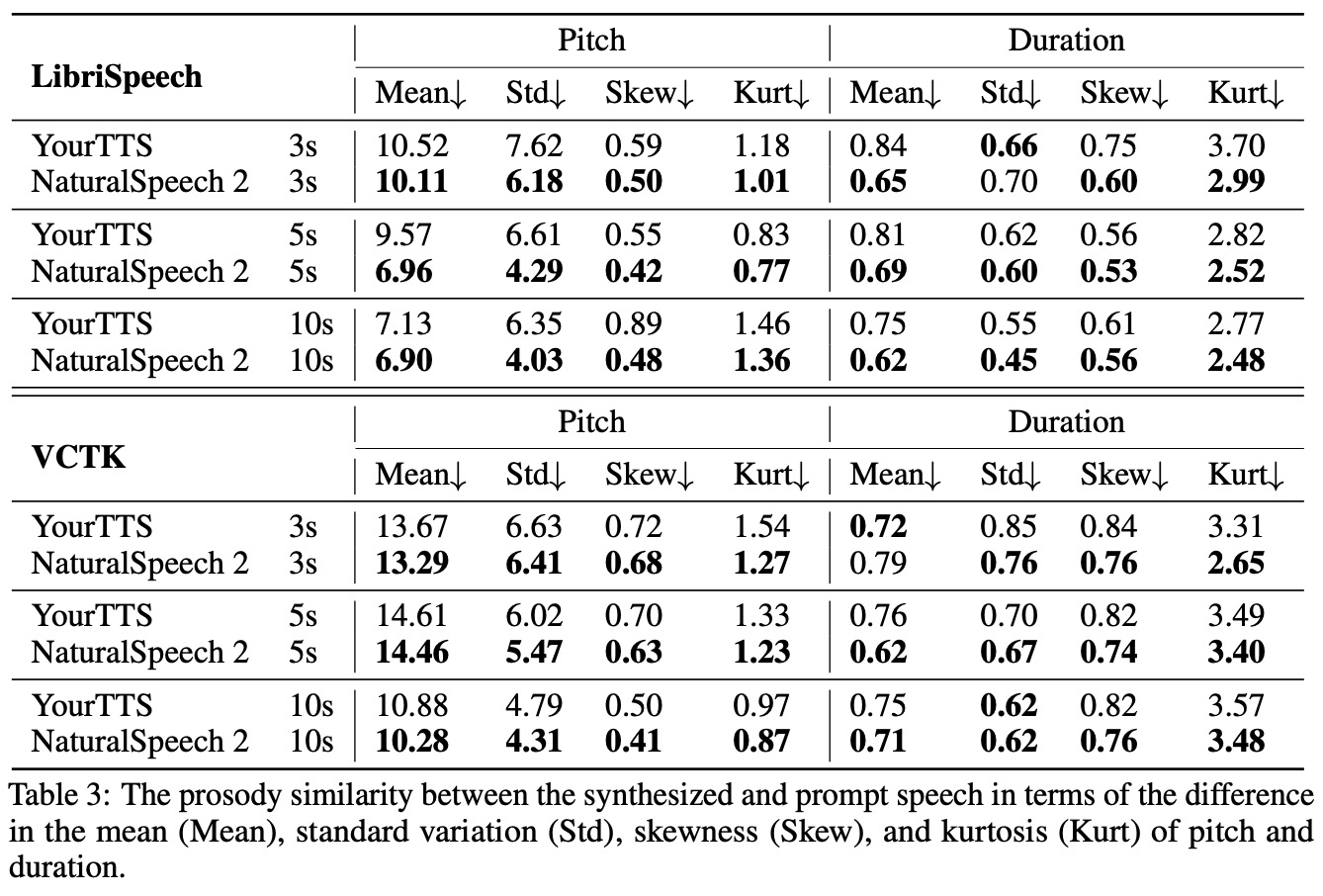
- Prosody Similarity with Prompt: This measures how well the text-to-speech (TTS) model follows the prosody (pitch and duration) in the speech prompt. It involves extracting phoneme-level duration and pitch from the prompt and the synthesized speech and comparing these features.
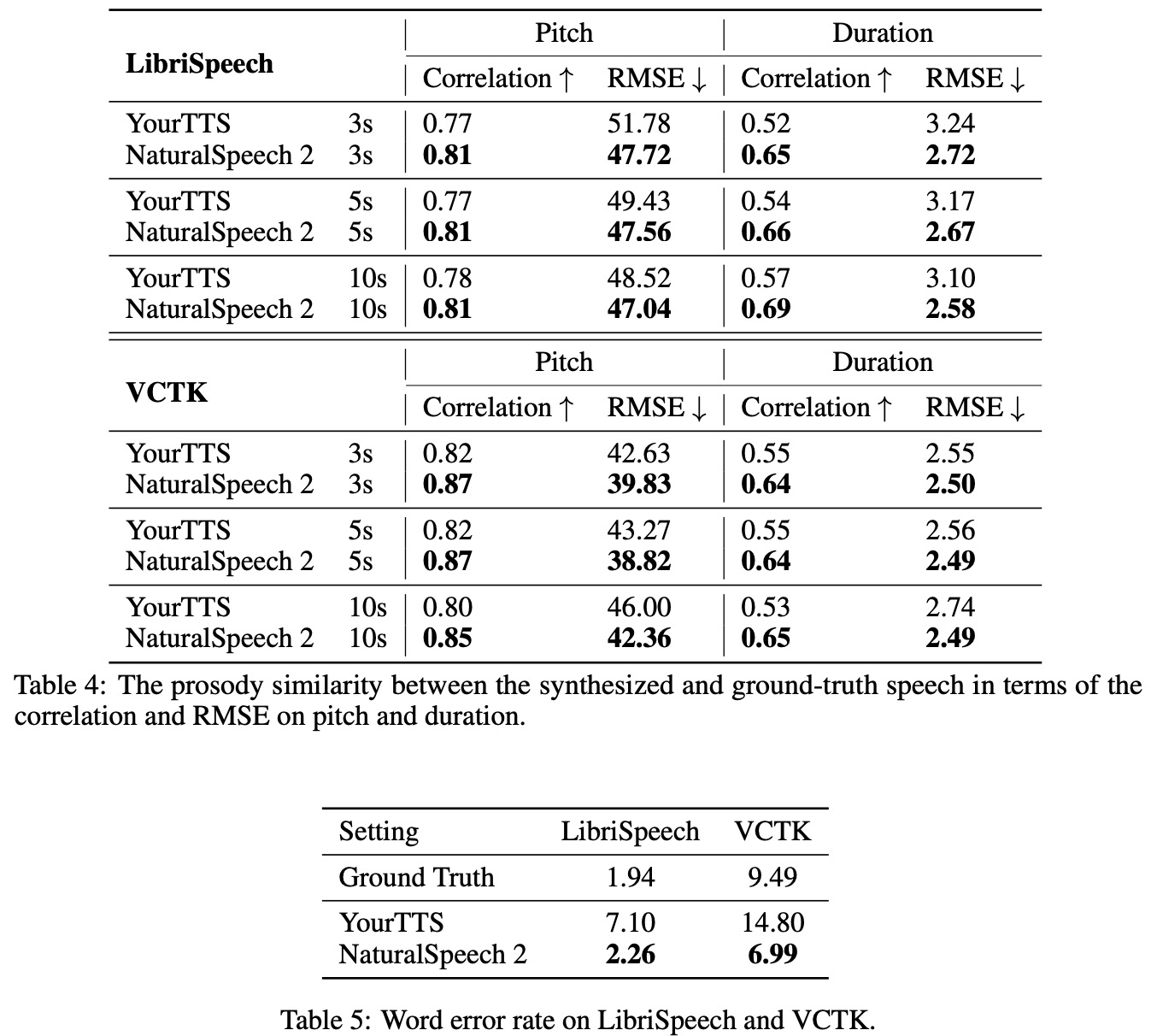
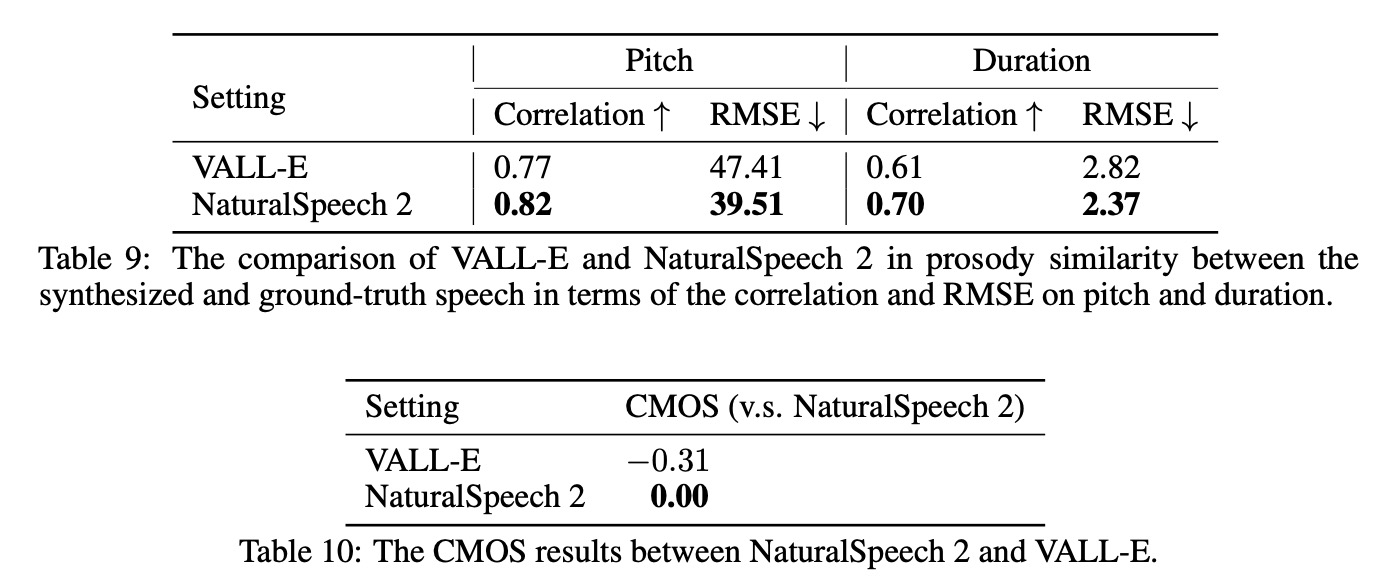
- Prosody Similarity with Ground Truth: This assesses how well the TTS model matches the prosody in the ground truth. It involves calculating the Pearson correlation and RMSE of the pitch/duration between the generated and ground-truth speech.
- Word Error Rate (WER): An Automatic Speech Recognition (ASR) model is used to transcribe the generated speech, and the WER is calculated.
Subjective metrics involve human evaluation and include:
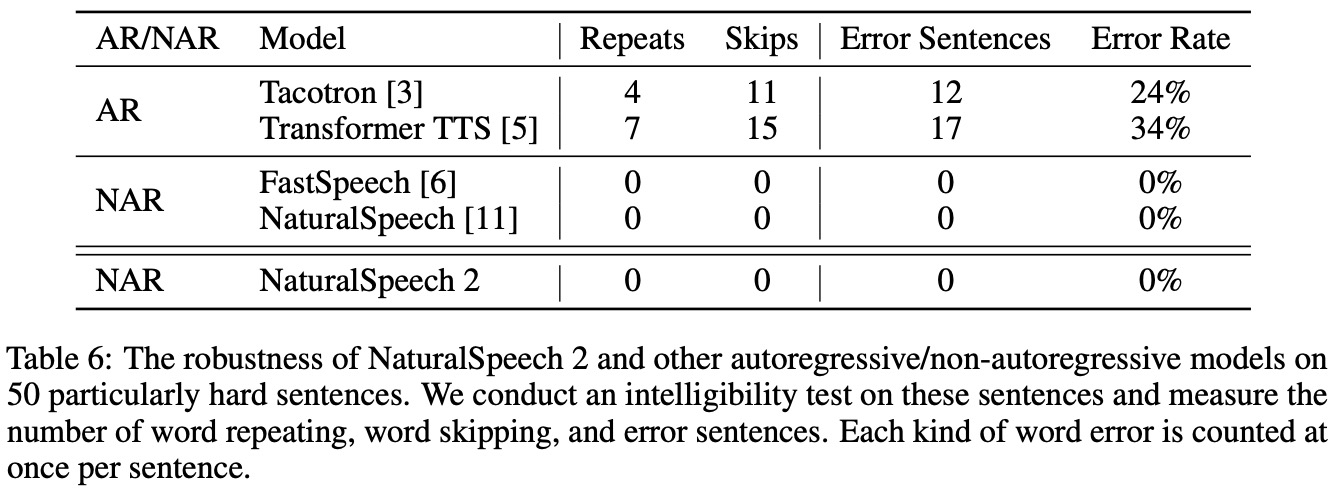
- Intelligibility Score: This measures the number of repeating words, skipping words, and error sentences in the synthesized speech to assess the robustness of NaturalSpeech 2.
- Comparative Mean Opinion Score (CMOS) and Similarity Mean Opinion Score (SMOS): CMOS measures naturalness of the synthesized voice, while SMOS measures the similarity between the synthesized and prompt speech. Both are scored by native speakers.
Results