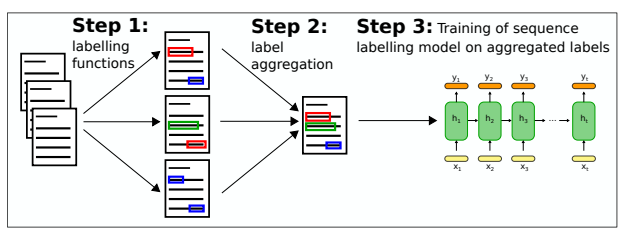
Paper Review: Named Entity Recognition without Labelled Data: A Weak Supervision Approach

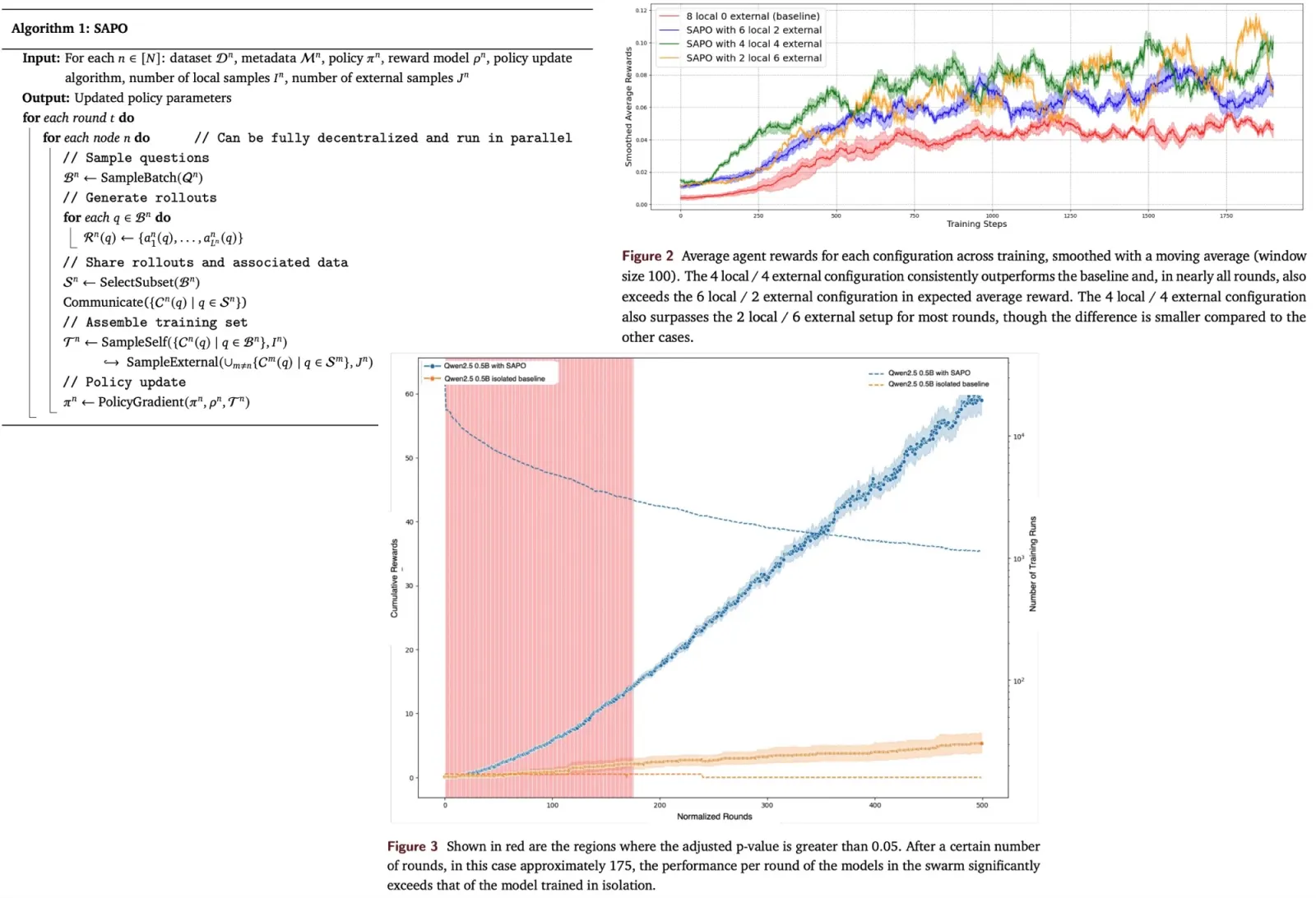
An approach to learn NER models in the absence of labelled data through weak supervision - by merging annotations from various labelling functions using the hidden Markov model. After that, you could train a usual NER model on the labelled data. This approach works better than the out-of-domain neural NER model!
Usefulness of the approach
When we have a lot of labelled data, we can use various NER models - flair, bi-LSTM, BERT. And we can use transfer learning to apply these models to other domains. If we don’t have labelled data in our specific domain, we need to use weak supervision - to bootstrap named entity recognition models without requiring any labelled data from the target domain. The main contributions of the paper:
- A broad collection of labelling functions for NER
- A novel weak supervision model suited for sequence labelling tasks and able to include probabilistic labelling predictions
- An open-source implementation of these labelling functions and aggregation model that can scale to large datasets
The approach
There are a lot of labelling functions; each predicts NER labels or probabilities (unlike the previous papers). Each function detects only a subset of labels. Then outputs of these labels are aggregated using HMM with multiple emissions (one per labelling function) whose parameters are estimated in an unsupervised manner. Then aggregated labels can be used for training a normal NER model.
Labelling functions
- Out-of-domain NER models. As far as I understand, we use models which predict relevant labels but were trained on data from a different domain. A transition-based NER model with 4 CNN layers is used. Glove + spacy.
- Gazetteers. Info from big knowledge bases. They are converted into a trie structure. Prefix search is then applied to extract matches
- Heuristic functions. One function per entity, usually using casing, part-of-speech tags, dependency relations, or regex
- Document-level relations. The idea is that if some entity occurs multiple times in the text, it is likely to have a single label. Also, if an entity is mentioned multiple times, it could have a full form at the first use and then be shorter - for example, full name and then simply the last name. We can find entities that are substrings of another entity - and make them have the same label distribution
Aggregation model
The aggregation model is represented as an HMM, in which the states correspond to the true underlying labels. This model has multiple emissions (one per labelling function) assumed to be mutually independent conditional on the latent underlying label. The learnable parameters of this HMM are the transition matrix between states and the α vectors of the Dirichlet distribution associated with each labelling function To ensure faster convergence, authors introduce a new constraint to the likelihood function: the aggregation model will only predict a particular label if this label is produced by at least one labelling function. This simple constraint facilitates EM convergence as it restricts the state space to a few possible labels at every time-step. Also, it is possible to add prior distribution - for example, based on the most reliable labelling function.

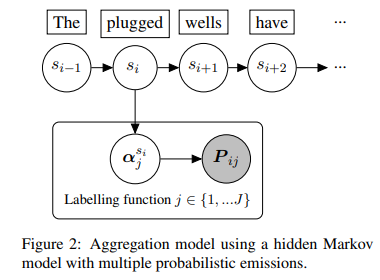
Sequence labelling model
And now we can train a model.

Evaluation datasets
CoNLL 2003, Reuters & Bloomberg. Authors don’t rely on labelled data for these domains.
Baselines
- Majority voting. First, take tokens marked as non-O by at least T labelling functions (T is a hyperparameter), and then apply majority voting.
- Snorkel. Usually, it gives labels to sentences, but heuristics can be used to get labels for sequences
- mSDA, Ontonotes-trained NER, AdaptaBERT, Mixtures of multinomials, Accuracy model, Confusion vector, Confusion matrix, Sequential Confusion Matrix, Dependent confusion matrix (I don’t really know most of them)
Evaluation
CEE - token-level crossentropy error (in log-scale). ACC and CV didn’t converge, so they are omitted. Quite interesting that document-level functions really help. And it is funny that the neural net trained on the aggregated labels isn’t better than HMM.
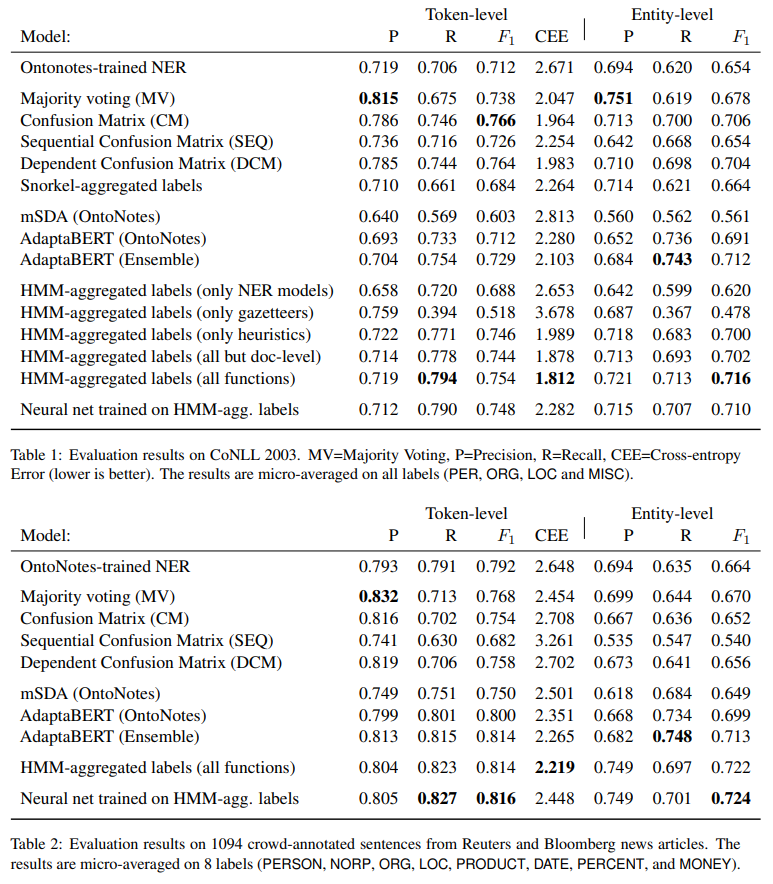
Additional thought
Informative priors didn’t help on the CoNLL dataset but improved the small Reuters and Bloomberg dataset score.
An example with a few selected labelling functions. Ontonotes-trained NER model mistakenly labels ”Heidrun” as a product. This is counter-balanced by other labelling functions, notably a document-level function. But there are still errors.

The functions with the highest overlap are those making predictions on all labels, while labelling functions specialized to few labels often have less overlap. Two gazetteers often disagree, maybe because some words can mean both location and company.
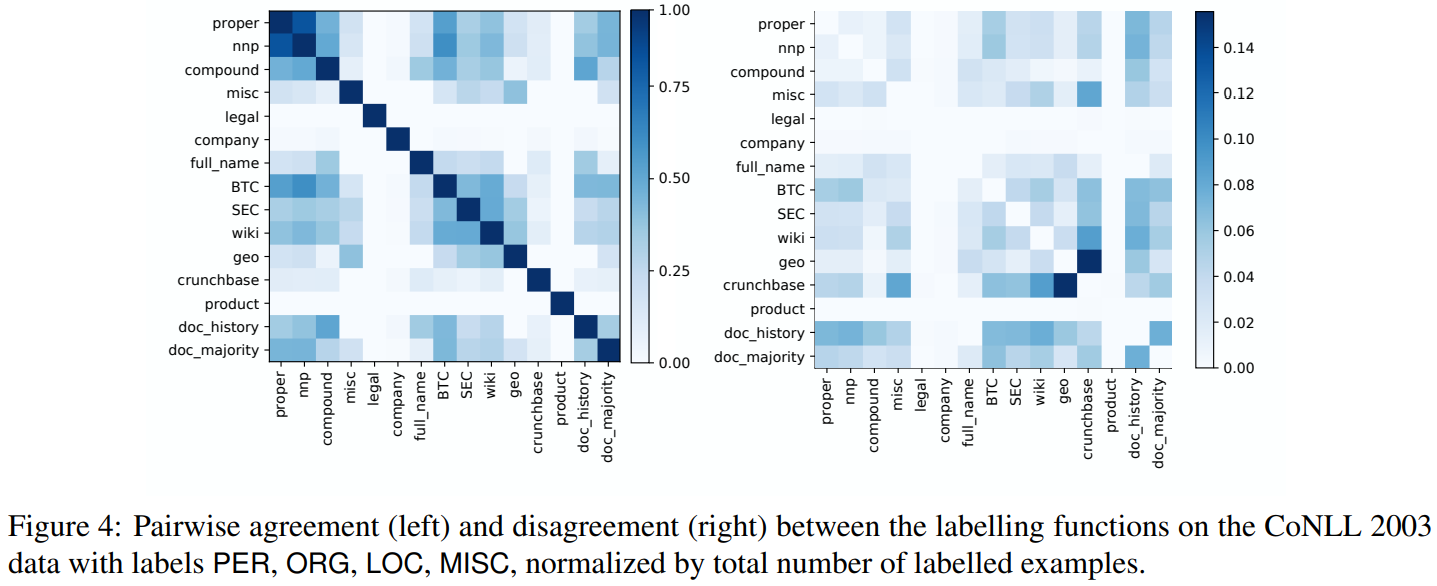
HMM trains quite fast, and predictions are done using a single forward-backward pass, so it can be scaled to big datasets.
paperreview nlp ner weaksupervision