Paper Review: Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Code link (no published yet)
While vision transformers show high scores, they can’t be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
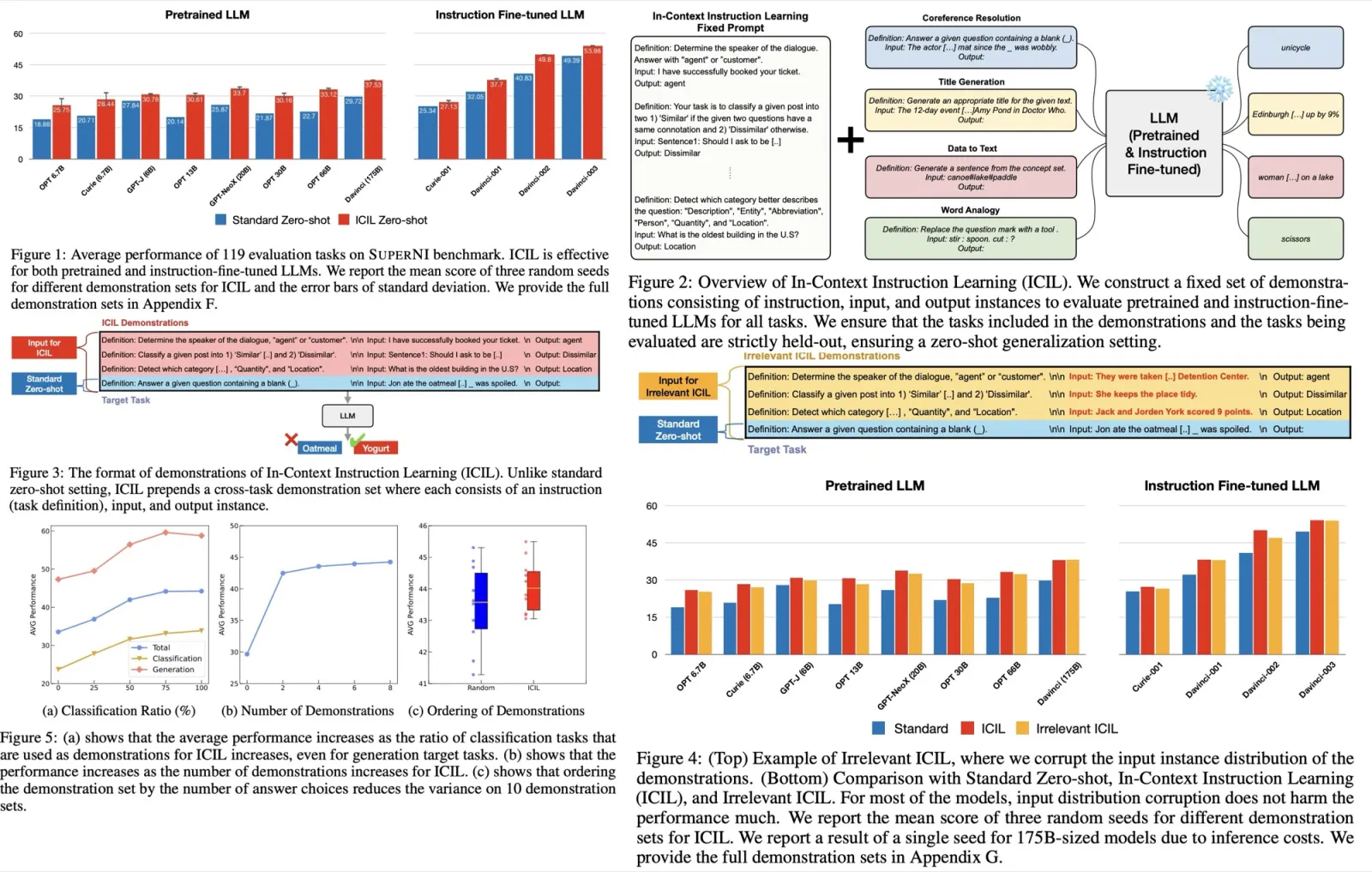
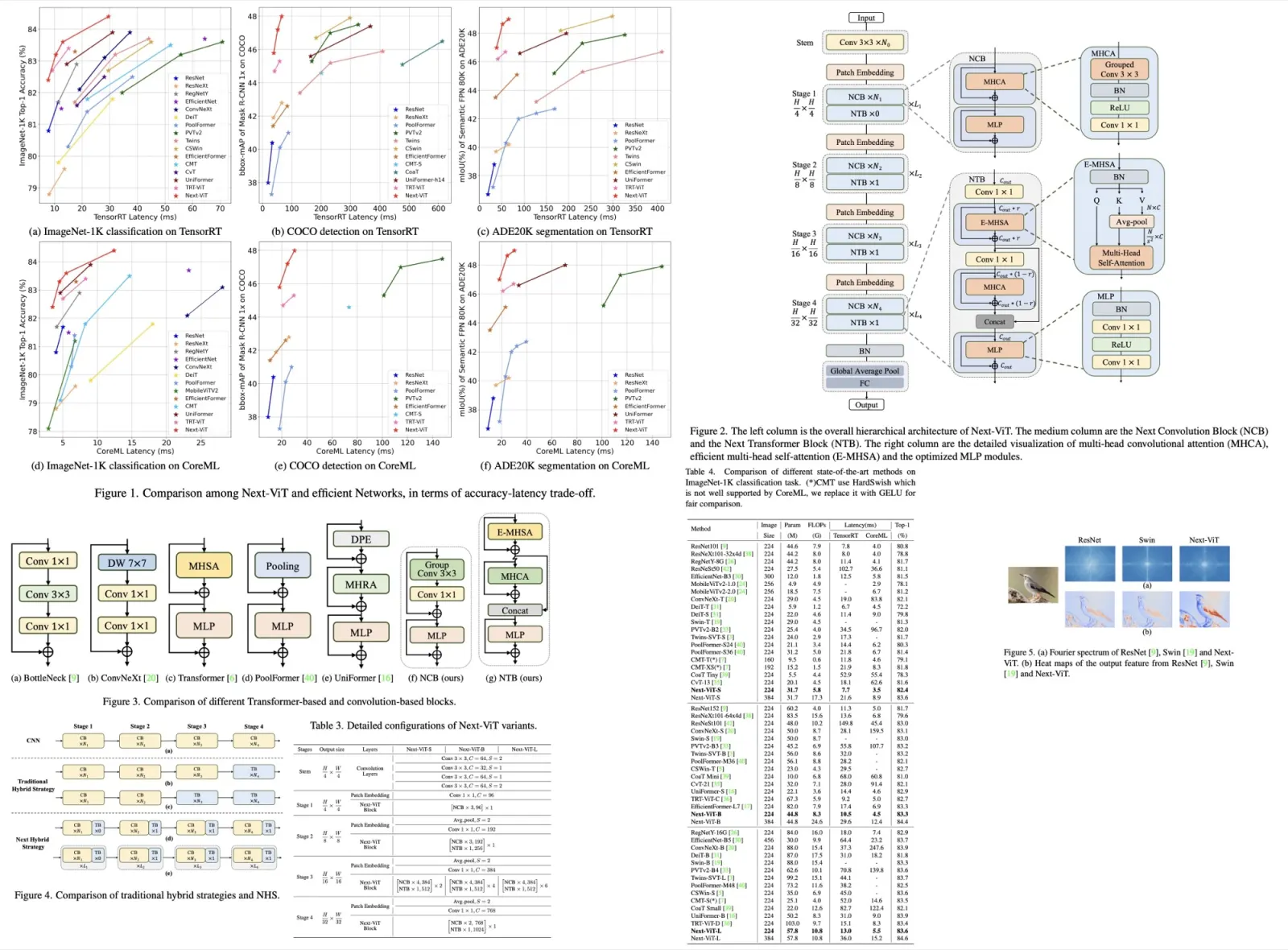
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Architecture overview
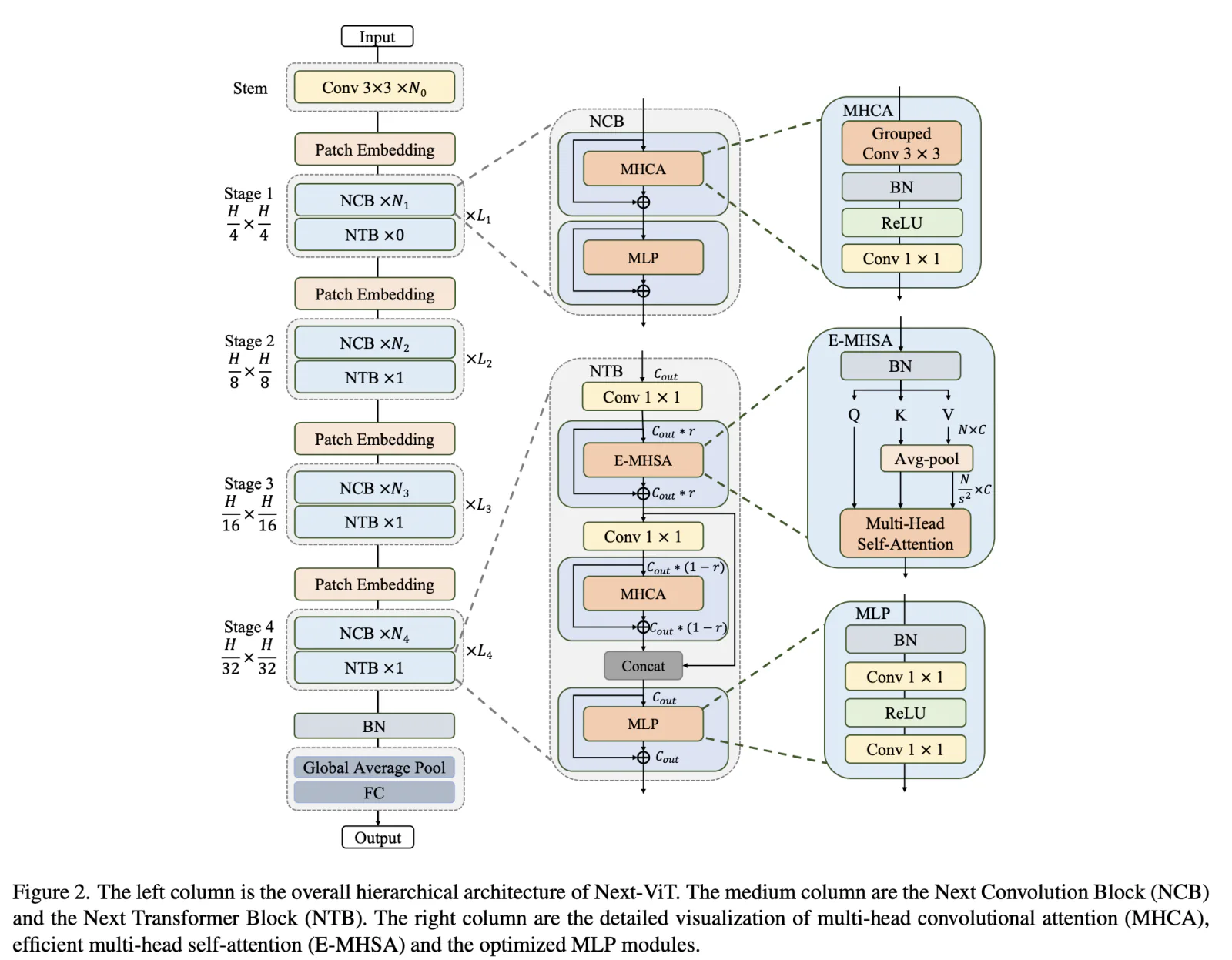
Usual approaches to tackle high latency with ViT models are about designing more efficient attention mechanisms or CNN-Transformer hybrids. Most such hybrids use convolutional layers at the beginning and transformer layers at the later stages. The authors think that such hybrids lead to performance saturation on downstream tasks; furthermore, convolutional and transformer blocks have either higher efficiency or high performance, but not both at the same time.
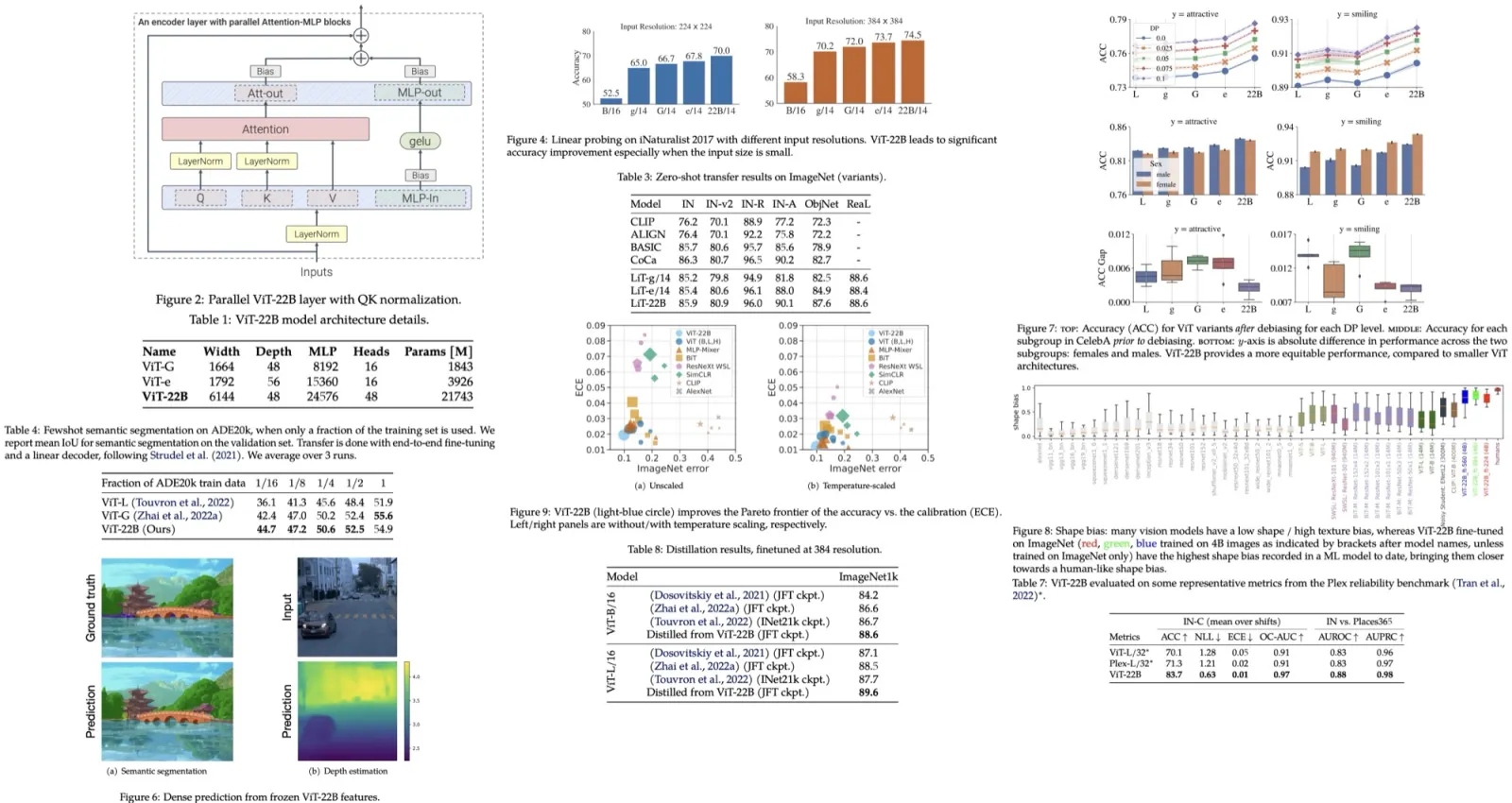
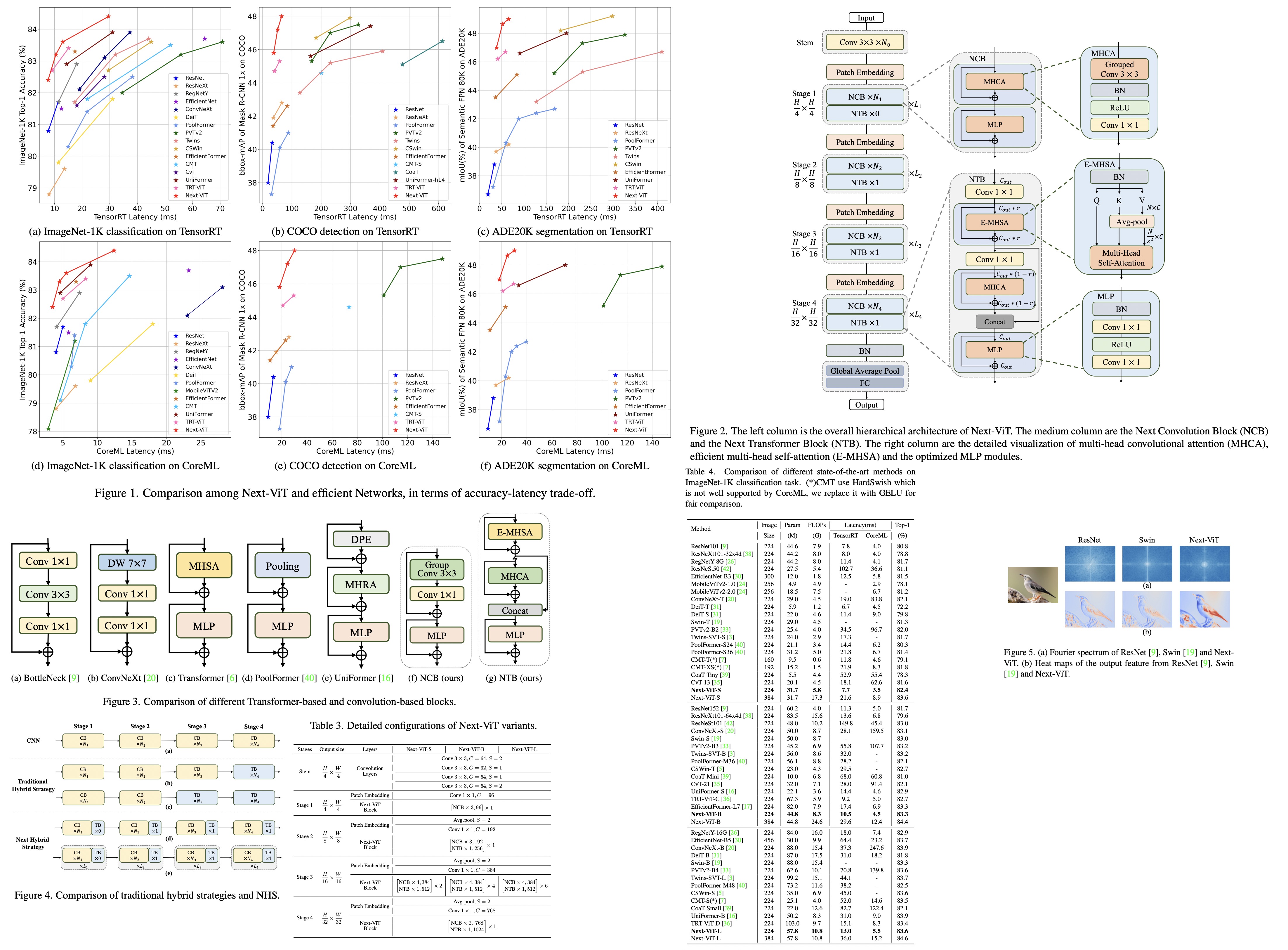
The authors developed three new components on which Next-ViT is based:
- Next Convolution Block (NCB) for capturing short-term dependency information in visual data with a Multi-Head Convolutional Attention (MHCA);
- Next Transformer Block (NTB) for capturing long-term dependency information and as a lightweight and high-and-low frequency signal mixer to enhance modeling capability;
- Next Hybrid Strategy (NHS) to stack NCB and NTB in a novel hybrid paradigm in each stage to greatly reduce the proportion of the Transformer block and retain the high precision of the vision Transformer network in downstream tasks;
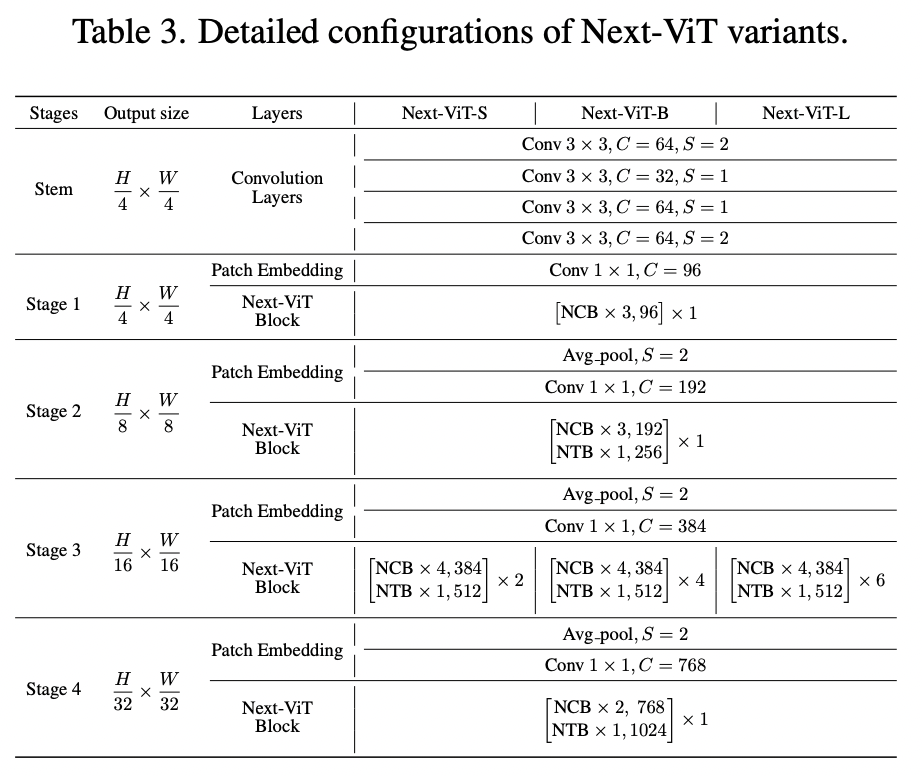
Next-ViT follows the hierarchical pyramid architecture and has a patch embedding layer and a series of convolution or Transformer blocks in each stage. The spatial resolution is progressively reduced by 32× while the channel dimension is expanded across different stages.
Next Convolution Block
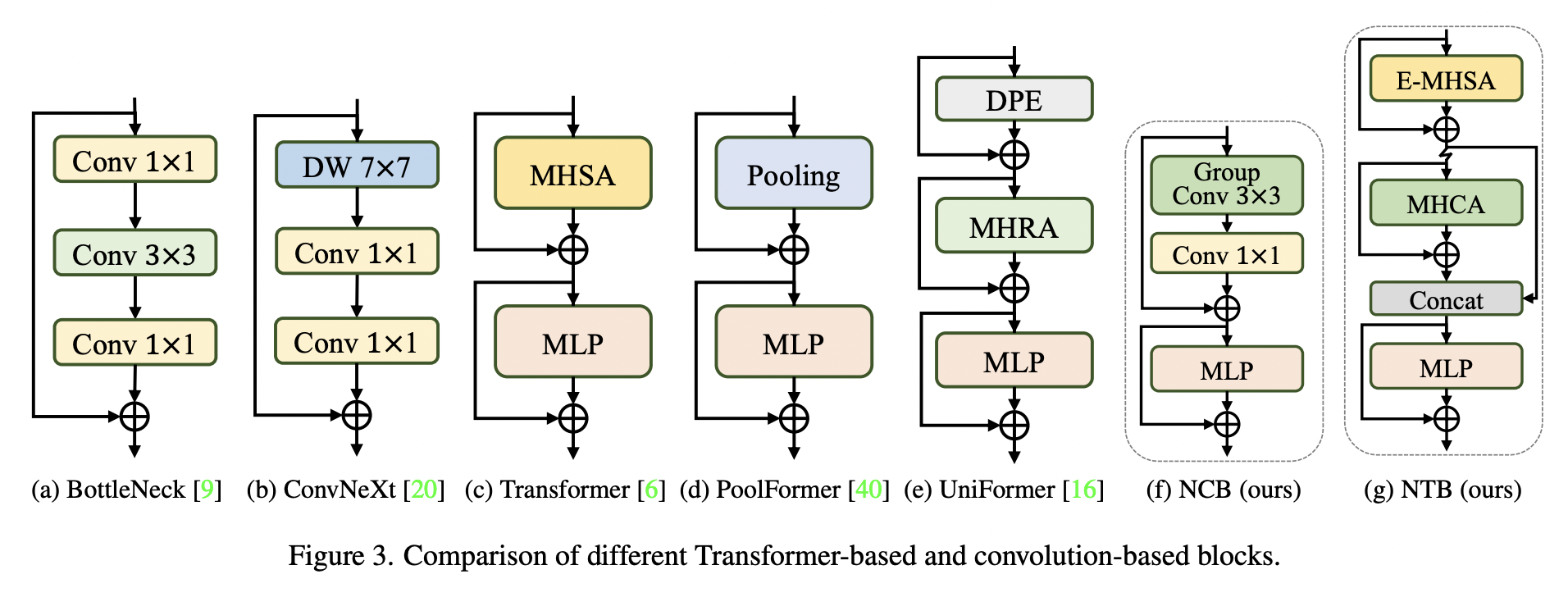
Here the authors compare different convolutional and transformer blocks:
- ResNet block was a start;
- ConvNeXt has better performance; its inference speed is much lower due to 7x7 convolution and other things;
- Transformer blocks have even better performance but also have low inference speed;
The authors suggest the Next Convolution Block:
- it follows the general architecture of MetaFormer (essentially a transformer block);
- it uses Multi-Head Convolutional Attention - convolutional attention over adjacent tokens (inner product operation) with a trainable parameter; we also have a multi-head group convolution and a point-wise convolution;
- it uses efficient BatchNorm and ReLU instead of LayerNorm and GELU (like in traditional Transformer blocks);
Next Transformer Block
Transformer blocks capture low-frequency signals well and thus work well with global information (global shapes and structures), but they usually don’t work well with high-frequency (local) information.
The structure of the block is the following:
- Efficient Multi-Head Self Attention(E-MHSA) for capturing low-frequency signals. It has a spatial reduction self-attention operator with an average-pooling for downsampling spatial dimension before the attention;
- then MHCA module to capture multi-frequency signals;
- the output of these layers is concatenated and fed into an MLP;
Next Hybrid Strategy
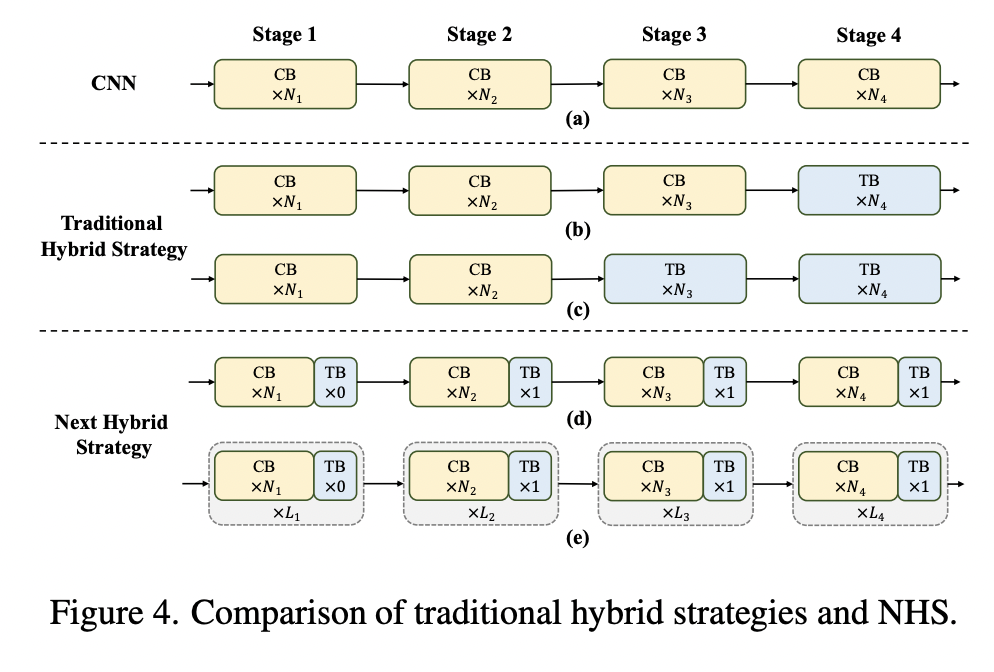
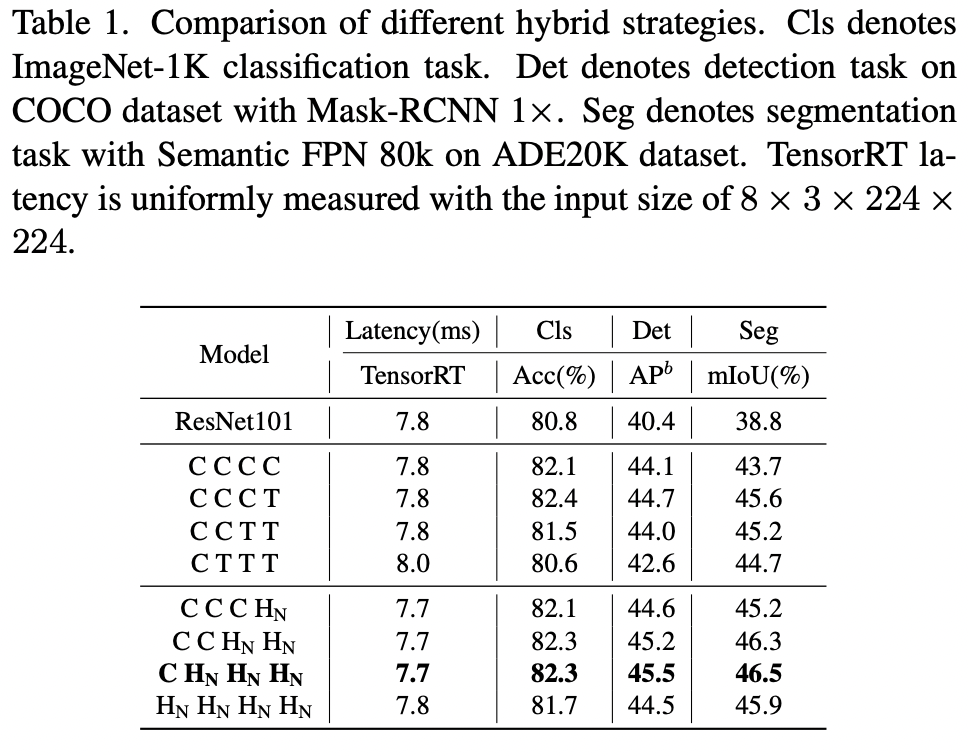
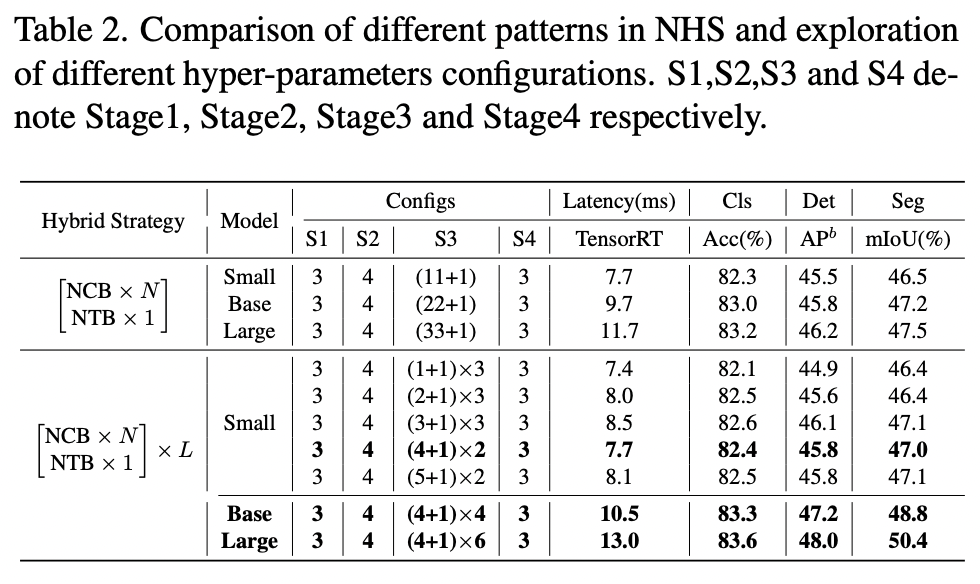
As it was said earlier, usual hybrid strategies use convolutional layers at first and transformer layers at later stages. For classification downstream tasks, this is fine, but for segmentation and object detection, we usually take the outputs from multiple stages - and the outputs from the earlier stages fail to capture global information, which is vital for these tasks.
The authors suggest the following:
- At each stage, stack N NCB blocks and 1 NTB block (transformer block is after convolutional blocks). In the images, HN is a (NCB×N +NTB×1) pattern;
- They tune the number of blocks and the number of stacks;
Next-ViT Architectures
The results
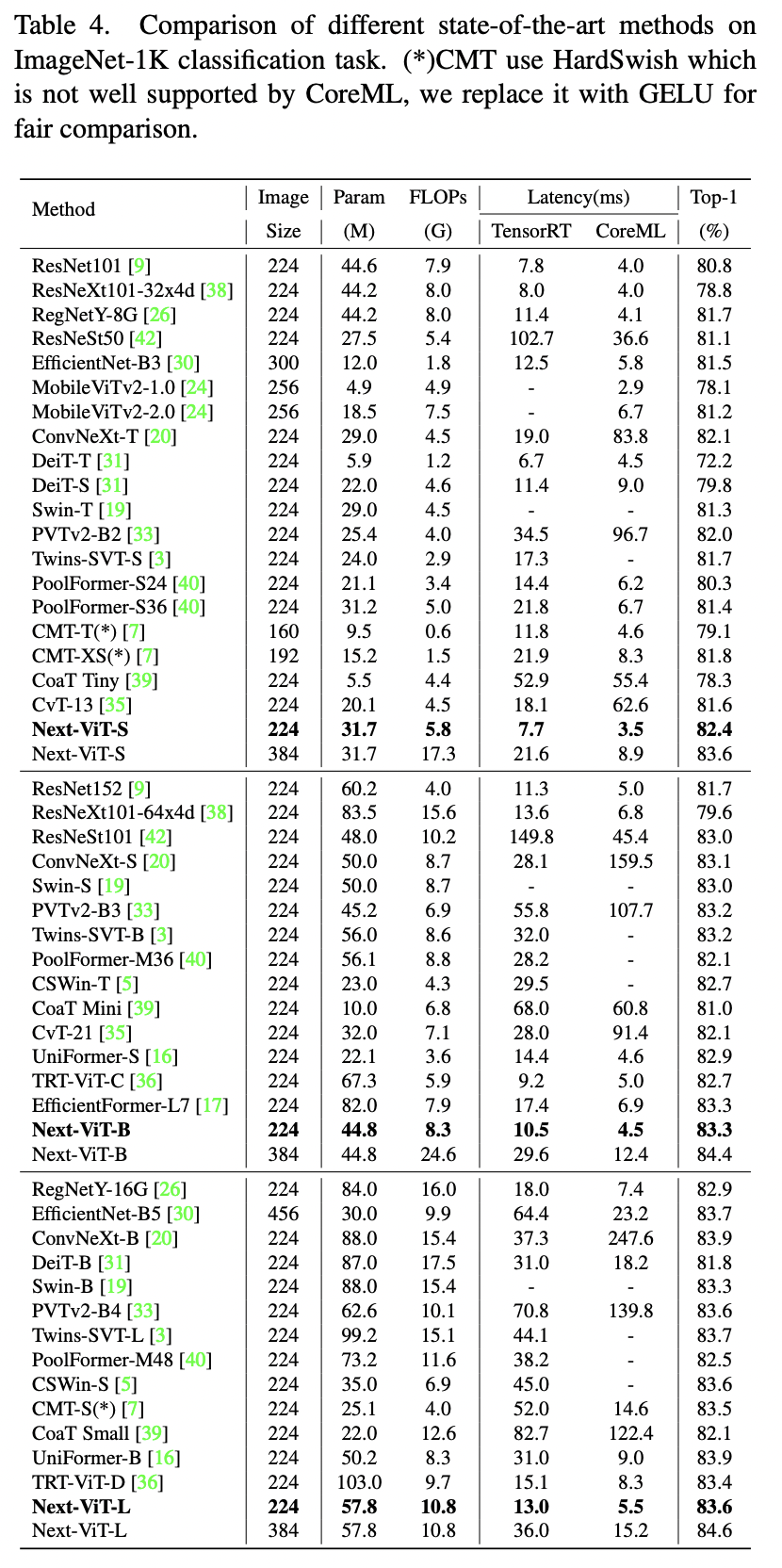
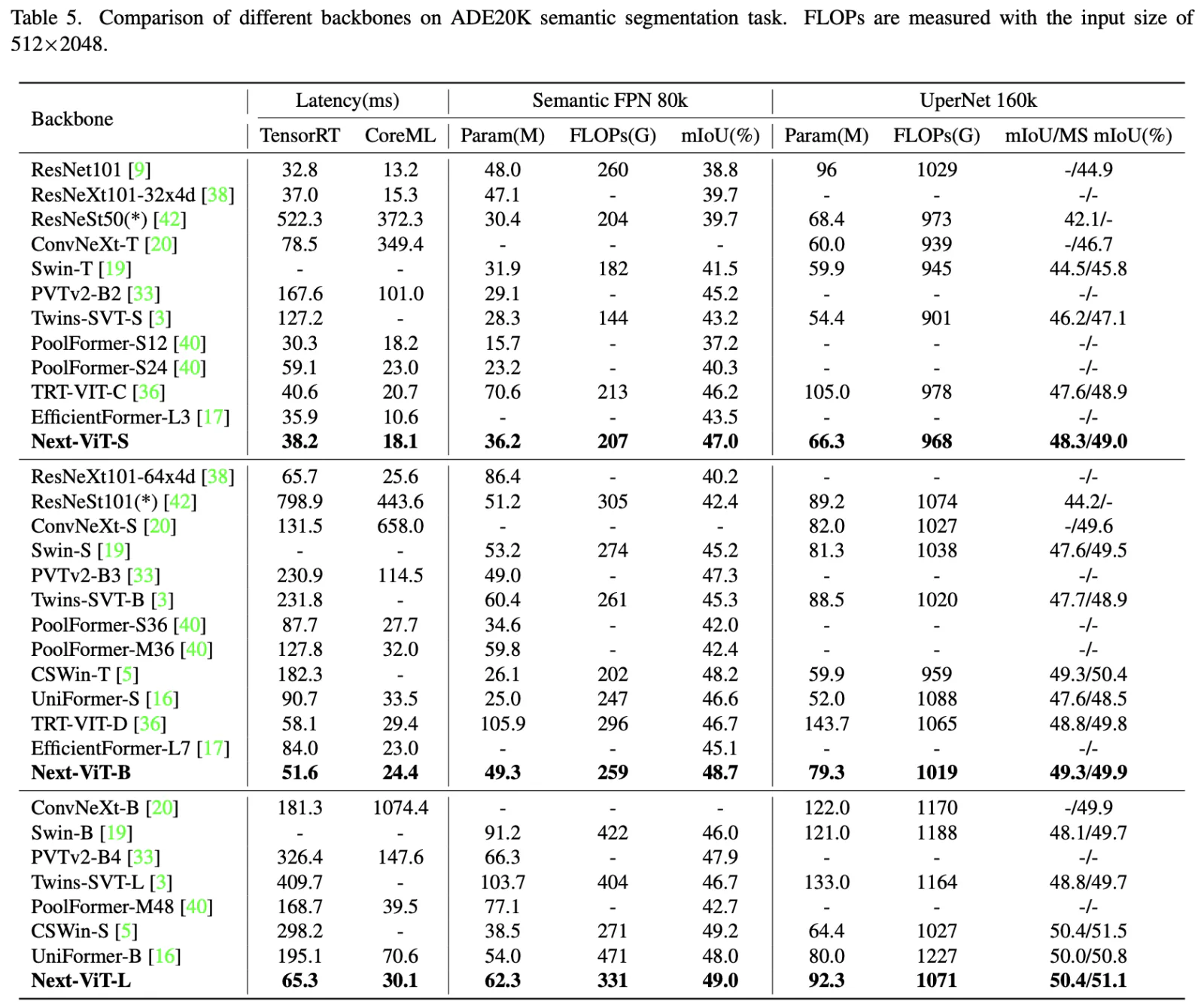
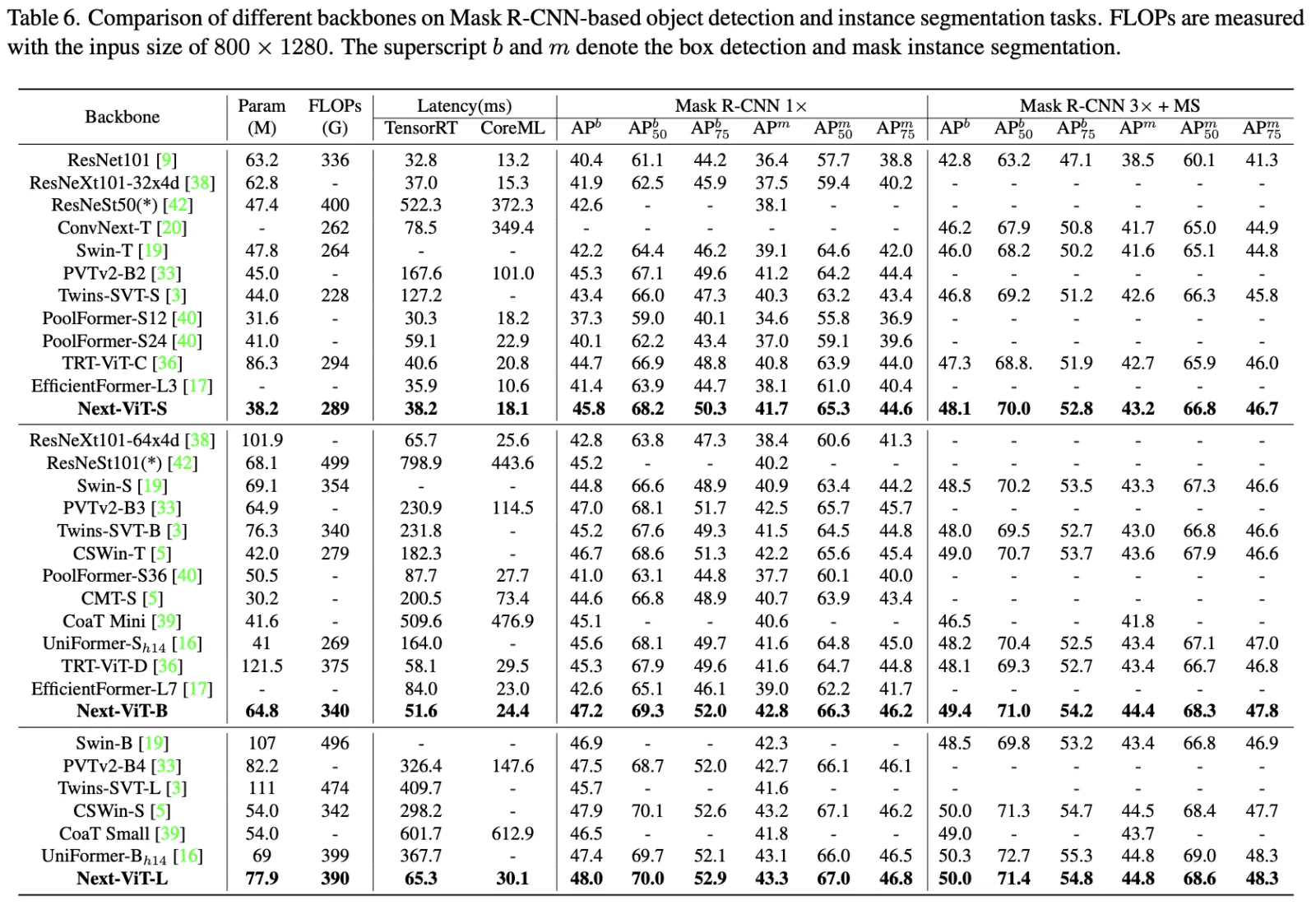
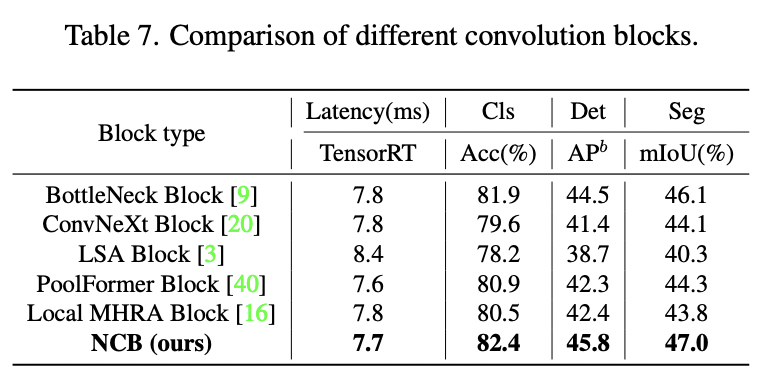
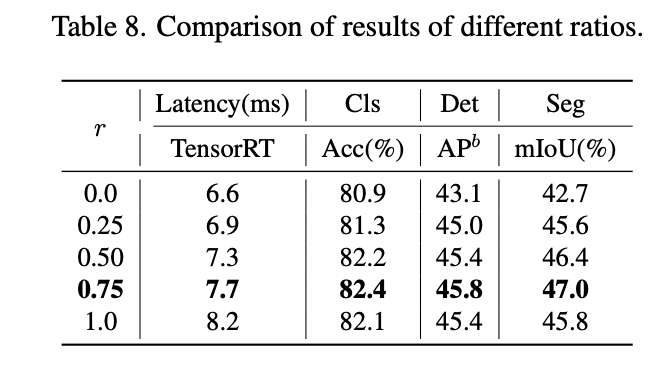
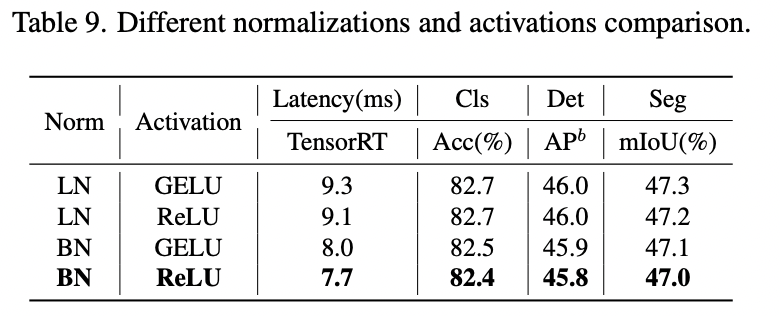
Training settings: 300 epochs on 8 V100, total batch size 2048, 224x224 images, AdamW, cosine decay with a warm-up, increasing stochastic depth augmentation.
Latency is measured on TensorRT-8.0.3 with a T4 GPU and on CoreML on an iPhone12 Pro Max with iOS 16.0.
paperreview deeplearning cv transformer