Paper Review: Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
A practical paper on improving the performance of few-shot text classification. The main approaches suggested in the paper are:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss;
- using curriculum learning (two-stage and gradual)
Datasets
The authors use 4 datasets:
- HUFF. 200k news headlines in 41 categories.
- FEWREL. Sentences, where 64 classes are relationships between the head and tail tokens.
- COV-C. Questions in 89 clusters (87 are used).
- AMZN. Amazon reviews, 318 “level-3” classes are used.
During training N examples per class are sampled (10 in the first two datasets, 3 in the others). The metric is top-1 accuracy.
Model and training
The model is BERT-base with average-pooled encodings; on top of them, they train a two-layer triplet loss network.
The batch size is 64.
Augmentations
They use EDA (no, not Exploratory Data Analysis, but Easy Data Augmentation): synonym replacement, random insertion, random swap, random deletion. A temperature parameter tau defines a fraction of perturbed tokens.
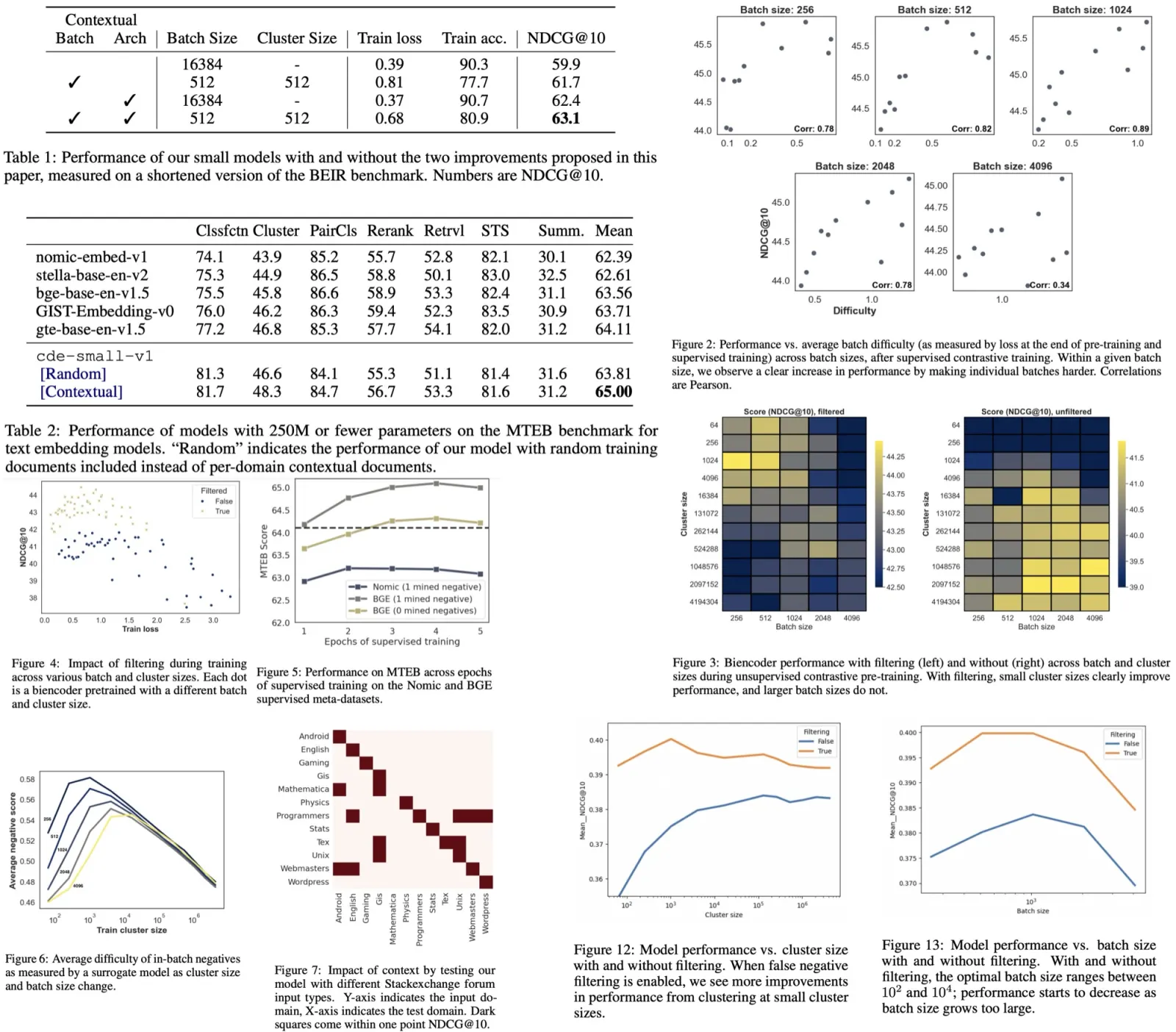
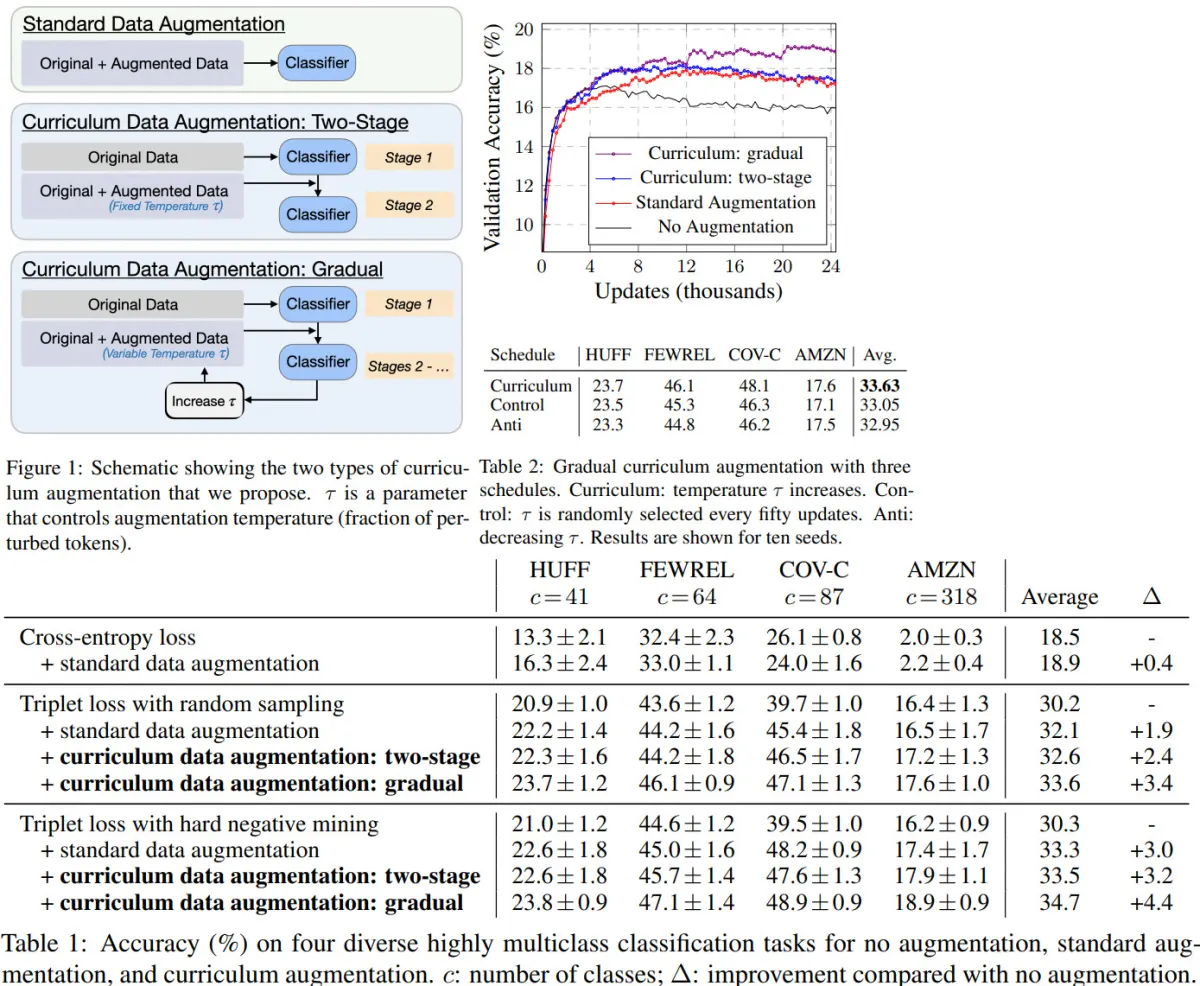
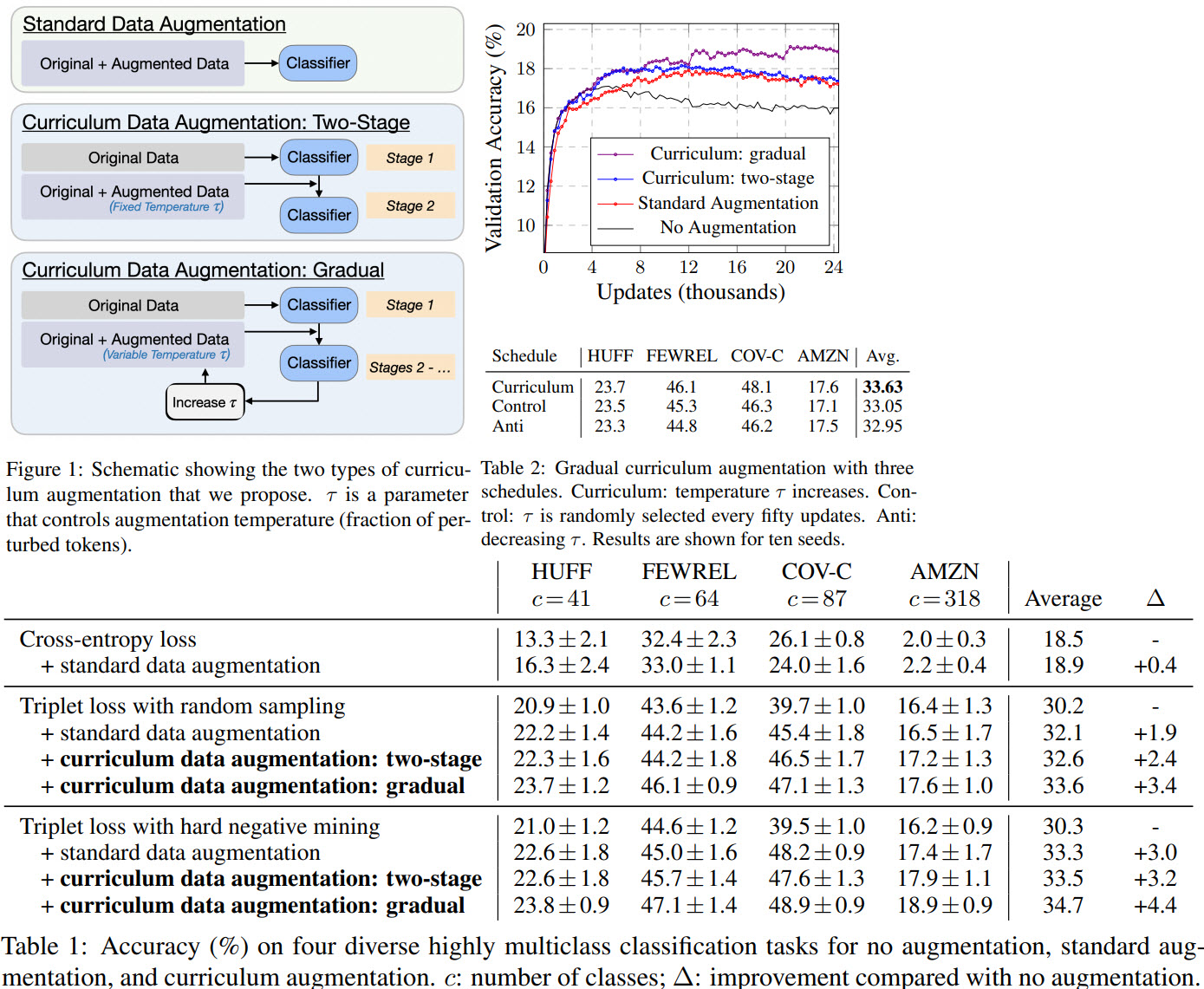
Schedules
Two-stage curriculum: at first, train on the original data, then add augmented data to the original (the ratio is 4:1). Gradual curriculum: at first, train on the original data, then gradually increase the temperature by 0.1 on validation loss plateau (up to 0.5).
Results
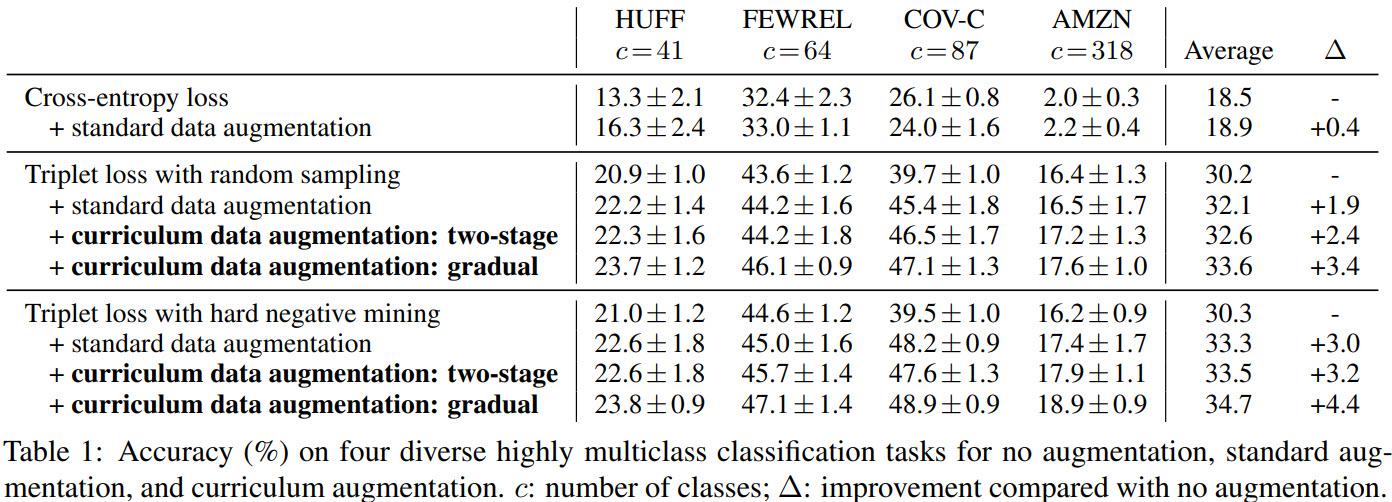
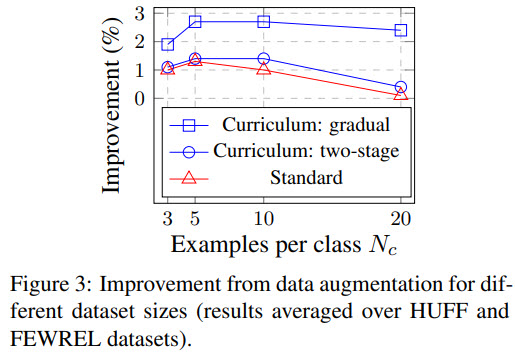
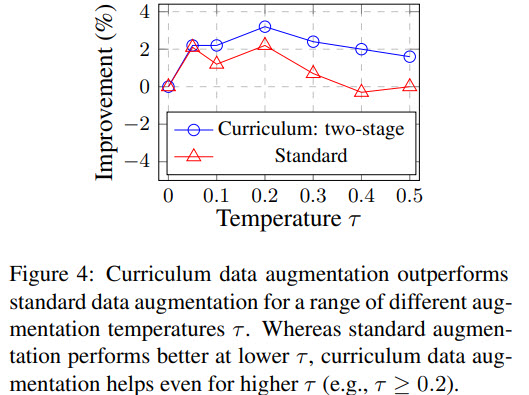
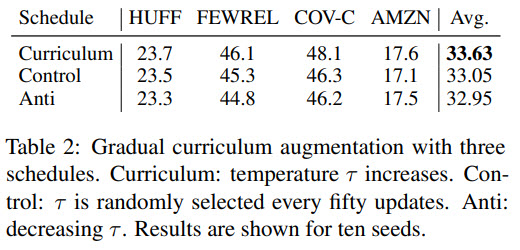

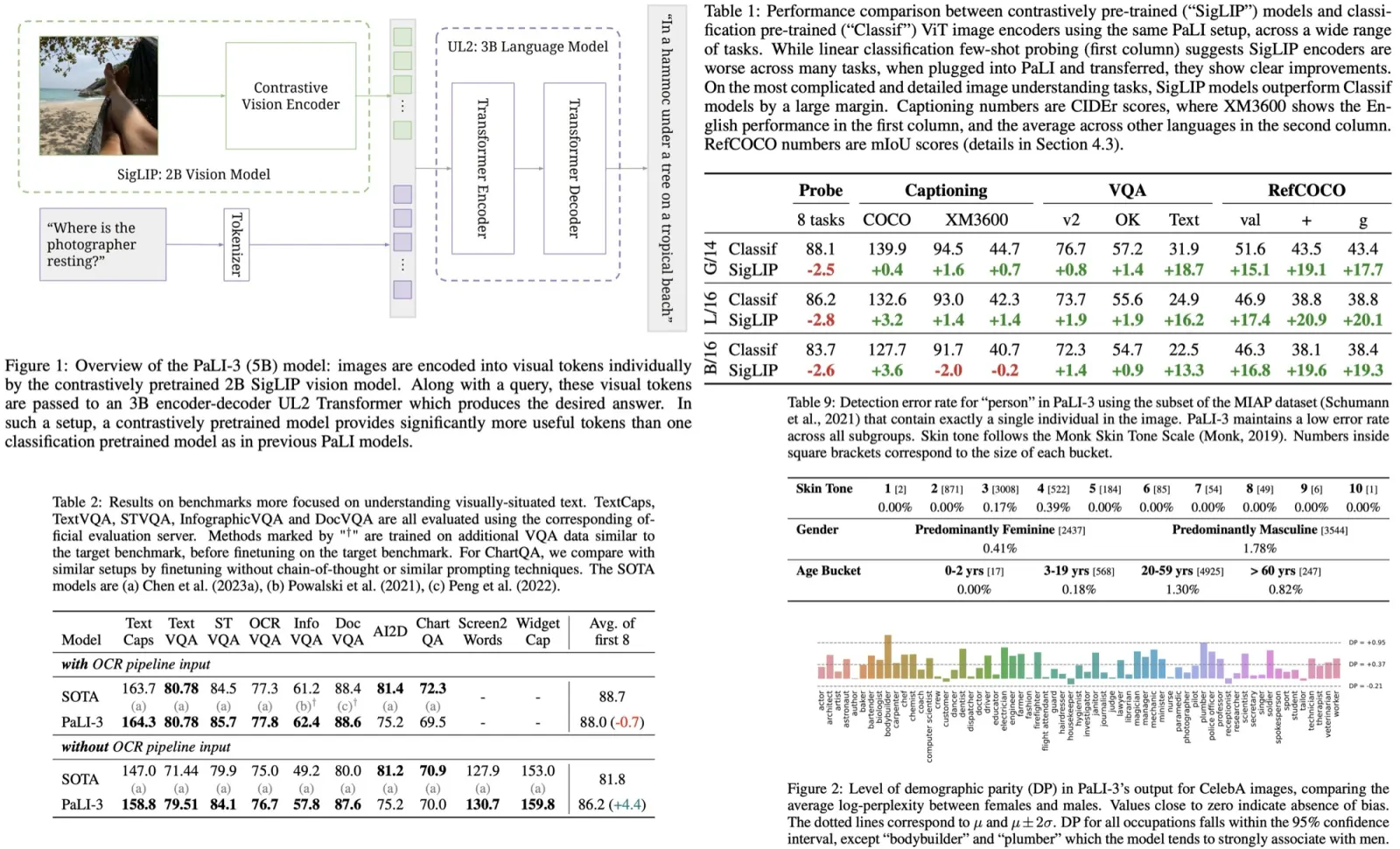
Several points:
- gradual curriculum with hard negative mining gives the best results (though, of course, it takes longer to train);
- the more samples we have, the better is model performance. Though the improvement is stable only for gradual curriculum - for other approaches the improvement stops fast;
- curriculum learning can use higher temperatures more efficiently;
- gradually increasing temperature is better than gradually decreasing or having it constant;