NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Code link (no code yet)
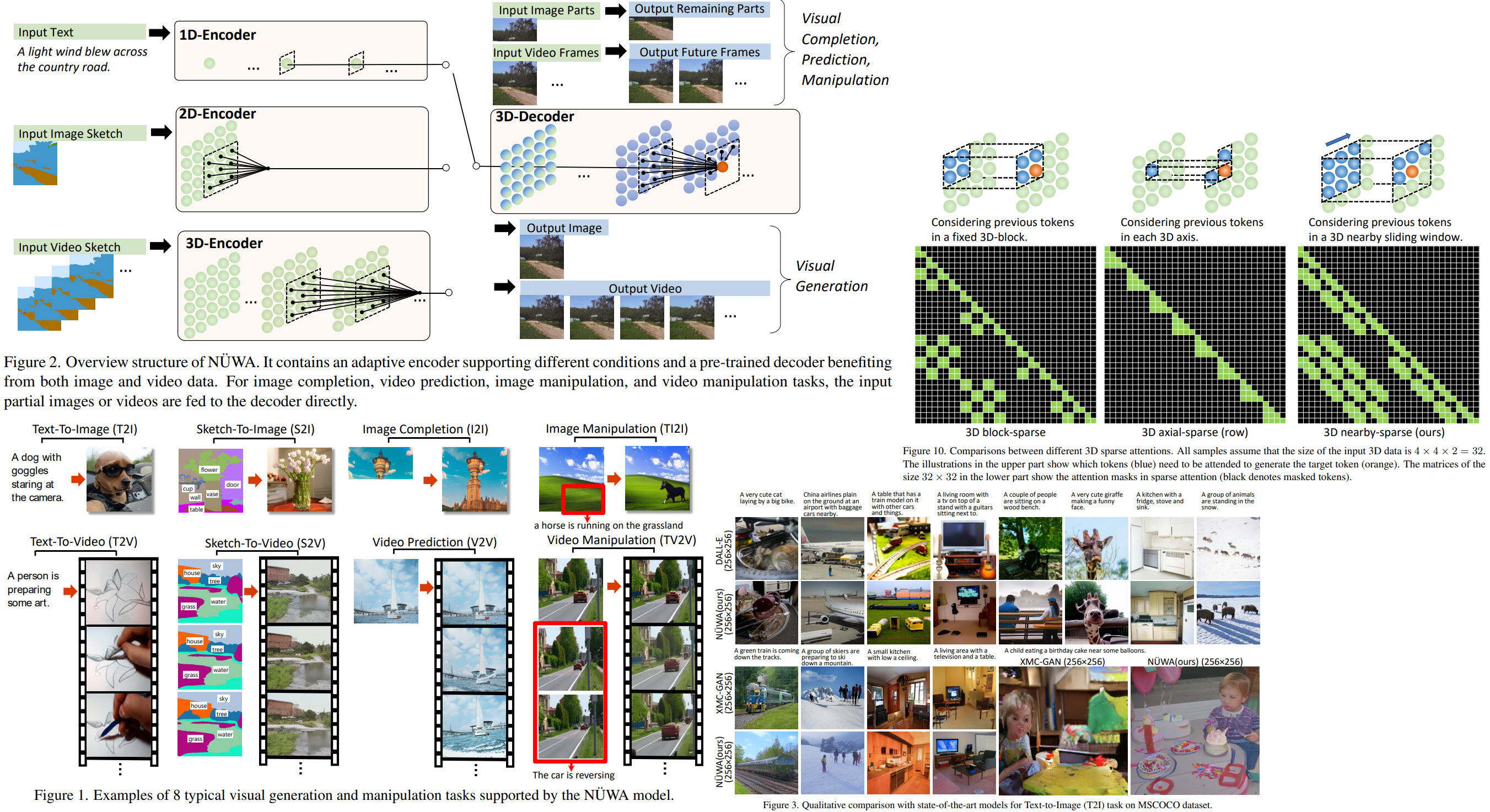
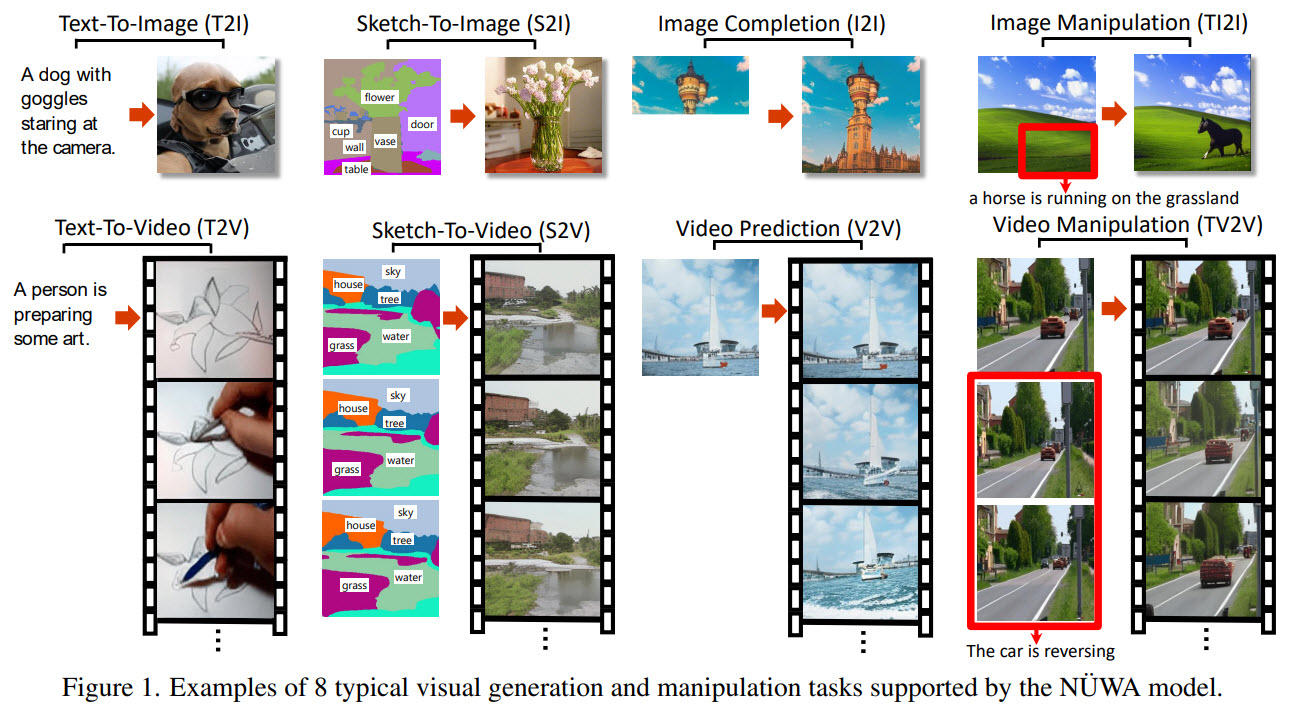
In this paper, the researchers from Microsoft Research Asia and Peking University share a unified multimodal pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
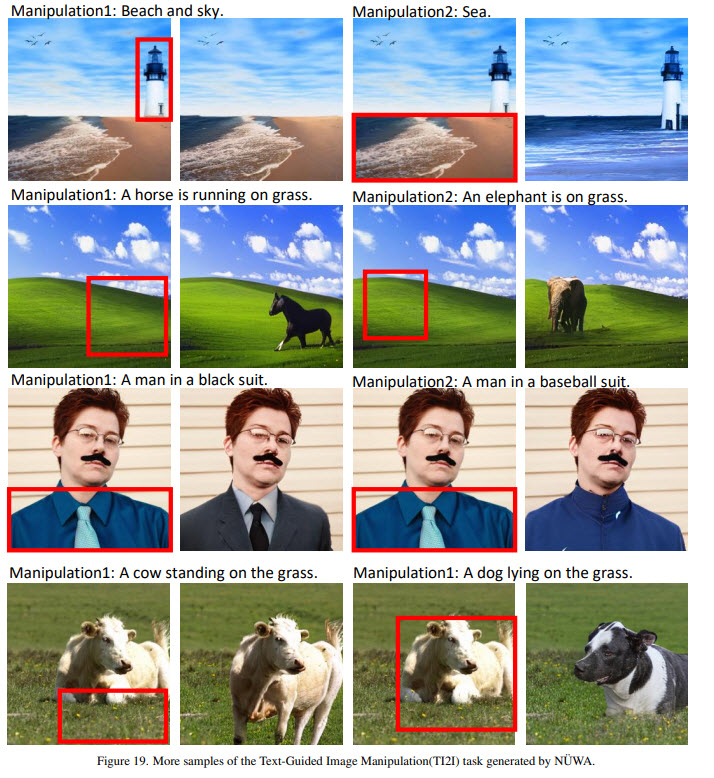
NÜWA not only achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks but also demonstrates good results on zero-shot text-guided image and video manipulation tasks.
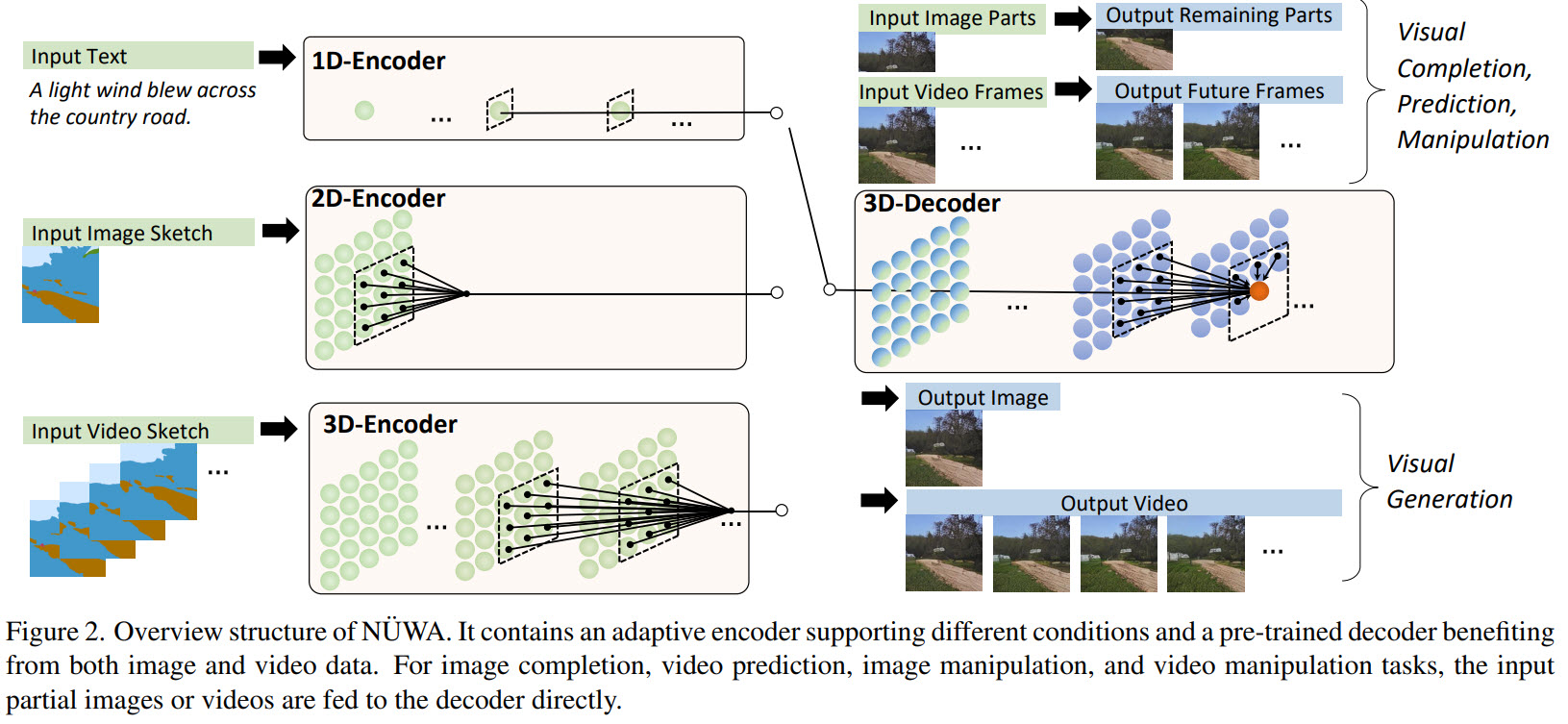
The method
3D Data Representation
All types of the data (texts, images, videos or their sketches) are viewed as tokens and are presented as 3D objects HxWxSxD, where h and w - the number of tokens in height and width, s - the number of tokens in the temporal axis, d - the dimension of each token.
- texts: 1x1xsxd (1 because there is no spatial dimension). Lower-cased BPE for tokenization;
- images: hxwx1xd (s == 1 as there is no spatial dimension). They train VQ-GAN for tokenization;
- videos: hxwxsxd (s is the number of frames). VQ-GAN on each frame for tokenization;
- sketches of images: hxwx1xd. They take a sketch mask HxW, transform it into HxWxC, where C is the number of segmentation classes. Then a separate VQ-GAN for tokenization;
- sketches of videos are hxwxsxd and are tokenizes similar to the previous points;
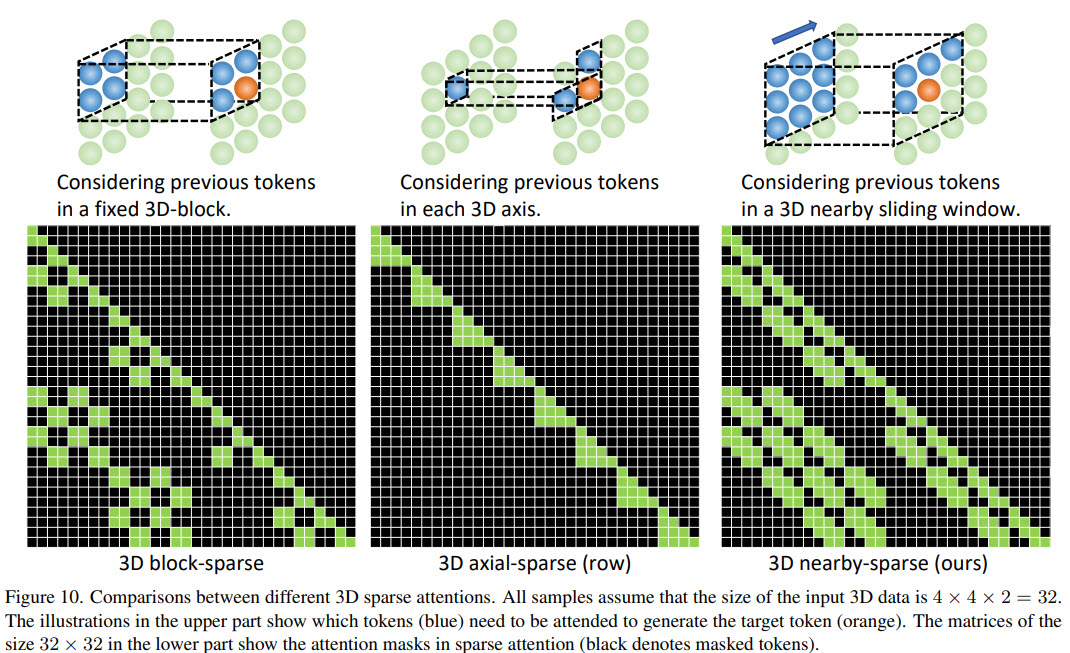
3D Nearby Self-Attention
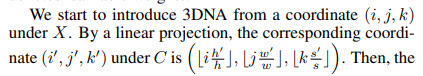

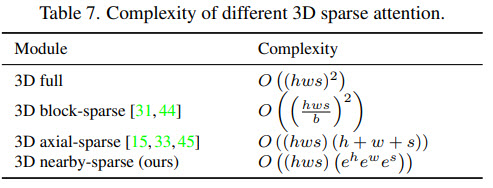
3D Encoder-Decoder
To generate a target Y under condition C, the positional encodings for both of them are updated by three learnable vocabularies; then the condition C is passed through a stack of L 3DNA layers. The decoder is a stack of L 3DNA layers too. It calculates self-attention of generated results and cross-attention between the results and the conditions. The initial token V0,0,0 is a special <bos> learnable token.
Training Objective
The models are trained on three tasks: Text-to-Image (T2I), Video Prediction (V2V), and Text-to-Video (T2V). The loss is cross-entropy.

Experiments
NÜWA is pre-trained on three datasets:
- Conceptual Captions for text-to-image (T2I) generation. 2.9M text-image pairs
- Moments in Time for video prediction (V2V). 727K videos;
- VATEX for text-to-video (T2V) generation. 241K text-video pairs;
3D representation sizes:
- Text: 1 × 1 × 77 × 1280;
- Image: 21 × 21 × 1 × 1280;
- Video: 21 × 21 × 10 × 1280. 10 frames are sampled from a video with 2.5 fps;
The model is pre-trained on 64 A100 GPU for two weeks.
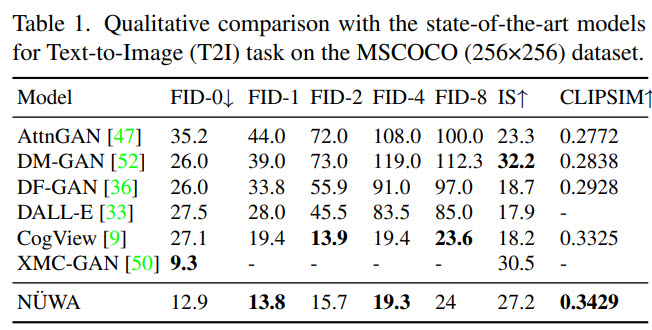
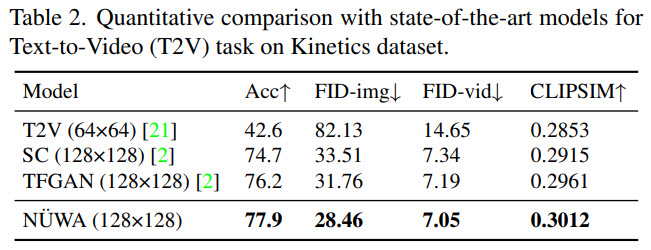
Results
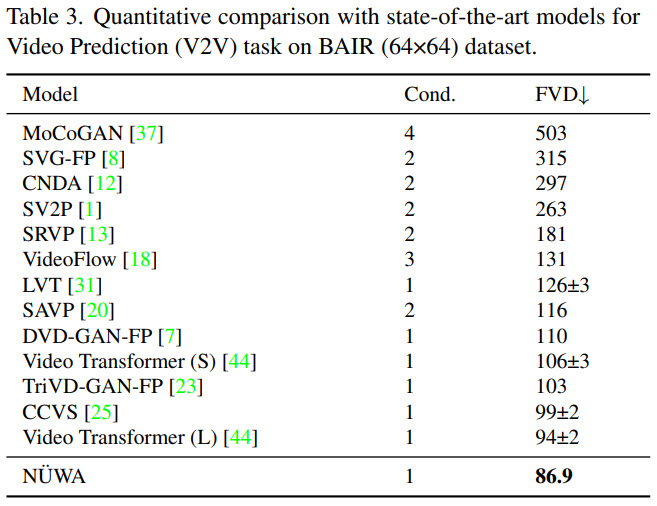





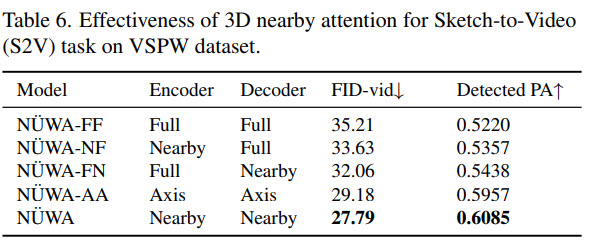
Ablation study
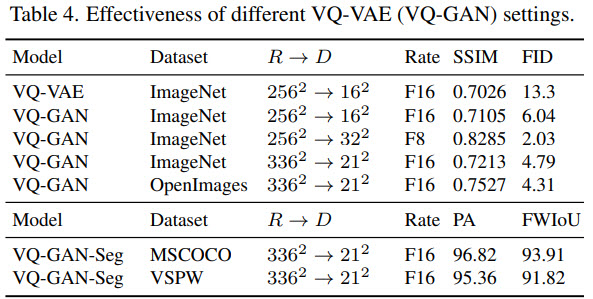
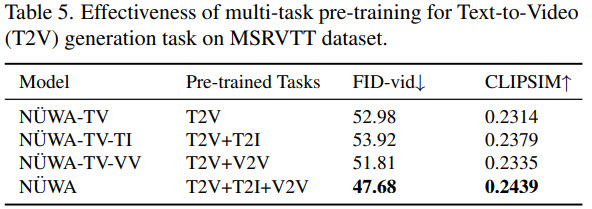

- VQ-GAN is better than VQ-VAE;
- increasing the number of discrete tokens improves the performance at the cost of more computing, so 21 is a trade-off version;
- training on all three objectives is better than using only one or two of them;
- nearby attention is better than full attention;
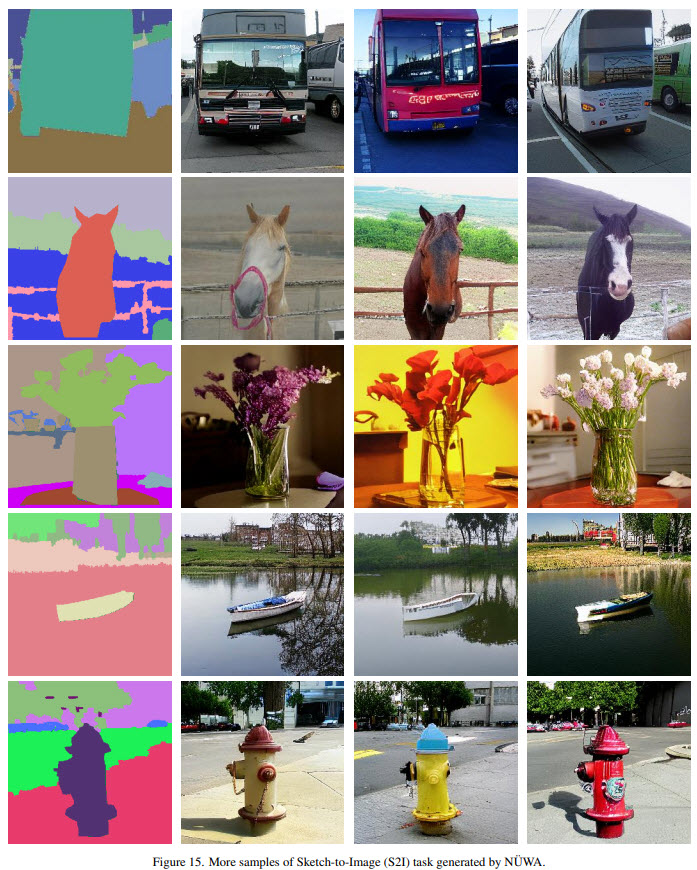
Examples of generated samples