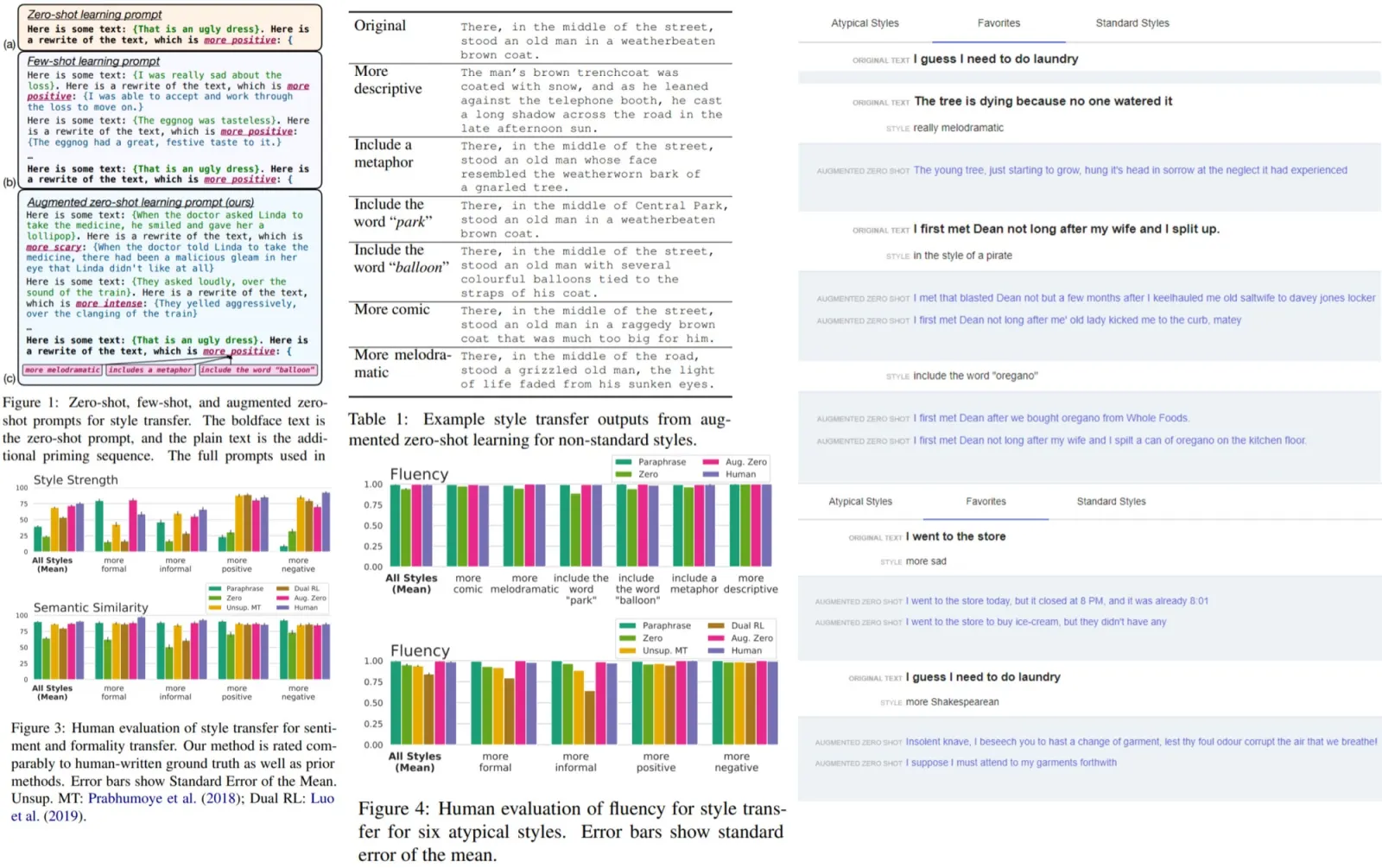
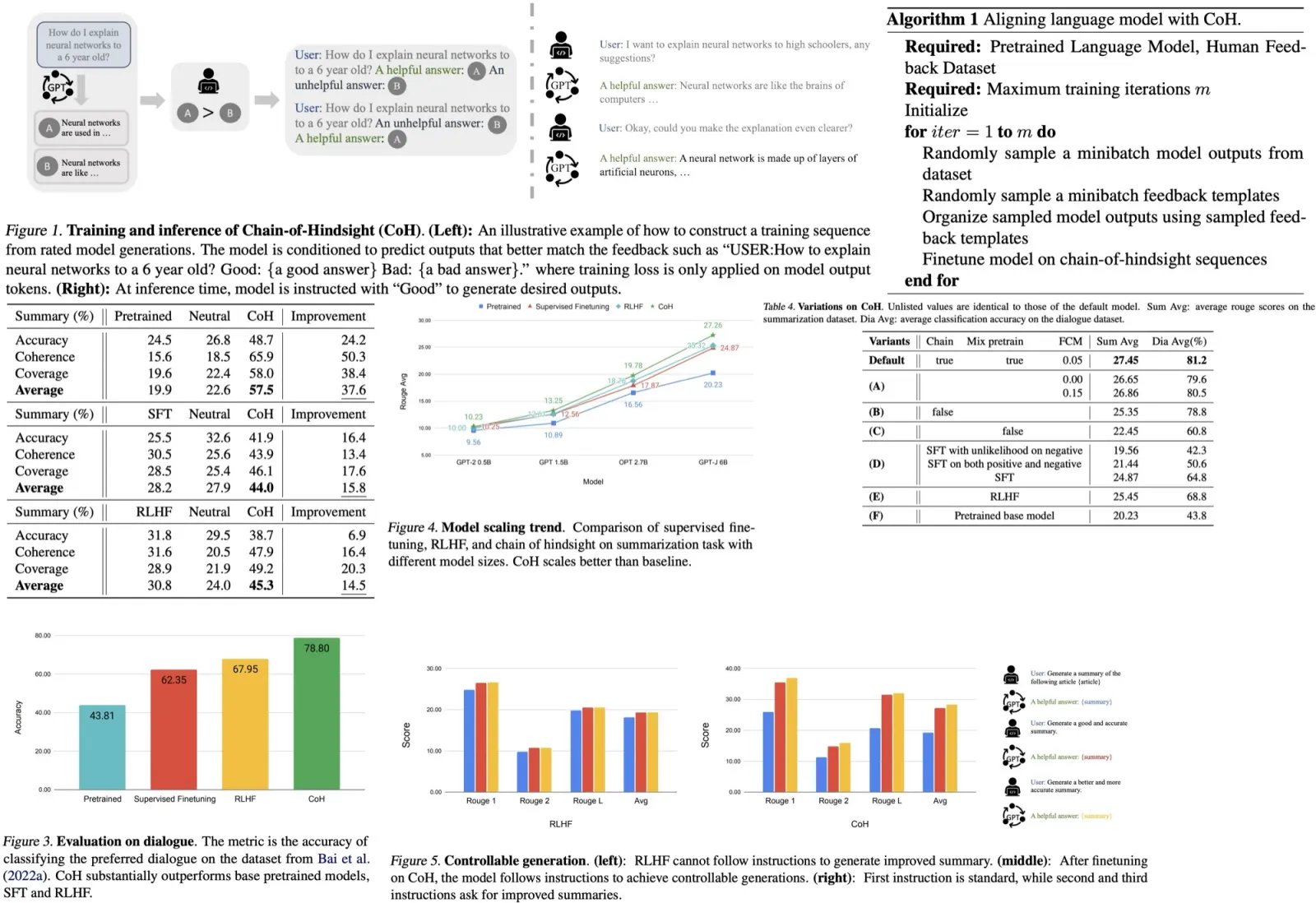
Paper Review: OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents

Large multimodal models that learn from both images and interwoven text perform better than those trained just on image-text pairs. Yet, there hasn’t been a release of the datasets used for these models nor full details on how they were gathered. The OBELISC dataset is introduced as a solution: an extensive, open-access dataset sourced from 141 million web pages on Common Crawl, with 353 million images and 115 billion text tokens. Using OBELISC, two models named IDEFICS were trained, showcasing impressive performance on various multimodal tests.
Creation of the Multimodal Web Document Dataset
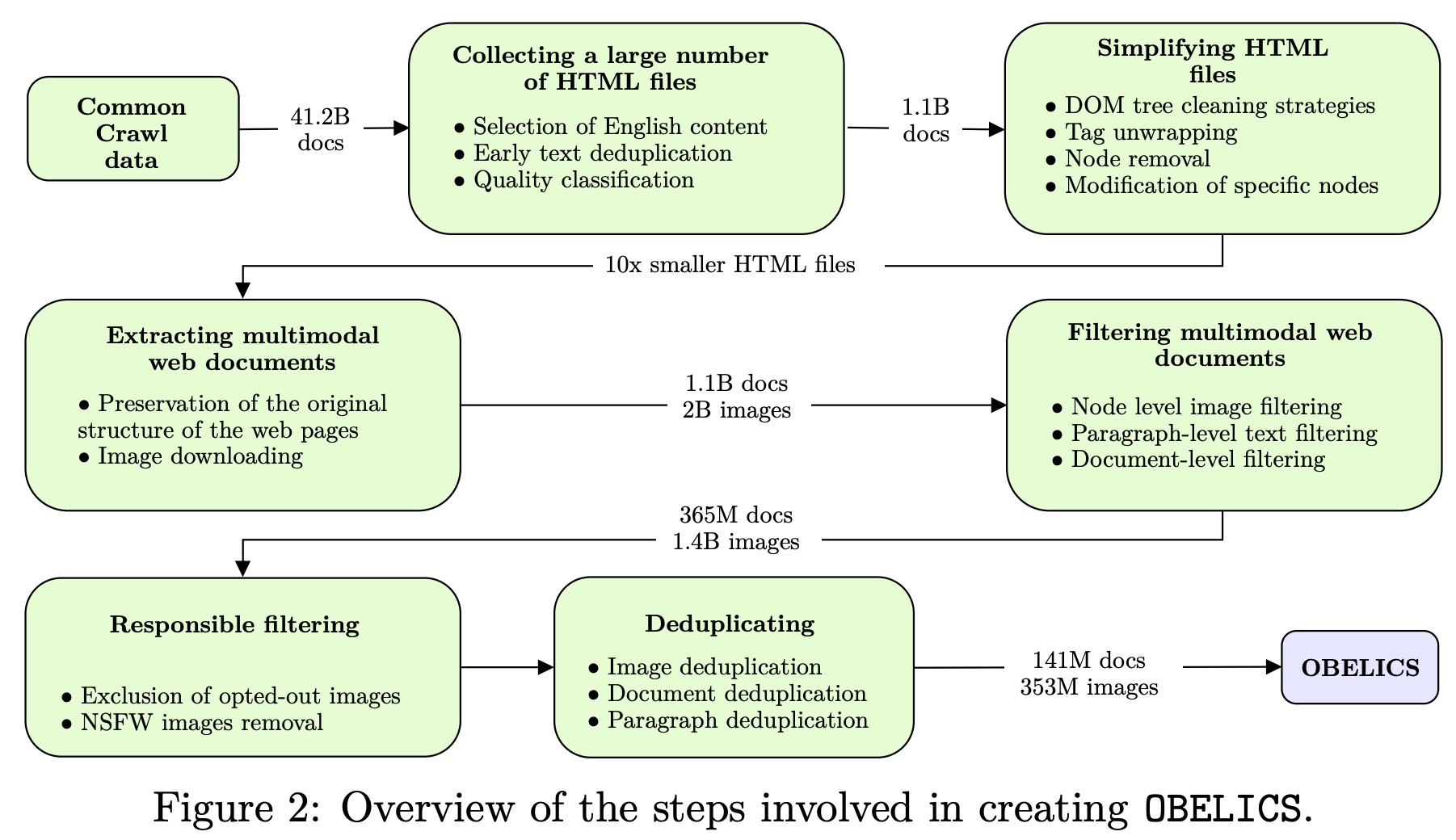
The process of creating the OBELISC dataset involves multiple steps to ensure quality and relevance:
- Collecting HTML Files: Raw web documents are gathered from the 25 most recent Common Crawl dumps, resulting in 41.2 billion documents. FastText is used to filter out non-English content, and MinHash deduplication removes duplicate content. After quality checks using logistic regression, 1.1 billion documents remain.
- Simplifying HTML: The original HTML is simplified to make subsequent text and image extraction more efficient. This results in HTML files that are ten times smaller and stripped of irrelevant content (spam, ads, templates, generic images like logos).
- Extracting Multimodal Content: Simplified HTML files are transformed into structured multimodal web documents. These documents maintain the original structure of web pages and comprise interleaved texts and images. 3.6 billion image links are obtained, and 55% of them are successfully downloaded.
- Filtering Content: Filtering occurs at both the node level for images and the paragraph level for text to retain only high-quality and relevant content. Additional document-level filters (for too low or too high amount of content) are applied, and the dataset is narrowed down to 365 million web documents and 1.4 billion images.
- Responsible Filtering and Deduplication: To respect content creators and minimize inappropriate content, the team implements filters for data consent and removes NSFW images. Deduplication steps are taken at multiple levels—based on URL, image set, and domain name.
After all these steps, the dataset comprises 141 million documents and 353 million images, 298 million of which are unique.
Validating the Viability of OBELISC
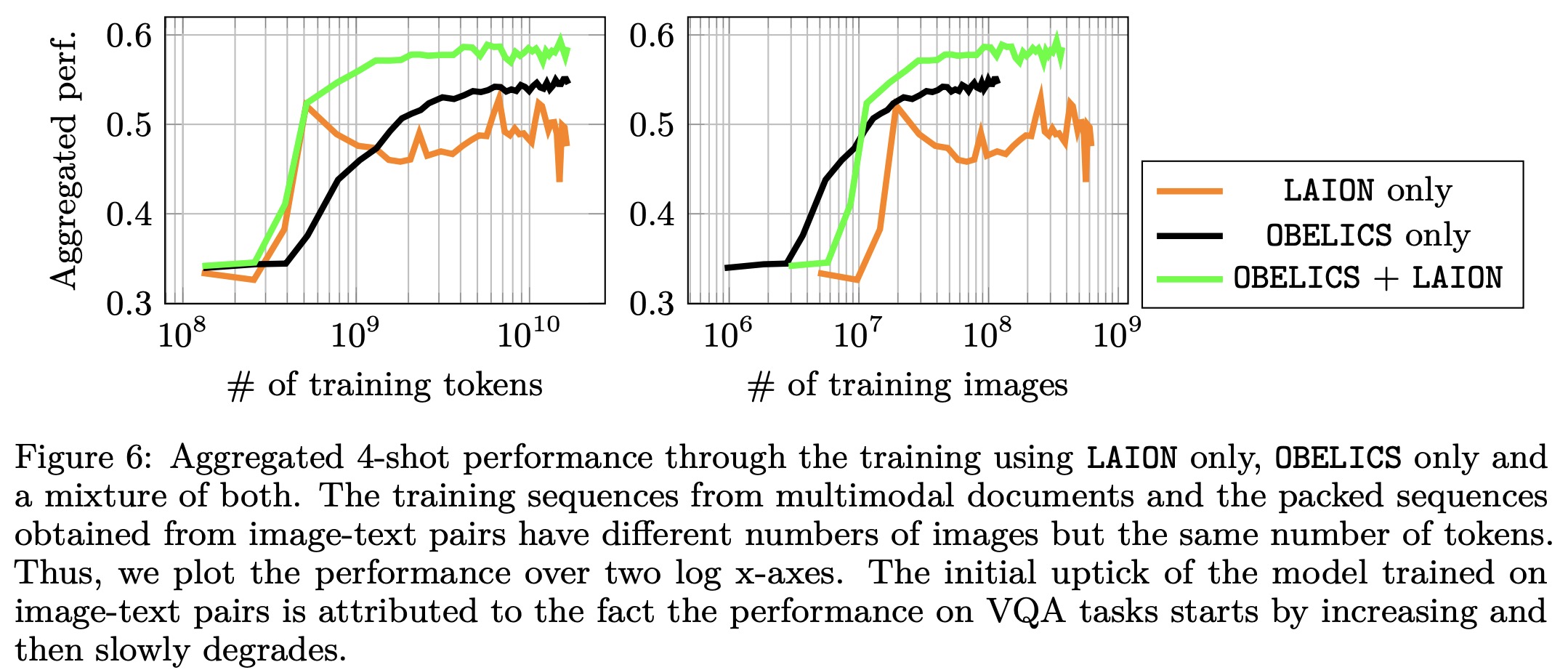
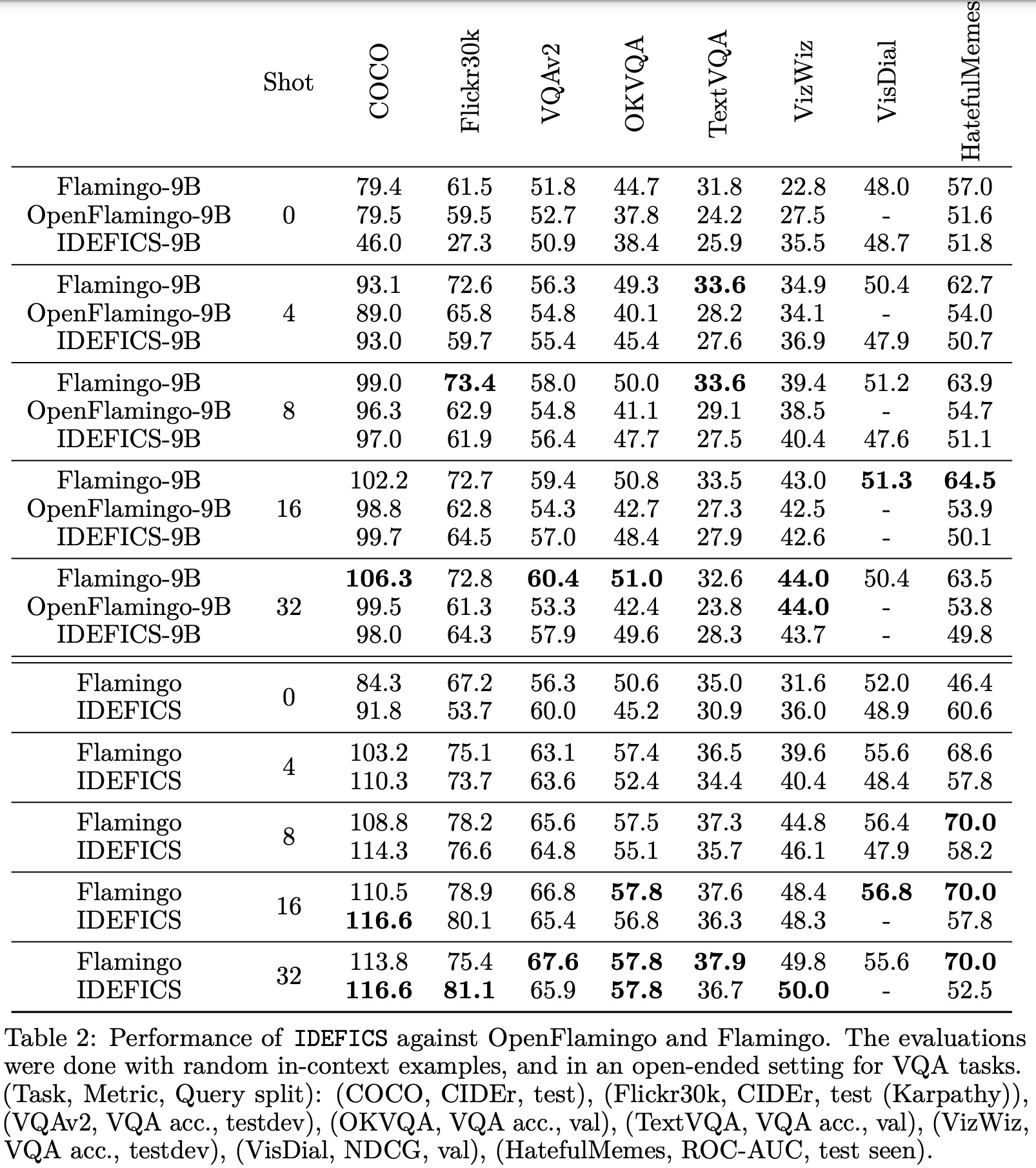
The authors validate the OBELISC dataset by training vision and language models and comparing their performance to models trained on image-text pairs and closed datasets:
- The models use the Flamingo architecture, combining LLaMA for the language model and OpenClip for the vision encoder. They add learnable cross-attention Transformer blocks to link vision and language. The objective is next-token prediction.
- Training on the OBELISC multimodal web documents requires significantly fewer images to reach the same performance as models trained on image-text pairs. The multimodal web document models also generally perform better, particularly on visual question-answering benchmarks. However, image-text pair models perform slightly better in captioning, classification, and OCR tasks.
- Models trained on OBELISC, named IDEFICS, come in two sizes: 80 billion parameters and 9 billion parameters. When compared to Flamingo models of similar sizes, IDEFICS models generally perform on par or better on various multimodal benchmarks. At the 9 billion parameter scale, although IDEFICS-9B is slightly behind Flamingo-9B, it outperforms OpenFlamingo-9B, supporting OBELISC as a viable open alternative for multimodal training datasets.