Paper Review: Tracking Everything Everywhere All at Once

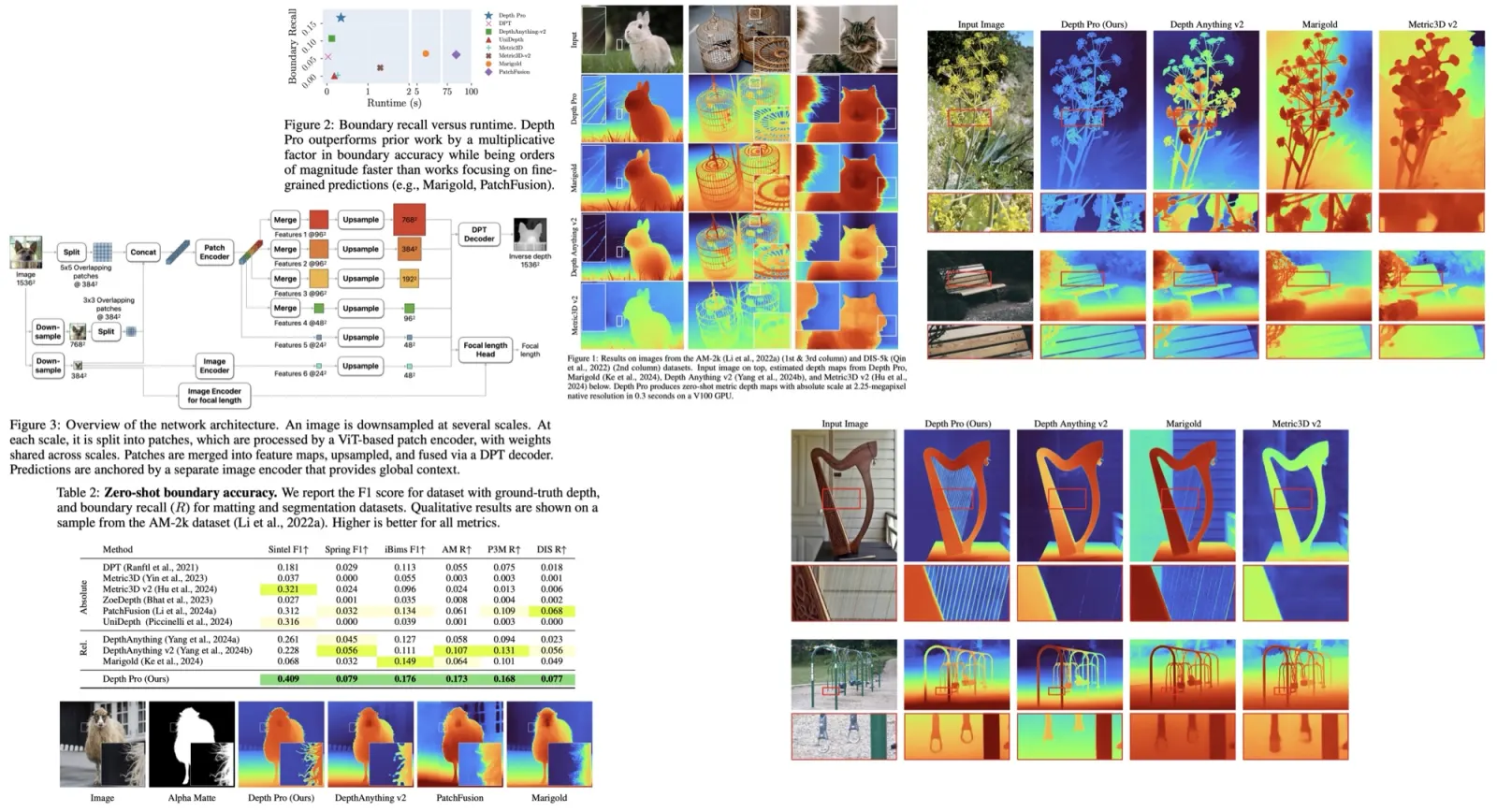
The researchers have developed a new method, OmniMotion, for estimating dense, long-range motion from a video sequence. Traditional optical flow or video tracking algorithms face difficulties in maintaining global consistency and tracking through occlusions due to their limited temporal window operation. OmniMotion, however, offers a globally consistent motion representation by using a quasi-3D canonical volume to represent a video. It also allows pixel-wise tracking through a bijection between local and canonical space, making it possible to track through occlusions and model any combination of camera and object motion. Tests conducted on the TAP-Vid benchmark and real-world videos have demonstrated that OmniMotion outperforms previous best methods significantly in both quantitative and qualitative terms.
OmniMotion representation
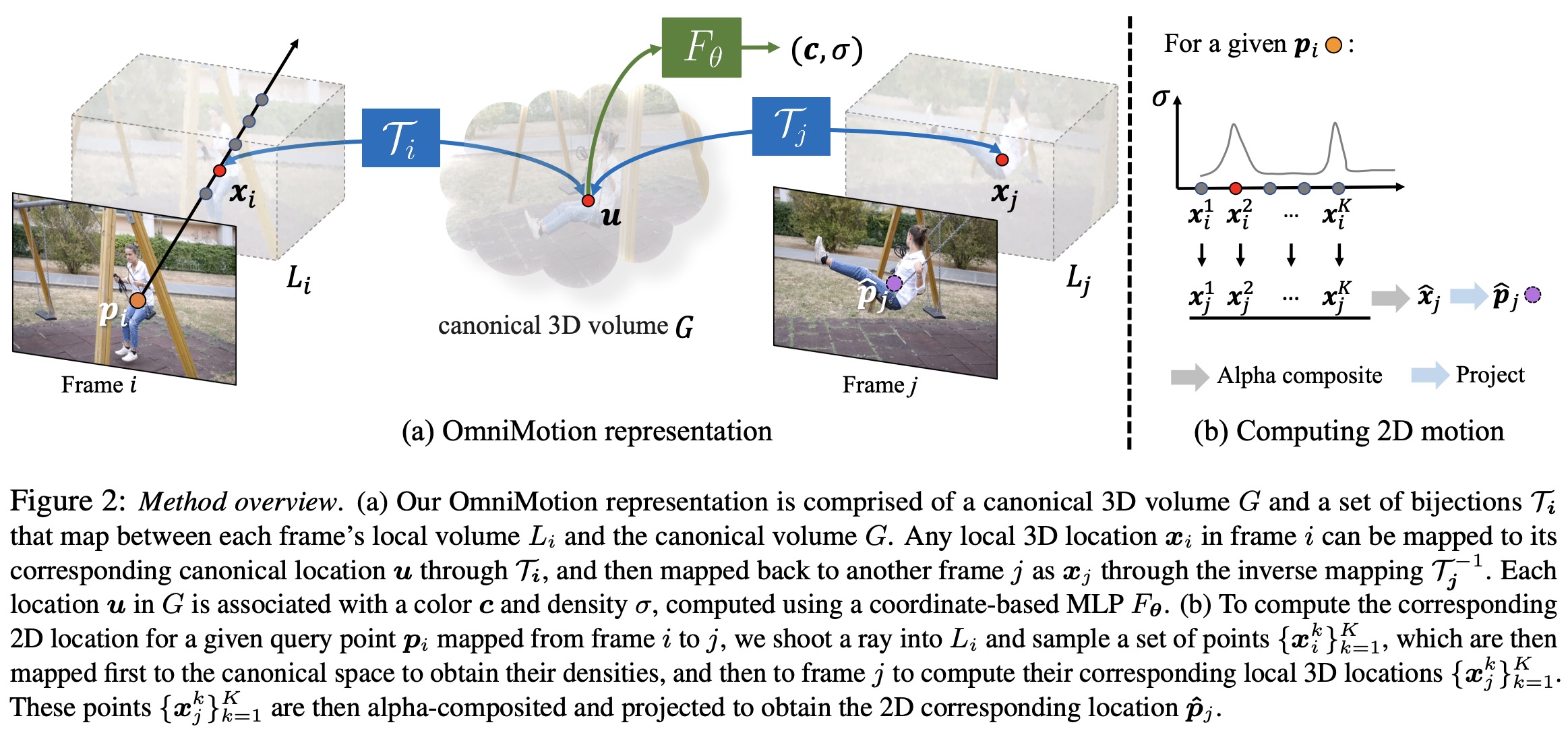
The researchers argue that traditional motion representations like pairwise optical flow lose object tracking when occlusions occur and generate inconsistencies when correspondences span multiple frames. To solve this, they propose a global motion representation, OmniMotion, which provides consistent and accurate tracking even through occlusion. Unlike other global representations like decomposition into depth-separated “layers” or full 3D reconstruction, OmniMotion uses a quasi-3D volume to represent a video scene, bypassing issues with both extremes.
OmniMotion creates a quasi-3D representation of the video, treating the video as a rendering of local volumes from a static camera. It does not explicitly separate camera and scene motion, which allows the avoidance of ambiguities that make dynamic 3D reconstruction difficult. However, it still guarantees globally cycle-consistent 3D mappings across all frames, mimicking the one-to-one correspondences between real-world 3D reference frames. This approach enables tracking of all scene points, even those temporarily occluded, while preserving their relative depth ordering.
Canonical 3D volume
The researchers use a canonical volume as a three-dimensional atlas to represent the content of a video. A coordinate-based network is defined over this volume, mapping each 3D canonical coordinate to a density and a color. The density information is vital as it indicates the location of surfaces in the canonical space. Coupled with the 3D bijections, this permits tracking of surfaces over several frames and reasoning about occlusion relationships. The color information in the volume helps in computing a photometric loss during optimization, aiding in better performance.
3D bijections
Continuous bijective mapping associates 3D points from each local coordinate frame to a canonical 3D coordinate frame. The canonical coordinate is time-independent and serves as a globally consistent “index” for a particular scene point or 3D trajectory over time. By composing these bijective mappings and their inverses, they can map a 3D point from one local coordinate frame to another.
To capture real-world motion, the bijections are parameterized as invertible neural networks (INNs), specifically using Real-NVP due to its simplicity and analytic invertibility. Real-NVP constructs bijective mappings by composing simple bijective transformations known as affine coupling layers. This architecture is modified to also condition on a per-frame latent code. All invertible mappings are parameterized by the same invertible network, but with different latent codes.
Computing frame-to-frame motion
Computing the 2D motion for any pixel in a frame involves four steps:
- Lifting: The pixel in question is translated into 3D space by sampling points along a ray. This ray is defined with a fixed, orthographic camera model.
- Mapping: These 3D points are then mapped to a target frame using the bijective mappings that connect each local frame to the canonical space.
- Rendering: The mapped 3D points from different samples are rendered using alpha compositing, a process that combines colors from different samples based on their density values (similar to NeRF).
- Projecting: The rendered 3D points are projected back to the 2D plane to obtain a final correspondence in the target frame.
Optimization
The researchers’ optimization process inputs a video sequence along with a set of noisy correspondence predictions from an existing method. It uses these inputs to produce a complete and globally consistent motion estimate for the entire video, enhancing the accuracy and consistency of motion tracking.
Collecting input motion data
In their experiments, the researchers mainly use an existing method called RAFT to compute initial correspondence between frames, though they also test with another method called TAP-Net. After computing optical flows, which represent the apparent motion of objects in the scene, they filter out unreliable data using cycle consistency and appearance consistency checks. They can optionally augment the flows through chaining if it’s reliable enough. Despite this filtering, the optical flows still contain noise and inconsistencies. They then introduce their optimization method that consolidates these noisy, incomplete pairwise motions into complete and accurate long-range motion for the entire video.
Loss functions
The researchers use three types of loss functions in their optimization process:
- Flow Loss: They aim to minimize the mean absolute error between the predicted flow from their representation and the supervising input flow.
- Photometric Loss: This loss function minimizes the mean squared error between the predicted color and the observed color in the source video frame.
- Regularization term: To ensure smoothness of the 3D motion, a regularization term is applied that penalizes large changes in acceleration.
The final combined loss can is a sum of these three losses, each with a weight controlling their relative importance.
The goal of this optimization process is to leverage the bijections to a single canonical volume, photo consistency, and the spatiotemporal smoothness provided by the networks to reconcile inconsistent pairwise flow and fill in missing content in the correspondence graphs.
Balancing supervision via hard mining
The researchers’ approach to collecting exhaustive pairwise flow input can lead to an imbalance in motion samples, especially in dynamic regions. The rigid background regions tend to have many reliable correspondences, while fast-moving and deforming foreground objects usually have fewer reliable correspondences. This can cause the network to focus mainly on the dominant background motions and overlook the challenging moving objects.
To counter this issue, they periodically store flow predictions and compute error maps, which calculate the Euclidean distance between the predicted and input flows. These error maps guide their sampling process during optimization, causing regions with high errors to be sampled more often. The error maps are computed on consecutive frames where the supervisory optical flow is assumed to be most reliable.
Evaluation

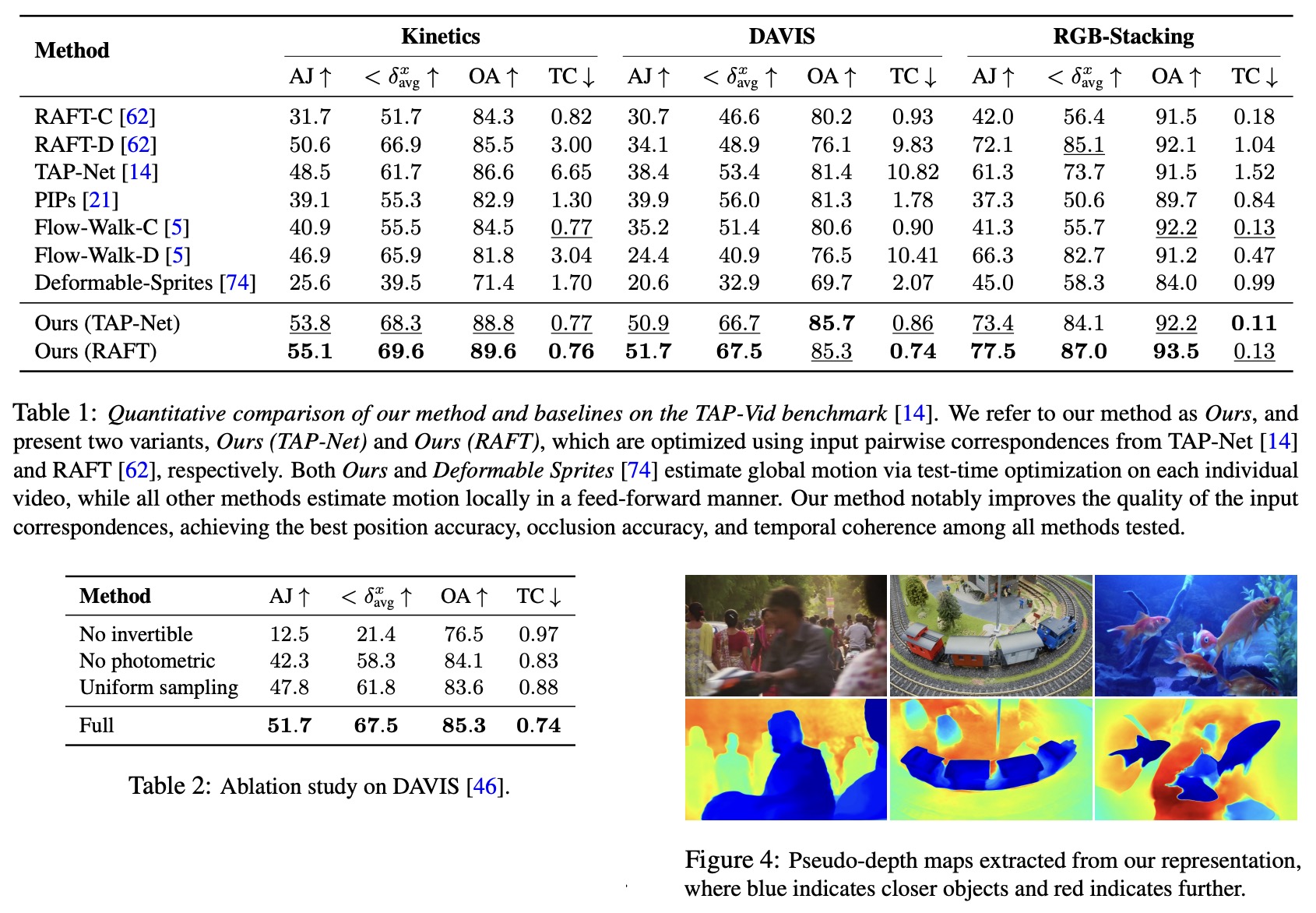
- In quantitative comparisons on the TAP-Vid benchmark, the proposed method outperforms all baselines in position accuracy, occlusion accuracy, and temporal coherence across various datasets. This performance is consistent regardless of the input pairwise correspondences from RAFT and TAP-Net, offering significant improvements over both base methods. The proposed method offers superior temporal coherence compared to approaches operating on non-adjacent pairs of frames. It also outperforms chaining-based methods in tracking performance, especially on longer videos.
- In qualitative comparisons, the method shows strong capabilities in tracking through extended occlusions and handling large camera motion parallax.
- A series of ablation studies were conducted to verify the effectiveness of the design decisions. These included a model variant without invertible mapping, a version without the photometric loss, and a strategy that replaces hard-mining sampling with uniform sampling. The findings from these ablations reinforced the importance of various components of the proposed method.
- An analysis using pseudo-depth maps demonstrated the method’s ability to effectively sort out the relative ordering between different surfaces, a crucial feature for tracking through occlusions. More ablations and analyses are available in the supplemental material.
Limitations
While the method presents significant advancements in motion estimation, it does have a few limitations. It can struggle with rapid and highly non-rigid motion as well as thin structures. In these cases, pairwise correspondence methods may not provide enough reliable correspondences for accurate global motion computation. Additionally, due to the complex nature of the optimization problem, the training process can occasionally get stuck at sub-optimal solutions.
The method can also be computationally expensive. The process of collecting flow involves calculating all pairwise flows, which scales quadratically with sequence length, although improvements could be made by exploring more efficient alternatives to exhaustive matching. Similarly, like other methods using neural implicit representations, the optimization process can be quite long. However, recent research could potentially help to speed up this process and allow for scaling to longer sequences.
paperreview deeplearning cv motiontracking video