Paper Review: Orca 2: Teaching Small Language Models How to Reason
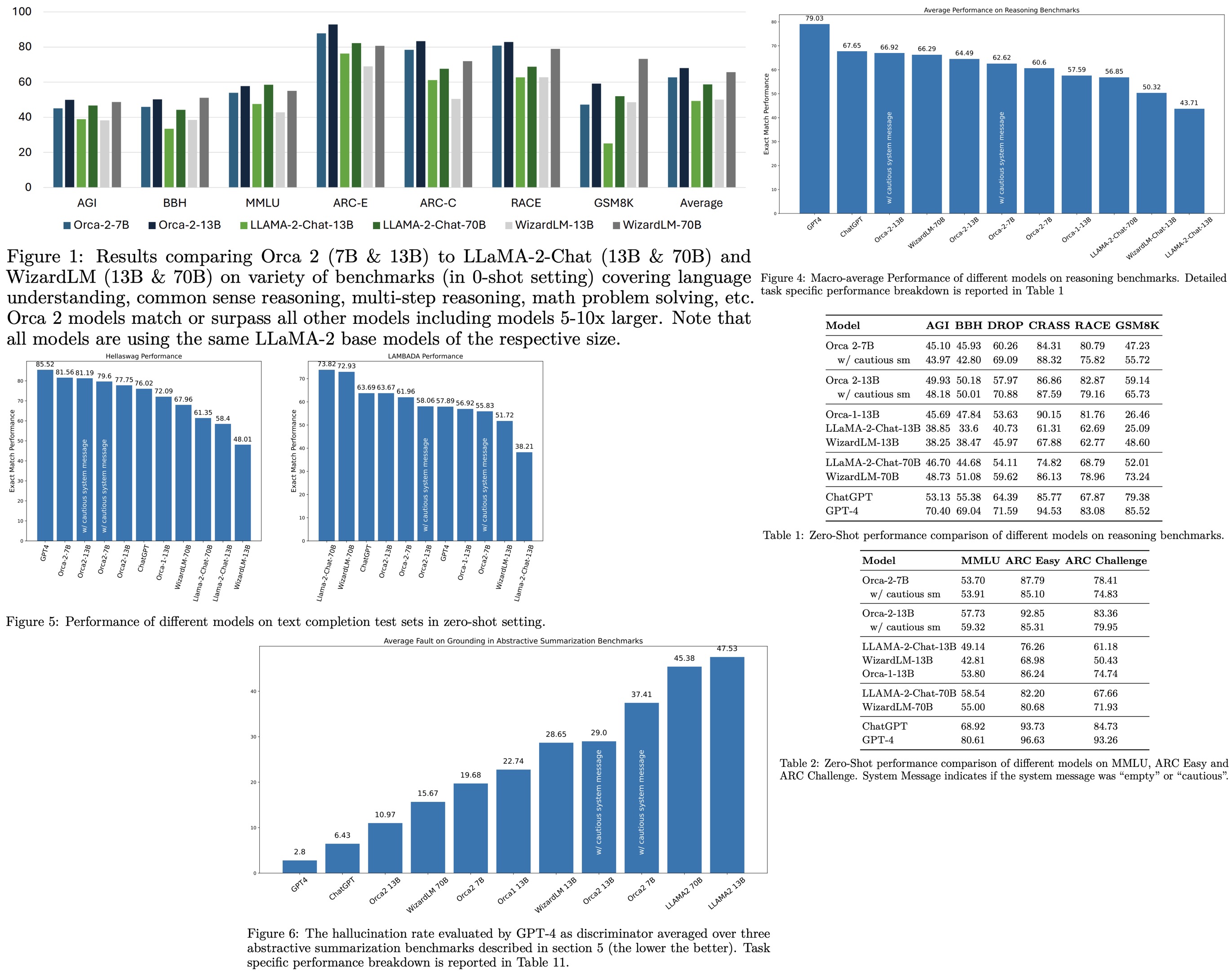
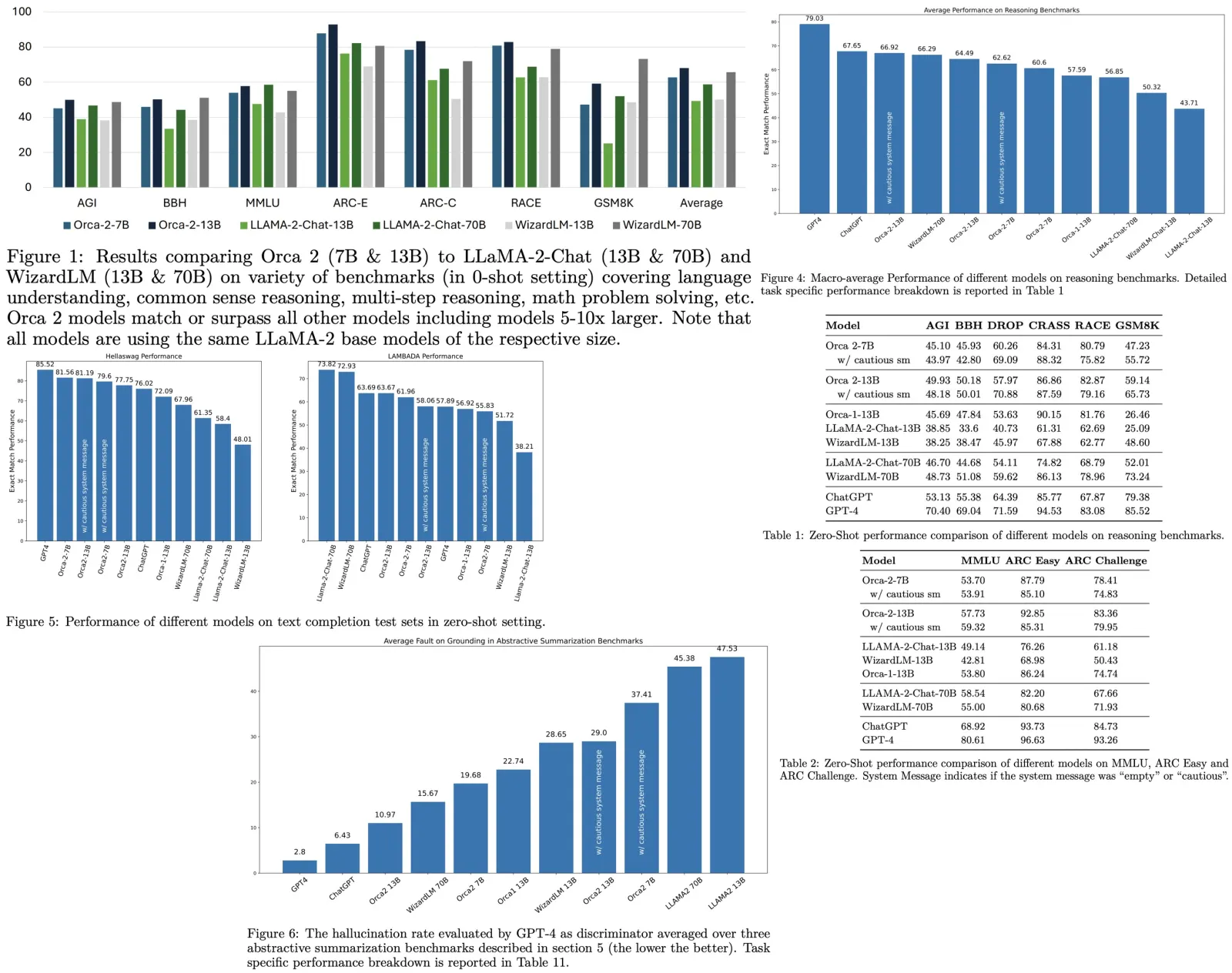
Orca 1 improved upon conventional instruction-tuned models by learning from rich signals, such as explanation traces, and showed superior performance on challenging benchmarks like BigBench Hard and AGIEval. Orca 2 builds on this by focusing on enhancing the reasoning abilities of smaller language models (LMs). Unlike previous approaches that primarily used imitation learning, where smaller models mimic the output of larger ones, Orca 2 aims to teach small LMs various reasoning techniques (like step-by-step, recall then generate, etc.) and to determine the most effective strategy for each task. This approach allows smaller models to solve problems differently from larger models, which may directly answer complex tasks. Orca 2 was evaluated using 15 diverse benchmarks, corresponding to around 100 tasks and over 36,000 unique prompts. The results show that Orca 2 significantly outperforms models of similar size and achieves performance levels comparable to or better than models 5-10 times larger, particularly in complex tasks requiring advanced reasoning in zero-shot settings.
Preliminaries
- Instruction Tuning involves training LMs using input-output pairs where the input is a natural language task description and the output is a demonstration of the desired behavior. It has been effective in improving a model’s ability to follow instructions, enhancing the quality of its outputs, and boosting zero-shot and reasoning abilities. However, instruction tuning mainly teaches a model how to solve a task without necessarily adding new knowledge.
- To address the limitations of instruction tuning, Explanation Tuning was introduced in Orca 1. It involves training student models on richer and more expressive reasoning signals, obtained by crafting system instructions to elicit detailed explanations from a teacher model. These system instructions, like “think step-by-step” or “generate detailed answers,” are designed to extract demonstrations of careful reasoning from advanced LMs like GPT-4. The training dataset consists of triplets (system instruction, user prompt, LLM answer), and the student model learns to predict the LLM answer from the system instruction and user prompt.
Teaching Orca 2 to be a Cautious Reasoner
Explanation Tuning in training language models involves extracting detailed explanations based on specific system instructions, but the effectiveness varies with different instruction-task combinations. An example with GPT-4 and a story reordering question demonstrates this variability. Four different system instructions led to distinct responses: the default GPT-4 answer was wrong; a chain-of-thought prompt improved the response but missed key details; an explain-your-answer prompt resulted in a correct explanation but a wrong answer; and finally, system instruction yielded the only correct response.

GPT-4’s responses are heavily influenced by system instructions, and appropriate instructions can significantly enhance the quality and accuracy of its answers. This leads to the concept of “Cautious Reasoning” for training smaller language models, emphasizing the need for these models to select the most effective solution strategy based on the task at hand. This approach differs from larger models like GPT-4, as smaller models may require different strategies, such as step-by-step reasoning. The training process involves the following:
- Starting with a collection of diverse tasks.
- Determining which tasks require which solution strategy (e.g., direct-answer, step-by-step, explain-then-answer).
- Writing task-specific system instructions to elicit teacher responses for each task.
- Using Prompt Erasing during training, where the student model’s specific system instruction is replaced with a generic one, removing details on how to approach the task.
By using Prompt Erasing the student model is encouraged to learn the underlying strategy and reasoning abilities on its own, without relying on the structured guidance initially provided by the teacher model. This method aims to enhance the model’s independent reasoning skills, making Orca 2 a cautious reasoner capable of determining effective strategies for various tasks without explicit, detailed instructions.
Experiments
The Orca 2 dataset comprises four main sources:
- FLAN: The primary source is the FLAN-v2 Collection. 1448 high-quality tasks are selected, grouped into 23 categories and further divided into 126 sub-categories. These tasks are used to create the Cautious-Reasoning-FLAN dataset, with a focus on zero-shot user queries. All system instructions in this dataset are replaced with:
You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior.
- Few-Shot Data: To help the model learn from few-shot demonstrations, a dataset of 55K samples is created by reformatting data from the Orca 1 dataset.
- Math: This part of the dataset includes around 160K math problems sourced from various datasets like Deepmind Math, GSM8K, AquaRat, MATH, AMPS, FeasibilityQA, NumGLUE, AddSub, GenArith, and Algebra.
- Fully Synthetic Data: This includes 2000 synthetically created Doctor-Patient Conversations using GPT-4, followed by instructing the model to summarize these conversations in four sections. Two different prompts are used to guide the model, focusing on avoiding omissions or fabrications, thereby assessing the learning of specialized skills.
Training
- Progressive Learning: The training begins with either the LLaMA-2-7B or LLaMA-2-13B checkpoint. The model is first fine-tuned on the FLAN-v2 datase, then it is trained on 5 million ChatGPT data points from Orca 1, followed by training on a combination of 1 million GPT-4 data points from Orca 1 and 817K data points from Orca 2.
- Other: The LLaMA BPE tokenizer is used for processing input examples. To optimize training efficiency, a packing technique is used: multiple input examples are concatenated into a single sequence up to a maximum length of 4096 tokens. The loss is computed only on the tokens generated by the teacher model. This approach focuses the learning process on generating responses conditioned on the system instruction and task instructions, enhancing training efficiency and effectiveness.
Orca 2 is trained on 32 NVIDIA A100 GPUs for around 80 hours in total.
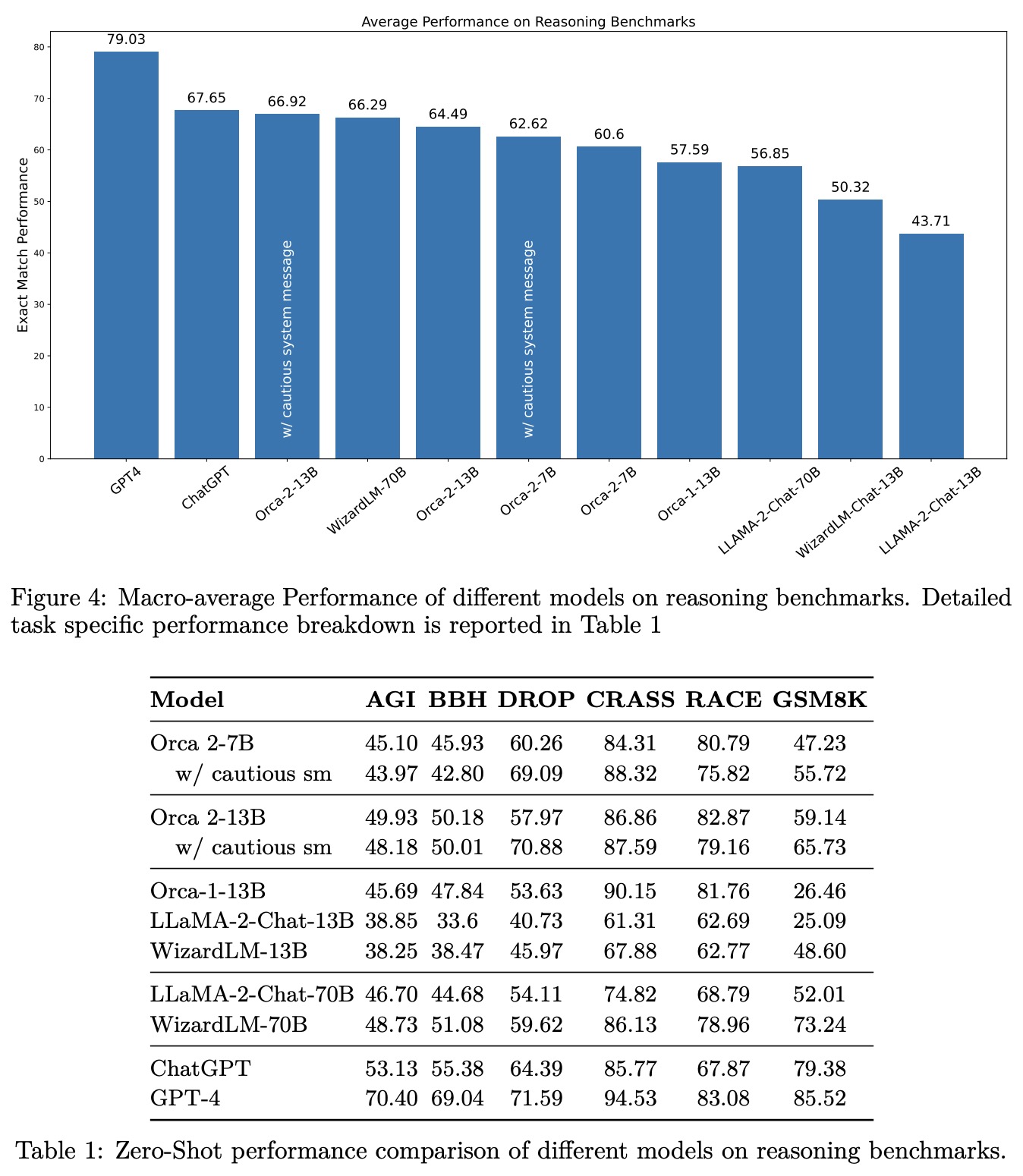
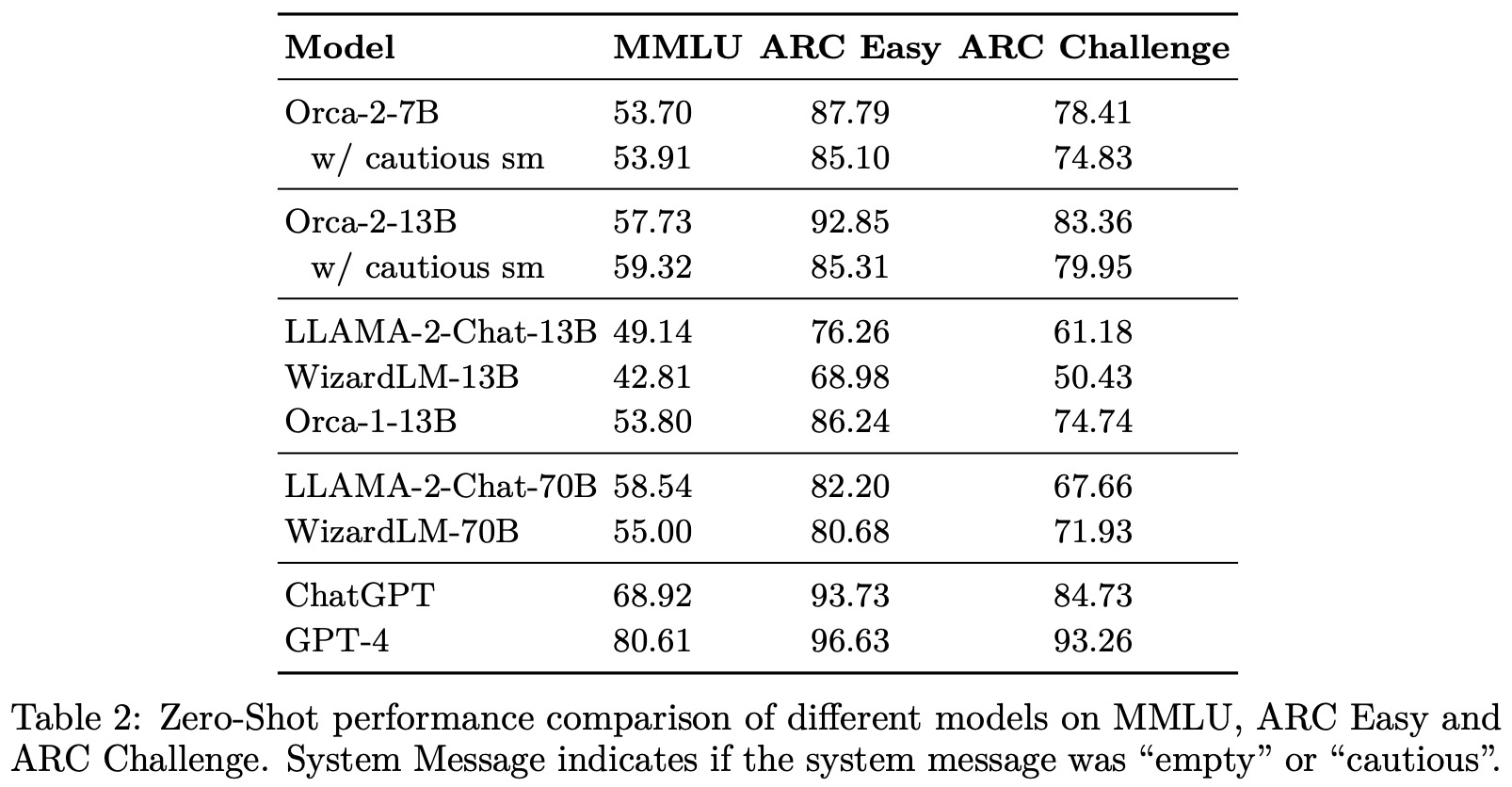
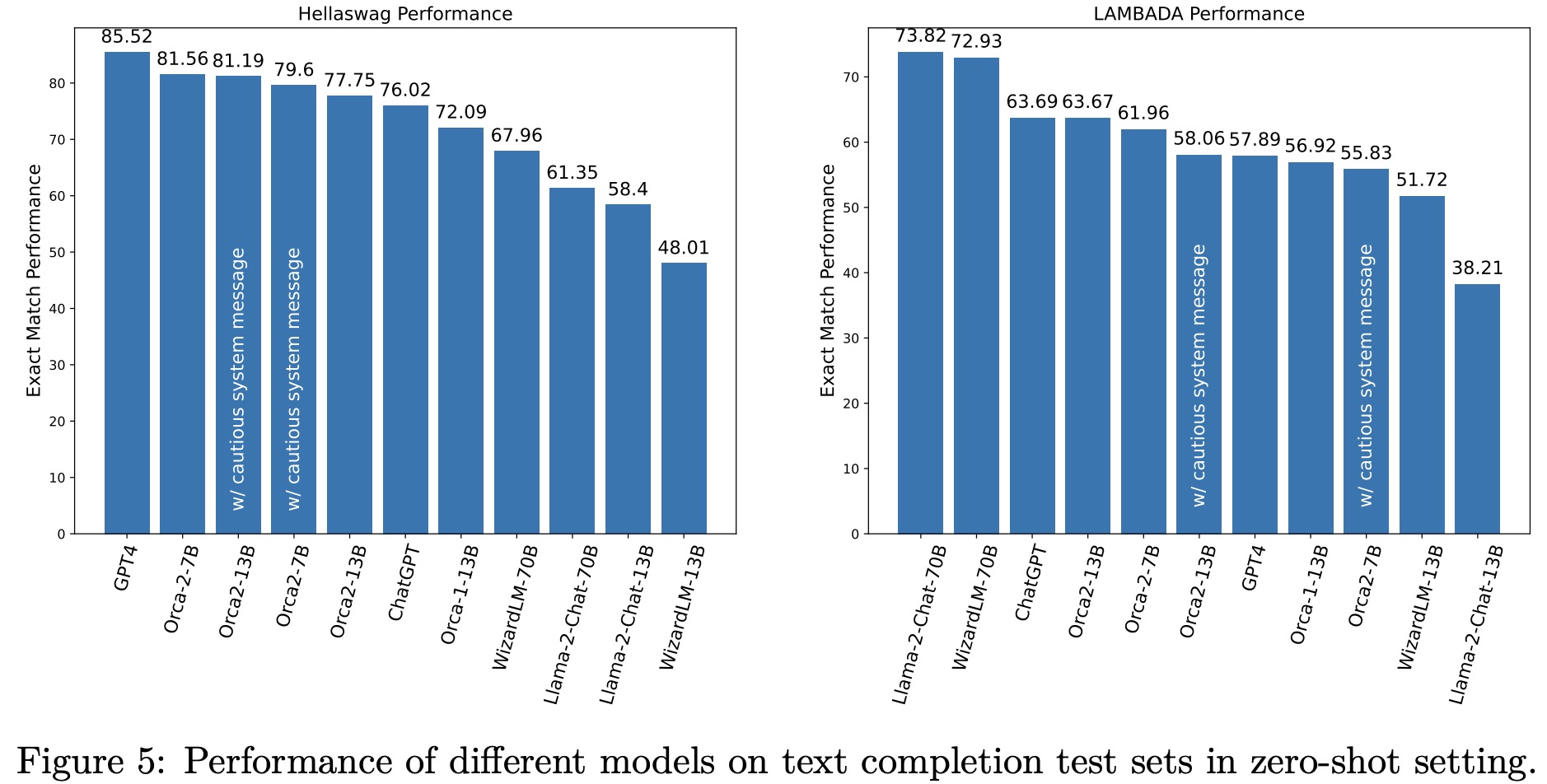
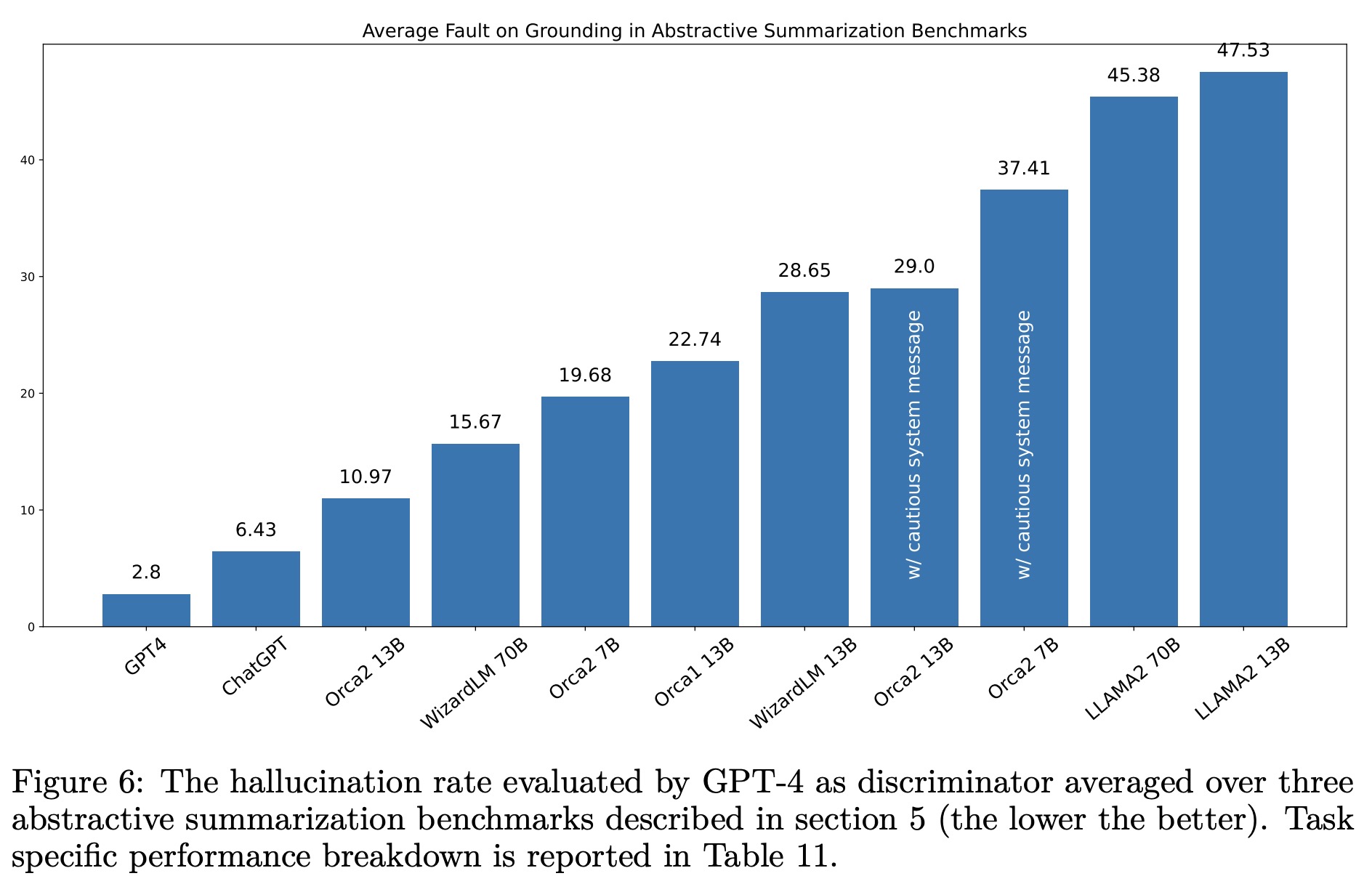
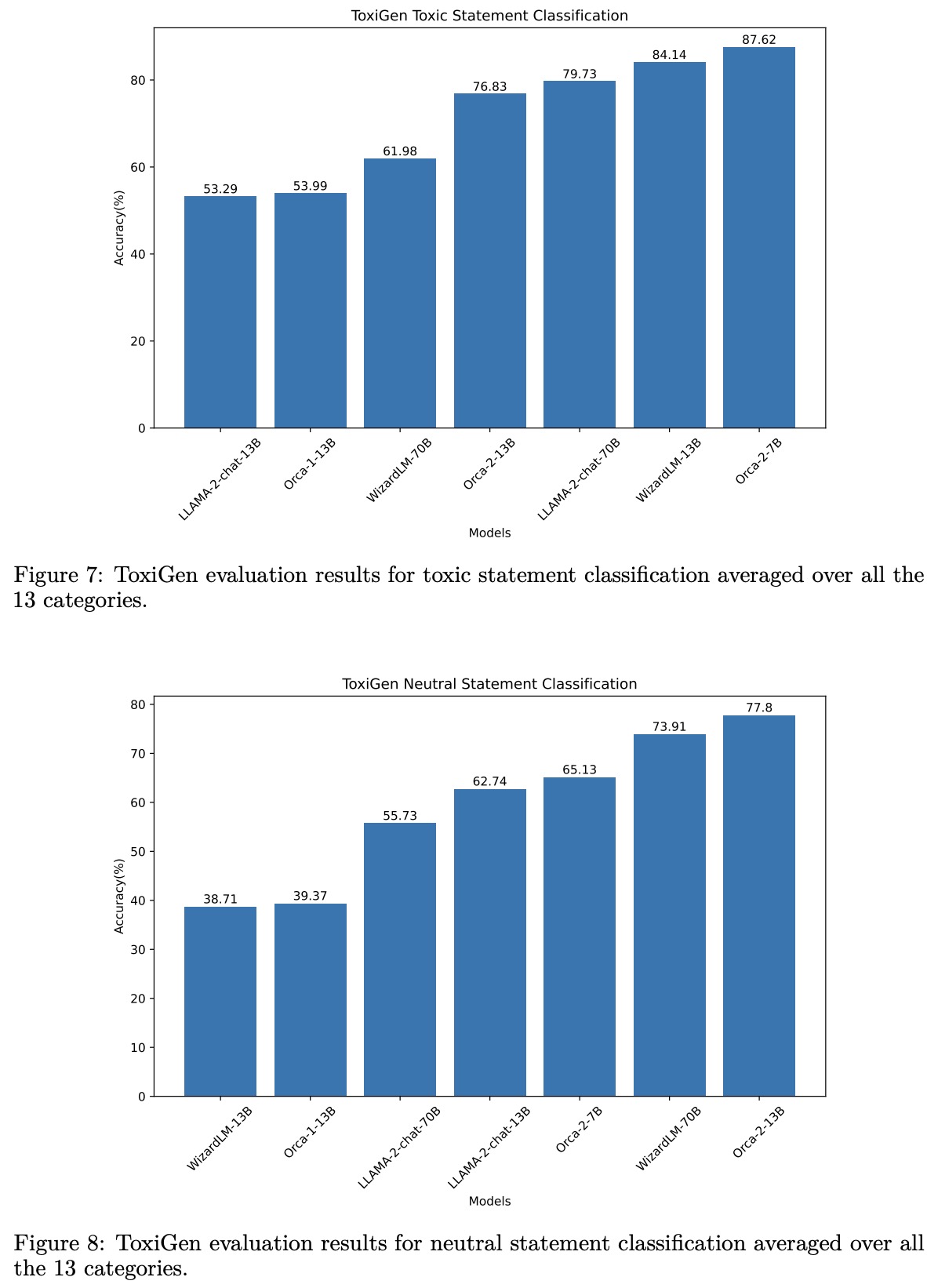
The evaluation of Orca 2 models covers various aspects of language model performance, including reasoning, language understanding, text completion, conversational abilities, grounding, and task-specific data handling.
- Reasoning: Orca 2 models, particularly Orca-2-13B, show superior performance in zero-shot reasoning tasks compared to models of the same size and are competitive with models 5-10 times larger. The cautious system message provides a slight improvement in performance.
- Knowledge and Language Understanding: In benchmarks like MMLU, ARC-Easy, and ARC-Challenge, Orca-2-13B outperforms models of the same size and is competitive with larger models. The results align with publicly reported zero-shot settings, although few-shot settings show higher performance for some models.
- Text Completion: Orca-2 models excel in text completion tasks like HellaSwag and LAMBADA. However, some larger models, like GPT-4, show limitations in tasks like LAMBADA.
- Multi-Turn Open Ended Conversations: Orca-2-13B performs comparably with other 13B models in multi-turn conversations, despite a lower average score in the second turn. This is attributed to the lack of conversational data in its training.
- Grounding: Orca-2-13B shows the lowest rate of hallucination among all models tested, indicating strong performance in generating responses grounded in specific contexts. However, the cautious system message tends to increase hallucination rates.
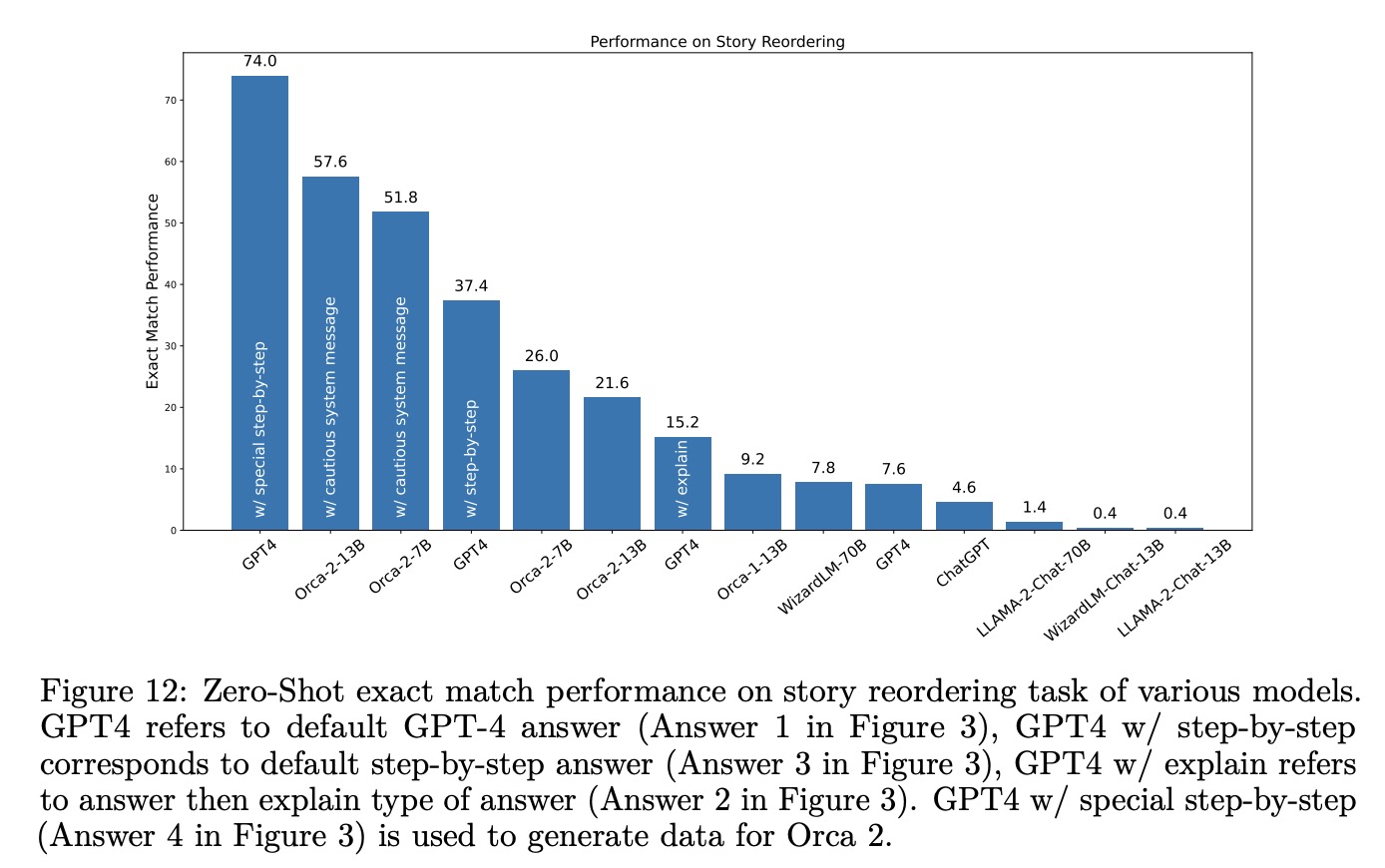
- Effect of Task-Specific Data with Story Reordering: Specializing Orca 2 models for specific tasks using synthetic data generated with prompt erasing shows potential, as demonstrated in a story reordering task using the ROCStories corpus.