Paper Review: PaLM-E: An Embodied Multimodal Language Model

The authors propose using “embodied language models” to incorporate real-world sensory information into language models and enable them to perform tasks related to robotics and perception. These models are trained end-to-end with a large language model and multiple sensory inputs, including visual and textual information, to perform tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The paper presents evaluations demonstrating the proposed approach’s efficacy, including positive transfer across domains. The largest model, PaLM-E-562B, performs well on robotics tasks and exhibits state-of-the-art performance on OK-VQA while retaining generalist language capabilities.

The main contributions:
- The authors propose and demonstrate that it is possible to train a generalist, multi-embodiment decision-making agent by incorporating embodied data into the training of a multimodal large language model;
- They show that it is possible to train a competent general-purpose visual-language model that is also an efficient embodied reasoner;
- The authors introduce novel architectural ideas to optimize the training of such models, including neural scene representations and entity-labeling multimodal tokens;
- They demonstrate that PaLM-E, their proposed embodied reasoner, is also a competent vision and language generalist;
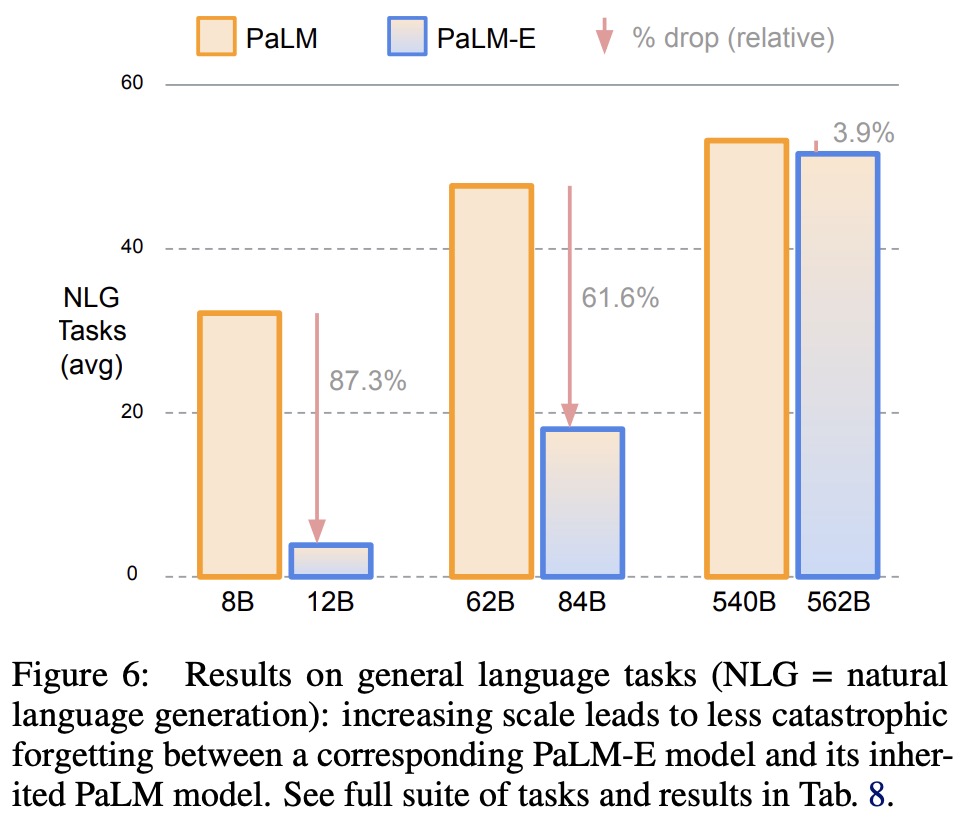
- They show that scaling the language model size enables multimodal fine-tuning with less catastrophic forgetting;

The model
PaLM-E is an embodied language model that injects continuous, embodied observations (such as images or state estimates) into the language embedding space of a pre-trained language model, using PaLM as the base model. It generates textual completions given a prefix or prompt and takes in multi-modal sentences consisting of text and continuous observations. The model outputs text that could be an answer to a question or a sequence of decisions to be executed by a robot. When tasked with producing plans, PaLM-E assumes the existence of a low-level policy or planner to translate decisions into actions.
Prefix-decoder-only LLMs are autoregressive language models that can be conditioned on a prefix or prompt, without the need to change the model’s architecture. The prefix provides context for the model to predict subsequent tokens. This approach is commonly used for inference, where the prompt contains a description of the task or examples of desired text completions for similar tasks, allowing the model to make predictions that are more aligned with the desired output.
The paper describes a method for injecting multi-modal information, such as image observations, into a language model (LLM) by mapping continuous observations into the language embedding space. This is done by training an encoder that maps a continuous observation space into a sequence of vectors that are interleaved with normal embedded text tokens to form the prefix for the LLM. Each vector in the prefix is either a word token embedder or an encoder for an observation. The injection of continuous information is done dynamically within the surrounding text, rather than at fixed positions. This approach reuses the existing positional encodings of the LLM. It is possible to interleave different encoders at different locations in the prefix to combine information from different observation spaces.
PaLM-E is a generative language model that produces text based on multi-modal sentences as input. The output of the model can be directly used as a solution for tasks that can be accomplished by outputting text, such as embodied question answering or scene description tasks. However, if PaLM-E is used to solve an embodied planning or control task, it generates text that conditions low-level commands. In this case, PaLM-E is integrated into a control loop, where its predicted decisions are executed through low-level policies by a robot. This leads to new observations based on which PaLM-E can replan if necessary. PaLM-E can be understood as a high-level policy that sequences and controls the low-level policies. The policies used in the control loop are language conditioned, but are not capable of solving long-horizon tasks or taking in complex instructions.
Input & Scene Representations for Different Sensor Modalities
The authors use different architectures for different modalities.
State estimation vectors contain information such as pose, size, and color. The model uses an MLP to map the state vector into a language embedding space.
ViT maps an image into a sequence of token embeddings. The authors consider several variants, including the ViT-4B and ViT22B models, as well as ViT token learner architecture (ViT + TL) trained from scratch. To ensure compatibility with the language model, the embeddings are projected using a learned affine transformation.
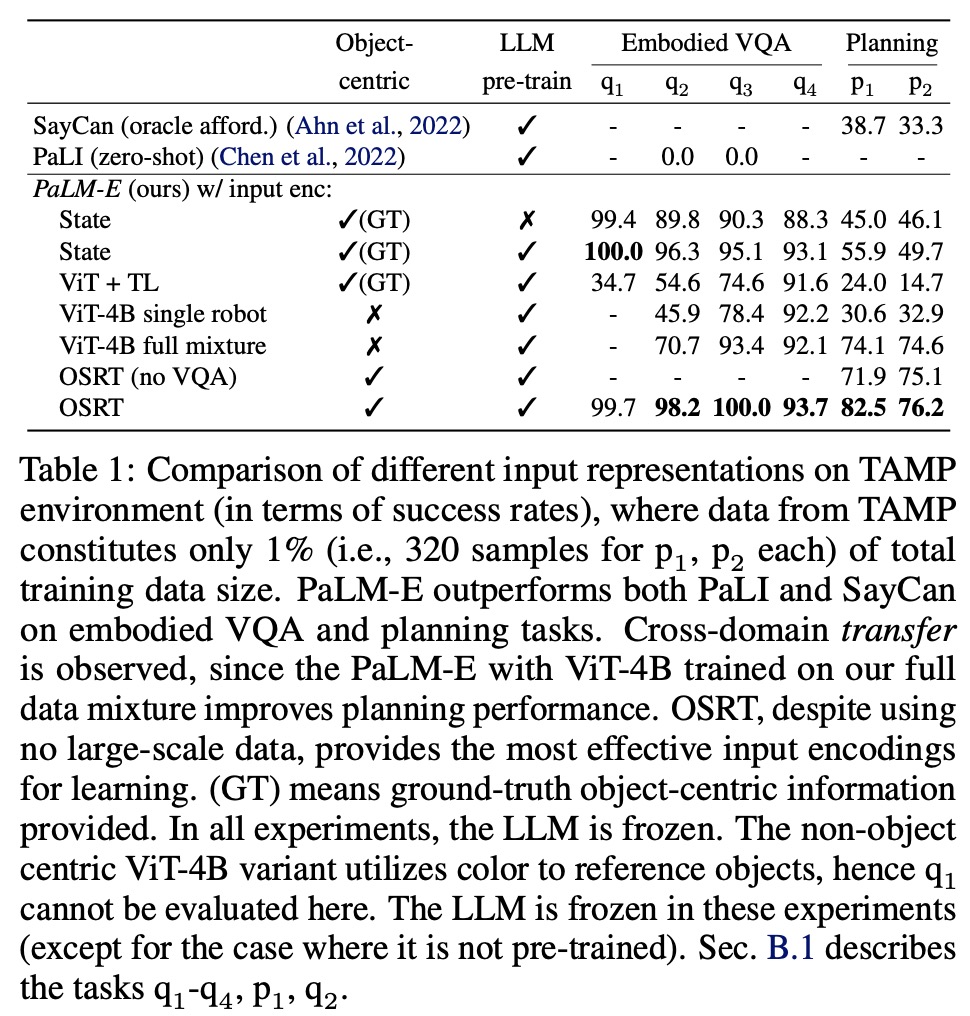
Object-centric representations separate visual input into distinct objects before injecting them into a language model. This is necessary because visual input is not pre-structured into meaningful entities and relationships. The Vision Transformer (ViT) architecture captures semantics but produces a static grid-like representation. To address this challenge, structured encoders are explored. By using ground-truth object instance masks, the ViT representation can be decomposed into distinct object embeddings. This allows for interaction with physical objects and better compatibility with language models that have been pre-trained on symbols.
Object Scene Representation Transformer (OSRT) discovers objects in an unsupervised way through inductive biases in the architecture. OSRT learns 3D-centric neural scene representations through a novel view synthesis task and produces scene representations consisting of object slots. Each slot is projected into multiple embeddings with an MLP.
Entity referrals enable PaLM-E to reference objects in its generated plan for embodied planning tasks. Objects in a scene can be identified in natural language by their unique properties, but there are cases where objects are not easily identifiable by language, such as when multiple objects have the same color. For object-centric representations such as OSRT, multi-modal tokens corresponding to an object in the input prompt are labeled with special tokens like this Object 1 is <obj 1>. This allows PaLM-E to reference objects via these tokens in its generated output sentences. It is assumed that low-level policies also operate on these tokens.
Training Recipes
PaLM-E is trained on a dataset consisting of samples with continuous observations, text, and an index. The text contains a prefix part formed from multi-modal sentences and a prediction target that only contains text tokens. The loss function is a cross-entropy loss averaged over the individual non-prefix tokens. Special tokens in the text are replaced by embedding vectors of the encoders at the corresponding locations in the text to form the multi-modal sentences. PaLM-E is based on the pre-trained 8B, 62B, and 540B variants of PaLM as the decoder-only LLM and injects continuous observations through input encoders that are either pre-trained or trained from scratch. PaLM-E combines with a 4B ViT, 22B ViT, or both, and the resulting models are referred to as PaLM-E12B, PaLM-E-84B, and PaLM-E-562B, respectively.
The authors discuss a variation of PaLM-E where the parameters of the LLM are frozen and only the input encoders are trained. This approach aims to leverage the reasoning capabilities of LLMs when supplied with a suitable prompt. The encoder must produce embedding vectors that ground the frozen LLM on observations and provide information about the embodiment’s capabilities. This approach is a form of input-conditioned soft-prompting and is different from normal soft prompts. In experiments with OSRT, the slot representation is also frozen, and only the small projector, which serves as the interface between OSRT and the LLM, is updated.
Results
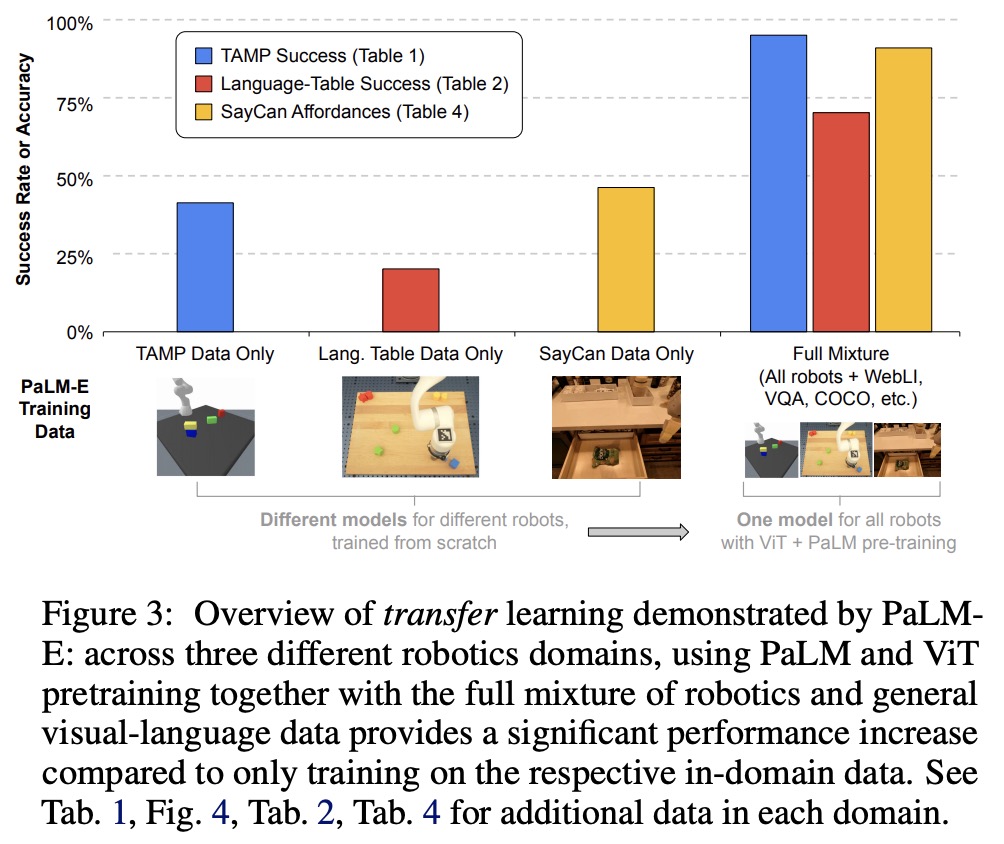
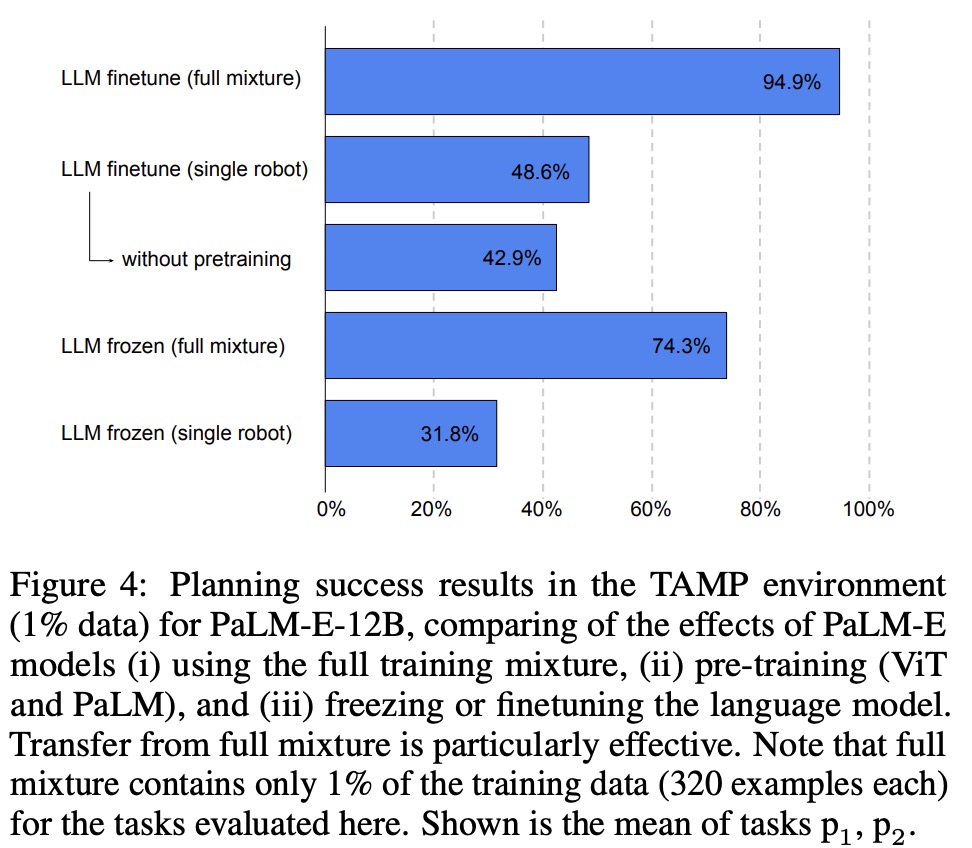

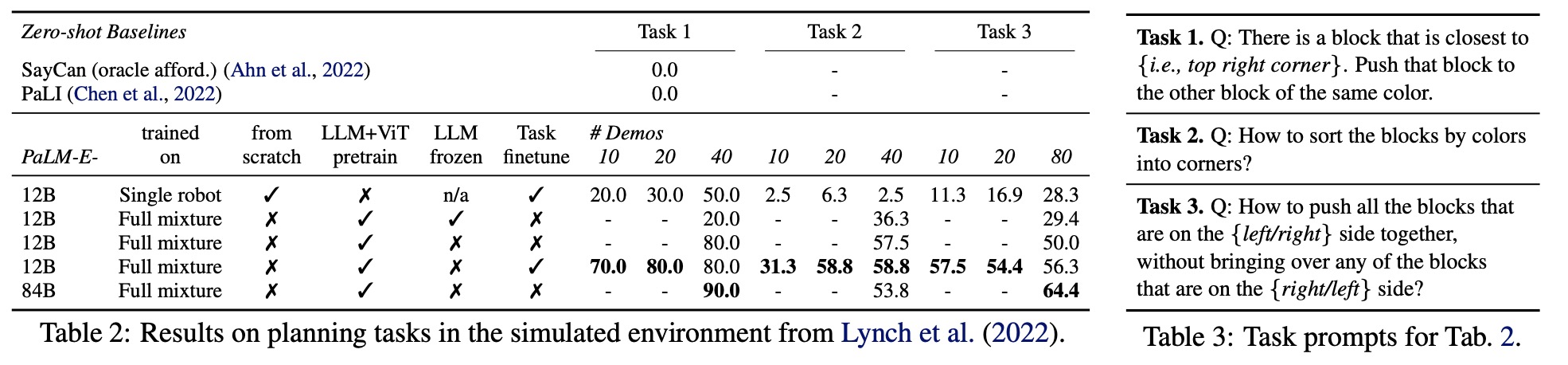
- PaLM-E is able to guide a real robot through a multi-stage tabletop manipulation task while remaining robust to adversarial disturbances. PaLM-E outputs language subgoals to the policies, enabling the robot to perform the task without human intervention. PaLM-E demonstrates one-shot and zero-shot learning by fine-tuning on 100 different long-horizon tasks with a single training example each. Additionally, PaLM-E can generalize zero-shot to tasks involving novel object pairs and to tasks involving objects that were unseen in either the original robot dataset or the fine-tuning datasets, such as a toy turtle. These results highlight the versatility and generalizability of PaLM-E for embodied planning tasks;
- PaLM-E can be used for end-to-end embodied planning for mobile manipulation tasks with long-horizon planning. The prompt structure consists of a human instruction, robot step history, and current image observation. PaLM-E is trained to generate the next step of the plan based on the history of taken steps and current image observation, until the model outputs “terminate.” Each step is mapped to a low-level policy in an autoregressive manner. The model is trained using runs and evaluated qualitatively in a real kitchen, where it was found to perform long-horizon mobile manipulation tasks, even under adversarial disturbances. The results demonstrate the potential of PaLM-E for complex real-world applications in robotics.
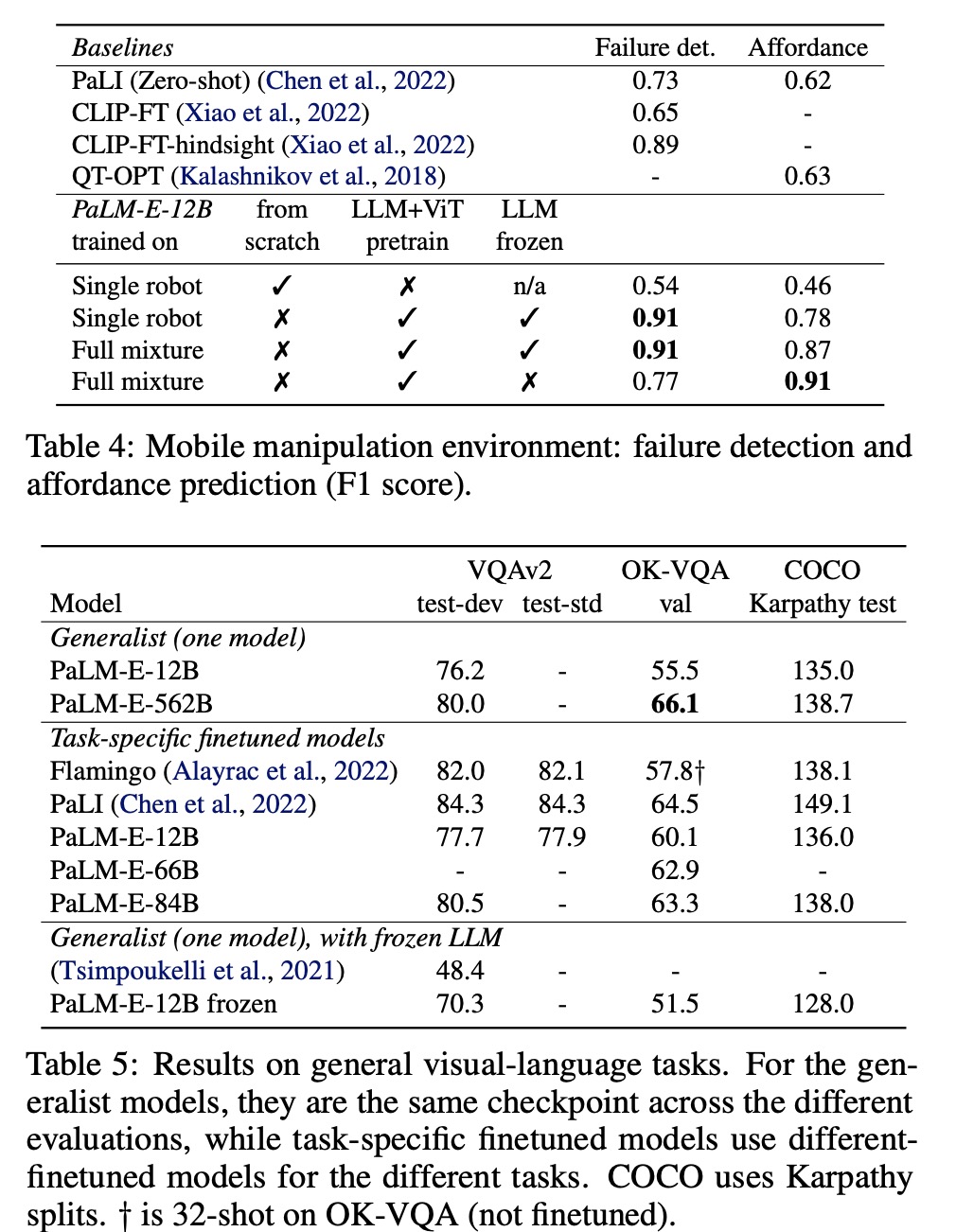
- PaLM-E-562B model achieves the highest reported number on OK-VQA, including outperforming models fine-tuned specifically on OK-VQA. PaLM-E achieves the highest performance on VQAv2;
- PaLM-E trained on different tasks and datasets at the same time leads to significantly increased performance relative to models trained separately on the different tasks alone;