Paper Review: Think before you speak: Training Language Models With Pause Tokens
Language models typically generate responses token by token based on preceding tokens. The proposed approach lets the model process more hidden vectors before producing the next token by introducing a “pause token” added to the input. Outputs are extracted only after the last pause token is processed, allowing the model to process extra computation. When tested on models with 1B and 130M parameters and various tasks, results showed improved performance, especially an 18% EM score increase on SQuAD’s QA task, 8% on CommonSenseQA, and 1% on GSM8k’s reasoning task.
Pause-training
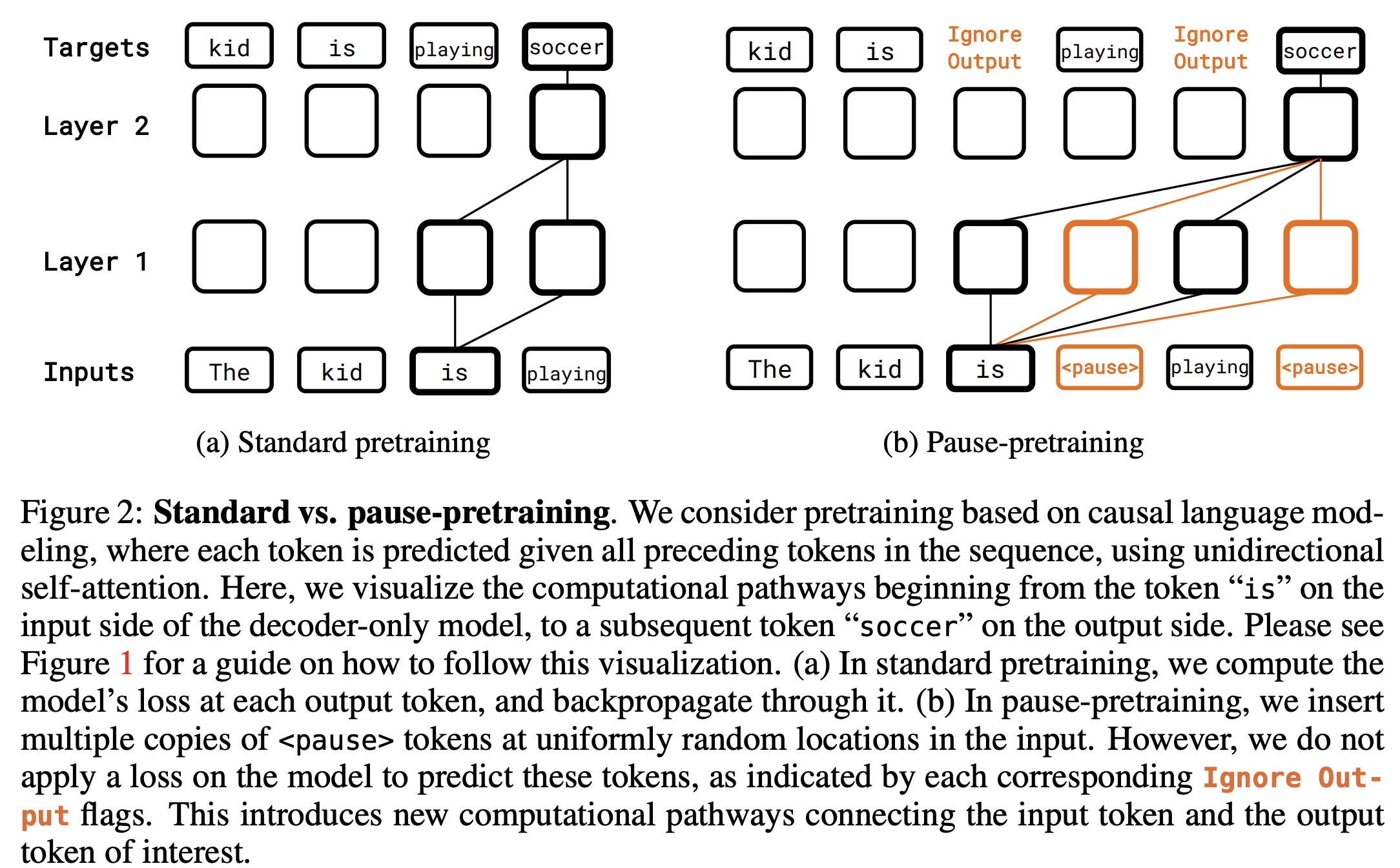
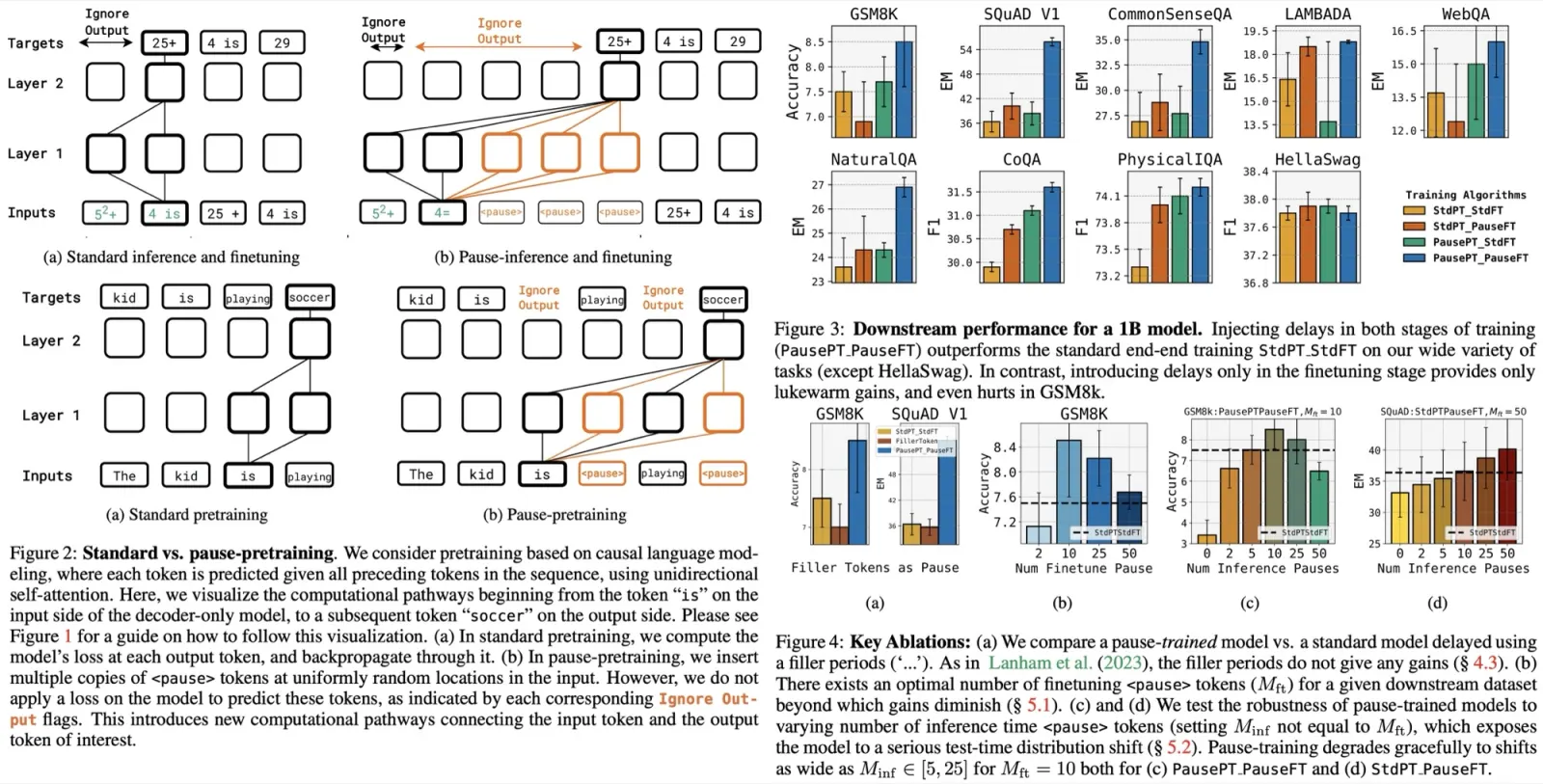
Language models traditionally compute K embeddings in each layer before generating the (K + 1)th token. The proposed approach challenges this by suggesting that the model can benefit from more than K operations before producing the next token. Instead of adding more attention heads, the method introduces M dummy tokens to the input, effectively delaying the model’s response by M tokens. This allows the model to process an additional set of M intermediate vectors before deciding on its next output token, potentially leading to a richer input representation and a more accurate next token prediction.
Learning and inference with the token
- Dummy Tokens: Instead of using common characters like ‘.’ or ‘#’, a unique
<pause>token outside the standard vocabulary is used. Repeating this token creates multi-token delays. - Pretraining with the
<pause>token: During pretraining, multiple<pause>tokens are randomly inserted into the sequence. The model is then trained on this modified sequence using standard next-token prediction loss, but any loss associated with predicting the<pause>tokens themselves is ignored. This method is termed pause-pretraining. - Finetuning with the
<pause>token: For downstream tasks, after being given a prefix with a target, multiple copies of the<pause>token are appended to the prefix. The model’s outputs are ignored until the last<pause>token is seen. The standard next-token prediction loss is applied to the target with the new prefix. This method is termed pause-finetuning. - Pausing during inference: During inference, several
<pause>tokens are added to the prefix. The model’s output is disregarded until the last<pause>token is processed, termed pause-inference.
Variants of Pause-Training
The authors explore four techniques to understand the impact of pause tokens during different training stages:
- StdPT StdFT (Standard Pretraining and Standard Finetuning): Regular pretraining and finetuning without pause tokens.
- StdPT PauseFT: Regular pretraining but introduces pause tokens during finetuning. This could offer a way to improve off-the-shelf models using pause-training.
- PausePT StdFT: Pause tokens are used during pretraining but not in finetuning. This is mainly for analytical insights.
- PausePT PauseFT: Pause tokens are incorporated in both pretraining and finetuning stages.
Experiments
The authors use decoder-only models of 1B and 130M sizes, with ablation studies focused on the 1B model. Both standard and pause models are pretrained on the C4 English mixture for 200B tokens. During pause-pretraining, the <pause> token is inserted randomly at 10% of the sequence length, and the sequence is then trimmed to its original length.
Results:
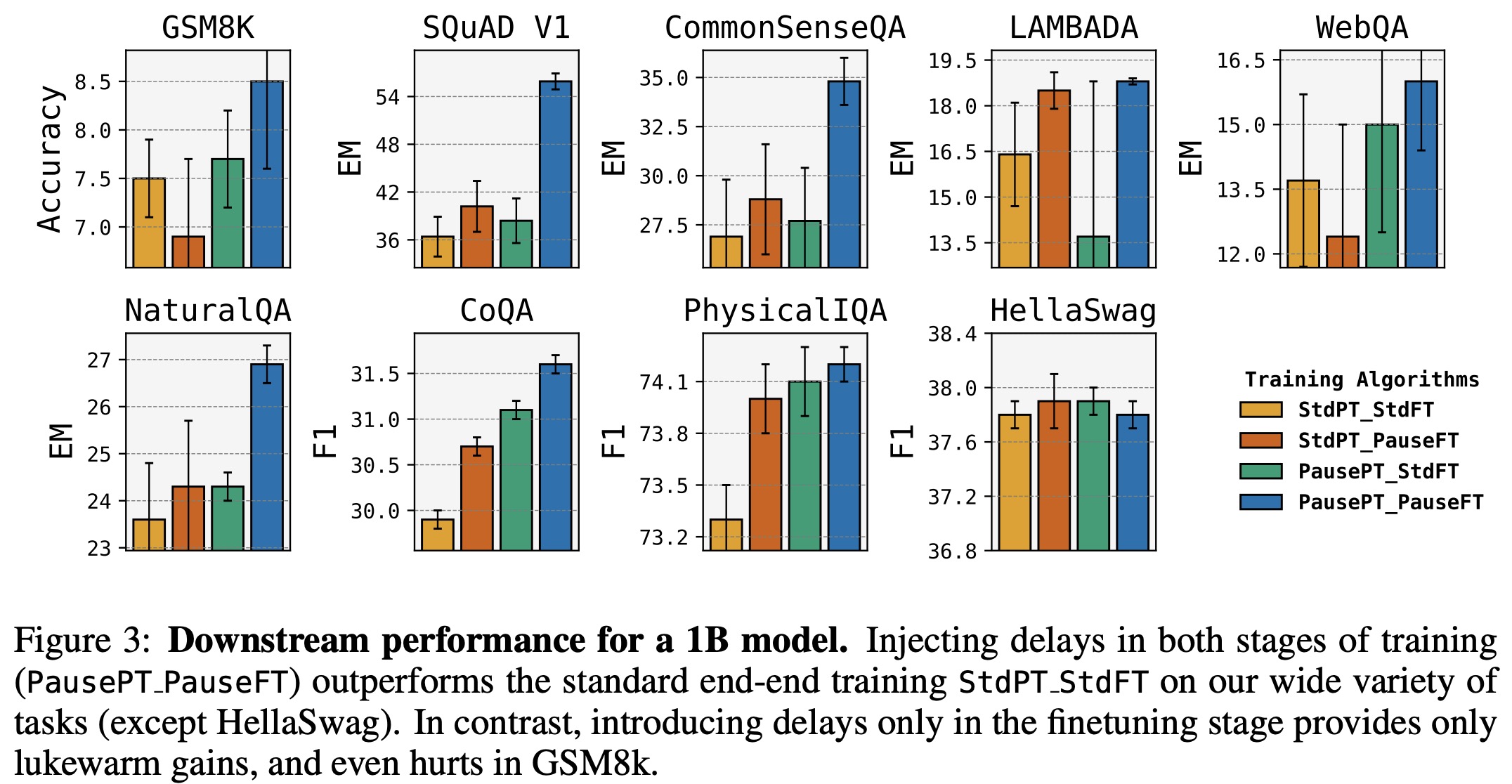
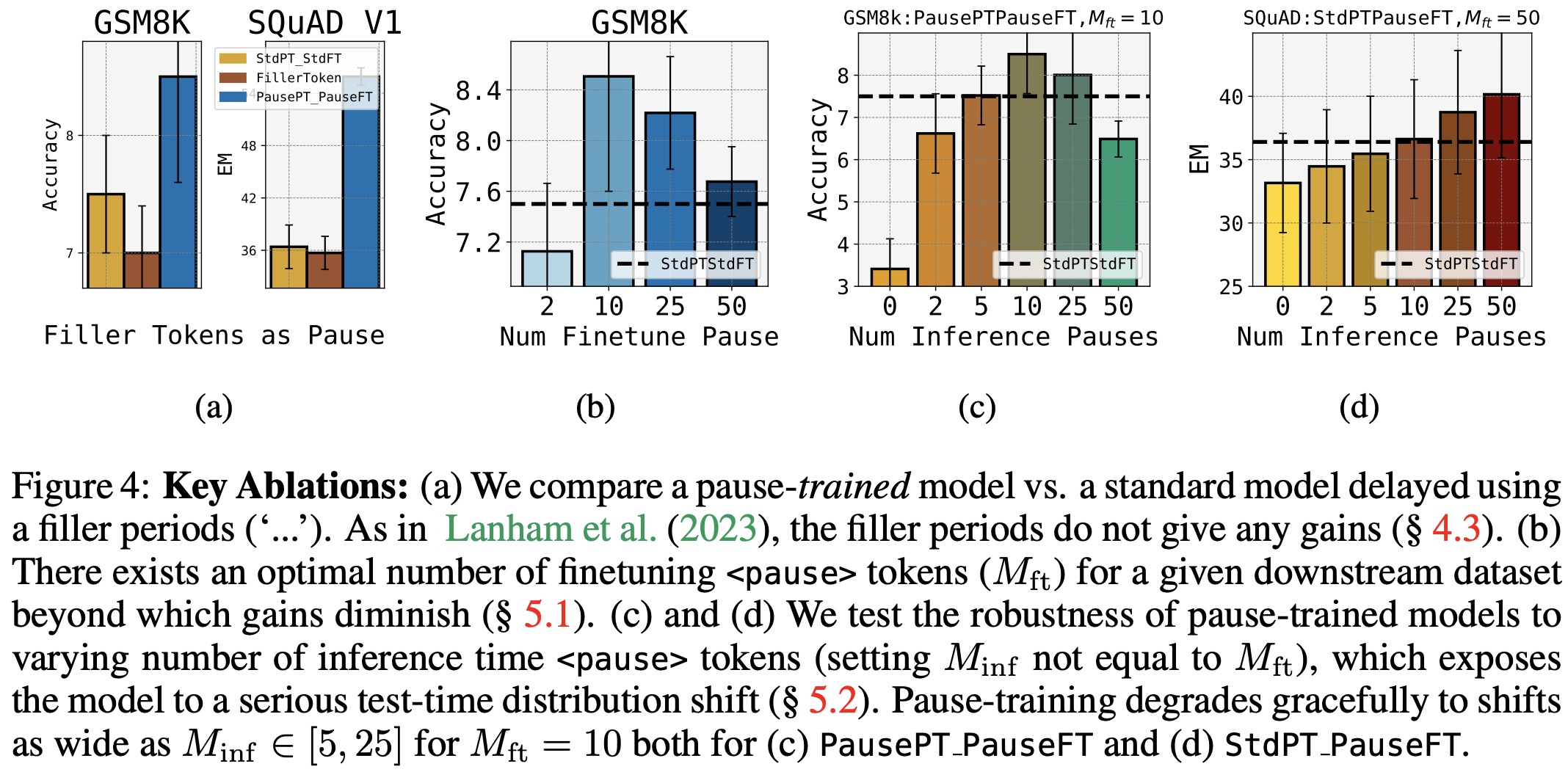
- PausePT PauseFT shows significant gains across most tasks. The 1B model outperforms the standard baseline on eight tasks, with notable improvements like an 18% EM score increase on the SQuAD task and 8% gains on CommonSenseQA.
- StdPT PauseFT yields mixed results. Some benchmarks show gains, but they are generally smaller, and in some cases, performance is equivalent to or worse than standard training.
- PausePT StdFT shows improvements in only two tasks, suggesting that the main benefits of PausePT PauseFT come from delays during inference.
Ablations:
- Optimal number of
<pause>tokens during finetuning depends on the dataset. The optimal number might be influenced by the self-attention mechanism’s capacity. - Robustness to varying inference-time pauses: The PausePT PauseFT model remains robust across a range of test-time shifts in the number of
<pause>tokens, maintaining performance even when the inference tokens are half of those during training. - Appending vs. Prepending Pauses: While the main experiments appended
<pause>tokens (as it’s more natural in settings like long-text-generation), the authors also explored prepending them, especially in tasks using bidirectional attention. Prepending the<pause>token still outperforms standard training in the PausePT PauseFT setup, but appending remains the optimal choice. This suggests that pause-pretraining creates biases based on the positional embeddings of the delays.
Discussion and key open questions
- Enhanced Computational Width: The introduction of delays might increase the computational width. In standard inference, the computational depth is L (layers) and the width is K (parallel computations per layer). With M
<pause>tokens, the width becomes K + M. This might help in tasks like comprehension-based question-answering by allowing a more refined distribution of attention across the context. - Pause-Inference vs. Chain-of-Thought: While both methods increase computational width, CoT also significantly increases computational depth (m * L).
- Capacity Expansion without Parameter Expansion: While there are straightforward ways to extend computation (like adding more attention heads or layers), they increase parameter count. Pause-training doesn’t add significant parameters, making its benefits both practical and theoretically intriguing.
- Computational Expansion with Parameter Expansion: An empirical question arises about how the benefits of computational expansion with
<pause>tokens change as the model’s parameter count changes. Preliminary findings suggest that smaller models might not benefit as much from delays, possibly because they can’t implement diverse computations to utilize new pathways.


