Paper Review: Phoenix: Democratizing ChatGPT across Languages
This paper introduces Phoenix, a large language model that democratizes ChatGPT across various languages. Phoenix performs competitively in both English and Chinese, and excels in languages with limited resources, including Latin and non-Latin languages. The goal is to make ChatGPT more accessible, particularly in countries where usage is restricted by OpenAI or local governments.
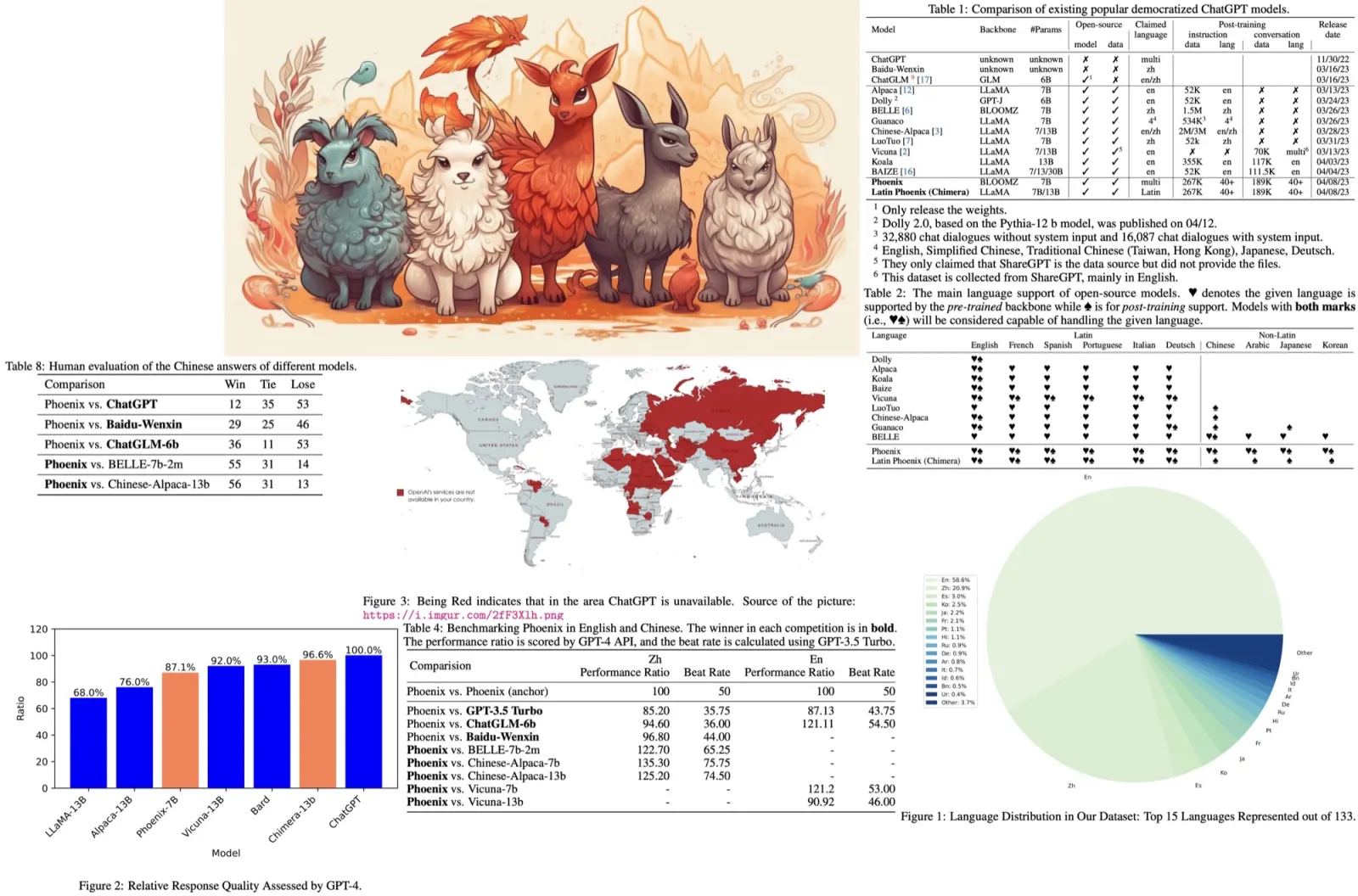
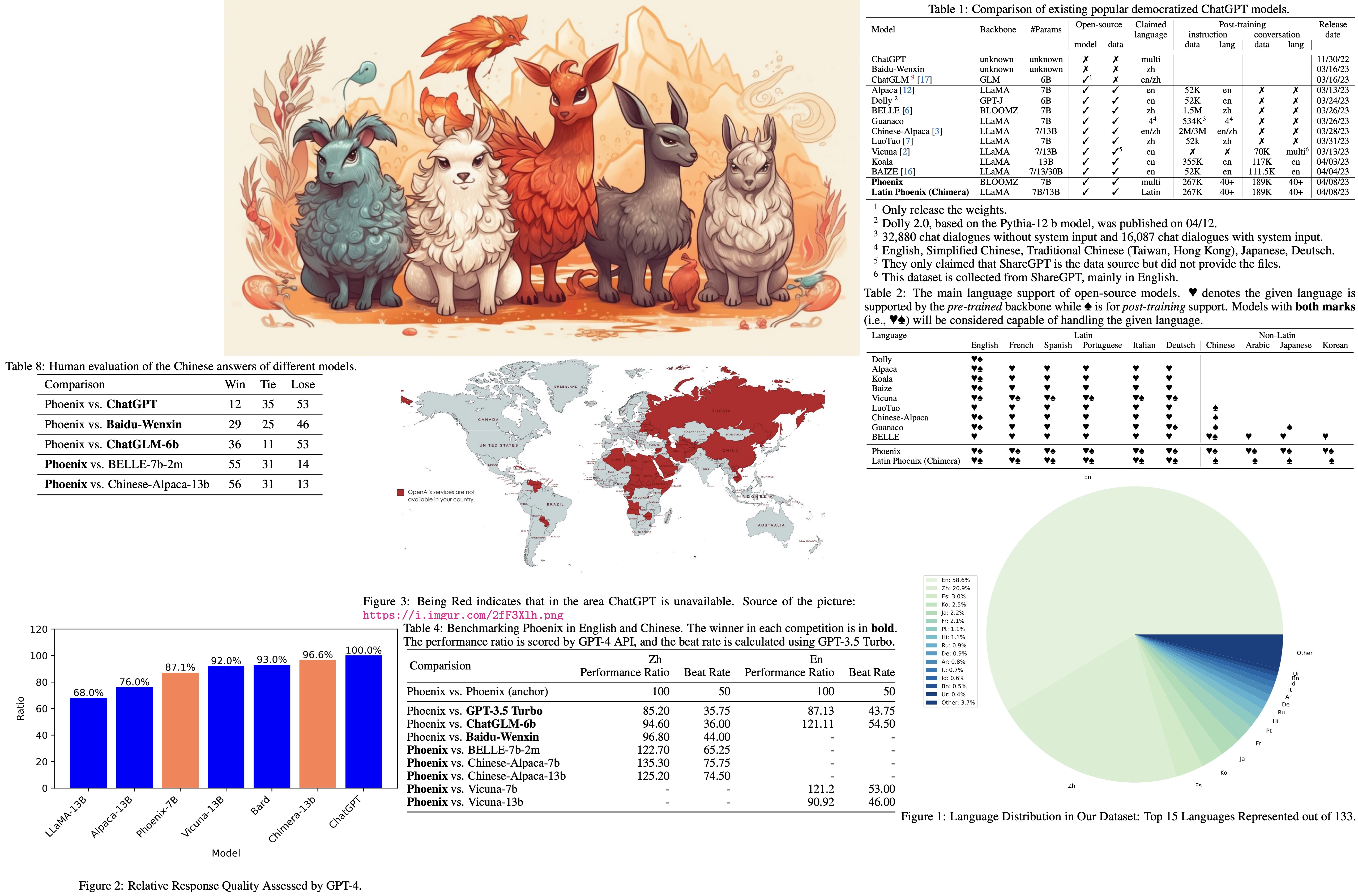
The authors name their model “Phoenix,” drawing inspiration from Chinese culture where the Phoenix is seen as a symbol of the king of birds, indicating its ability to communicate in various languages. They also reference Chimera (Latin language model), a hybrid creature from Greek mythology, symbolizing collaboration between Eastern and Western cultures. The naming aims to emphasize the goal of democratizing ChatGPT across multiple languages and cultural contexts.
Overview of existing Democratized ChatGPTs
The tendency to democratize ChatGPT
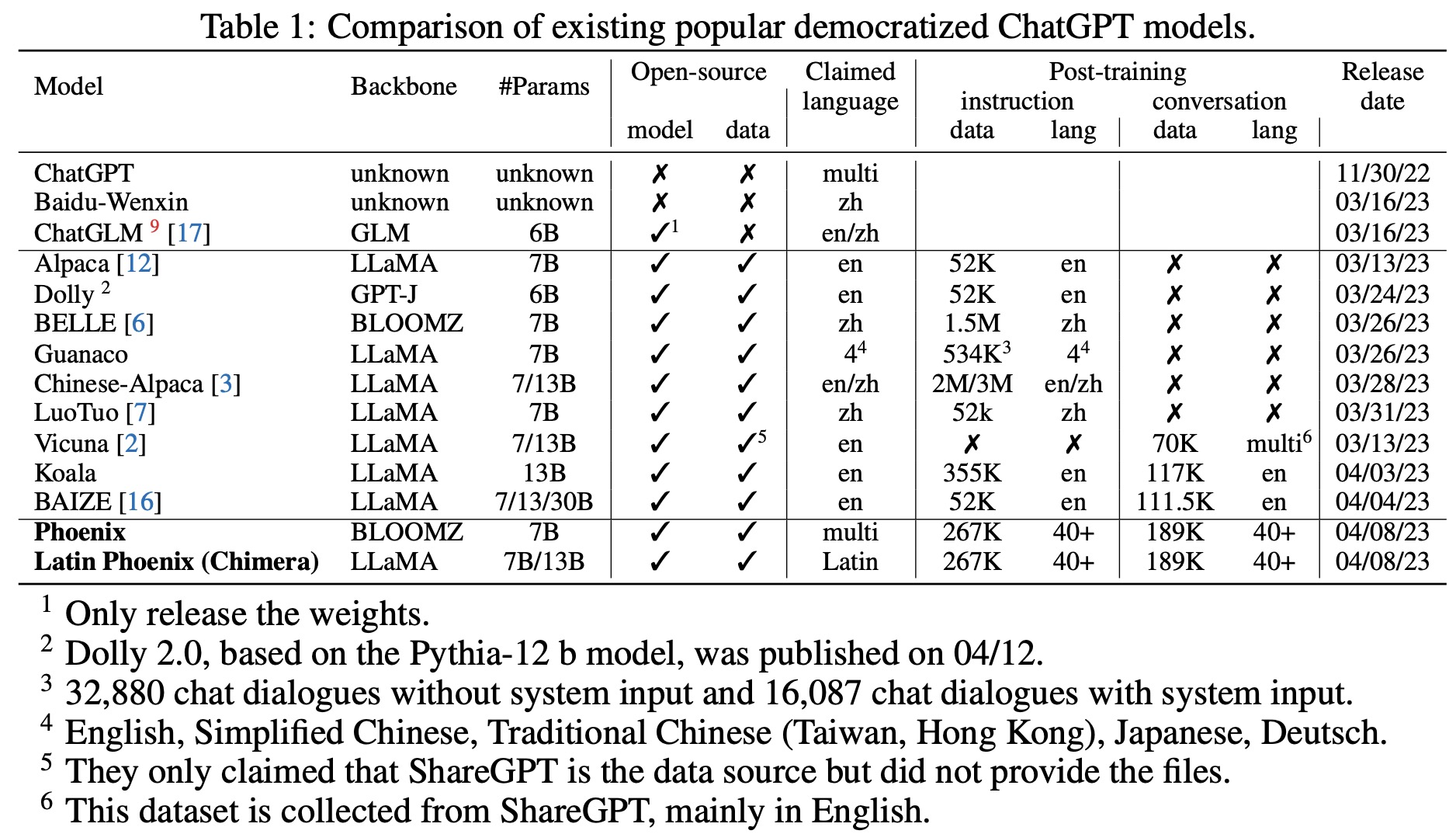
Since ChatGPT’s release, many related models have been developed based on LLaMA and BLOOM. Recent work focuses on computationally cheaper post-training methods, skipping the first pre-training step. Post-training models fall into two categories: instruction-based tuning, exemplified by Alpaca, which uses self-instruction techniques to generate more instructions for fine-tuning, and conversation-based tuning, represented by Vicuna, which utilizes large-scale user-shared dialogue datasets to improve performance.
Instruction-based Tuning. Many variant models have been fine-tuned on Alpaca’s instruction dataset, including Dolly (based on GPT-J), LuoTuo (based on LaMMA), and BELLE (based on Alpaca, on Chinese dataset). These models adapt to different linguistic environments, such as Chinese culture and background knowledge, or support bilingual and multilingual settings. Researchers also experiment with using stronger teacher models to generate instruction data, further expanding the capabilities of these models.
Conversation-based Tuning. Following Vicuna’s success, distilling data from user-shared ChatGPT conversations has become a trend in training models. Since Vicuna did not release their dataset samples, subsequent models created their own datasets. Examples include Koala, which used 30K conversation examples from ShareGPT with non-English languages removed and incorporated the HC3 dataset, and BAIZE, which generated a multi-turn conversation corpus of 111.5K samples by having ChatGPT converse with itself as the training dataset.
Multilingual Capabilities of Democratized ChatGPT Models

Most large language models focus on Latin languages, especially English, which limits their global applicability. Models based on the LLaMA backbone are generally restricted to Latin and Cyrillic languages, with non-Latin languages added in post-training stages. Chinese-alpaca augments LLaMA vocabulary with Chinese tokens to address this issue. BELLE, based on the Bloom backbone, is more versatile but specifically fine-tuned for Chinese. Phoenix, also based on Bloom, supports multiple languages in both pre-training and post-training stages. Chimera, the Latin version of Phoenix, underperforms due to the lack of non-Latin corpora in the backbone pre-training.
Methodology
Instruction Data
The authors use three groups of instruction data:
- Collected multi-lingual Instructions from Alpaca, including English and Chinese answers generated by GPT-4. Each sample contains instruction (task description), input (optional context) and output (answer generated by GPT-4);
- Post-translated multi-lingual instructions, adding other languages like French, Spanish, Portuguese, and Italian through translation. They utilize two methods, one with complete translation of instructions and outputs, and another translating only the instructions while using GPT-3.5 for output generation;
- Self-generated User-centered multi-lingual instructions, driven by a given role set, translated into 40 languages based on speaker population.
Conversation Data
The authors use ChatGPT-distilled conversation data, translated into 40 languages based on speaker population, to adapt their language model for chatting. Data sources include ShareGPT, a Chrome extension for sharing ChatGPT conversations, and the ChatGPT channel on Discord. Unlike Koala, they do not exclude non-English conversation data.
Dataset Statistics
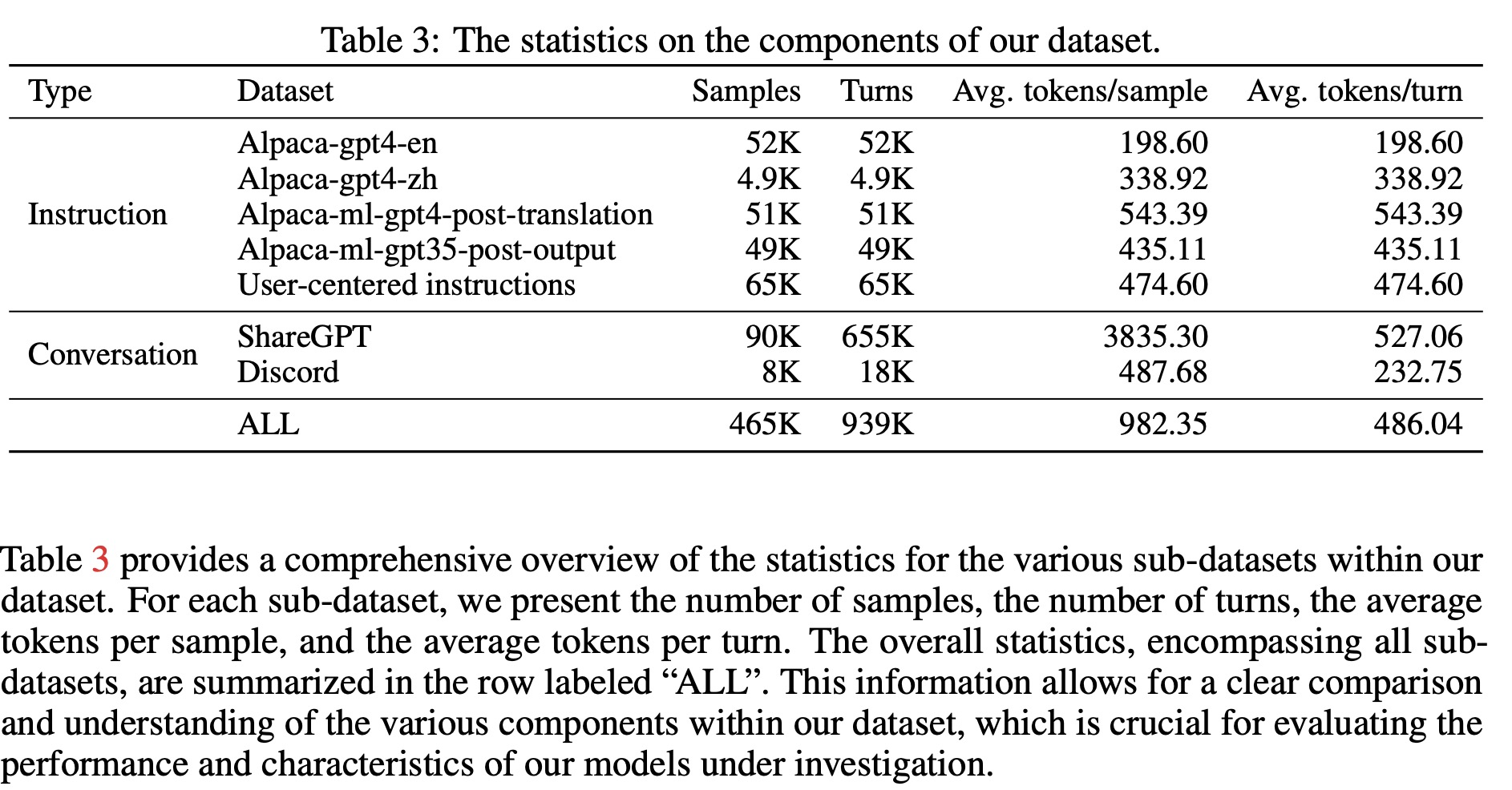
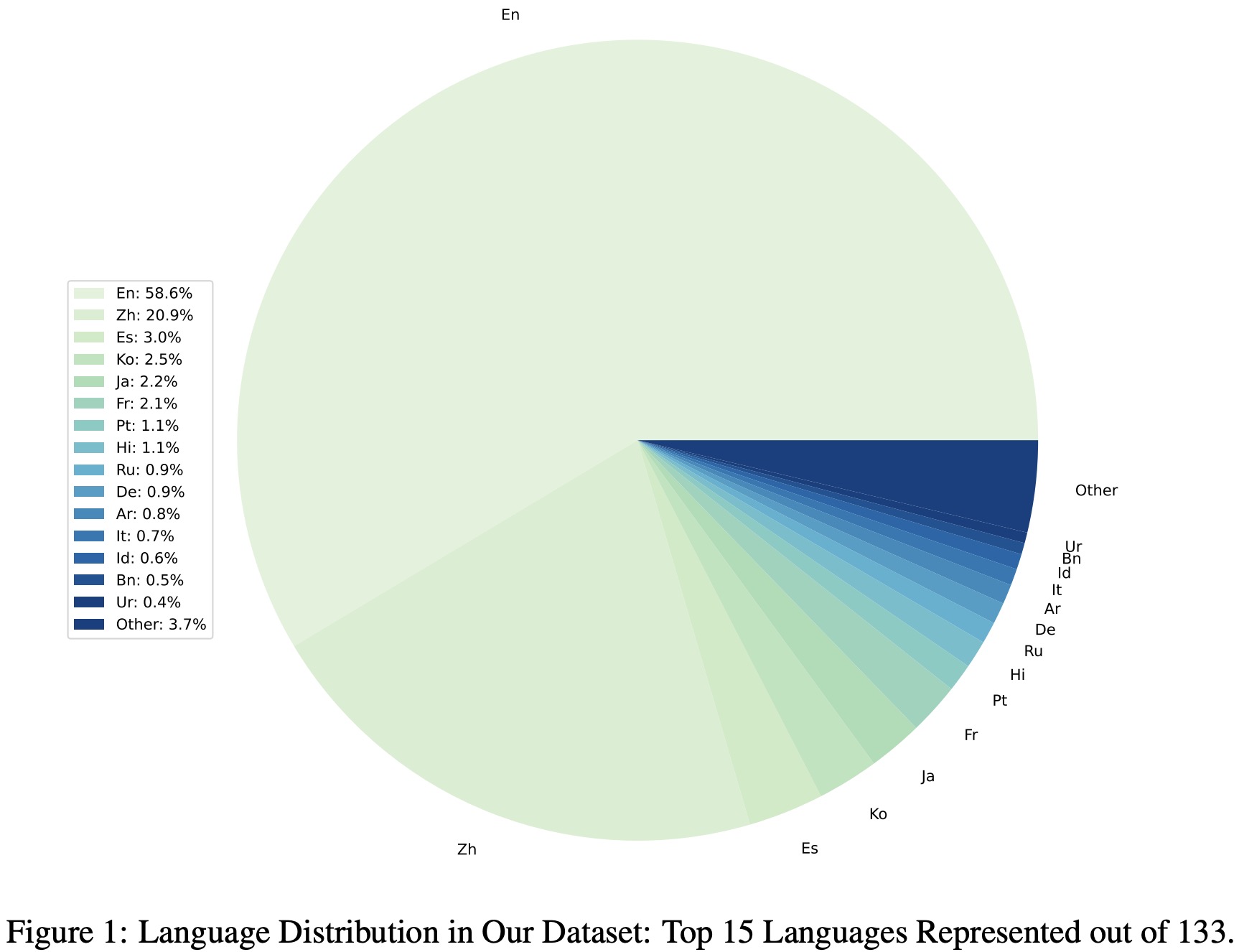
The models are implemented in PyTorch using the Huggingface Transformers package, with a max context length of 2,048. They are trained using the AdamW optimizer with a batch size of 256, three epochs, a learning rate of 2e-5, and no weight decay. The model based on the BLOOMZ backbone is called “Phoenix,” while the one based on the LLaMA backbone is called “Chimera.”
Evaluation
Evaluating AI chatbots is challenging due to the need for comprehensive assessment of language coherence, comprehension, reasoning, and contextual awareness. Existing evaluation methods face issues such as not being blind, not being static, and having incomplete testing path coverage. To address these challenges, the authors present an evaluation framework based on GPT-4/GPT-3.5 Turbo API to automate chatbot performance assessment.
Evaluation Protocol
Baselines. To validate Phoenix’s performance, it is compared with existing instruction-tuned large language models in Chinese and English, such as GPT-3.5 Turbo, ChatGLM-6b, Wenxin, BELLE-7b-2m, Chinese-Alpaca 7b/13b, and Vicuna-7b/13b. The evaluation also includes comparisons in more Latin and non-Latin languages, such as French, Spanish, Portuguese, Arabic, Japanese, and Korean, to demonstrate its multi-lingual ability. The main comparison models are GPT-3.5 Turbo and the multi-lingual instruction-tuned model, Guanaco.
Metrics.

The evaluation of Phoenix follows Vicuna’s approach, testing it on a set of 100 questions across 10 categories, including two additional categories: reasoning and grammar. A pairwise comparison of the models’ absolute performance is conducted, using GPT-4 to rate potential answers based on their helpfulness, relevance, accuracy, and level of detail on the 80 English questions in Vicuna’s test set. Due to limitations in the OpenAI account quota, GPT-4 API is only used for Chinese and English test sets, while GPT-3.5 Turbo API is used for the other languages. GPT-3.5 Turbo is tasked with determining which of two answers is better and providing the justification for its choice. The performance ratio is calculated by averaging the scores obtained by each model across the 100 questions, and the beat rate is determined by the number of times a model wins divided by the sum of its wins and losses.
Experimental Results
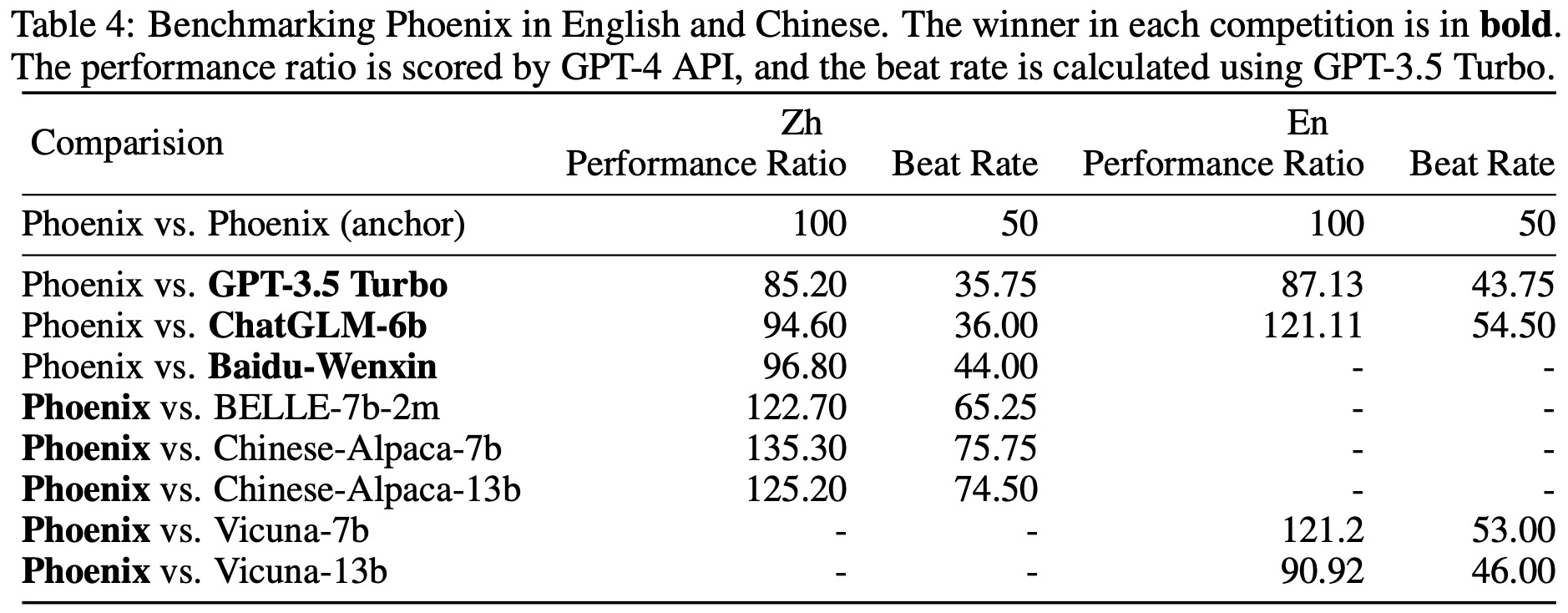

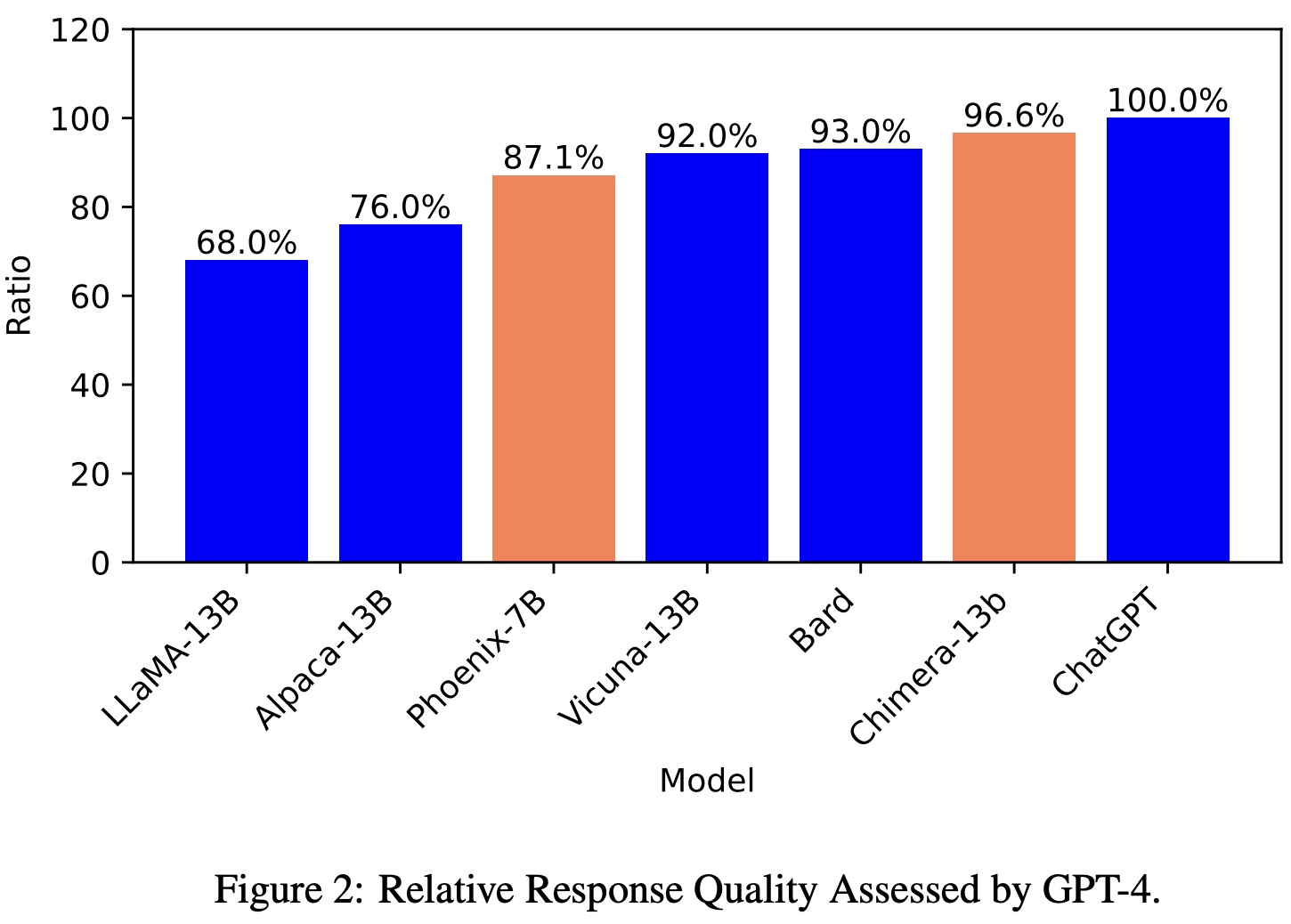

Monolingual tests in English and Chinese are conducted, with GPT-4 assigning a quantitative score from 1 to 10 for each response. The final score for each comparison pair (baseline, Phoenix) is calculated by averaging the scores obtained by each model across the 100 questions in the English and Chinese subsets.
The Phoenix model is compared to other Chinese and English models, as well as models in other languages. In Chinese, Phoenix slightly underperforms Baidu-Wenxin and ChatGLM-6b but significantly surpasses other open-source Chinese models. Despite being a multi-lingual LLM, it achieves state-of-the-art performance among open-source Chinese LLMs. In English, Phoenix outperforms Vicuna-7b and ChatGLM-6b but lags behind Vicuna-13b and ChatGPT in terms of absolute performance. Chimera, a tax-free Phoenix, sets a new state-of-the-art in open-source LLMs. In other languages, Phoenix has an advantage over the Guanaco model, with Chimera performing even better in Latin languages, comparable to GPT-3.5 Turbo and slightly better in French and Spanish.
Ablation study

Human Evaluation
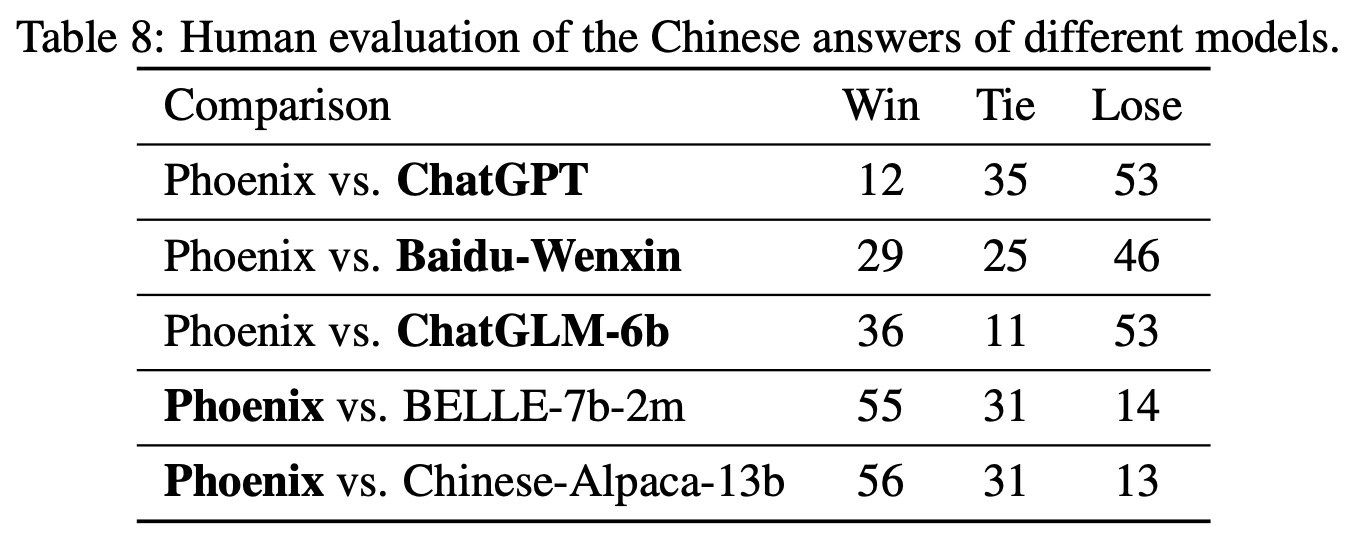
The researchers used human evaluation to assess the performance of the Phoenix model more comprehensively. Volunteers were asked to rank the results generated by two models for the same question, without knowing which model produced each answer. Phoenix performed significantly better than open-source Chinese language models (BELLE-7b-2m and Chinese-Alpaca-13b) and demonstrated competitive performance with non-open source models (such as ChatGPT and Baidu-Wenxin).
paperreview deeplearning nlp