Paper Review: Pixel Aligned Language Models

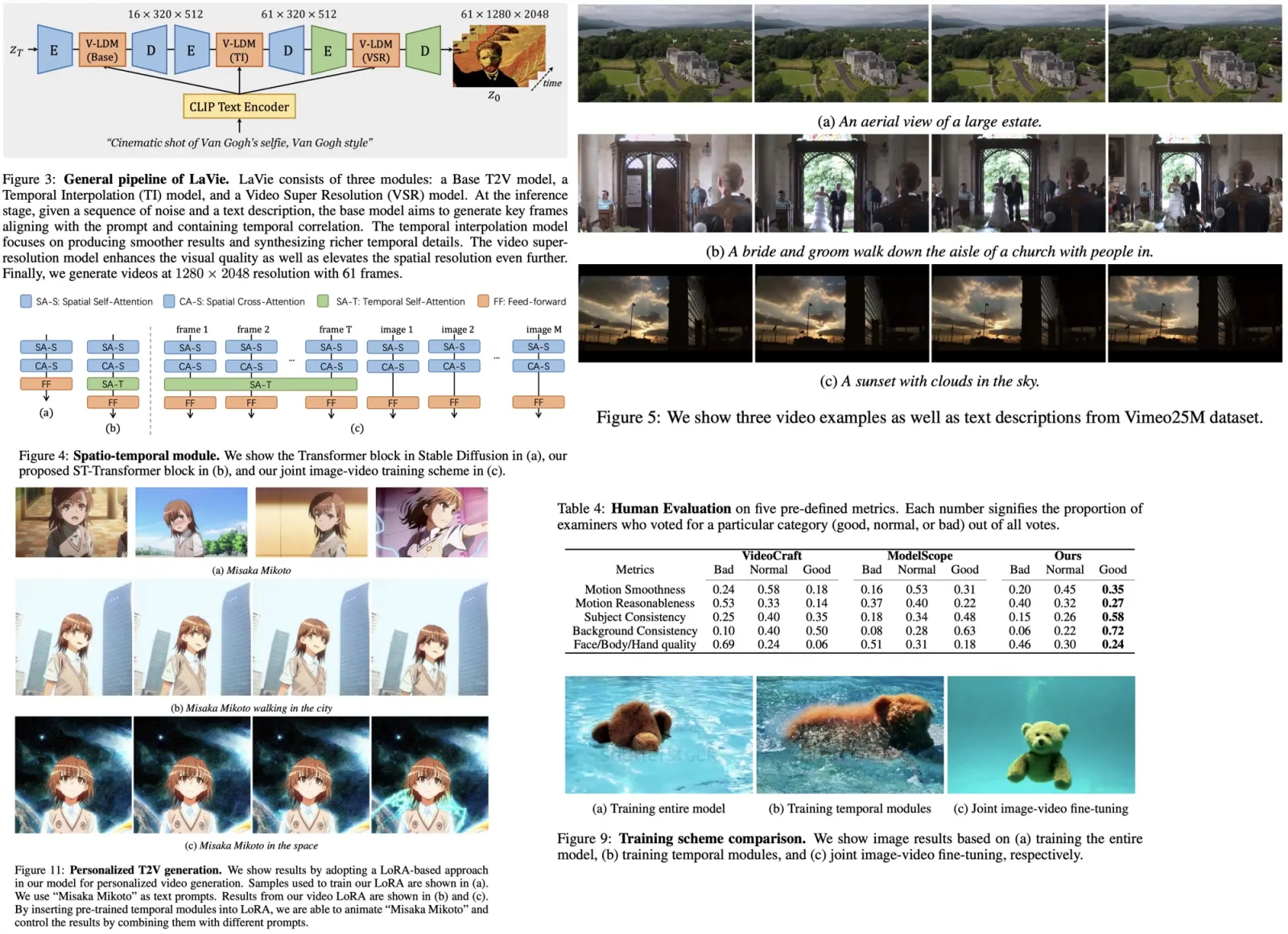
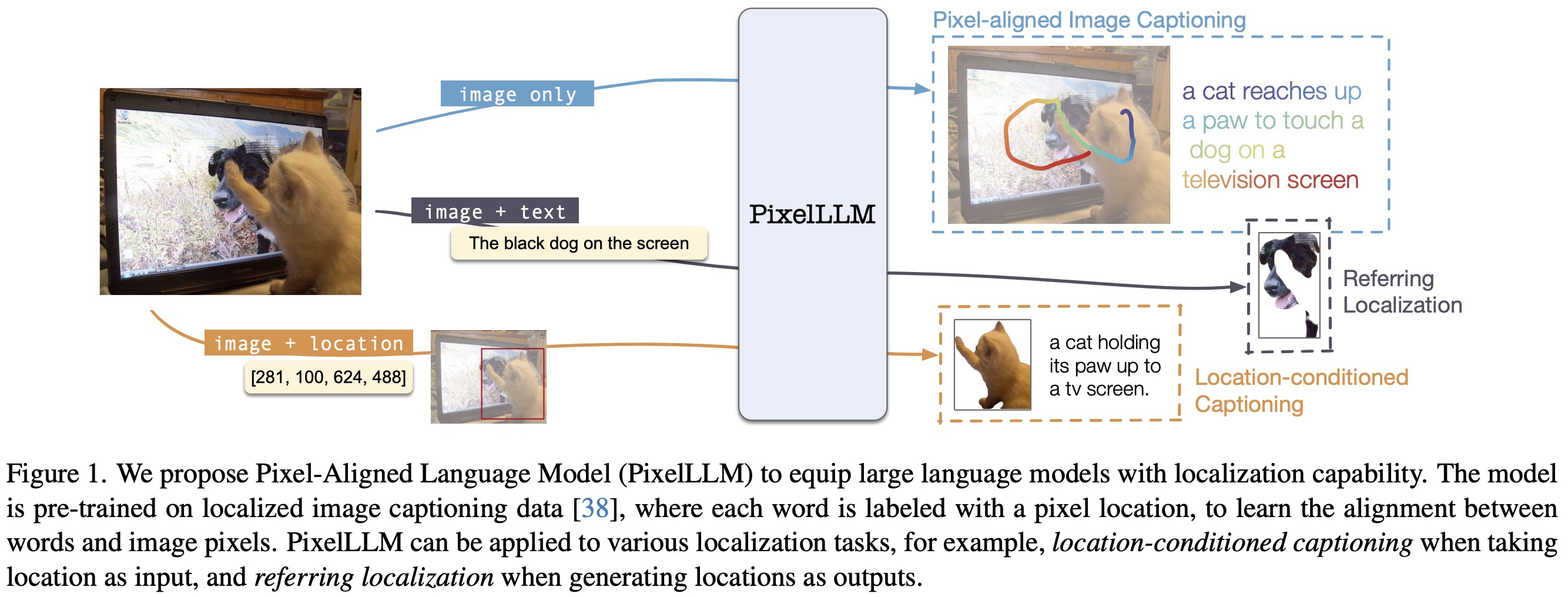
While existing large language models can describe images in natural languages, answer visual-related questions, or perform complex reasoning about the image, it is yet unclear how can they perform localization tasks, such as word grounding or referring localization. The authors develop a vision-language model to handle localization tasks, integrating location information with language processing. It can either take locations as inputs for generating specific image region captions or output locations as pixel coordinates for each word it generates, facilitating dense word grounding.
Trained on the Localized Narrative dataset with pixel-word-aligned captions from human attention, the model demonstrates superior performance in location-aware vision-language tasks, achieving top results in benchmarks like RefCOCO and Visual Genome.
Preliminary
The first goal is to generate a caption for an image as a sequence of word tokens where each token represents an integer index from a vocabulary.
Additionally, the authors aim to incorporate optional prompts that specify the region or concepts the model should focus on. These prompts can be locations, represented by points or a box or text sequences.
Pixel-Aligned Language Model
Localization in computer vision has been explored in various contexts, including object detection, referring localization, and entity grounding. The proposed approach focuses on aligning each word in an output sentence with a pixel location in an image. Alongside generating a sentence, the model outputs a corresponding sequence of points, each linked to a word in the sentence. Unlike previous models that ground only nouns to regions, this method includes non-visual tokens, enabling the learning of relational terms and offering a more comprehensive image context understanding.
Architecture
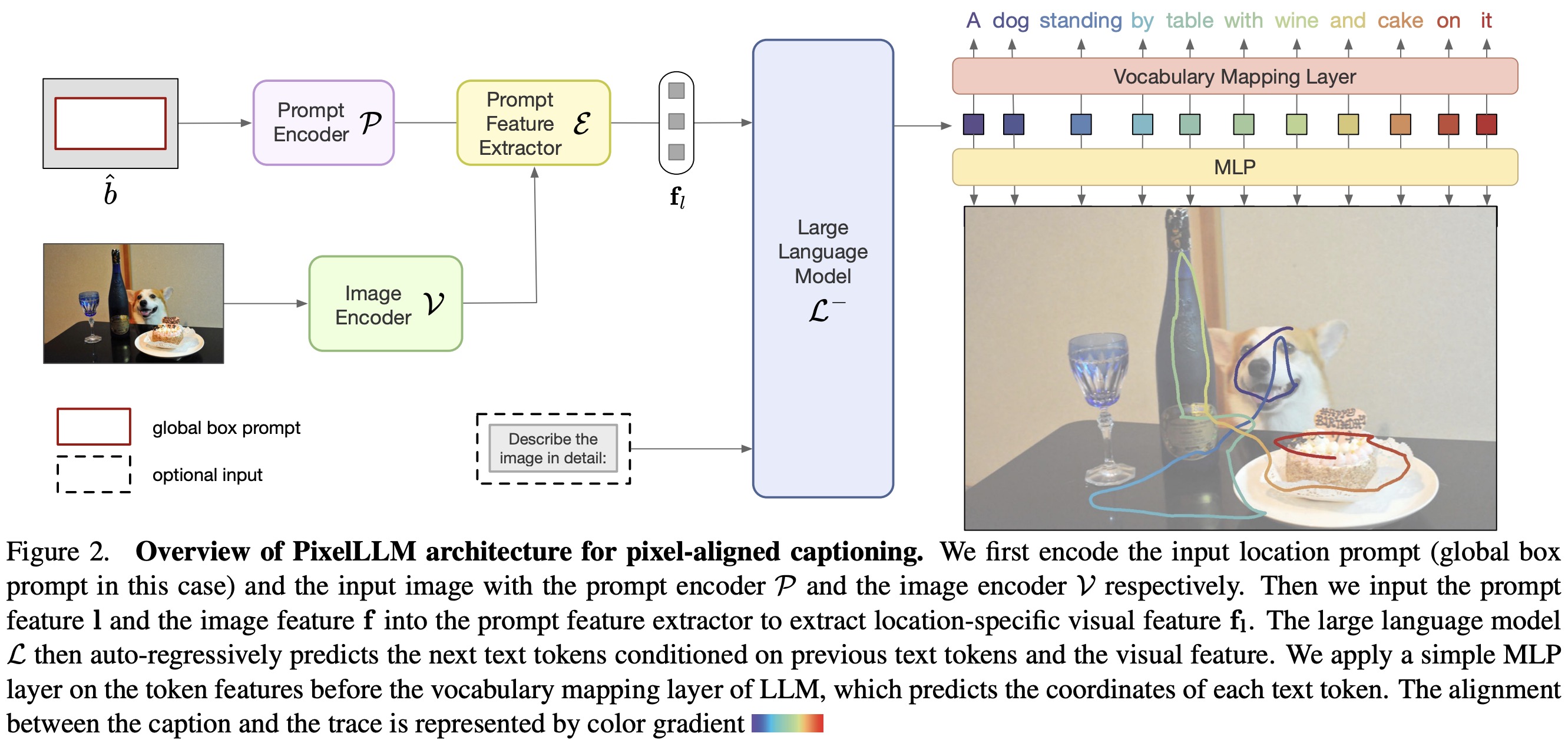
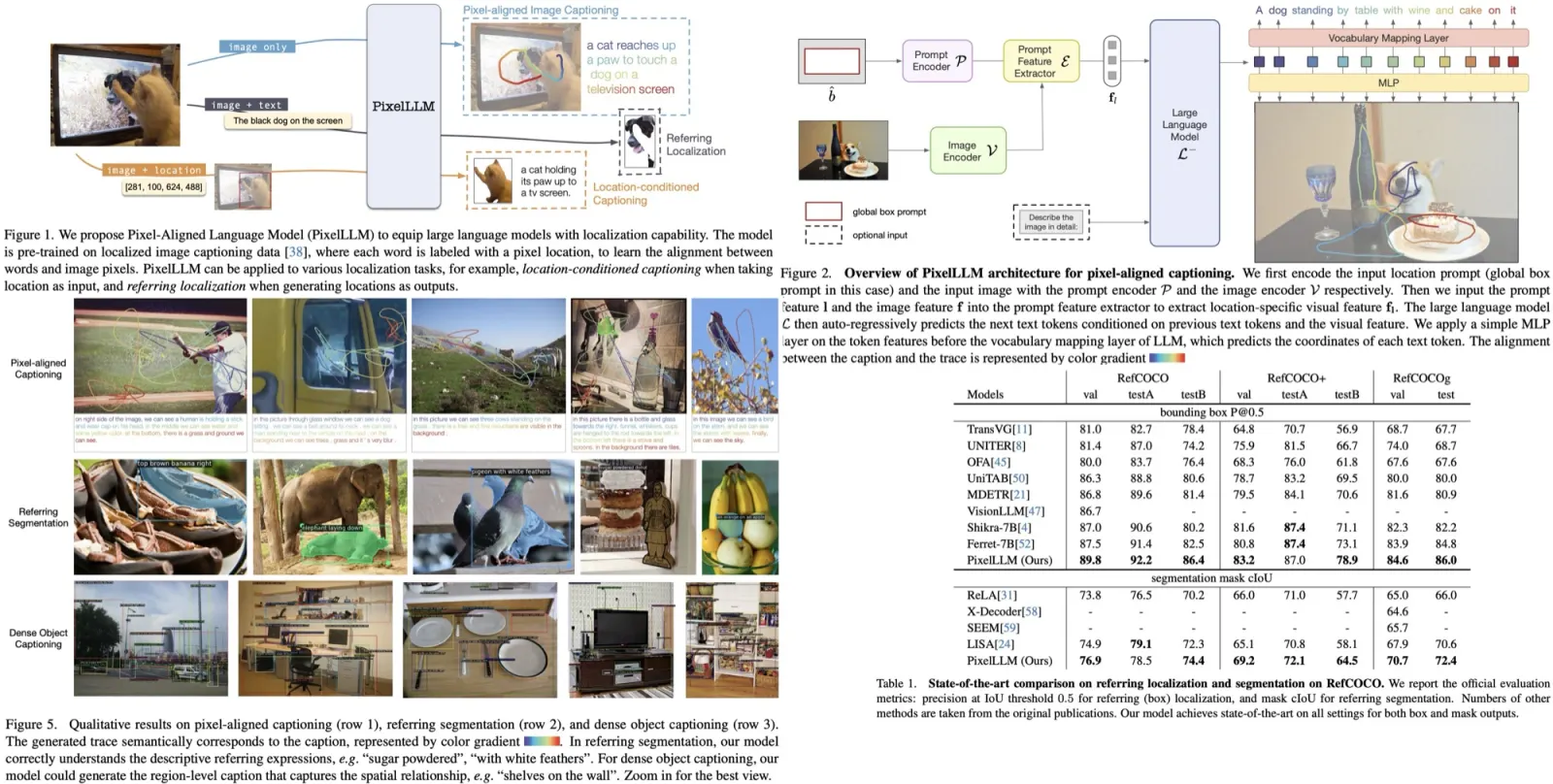
The approach involves processing an image with an optional location prompt. If no prompt is provided, a global box prompt encompassing the entire image is used. The output includes a sentence and a corresponding point trajectory. The image feature is obtained using an image encoder, and the location prompt feature is derived using a prompt encoder. A prompt feature extractor is used to extract location-specific visual features from the overall image feature, based on the location prompt.
The extractor is based on a two-way transformer with learnable tokens, functioning similarly to ROIAlign but without requiring feature interpolation and sampling. This results in a feature specific to the location prompt.
For dense location outputs, the location-specific feature is fed to a language model for captioning. The decoding process involves mapping the language feature space to vocabulary indices, with an additional MLP layer for converting language features to 2D location outputs. This allows for simultaneous location prediction and language decoding without significantly increasing computational load.
The design is adaptable to any language model and can incorporate text prompts by concatenating text prompt word embeddings with the visual feature.
Training
The model is trained using the Localized Narrative dataset, which features human-annotated, caption-location aligned data. In this dataset, annotators describe an image while moving their mouse over the relevant region, synchronizing the narration with the mouse trace. This method provides a location for each word in the narration, although the mouse trace might be somewhat noisy. For training, the model uses standard label-smoothed cross-entropy loss for the captioning output and an L1 regression loss for the localization output.
Adapting to downstream vision tasks
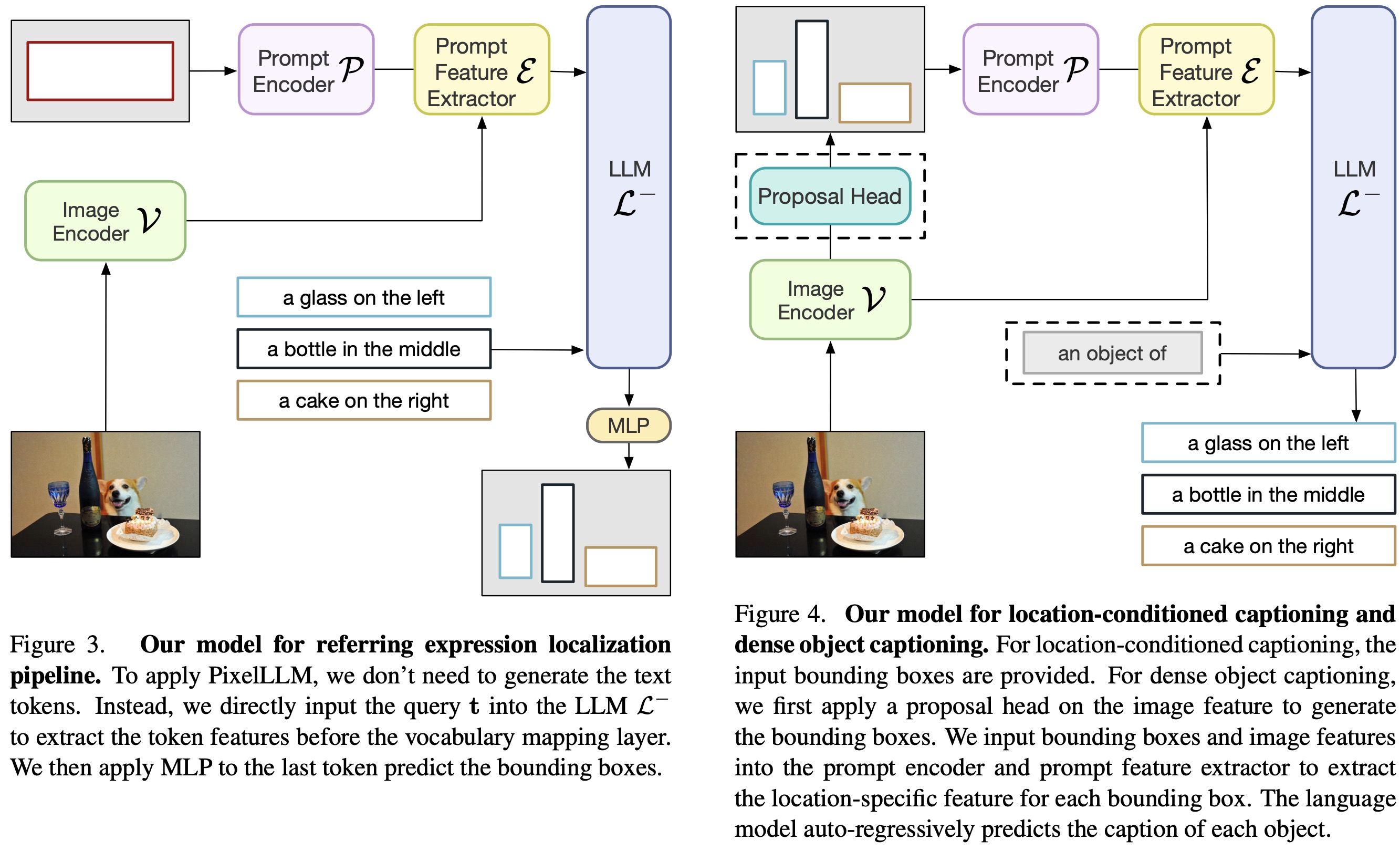
Referring Localization and Segmentation involves taking an image and a sentence query, with the aim of producing a bounding box that corresponds to the query. The model is trained to output an accurate object bounding box at the end-of-sentence token, using regression MLP layers. Additionally, by integrating a mask decoder, the model can also generate a segmentation mask, providing both the bounding box and mask for the queried object.
Location-Conditioned Captioning involves generating a caption for a specific object in an image, identified by a bounding box. The model uses the prompt encoder and autoregressive language model to produce a caption specific to the indicated object while ignoring the per-word location output.
Dense Object Captioning involves detecting all objects in an image and then captioning them. The model adds a proposal head to the image encoder for object detection, using bounding box candidates. It then performs location-conditioned captioning for each detected object. The model is fine-tuned with both detection and caption losses to optimize performance.
Experiments
Implementation details
The architecture uses two parallel visual encoder backbones: ViT-H initialized with SAM and ViT-L initialized with EVA02. The dual-backbone approach serves two purposes: inheriting strong segmentation ability and localization features from SAM, and learning semantic features with a tunable backbone. The features from both backbones are concatenated for the prompt feature extractor.
The language model used is an instruction-finetuned T5-XL, adapted for vision tasks using LoRA on specific layers, while keeping other parameters frozen. A 2-layer transformer with 32 learnable tokens serves as the prompt feature extractor. This setup follows the PrefixLM paradigm, where prompt extractor outputs and text embeddings are concatenated and fed into the language model.
For segmentation mask generation, the SAM’s mask decoder is used directly on the prompt embedding of the predicted bounding box, with a learnable embedding for finetuning on downstream datasets.
Training involves two stages: pretraining on the WebLI dataset with an image captioning objective to initialize prompt feature extractor weights, and then training on the Localized Narrative dataset with joint captioning and localization objectives. During training, multiple sentences in a caption are treated as separate targets instead of concatenating them.
Results

Joint Captioning and Trace Generation: The model shows strong performance in generating captions and traces that semantically correspond well to each other. Quantitatively, it outperforms MITR in trace generation. Notably, the traces are generated from language model features, not visual features like in MITR.
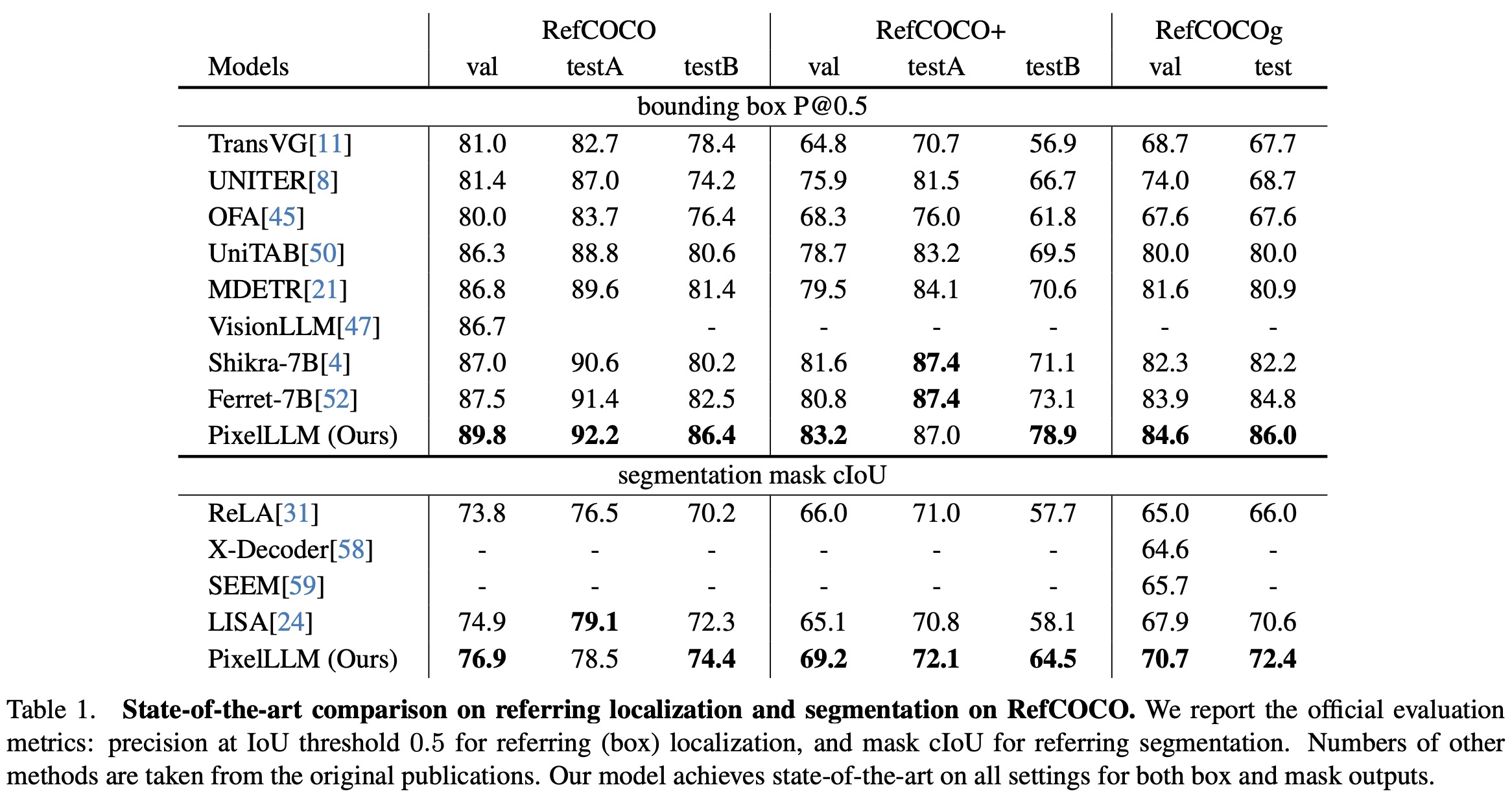
Referring Localization and Segmentation: Fine-tuned on RefCOCO datasets, the model excels in producing bounding boxes and segmentation masks from query texts. It outperforms existing models on most metrics, showcasing its generalization capabilities in tasks it wasn’t specifically designed for.
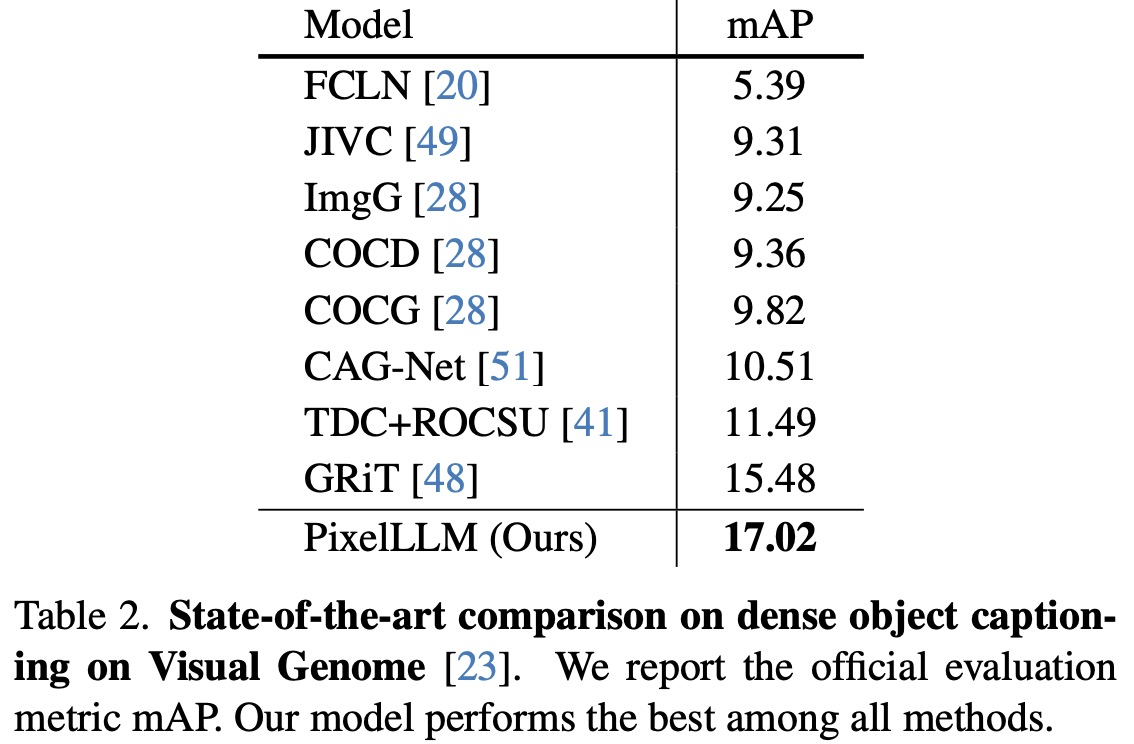
Dense Object Captioning: The model is adapted with a proposal head for detecting and captioning objects in images, evaluated on the Visual Genome dataset. It outperforms the GRiT model in terms of mAP, highlighting the effectiveness of its prompt feature extractor that does not require image feature sampling and interpolation like ROIAlign.
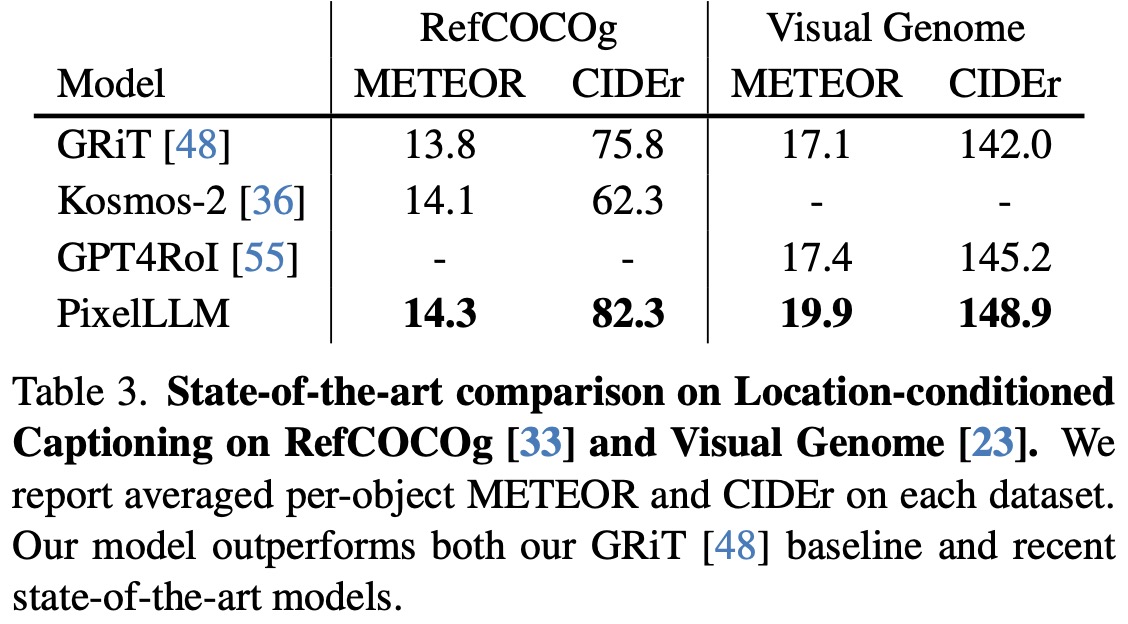
Location Conditioned Captioning: Evaluated on RefCOCOg and Visual Genome datasets, the model uses ground truth bounding boxes to generate captions. It surpasses previous works like Kosmos-2 and GPT4RoI, attributed to its unique approach to encoding bounding box coordinates and the use of localized narrative training.
Ablation studies
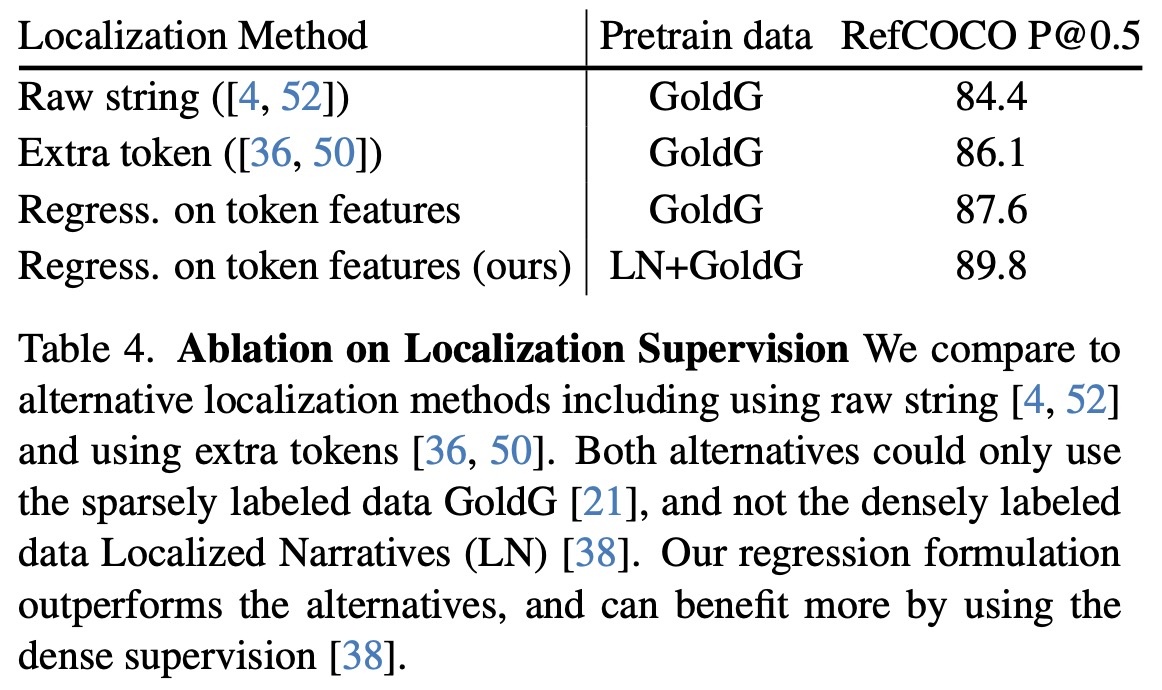
Importance of per-token localization: The model’s per-token regression approach for localization is compared with two alternatives: encoding bounding box coordinates as raw strings and discretizing coordinates into bins. The alternatives are suitable for sparse encoding (i.e., encoding locations for nouns), but impractical for dense encoding as it would significantly lengthen the output sequence. The model’s approach allows for training with both sparse and dense localization data. Results show that the model slightly outperforms alternatives with sparse supervision, likely due to a more efficient localization decoding process. Furthermore, utilizing densely annotated data from Localized Narratives significantly improves performance, demonstrating the value of the dense word-pixel alignment training objective in referring localization tasks.
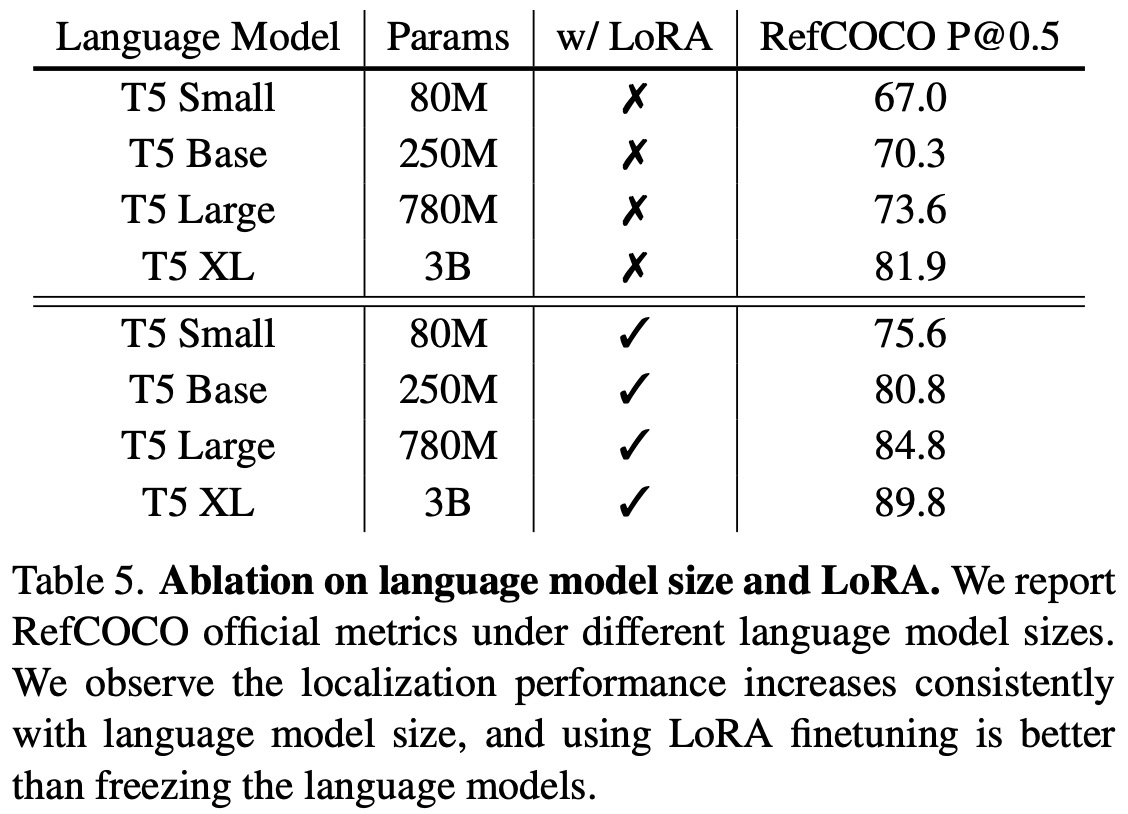
Model size and LoRA fine-tuning: Increasing the size of the language model improves accuracy, as expected due to larger models encapsulating more knowledge. LoRA fine-tuning significantly enhances performance compared to models without it, indicating its effectiveness in adapting a frozen language model to localization tasks. Interestingly, even without LoRA, the frozen T5-XL model performs comparably to models that fine-tune the text encoder jointly, highlighting the inherent strong localization ability of large language models, which is effectively harnessed by the proposed PixelLLM framework.
paperreview deeplearning llm cv