Paper Review: ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
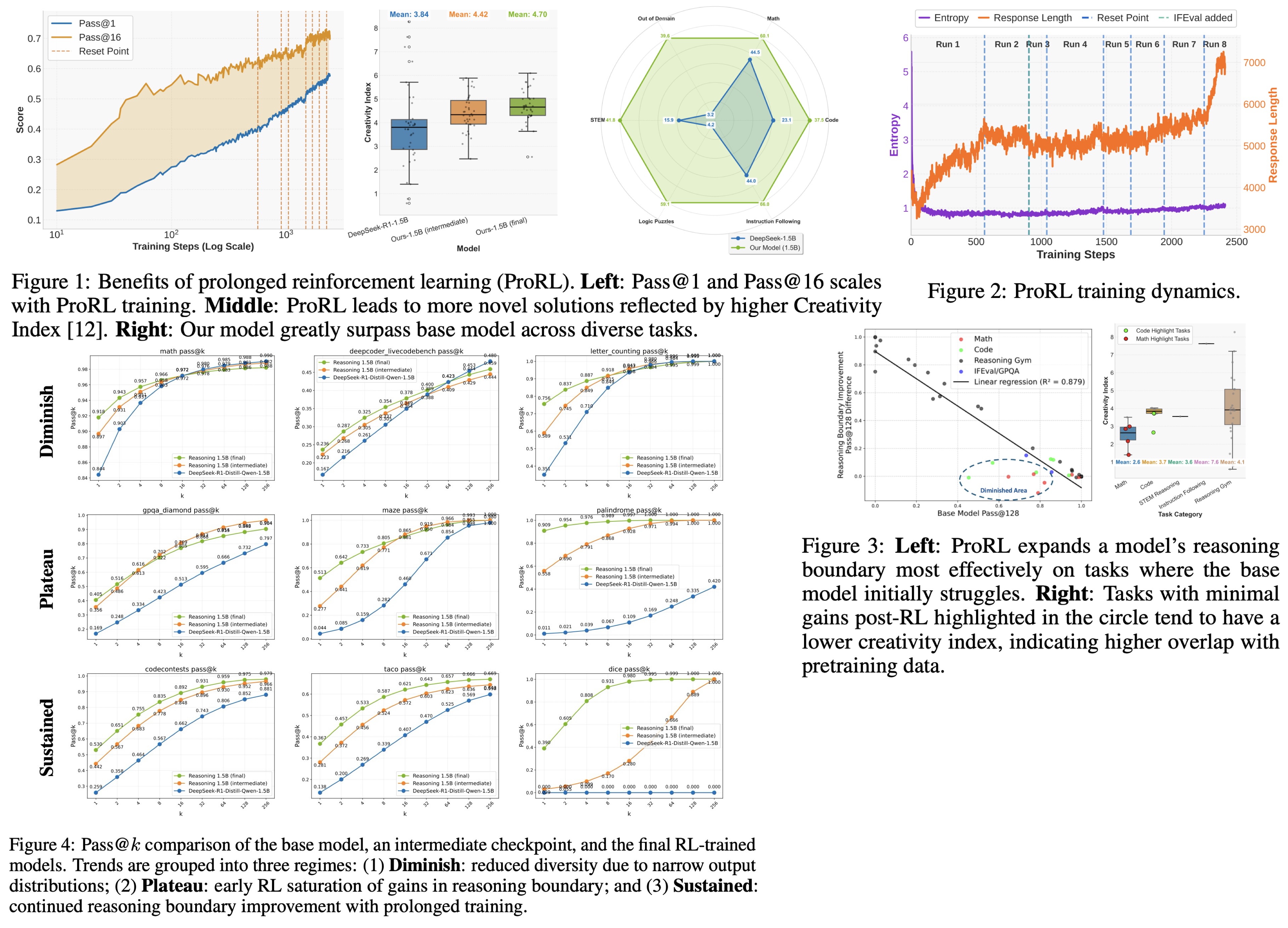
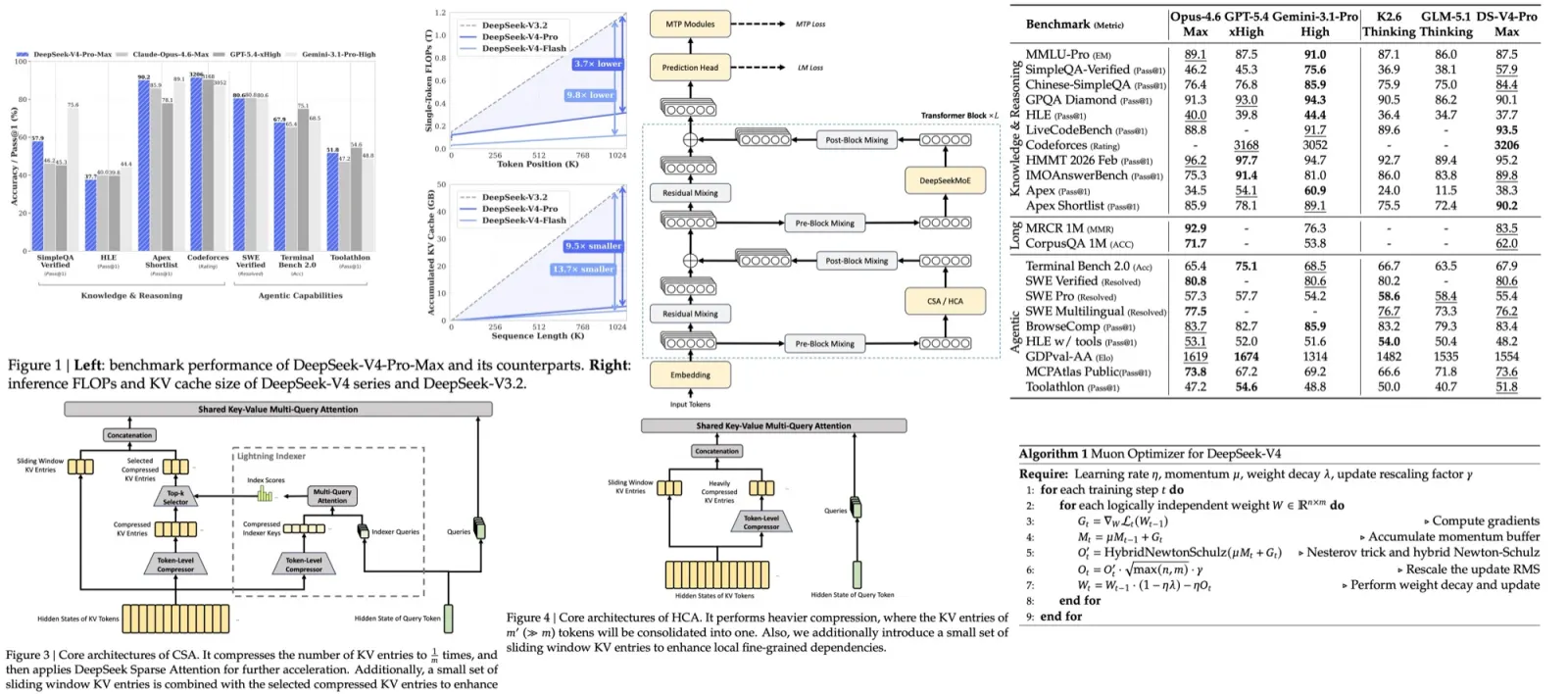
Researchers from NVIDIA propose enhancing the reasoning capabilities of LLMs through prolonged reinforcement learning (ProRL). Prolonged reinforcement learning training lets language models develop novel reasoning strategies that base models cannot reach, even with extensive sampling. ProRL combines KL divergence control, reference policy resetting, and a diverse set of tasks to guide training. Models trained with ProRL consistently outperform base models across various pass@k evaluations, including cases where base models fail entirely. The improvement in reasoning correlates with the base model’s competence and the duration of training, indicating that reinforcement learning can explore and populate new regions of the solution space over time.
ProRL: Prolonged Reinforcement Learning
Prolonged policy optimization faces the issue of entropy collapse, where the model’s output distribution becomes too narrow early in training, limiting exploration and degrading learning. Simply increasing sampling temperature delays but does not prevent this collapse. To address it, the authors incorporate elements from the DAPO algorithm: decoupled clipping with separate upper and lower bounds to boost unlikely token probabilities and encourage broader exploration, dynamic sampling to focus on prompts of intermediate difficulty, which maintain a useful learning signal.
Additionally, KL divergence regularization between the current and reference policy stabilizes learning and prevents overfitting, especially when starting from a well-initialized checkpoint. To avoid the KL term from dominating the loss over time and stalling progress, the reference policy is periodically reset to a recent version of the online policy, along with reinitializing the optimizer, allowing stable yet continued training.
Nemotron-Research-Reasoning-Qwen-1.5B
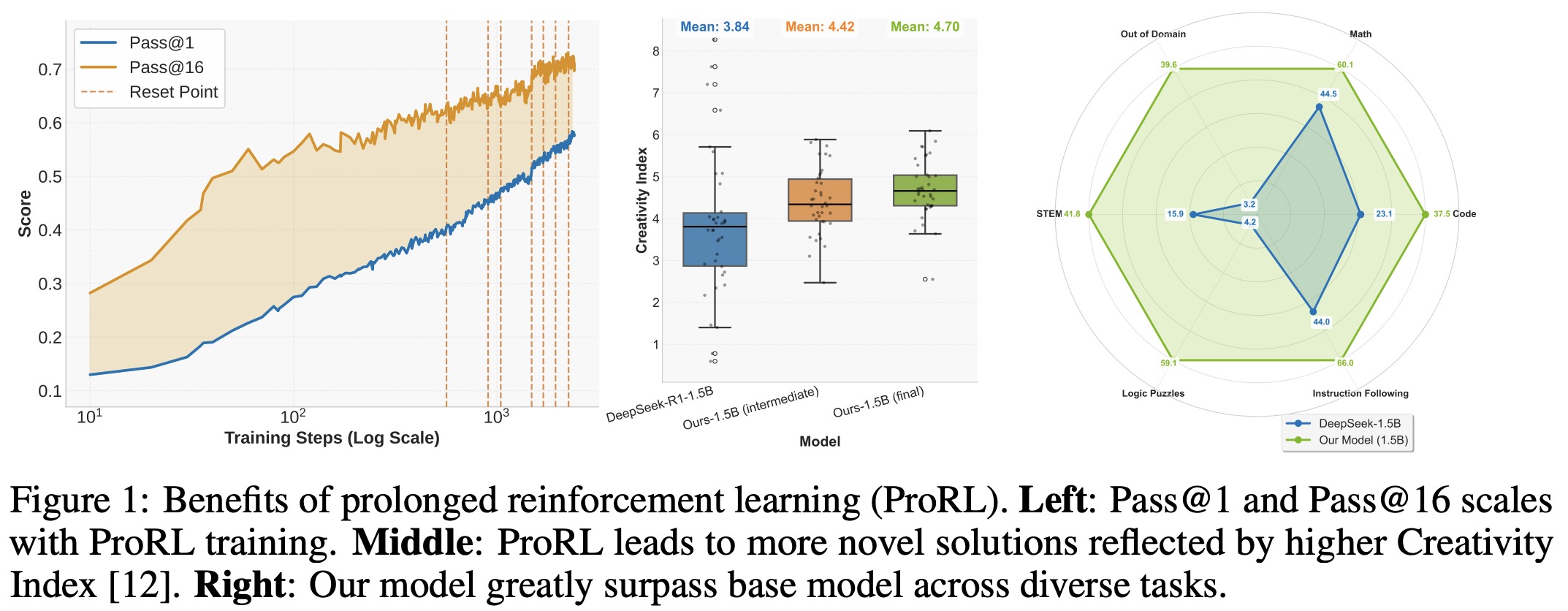
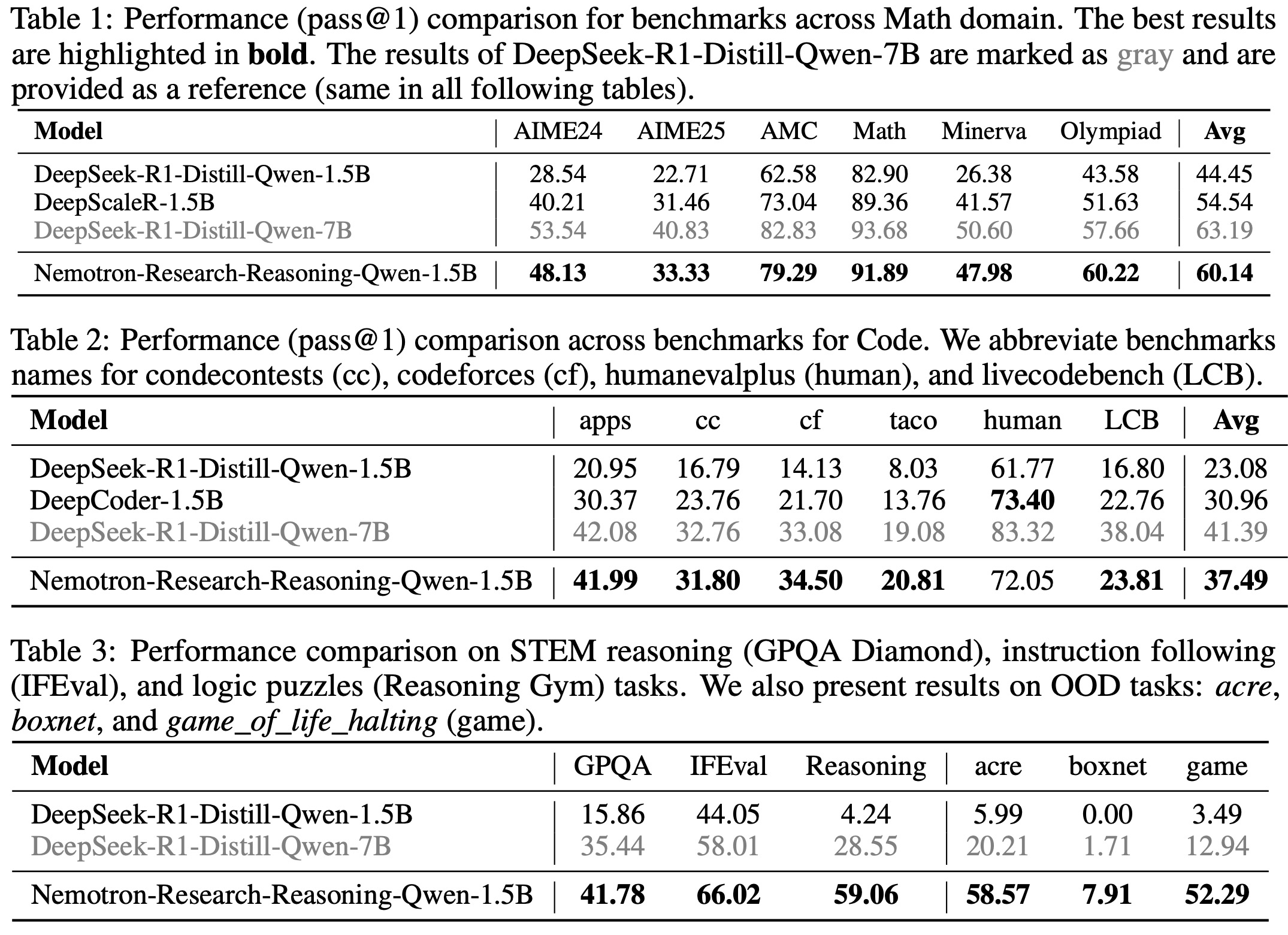
Nemotron-Research-Reasoning-Qwen-1.5B is a generalist model trained with RL on 136k diverse, verifiable problems across math, code, STEM, logic puzzles, and instruction following. Using stable reward signals, improved GRPO techniques, and prolonged training, the model shows strong cross-domain generalization. It outperforms its base model (DeepSeek-R1-Distill-Qwen-1.5B) significantly, with gains such as +15.7% in math and +54.8% in logic puzzles, and even exceeds domain-specialized models in math and code.
Total compute: approximately 16k GPU hours on 4 nodes with 8 × NVIDIA H100 80GB GPUs each.
Analysis: Does ProRL Elicit New Reasoning Patterns?
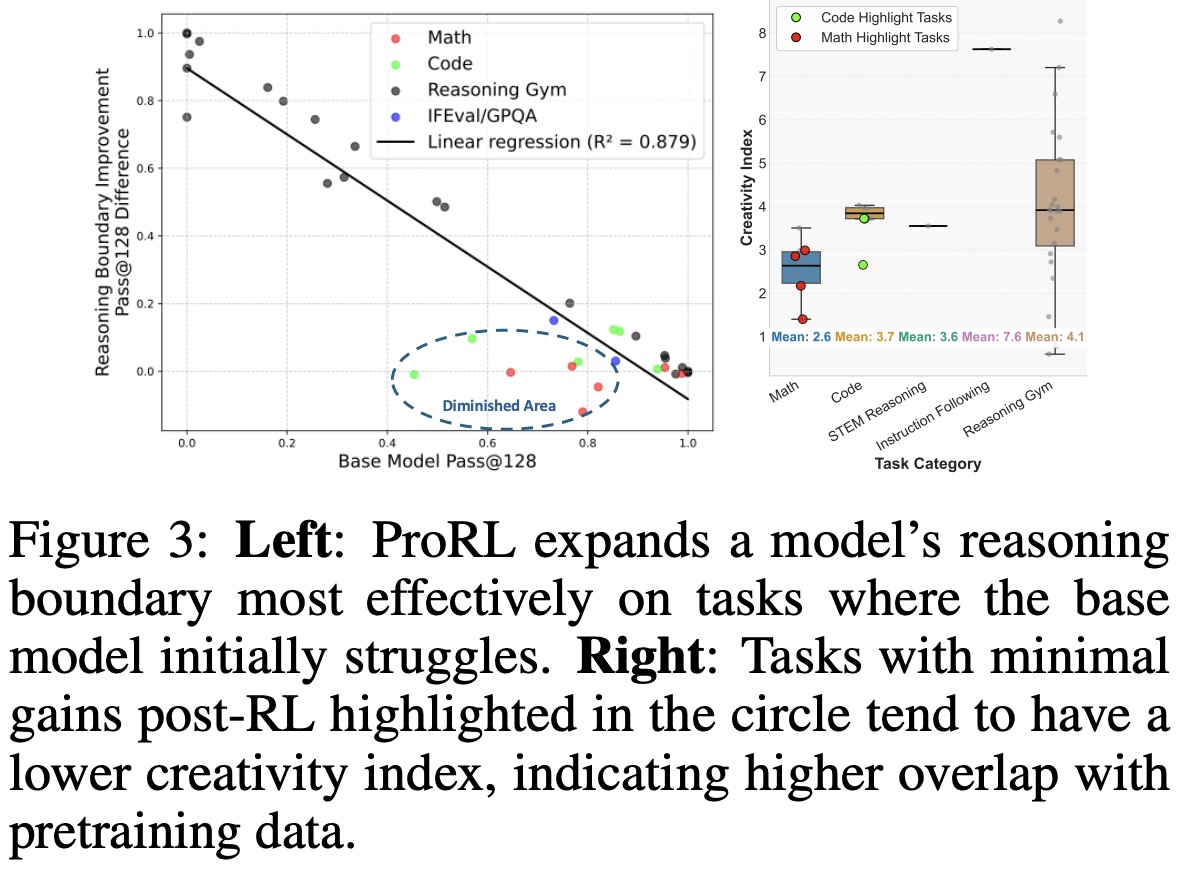
The effectiveness of ProRL in expanding a model’s reasoning abilities depends on the base model’s initial performance. Tasks where the base model starts off weak see the greatest improvements in both accuracy and reasoning diversity after RL training. In contrast, tasks where the base model already performs well tend to show little or even negative gains, as the model narrows its focus to known solutions rather than exploring new ones.
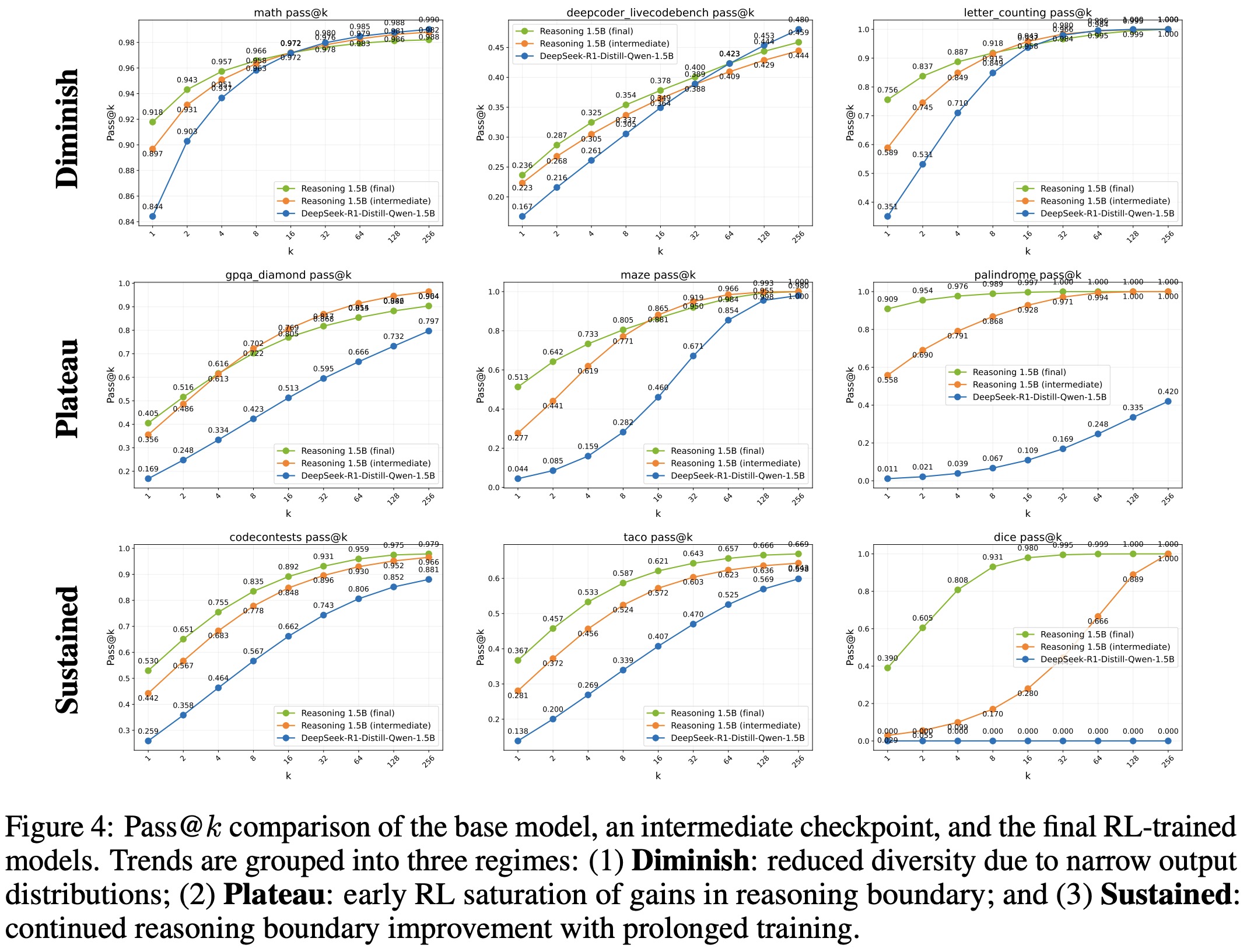
Reinforcement learning with ProRL can significantly expand a model’s reasoning ability, especially on challenging tasks where the base model struggles. Performance across benchmarks falls into three patterns:
- Some tasks, especially in math, show diminished reasoning breadth after RL. While pass@1 improves, pass@128 often declines, indicating overconfidence in known solutions and reduced exploration.
- In other tasks, early gains plateau, with improvements in both pass@1 and pass@128 occurring quickly but offering little additional benefit with continued training.
- For complex domains like code generation, RL enables sustained gains, with reasoning abilities improving steadily over time as the model explores more diverse solutions.
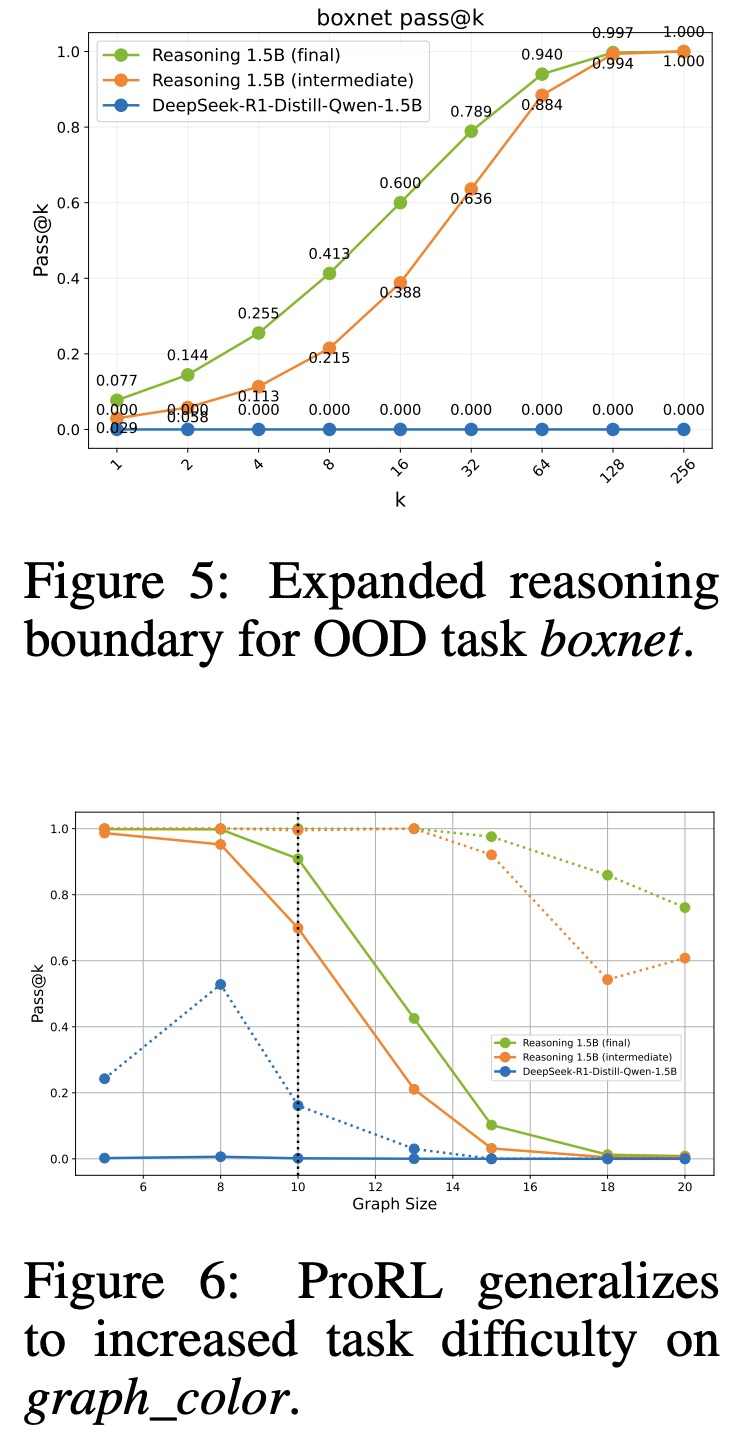
ProRL enhances a model’s ability to generalize beyond its training distribution, particularly on novel or more complex tasks. On the unseen boxnet task from Reasoning Gym, the base model fails completely, while the ProRL-trained model shows strong performance, demonstrating expanded reasoning capabilities. Continued RL training further amplifies these gains. On the graph_color task, where test graphs exceed the size seen during training, all models show performance declines with increased difficulty. However, the ProRL-trained model consistently outperforms both the base and intermediate models across all graph sizes.
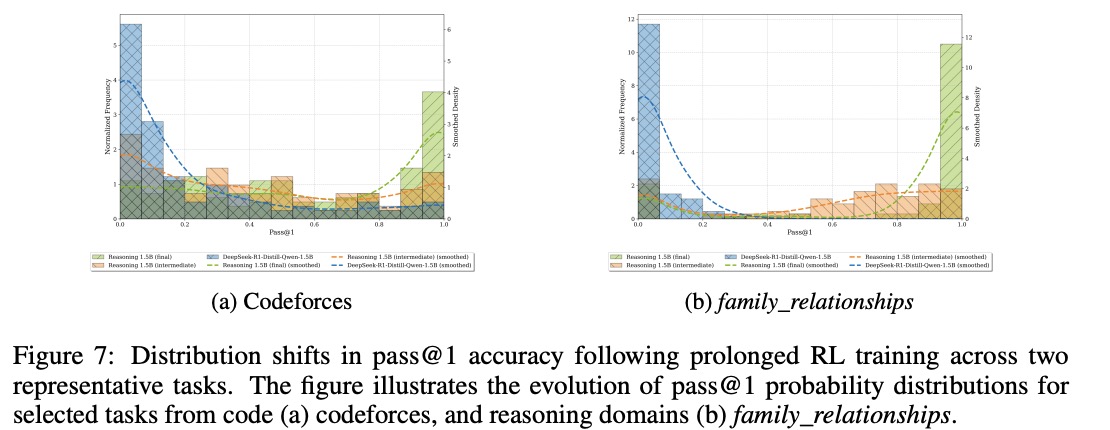
ProRL leads to consistent improvements in both pass@1 and pass@16 metrics, contrary to prior findings that pass@k may decline during training due to increased variance.
paperreview deeplearning llm rl