Paper Review: QLoRA: Efficient Finetuning of Quantized LLMs

The paper introduces QLoRA, an efficient finetuning technique that minimizes memory usage, enabling the finetuning of a 65-billion parameter model on a single 48GB GPU. QLoRA employs a frozen, 4-bit quantized pretrained language model and backpropagates gradients into Low Rank Adapters (LoRA). The top performing model family, Guanaco, surpasses all previously open-source models on the Vicuna benchmark, achieving 99.3% of ChatGPT’s performance while needing only 24 hours of finetuning on a single GPU.
To decrease memory usage without sacrificing performance, QLoRA introduces innovations like 4-bit NormalFloat (NF4), a data type optimal for normally distributed weights, Double Quantization to further decrease memory footprint, and Paged Optimizers to manage memory spikes.
Over 1,000 models were finetuned using QLoRA, providing extensive analysis of instruction following and chatbot performance across various datasets, model types (LLaMA, T5), and model scales that wouldn’t be feasible with standard finetuning, such as 33B and 65B parameter models. The results suggest that QLoRA finetuning on a small, high-quality dataset can yield state-of-the-art results, even with smaller models than those currently leading in the field.
Additionally, the paper analyses chatbot performance based on human and GPT-4 evaluations, indicating that GPT-4 evaluations are a viable, cost-effective alternative to human evaluation. However, the authors also warn that current chatbot benchmarks may not be reliable for accurately evaluating chatbot performance levels. The paper concludes with a lemon-picked analysis, illustrating areas where Guanaco falls short in comparison to ChatGPT.
QLoRA Finetuning
4-bit NormalFloat Quantization
The authors introduce the 4-bit NormalFloat (NF4) data type, which builds on Quantile Quantization—an information-theoretically optimal data type ensuring equal number of values per quantization bin from the input tensor. However, Quantile Quantization is limited by the costly process of quantile estimation and large quantization errors for outliers.
To address this, the authors use fast quantile approximation algorithms. They suggest that the downsides can be avoided when input tensors come from a distribution fixed up to a quantization constant. In such cases, exact quantile estimation becomes feasible because the input tensors have the same quantiles.
Pretrained neural network weights typically have a zero-centered normal distribution with a standard deviation. These weights can be transformed to a fixed distribution by scaling the standard deviation to fit into the data type’s range. The optimal data type for zero-mean normal distributions is computed by estimating the quantiles of a theoretical normal distribution, normalizing its values into the range [−1, 1], and then quantizing an input weight tensor by normalizing it into the same range through absolute maximum rescaling.
However, symmetric k-bit quantization doesn’t have an exact representation of zero, which is important for quantizing padding and zero-valued elements with no error. To address this, they create an asymmetric data type that includes a discrete zero-point of 0. The resulting data type, termed k-bit NormalFloat (NFk), is optimal for zero-centered normally distributed data.
Double Quantization
Double Quantization (DQ) is a process that further reduces memory usage by quantizing the quantization constants. While small blocksize is necessary for precise 4-bit quantization, it also results in substantial memory overhead. By applying a second quantization to the quantization constants, the memory footprint of these constants can be significantly reduced. This process turns 32-bit constants into 8-bit floats with a blocksize of 256, resulting in an average memory footprint reduction of 0.373 bits per parameter.
Paged Optimizers
To handle scenarios where the GPU occasionally runs out of memory, the authors use Paged Optimizers that utilize the NVIDIA unified memory feature, which performs automatic page-to-page transfers between the CPU and GPU, functioning much like regular memory paging between CPU RAM and the disk. This feature is used to allocate paged memory for the optimizer states which are then moved to CPU RAM when the GPU runs out of memory, and transferred back into GPU memory when needed.
QLORA.

QLORA is defined for a single linear layer in the quantized base model with a single LoRA adapter. They use NF4 for the weights (W) and FP8 for the quantization constants (c2). For higher quantization precision, they use a blocksize of 64 for W, and to conserve memory, a blocksize of 256 for c2. They also explain the process of computing the gradient for the adapter weights during parameter updates.
Overall, QLORA uses one storage data type (typically 4-bit NormalFloat) and one computation data type (16-bit BrainFloat). The storage data type is dequantized to the computation data type for performing the forward and backward pass, with weight gradients only computed for the LoRA parameters, which use 16-bit BrainFloat.
QLoRA vs. Standard Finetuning
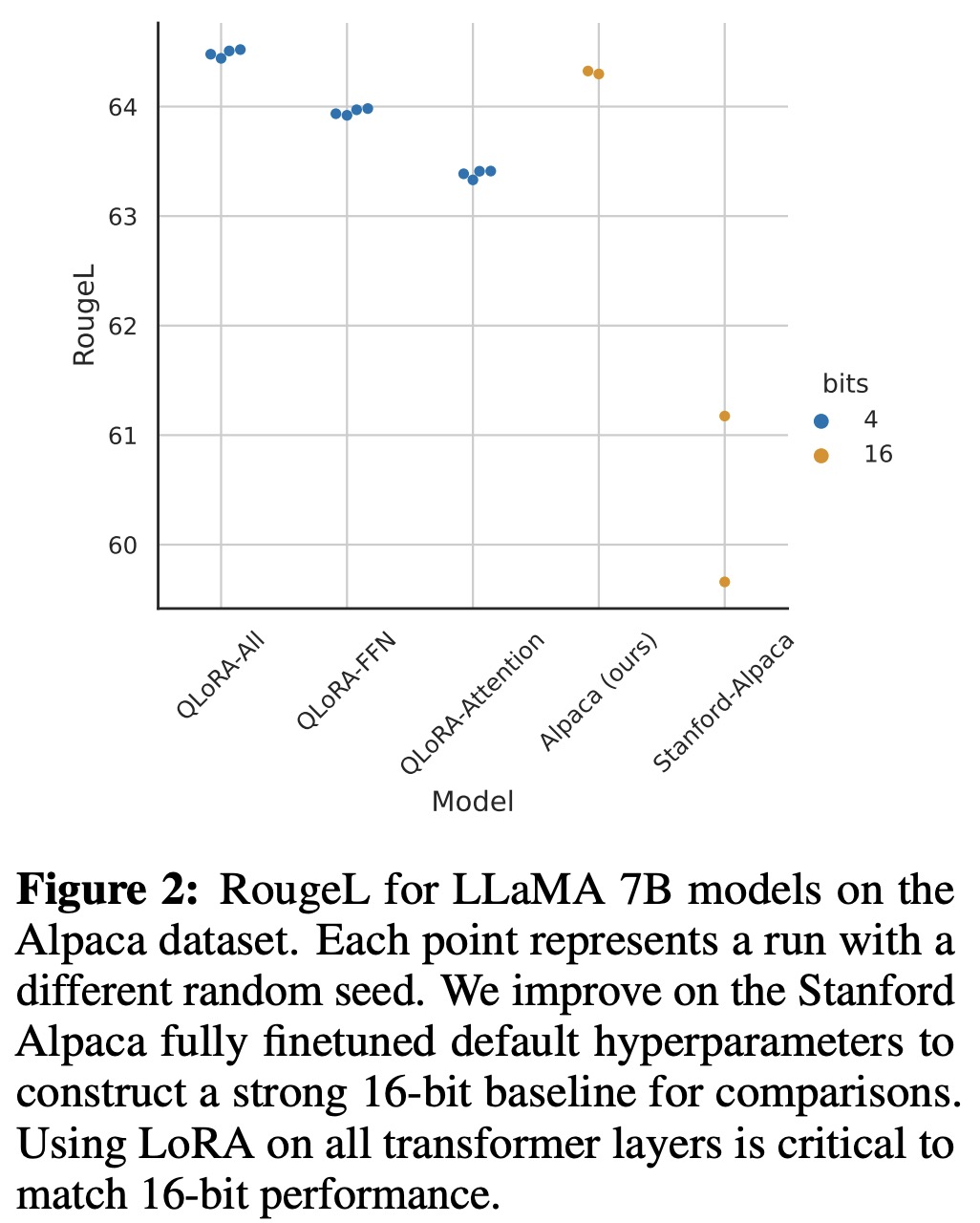
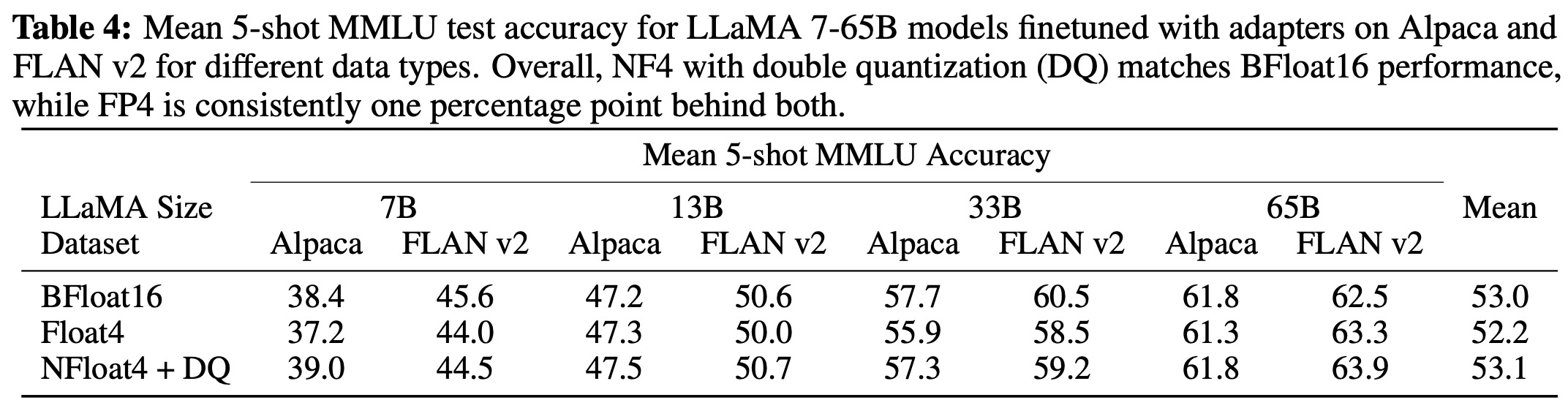
- The authors found that default LoRA hyperparameters did not match the performance of 16-bit methods when using large base models. They determined that the quantity of LoRA adapters used was a critical factor and found that LoRA on all linear transformer block layers was required to match full finetuning performance. Other LoRA hyperparameters did not significantly affect performance.
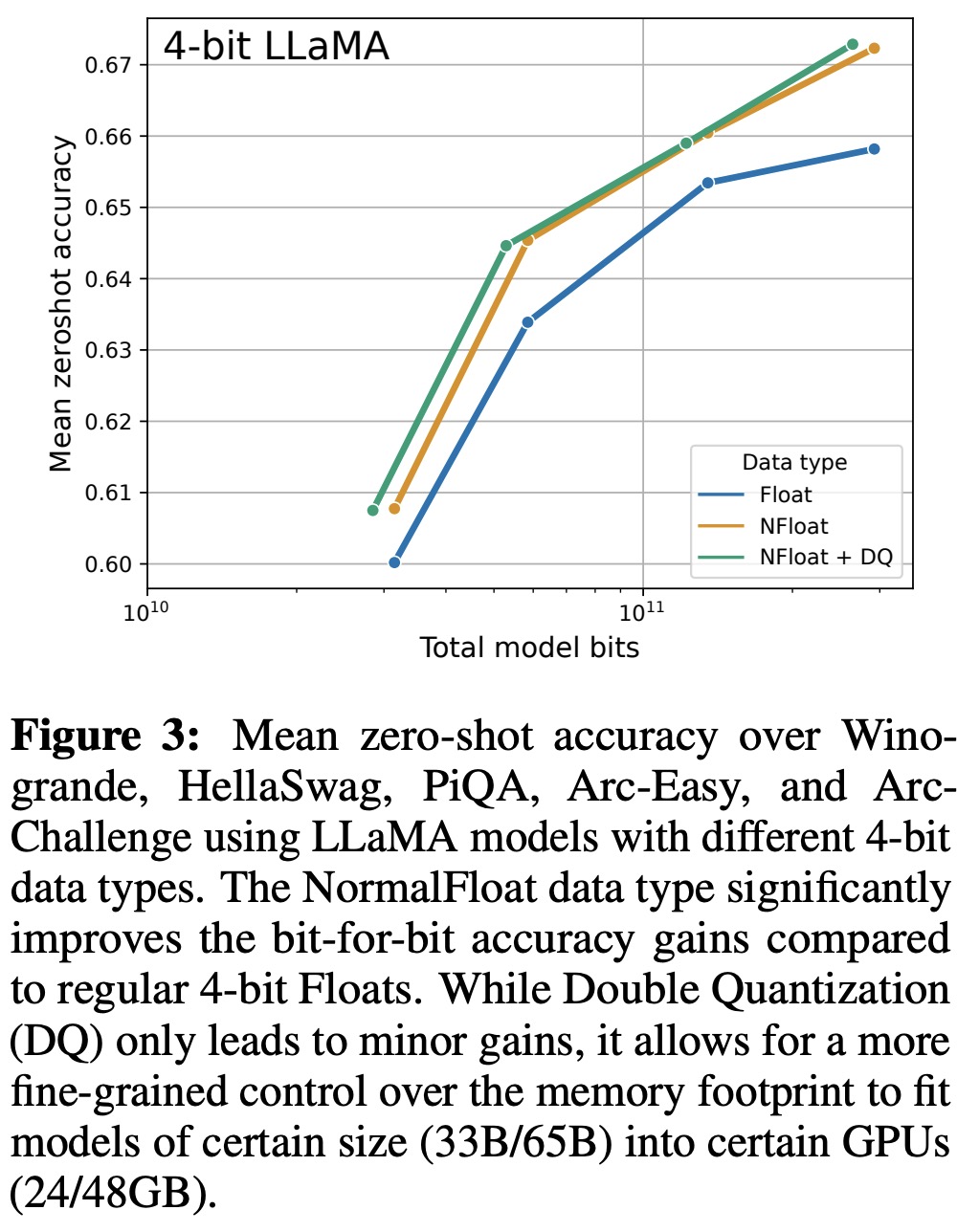
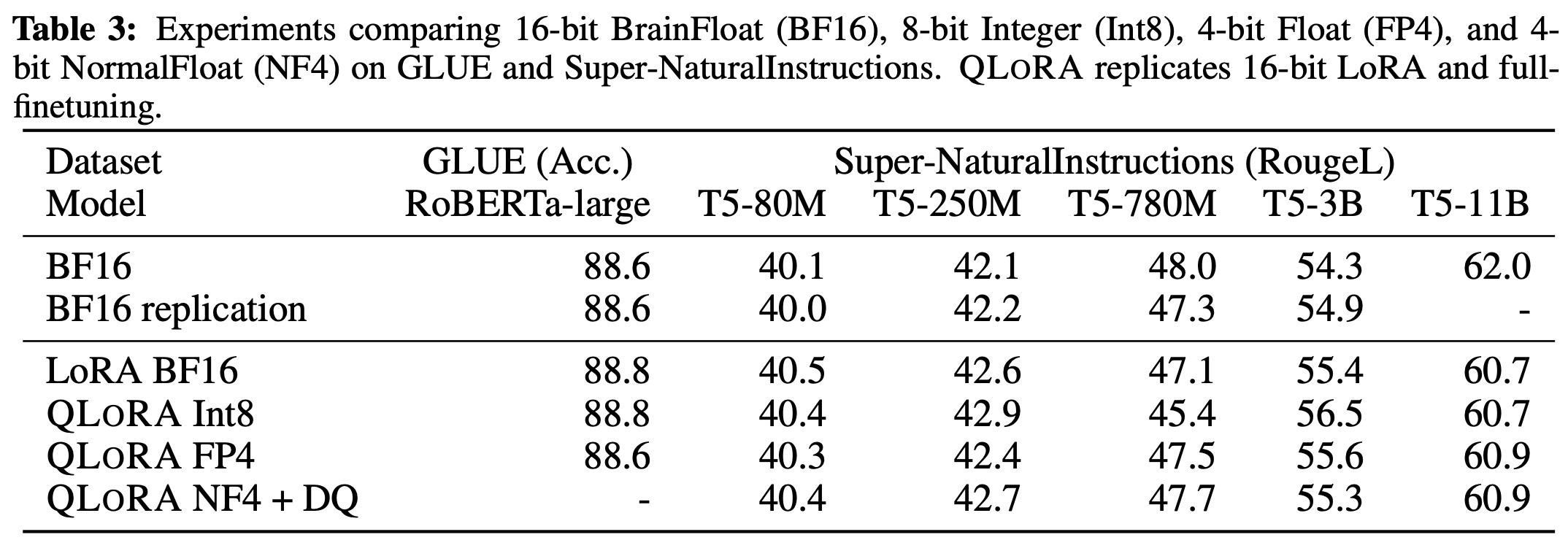
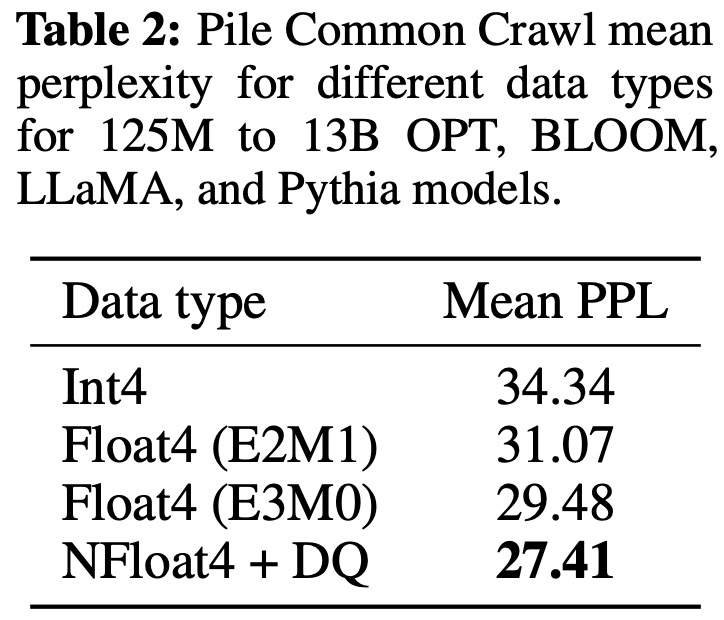
- They also found that the 4-bit NormalFloat (NF4) data type provided better performance than the 4-bit Floating Point (FP4) data type.
- Furthermore, k-bit QLORA matched the performance of 16-bit full finetuning and 16-bit LoRA. They found that any performance lost due to the imprecise quantization can be fully recovered through adapter finetuning after quantization.
Pushing the Chatbot State-of-the-art with QLoRA
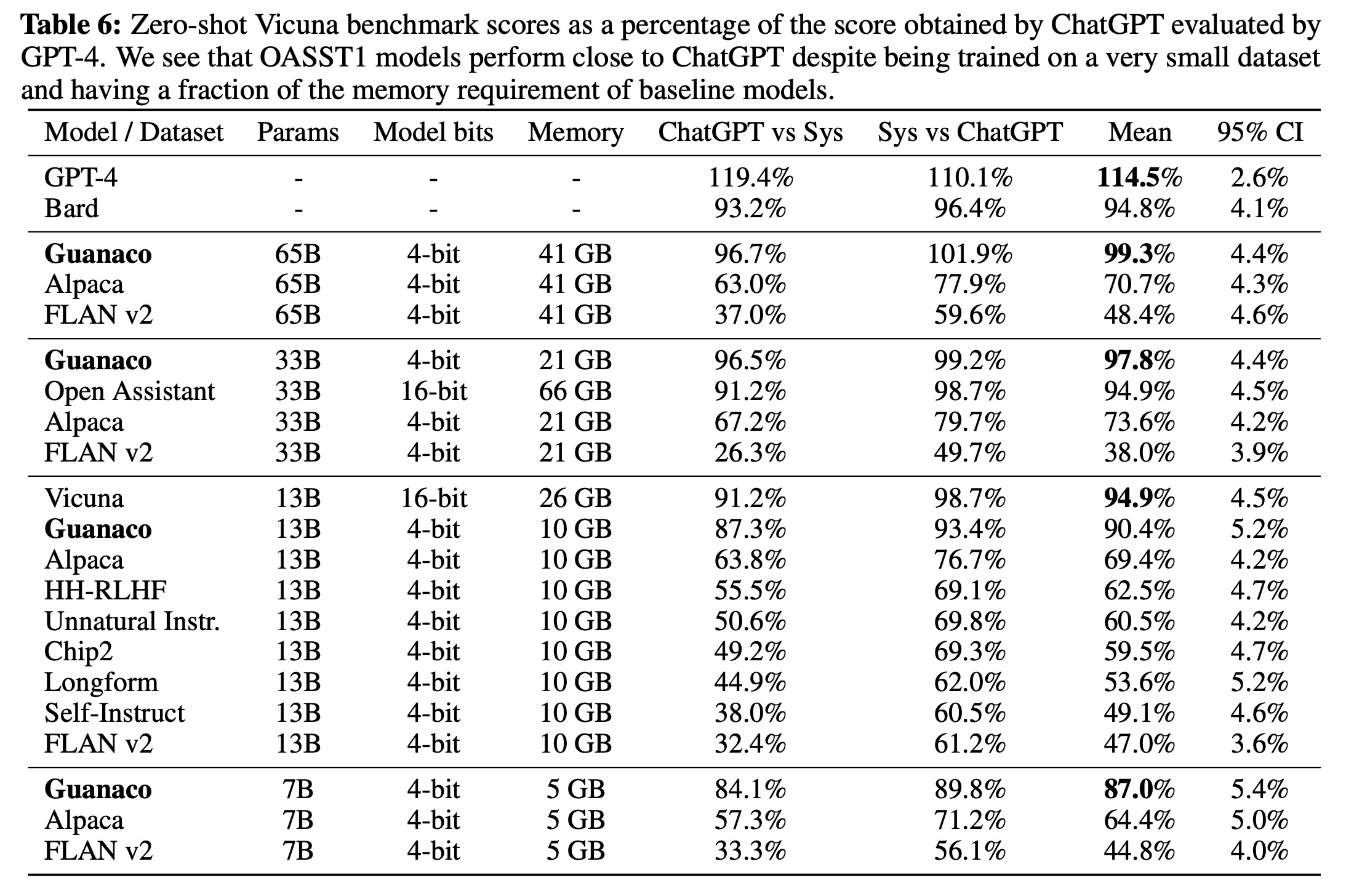
The authors conducted evaluations on the Guanaco 65B model, which was finetuned on a variant of OASST1 using QLORA. The results indicated that it is the best-performing open-source chatbot model, offering performance competitive to ChatGPT. When compared to GPT-4, Guanaco 65B and 33B have an expected win probability of 30%.
- Guanaco 65B performed the best after GPT-4 on the Vicuna benchmark, achieving 99.3% performance relative to ChatGPT. The Guanaco 33B model was more memory efficient than the Vicuna 13B model despite having more parameters, due to using only 4-bit precision for its weights. Moreover, Guanaco 7B could fit on modern phones while scoring nearly 20 percentage points higher than Alpaca 13B.
- Despite the impressive results, there was a wide range of confidence intervals with many models overlapping in performance. The authors attributed this uncertainty to a lack of clear specification of scale. To address this, they recommended using the Elo ranking method, which is based on pairwise judgments from human annotators and GPT-4.
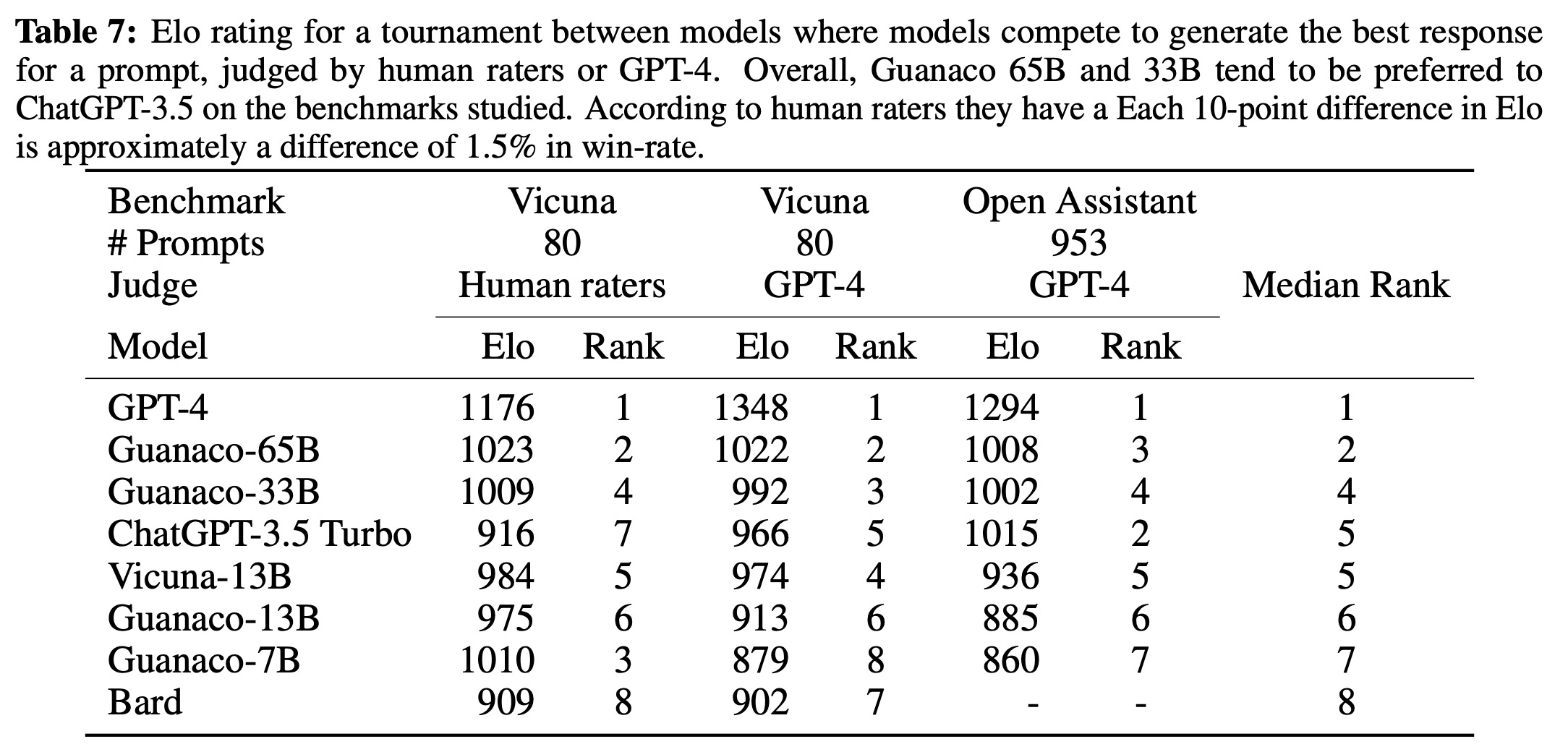
- Elo rankings indicated that Guanaco 33B and 65B models outperformed all models except for GPT-4 on the Vicuna and OA benchmarks and performed comparably to ChatGPT. However, the choice of finetuning dataset greatly influenced the performance, indicating the importance of dataset suitability.
Qualitative Analysis
Qualitative Analysis of Example Generations
The authors show multiple examples of correct and wrong behavior of Guanaco model.




Considerations
The study reveals moderate agreement among human annotators in evaluating chatbot performance, indicating limitations in current benchmarks and evaluation protocols. The authors noticed subjective preferences influencing judgments, suggesting the need for future research on this issue. There were also noted biases in automated evaluation systems, with GPT-4 favoring the system appearing first in its prompt and assigning higher scores to its own outputs.
The Guanaco models, trained on a multilingual OASST1 dataset, performed well; future work should explore if multilingual training improves non-English instruction performance. There was no evidence of data leakage between the OASST1 data and the Vicuna benchmark prompts. Lastly, Guanaco models were trained using cross-entropy loss, not reinforcement learning from human feedback (RLHF), suggesting further study on the trade-offs between these training methods, enabled by QLORA’s efficiency.
paperreview deeplearning finetuning optimization