Recognize Anything: A Strong Image Tagging Model

The Recognize Anything Model (RAM) is a new foundational model for image tagging that presents significant advancements in the field of computer vision. Unlike traditional models, RAM does not rely on manual annotations for training; instead, it leverages large-scale image-text pairs. The development process of RAM involves four key stages:
- Obtaining annotation-free image tags at scale through automatic text semantic parsing.
- Training a preliminary model for automatic annotation by combining the caption and tagging tasks. This model is supervised by the original texts and parsed tags.
- Utilizing a data engine to create additional annotations and correct incorrect ones.
- Retraining the model with the processed data and fine-tuning it using a smaller but higher-quality dataset.
RAM demonstrated impressive zero-shot performance on multiple benchmarks, outperforming previous models like CLIP and BLIP. Notably, its performance exceeded even fully supervised methods, proving competitively against the Google tagging API.
Recognize Anything Model
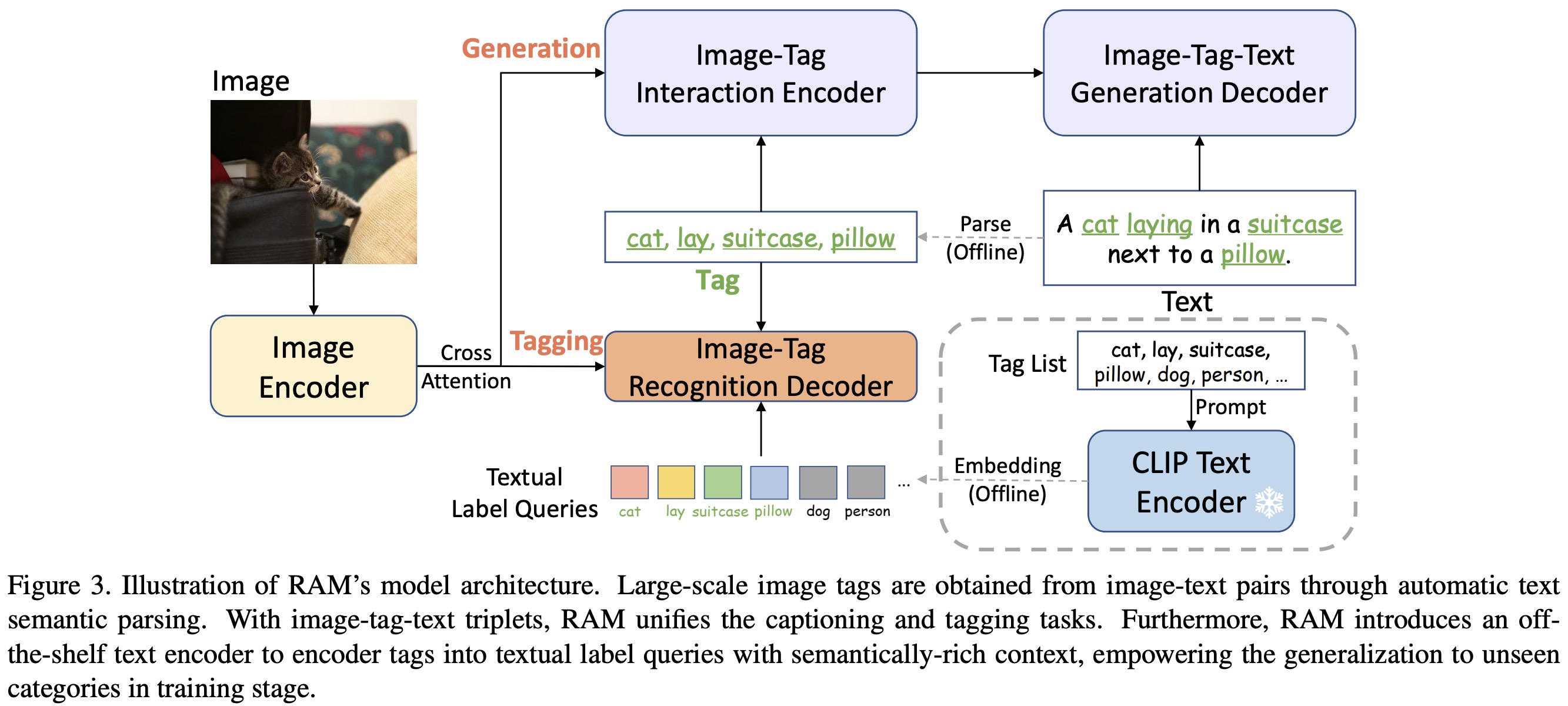
Recognize Anything Model (RAM) uses text semantic parsing to extract image tags, providing a vast amount of tags without the need for costly manual annotations. RAM’s overall architecture is similar to Tag2Text and comprises three critical modules: an image encoder for feature extraction, an image-tag recognition decoder for tagging, and a text generation encoder-decoder for captioning.
During training, the recognition head learns to predict tags parsed from the text, while in the inference stage, it serves as a bridge from image-to-tags by predicting tags that provide more explicit semantic guidance to image captioning.
A key advancement of RAM over Tag2Text is the introduction of open-vocabulary recognition. Unlike Tag2Text, which can only recognize categories it has encountered during training, RAM can recognize any category, thereby expanding its practical applicability.
Open-Vocabulary Recognition
The significant enhancement of the Recognize Anything Model (RAM) lies in its incorporation of semantic information into the label queries of the recognition decoder. This addition allows the model to generalize to categories unseen during the training stage. RAM achieves this by employing an off-the-shelf text encoder to encode the individual tags from the tag list, which enriches textual label queries with semantically-rich context. In contrast, the label queries in the original recognition decoder are randomly learnable embeddings that lack a semantic relationship with unseen categories, thus being limited to predefined seen categories.
In terms of implementation details, RAM uses a Swin-transformer as the image encoder due to its superior performance over the standard Vision Transformer (ViT) in both vision-language and tagging domains. The text generation encoder-decoder consists of 12-layer transformers, and the tag recognition decoder is a 2-layer transformer.
RAM also utilizes the off-the-shelf text encoder from CLIP for generating textual label queries via prompt ensembling. Furthermore, it adopts the CLIP image encoder to distill image features, which enhances the model’s recognition ability for unseen categories through image-text feature alignment.
Model Efficiency
In its training phase, the Recognize Anything Model (RAM) is pretrained on large-scale datasets with a resolution of 224 and then fine-tuned at a resolution of 384 using smaller, high-quality datasets. RAM converges rapidly, typically in less than 5 epochs, which enhances its reproducibility with limited computational resources. For instance, the version of RAM pretrained on 4 million images requires just 1 day of computation, while the strongest version, pretrained on 14 million images, requires only 3 days of computation on 8 A100 GPUs.
During the inference phase, the lightweight image-tag recognition decoder enhances RAM’s inference efficiency for image tagging. The self-attention layers are eliminated from the recognition decoder, which not only improves efficiency but also prevents potential interference between label queries. Consequently, RAM allows customization of label queries for any category and quantity that need automatic recognition, enhancing its utility across various visual tasks and datasets.
Data
Label System
The formulation of the label system in the Recognize Anything Model (RAM) follows three principles:
- Tags that frequently appear in image-text pairs are given more value due to their significant role in image description.
- A variety of domains and contexts should be represented in the tags, including objects, scenes, attributes, and actions, which aids in generalizing the model to complex, unseen scenarios.
- The quantity of tags needs to be moderate to avoid heavy annotation costs.
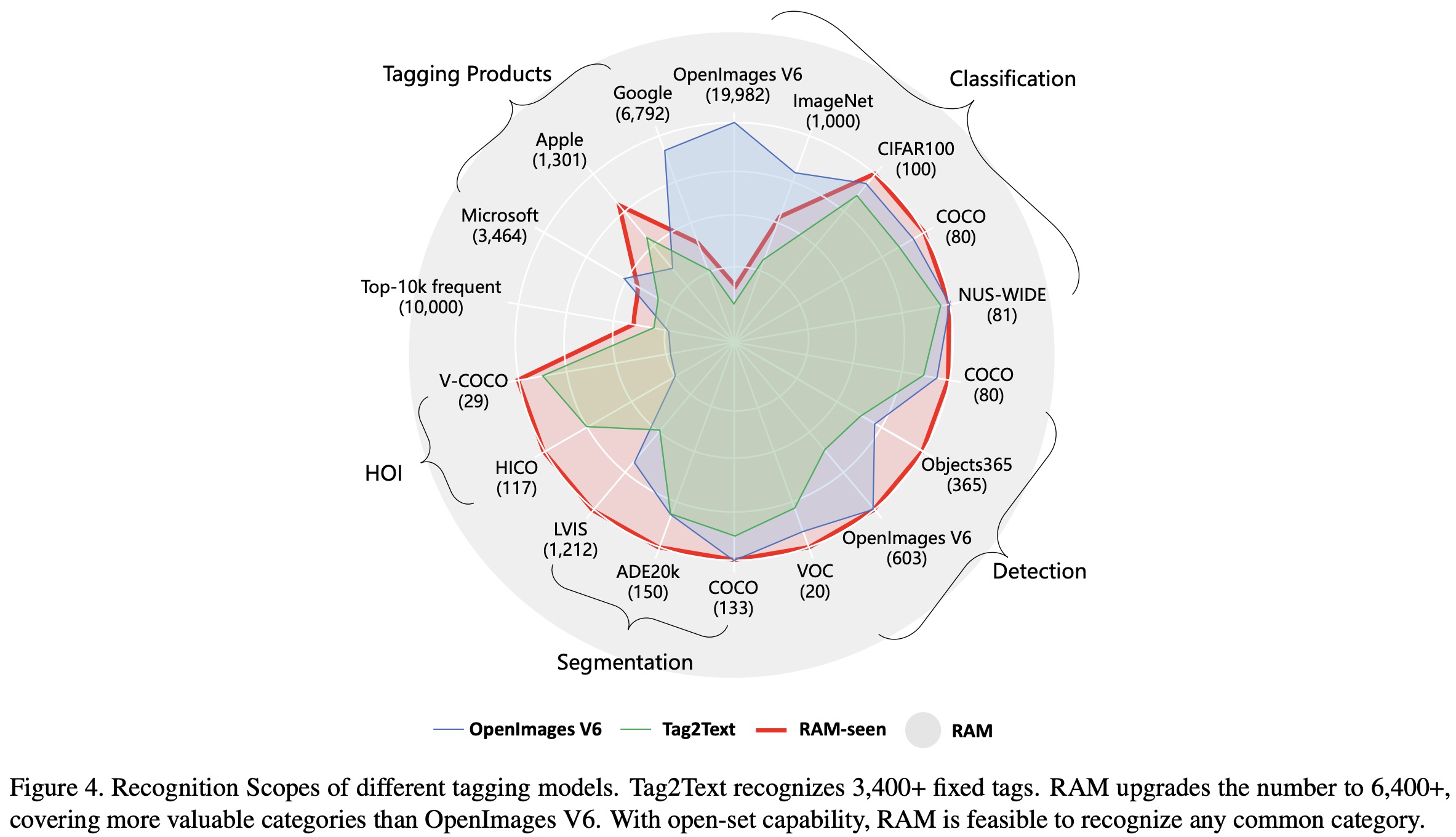
Initially, RAM parses 14 million sentences from its pretraining datasets into tags using a SceneGraphParser with minor modifications. The top 10,000 most frequently occurring tags are then manually selected. The chosen tags cover numerous popular datasets for classification, detection, and segmentation, with the exception of a few like ImageNet and OpenImages V6 due to their unusual tag presence. RAM also partially covers tags from leading tagging products obtained via public APIs using open-source images.
As a result, RAM can recognize up to 6449 fixed tags, significantly more than Tag2Text, and includes a higher proportion of valuable tags. To reduce redundancy, synonyms are collected through various methods, including manual checks, referring to WordNet, translating and merging tags, and so on. Tags within the same synonym group are assigned the same tag ID, resulting in 4585 tag IDs in the label system.
Data Engine
To deal with missing and incorrect labels in the predominantly open-source training datasets, an automatic data engine is designed to generate additional tags and correct erroneous ones.
In the generation phase, a baseline model is trained using captions and tags parsed from these captions, similar to the approach used in Tag2Text. This model is then used to supplement both captions and tags, expanding the number of tags in the 4 million image dataset from 12 million to 39.8 million.
In the cleaning phase, Grounding-Dino is used to identify and crop regions corresponding to specific categories within all images. These regions are then clustered based on K-Means++, and tags associated with the outlier 10% are removed. Tags without the prediction of the specific category using the baseline model are also eliminated. The reasoning behind this is that the precision of tagging models can be improved by predicting regions rather than whole images.
Experiment
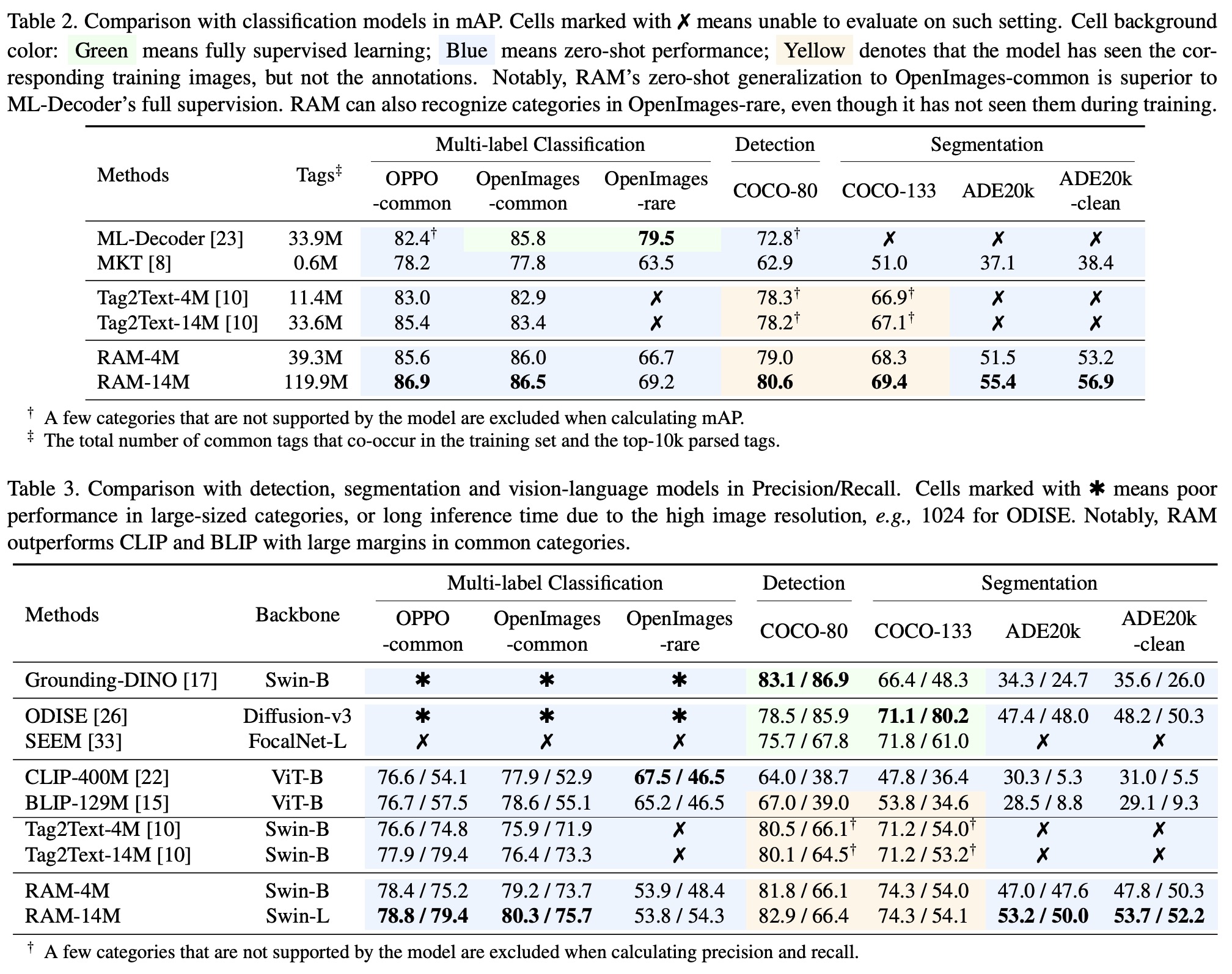
The Recognize Anything Model (RAM) was compared with state-of-the-art models in multi-label classification, detection, segmentation, and vision-language models.
- Multi-Label Classification Models: While supervised expert models excel in specific domains, they struggle to generalize to other domains and unseen categories. Generalist models fail to achieve satisfactory accuracy across all domains. RAM showcases broad coverage and impressive accuracy, even surpassing supervised expert models on certain datasets, with fewer training data but more tags. It leverages its open-vocabulary ability to recognize any common category.
- Detection and Segmentation Models: These models excel in specific domains with limited categories but struggle with larger categories due to high computational overheads and poor generalization performance. RAM demonstrates an impressive open-set ability, surpassing existing detection and segmentation models in generalizing across a broader range of categories.
- Vision-Language Models: Despite their open-set recognition capabilities, models like CLIP and BLIP suffer from subpar accuracy and limited interpretability. RAM surpasses these models by a significant margin in almost all datasets, showcasing superior performance. However, RAM underperforms slightly in the case of rare classes, due to its smaller training dataset and less emphasis on such classes during training.
Ablations
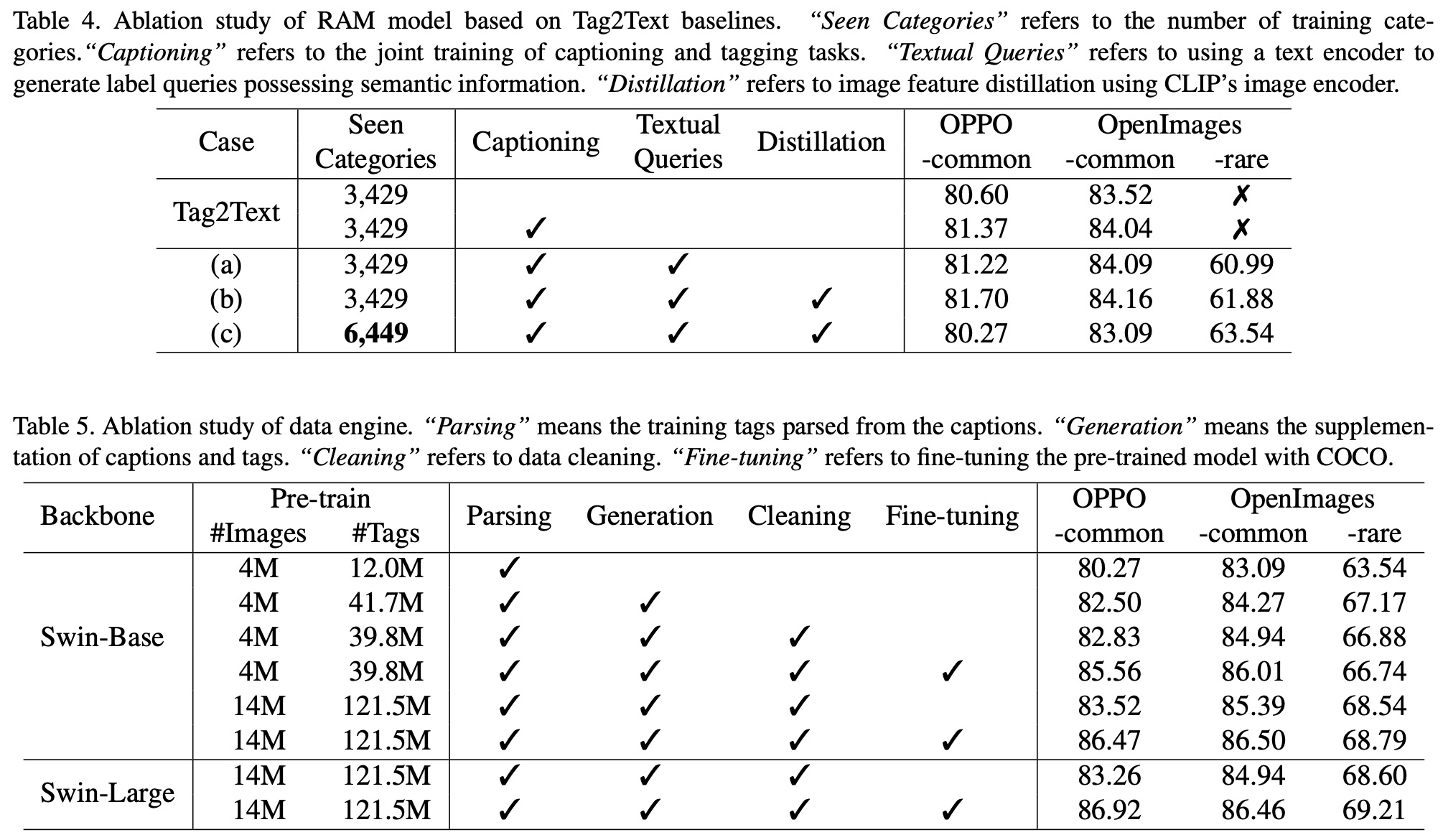
Model Ablation Study: The key findings are:
- Integrating captioning and tagging during training enhances tagging ability.
- Open-set recognition can be achieved through textual queries by CLIP but has little impact on seen categories in training.
- Expanding the label system slightly impacts existing categories due to the increased difficulty of model training. However, it enhances the model’s coverage and open-set ability for unseen categories.
Data Engine Ablation Study: The study reveals:
- Adding more tags significantly improves model performance across all test sets, highlighting the missing label problem in the original datasets.
- Cleaning the tags of some categories slightly increases performance on the OPPO-common and OpenImages-common test sets.
- Scaling up the training images from 4M to 14M significantly improves performance across all test sets.
- Employing a larger backbone network only slightly improves performance on OpenImages-rare and even slightly reduces performance on common categories, which the authors attribute to limited resources for conducting hyper-parameter search.
- Fine-tuning with tags parsed from the COCO Caption dataset notably increases performance on the OPPO-common and OpenImages-common test sets. The dataset provides comprehensive descriptions, approximating a complete set of tag labels.
Limitations
Like CLIP, the current version of RAM effectively recognizes common objects and scenes but finds difficulty with abstract tasks, such as object counting. Its performance in fine-grained classifications (like differentiating between car models or identifying specific flower or bird species) also falls behind task-specific models in a zero-shot setting. Additionally, since RAM is trained on open-source datasets, it might potentially reflect the biases present in those datasets.
paperreview deeplearning cv imagecaptioning multimodal