Paper Review: RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
RankRAG by NVIDIA is a novel instruction fine-tuning framework for RAG that allows a single LLM to handle both context ranking and answer generation. By incorporating a small amount of ranking data into the training mix, RankRAG significantly outperforms existing expert ranking models, even those fine-tuned on extensive ranking data. In evaluations, Llama3-RankRAG surpasses models like Llama3-ChatQA-1.5 and various versions of GPT-4 on nine knowledge-intensive benchmarks and performs comparably to GPT-4 on five biomedical RAG benchmarks, demonstrating exceptional generalization without the need for domain-specific fine-tuning.
RankRAG is a novel instruction fine-tuning framework for large language models (LLMs) in retrieval-augmented generation (RAG). It trains a single LLM to both rank contexts and generate answers, performing well with minimal ranking data in the training mix. RankRAG outperforms existing expert ranking models and strong baselines like GPT-4 and ChatQA-1.5 on various knowledge-intensive benchmarks. Notably, Llama3-RankRAG shows impressive performance across domains, including biomedical RAG tasks, without specific fine-tuning. This approach demonstrates significant potential for improving LLM performance in RAG tasks and generalizing to new areas.
Preliminaries
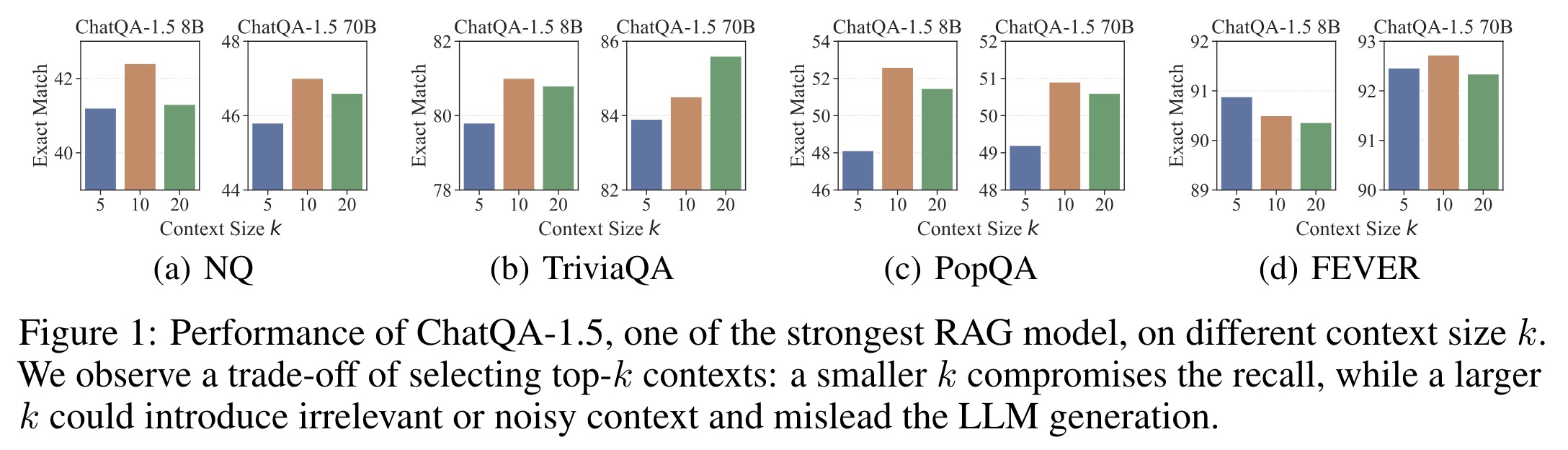
In RAG, a retriever model first selects the top-k relevant contexts from a document collection, after which a language model generates the final answer. Current RAG systems face limitations, including the limited capacity of retrievers and the trade-off in selecting the top-k contexts. Retrievers often use sparse models or moderate-size embedding models for efficiency, but these models’ independent encoding of questions and documents constrains their ability to accurately estimate textual relevance. Additionally, while SOTA long-context language models can process many retrieved contexts, their performance saturates with increased k. Research indicates that the optimal number of context chunks is around 10 for long document QA tasks. Smaller k values risk missing relevant information, reducing recall, whereas larger k values introduce irrelevant content, which hampers the language model’s accuracy.
The approach
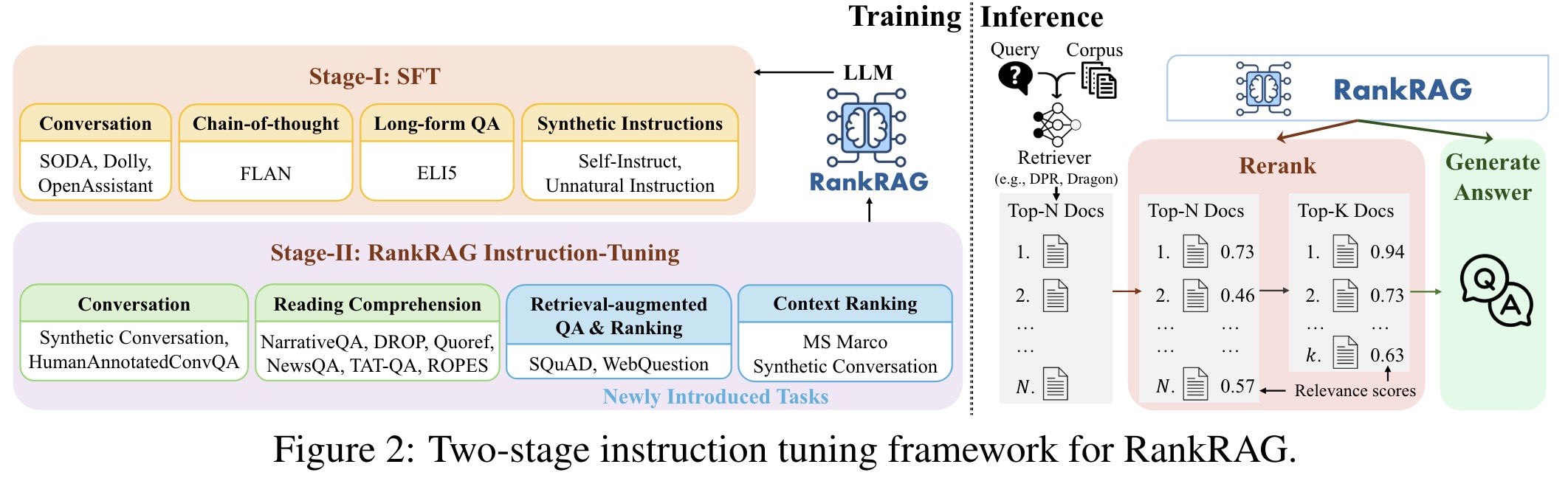
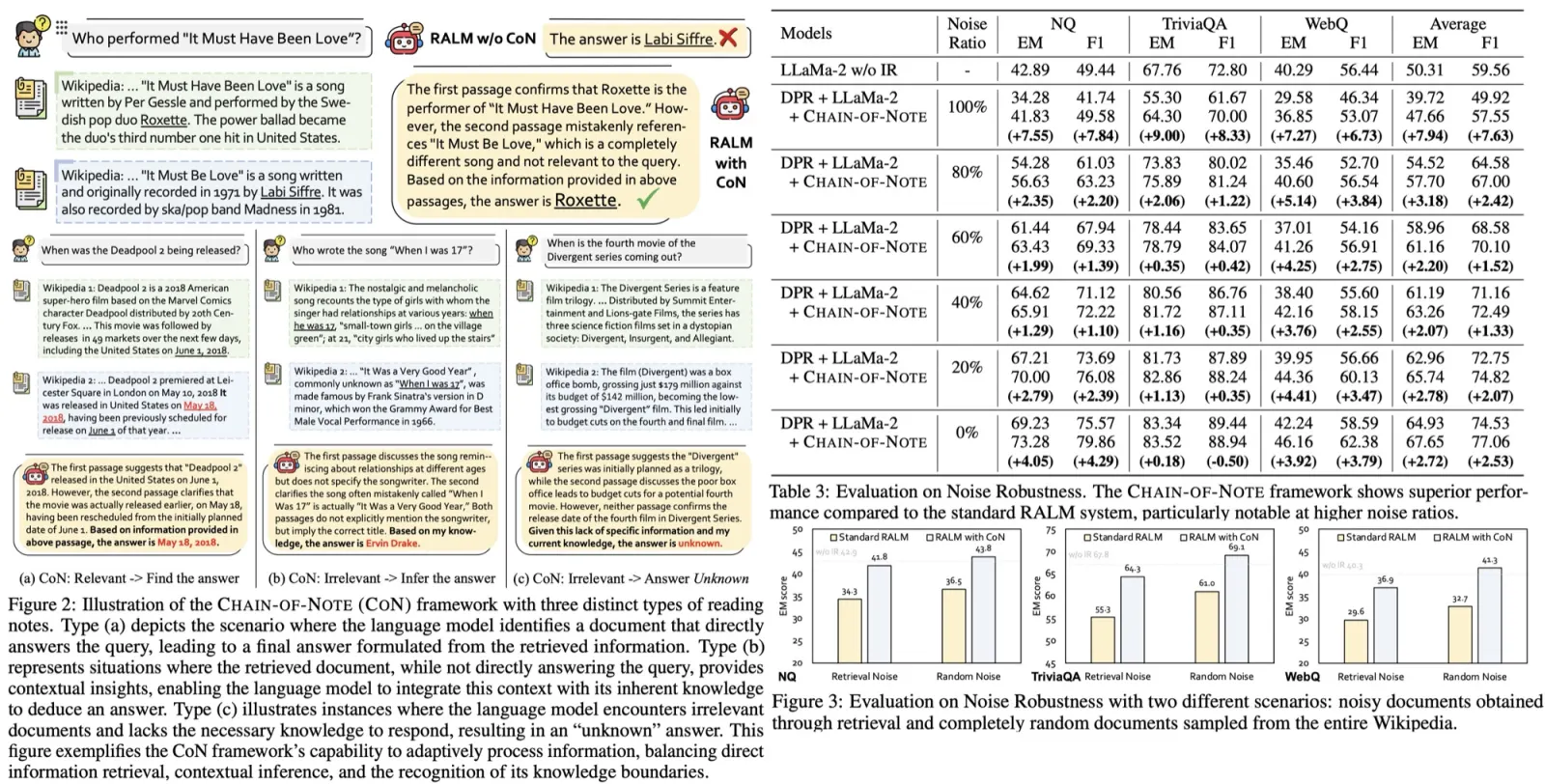
Stage-I: Supervised Fine-Tuning
In Stage-I, RankRAG uses SFT on a blend of high-quality instruction-following datasets (128K examples) to establish basic instruction-following capabilities.
Stage-II: Unified Instruction-Tuning for Ranking and Generation

Stage-I’s SFT provides basic instruction-following capabilities, but LLMs still perform suboptimally on RAG tasks. RankRAG addresses this by instruction-tuning the LLM for both context ranking and answer generation. This involves:
- SFT data from Stage-I to maintain instruction-following capabilities.
- Context-rich QA data to improve the LLM’s use of context for generation.
- Retrieval-augmented QA data to enhance robustness against irrelevant contexts.
- Context ranking data to empower LLMs with ranking capabilities.
- Retrieval-augmented ranking data to train the LLM to determine the relevance of multiple contexts simultaneously, closer to real-world RAG scenarios.
All tasks are standardized into a QA format (question, context, answer), allowing mutual enhancement and resulting in a unified model capable of various knowledge-intensive tasks.
RankRAG Inference: Retrieve-Rerank-Generate Pipeline
The inference pipeline for RankRAG is a three-step process:
- The retriever model retrieves top-N contexts from the corpus.
- The RankRAG model calculates the relevance scores between the question and the N contexts, retaining only the top-k contexts.
- The top-k contexts and the question are concatenated and fed into the RankRAG model to generate the final answer.
Experiments
Training RankRAG-8B uses 32 NVIDIA A100 GPUs for 10 hours (4 hours for Stage-I and 6 hours for Stage-II finetuning), while training RankRAG-70B uses 128 NVIDIA A100 GPUs for 16 hours (4 hours for Stage-I and 12 hours for Stage-II Finetuning).
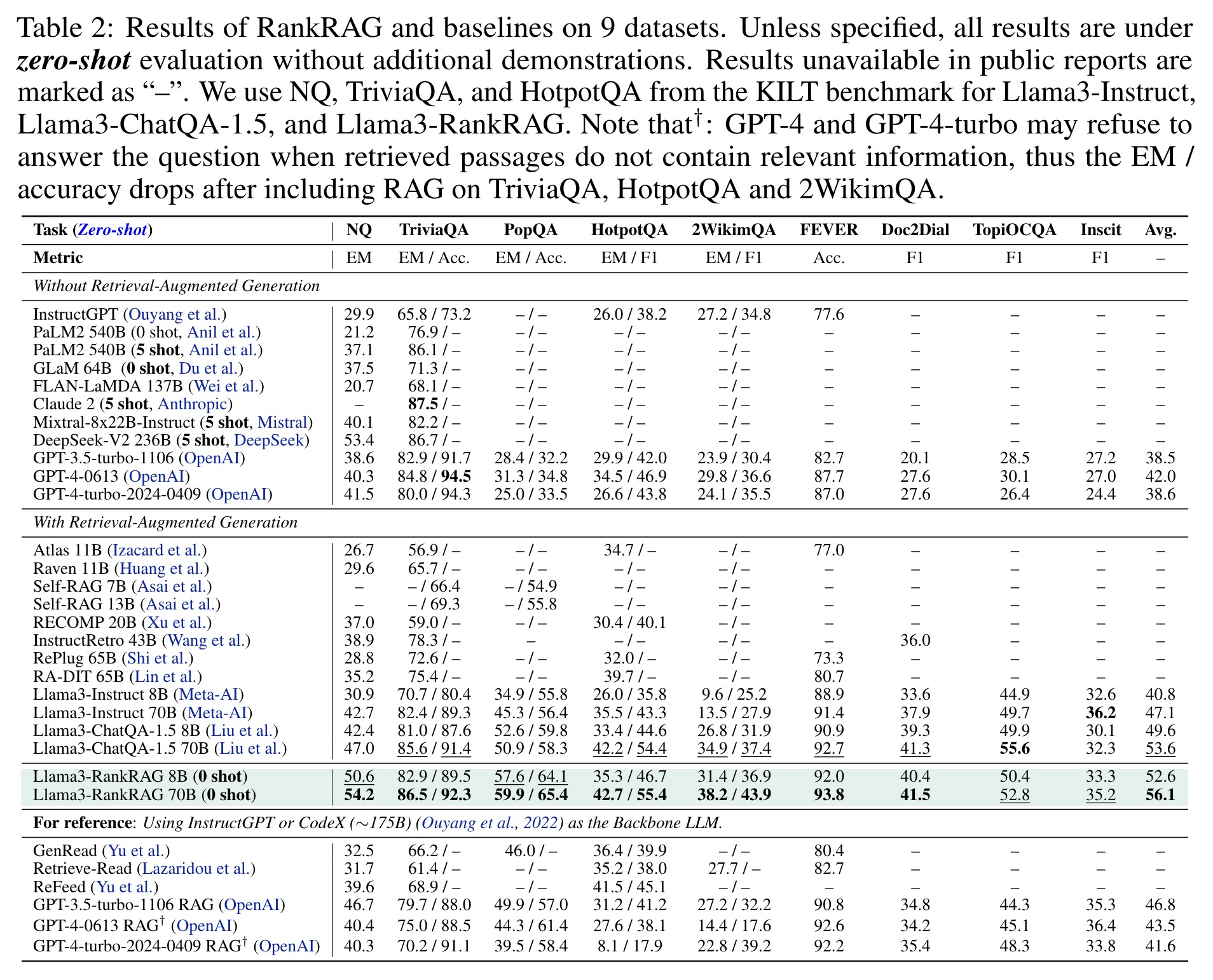
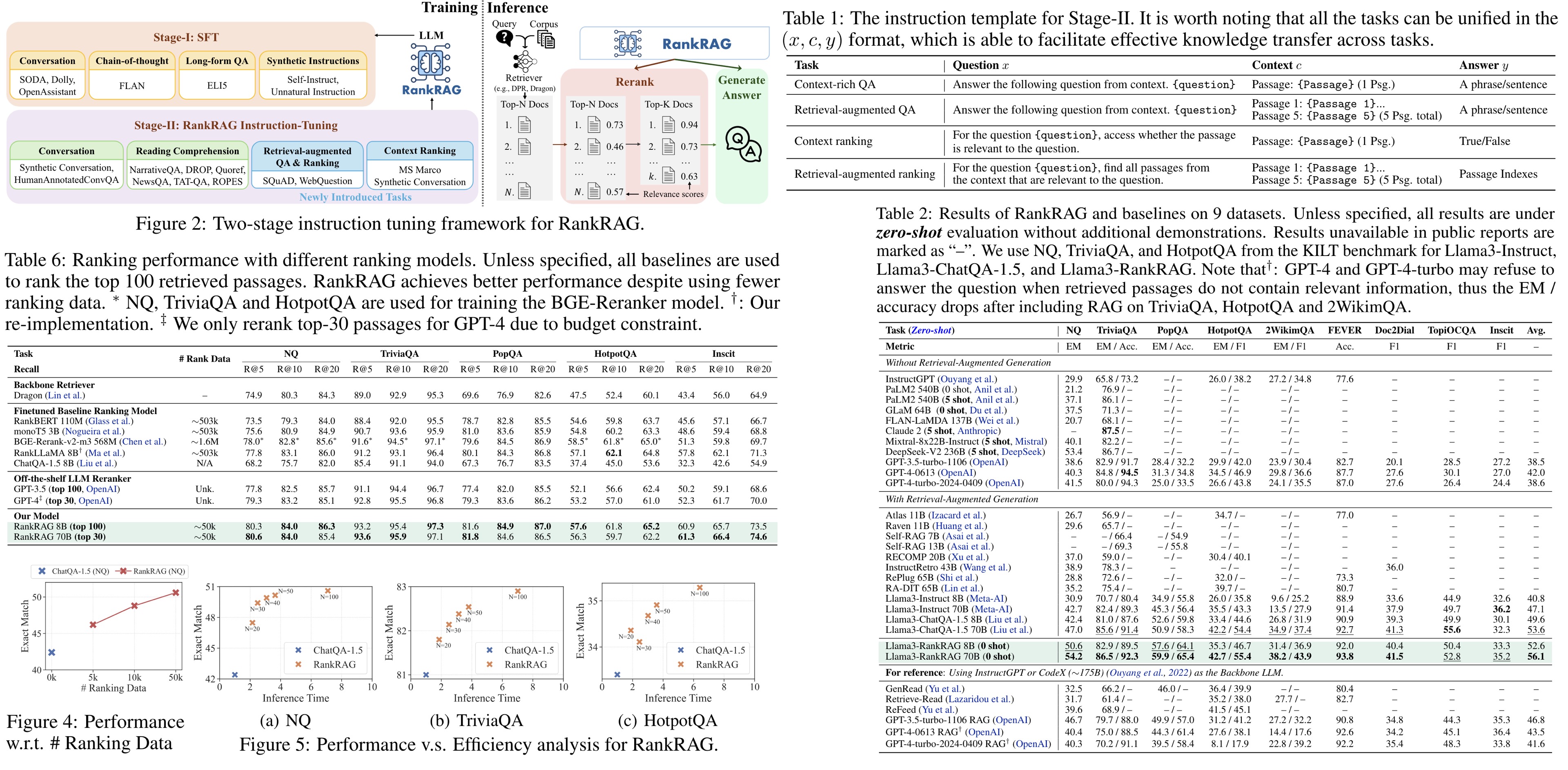
RankRAG outperforms existing RAG methods, including the state-of-the-art ChatQA-1.5 8B model. At the 8B parameter scale, RankRAG consistently exceeds the performance of ChatQA-1.5 and remains competitive against models with significantly more parameters, such as InstructRetro, RA-DIT 65B, and Llama3-instruct 70B. RankRAG 70B further outperforms ChatQA-1.5 70B and other RAG baselines using InstructGPT. The performance gains of RankRAG are particularly notable on challenging datasets, with over 10% improvement on long-tailed QA and multi-hop QA tasks, demonstrating the effectiveness of context ranking.
Ablation Studies
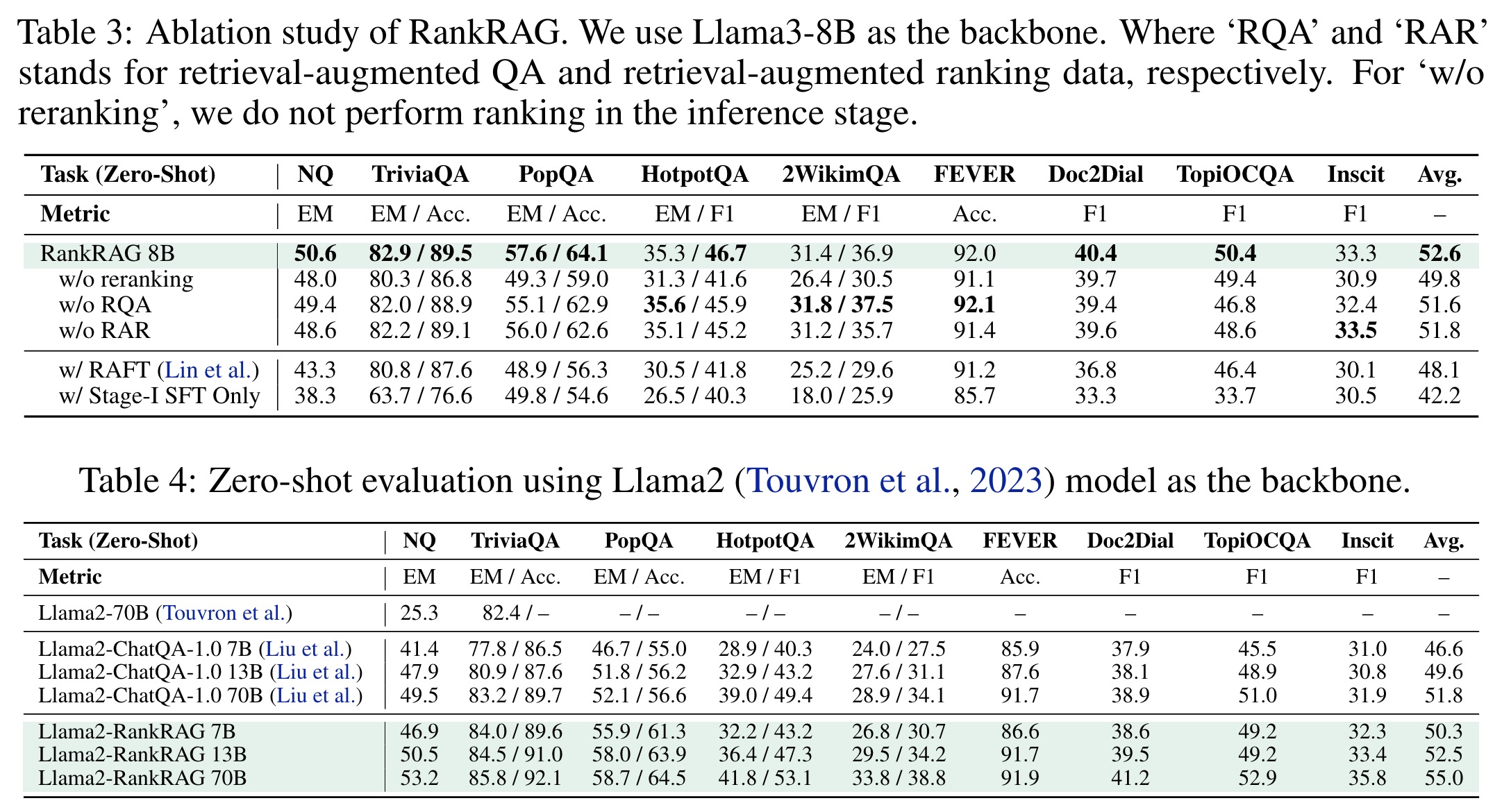
- Removing context ranking reduces performance across all tasks, highlighting its importance in selecting relevant contexts. The retrieval-augmented QA and retrieval-augmented ranking components also enhance performance by helping the model identify relevant contexts more accurately. In contrast, the RAFT method, which treats each retrieved context separately during instruction finetuning, yields suboptimal results compared to RankRAG.
- RankRAG consistently outperforms the baseline ChatQA when using Llama2 with varying parameter scales. It shows an average performance gain of 7.8% for 7B, 6.4% for 13B, and 6.3% for 70B variants, demonstrating its advantage across different LLM types and scales.
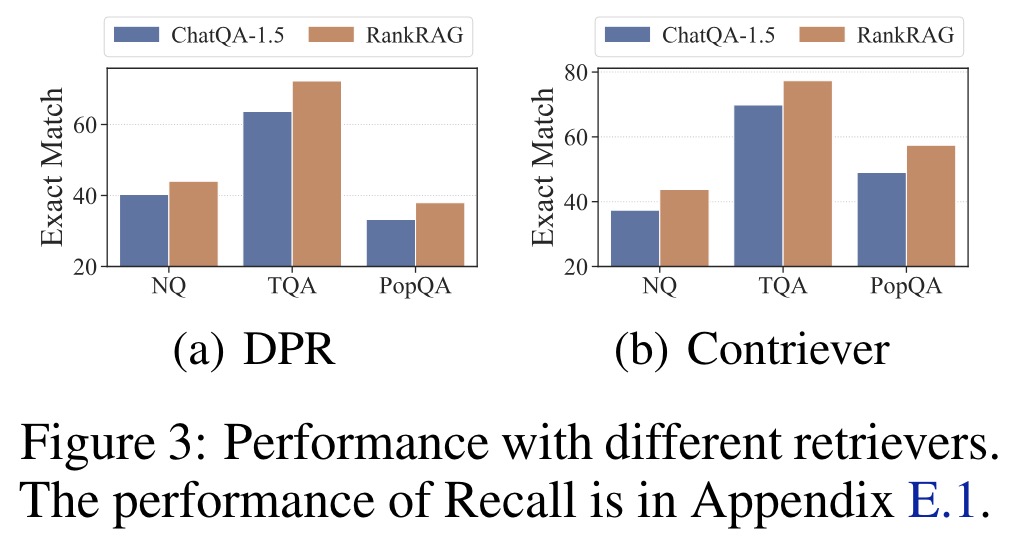
- RankRAG is robust to the choice of retrievers
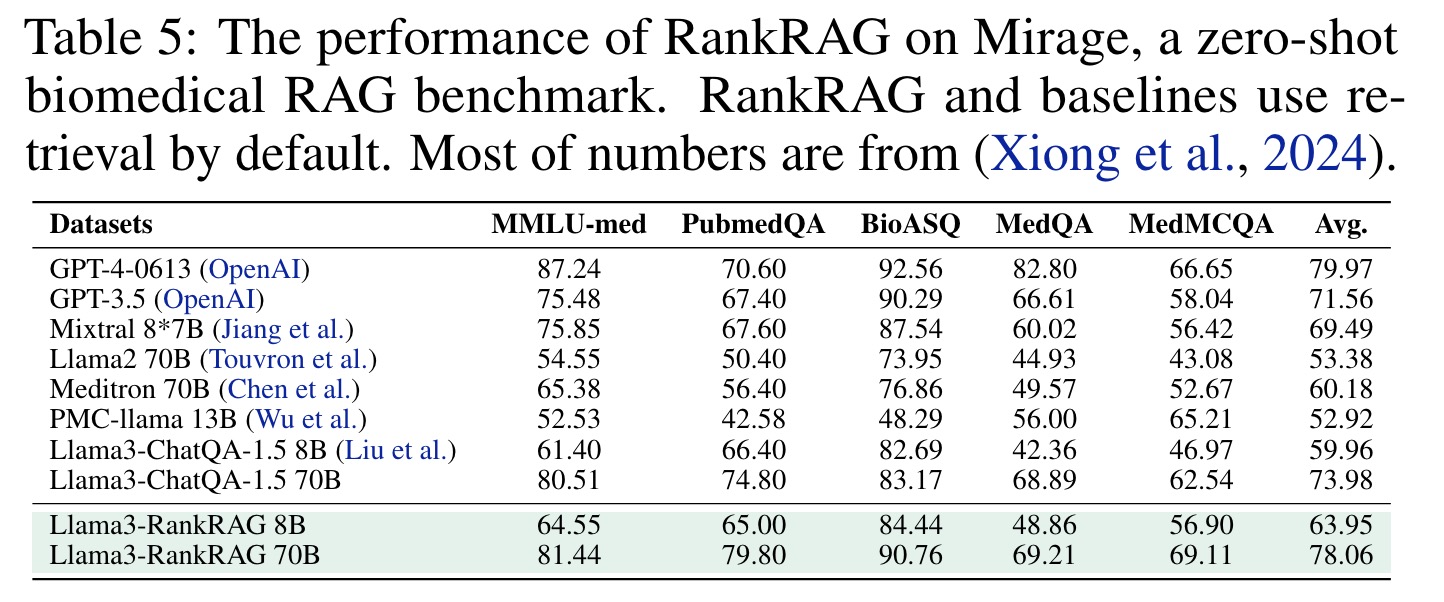
RankRAG’s adaptability to specialized domains is demonstrated through experiments on the Mirage biomedical RAG benchmark. Using MedCPT as the retriever and MedCorp3 as the corpus, RankRAG 8B outperforms the leading Meditron 70B by 6.3%, and RankRAG 70B achieves over 98% of GPT-4’s performance.
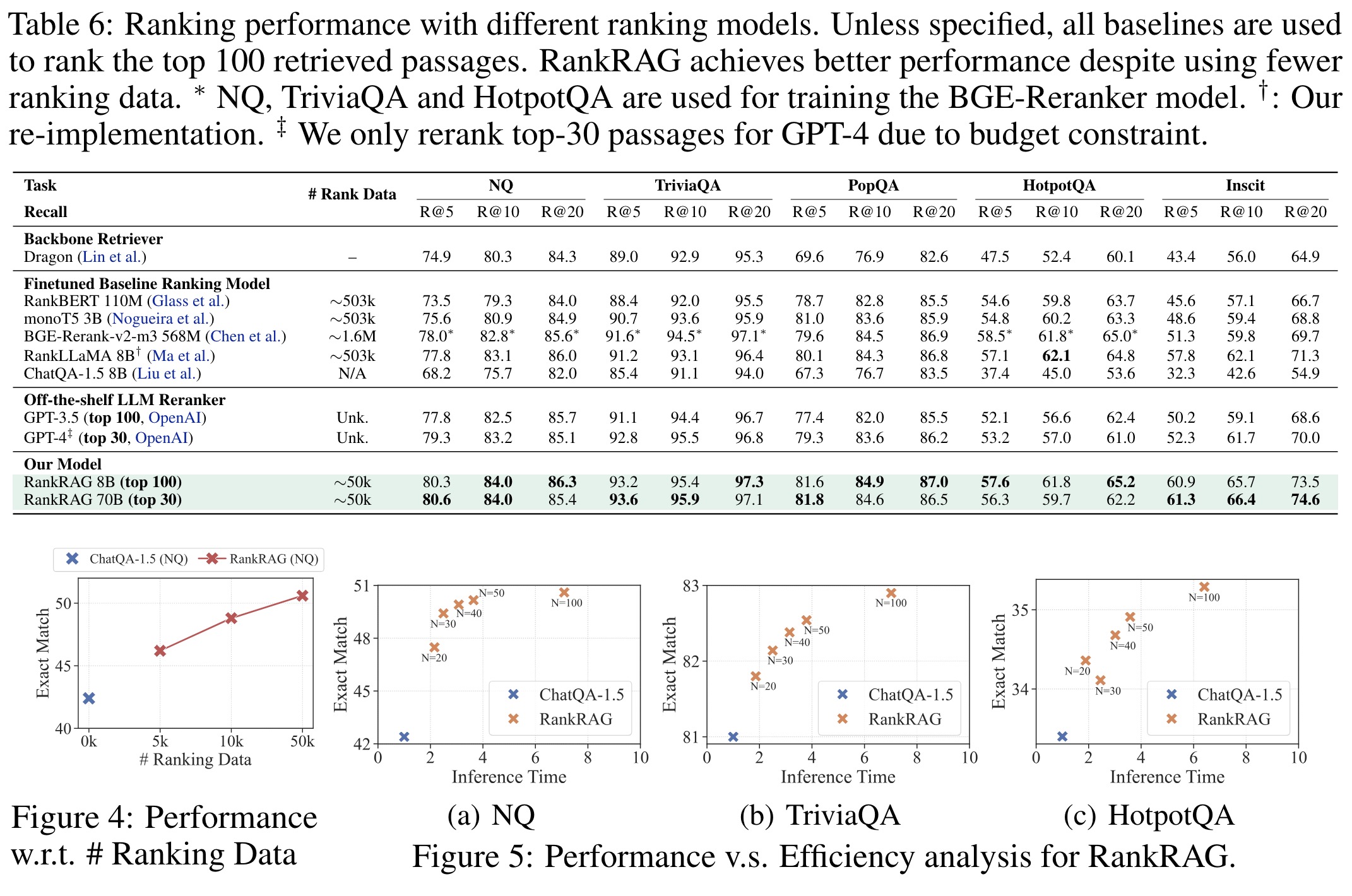
RankRAG demonstrates significant data efficiency and strong performance compared to other RAG methods that use separate reranking models. When evaluated against models fine-tuned on the full MS MARCO passage ranking dataset and a strong off-the-shelf reranker model (BGE-ranker), RankRAG achieves better recall despite using 10 times less ranking data. This success is attributed to RankRAG’s adaptable training that closely resembles general RAG fine-tuning data.
Furthermore, RankRAG achieves compelling results with just 5,000 ranking data points (about 1% of the MS MARCO dataset), with additional gains seen up to 50,000 data points, confirming its data efficiency. Regarding time efficiency, while increasing the number of contexts for reranking from 20 to 100 improves accuracy by 5.9% to 9.1% across three tasks, it only incurs a 0.9× to 6.0× increase in time, which is significantly less than the expected 20× to 100× increase.
paperreview deeplearning llm rag ranking