Paper Review: ReBotNet: Fast Real-time Video Enhancement

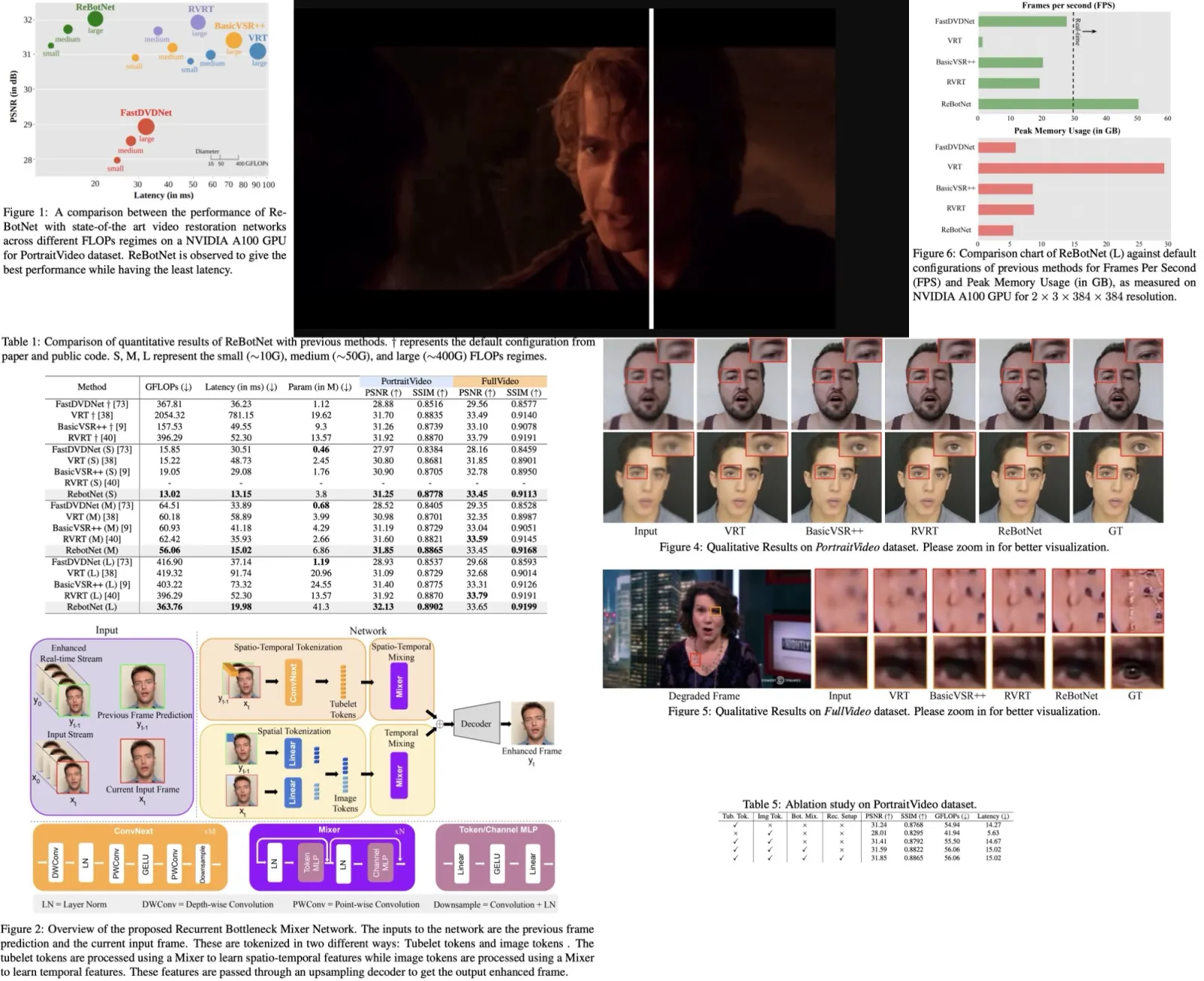
The authors present a new Recurrent Bottleneck Mixer Network (ReBotNet) method for real-time video enhancement in practical use cases like live video calls and video streams. ReBotNet uses a dual-branch framework, with one branch learning spatio-temporal features and the other focusing on improving temporal consistency. A common decoder merges the features from both branches to produce the enhanced frame. The method includes a recurrent training approach that leverages previous frame predictions for efficient enhancement and improved temporal consistency.
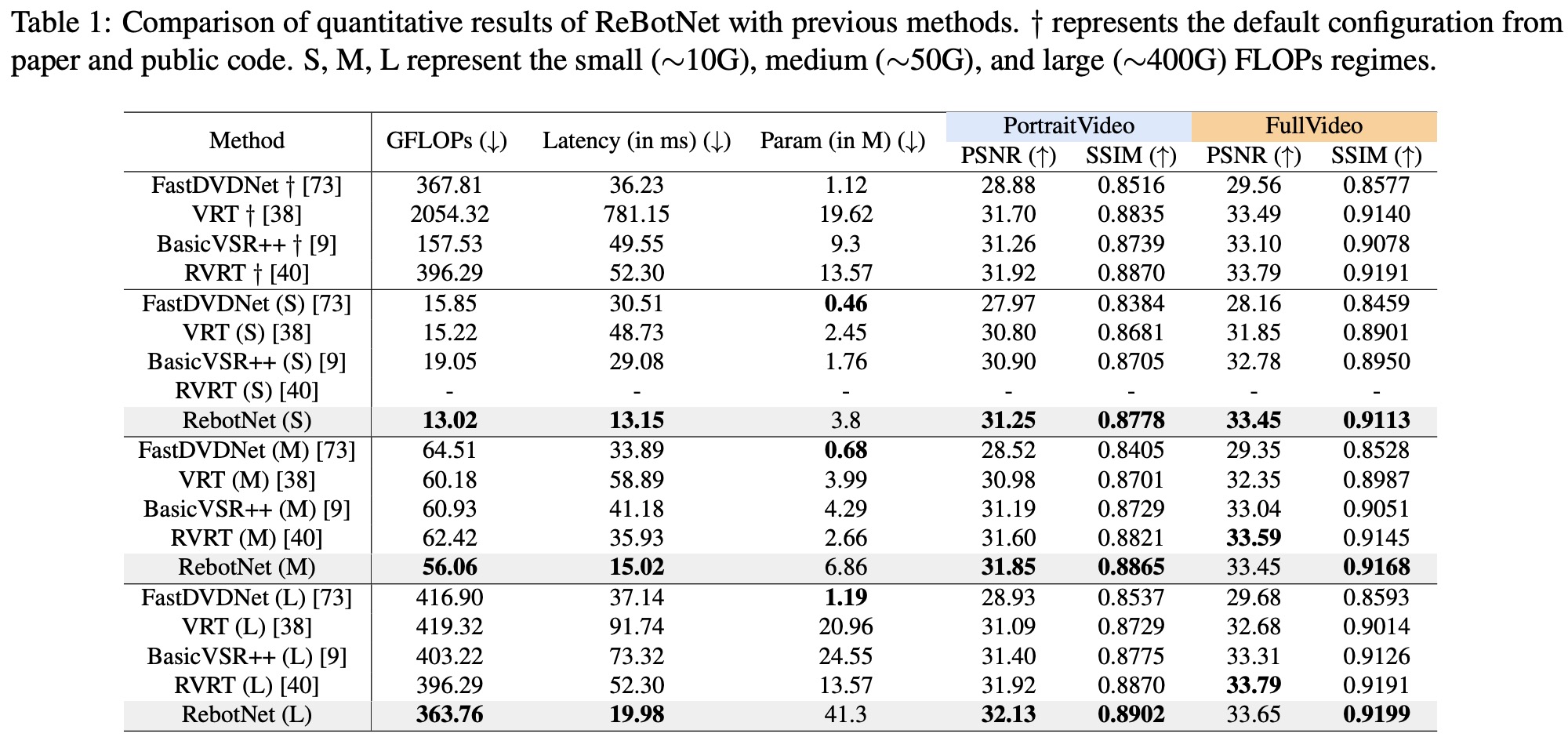
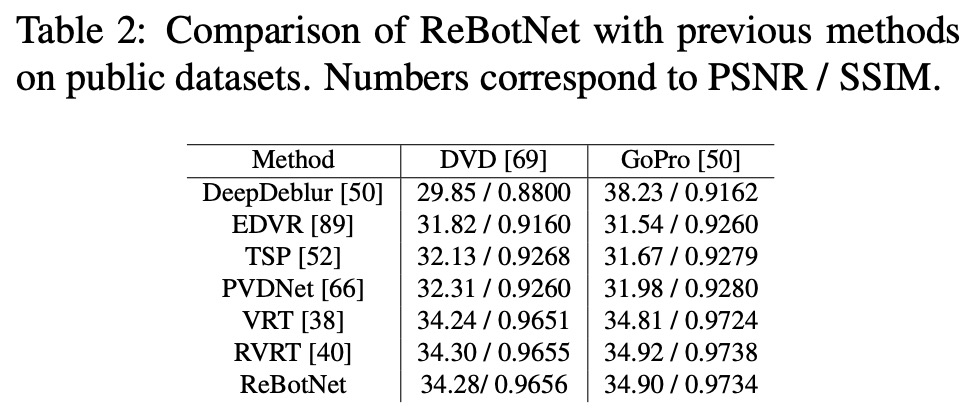
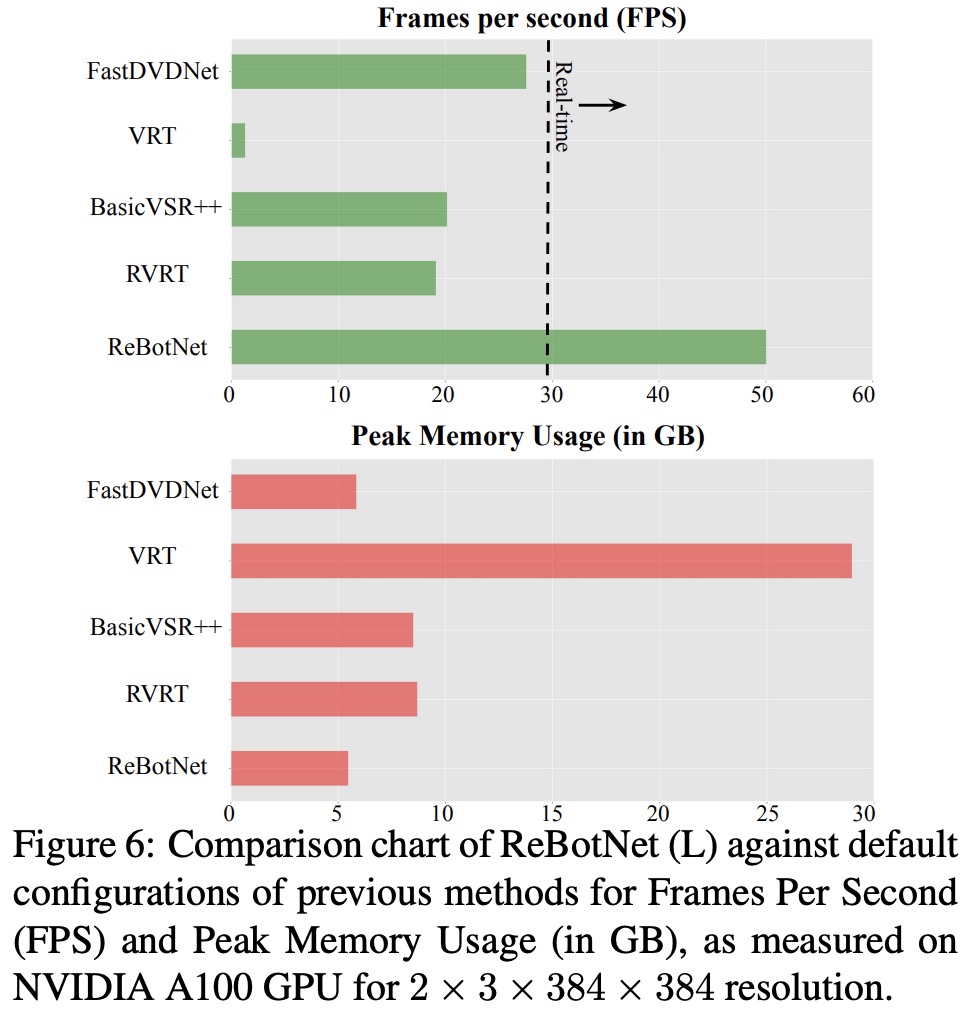
The authors evaluate ReBotNet using two new datasets that mimic real-world scenarios and demonstrate that their method outperforms existing approaches in terms of lower computations, reduced memory requirements, and faster inference time.
The approach
Recurrent Bottleneck Mixer
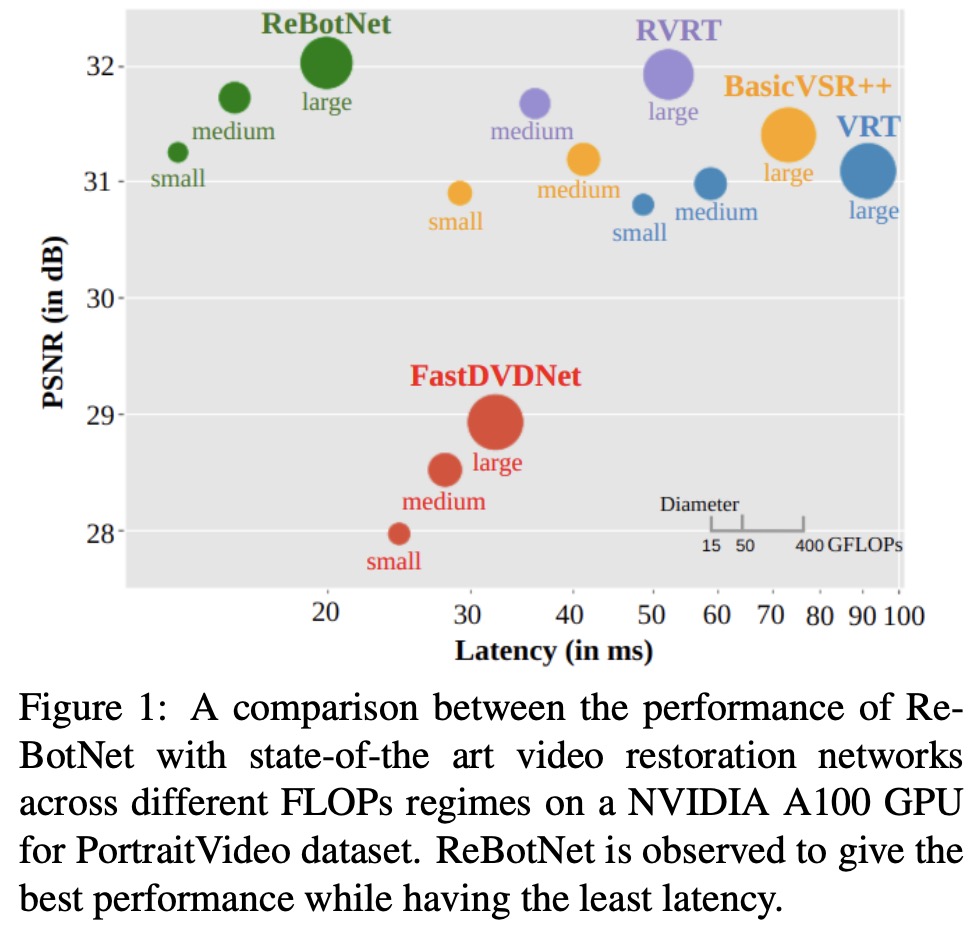
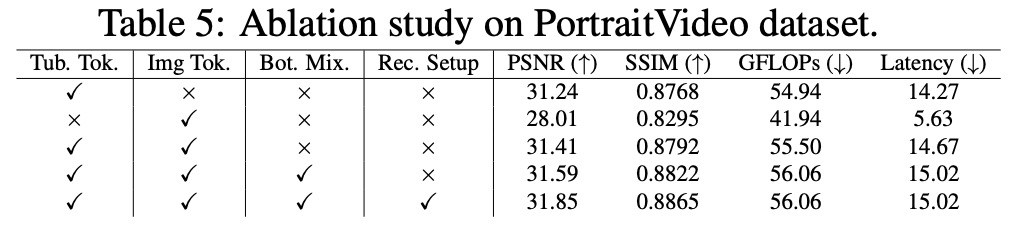
The authors discuss the limitations of current state-of-the-art video restoration methods, which use transformers and suffer from high computational costs due to the quadratic complexity of the attention mechanism. They highlight the need for a new backbone for video enhancement, which combines tubelets (spatio-temporal tokens extracted from a sequence of video frames) and image tokens in a single efficient architecture.
The proposed Recurrent Bottleneck Mixer Network (ReBotNet) addresses these issues with an encoder-decoder architecture that has two branches. The first branch focuses on spatio-temporal mixing by tokenizing input frames as tubelets and processing these features using mixers (multi-layer perceptrons). The second branch extracts only spatial features from individual frames and processes them using another mixer bottleneck block to capture temporal information.
The features from both branches are combined and forwarded to a decoder, which upsamples the feature maps to produce an enhanced image of the current frame. This design allows ReBotNet to overcome the limitations of traditional transformer-based approaches, enabling more efficient video enhancement.
Encoder and Tokenization
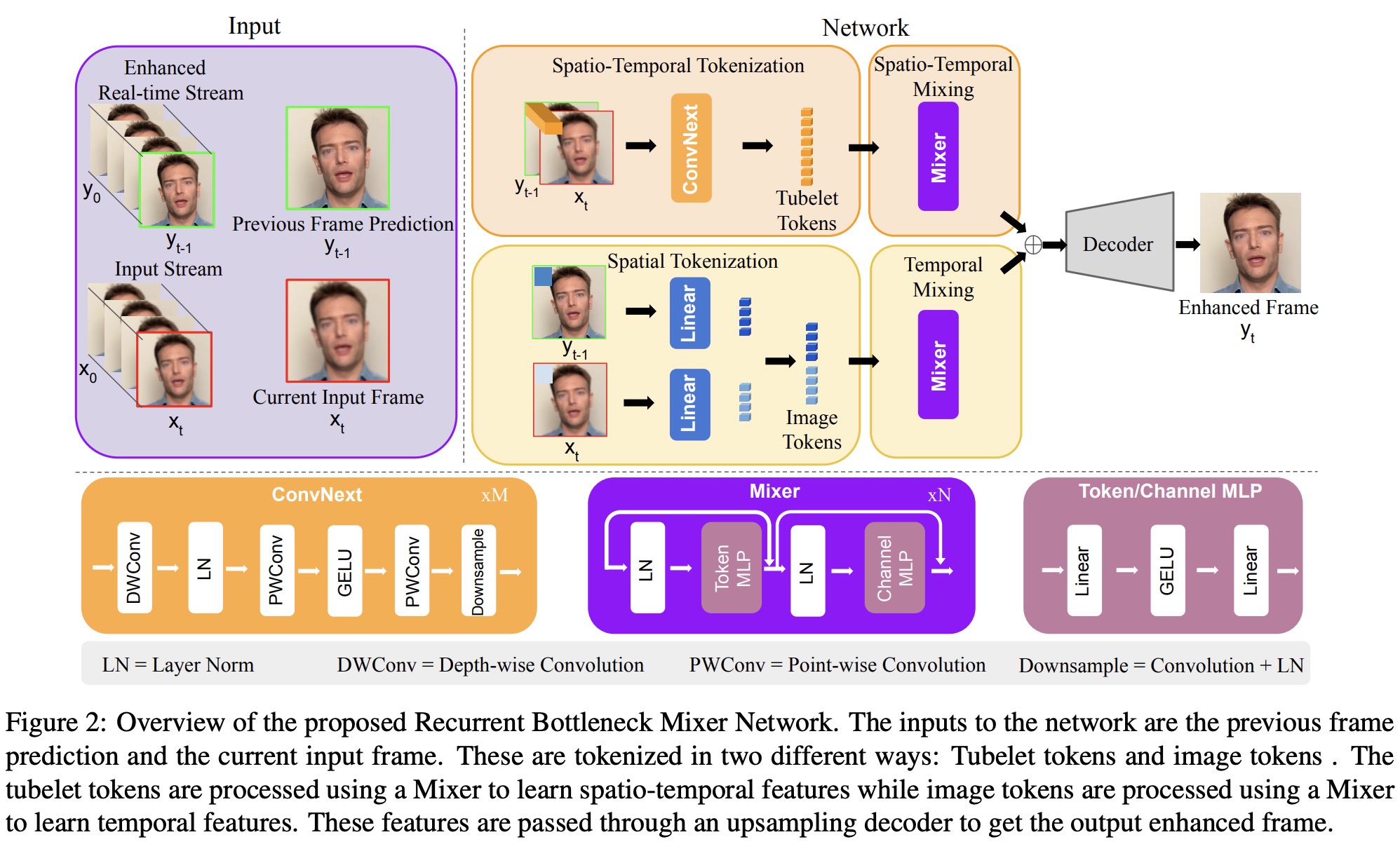
Tubelet tokens are extracted across multiple frames (the current and the previously predicted frames) to encode spatio-temporal data. ConvNext blocks are used to extract these tokens as they capture more informative features compared to linear layers. ConvNext blocks consist of a depth-wise 7x7 convolution layer, layer normalization, and point-wise convolution functions, with GeLU activation in between. In addition, there are downsampling blocks after each layer, and the tokens are further processed using a bottleneck mixer to enhance the features and encode more spatio-temporal information.
The authors aim to improve the stability of the enhanced video and obtain clearer details by learning additional temporal features with the help of image tokens. They extract individual image tokens from the frames at different time steps, tokenize the images into patches, and use linear layers like in ViT. This branch focuses on temporal consistency, while the first handles high-quality spatial features.
The mixer bottleneck in this branch learns to encode the temporal information between image tokens extracted from individual frames. To ensure tubelet tokens and image tokens have the same dimensions (N × C), max pooling is applied to the image tokens to match the dimensions of the tubelet tokens.
Bottleneck
The bottleneck of both branches in ReBotNet consists of mixer networks with the same basic design. The mixer network processes input tokens using two different multi-layer perceptrons (MLPs) for token mixing and channel mixing. Token mixing encodes the relationship between individual tokens, while channel mixing learns dependencies in the channel dimension.
The process involves normalizing the input tokens, mixing them across the token dimension, and then flipping them along the channel axis before feeding them into another MLP. The MLP block consists of two linear layers activated by GeLU, which convert the number of tokens/channels into an embedding dimension and then bring them back to their original dimension. The selection of the embedding dimension and the number of mixer blocks for the bottleneck is determined through hyperparameter tuning.
Recurrent training
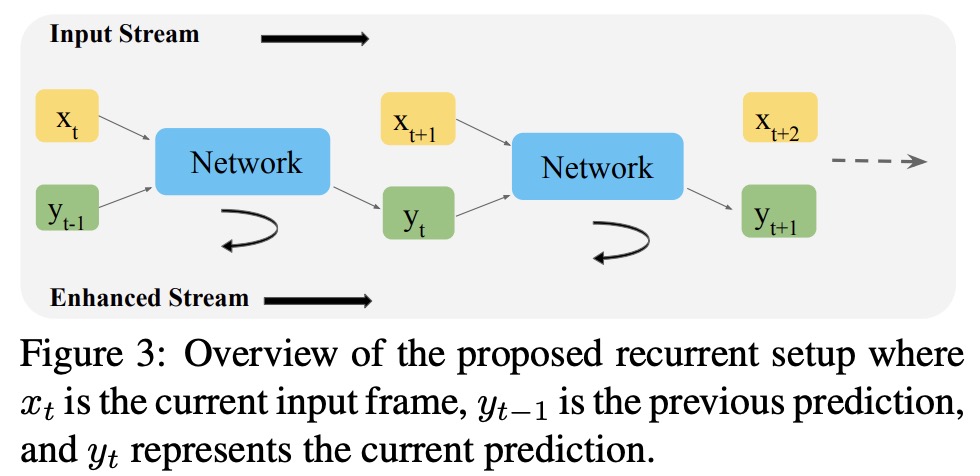
In real-time video enhancement, a recurrent setup is used to leverage information from previously enhanced frames to increase efficiency and temporal stability in predictions. Although multiple previous frames could be used, the authors choose to use only the most recent prediction for efficiency.
The original input stream (X) consists of individual frames (x), while the enhanced video stream (Y) consists of individual enhanced frames (y). To predict the enhanced frame (yt), the current degraded frame (xt) and the previous enhanced frame (yt-1) are used. During training, a single feed-forward step involves using the input values xt and yt-1 to predict yt. Multiple feed-forward steps are used sequentially to predict output values for all frames in the video.
Backpropagation is performed starting from the last frame and moving towards the first frame. For the corner case of predicting the first frame (y0), the ground truth frame is used as the initial prediction to start the training.
Experiments
The authors note that existing video enhancement datasets focus on single degradation types and may not represent real-world scenarios, such as video conferencing. To address this, they curate two new datasets for video enhancement: PortraitVideo and FullVideo.
PortraitVideo is built on top of the TalkingHeads dataset, which consists of YouTube videos with cropped face regions. The authors curate 113 face videos for training and 20 for testing, with a fixed resolution of 384x384. The videos are processed at 30 FPS with 150 frames per video and have a mixture of degradations such as blur, compression artifacts, noise, and small distortions in brightness, contrast, hue, and saturation.
FullVideo is developed using high-quality YouTube videos, with 132 training videos and 20 testing videos. These videos have a resolution of 720x1280, run at 30 FPS, and are 128 frames long. The dataset applies similar degradations as PortraitVideo but captures more context, including the speaker’s body and the rest of the scene.
The authors use NVIDIA A100 GPU cluster (8 cards). ReBotNet is trained with a learning rate of 4e −4 using Adam optimizer, and a cosine annealing learning rate scheduler with a minimum learning rate of 1e−7. The model is trained for 500,000 iterations.