Paper Review: RecMind: Large Language Model Powered Agent For Recommendation

Recent advancements have enabled Large Language Models (LLMs) to use external tools and execute multi-step plans, enhancing their performance in various tasks. However, their proficiency in handling personalized queries, such as recommendations, hasn’t been deeply studied. To address this, an LLM-based recommender system named RecMind has been developed.
RecMind offers personalized recommendations by planning, accessing external information, and using individual data. A novel algorithm Self-Inspiring is introduced, enabling the LLM to refer to prior planning stages for better decision-making. When tested in various recommendation scenarios, RecMind surpassed other LLM-based methods and showed comparable performance to a model called P5, which is explicitly pre-trained for recommendation tasks.
Architecture

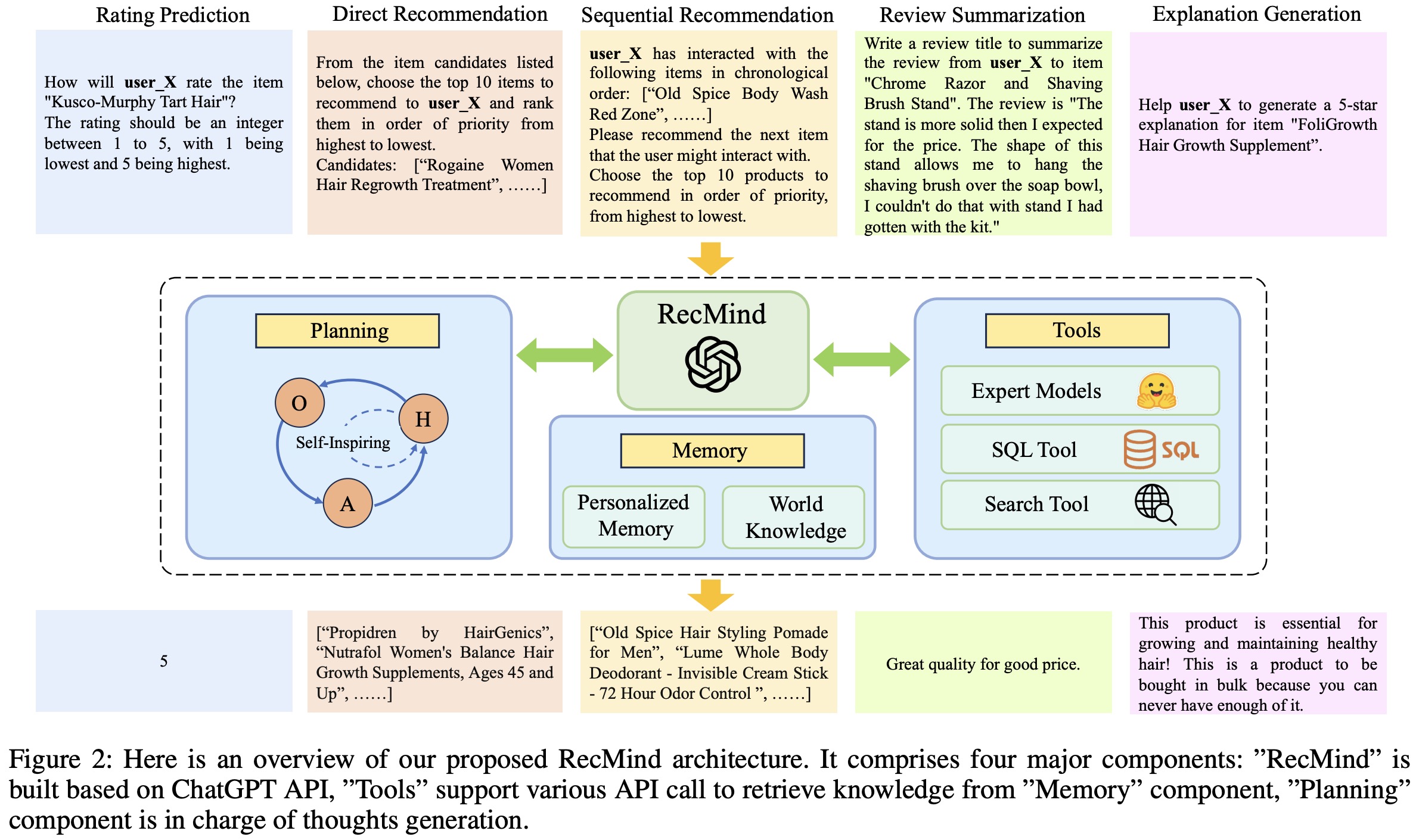

RecMind system has the following key components: an LLM-powered API (ChatGPT) for reasoning, a planning mechanism to break tasks into sub-tasks, memory for retaining and recalling information over time, and tools for supplementing the model’s knowledge.
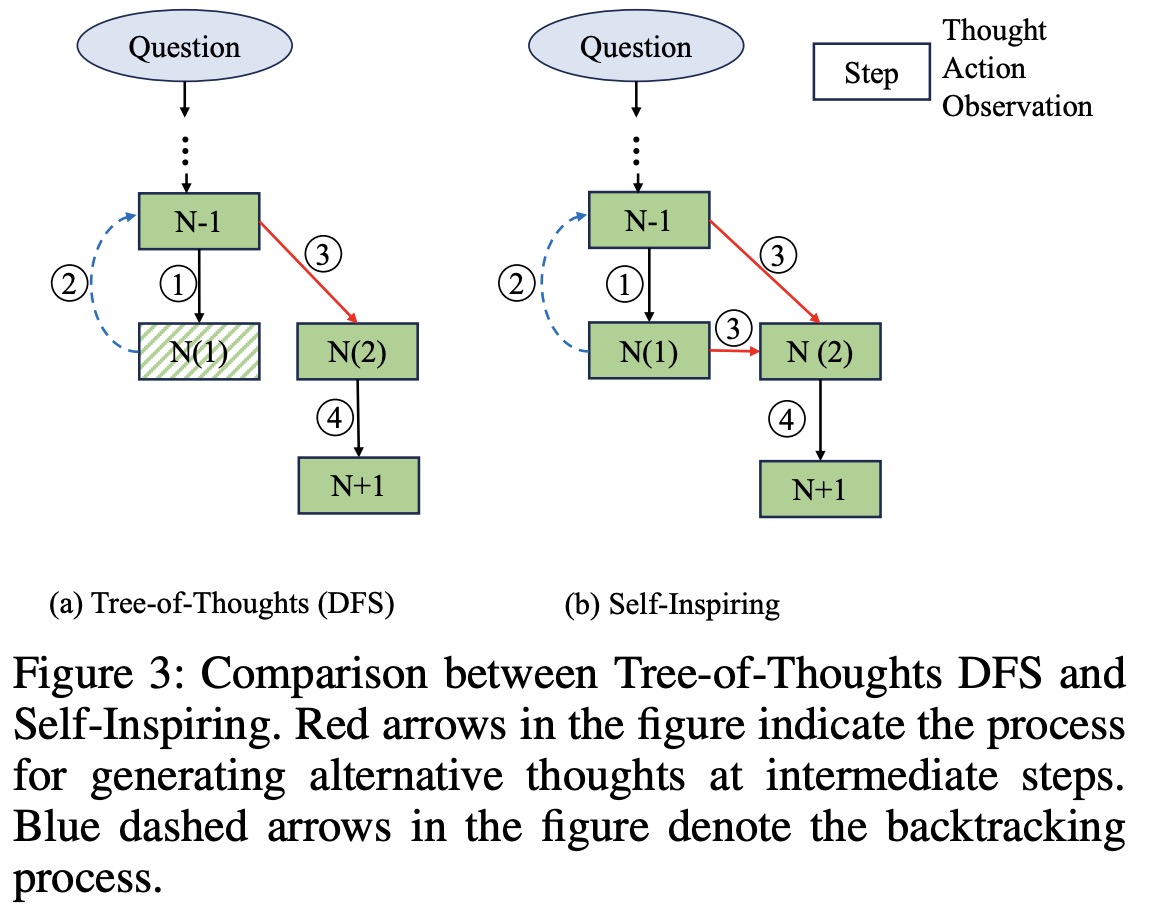
In planning, RecMind decomposes a given problem into sub-problems using a series of prompts that include thoughts, actions, and observations. Chain-of-Thoughts and Tree-of-Thoughts are discussed as potential planning approaches. CoT follows a single path in a reasoning tree, while ToT can explore multiple paths. However, both of these approaches don’t fully utilize previously discarded information from other branches of the reasoning tree.
To address this, a new planning method called Self-Inspiring is introduced. Unlike CoT and ToT, SI retains all previously explored states to inform future planning steps. This allows RecMind to make better-informed decisions by considering alternative reasoning paths. SI helps to offer more precise recommendations by taking into account a more comprehensive set of information.
Memory is divided into Personalized Memory and World Knowledge. Personalized Memory stores individual user data, such as their reviews or ratings for specific items. World Knowledge has two parts: the first is item metadata, which is domain-specific information, and the second is real-time information accessed via Web search tools. For example, information about the product “Sewak Al-Falah” was retrieved from World Knowledge using a Web search tool, aiding in the reasoning path and influencing the final prediction.
RecMind has three specialized tools to enhance its capabilities:
- Database Tool converts natural language questions into SQL queries to access specific information from memory, like user reviews or item metadata. For example, it can fetch the average rating of a specific product. The retrieved data is then converted back into a natural language answer by an LLM.
- Search Tool uses a search engine, like Google, to access real-time information that might not be available in the database. For instance, it can determine the product category of a specific item by prompting a search engine to find this information.
- Text Summarization Tool uses a text summarization model from the Hugging Face Hub to condense lengthy texts. It can summarize multiple reviews of a product into a short description, like “Most customers think this product is durable and has a good price.”
Experiments
gpt-3.5-turbo-16k is the core LLM in RecMind.
Experimental Results on Precision-oriented Recommendation Tasks:
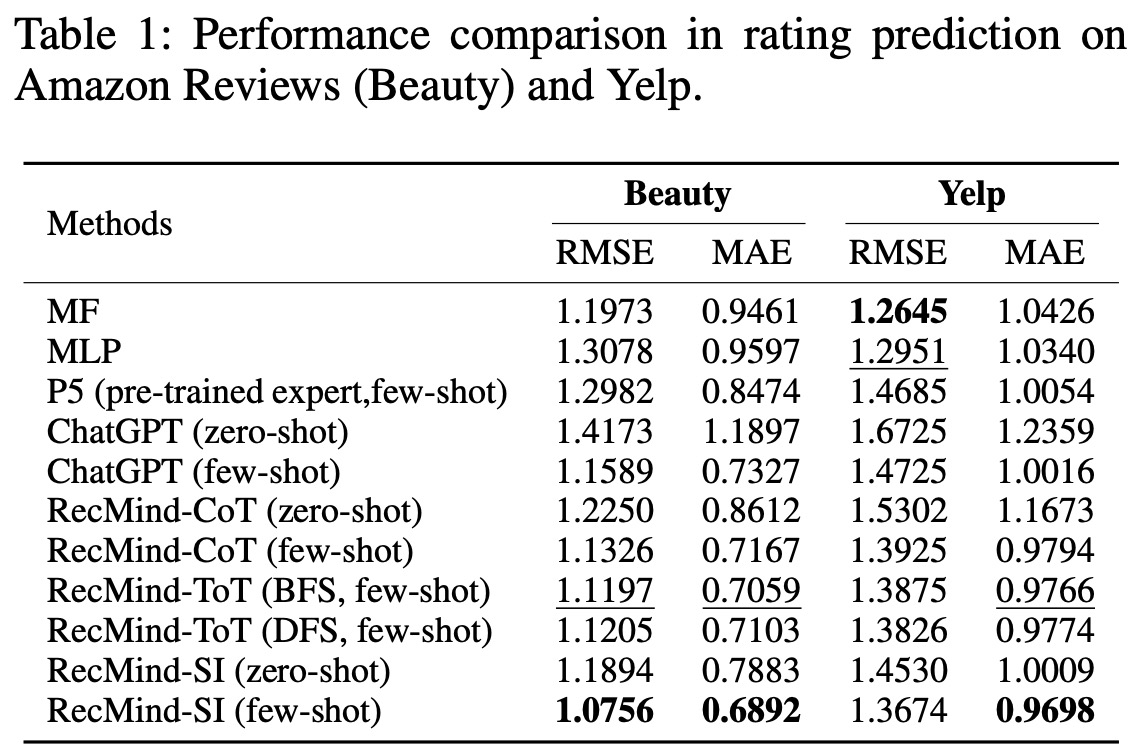
- Rating Prediction: RecMind outperformed traditional models like MF and MLP. RecMind excels because it accesses both the user’s rating history and the item’s rating history, reducing the risk of over-fitting seen in other models like MLP and P5.
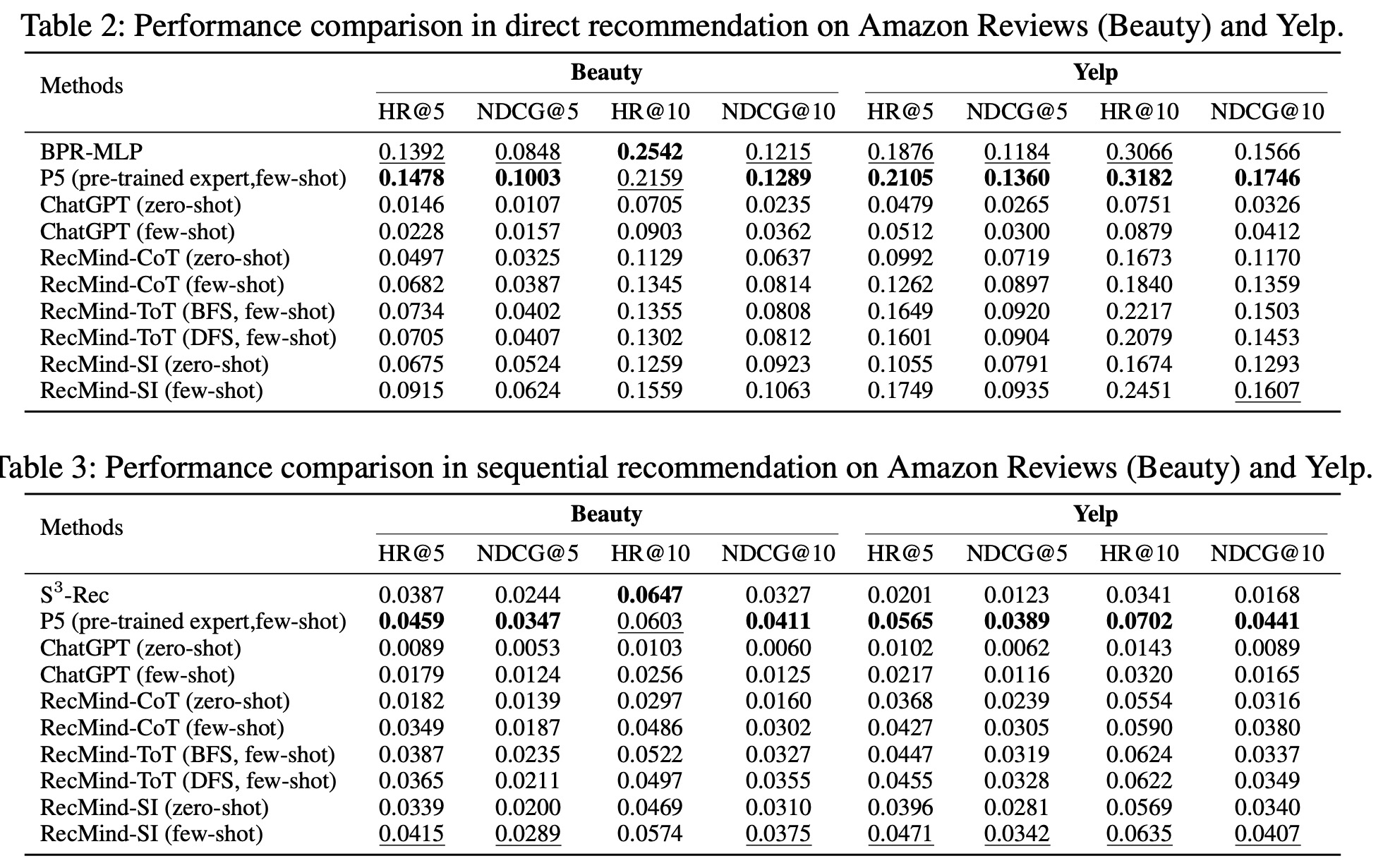
- Direct Recommendation: In this task, RecMind was outperformed by fully-trained models like P5. The main issue was a positional bias, where the system tended to focus on the first few items in a list of candidates. However, RecMind’s diverse reasoning planning methods, like the Tree-of-Thoughts and Self-Inspiring, were shown to mitigate this bias to some extent.
- Sequential Recommendation: RecMind’s performance was comparable to fully-trained models like P5 and S3-Rec. Without the use of advanced planning methods, LLMs generally prefer items that are semantically similar to the items previously interacted with by the user. However, RecMind’s explicit reasoning and access to domain knowledge enable it to explore more relevant options, thereby improving its recommendation quality.
Experimental Results on Explainability-oriented Recommendation Tasks:
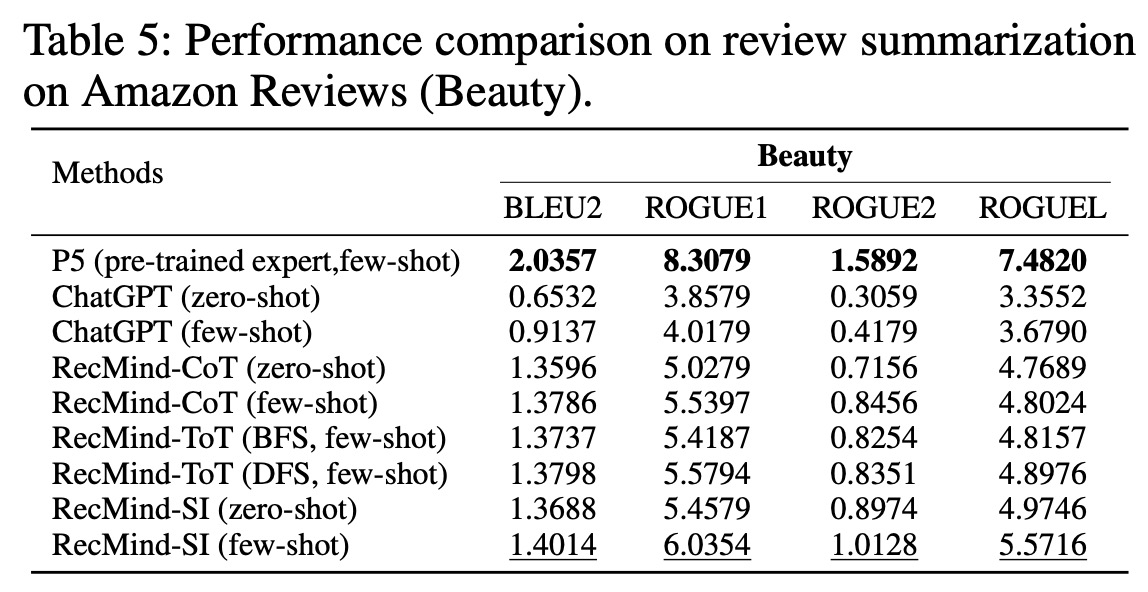
- Review Summarization: RecMind was found to perform better than general language models like ChatGPT in summarizing review comments into shorter titles. However, it did not outperform P5, a fully trained model optimized specifically for the review summarization task.
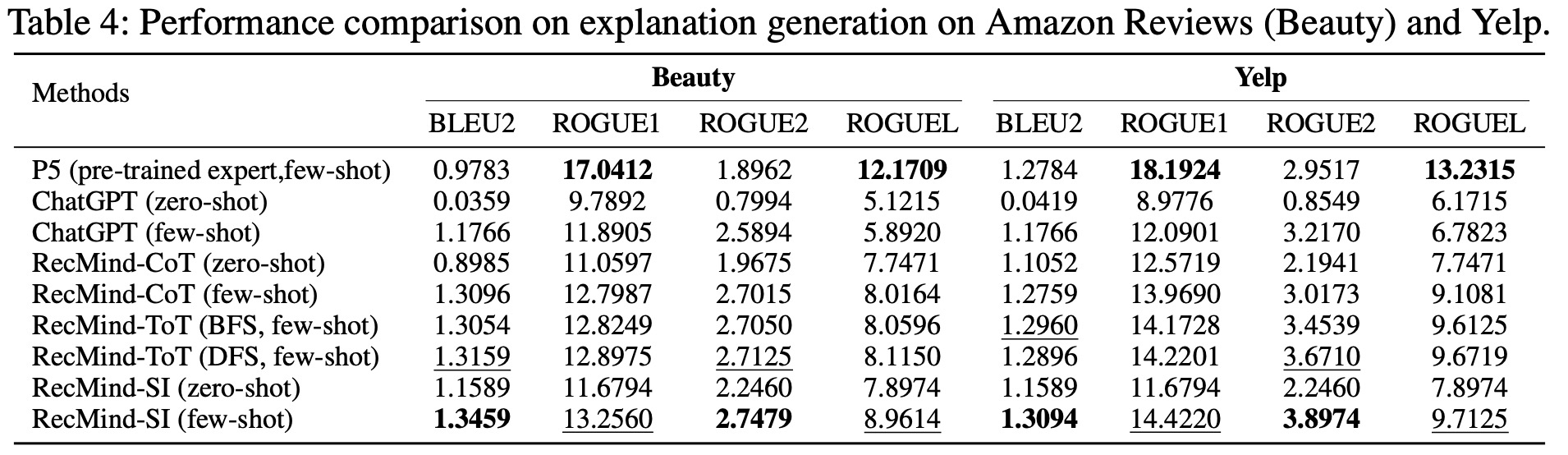
- Explanation Generation: RecMind excelled in creating textual explanations to justify a user’s interaction with a particular item. When using self-inspiring techniques, it achieved performance comparable to the fully trained P5 model. This was aided by leveraging in-domain knowledge from personalized memory, such as other users’ reviews of the same item.
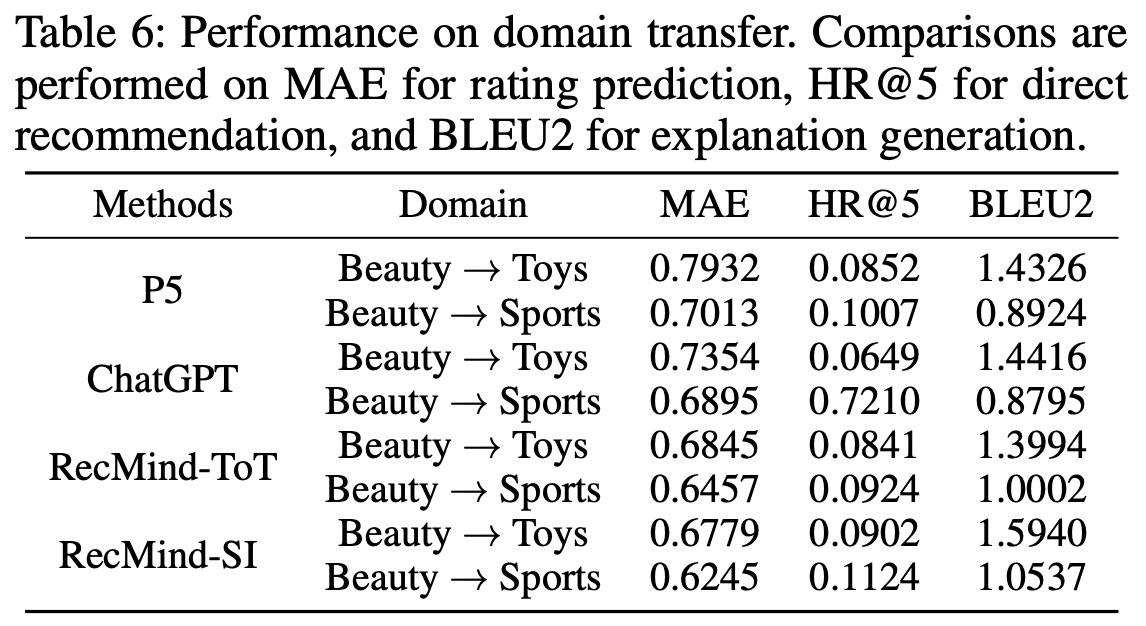
Transfer to Items in Unseen Domains:
- Using few-shot examples from the Beauty domain, RecMind was then evaluated on the Toys and Sports domain. The results showed that RecMind outperformed baseline models like ChatGPT and P5 in domain transfer capabilities, with P5 tending to overfit to its training domain.
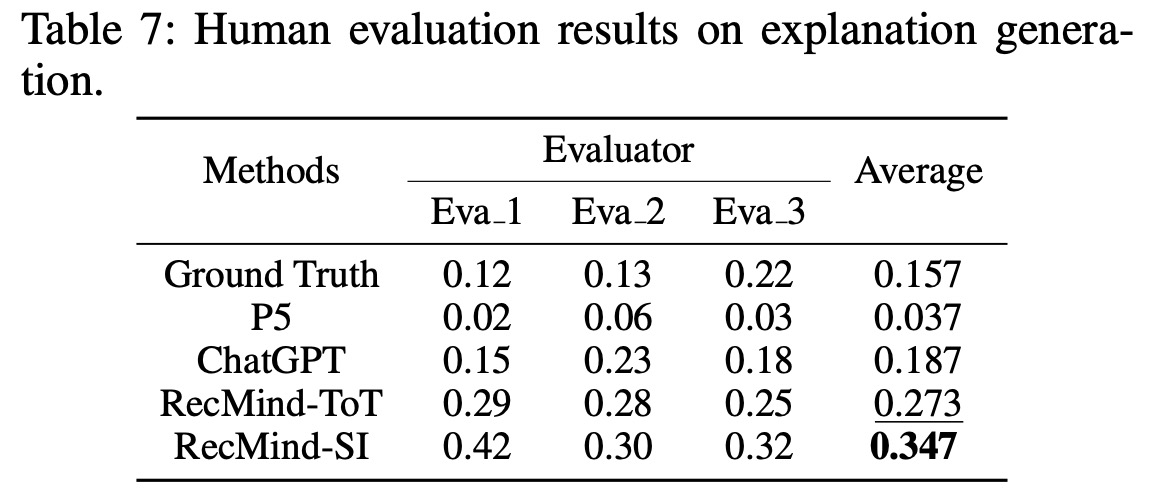
Human Evaluation:
- Human evaluators were used to assess the quality and rationality of explanations generated by RecMind and other baseline models like P5 and ChatGPT. Evaluators ranked the explanations based on 100 test samples. The “top-1 ratio” was used to measure how often a model’s explanation ranked first among the options. Results showed that the few-shot RecMind with self-inspiring techniques consistently yielded the most satisfactory results.