Paper Review: Revisiting ResNets: Improved Training and Scaling Strategies
Code and checkpoints are available in TensorFlow: https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
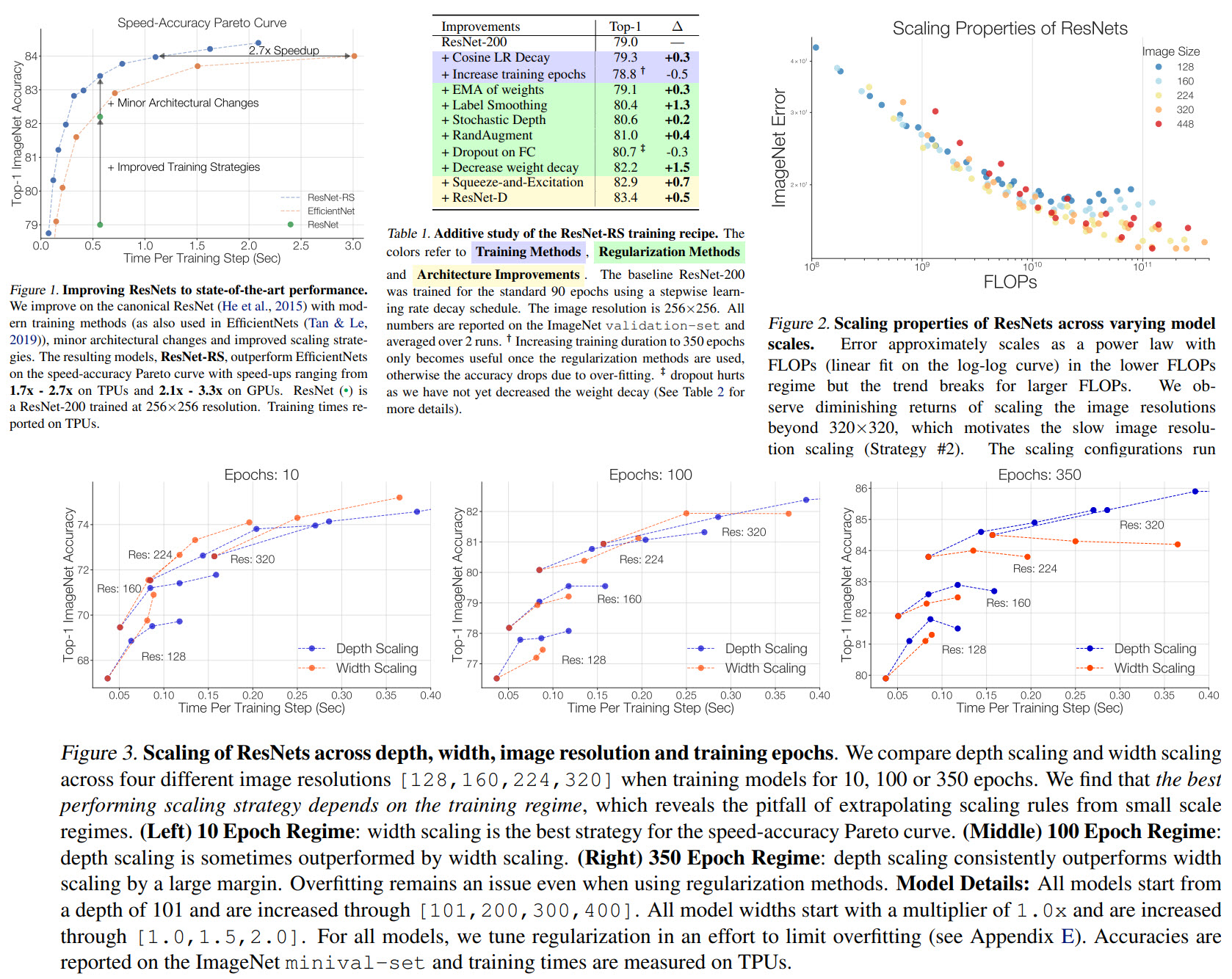
A fascinating paper from Google Brain and UC Berkeley about improving the architecture and training of ResNets. Does it seem we have a rival to EfficientNets now?
The authors of the paper have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x - 3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
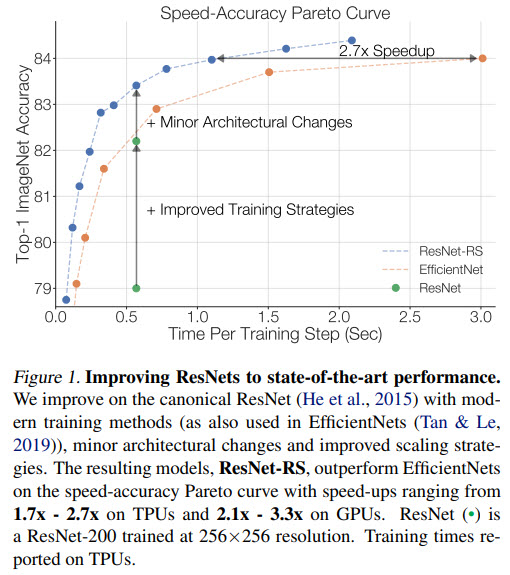
Some of the key ideas:
- If you are using other regularization techniques together with weight decay, it is better to decrease its value;
- The techniques that work on small models or a small number of epochs don’t necessarily work for bigger models and a higher number of epochs; thus, it is necessary to select scaling strategies doing the full training with the full model. I think this is a crucial point!;
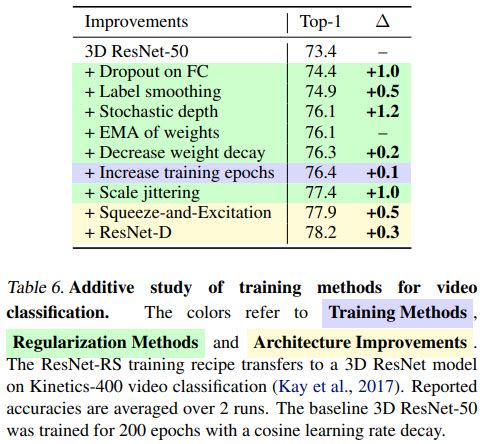
- Their improved training and scaling strategies also work for other models: for EfficientNets, for self-supervised learning, even for 3D video classification;
Characterizing Improvements on ImageNet
The authors name four broad types of possible model performance improvements: architecture, training/regularization methodology, scaling strategy, and additional training data.
Architecture. Well, this is architecture optimization: new blocks, attention, lambda layers, and NAS in general.
Training and Regularization Methods. Dropout, label smoothing, stochastic depth, dropblock, data augmentation; learning rate schedules also helped.
Scaling Strategies. Improving model width, depth, and resolution.
Additional Training Data. Obviously helps.
Methodology
Here the authors describe the methods and architectures, which they use.
- ResNet, ResNet-D, using SE-blocks;
- Matching the EfficientNet Setup with small changes: 350 epochs, cosine learning scheduler, RandAugment, Momentum optimizer. Most of the changes are for simplicity;
- weight decay, label smoothing, dropout, and stochastic depth for regularization;
- RandAugment applies a sequence of random image transformations (e.g. translate, shear, color distortions);
- For hyperparameter tuning, they use a hold-out validation of 2% of ImageNet;
Improved Training Methods
A detailed study of improvements
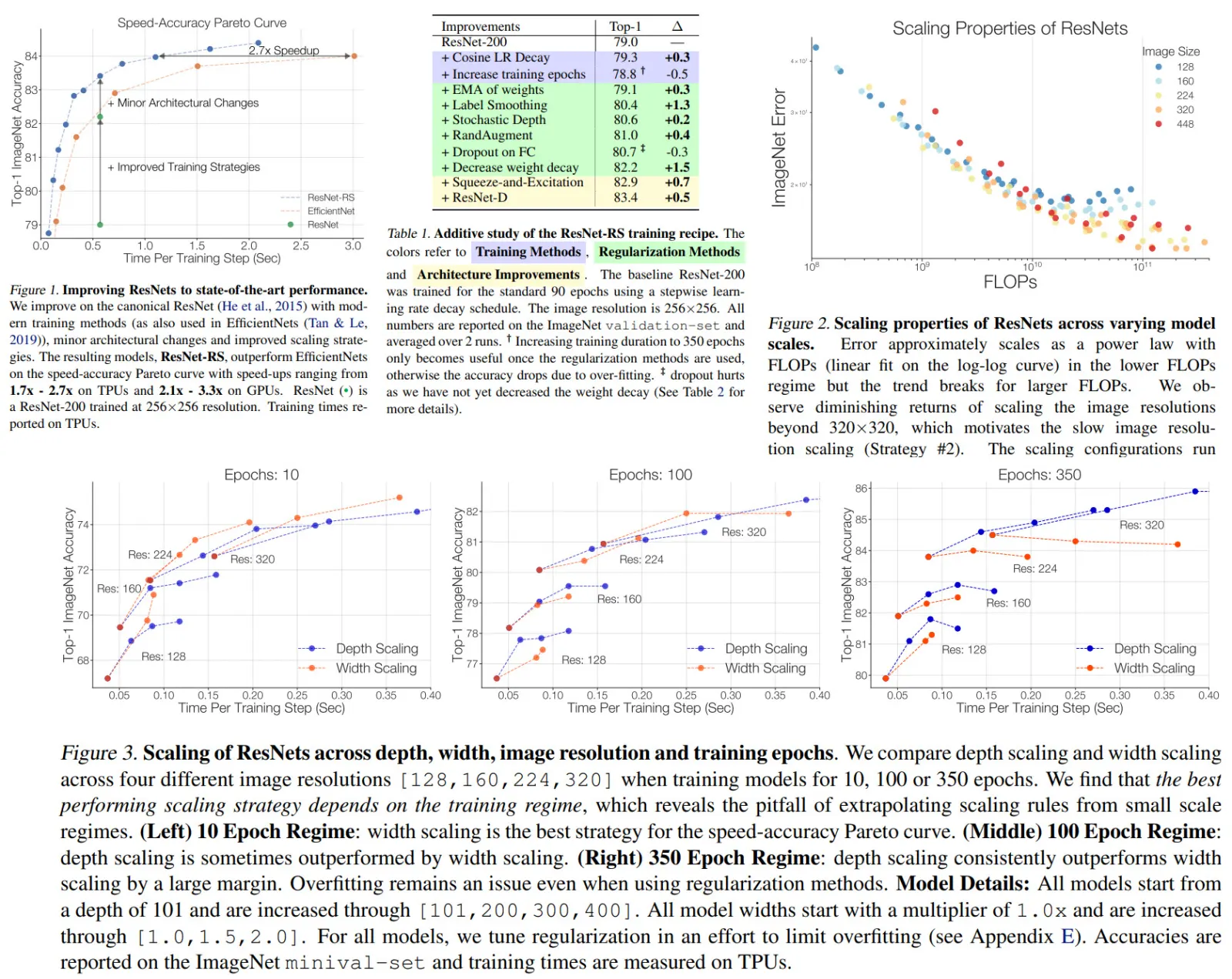
ResNet-200 gets 79.0% by itself, improved training methods give +3.2%, architecture changes give +1.2% more. This proves that improving the training alone already gives a huge boost.
Importance of decreasing weight decay when combining regularization methods
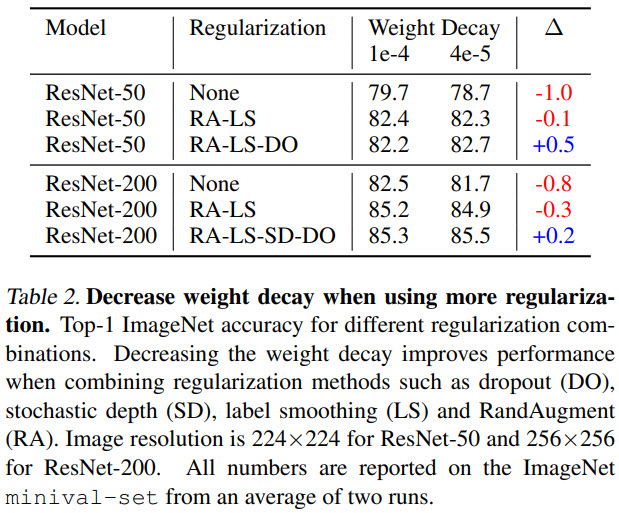
We can see that if we don’t change weight decay, adding other regularization methods may decrease the performance. On the other hand, if we lower the weight decay, adding other regularization methods improves the score.
Improved Scaling Strategies
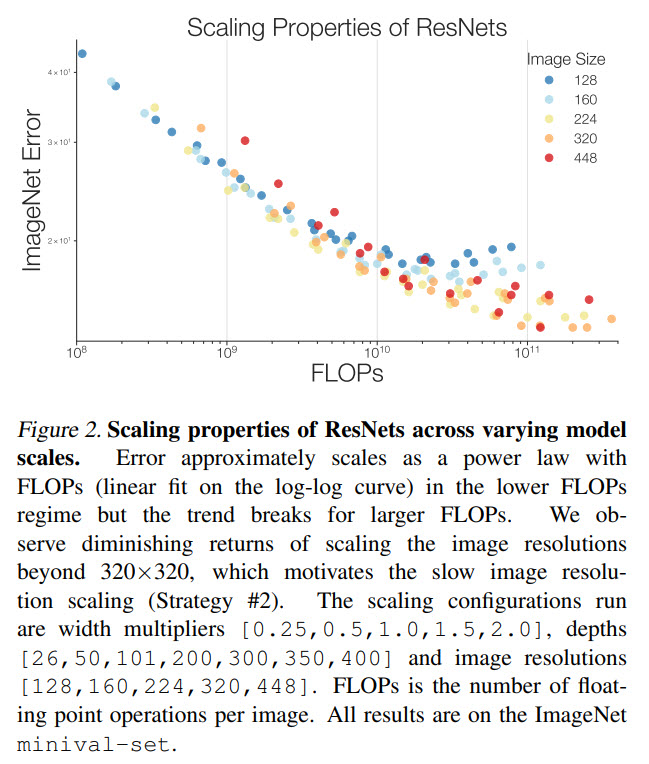
The authors perform an extensive search on ImageNet over width multipliers in [0.25,0.5,1.0,1.5,2.0], depths of [26,50,101,200,300,350,400] and resolutions of [128,160,224,320,448]. Training is done for 350 epochs, regularization is increased for bigger models to avoid overfitting.
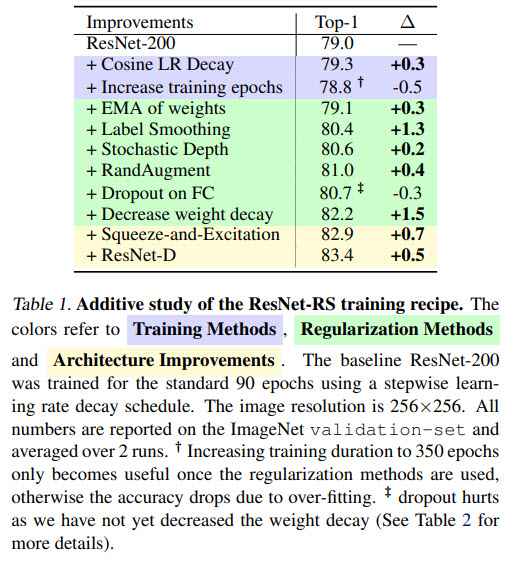
A significant result: FLOPs do not accurately predict performance in the bounded data regime. We can see that the difference in specific parameters can mean a noticeable difference in model performance for bigger models, even for the same FLOPS.
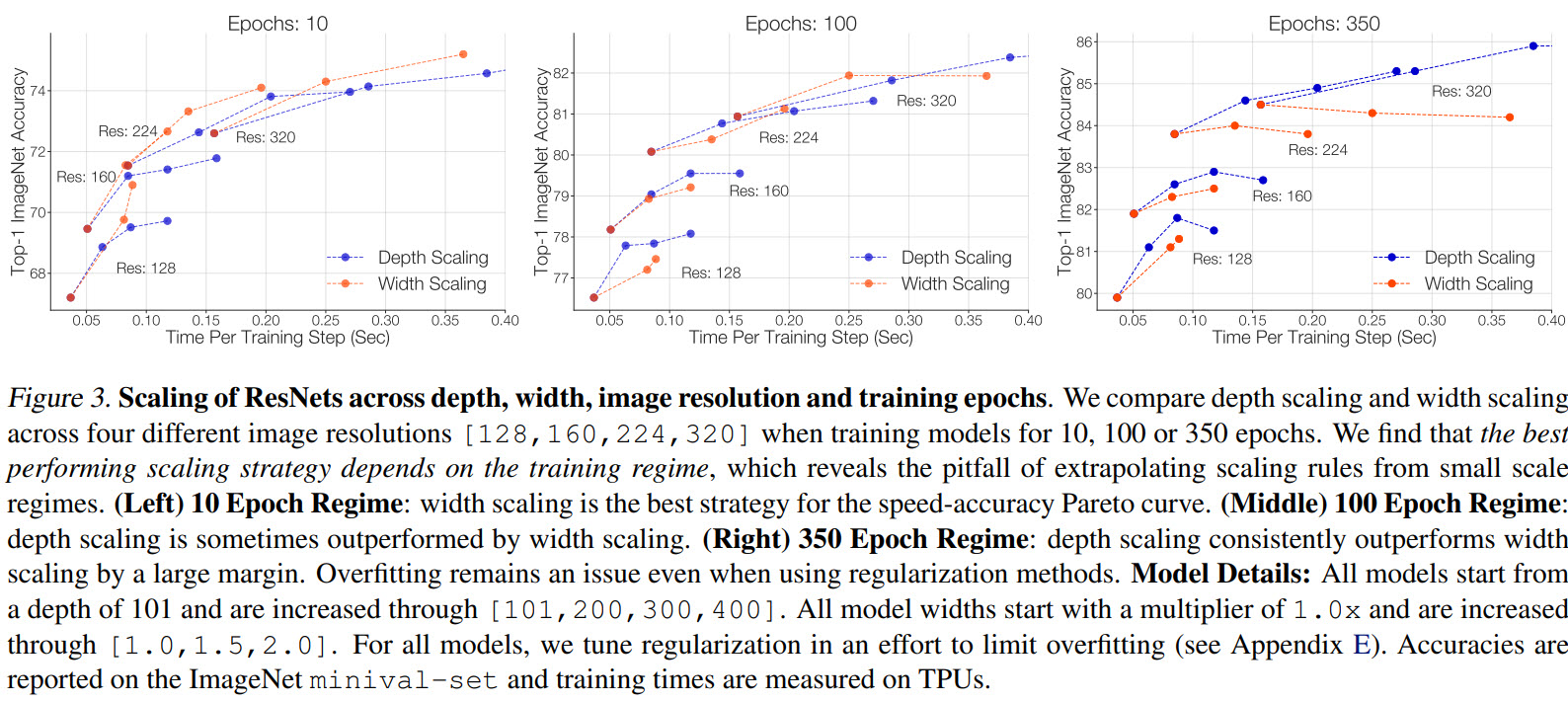
Another important finding: The best performing scaling strategy depends on the training regime.
We can see that depth scaling outperforms width scaling for long training, and on the other hand, width scaling is better for shorter training.
Experiments with Improved Training and Scaling Strategies
ResNet-RS on a Speed-Accuracy Basis
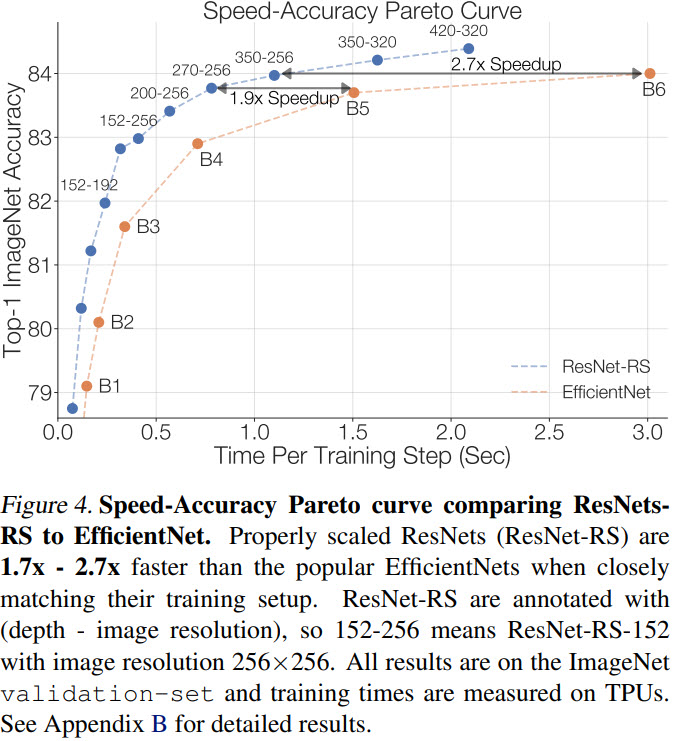
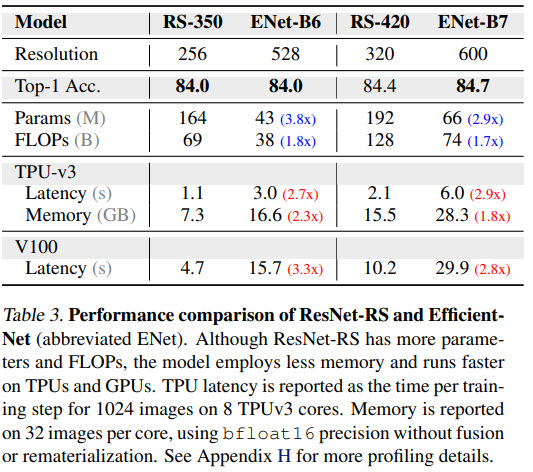
It is quite interesting that ResNet-RS is faster than EfficientNet even though FLOPS and parameter count are higher.
Improving the Efficiency of EfficientNets
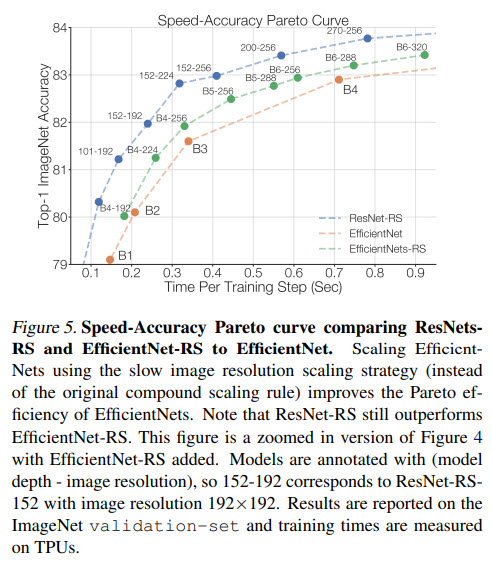
The authors apply slow image resolution scaling strategy to EfficientNets and train several versions with different image resolution.
Semi-Supervised Learning with ResNet-RS
The authors train ResNet-RS on 1.2M labeled ImageNet images and 130M pseudo-labeled images (like Noisy Student).
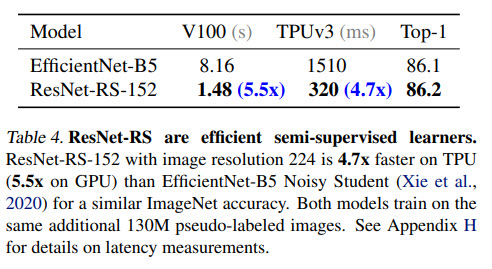
Transfer learning
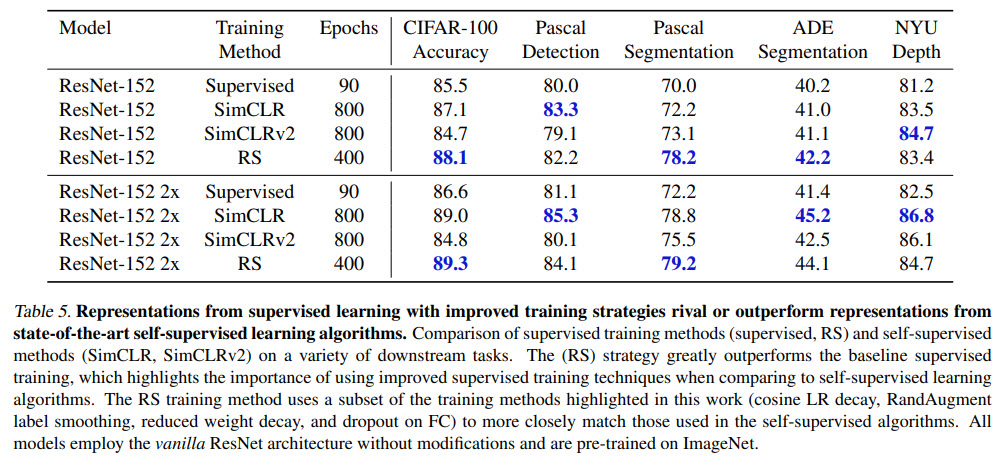
In an effort to closely match SimCLR’s training setup and provide fair comparisons, the authors restrict the RS training strategies to a subset of its original methods. Nevertheless, the results are much better.
Video Classification