Paper Review: Retentive Network: A Successor to Transformer for Large Language Models
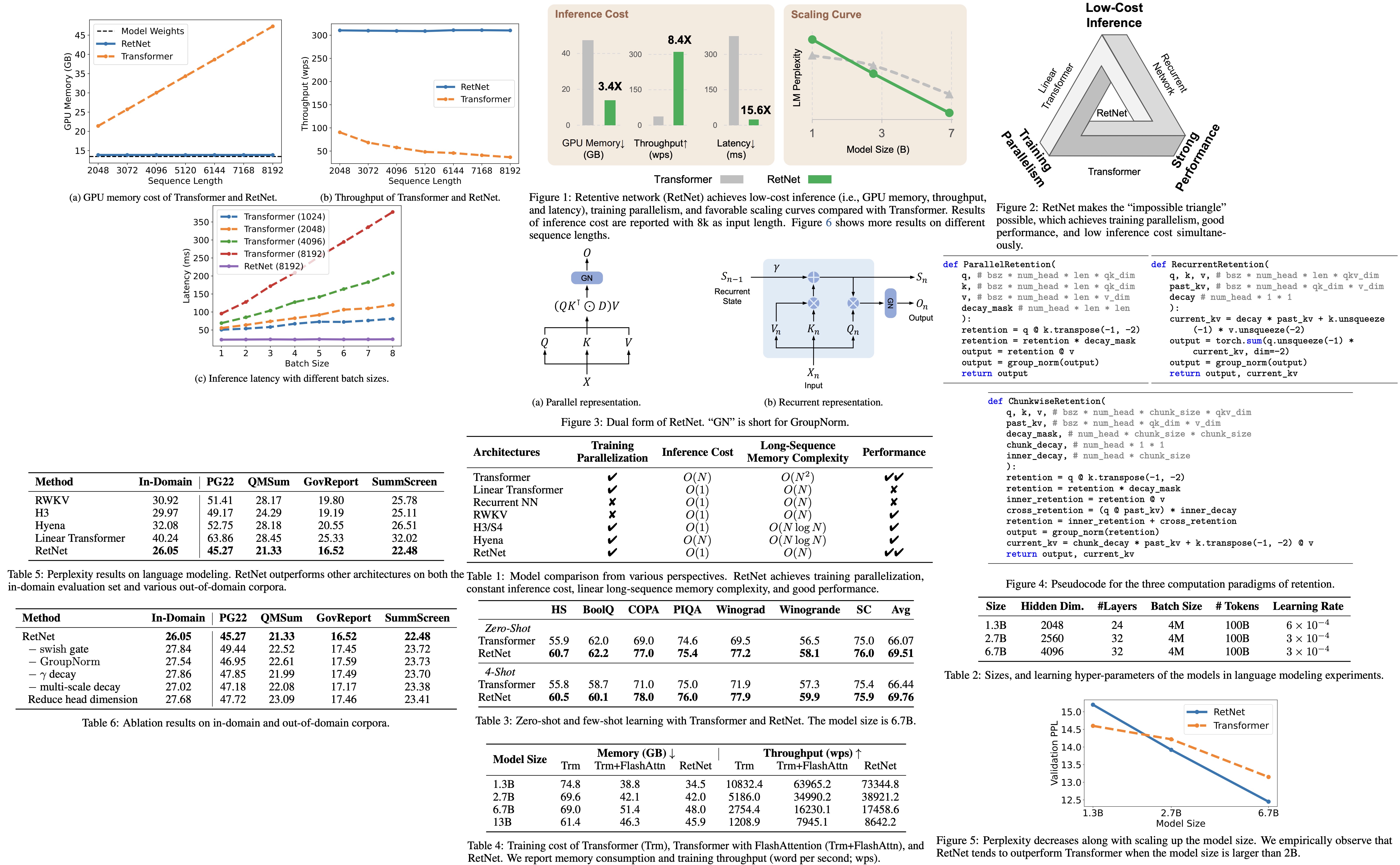
The authors propose a new foundation architecture for large language models called Retentive Network (RetNet). RetNet is designed to achieve training parallelism, low-cost inference, and robust performance. It theoretically establishes a connection between recurrence and attention and introduces a retention mechanism for sequence modeling. This mechanism supports parallel, recurrent, and chunkwise recurrent computation paradigms. Parallel representation promotes training parallelism, while the recurrent representation facilitates low-cost inference, improving decoding speed, latency, and GPU memory use without compromising performance. The chunkwise recurrent representation allows for efficient modeling of long sequences with linear complexity, processing each chunk in parallel while summarizing them recurrently. Experiments have shown that RETNET provides favorable scaling results, parallel training, cost-effective deployment, and efficient inference, making it a promising successor to the Transformer architecture for large language models.
Retentive Networks
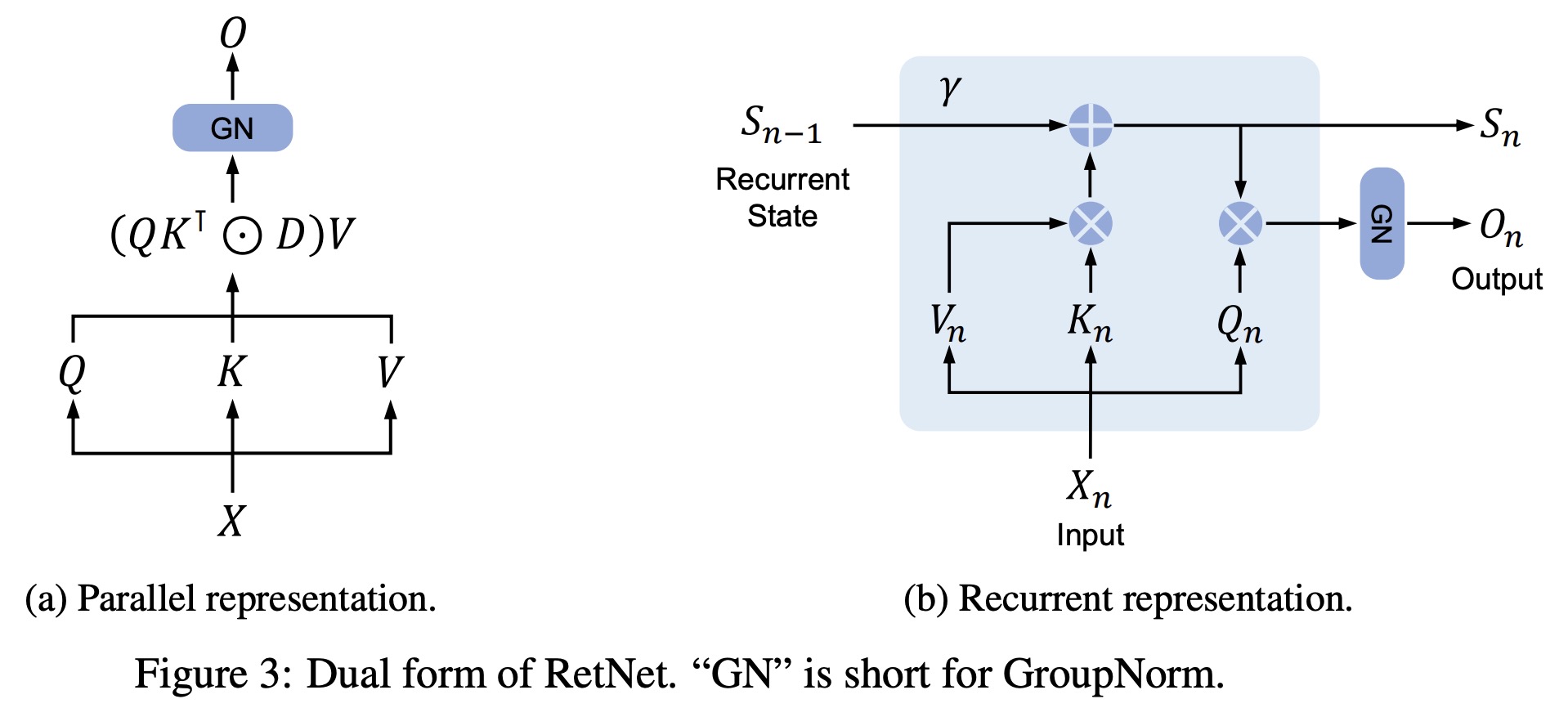
Retention
Retention mechanism which combines the features of recurrence and parallelism, allowing models to be trained in a parallel manner while conducting recurrent inference.
The mapping of input sequence to a state vector and output is formulated in a recurrent manner. This is achieved by making projections content-aware via learnable matrices. The authors show how they transform the initial equation and get to the final one, that is easily parallelizable within training instances with GPUs.
The mechanism can also be expressed as RNNs, which is favorable for inference. This recurrent representation of the retention mechanism updates state vectors over time and obtains outputs recurrently.
Furthermore, the authors propose a hybrid chunkwise recurrent representation that combines the parallel and recurrent representations to speed up training, especially for long sequences. This representation involves dividing input sequences into chunks and using parallel representation within each chunk while passing cross-chunk information via the recurrent representation.
Gated Multi-Scale Retention

The Retentive Network uses h = dmodel/d retention heads in each layer, where d represents the head dimension. Each head uses different parameter matrices and the multi-scale retention (MSR) assigns a unique γ value to each head. For simplicity, γ is kept identical among different layers and fixed.
To increase non-linearity of the retention layers, a swish gate is introduced. The input X is passed through each retention head and then through GroupNorm function, which normalizes the output of each head. The outputs are then concatenated, processed by a swish function, and finally transformed by a learnable weight matrix to get the MSR of X.
To improve the numerical precision of retention layers, scale-invariant GroupNorm is used, which allows multiplying a scalar value without affecting outputs and backward gradients. Three normalization factors are implemented in the retention mechanism, they don’t change the final results but help stabilize the numerical flow in both forward and backward passes.
Overall Architecture of Retention Networks
In an L-layer Retentive Network, the model is built by stacking MSR and FFN modules. The input sequence is transformed into vectors using a word embedding layer, and these packed embeddings are used as the input. The model output is computed by applying the MSR and FFN functions in sequence, with layer normalization applied before each function.
During training, the model uses both parallel and chunkwise recurrent representations. The parallelization within sequences or chunks helps efficiently utilize GPU resources and accelerates computation. The chunkwise recurrence is particularly beneficial for training with long sequences, as it’s efficient in both computational complexity and memory usage.
For inference, the model uses the recurrent representation, which is well-suited for autoregressive decoding. The O(1) complexity reduces memory requirements and inference latency while still providing equivalent results.
Experiments

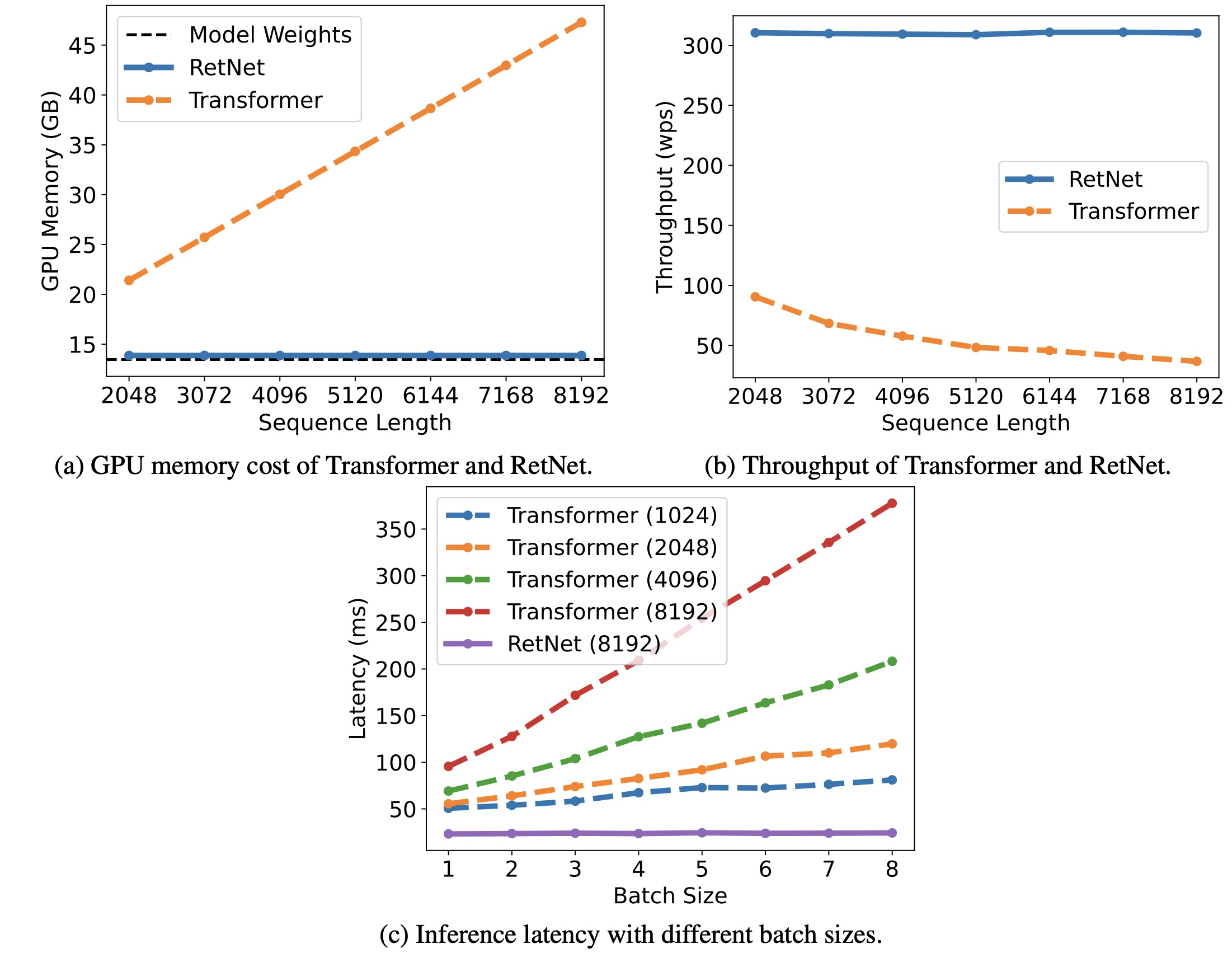
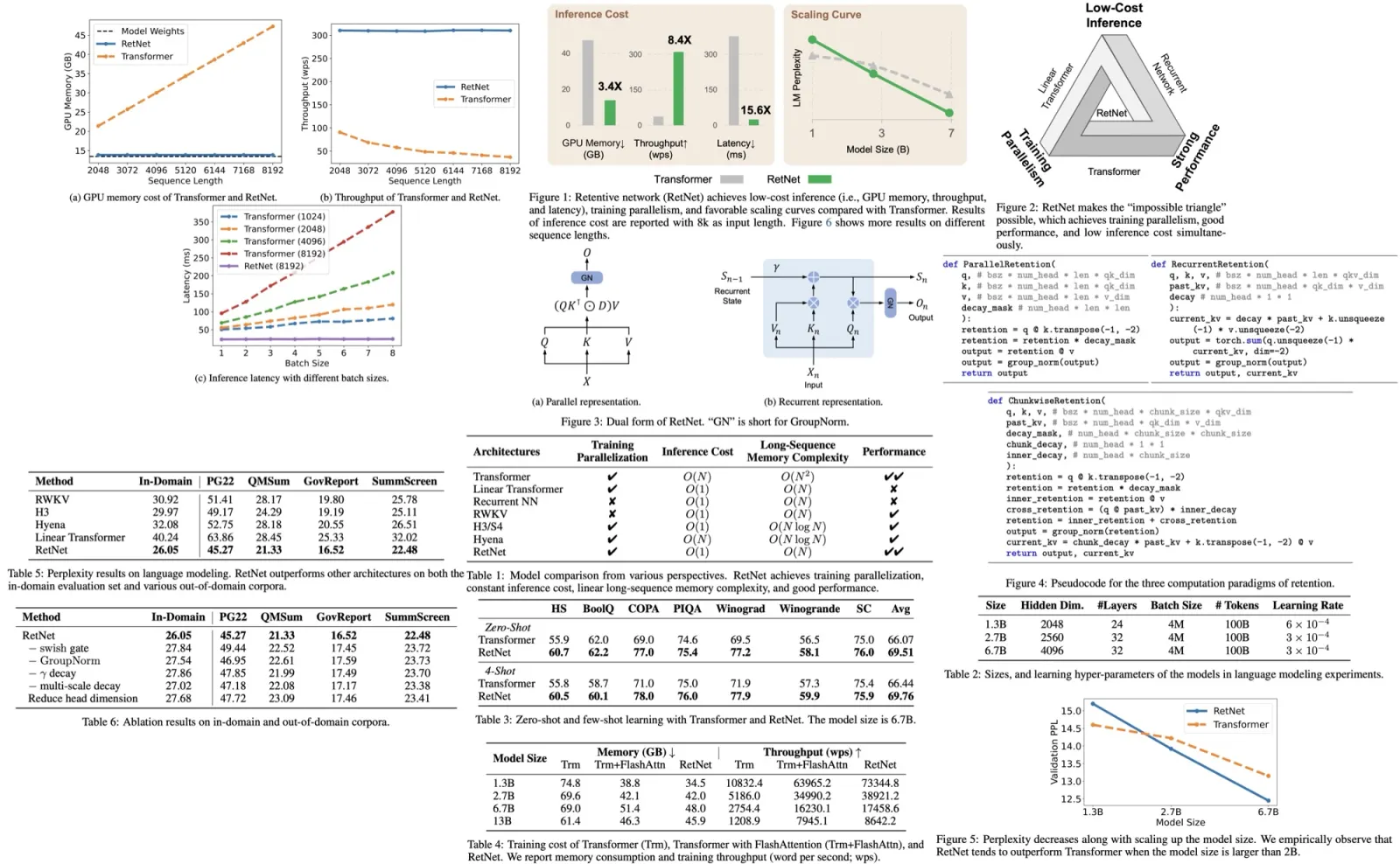
The RetNet model was evaluated on a variety of tasks and compared with the Transformer model. For language modeling tasks, RetNet showed comparable results to the Transformer model, but proved to be more favorable in terms of size scaling. It was found to be a strong competitor to the Transformer, particularly for larger language models, outperforming the latter when the model size exceeded 2 billion.
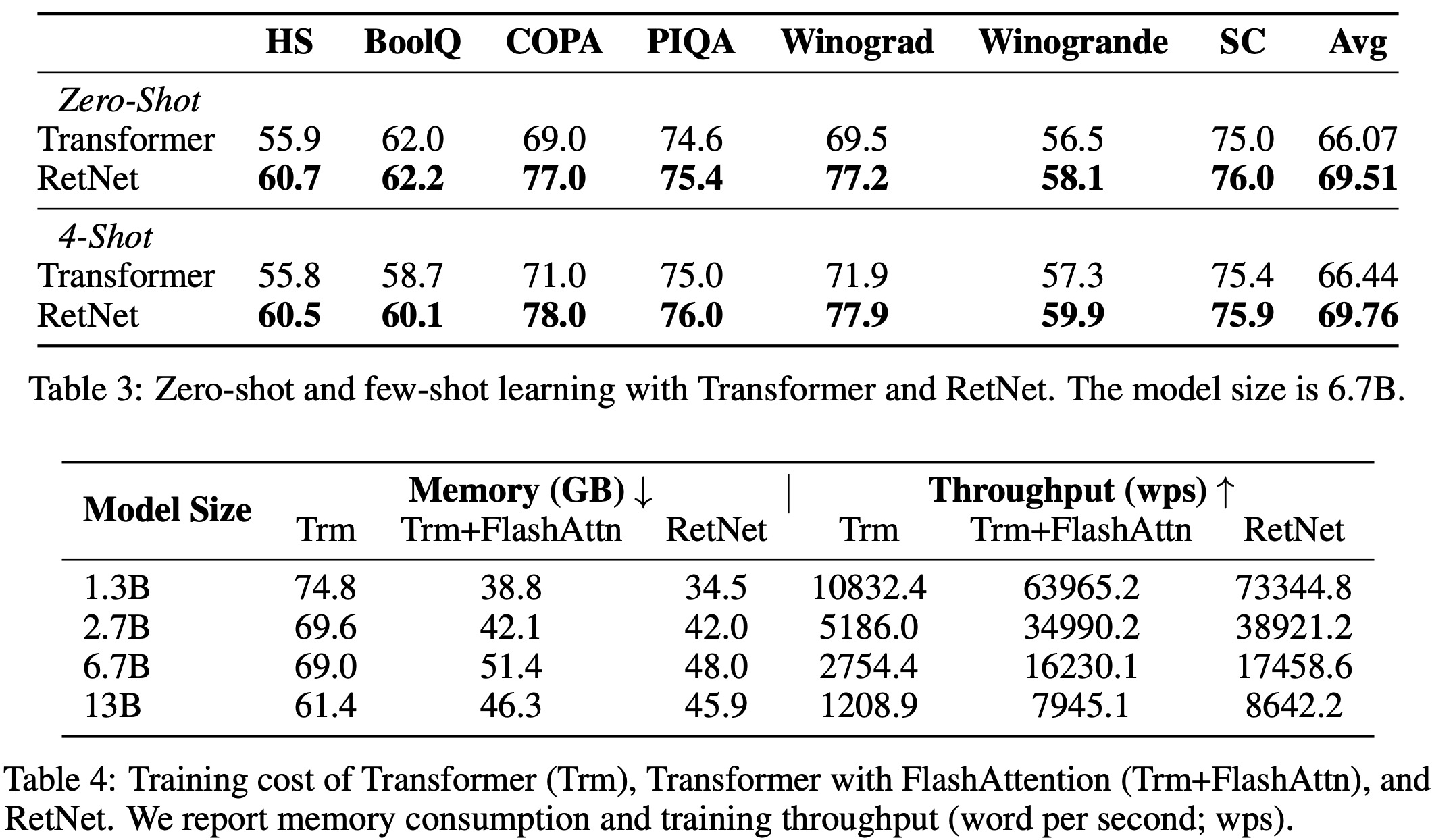
In terms of zero-shot and few-shot learning on various downstream tasks, RetNet also matched the performance of the Transformer model.
A comparison of training speed and memory consumption revealed that RetNet was more memory-efficient and provided higher throughput than the Transformer, even when compared to a highly optimized variant, FlashAttention. RetNet was also found to be easily trainable on other platforms, demonstrating potential for further cost reduction with advanced implementation techniques like kernel fusion.
During inference, RetNet outperformed the Transformer in terms of memory cost, throughput, and latency. It demonstrated consistent memory consumption even for longer sequences, higher and length-invariant throughput, and lower latency across different batch sizes and input lengths. The memory cost of the Transformer increased linearly, its throughput dropped with increasing decoding length, and its latency grew with increasing batch size and input length. This led to a decrease in the overall inference throughput of the Transformer.
Comparison with Transformer Variants
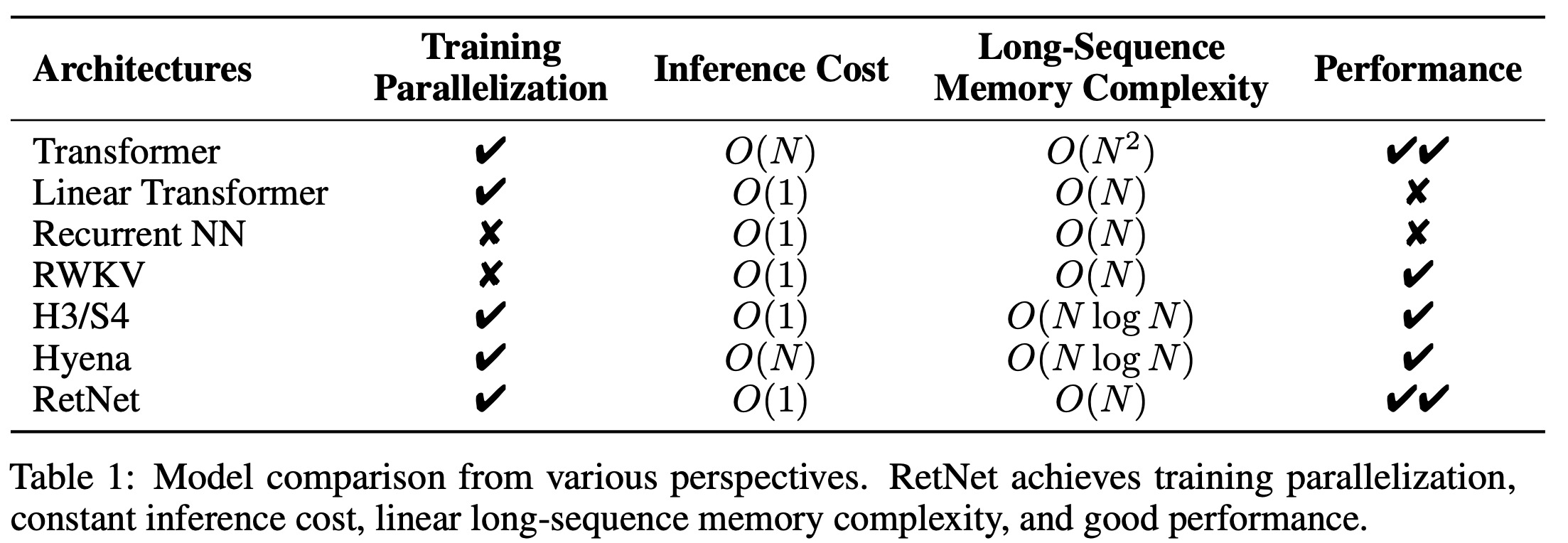
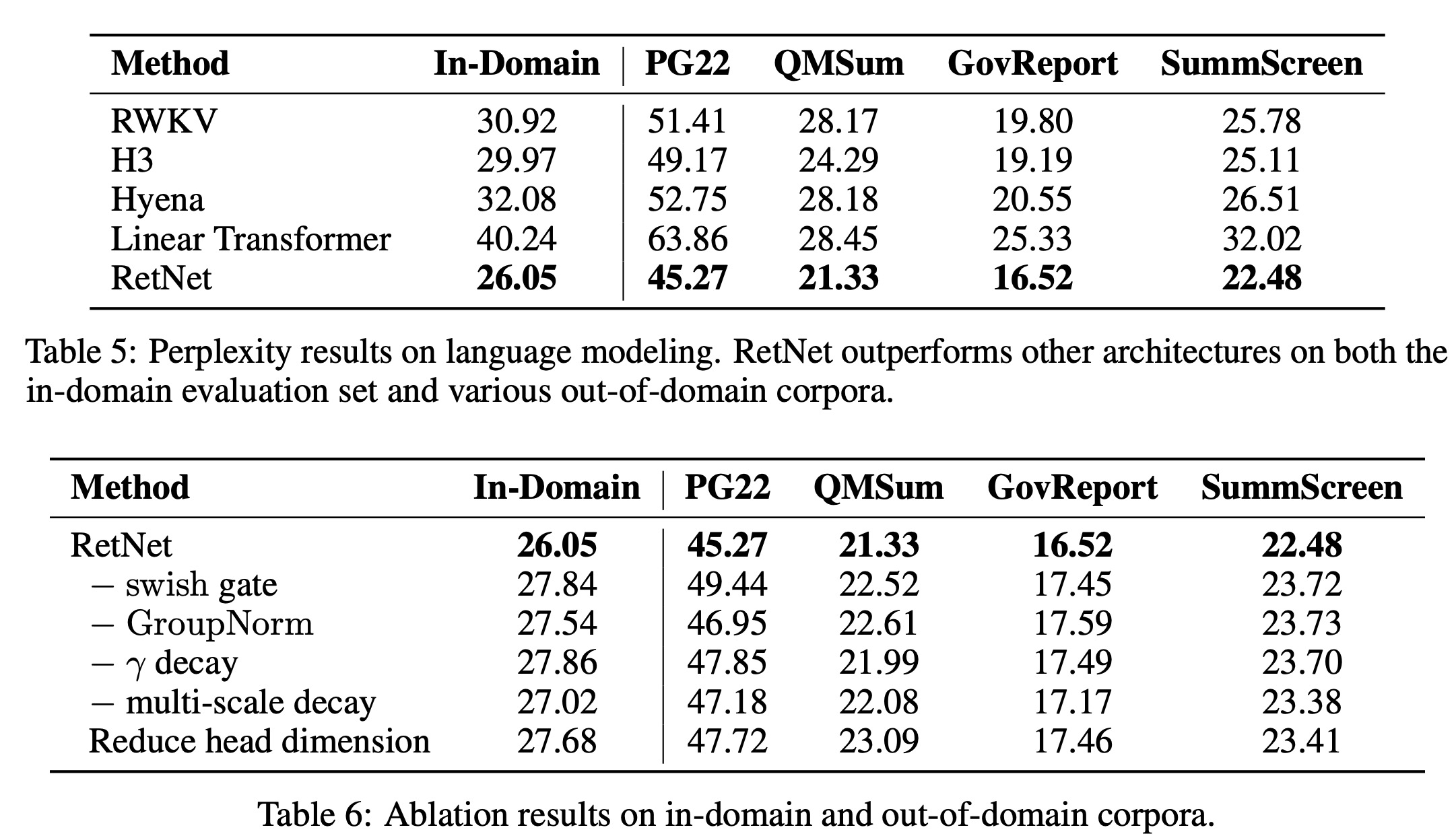
The RetNet model was compared with various efficient Transformer variants, including Linear Transformer, RWKV, H3, and Hyena. All models were similar in size with 200 million parameters, 16 layers, and a hidden dimension of 1024. They were trained with 10,000 steps and a batch size of half a million tokens, with most other hyperparameters and training corpora kept consistent.
The evaluation included both in-domain validation and out-of-domain corpora. RetNet outperformed the other methods across all datasets, achieving better results on in-domain corpus and lower perplexity on out-of-domain datasets. This superior performance, combined with its significant cost reduction benefits, made RetNet a strong successor to the Transformer model.
In terms of training and inference efficiency, RetNet proved to be quite efficient without sacrificing modeling performance. The complexity of its chunk-wise recurrent representation was manageable and had negligible effects for large model sizes or sequence lengths. For inference, RetNet was among the efficient architectures capable of O(1) decoding, alongside RWKV and others, outperforming Transformer and Hyena.
paperreview deeplearning nlp transformer llm