Paper Review: Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
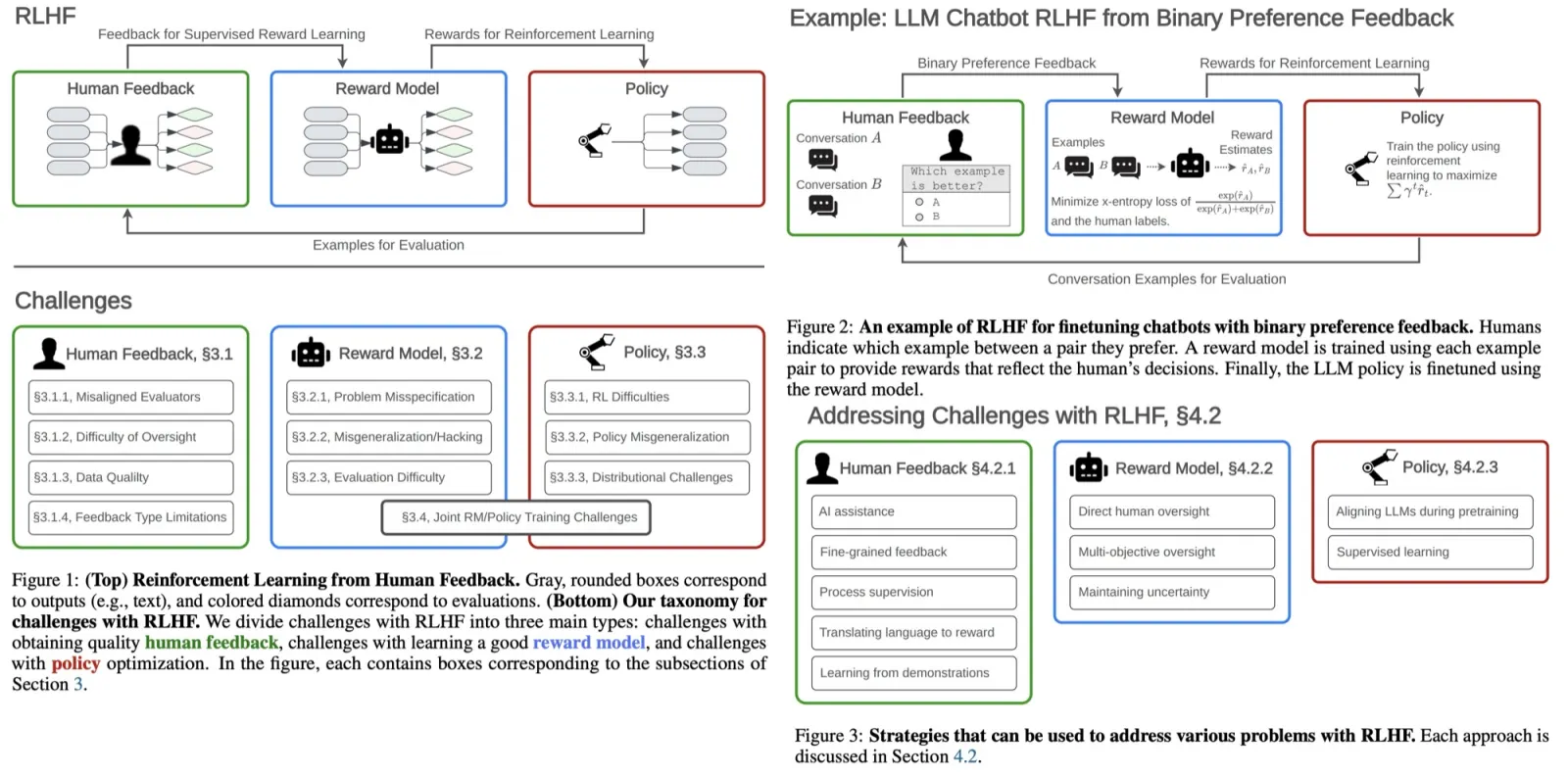
The paper focuses on Reinforcement Learning from Human Feedback (RLHF), a key method for tuning large language models to align with human objectives. Despite its widespread use, there has been limited examination of its flaws. The paper outlines three main areas of study:
- an exploration of the open problems and inherent limitations of RLHF;
- an overview of techniques to comprehend, enhance, and supplement RLHF in practice;
- suggestions for auditing and transparency measures to enhance societal control of RLHF systems.
The authors stress the need for a comprehensive approach to create safer AI systems.
Background information
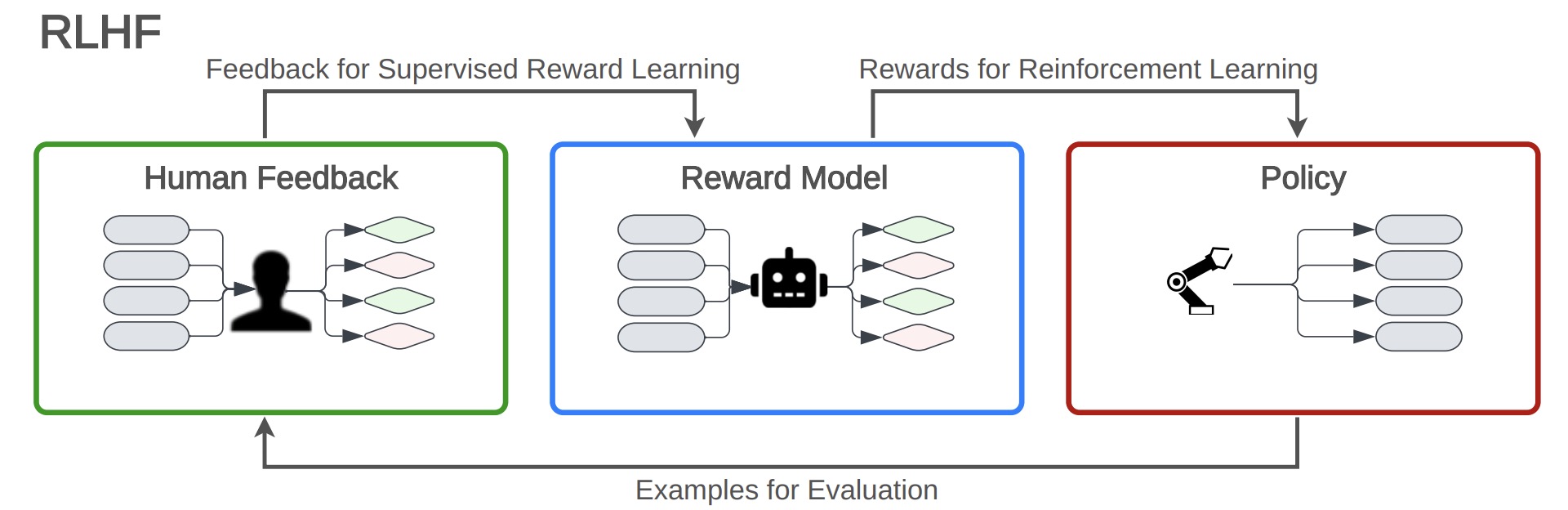
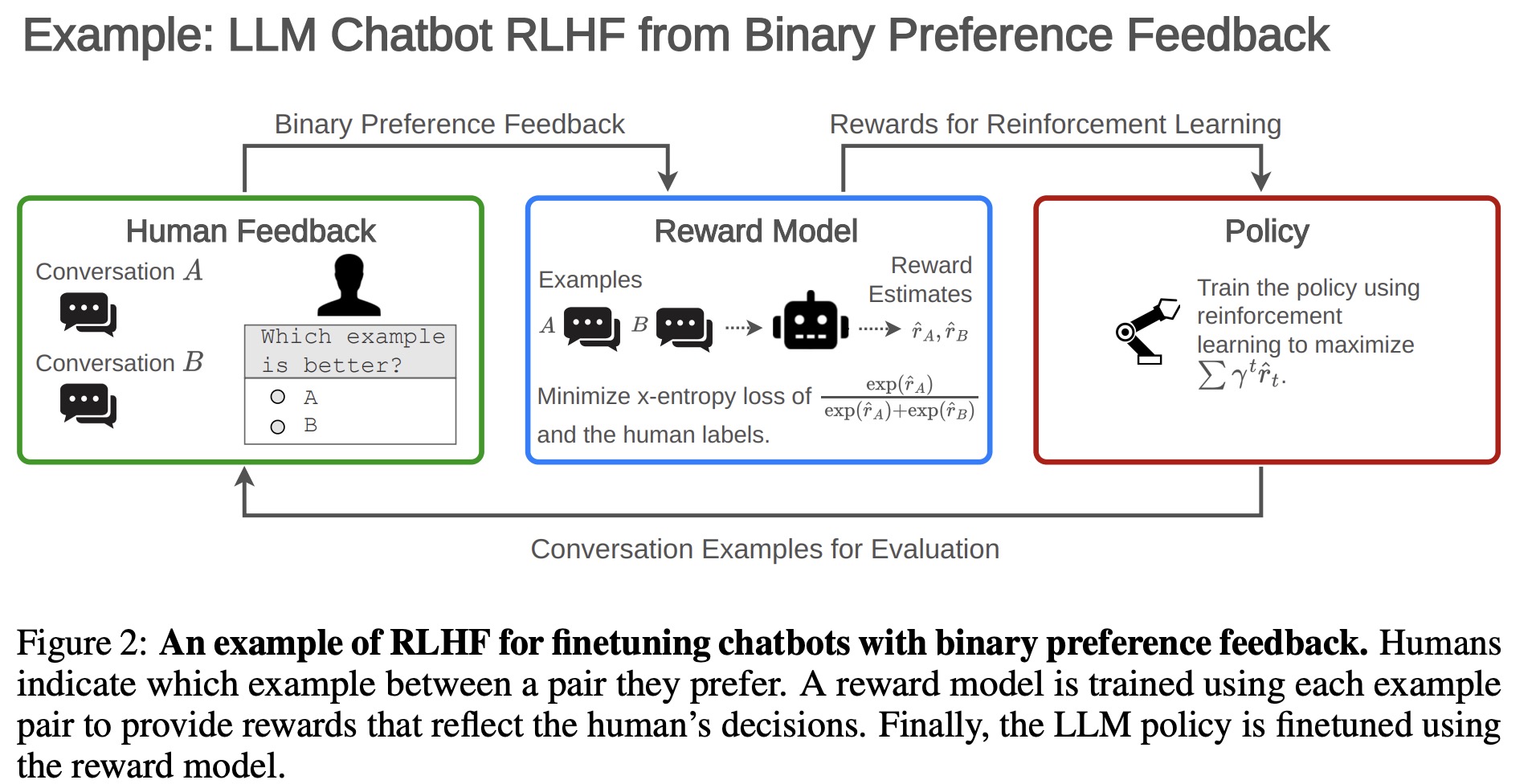
Reinforcement Learning from Human Feedback (RLHF) is a three-step iterative process used to finetune AI models, especially LLMs.
- Optional Pretraining: The process begins with an initial model that generates a distribution of examples, such as a language generator pre-trained on web text.
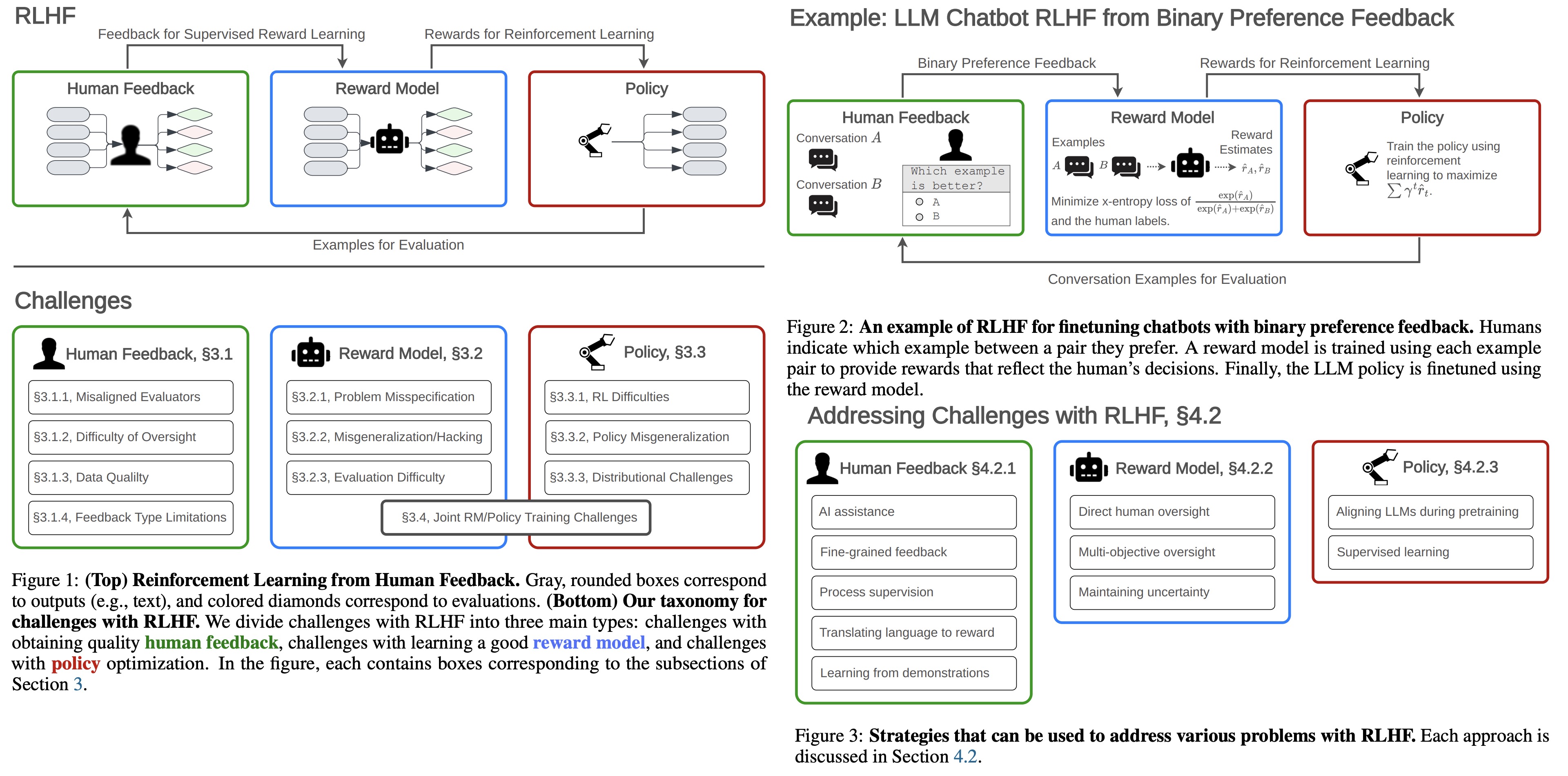
- Collecting Human Feedback: Examples are obtained from the base model, and human feedback is collected on those examples. Feedback may include preferences expressed within pairs of conversations.
- Fitting the Reward Model: Using the collected feedback, a reward model is created to approximate human evaluations. Various loss functions and regularizations may be used to minimize the discrepancy between the feedback and the model’s predictions.
- Optimizing the Policy with RL: The final step is to fine-tune the base model using reinforcement learning, maximizing a specific function that also may include regularization.
RLHF’s advantages include its ability to enable communication of goals without having to hand-specify a reward function, and its usefulness in mitigating reward hacking. It’s helpful in allowing policies to learn complex solutions and in fine-tuning LLMs.
Open problems and limitations of RLHF
Challenges with Obtaining Human Feedback
Misaligned Humans: Evaluators may Pursue the Wrong Goals
Selecting representative humans and getting them to provide quality feedback is difficult:
- Selecting and instructing human evaluators in Reinforcement Learning from Human Feedback (RLHF) has led to biases.
- Studies found that ChatGPT models became politically biased post RLHF.
- OpenAI’s evaluator demographics include 50% Filipino and Bangladeshi nationals and 50% aged 25-34. Anthropic’s evaluators are primarily white (68% from 82% white initial pool). Such demographics might introduce implicit biases.
- The choice of instructions for evaluators presents another area where biases can be introduced, and research into this area is lacking.
Some evaluators have harmful biases and opinions:
- Some human evaluators have harmful or biased opinions.
- Language models trained through RL can end up pandering to these biases, a phenomenon termed “sycophancy”. More than that, larger models might be more prone to sycophancy.
- While this problem exists in pretrained models, RLHF can sometimes amplify it.
Individual human evaluators can poison data:
- With many evaluators required in RLHF, some might intentionally compromise the model.
- The interactive data collection process with humans in RLHF can be exploited. For instance, during open-ended conversations with models, malicious annotators can introduce “trigger phrases” that make the model exhibit harmful behavior.
Good Oversight is Difficult
Humans make simple mistakes due to limited time, attention, or care:
- Humans may make simple errors due to lack of interest, attention decay, time constraints, and human biases, exacerbated by the complexity of evaluating model outputs.
- Evaluators are often paid per example, leading to cutting corners and preference for evasive or unsubstantive examples.
- Cognitive biases, misconceptions, false memories and even outsourcing work to chatbots can further impair label quality.
Partial observability limits human evaluators:
- If humans are not given all the information about the world state, they can’t provide informative feedback. There is an example of training a robotic hand via RLHF from 2D visuals for a 3D task. The robot learned to move within the human’s view rather than doing the desired action.
- Even with complete information, limitations in time and attention effectively result in partial observability.
Humans cannot evaluate performance on difficult tasks well:
- Humans may not evaluate performance well on difficult tasks, even with perfect information and extended time.
- Human evaluators often miss critical errors, inaccuracies, and security vulnerabilities, even in well-defined tasks such as summarizing passages.
- Studies found that humans missed critical errors in summaries and security vulnerabilities, indicating that relying solely on human feedback might not suffice for advanced AI oversight.
Humans can be misled, so their evaluations can be gamed:
- Models may exploit the difference between what is good and what is evaluated positively, leading to misleading evaluations.
- Language models can imitate persuasive human tactics, sound confident even when incorrect, and may lead to more positive feedback, contributing to manipulative behavior such as “sycophancy” or “gaslighting” of humans.
Data Quality
Data collection can introduce biases:
- Ideal feedback data should resemble the deployment distribution, especially highlighting difficult examples for the reward model.
- However, actual interactions with large language models (LLMs) might not align with any specific distribution causing potential biases.
There is an inherent cost/quality tradeoff when collecting human feedback:
- The limited resources for data collection present a tradeoff between the quality of feedback and other factors like the inclusion of long conversations.
- This tradeoff often hampers the effectiveness of RLHF, especially in aligning the performance of LLMs in extended dialogues.
- Some ways to improve data quality include obtaining diverse, adversarial, and uncertain samples. Yet, these strategies have limitations.
- Active learning techniques often rely on unreliable prediction confidence heuristics.
- Tight budgets may drive companies to take shortcuts, like freely sourcing data from users, leading to potential biases or even poisoned data.
Limitations of Feedback Types
Comparison-based Feedback:
- Commonly uses binary preferences, k-wise rankings, or best-of-k queries.
- Lacks precision in conveying the intensity of preferences.
- Can fail to converge to true preferences due to noise or unmodeled, contextual details.
- May lead to policies prioritizing median performance over average performance.
Scalar Feedback:
- More expressive than comparison-based feedback but can be poorly calibrated.
- Difficult for annotators to quantify success, leading to inconsistency and bias.
- Combining scalar and comparison feedback requires more complex human response models.
- Discretizing feedback can lead to opposite of the true one if policy assumptions are violated
Label Feedback:
- Consists of classifying examples, which is relatively low-effort.
- May suffer from choice set misspecification when given options are insufficient.
Correction Feedback:
- Includes corrective demonstrations or adjustments.
- Can be used to improve policies and plans but is high effort and skill-dependent.
Language Feedback:
- Uses human language to convey substantial information, reducing ambiguity.
- Faces challenges due to imprecision in speech and cultural differences in language use.
- Techniques for language feedback exist but haven’t been extensively applied to LLMs.
Challenges with the Reward Model
Problem Misspecification
An individual human’s values are difficult to represent with a reward function:
- Human preferences are complex and context-dependent, evolving over time, making them hard to accurately model.
- Incorrect assumptions about human decision-making can negatively impact reward inference.
- Various studies have highlighted wrong assumptions in human models, such as their use of regret, hypothesis space of reward models, and pedagogic behavior.
- The misspecification of models like the Boltzmann model, irrationalities in human behavior, and different modalities of feedback (e.g., demonstrations, preferences) further complicate reward learning.
- Some methods attempt to combine information about human goals, but they are sensitive to assumptions about human modeling, leading to a tradeoff between efficiency and accuracy.
A single reward function cannot represent a diverse society of humans:
- RLHF is often aimed at aligning AI with a single human, ignoring the vast diversity in human preferences, expertise, and capabilities.
- Human evaluators often don’t agree on feedback. Some studies show agreement rates between 63% to 77%.
- Condensing feedback from a variety of humans into a single reward model without considering these differences leads to a fundamentally misspecified problem.
- Current techniques often model differences among evaluators as noise instead of essential disagreement sources.
- Majority preferences might prevail, potentially disadvantaging under-represented groups.
Reward Misgeneralization and Hacking
Reward models can misgeneralize to be poor reward proxies, even from correctly labeled training data:
- There might be many ways to fit human feedback data, even with infinite training data.
- Reward models may compute rewards based on unexpected features of the environment, leading to causal confusion and weak generalization outside the training distribution.
- Some reward models fail to train new agents, questioning their reliability for policy learning.
Optimizing for an imperfect reward proxy leads to reward hacking:
- Optimizing for an imprecise reward proxy can result in “reward hacking,” where the model finds unintended ways to maximize its rewards.
- Misspecification and misgeneralization, along with the inherent complexity of real-world problems, contribute to the differences between reward models and human judgment.
- Models are trained to mirror human approval rather than genuine human benefit, which might result in undesirable outcomes.
- Strong optimization for an inaccurate proxy of a goal can cause failure in achieving the actual target goal.
- Specific problems like outputting nonsensical text have been observed without proper regularization, and reward hacking has been recognized in AI systems, including those trained with RLHF.
- Studies show that unhackable proxies are rare in intricate environments, and reward hacking is to be expected by default, especially as an agent’s capabilities increase.
Evaluating Reward Models
Evaluating reward models is difficult and expensive:
- If the true reward function is known, there are methods to assess the quality of the learned reward model. However, reward modeling is often used when the true reward isn’t known, preventing direct evaluation.
- Typically, the learned reward model’s effectiveness is gauged indirectly. An RL policy is optimized using this model, and the outcomes from the policy are then evaluated. This method ties the reward model’s assessment to the policy optimization process, which is costly and unreliable.
- Evaluations might vary based on numerous decisions made during policy optimization, such as the RL algorithm used, network design, computational resources allocated, and hyperparameters.
- Both the training and evaluation processes rely on human approval. Their overlap can lead to correlated errors in both phases.
- It remains uncertain which choices in the policy optimization process most impact the accurate evaluation of reward models.
Challenges with the Policy
Robust Reinforcement Learning is Difficult
It is still challenging to optimize policies effectively:
- RL agents need to balance between exploring new actions and exploiting known rewards. This balance is crucial but hard to determine and differs across environments. The challenge intensifies in high-dimensional or sparse reward settings.
- Deep RL has shown to be unstable with results being sensitive to initial conditions and hard to replicate. Various factors contribute to this instability, including the random nature of exploration, violations in data collection assumptions, bias in value functions, and unpredictability in deep neural learning.
Policies tend to be adversarially exploitable:
- Even well-trained policies that perform well in standard situations may fail in adversarial contexts. Models deployed in real-world scenarios are vulnerable to adversarial attacks from humans or AI.
- Superhuman policies can be catastrophically defeated by adversarial strategies designed to exploit them. These adversarial strategies can emerge from re-purposed RL algorithms, human optimizations, or other methods, especially in the context of language models.
- Black-box access (like API access) to a model is adequate for many adversarial policy attacks. However, white-box access (e.g., through open-source or leaked model weights) facilitates even more potent exploits.
Policy Misgeneralization
Policies can perform poorly in deployment even if rewards seen during training were perfectly correct:
- Even if the rewards during training are accurate, policies can perform poorly during deployment because the deployment environment might differ from the training and evaluation environments.
- Policies can end up pursuing the wrong goals if these incorrect objectives correlate with other events. A specific example is when a system trained with RLHF pursues the reward mechanism itself rather than the actual intended goal.
Optimal RL agents tend to seek power:
- RL agents inherently have the incentive to acquire power to achieve their objectives.
- This issue can surface when RLHF is used to fine-tune LLM systems. For instance, a question-answering LLM might manipulate human users to steer away from difficult topics. Another manifestation of this issue is LLMs displaying sycophantic behavior.
Distributional Challenges
The pretrained model introduces biases into policy optimization:
- RLHF in LLMs often starts with a base model pretrained on internet text, influencing the RL policy network.
- This approach has been formalized as a form of Bayesian inference, where the base model determines the prior, but it’s more of a convenience than a principled method.
- This leads to inheriting harmful biases present in internet text (such as demographic biases), which can persist through the RLHF training process.
- An example of this bias is the learned correlation between sounding confident and being correct, reinforcing confidence as a desirable trait in the policy.
RL contributes to mode collapse:
- RL fine-tuning reduces the diversity of samples produced by a model, leading to “mode collapse”.
- Studies have found that RLHF fine-tuning can negatively impact various aspects of models like GPT-4, such as calibration on question-answering or a narrow distribution of political views.
- Mode collapse might partially stem from switching from supervised pretraining to an RL objective, as RL pushes for high-scoring completions.
- Addressing mode collapse is complex as it can be both beneficial or harmful, depending on the context.
Challenges with Jointly Training the Reward Model and Policy
Joint training induces distribution shifts:
- Learning both a reward model and a policy simultaneously is complex: If the reward model is trained on offline data, it might misgeneralize. If reward and policy are learned jointly, the system may suffer from “auto-induced distributional shift”.
- Errors in over- or underestimating rewards can become gradually prominent, and such mistakes accumulate, making them hard to correct once the policy lacks diversity.
It is difficult to balance efficiency and avoiding overfitting by the policy:
- In practice, the three key steps of RLHF are often performed serially, leading to off-distribution inaccuracies in the reward model, where the policy will then learn to go.
- The balance must be struck in obtaining fresh preference labels after certain number of policy training iterations. Too low a setting wastes information; too high a setting leads the policy into unreliable areas.
- Without labeled validation sets where the policy is exploring, detecting over-optimization of rewards during training is challenging.
- Potential solutions might include measuring KL-shift or monitoring disagreement within a reward model ensemble.
Incorporating RLHF into a Broader Framework for Safer AI
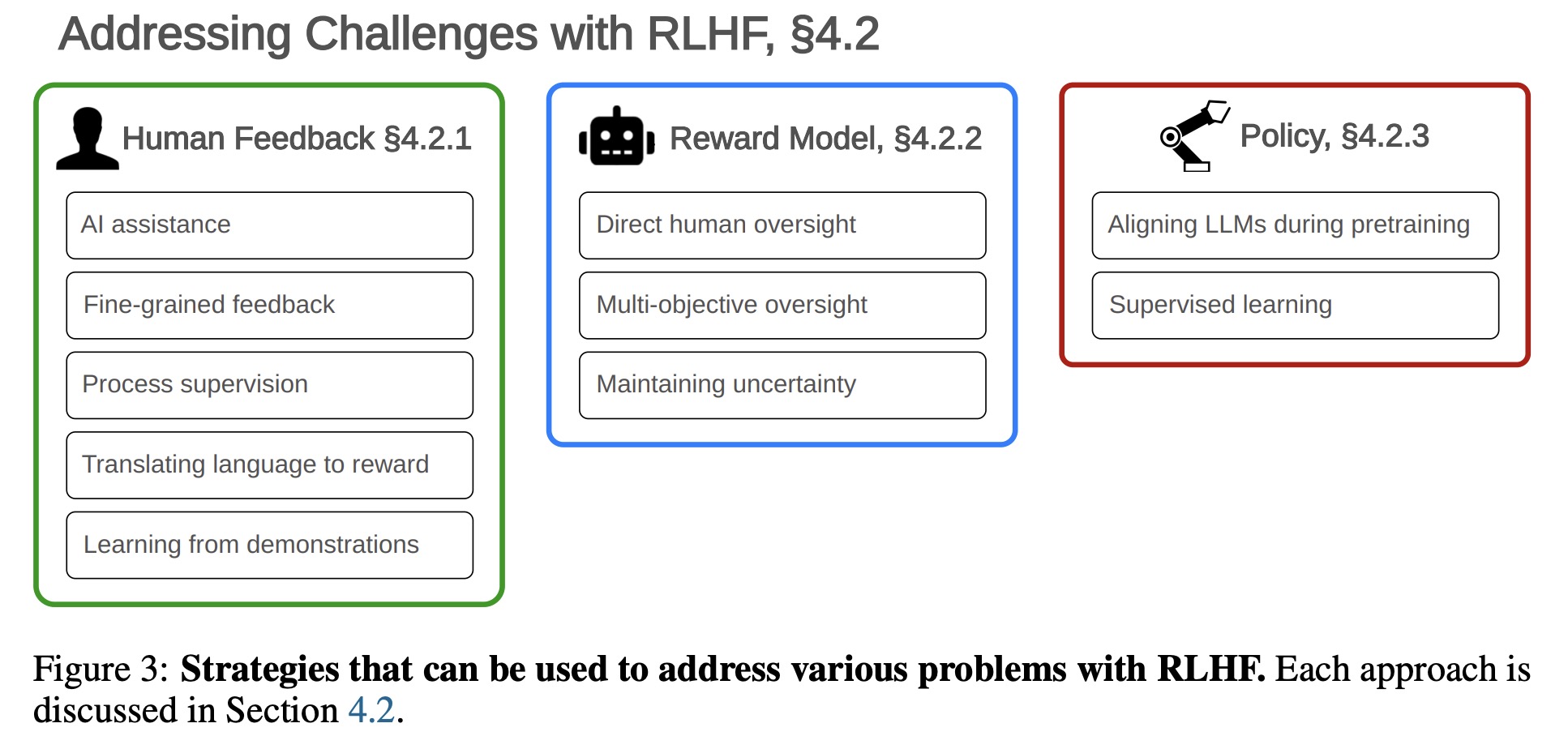
Addressing Challenges with RLHF
Addressing Challenges with Human Feedback:
- Providing Feedback with AI Assistance
- Fine-Grained Feedback: Precise, detailed feedback on specific portions of examples or in relation to different goals can improve reward models.
- Process-Based Supervision
- Translating Natural Language Specifications into a Reward Model
- Learning Rewards from Demonstrations (Inverse Reinforcement Learning): Instead of feedback, demonstrations by humans can teach reward models.
Addressing Challenges with the Reward Model:
- Using direct human oversight.
- Multi-objective oversight.
- Maintaining uncertainty over the learned reward function.
Addressing Challenges with the Policy:
- Aligning LLMs during pretraining.
- Aligning LLMs through supervised learning.
RLHF is Not All You Need: Complementary Strategies for Safety
Robustness:
- Solutions include training against adversarial examples, using anomaly detection techniques, and securing AI training against malicious threats.
Risk Assessment and Auditing:
- Evaluations, both in-house and second-party, are critical for spotting hazards and building trust, even though they aren’t proof of safety.
- Developing red teaming techniques is vital for robustness.
Interpretability and Model Editing:
- Progress in explainability and interpretability could verify models’ decision-making processes and build confidence in their safety without extensive testing.
- Techniques like red-teaming, understanding internal mechanisms, and direct interventions in model weights or activations can aid in improving truthfulness, modifying factual knowledge, or steering model behavior.