Paper Review: Scaling Transformer to 1M tokens and beyond with RMT
This technical report introduces the use of a Recurrent Memory Transformer architecture to extend BERT’s context length in natural language processing tasks. By increasing the effective context length to two million tokens, the model can store and process both local and global information while maintaining high memory retrieval accuracy. This approach has the potential to improve long-term dependency handling and enable large-scale context processing for memory-intensive applications.
Recurrent Memory Transformer
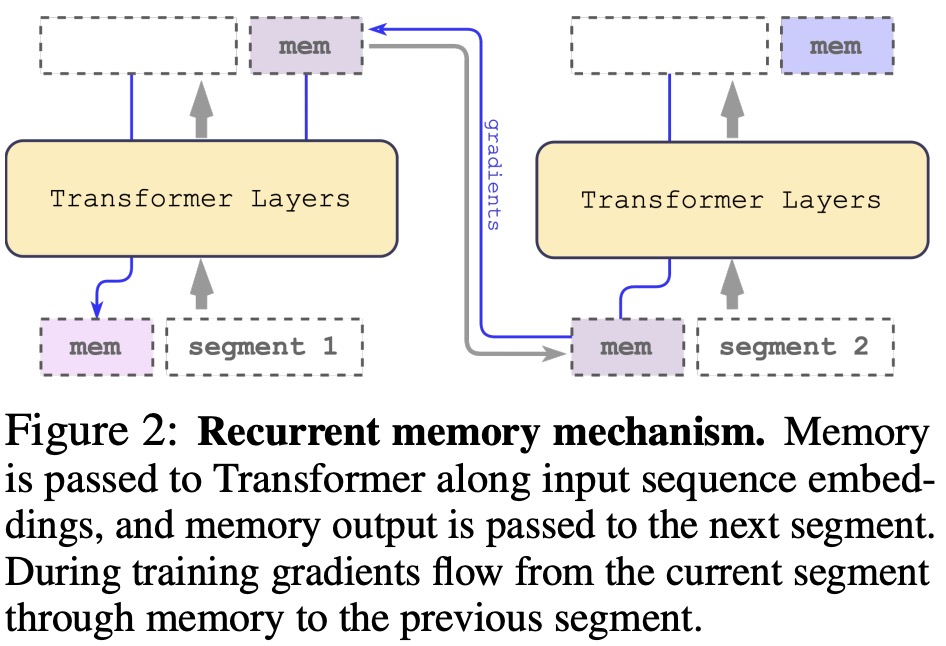
The authors adapted the Recurrent Memory Transformer (RMT) as a plug-and-play wrapper for Transformers, augmenting them with memory. Input is divided into segments, with memory vectors added to the first segment embeddings. For encoder-only models like BERT, memory is added only once, unlike decoder-only models that separate memory into read and write sections. The input sequence segments are processed sequentially, with updated memory tokens passed between segments. The RMT memory augmentation is compatible with any model from the Transformer family, as the backbone Transformer remains unchanged.
Computational efficiency
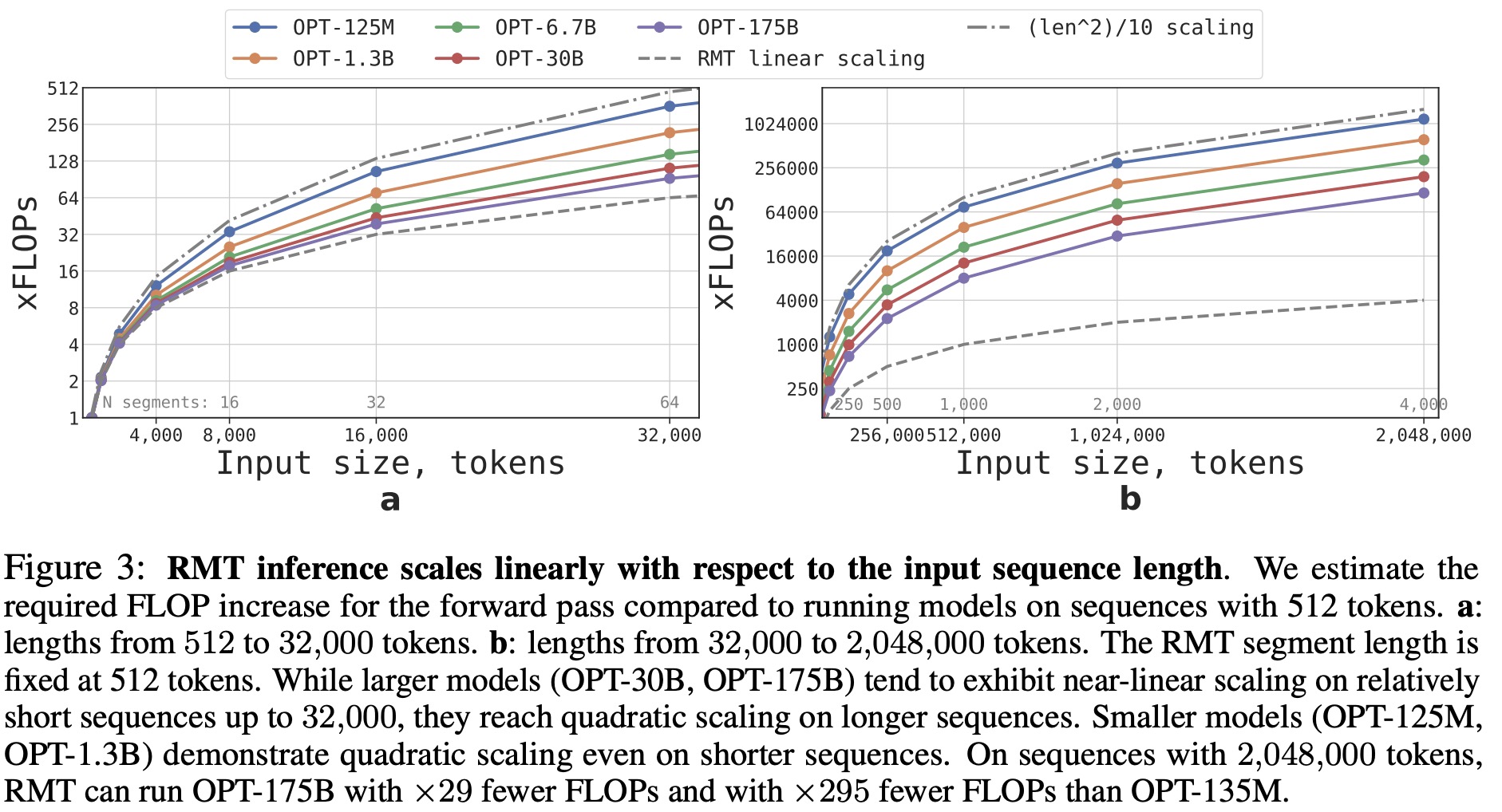
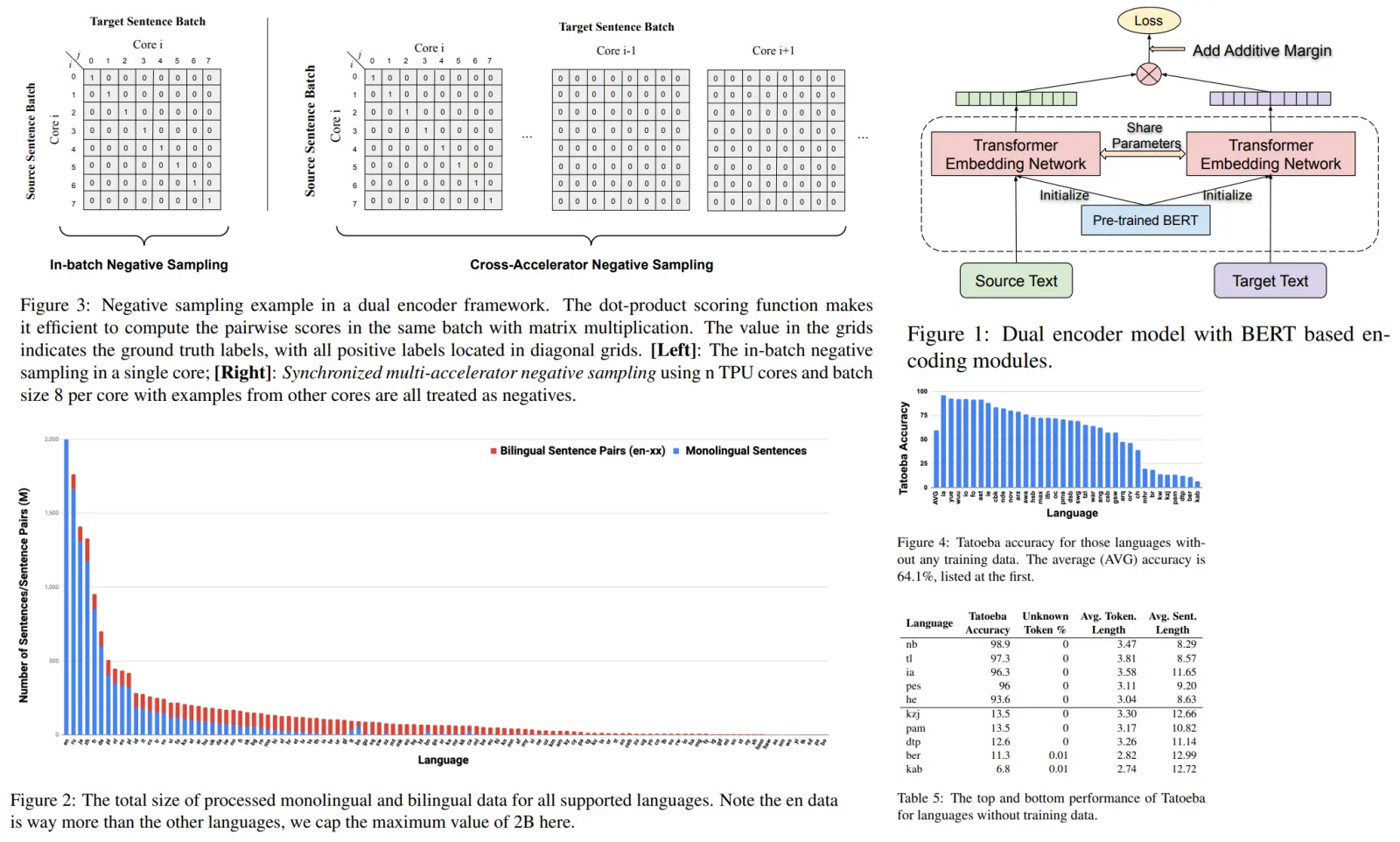
The authors estimated the required FLOPs for RMT and Transformer models with different sizes and sequence lengths, using configurations from the OPT model family. RMT scales linearly for any model size if the segment length is fixed, achieved by dividing the input sequence into segments and computing the attention matrix within segment boundaries. Larger Transformer models tend to exhibit slower quadratic scaling, but RMT requires fewer FLOPs for sequences with more than one segment, reducing FLOPs by up to 295 times. RMT offers a larger relative reduction in FLOPs for smaller models, but a 29 times reduction for OPT-175B models is still significant.
Memorization Task
The authors tested memorization abilities by creating synthetic datasets that require memorization of simple facts and basic reasoning. Task input consists of facts and a question that can only be answered using all facts. To increase difficulty, unrelated natural language text was added as noise. The model’s task is to separate facts from irrelevant text and use them to answer questions, formulated as a 6-class classification. Facts were generated using the bAbI dataset, while background text was sourced from questions in the QuALITY long QA dataset.
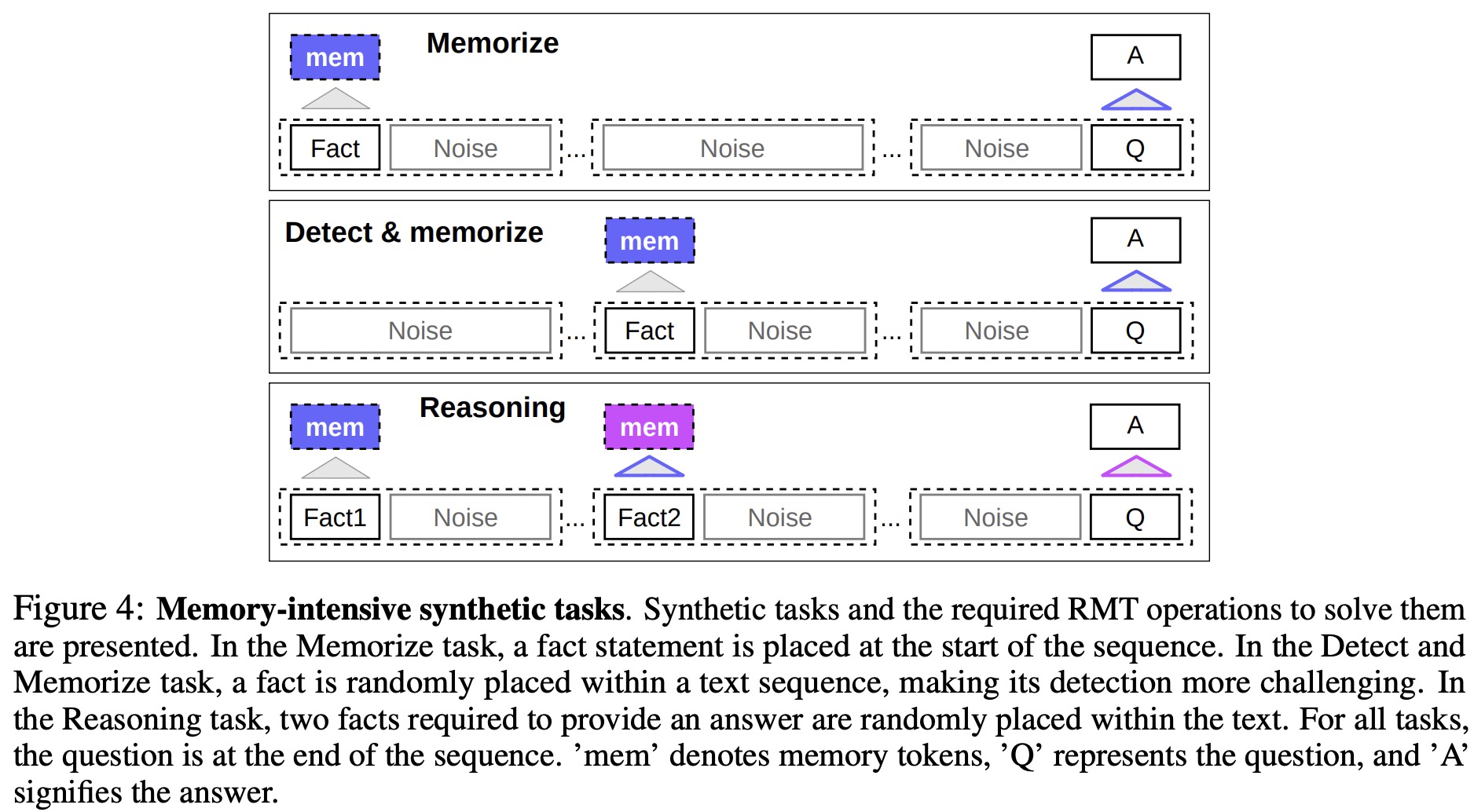
Fact Memorization. The first task evaluates RMT’s ability to write and store information in memory over an extended time. In the simplest case, the fact is always at the input’s beginning, and the question is at the end. The amount of irrelevant text between the question and answer is gradually increased so that the entire input doesn’t fit into a single model input.
Fact Detection & Memorization. In the fact detection task, the fact is placed at a random position in the input, increasing task difficulty. The model must distinguish the fact from irrelevant text, write it to memory, and later use it to answer the question located at the end.
Reasoning with Memorized Facts. To evaluate reasoning using memorized facts and current context, a more complicated task is used where two facts are randomly positioned within the input sequence. The question at the end requires the use of any of these facts to answer correctly, which is based on the Two Argument Relation bAbI task.
Experiments
In all experiments, the authors use the pretrained bert-base-cased model from HuggingFace Transformers as the backbone for RMT, with a memory size of 10. Models are trained using the AdamW optimizer, linear learning rate scheduling, and warmup. Training and evaluation are performed using 4-8 Nvidia 1080ti GPUs, while longer sequences are sped up by switching to a single 40GB Nvidia A100 GPU for evaluation.
Using a training schedule improves accuracy and stability in the experiments. RMT is initially trained on shorter tasks, and upon convergence, the task length is increased by adding another segment. This curriculum learning process continues until the desired input length is reached. Starting with sequences that fit in a single segment, the practical segment size is 499 (+3 special tokens + 10 placeholders = 512). Training on shorter tasks first makes it easier for RMT to solve longer versions, as it converges to the perfect solution using fewer training steps.
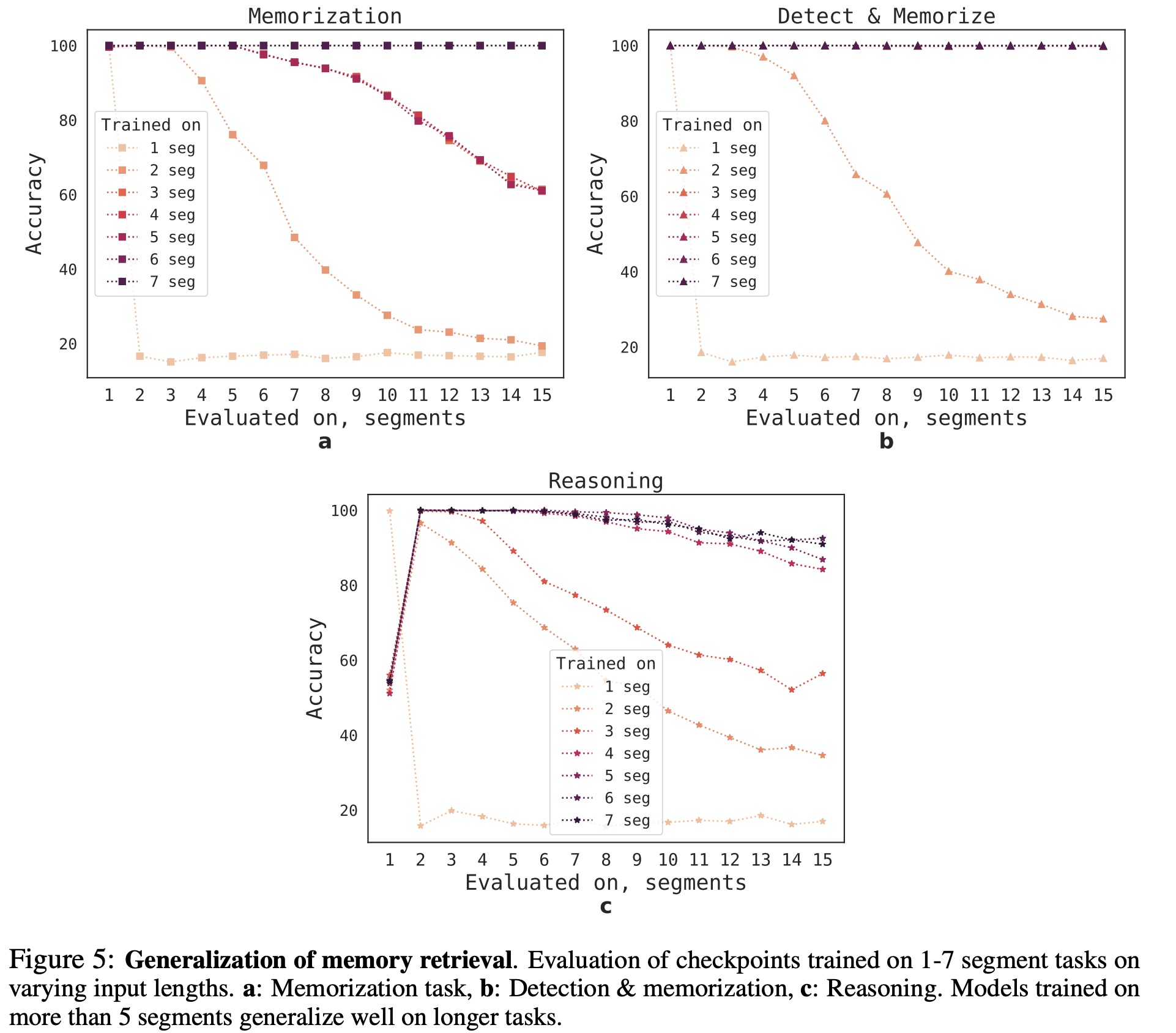
Extrapolation Abilities

RMT’s ability to generalize to different sequence lengths was evaluated by training models on varying numbers of segments and testing them on larger tasks. Models generally perform well on shorter tasks, but single-segment reasoning tasks become challenging when trained on longer sequences. RMT’s ability to generalize to longer sequences improves as the number of training segments grows. When trained on 5 or more segments, RMT can generalize nearly perfectly for tasks twice as long. RMT performs surprisingly well on very long sequences of up to 4096 segments or 2,043,904 tokens, with the Detect & Memorize task being the easiest and the Reasoning task the most complex.
Attention Patterns of Memory Operations
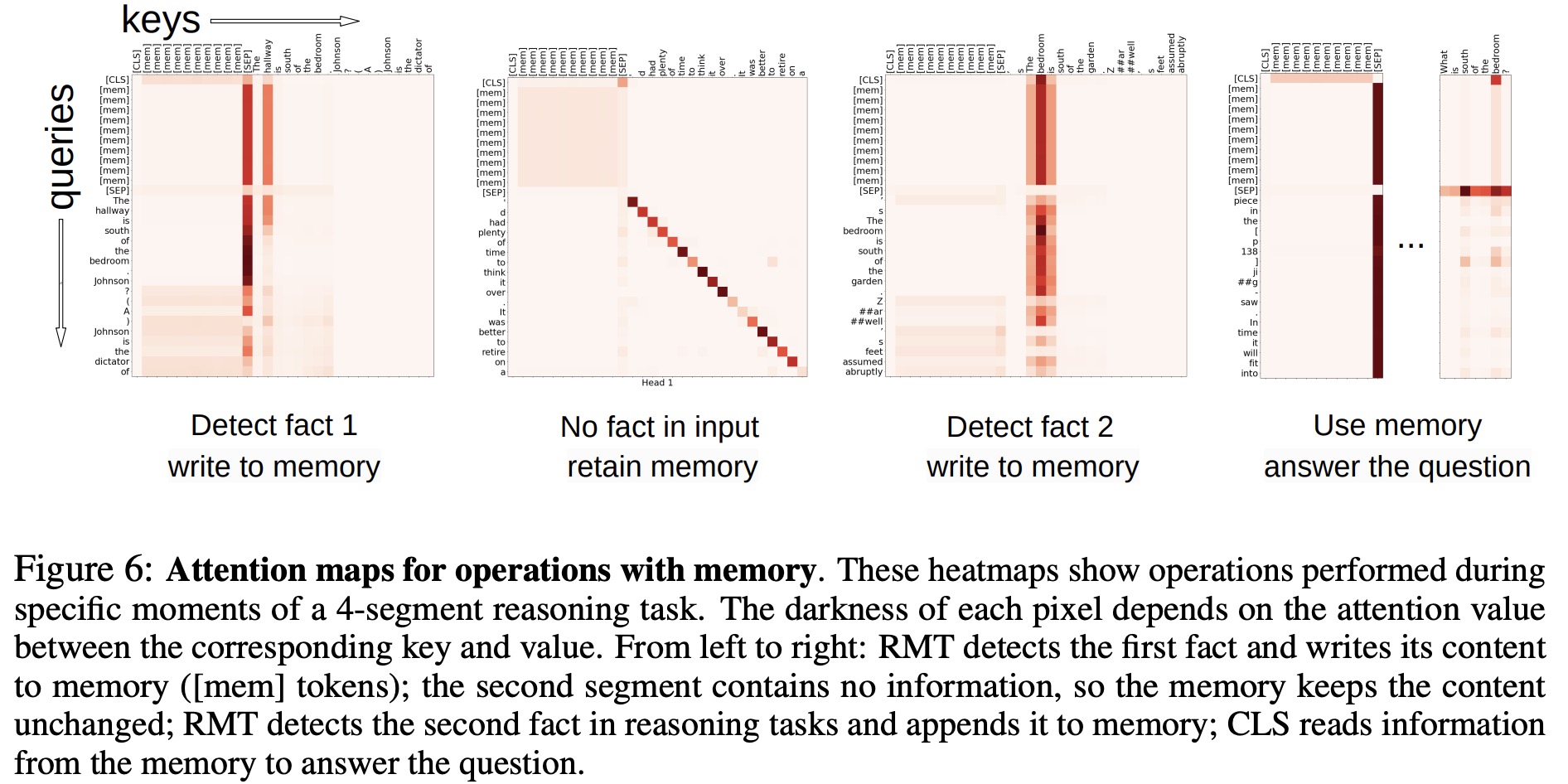
The authors observed that memory operations in RMT correspond to specific attention patterns when examining attention on particular segments. The high extrapolation performance on extremely long sequences demonstrates the effectiveness of learned memory operations, even when used thousands of times. This is impressive, especially since these operations were not explicitly motivated by the task loss.
paperreview deeplearning transformer