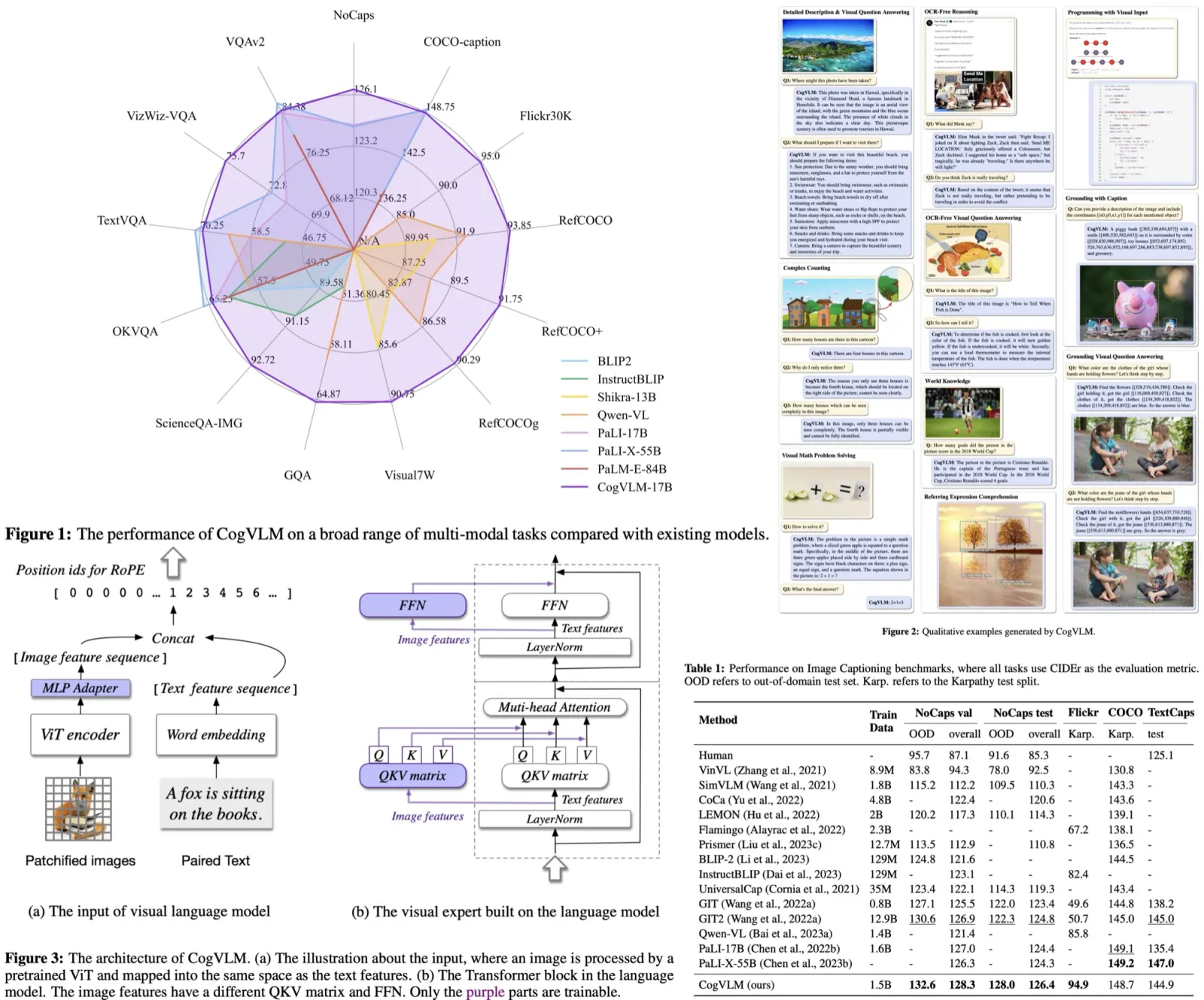
Paper Review: Segment Anything

The Segment Anything project aims to democratize image segmentation in computer vision by introducing a new task, dataset, and model. The project includes the general Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset ever released. The model is promptable and capable of zero-shot transfer to new tasks and image distributions. In addition, it exhibits impressive performance, often outperforming fully supervised methods. The SA-1B dataset is available for research purposes, and the SAM is open-source under the Apache 2.0 license. This initiative seeks to enable a wide range of applications and encourage further research into foundational models for computer vision.
Task

Foundation models in NLP and computer vision allow for zero-shot and few-shot learning for new datasets and tasks through prompting techniques. The promptable segmentation task aims to generate a valid segmentation mask based on a given prompt, which can include spatial or text information to identify an object.
In segmentation, prompts can be points, boxes, masks, text, or any information indicating the object to segment in an image. The promptable segmentation task requires generating a valid segmentation mask for any given prompt. Even when prompts are ambiguous and could refer to multiple objects, the output should provide a reasonable mask for at least one object, akin to a language model producing a coherent response to an ambiguous prompt. This task enables a natural pre-training algorithm and a general method for zero-shot transfer to downstream segmentation tasks through prompting.
The promptable segmentation task offers a natural pre-training algorithm that simulates a sequence of prompts for each training sample and compares the model’s mask predictions against the ground truth. Adapted from interactive segmentation, the goal is to predict a valid mask for any prompt, even when ambiguous. This ensures the pre-trained model is effective in use cases involving ambiguity, such as automatic annotation.
Model
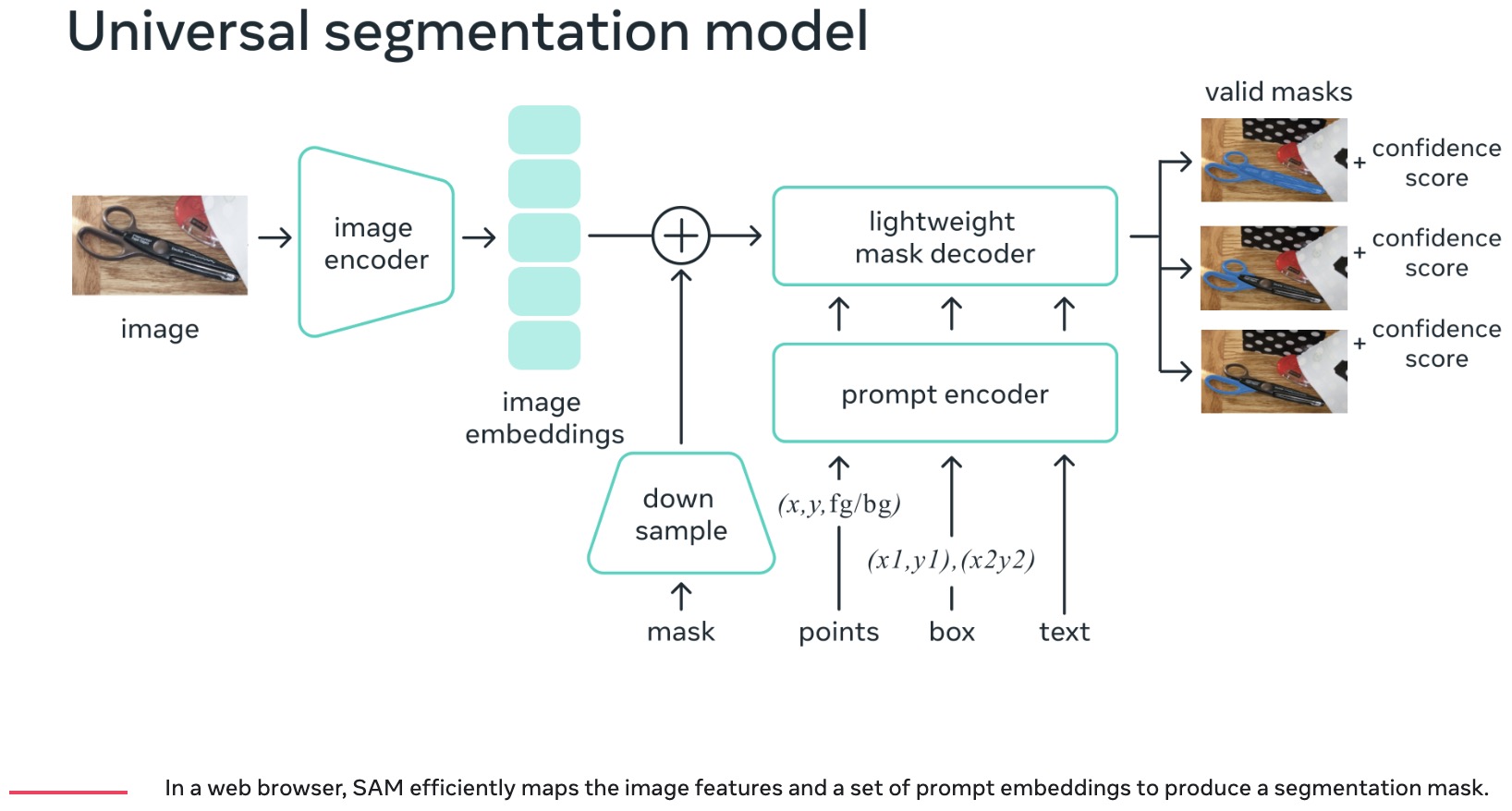
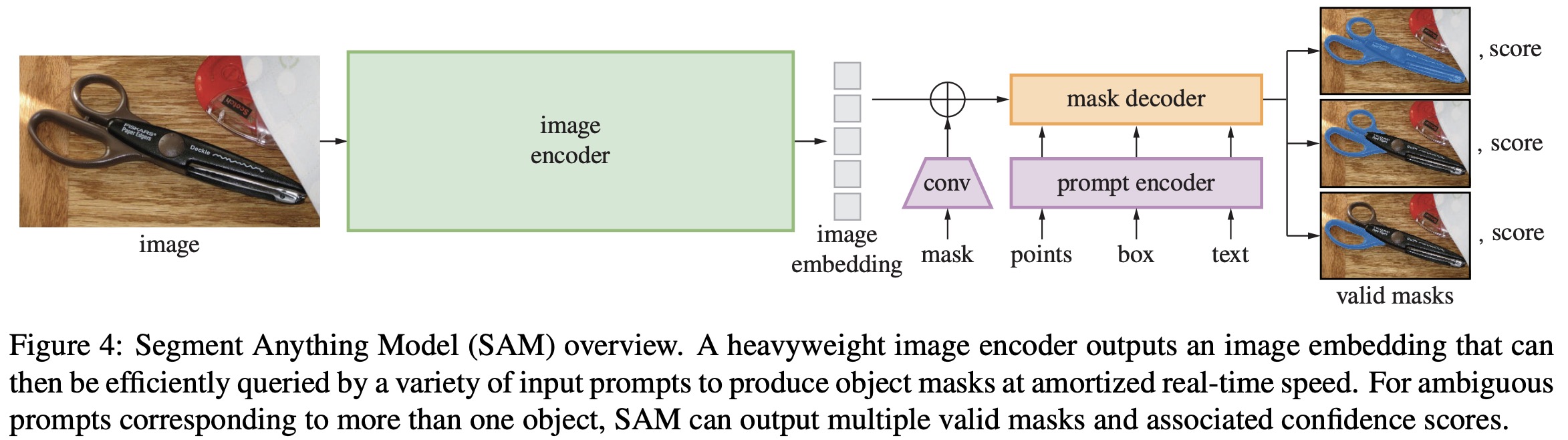
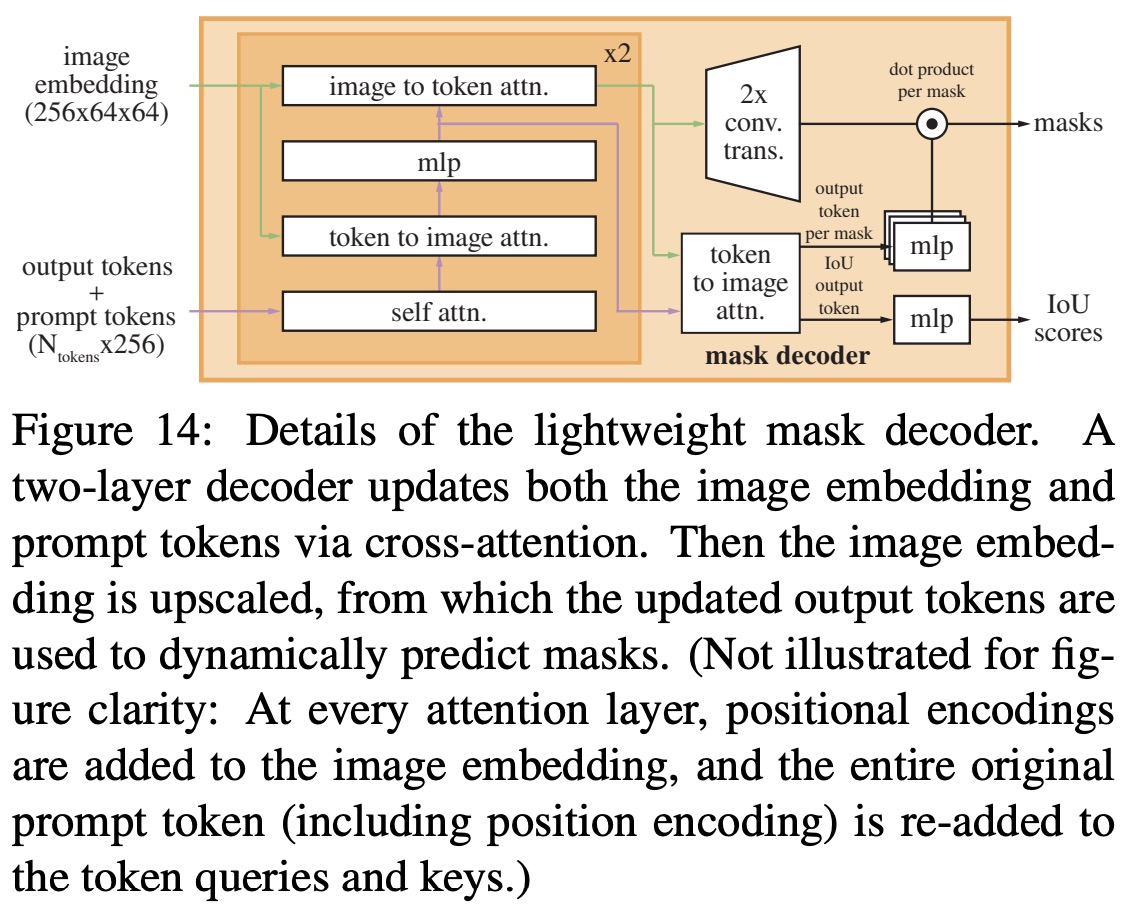
SAM has three components: an image encoder (MAE pre-trained (ViT)), a flexible prompt encoder, and a fast mask decoder.
The authors consider two sets of prompts for segmentation: sparse (points, boxes, text) and dense (masks). Points and boxes are represented using positional encodings combined with learned embeddings for each prompt type, while free-form text uses a text encoder from CLIP. Dense prompts, such as masks, are embedded using convolutions and summed element-wise with the image embedding.
The mask decoder efficiently maps image and prompt embeddings, along with an output token, to a mask. Inspired by previous research, it uses a modified Transformer decoder block followed by a dynamic mask prediction head. The decoder block employs prompt self-attention and cross-attention in both directions (prompt-to-image and image-to-prompt) to update all embeddings. After two blocks, the image embedding is upsampled, and an MLP maps the output token to a dynamic linear classifier, which calculates the mask foreground probability at each image location.
The model is modified to predict multiple output masks for a single ambiguous prompt, with three mask outputs found sufficient to address most common cases. The minimum loss over masks is used during training, while a confidence score is predicted for each mask. Mask prediction is supervised using a linear combination of focal loss and dice loss. The promptable segmentation task is trained using a mixture of geometric prompts and an interactive setup with 11 rounds per mask, allowing seamless integration into the data engine.
Data engine
As segmentation masks are not abundant on the internet, the authors built a data engine to enable the collection of the 1.1B mask dataset, SA-1B. The data engine has three stages:
Assisted-manual stage. In the first stage, professional annotators used a browser-based interactive segmentation tool powered by SAM to label masks by clicking foreground and background object points. The model-assisted annotation ran in real-time, providing an interactive experience. Annotators labeled objects without semantic constraints and prioritized prominent objects. SAM was initially trained on public segmentation datasets and retrained using newly annotated masks, with a total of six retraining iterations. As SAM improved, average annotation time per mask decreased from 34 to 14 seconds, and the average number of masks per image increased from 20 to 44. In this stage, 4.3 million masks were collected from 120,000 images.
In the semi-automatic stage, the aim was to increase mask diversity and improve the model’s segmentation ability. Confident masks were automatically detected and presented to annotators with pre-filled images, who then annotated additional unannotated objects. A bounding box detector was trained on first-stage masks using a generic “object” category. This stage collected an additional 5.9 million masks from 180,000 images, totaling 10.2 million masks. The model was retrained periodically on newly collected data (5 times). The average annotation time per mask increased to 34 seconds for more challenging objects, and the average number of masks per image went from 44 to 72, including the automatic masks.
In the fully automatic stage, annotation became entirely automatic due to two major enhancements: a larger number of collected masks and the development of the ambiguity-aware model. The model was prompted with a 32x32 grid of points and predicted a set of masks for valid objects. The IoU prediction module was used to select confident masks, and only stable masks were chosen. Non-maximal suppression (NMS) was applied to filter duplicates, and overlapping zoomed-in image crops were processed to improve smaller mask quality. The fully automatic mask generation was applied to all 11 million images, resulting in a total of 1.1 billion high-quality masks.
Dataset
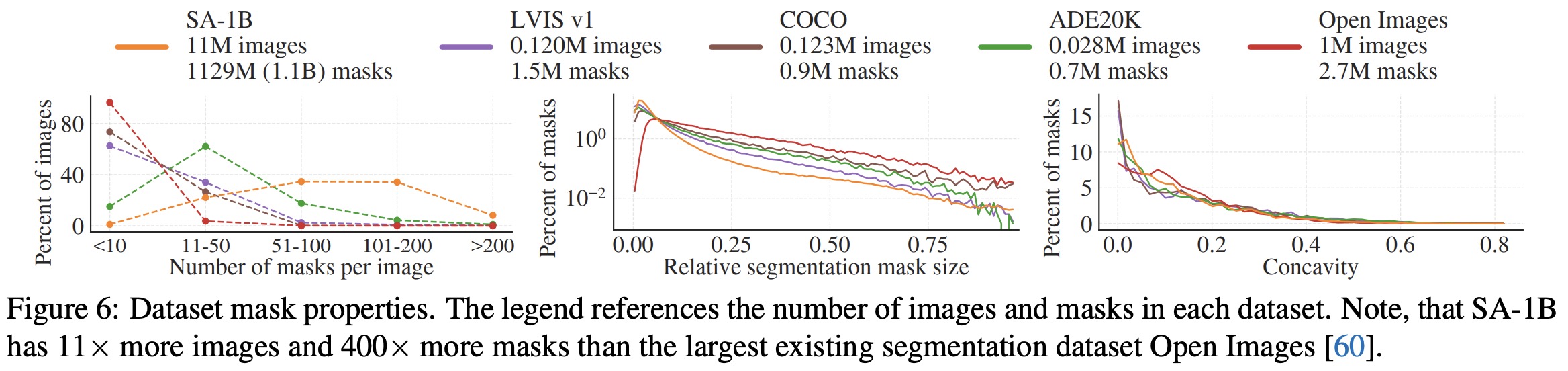
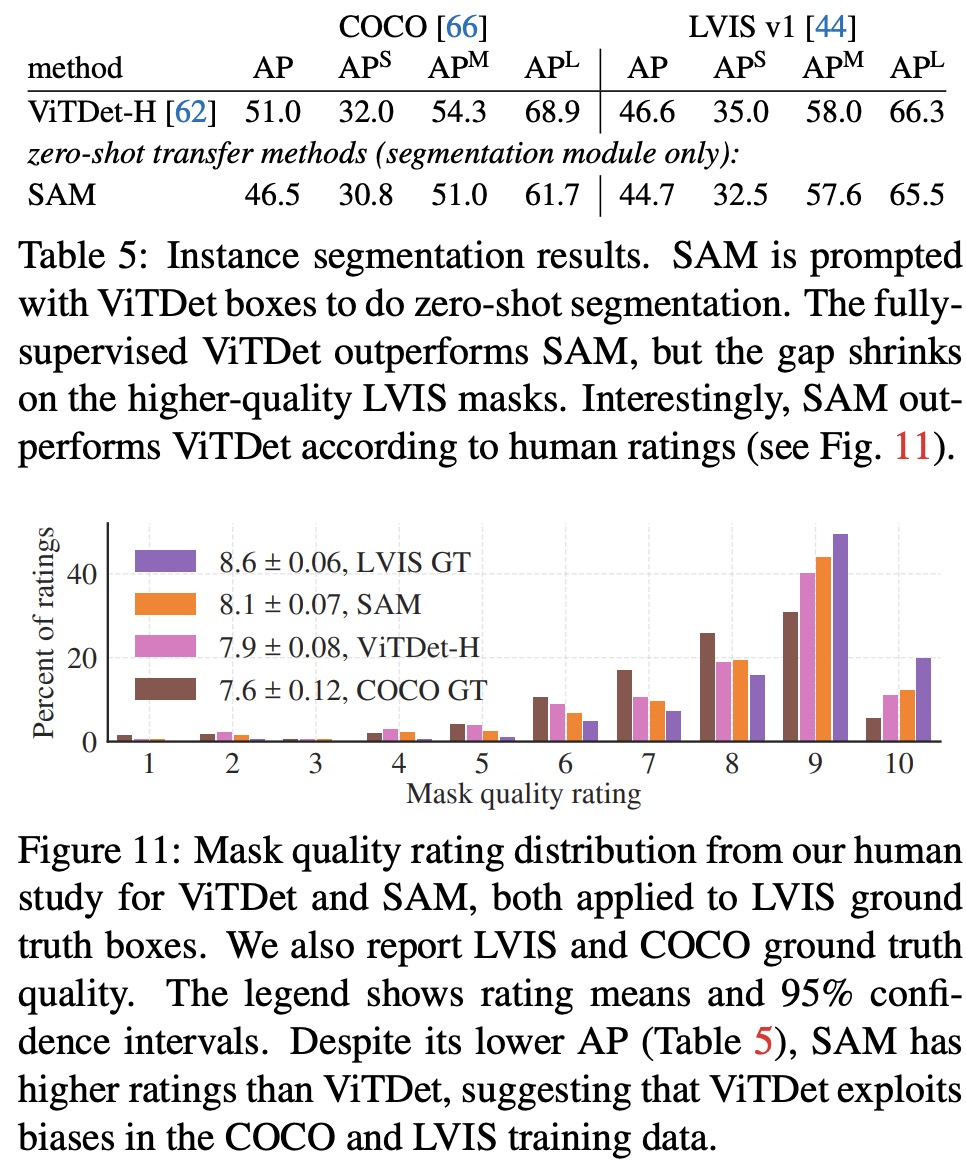
SA-1B is a dataset consisting of 11 million diverse, high-resolution, licensed, and privacy-protecting images and 1.1 billion high-quality segmentation masks. The images have higher resolution (3300×4950 pixels on average, downscaled to 1500) than existing datasets, and faces and vehicle license plates have been blurred. 99.1% of the masks were generated fully automatically, with their quality being a central focus. A comparison of automatically predicted and professionally corrected masks showed that 94% of pairs have over 90% IoU. This high mask quality is also confirmed by human ratings. The spatial distribution of object centers in SA-1B shows greater coverage of image corners compared to other datasets, and SA-1B has significantly more images, masks, and masks per image than other datasets. It also contains a higher percentage of small and medium relative-size masks. The shape complexity of masks in SA-1B is broadly similar to that of other datasets.
Responsible AI Analysis
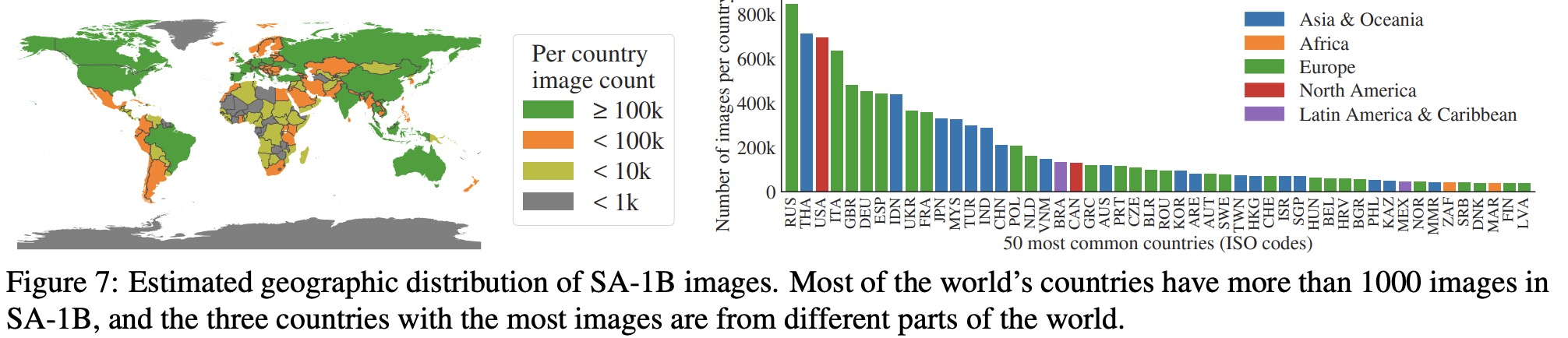
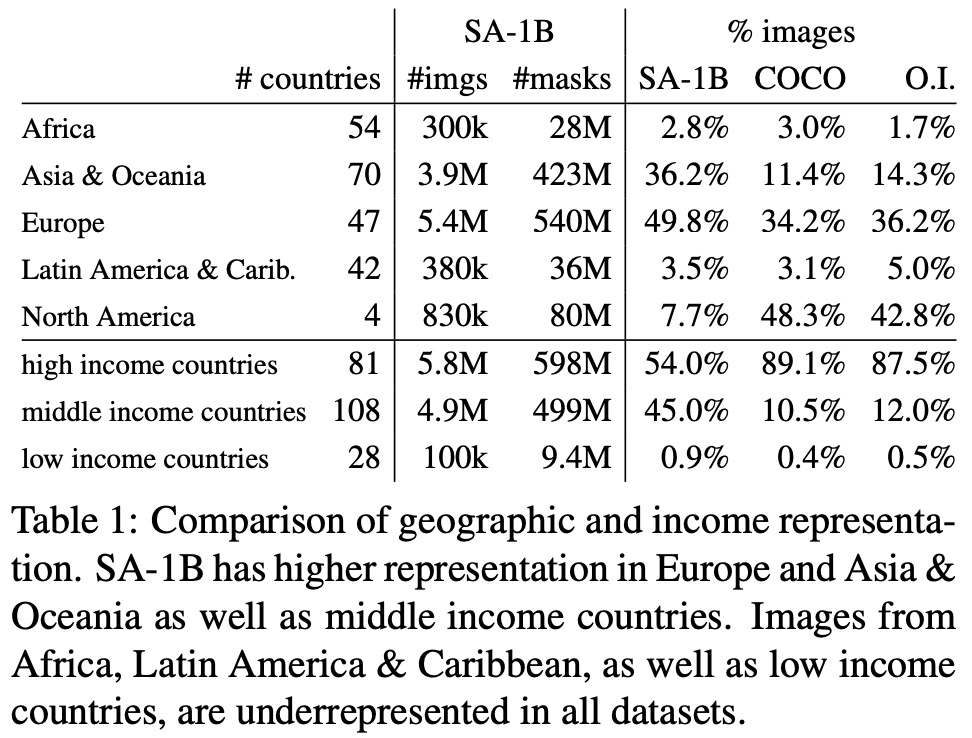
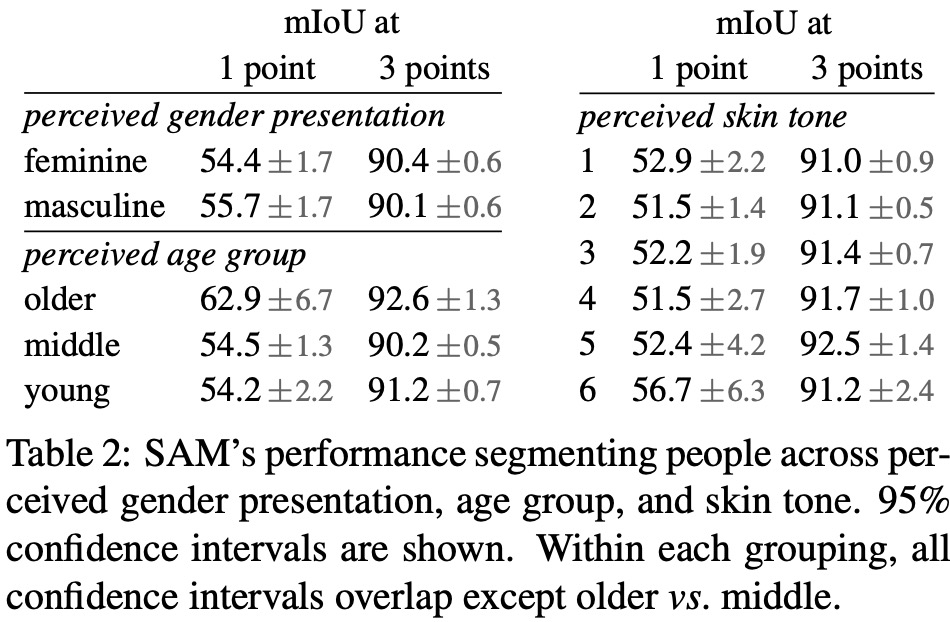
SA-1B has a higher percentage of images from Europe, Asia & Oceania, and middle-income countries, but underrepresents Africa and low-income countries. However, all regions in SA-1B have at least 28 million masks. The dataset’s fairness in segmenting people was investigated across perceived gender presentation, perceived age group, and perceived skin tone. Results indicate that SAM performs similarly across gender and age groups, and no significant difference was found across perceived skin tone groups. However, there may be biases when SAM is used as a component in larger systems, and an indication of bias across perceived gender presentation was found in segmenting clothing.
Zero-Shot Transfer Experiments
Zero-Shot Single Point Valid Mask Evaluation
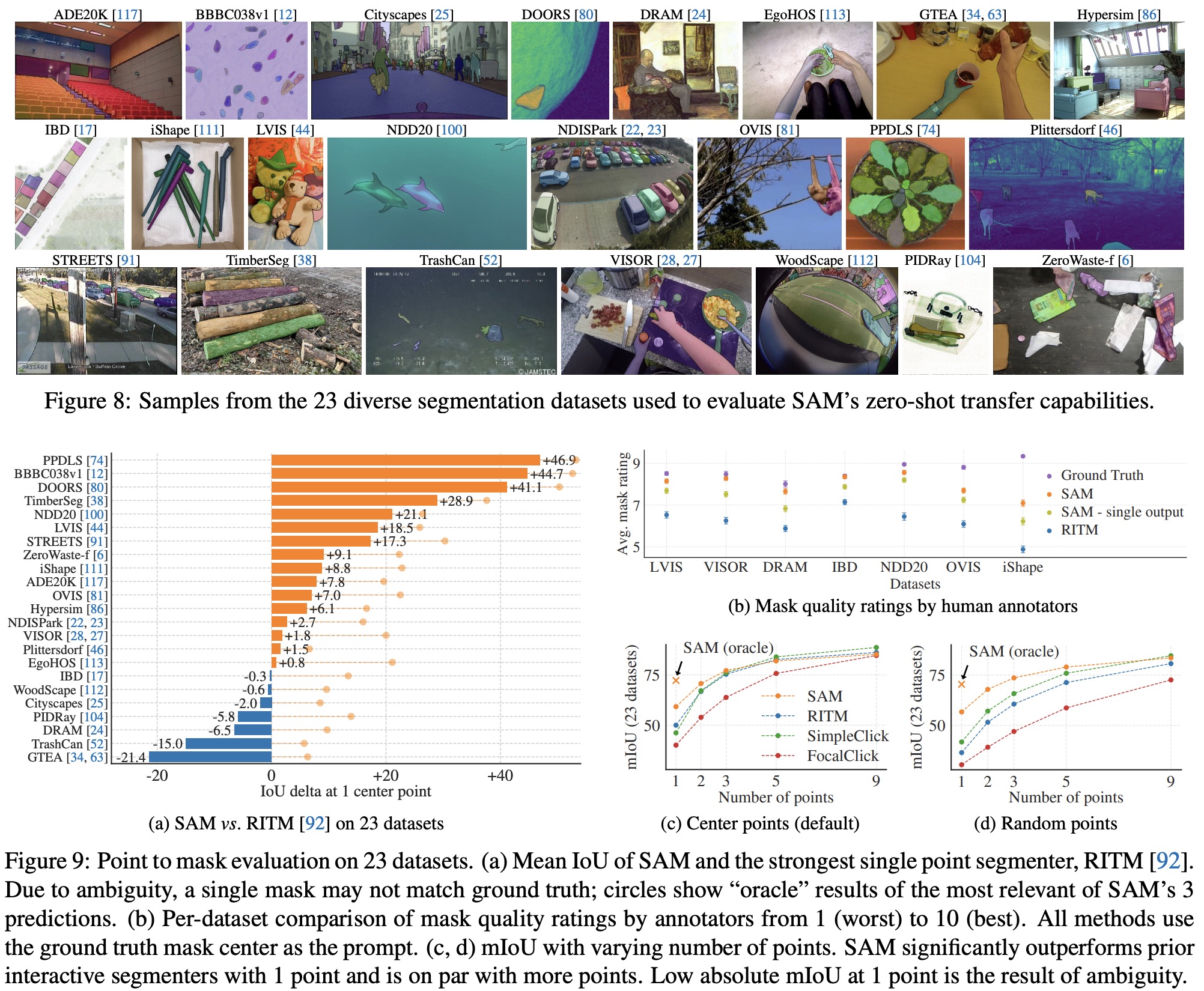
The evaluation focuses on segmenting an object from a single foreground point, which is an ill-posed task as one point can refer to multiple objects. Ground truth masks in most datasets do not enumerate all possible masks, making automatic metrics unreliable. Therefore, the mean Intersection over Union (mIoU) metric is supplemented with a human study in which annotators rate mask quality on a scale of 1 to 10. Points are sampled from the “center” of ground truth masks, following the standard evaluation protocol in interactive segmentation. SAM can predict multiple masks, but the evaluation considers only the model’s most confident mask by default. The main comparison is with RITM, a strong interactive segmenter that performs best on the benchmark compared to other strong baselines.
The results show that SAM outperforms the strong RITM baseline on 16 of the 23 datasets in terms of automatic evaluation using mIoU. With an oracle to resolve ambiguity, SAM outperforms RITM on all datasets. In the human study, annotators consistently rate the quality of SAM’s masks substantially higher than RITM, and an ablated, “ambiguity-unaware” version of SAM still has higher ratings than RITM. Additional baselines, SimpleClick and FocalClick, obtain lower single point performance than RITM and SAM. As the number of points increases, the gap between methods decreases, since the task becomes easier. When the default center point sampling is replaced with random point sampling, the gap between SAM and the baselines grows, and SAM achieves comparable results under either sampling method.
Other experiments
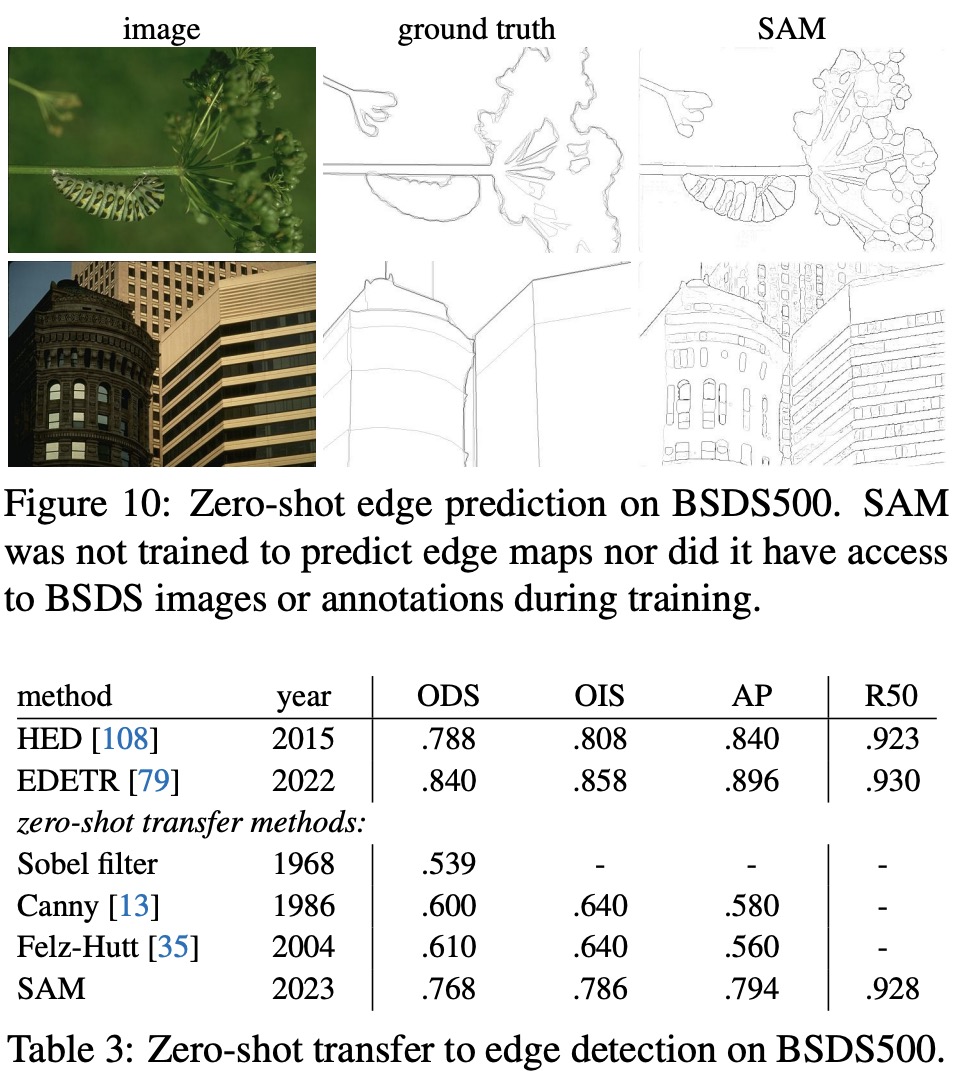
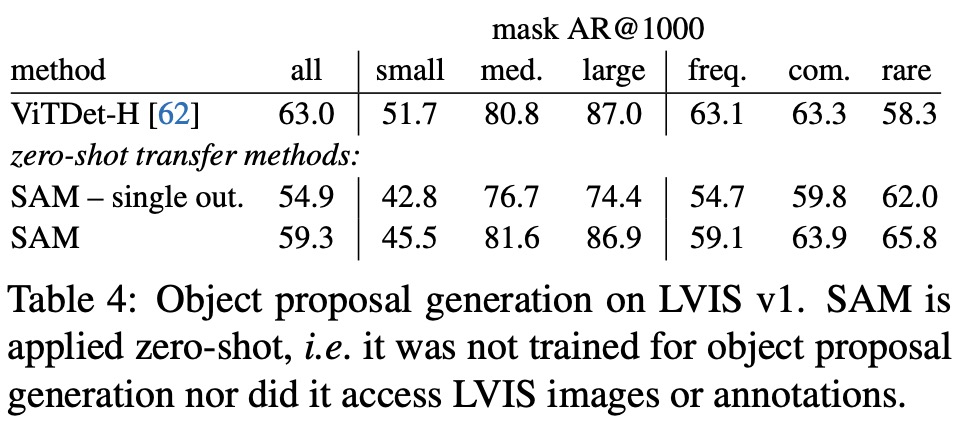

Ablations
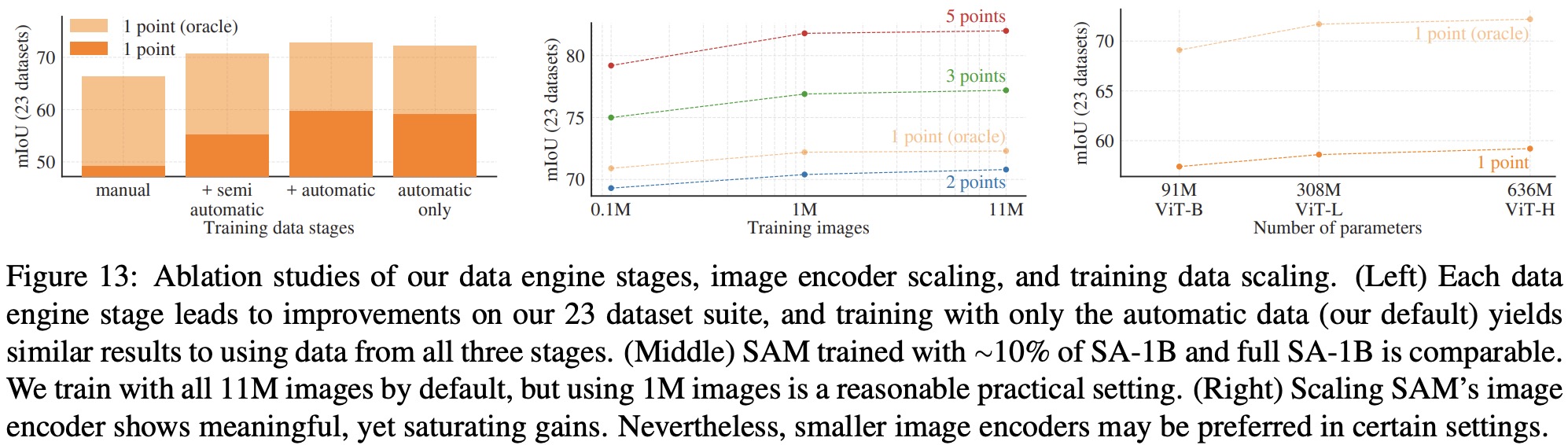
The ablation study investigates the impact of data engine stages and data volume on SAM’s performance. Each stage of the data engine increases mIoU, and oversampling manual and semi-automatic masks by 10x gave the best results. However, using only automatically generated masks resulted in a marginal decrease in mIoU.
A significant mIoU decline is observed if the dataset is decreased to 0.1M images. However, using 1M images (about 10% of the full dataset), the results are comparable to using the full dataset. This data regime, with approximately 100M masks, may be a practical setting for many use cases.
Discussions
The authors align their work with foundation models, emphasizing that SAM’s large-scale supervised training is effective in situations where data engines can scale available annotations. Compositionality is another aspect, as SAM can be used as a component in larger systems, enabling new applications and generalizing to new domains without additional training.
However, SAM has limitations. It can miss fine structures, hallucinate small disconnected components, and produce less crisp boundaries than computationally intensive methods. Dedicated interactive segmentation methods may outperform SAM when provided with many points. SAM’s overall performance is not real-time when using a heavy image encoder. Its text-to-mask task is exploratory and not entirely robust. Additionally, it is unclear how to design simple prompts for semantic and panoptic segmentation, and domain-specific tools may outperform SAM in their respective domains.
paperreview deeplearning cv pytorch imagesegmentation