Paper Review: SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
This paper presents a new method to combine vision foundation models like CLIP, which is adept at semantic understanding, and SAM, which specializes in spatial understanding for segmentation, into a single, more efficient model. This approach uses multi-task learning, continual learning, and teacher-student distillation, requiring less computational power than traditional multi-task training and only a small portion of the original training datasets.
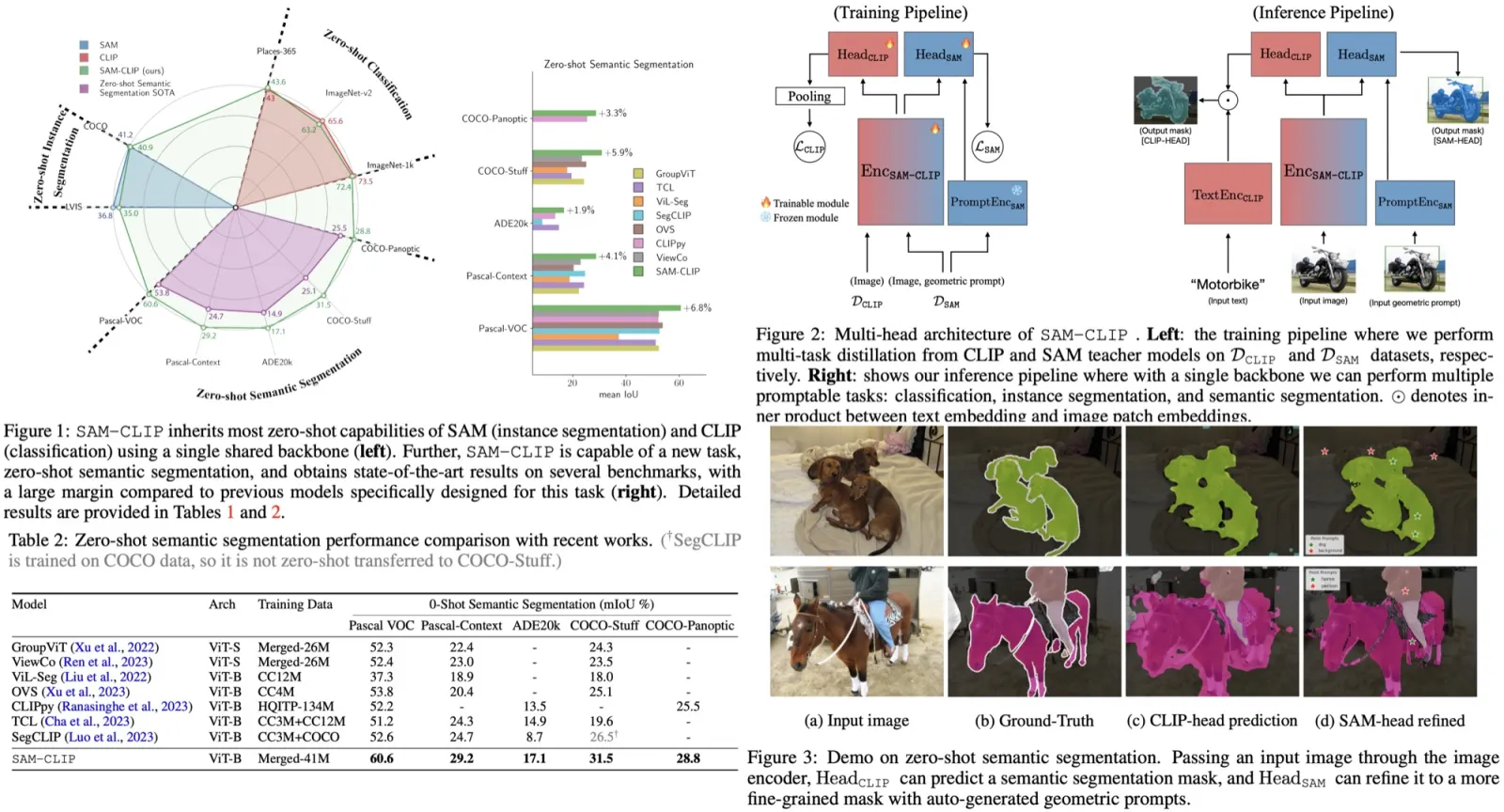
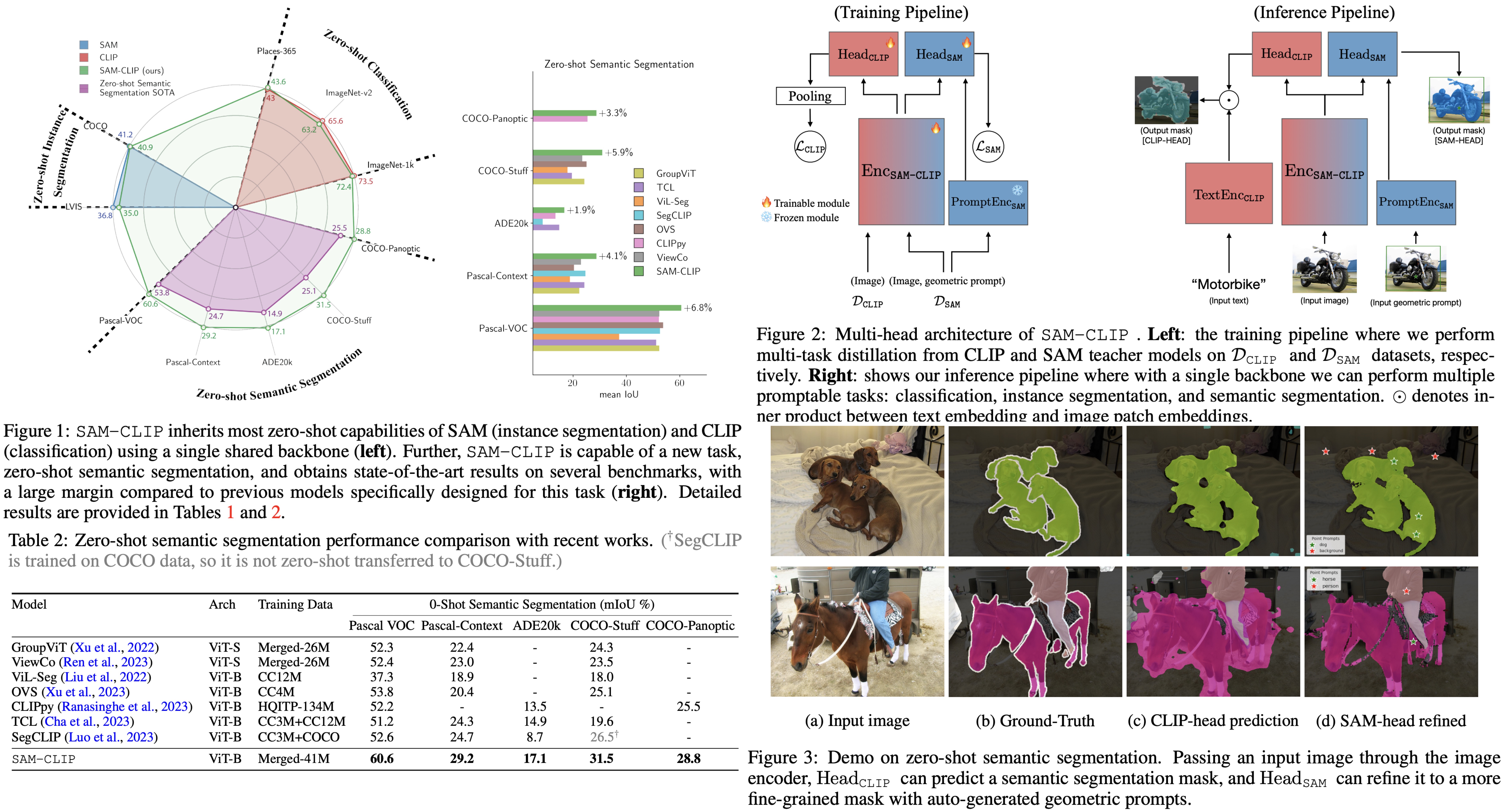
The resulting model, SAM-CLIP, integrates the capabilities of both SAM and CLIP, making it suitable for edge device applications. SAM-CLIP demonstrates enhanced visual representations that encompass both localization and semantic features, leading to better performance on various vision tasks. Notably, it sets new state-of-the-art results in zero-shot semantic segmentation on five benchmarks, significantly outperforming specialized models in this area.
Proposed approach
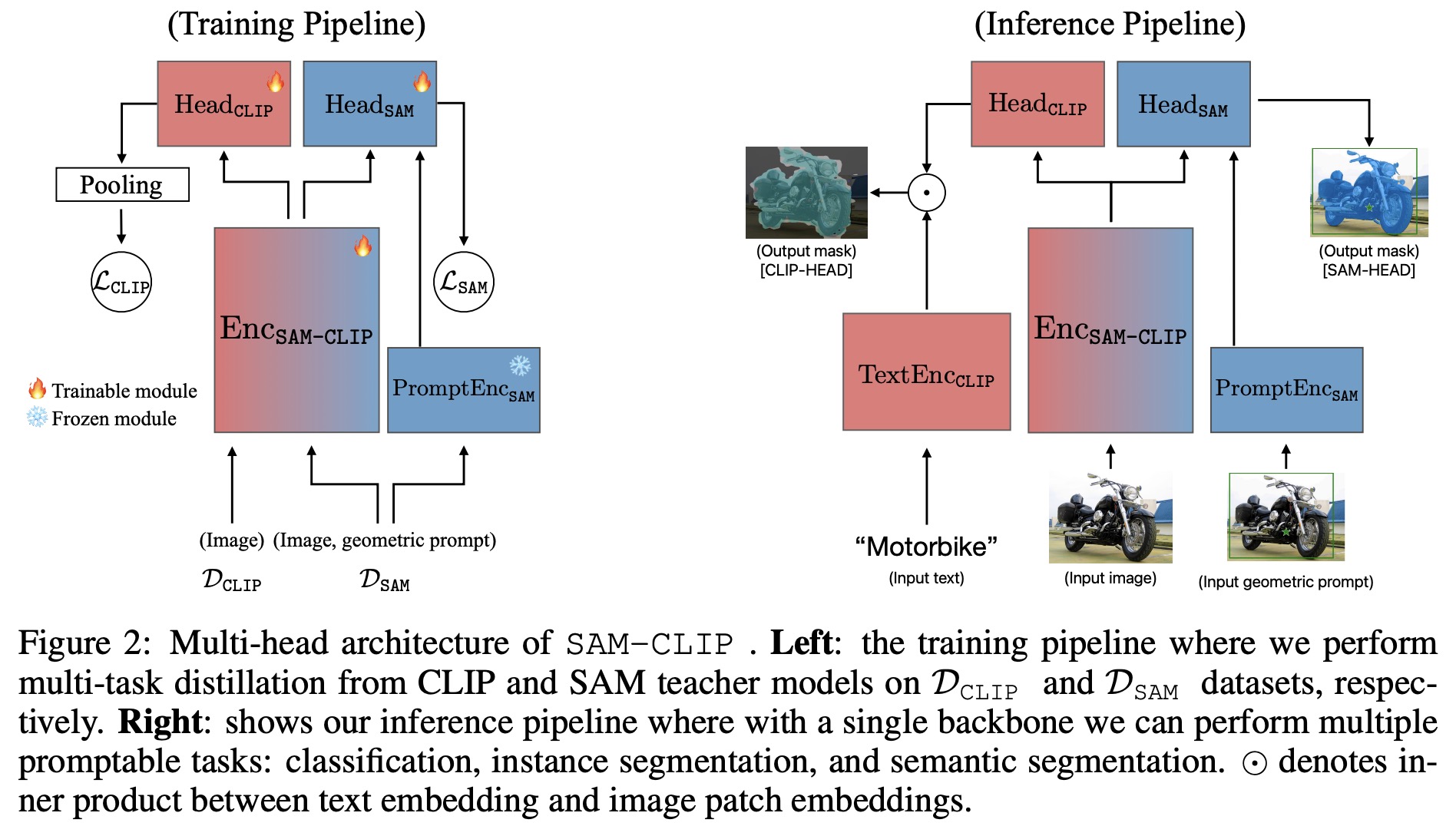
The approach involves using one VFM as a base model and transferring knowledge from other VFMs to it while minimizing the loss of the base model’s original capabilities. SAM is the base model for its spatial understanding and high-resolution image segmentation, and CLIP as the auxiliary VFM for its semantic understanding.
The authors use a multi-head architecture where the base model’s image encoder is merged with the auxiliary’s image encoder to form a single backbone. Lightweight heads for each model are also included, with SAM’s head using its existing mask decoder and CLIP’s head starting from scratch. The approach uses subsets of the original datasets to help the merged model retain the foundational capabilities of both SAM and CLIP.
Initially, a baseline method using knowledge distillation with a cosine distillation loss was applied to transfer CLIP’s semantic understanding to SAM. However, this approach risks catastrophic forgetting of SAM’s original functions. To mitigate this, a rehearsal-based multi-task distillation strategy is used, consisting of:
- Head probing: The image backbone is frozen to prevent forgetting, and only the new head, which is responsible for semantic understanding, is trained.
- Multi-task distillation: Both the new head and the image backbone are trained together. This stage uses a combined loss function from both SAM and CLIP datasets, with a smaller learning rate for the original SAM parameters to reduce forgetting.
Experiments

Implementation details
- The model architecture uses SAM with a ViT-B/16 base, a lightweight head with 3 additional transformer layers is appended to the SAM backbone. This head processes the patch token outputs through a max-pooling layer to create an image-level embedding, which has been found to enhance zero-shot learning capabilities and the learning of spatial features.
- For dataset preparation, a large dataset for CLIP distillation is created by merging images from multiple sources, resulting in a collection of 40.6 million unlabeled images. For SAM self-distillation, a smaller subset (5.7%) is sampled from the SA-1B dataset, which includes 11 million images and 1.1 billion masks, to form DSAM. Validation sets are taken as 1% from both DCLIP and DSAM. The total training dataset, referred to as Merged-41M, consists of approximately 40.8 million images.
- A mixed input resolution strategy is adopted due to the different optimal resolutions for SAM (1024px) and CLIP (typically lower resolutions like 224/336/448px). The training uses variable resolutions for CLIP distillation and a consistent 1024px resolution for SAM distillation. Batches are composed of 2048 images from DCLIP and 32 images from DSAM, each with 32 mask annotations, and training is performed in a multi-task manner.
- After the two-stage training, the model can perform CLIP tasks at lower resolutions and SAM tasks at 1024px. For efficiency, a short finetuning stage adapts the CLIP head to work at 1024px by freezing the image encoder and only finetuning the CLIP head for 3 epochs.
- Zero-Shot Image Classification: Tested on ImageNet, ImageNet-v2, and Places365 at a resolution of 224x, SAM-CLIP achieved zero-shot accuracy comparable to state-of-the-art CLIP models, validating the effectiveness of the model’s merging approach.
- Zero-Shot Instance Segmentation: Using the COCO and LVIS datasets, SAM-CLIP was evaluated for instance segmentation, a task where the original SAM model is particularly strong. The model used bounding boxes from a ViT-Det model as geometric prompts for the prompt encoder to predict masks. SAM-CLIP’s performance was very close to the original SAM, indicating it retained its segmentation capabilities without significant forgetting.
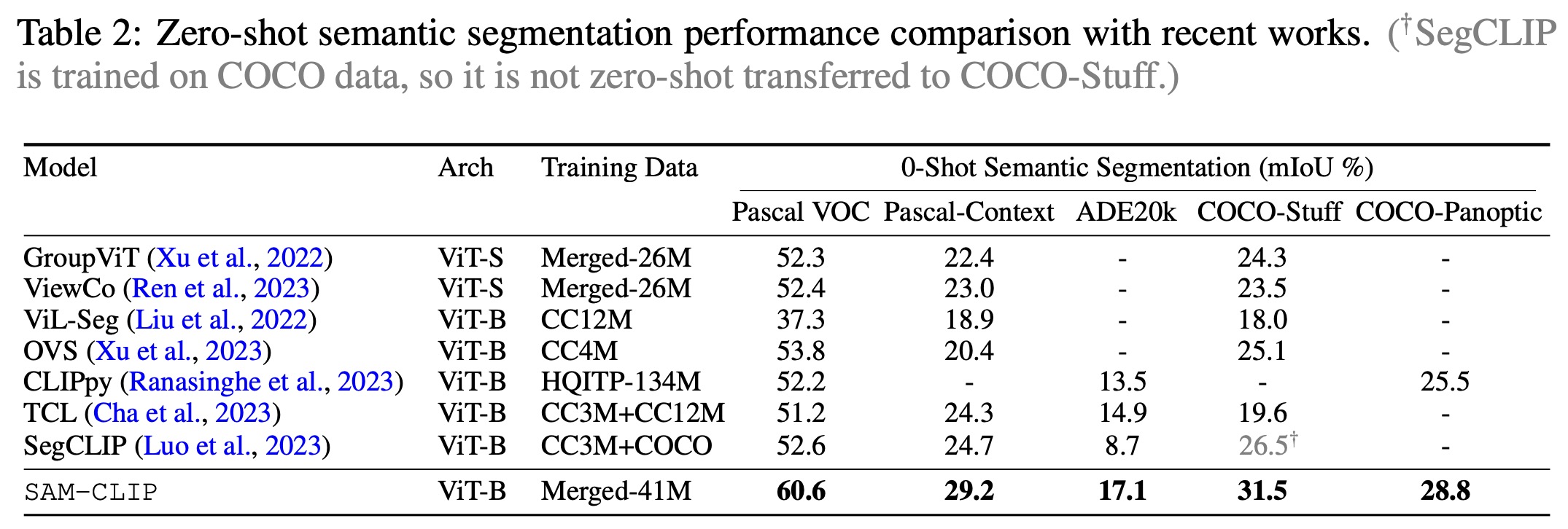
- Zero-Shot Transfer to Semantic Segmentation: SAM-CLIP was also tested on zero-shot semantic segmentation across five datasets: Pascal VOC, Pascal Context, ADE20k, COCO-Stuff, and COCO-Panoptic. Using a common protocol and OpenAI’s pre-defined CLIP text templates for mask prediction, SAM-CLIP set new state-of-the-art performance on all five datasets, outperforming previous models by a substantial margin.

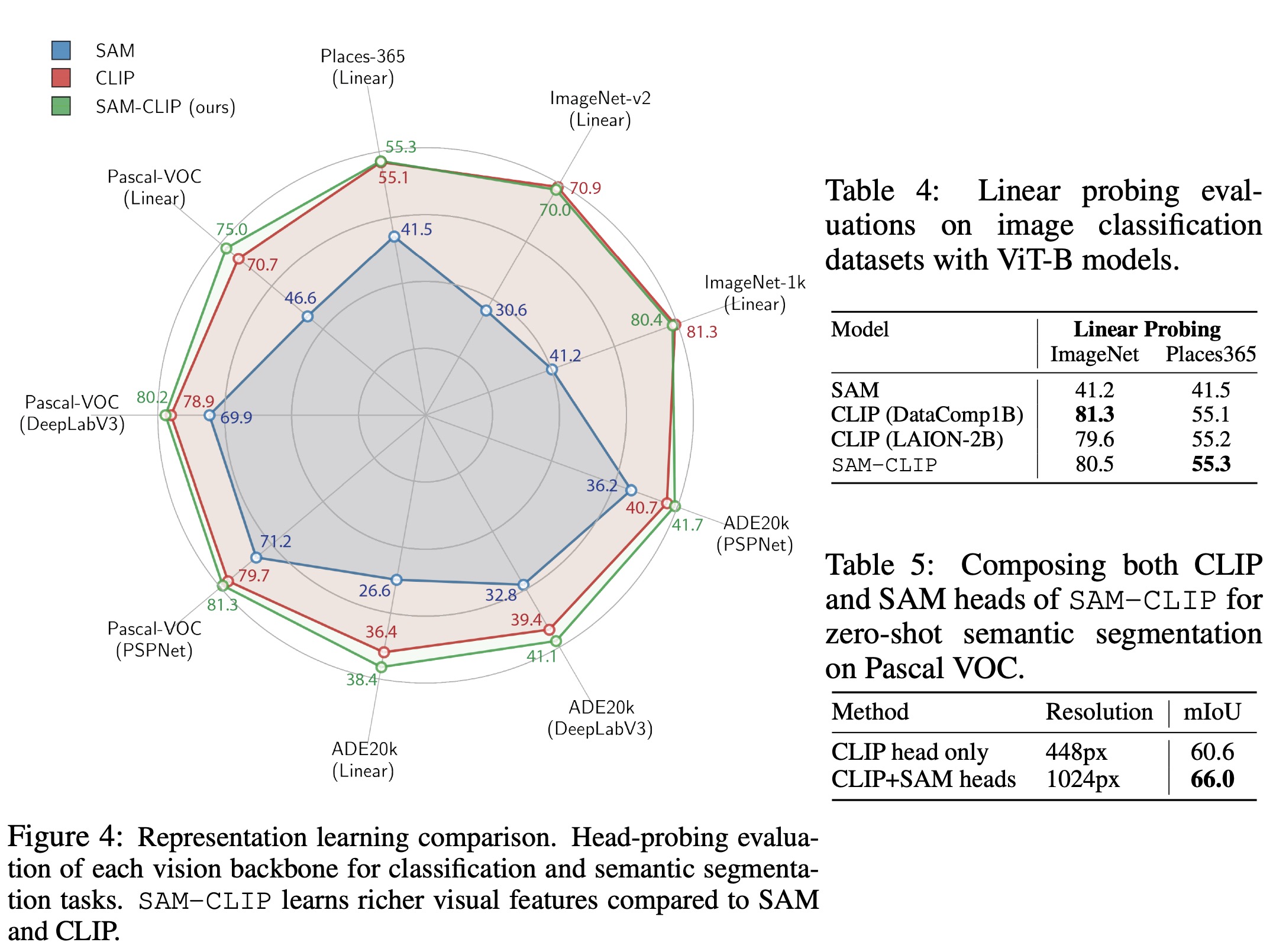
The merged SAM-CLIP model was hypothesized to combine the strengths of SAM’s spatial detail capture for segmentation tasks and CLIP’s high-level semantic information processing. This was tested through head-probing evaluations on different segmentation head structures and datasets. The results confirmed that SAM-CLIP outperformed both parent models in semantic segmentation tasks, showcasing superior visual feature representation capabilities.
Additionally, linear probing for image classification tasks on ImageNet and Places365 showed that SAM-CLIP’s image-level representations are on par with those of CLIP, indicating that it has effectively learned image-level features. These findings suggest that SAM-CLIP is a robust model for a broad range of vision tasks, effectively integrating the advantages of both SAM and CLIP models.