Paper Review: Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
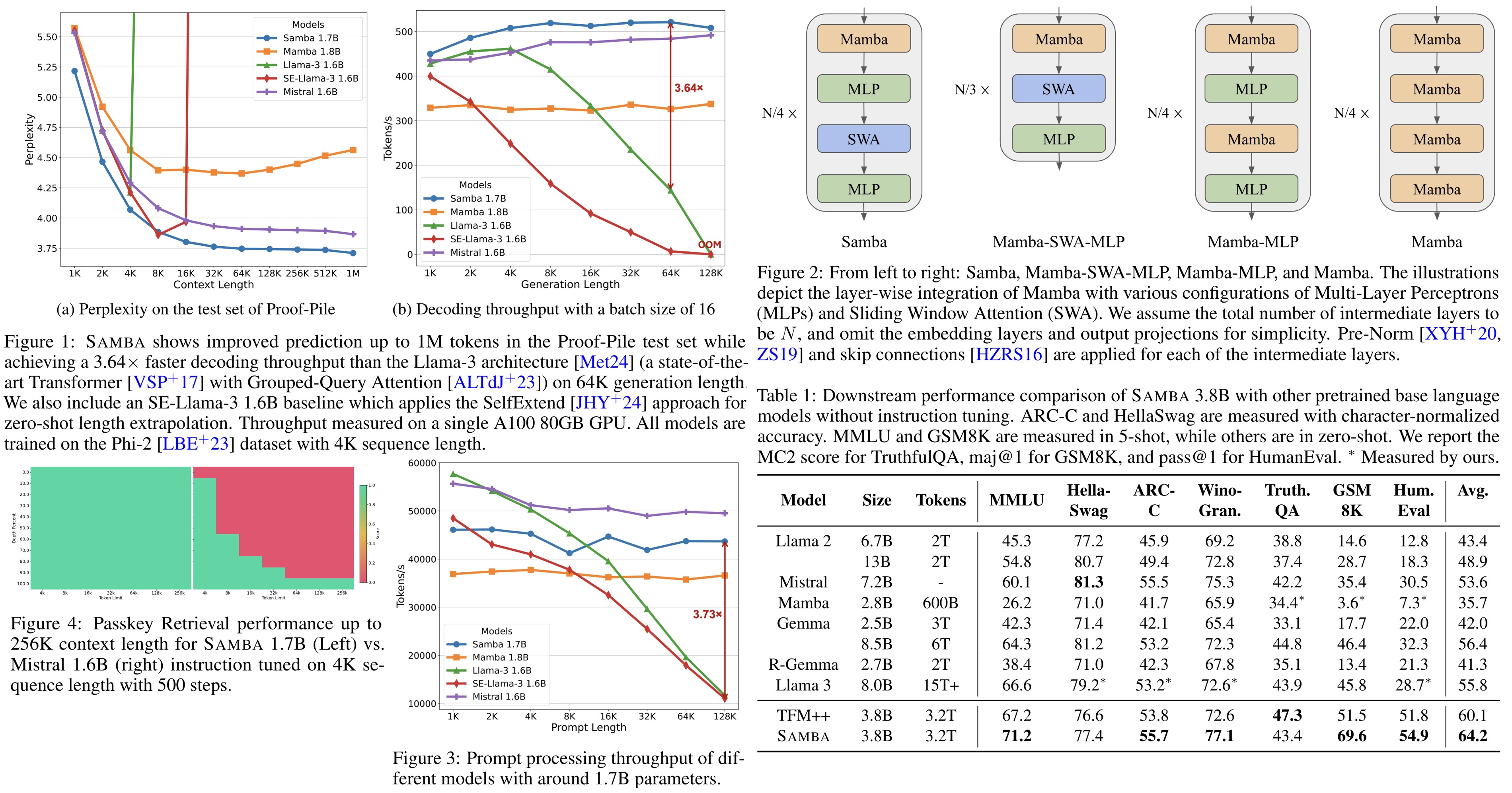
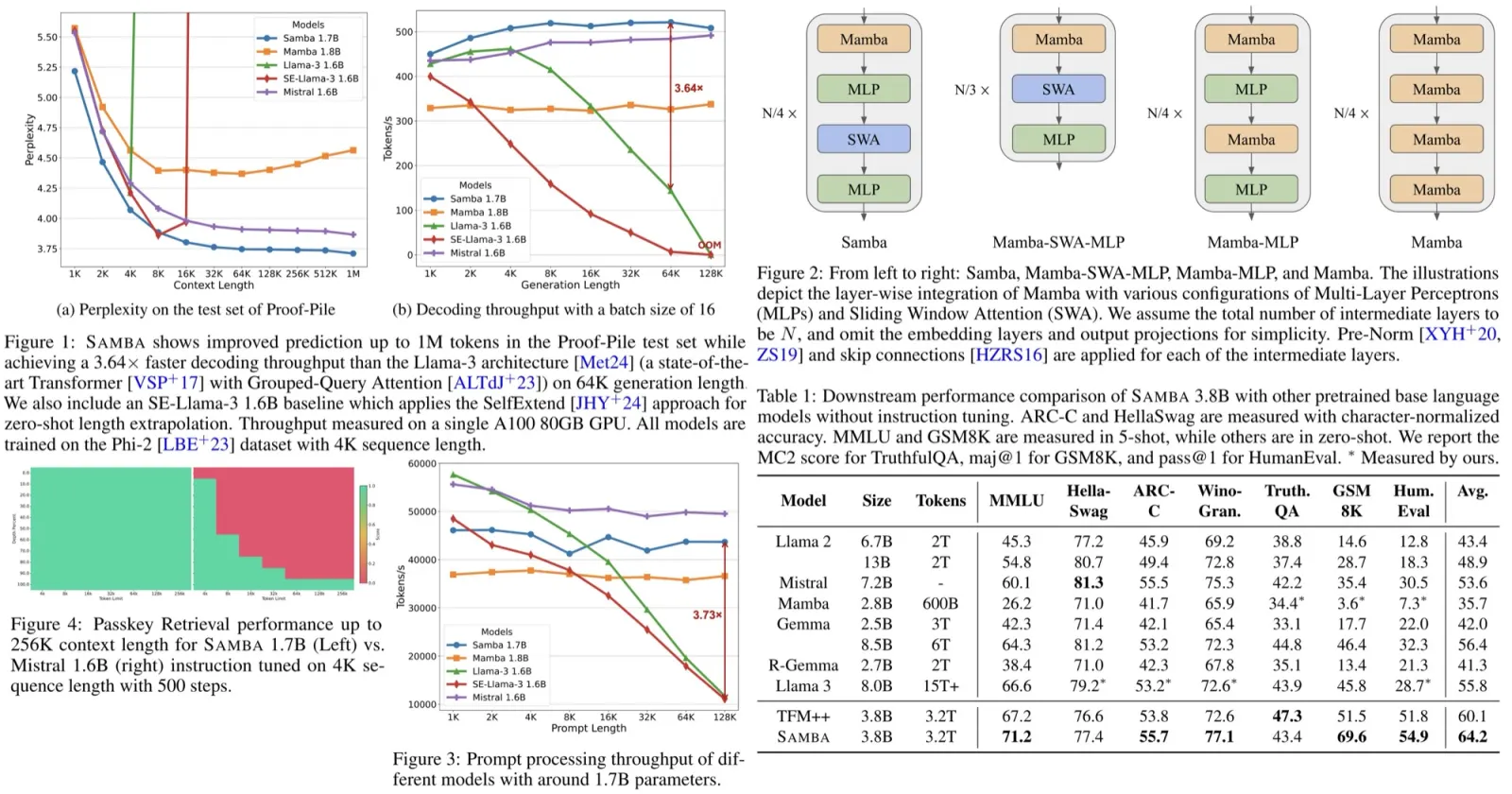
Samba is a new hybrid architecture designed to efficiently model sequences with infinite context length. It combines Mamba, a selective State Space Model, with Sliding Window Attention. This allows SAMBA to compress sequences into recurrent hidden states while retaining precise memory recall through attention mechanisms. With 3.8 billion parameters and training on 3.2 trillion tokens, SAMBA significantly outperforms state-of-the-art models based on pure attention or SSMs across various benchmarks. It can efficiently extrapolate from 4K length sequences to 256K context length with perfect memory recall and improve token predictions up to 1 million context length. SAMBA achieves 3.73× higher throughput compared to Transformers with grouped-query attention for processing 128K length prompts and a 3.64× speedup when generating 64K tokens with unlimited streaming.
The approach
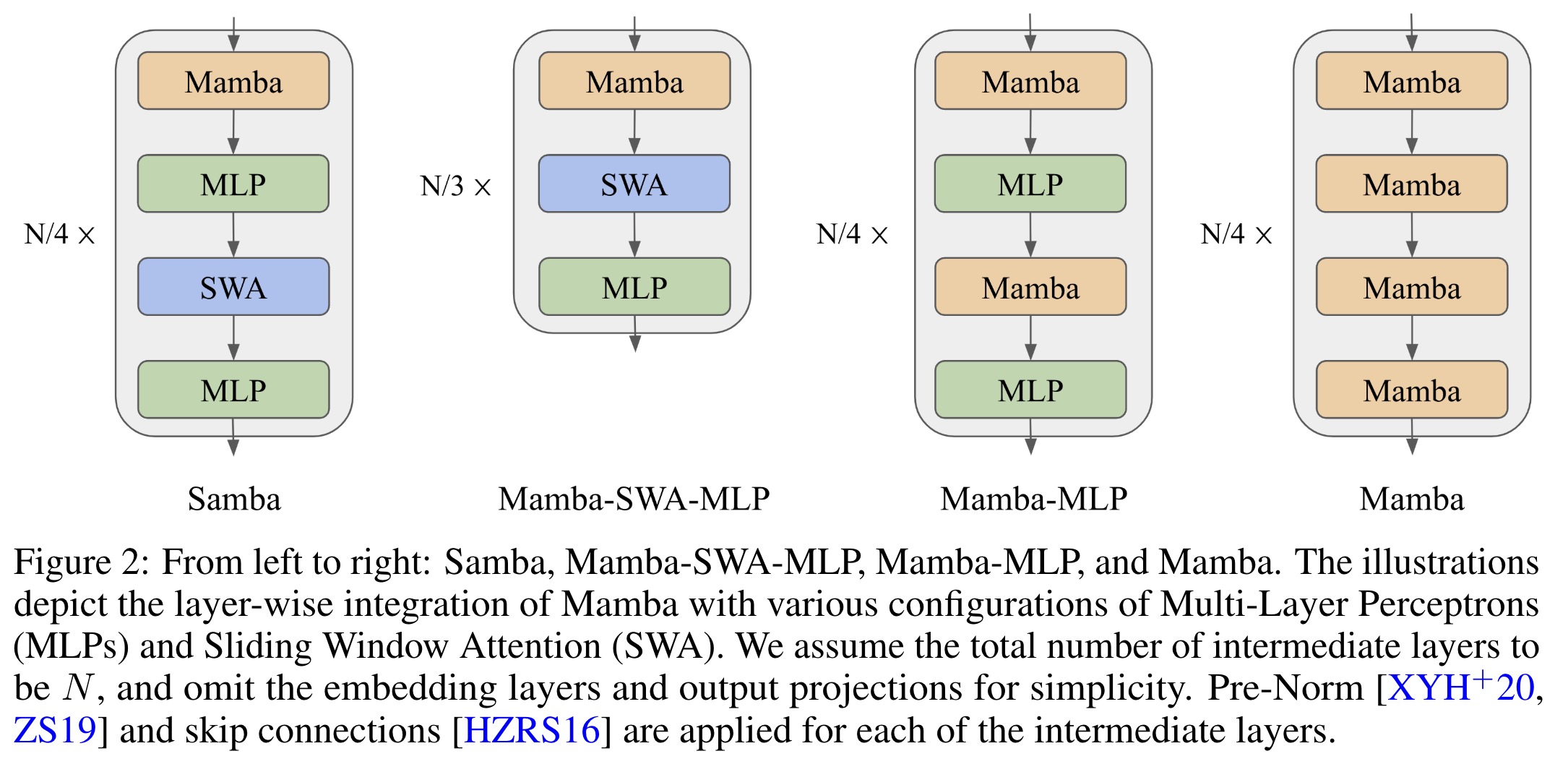
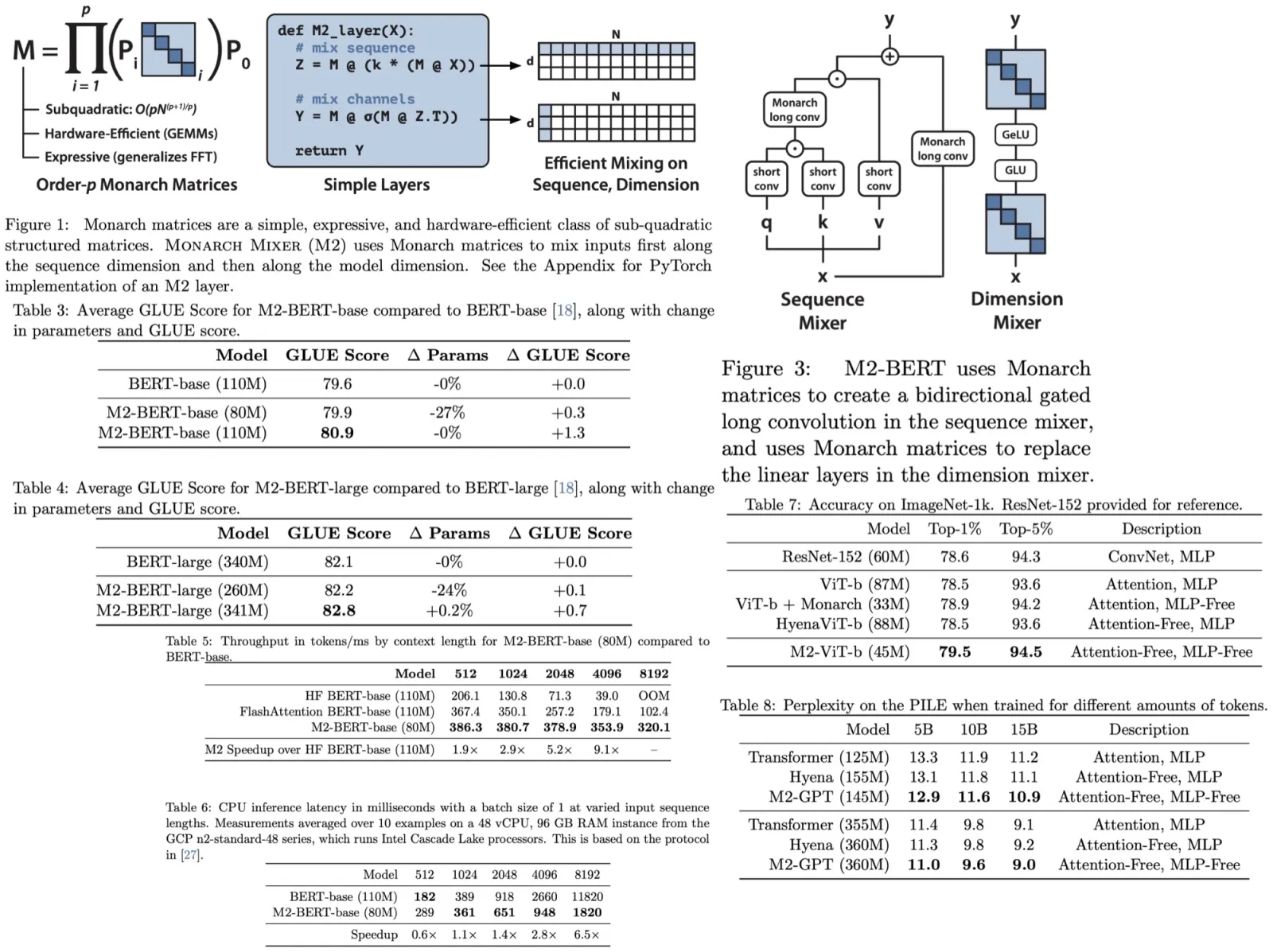
Mamba is a recently proposed model based on selective state spaces. It employs input-dependent gating to selectively process elements of an input sequence. Mamba first expands the input sequence to a higher dimension using a learnable projection matrix. A Short Convolution operator is then applied to smooth the input signal, followed by Depthwise Convolution and SiLU activation.
The model calculates a selective gate through a low-rank projection and Softplus activation, initializing parameters to ensure the gate values remain within a specific range. For each time step, the recurrent inference of the Selective SSM is performed in an expanded state space, combining previous states with current inputs through a series of point-wise and outer product operations. The final output is obtained using a gating mechanism similar to the Gated Linear Unit.
Mamba’s layer in Samba captures the time-dependent semantics of input sequences through its recurrent structure and input selection mechanism, enabling the model to focus on relevant inputs and memorize important information over the long term.
The Sliding Window Attention layer is designed to overcome the limitations of the Mamba layer in capturing non-Markovian dependencies in sequences. Operating on a window size of 2048 that slides over the input sequence, SWA maintains linear computational complexity relative to sequence length. It applies RoPE relative positions within the window, allowing the model to retrieve high-definition signals from the middle to short-term history that Mamba’s recurrent states cannot capture clearly. SWA uses FlashAttention 2 for efficient self-attention implementation. The 2048 window size is chosen for efficiency, providing similar training speed to Mamba’s selective parallel scan at this sequence length.
Experiments
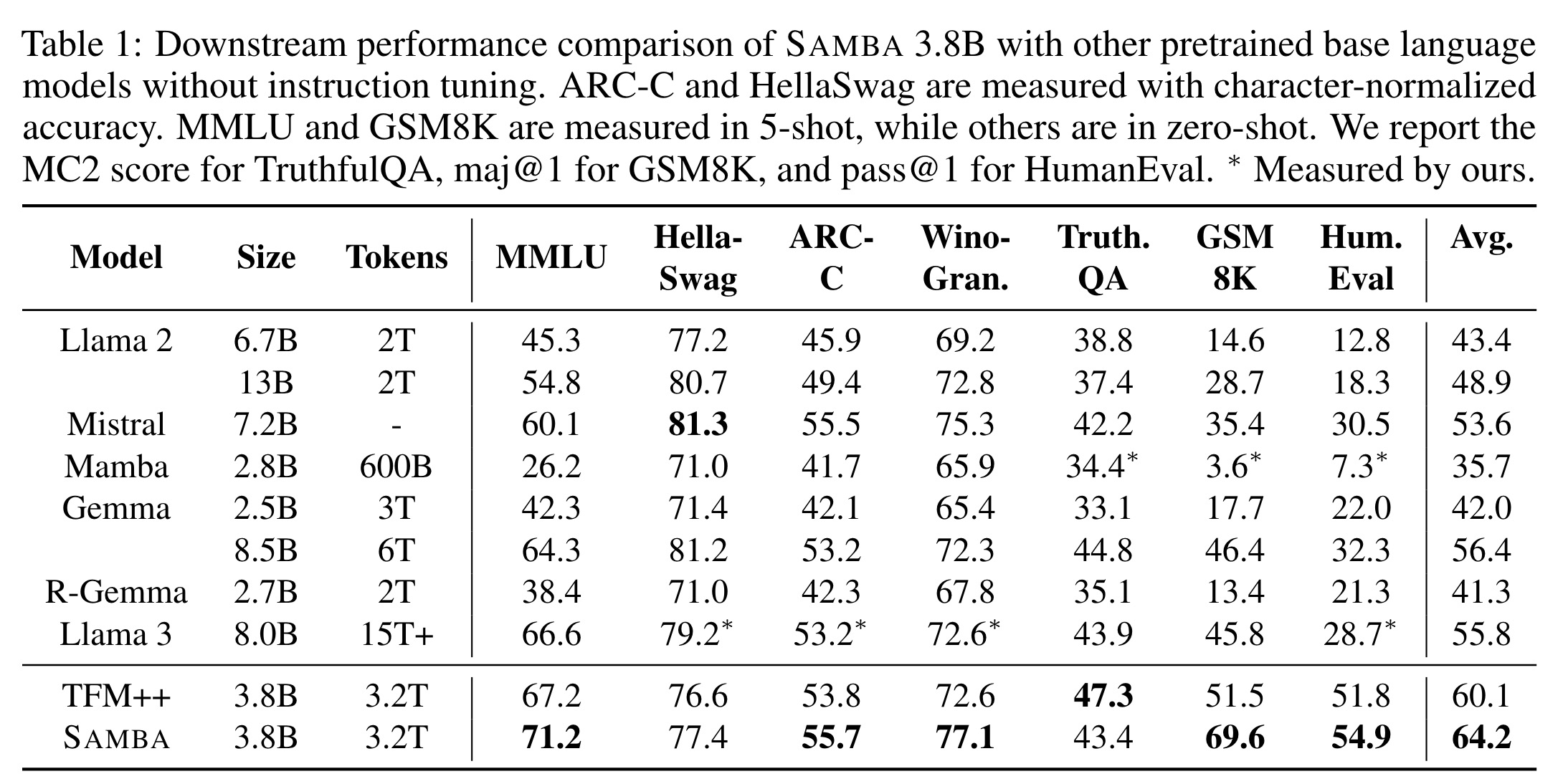
Samba outperforms several strong baselines, including Llama 2, Mistral, Mamba, Gemma, Recurrent-Gemma, Llama 3, and TFM++. It achieves the highest average scores on all benchmarks and excels in the GSM8K benchmark with an 18.1% higher accuracy than TFM++.
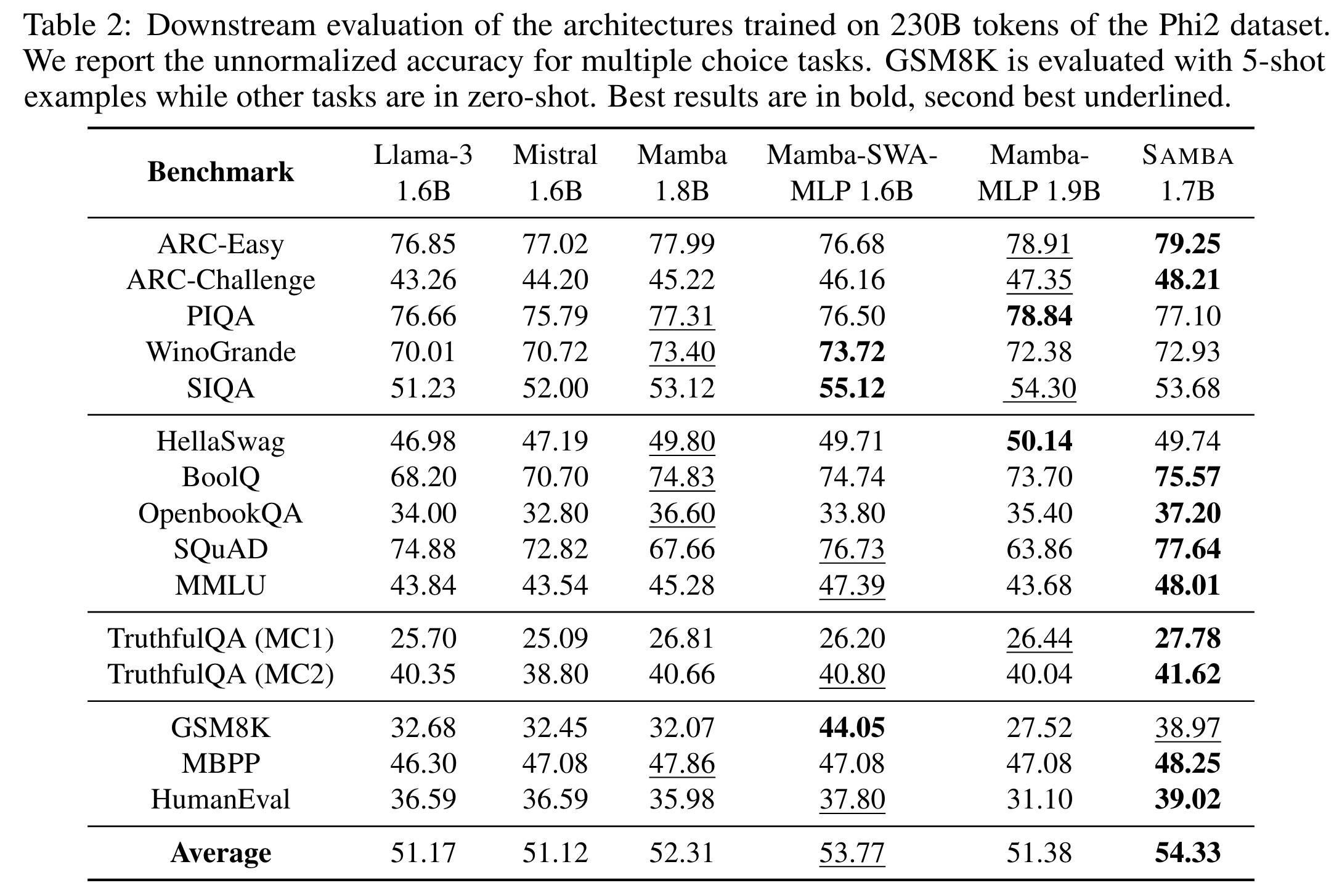
In an evaluation of six models with around 1.7B parameters on the Phi2 dataset, Samba demonstrated superior performance across 15 downstream benchmarks, including commonsense reasoning, language understanding, TruthfulQA, and code generation. Samba outperformed both pure attention-based and SSM-based models in most tasks, achieving the best average performance.
Replacing Mamba blocks with MLPs did not harm commonsense reasoning but significantly reduced performance in language understanding and complex reasoning tasks. Pure Mamba models struggled with retrieval-intensive tasks like SQuAD due to their lack of precise memory retrieval ability. The best results were achieved through the combination of attention and Mamba modules in the Samba architecture. The Mamba-SWA-MLP combination showed significantly better performance on GSM8K, indicating effective collaboration between Mamba and SWA layers.
Exploration on Attention and Linear Recurrence
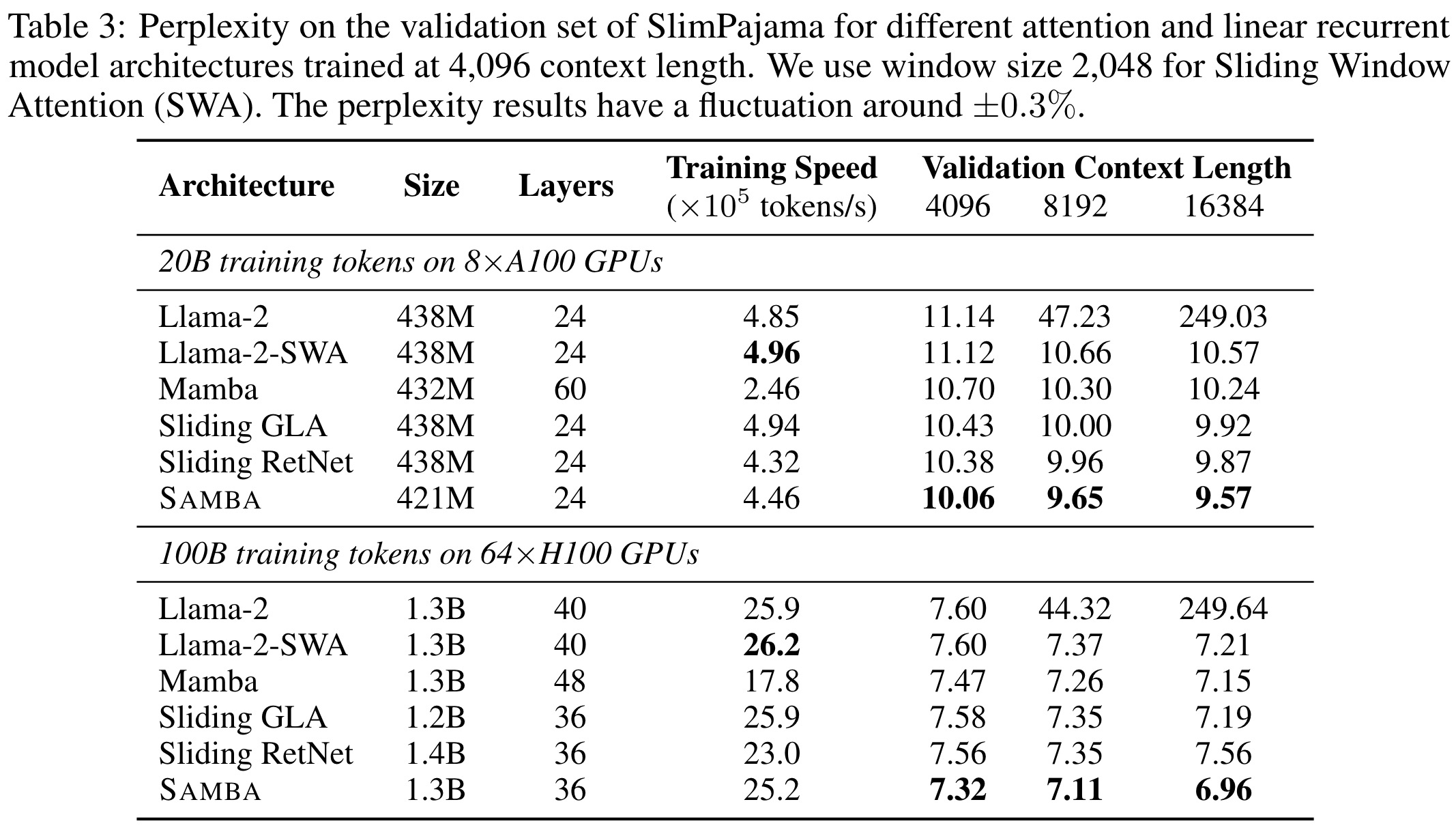
There are other models combining attention layers with recurrent:
- Llama-2 is an attention-based Transformer with full self-attention across the entire sequence.
- Llama-2-SWA is an attention-based architecture that replaces all full attention layers with sliding window attention.
- Sliding RetNet replaces Mamba layers in the Samba architecture with Multi-Scale Retention layers. RetNet is a linear attention model with fixed and input-independent decay applying to the recurrent hidden states.
- Sliding GLA replaces Mamba layers in the Samba architecture with Gated Linear Attention. GLA is a more expressive variant of linear attention with input-dependent gating.
Samba consistently outperforms all other models across different context lengths and model sizes. Its training speed is competitive with pure Transformer-based models at the 1.3B scale.
Efficient Length Extrapolation
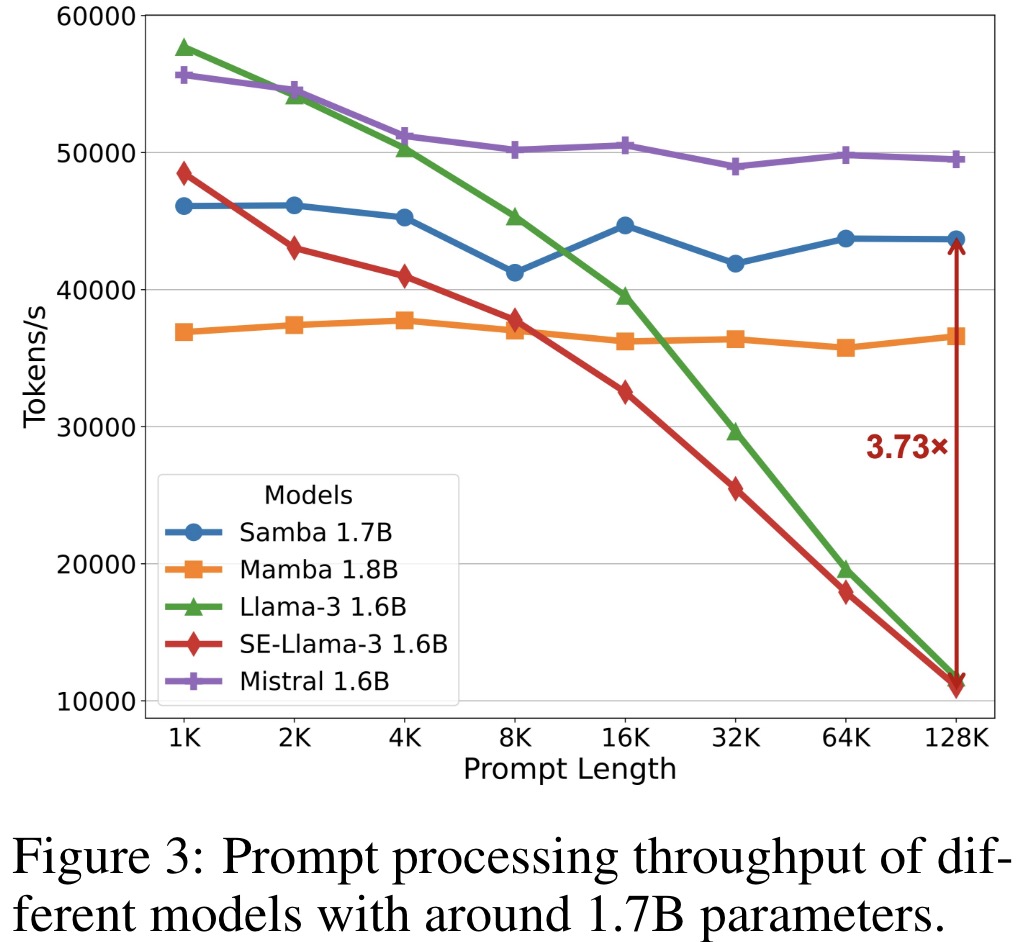
The evaluation of models at a scale of around 1.7B parameters using the Proof-Pile dataset focuses on length extrapolation ability. Data pre-processing follows Position Interpolation, and the sliding window approach with a window size of 4096 is used for perplexity evaluation.
- Samba achieves 3.73× higher throughput in prompt processing compared to Llama-3 1.6B at a 128K prompt length, maintaining linear processing time relative to sequence length.
- Existing zero-shot length extrapolation techniques introduce significant inference latency and fail to match Samba’s perplexity performance.
- Samba can extrapolate its memory recall ability to a 256K context length through supervised fine-tuning while keeping linear computation complexity.
- Fine-tuning Samba 1.7B on Passkey Retrieval demonstrates superior long-range retrieval ability compared to Mistral 1.6B. Samba achieves near-perfect retrieval performance early in the training process, while Mistral struggles with around 30% accuracy.
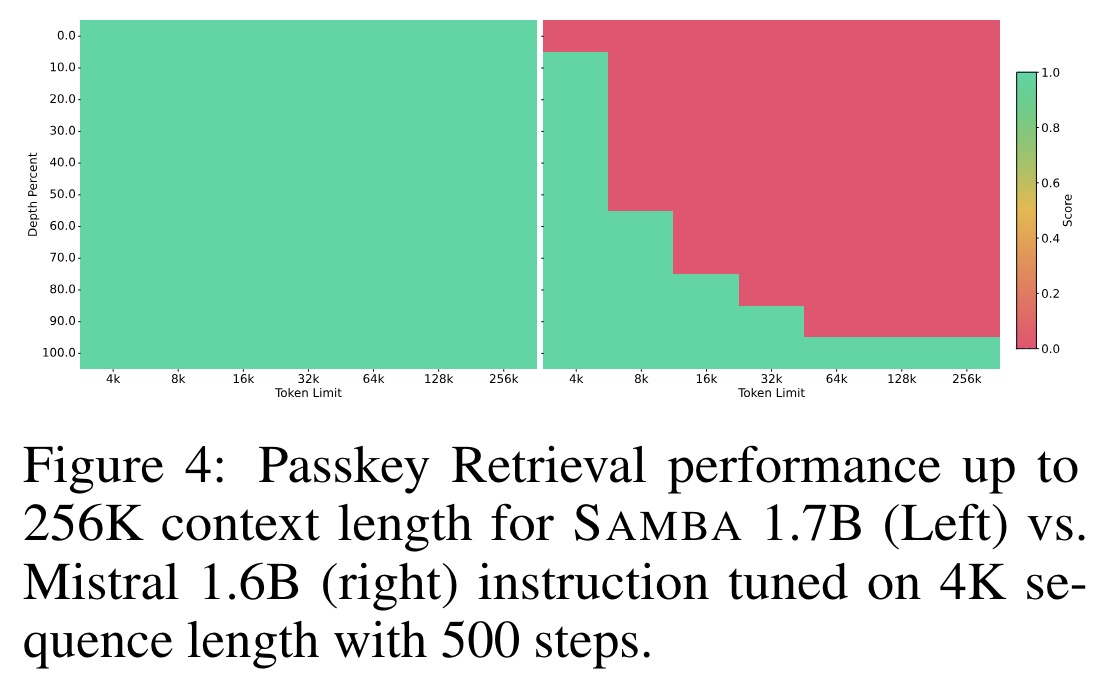
Long-Context Understanding
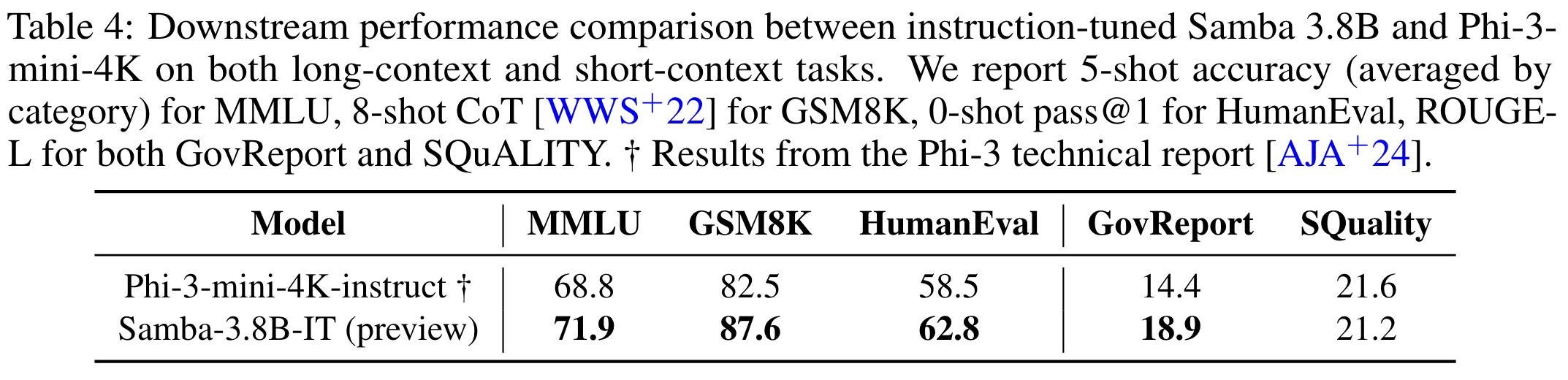
Following the same post-training recipe used for the Phi-3-mini series, the instruction-tuned Samba-3.8B-IT was evaluated on both long-context summarization tasks (GovReport, SQuALITY) and main short-context benchmarks (MMLU, GSM8K, HumanEval). Samba-3.8B-IT outperforms Phi-3-mini-4k-instruct on both short-context and long-context tasks.
Analysis
Despite SWA’s linear complexity with sequence length, increasing sequence length leads to higher validation perplexity due to smaller batch sizes. The optimal ratio of sequence length to window size is 2, resulting in a training length of 4096.
Hybridizing with full attention is not ideal, as it leads to exploding perplexity at longer context lengths and worse training throughput compared to using self-attention with FlashAttention 2. Mamba can capture low-rank information, so attention layers in Samba focus on information retrieval, requiring fewer attention heads. Samba performs better with a smaller number of query heads than Llama-2-SWA.
The hybrid architecture is advantageous due to the specialization of attention layers in Samba, which focus on global integration in upper and lower layers and precise retrieval in middle layers. This specialization improves downstream performance.
The Short Convolution operator, used in Mamba, can enhance other linear recurrent models. Adding SC improves the performance of Llama-2-SWA and Sliding RetNet, but not Sliding GLA, which already has fine-grained decays at the channel level. Even with SC, these models do not outperform the original Samba, justifying the use of Mamba for hybridization. Adding SC to both SWA and linear attention layers in hybrid models produces negative results, suggesting future research to understand SC’s effectiveness in language modeling.
paperreview deeplearning swa nlp mamba