Paper Review: Semi-Autoregressive Transformer for Image Captioning
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel, but they suffer from quality degradation due to their design. The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality. Experiments on MSCOCO show that SATIC can do it “without bells and whistles”.
The approach
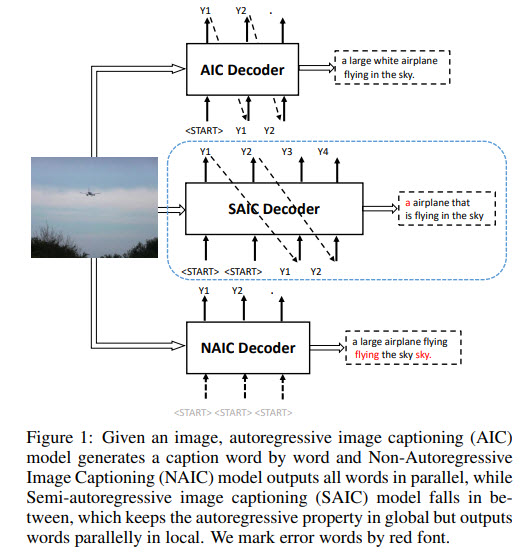
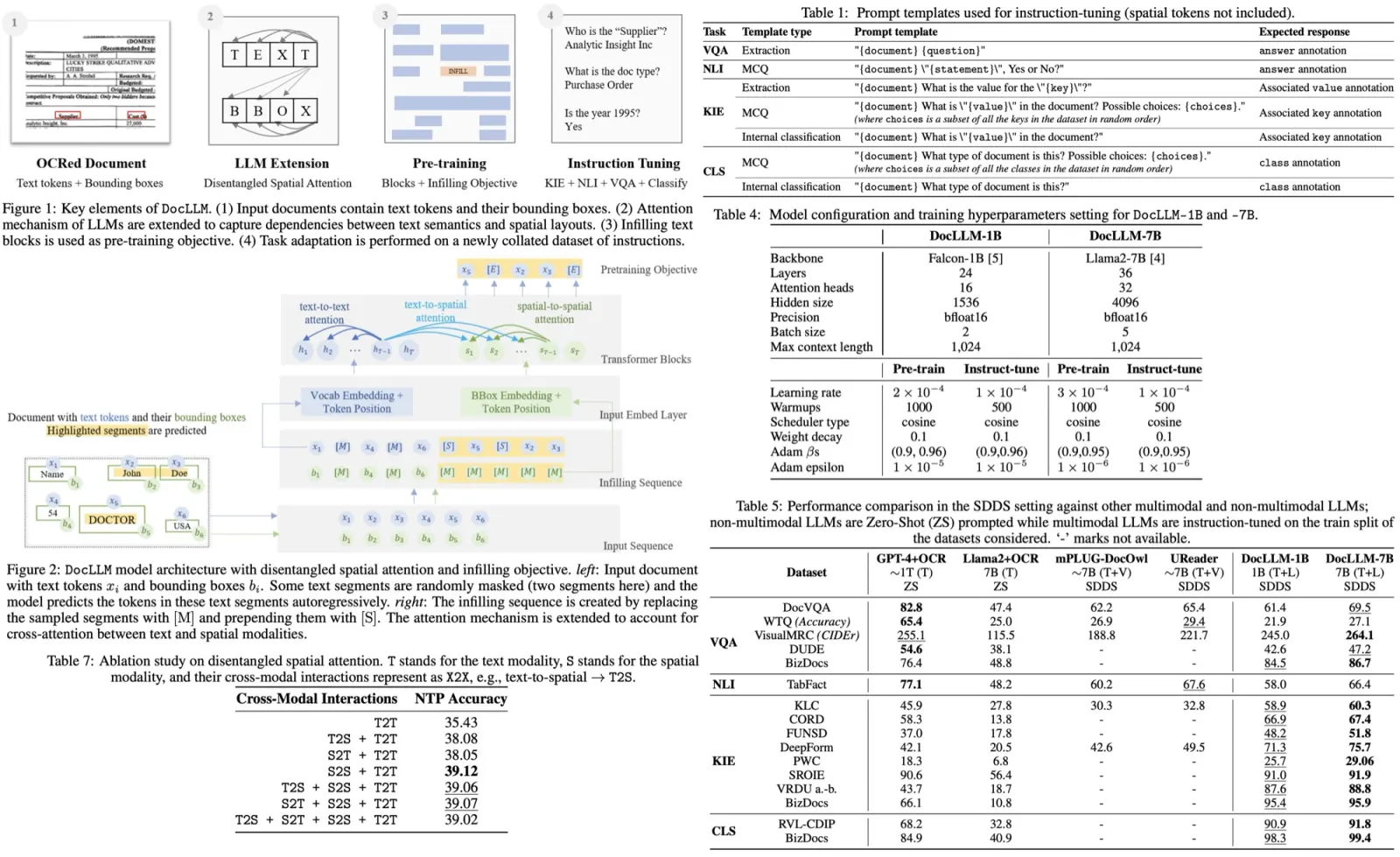
The main idea is to consider a sentence as a series of concatenated word groups, and each word in a group is predicted in parallel.
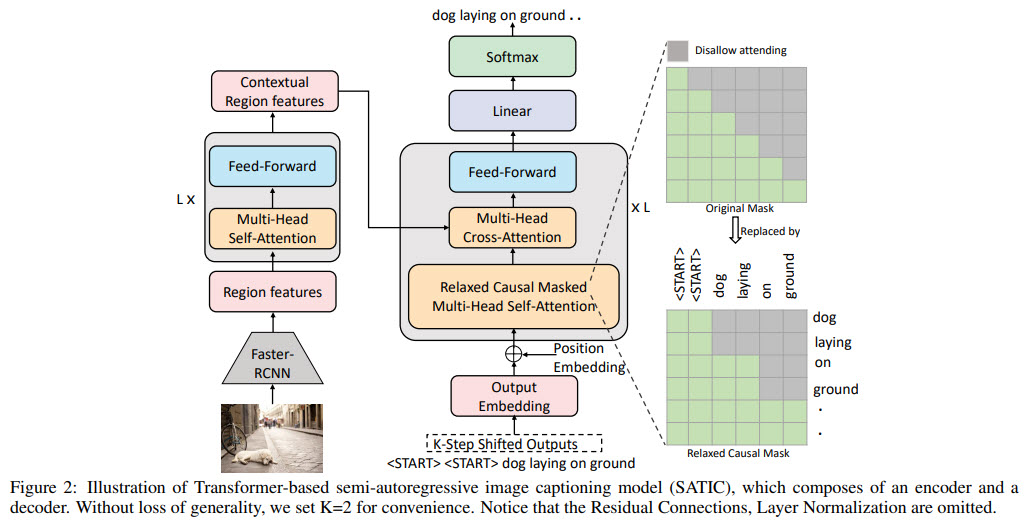
The encoder
The encoder takes the features extracted by a pre-trained Faster-RCNN and generates a visual context representation. It consists of L layers (multi-head self-attention and position-wise feed-forward layer)
The decoder
- The decoder takes visual context representation and word embeddings (with position encodings) as an input, predicts words probability;
- The decoder takes word groups as an input and predicts the next groups. Group size is K (2 by default). So it predicts first K words, then next K words, etc.;
- The decoder consists of L layers; each one has a relaxed causal masked multi-head attention sublayer, multi-head cross-attention sublayer, and a position-wise feed-forward sublayer;
- Casual masked attention has a different self-attention mask - with a step K;
- In cross-attention, key and value are visual context representation, and the query is the output of its last sublayer;
The training
The model is trained in two stages. The first stage uses cross-entropy loss; at the second stage the model is fine-tuned using self-critical training.
In the gradient formula, R is the CIDEr score function, b is a baseline score. This baseline score is defined as the average reward of five samples.
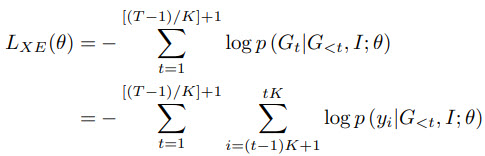
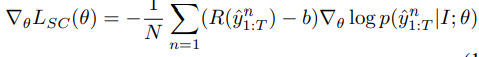
Implementation details
- each image is represented as 10-100 features with 2048 dimensions;
- rare words (less than 5 occurrence) are dropped from the dictionary;
- captions are truncated to 16 words max;
- trained for 15 epochs with cross-entropy loss and then 25 epochs with the second objective;
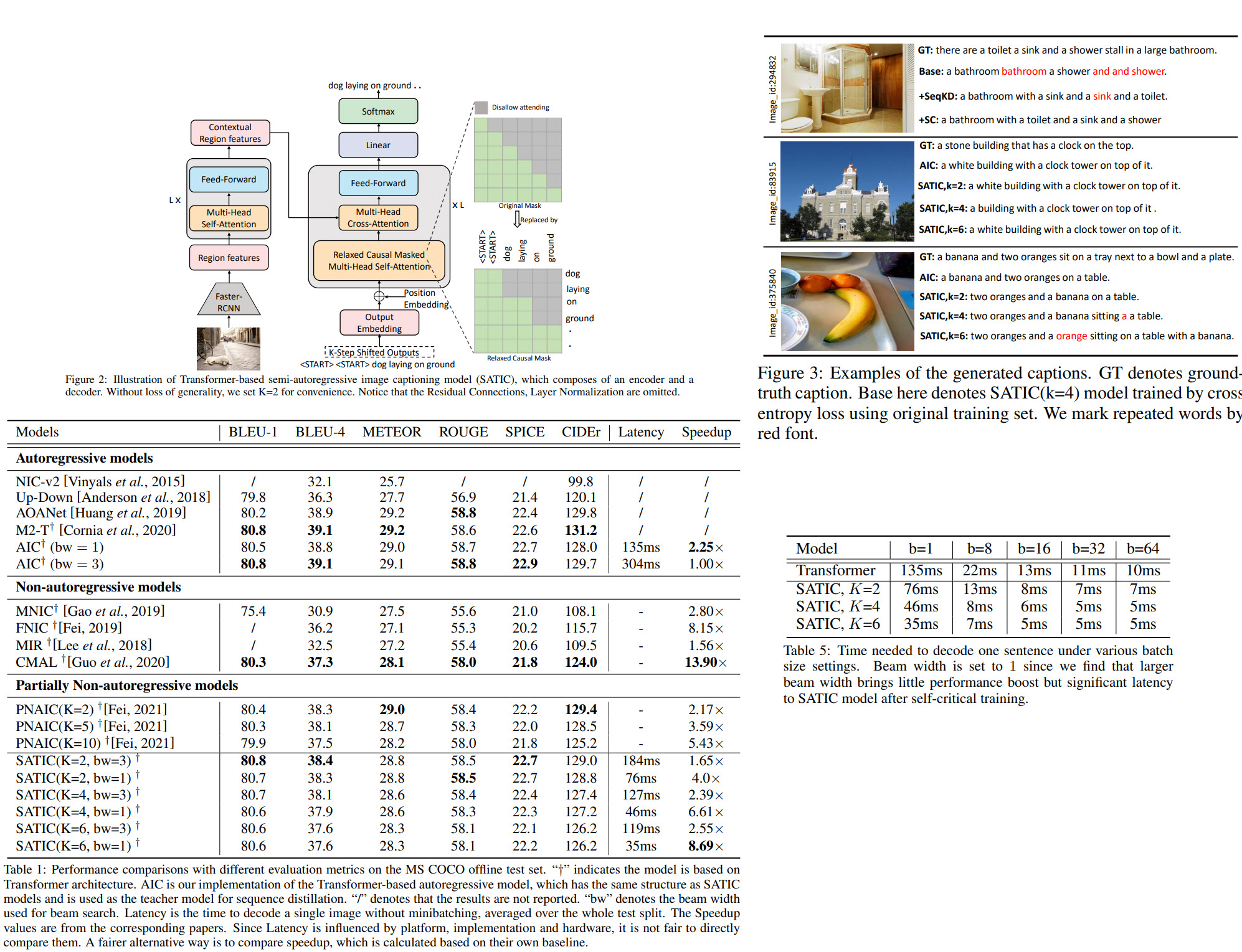
- Unless otherwise indicated, latency shows the time to decode a single image without batching averaged over the whole test split, and is tested on an NVIDIA Tesla T4 GPU;
Results
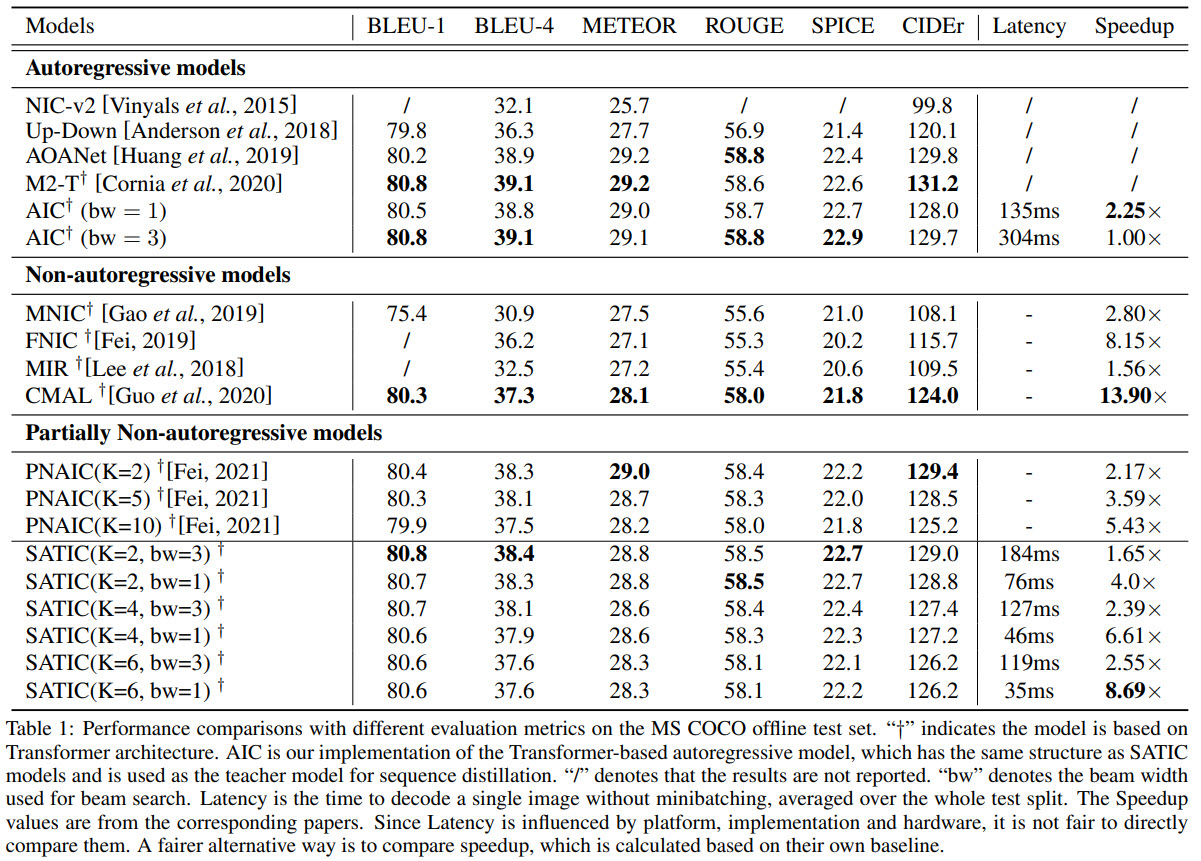
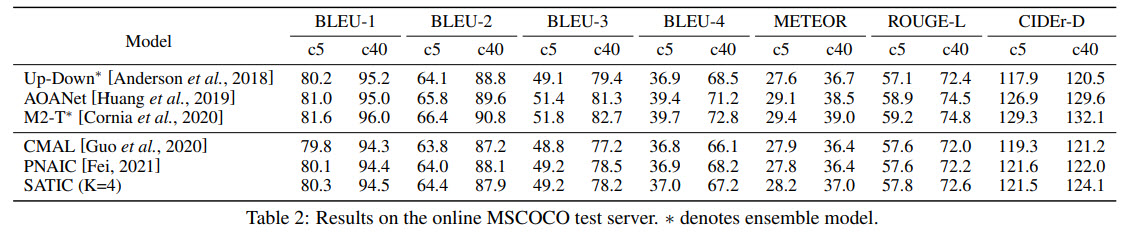
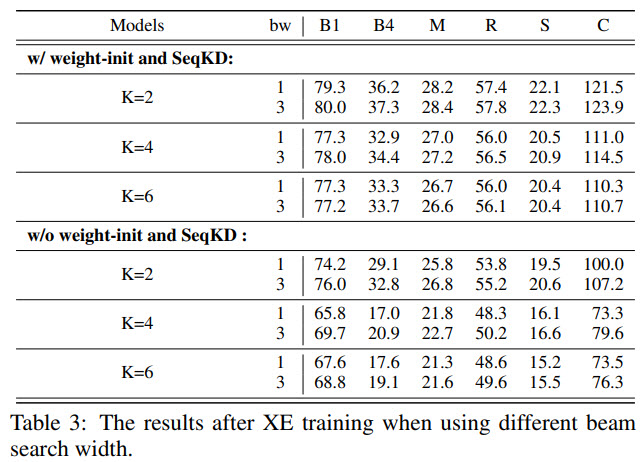
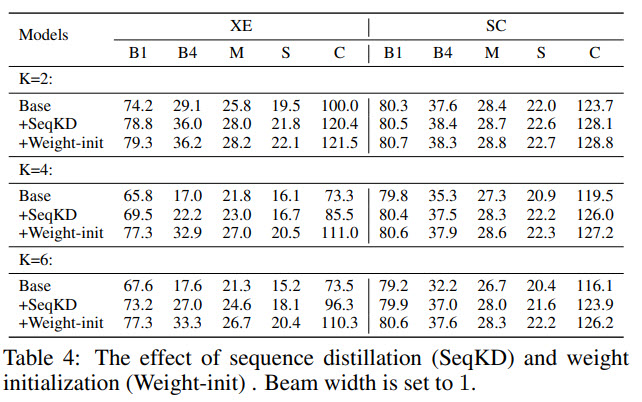
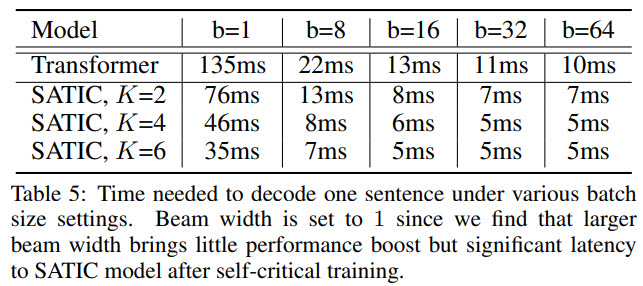
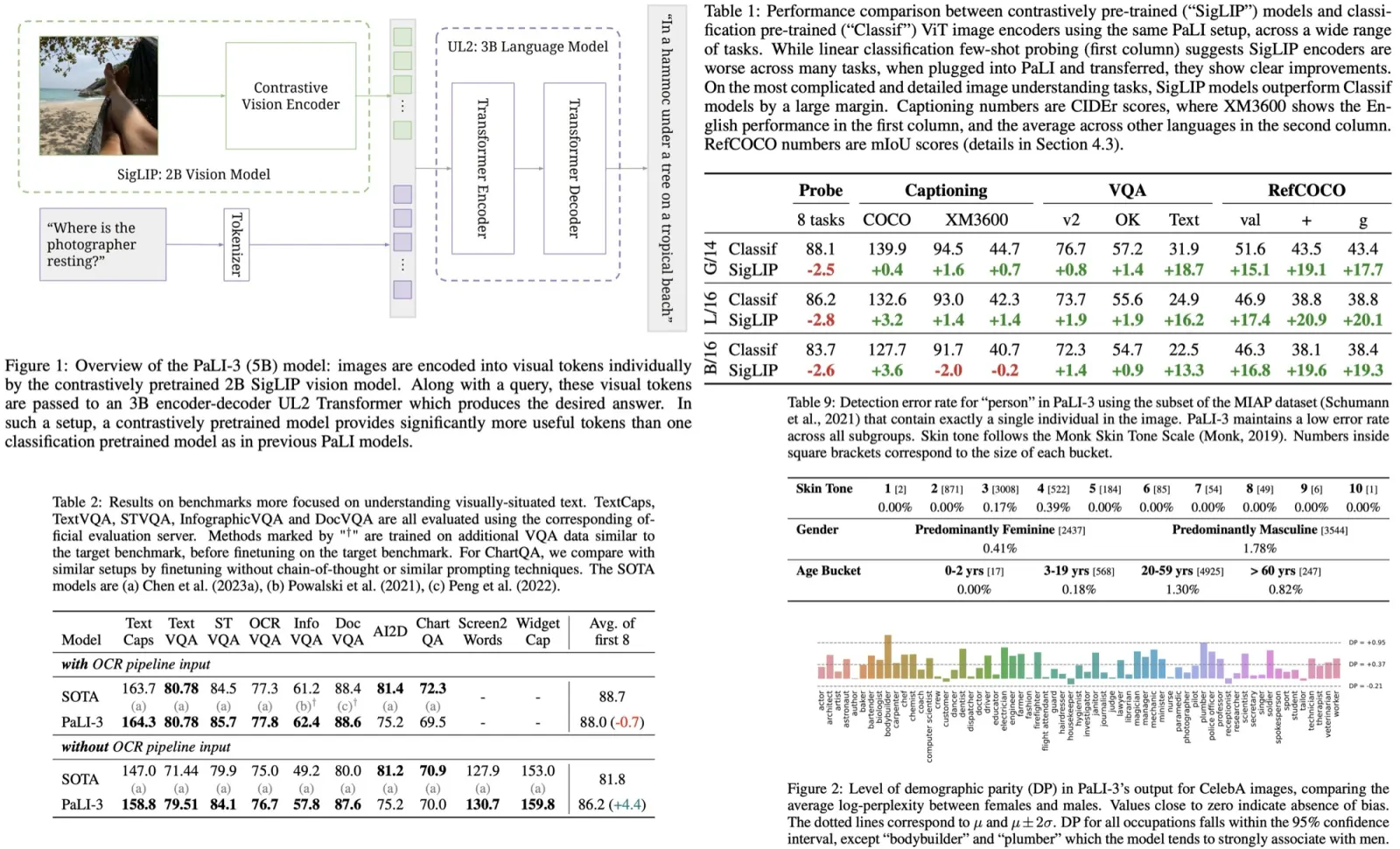
- SATIC achieves performance on the level of the state-of-the-art autoregressive models but with impressive speedup;
- Increasing K leads to better speed, and the score doesn’t drop much;
- The authors tried adding beam search, but it didn’t help much, but they made the following observations: with higher K, the increase of score from beam search is lower; the effect of beam search is larger when without weight initialization and sequence distillation;
- if we increase batch size, the SATIC will be even faster. But at the high batch size, the speedup is smaller;
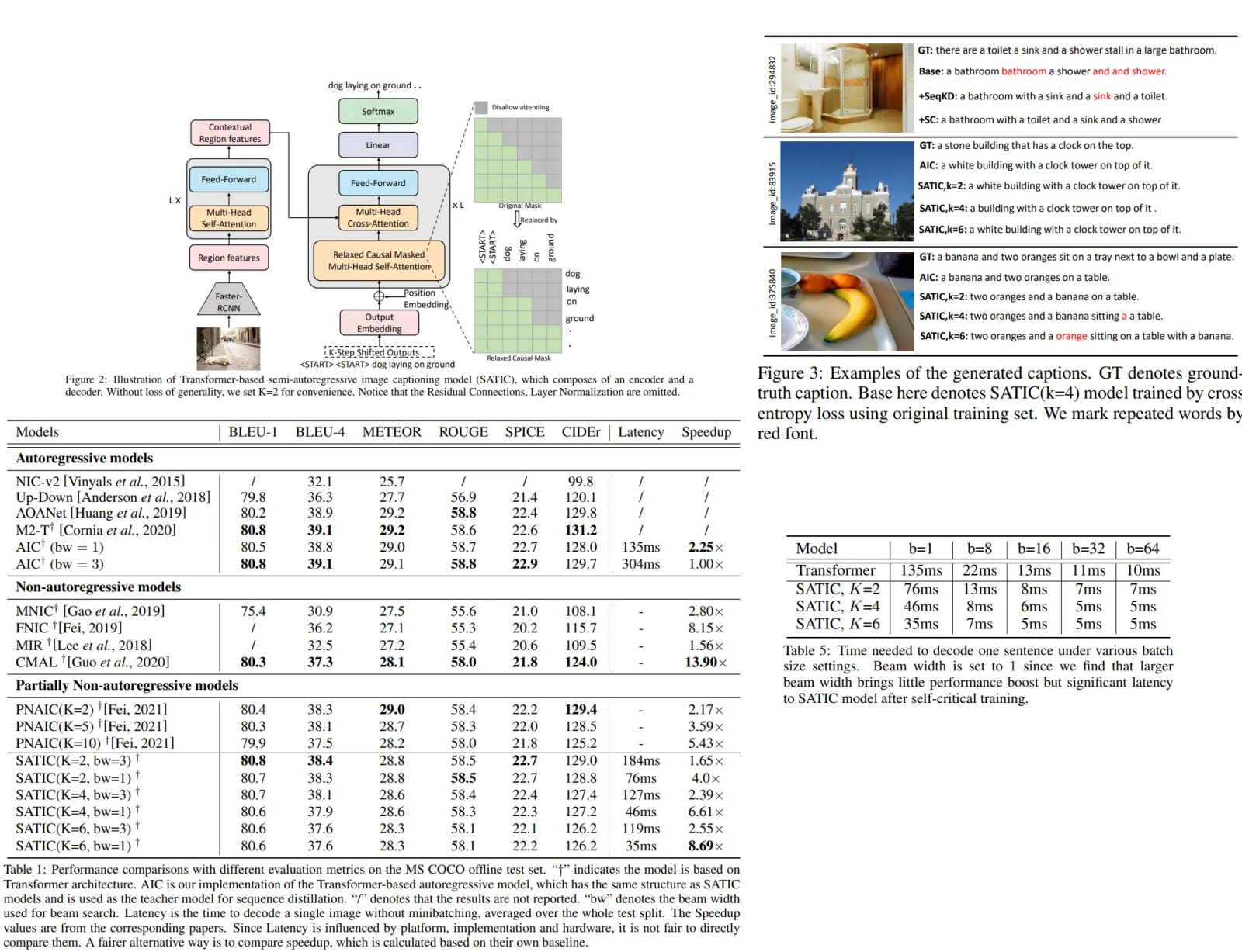
Qualitative Results
In some cases, SATIC generates fluid captions, but the problem of repeated words and incomplete content isn’t solved completely, especially at high K.