Paper Review: Training Language Models to Self-Correct via Reinforcement Learning
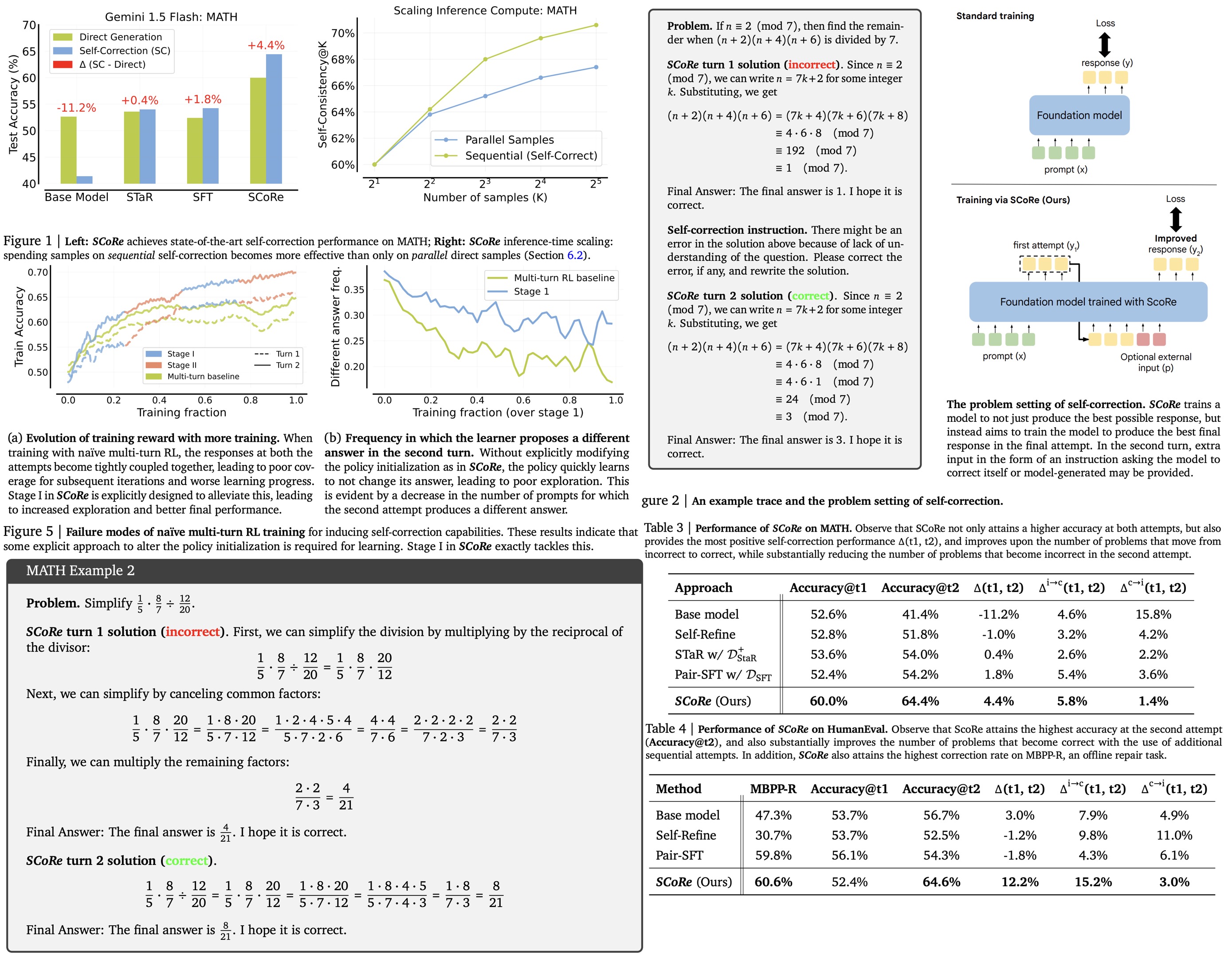
SCoRe - a new approach to improving LLMs self-correction ability through multi-turn online RL. Existing methods rely on multiple models or external supervision, but SCoRe uses only self-generated data. The authors found that previous supervised fine-tuning methods are insufficient due to distribution mismatches and ineffective correction behavior. SCoRe addresses this by training the model on its own correction traces, using regularization to enhance self-correction. Applied to Gemini 1.0 Pro and 1.5 Flash models, SCoRe improves self-correction performance by 15.6% and 9.1% on MATH and HumanEval benchmarks.
Preliminaries and Problem Setup
The goal is to train LLMs to improve their own predictions by relying solely on self-generated data. In this self-correction setting, models try to correct their responses without external feedback. The approach uses a dataset of problems and oracle responses, training a policy that generates multiple attempts to solve a problem. A reward function evaluates the correctness of the responses. The model learns to detect and correct mistakes without access to the reward function during testing. The objective is to optimize a policy over multiple turns, using policy gradient reinforcement learning with a KL-divergence penalty to ensure gradual improvements. Key performance metrics include accuracy on the first and second attempts, the improvement in accuracy between attempts, the fraction of initially incorrect problems that become correct after self-correction, and the fraction of initially correct responses that become incorrect.
Supervised Fine-Tuning on Self-Generated Data is Insufficient for Self-Correction
An empirical study was conducted to evaluate whether SFT approaches can improve large language models’ self-correction abilities. Two methods, STaR and an approach with training only one model, were tested. Although these methods improve the base model’s self-correction performance, they still fail to achieve a positive self-correction rate, often producing worse second attempts. The failures stem from SFT amplifying the initial biases of the base model, resulting in only minor changes in responses. Adjusting the distribution of initial responses helps but does not fully solve the problem, as learning remains hindered by distribution shifts or bias amplification.
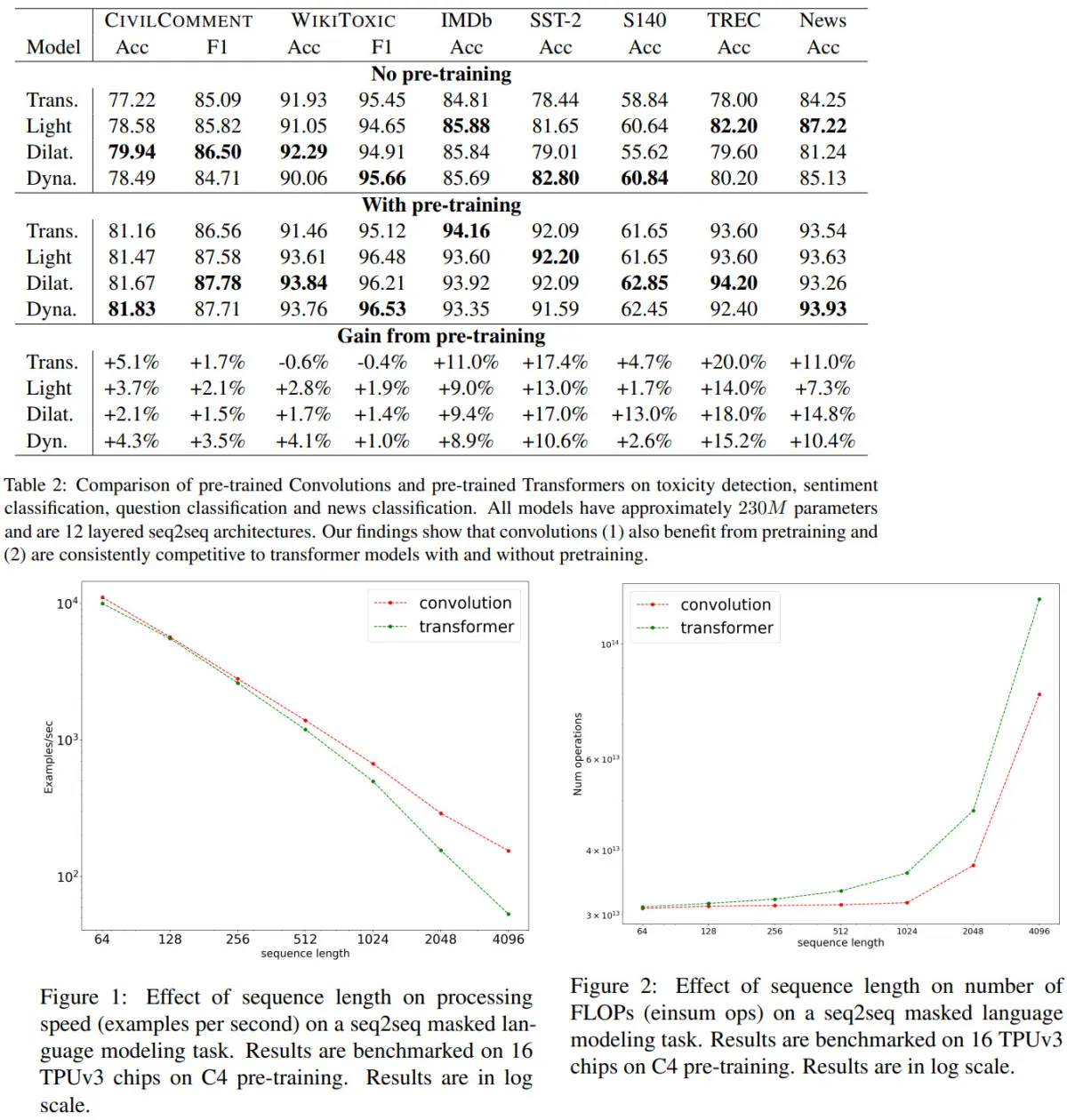
These methods were tested for improving self-correction in large language models using the MATH dataset. The STaR approach filters model-generated traces to retain only those where incorrect responses were successfully revised, then applies SFT on this filtered dataset. The second method, called Pair-SFT, pairs incorrect responses with correct ones to create “synthetic” repair traces without training a separate corrector model or using multi-turn traces. The datasets for each method were constructed from Gemini 1.5 Flash’s outputs, and SFT was applied: STaR underwent three iterations of data collection and fine-tuning, while Pair-SFT had only one epoch due to the large dataset size.
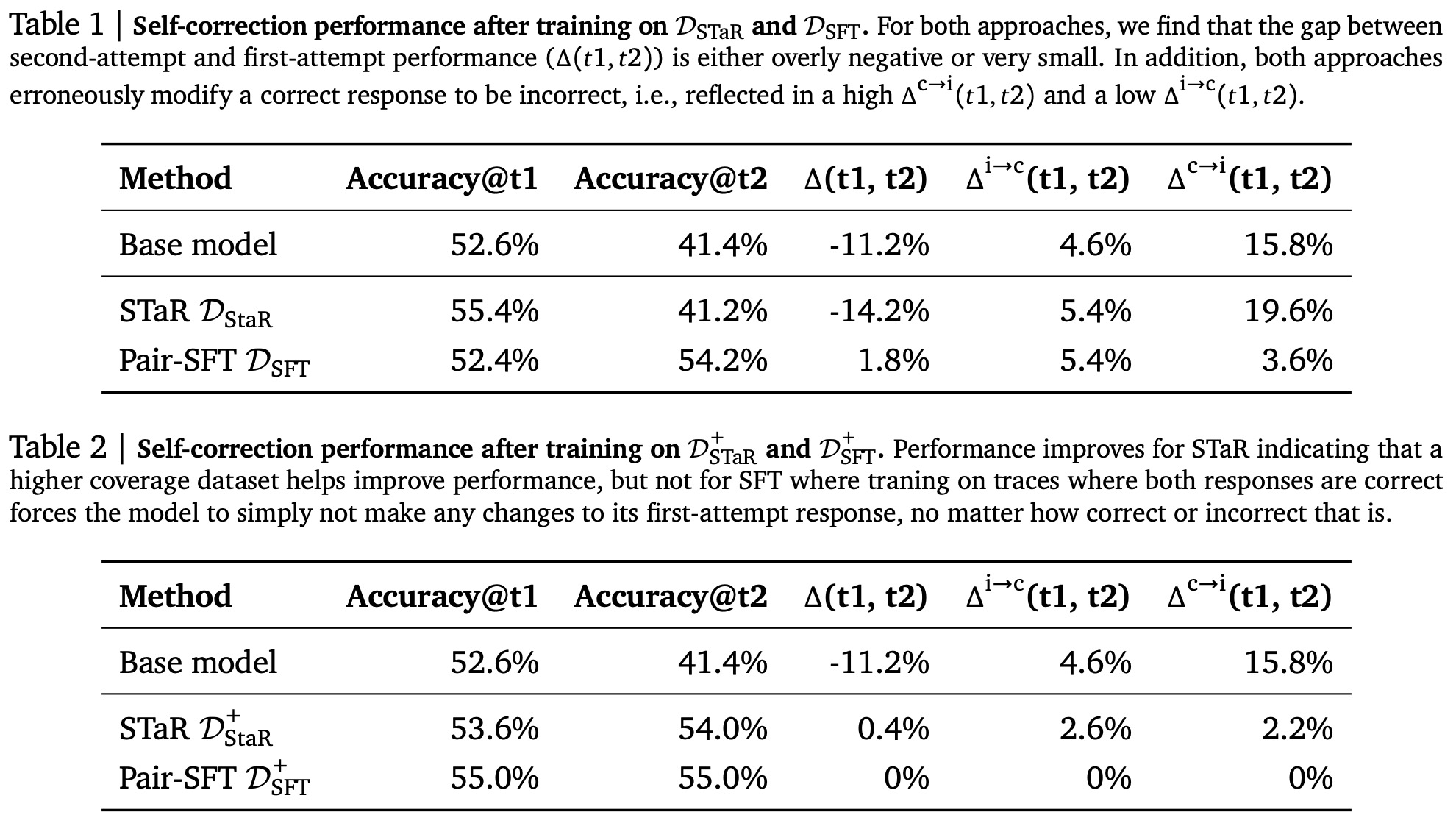
Pair-SFT showed a small 1.8% gain in self-correction compared to the base model, mainly by reducing the number of correct responses that were mistakenly revised to incorrect ones. However, it did not significantly improve the correction of incorrect first attempts. STaR, in contrast, did not reduce the number of incorrect revisions, indicating a lack of understanding of when to make changes. The discrepancy is attributed to differences in data distributions: Pair-SFT’s random pairing covered a broader range of revision scenarios, while STaR had a narrower focus. Adding “correct-to-correct” data improved STaR slightly but still yielded minimal self-correction. For SFT, however, adding this data overly biased the model, causing it to avoid making changes entirely.
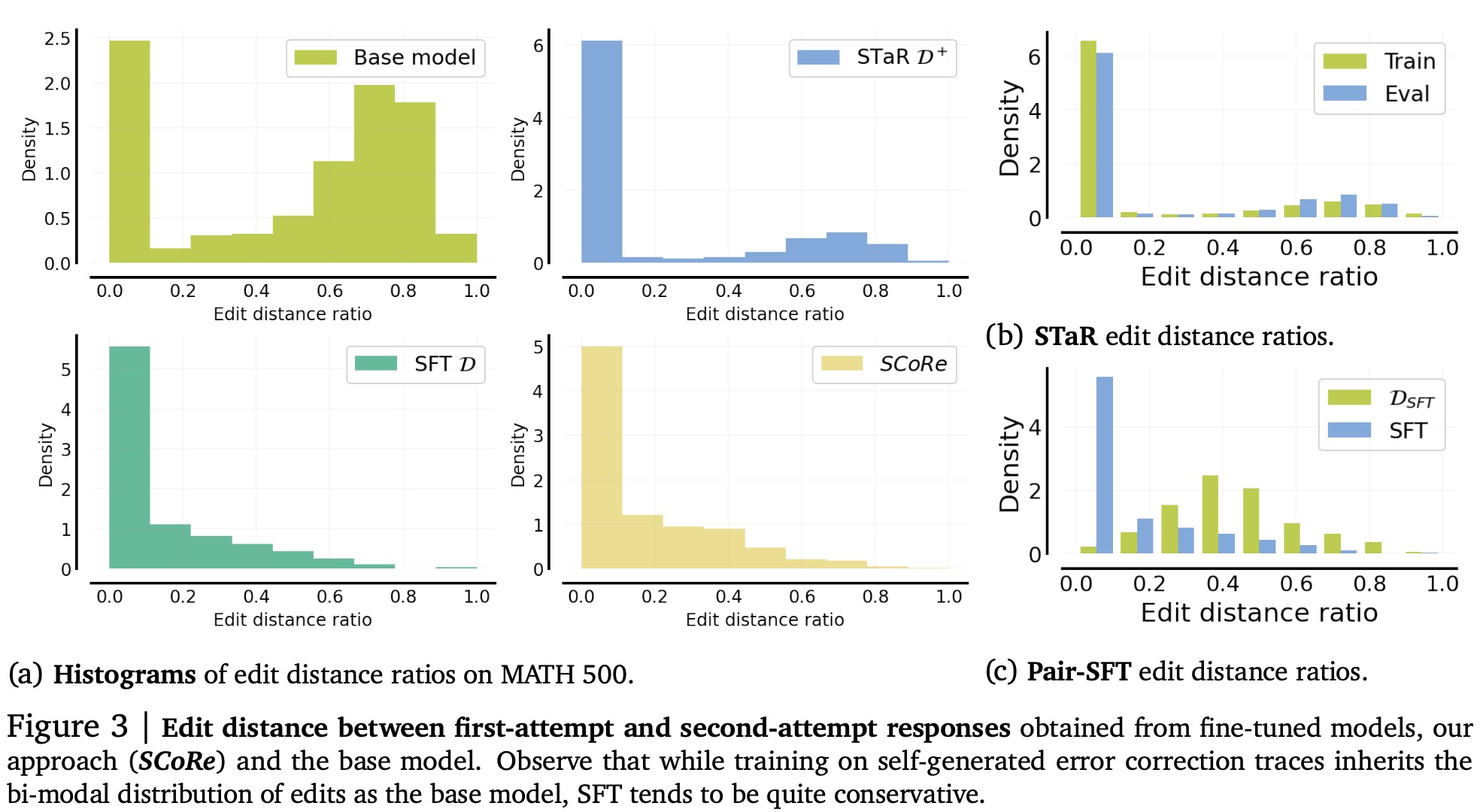
The authors analyzed the self-correction behavior of the models by measuring the edit distance ratio, which quantifies how much models modify their first-attempt responses. The results showed that while the base model sometimes made substantial edits, the fine-tuned models were overly conservative and often made no edits at all. STaR performed similarly on both training and validation data, whereas Pair-SFT showed discrepancies in edit distance ratios between training and validation, indicating poor generalization. Furthermore, while Pair-SFT optimized correction accuracy on training data and maintained accuracy on validation problems, its self-correction accuracy degraded when tested on self-generated responses with more training. SCoRe, on the other hand, avoids the bias of minimal edits without explicit training for controlling the degree of response changes.
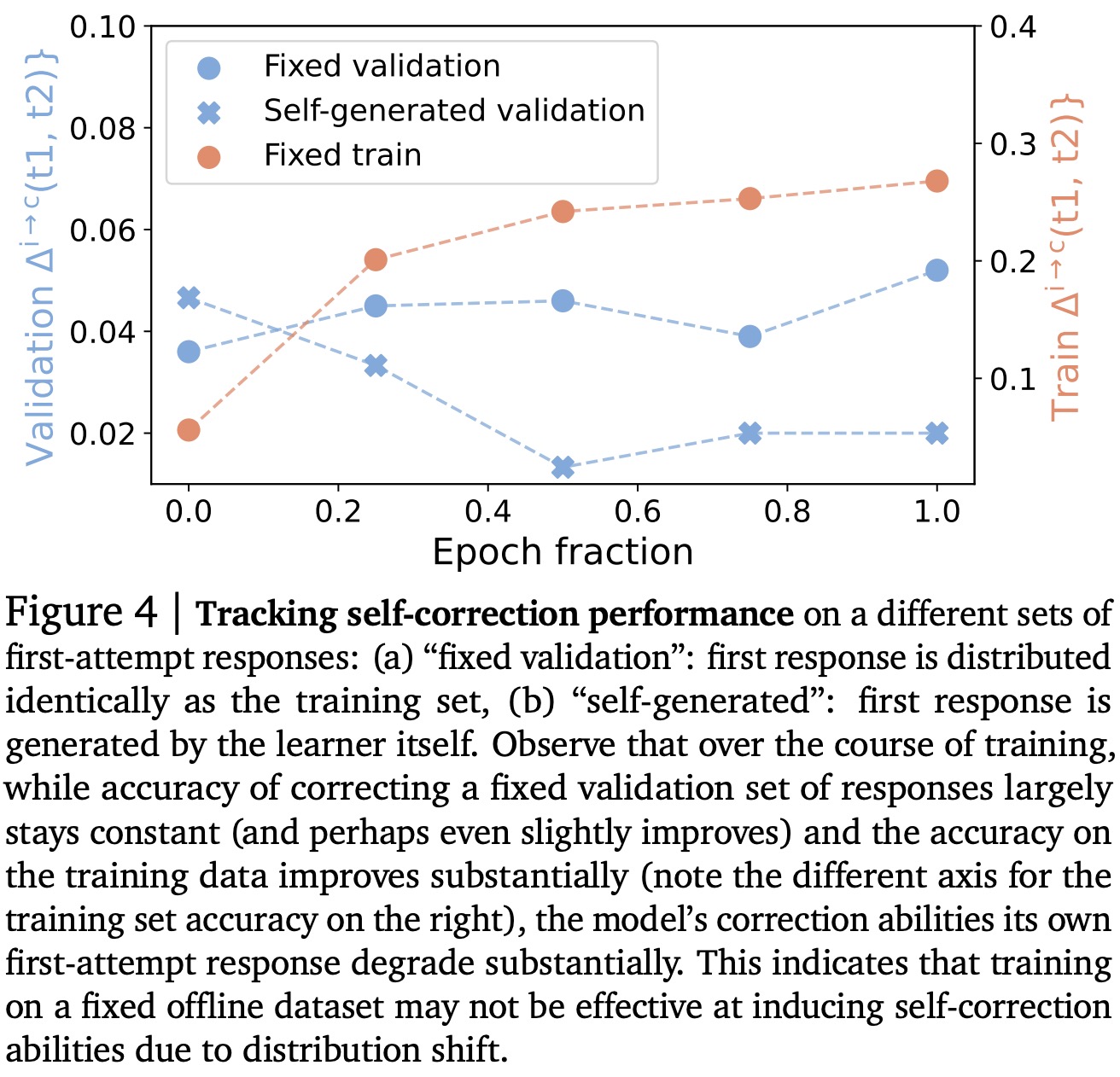
That takeaway is that there are two key failures of SFT methods for self-correction. STaR was too focused on a single correction strategy that made only minor changes, while Pair-SFT, despite covering a broader range of data, suffered from a degradation in self-correction performance due to distribution shift. These findings highlight two important criteria for an effective approach:
- it must train on self-generated traces to address distribution mismatch
- it should prevent models from collapsing into making only minor edits during training
SCoRe: Self-Correction via Multi-Turn Reinforcement Learning
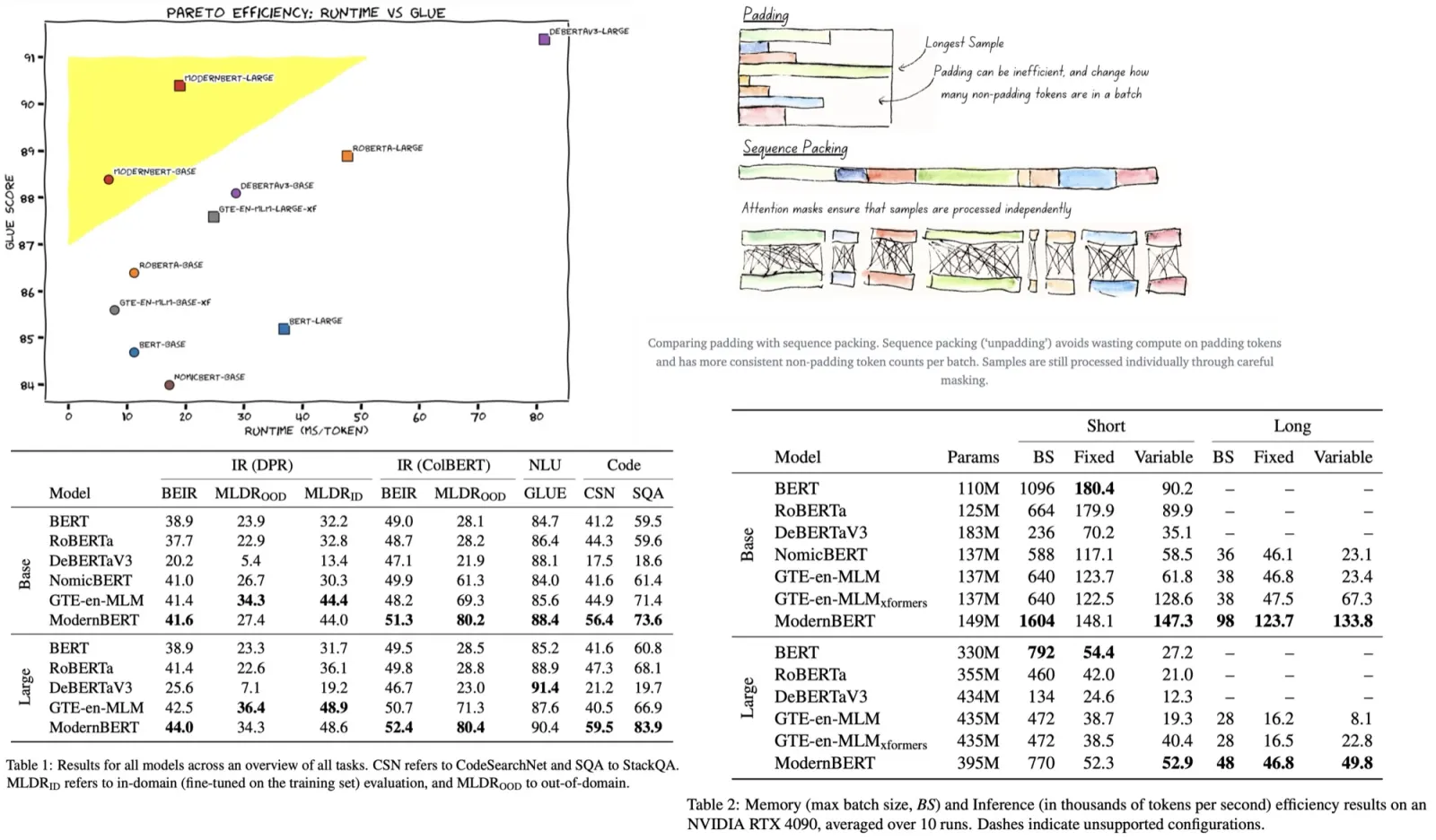
To develop an effective method for teaching LLMs to self-correct using only self-generated data, SCoRe leverages on-policy RL to address distribution mismatch and prevent mode collapse. A key challenge is that multi-turn RL, while addressing distribution shift, often leads to models that don’t self-correct, instead opting to maintain their first attempt responses. This happens because both producing the best first attempt or improving on it appear equally optimal during training.
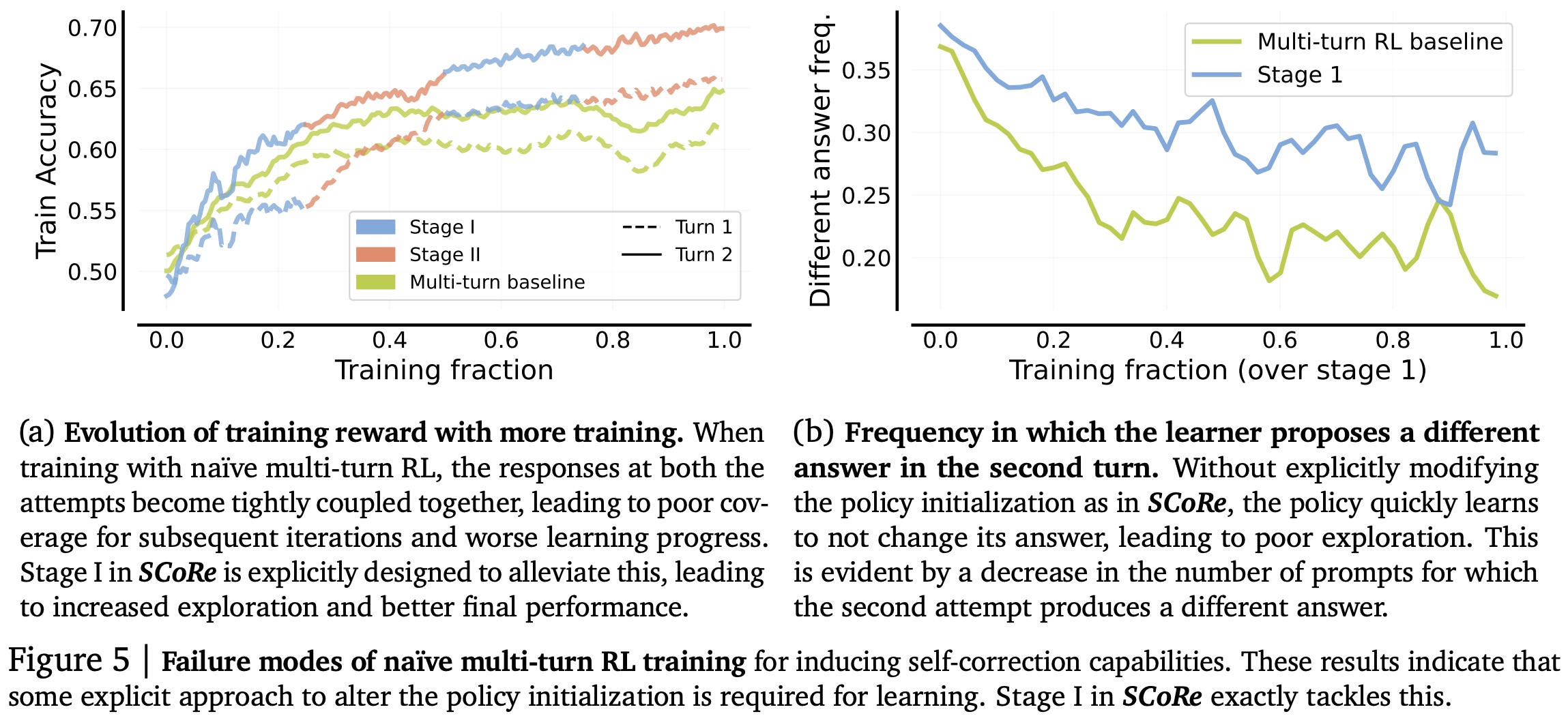
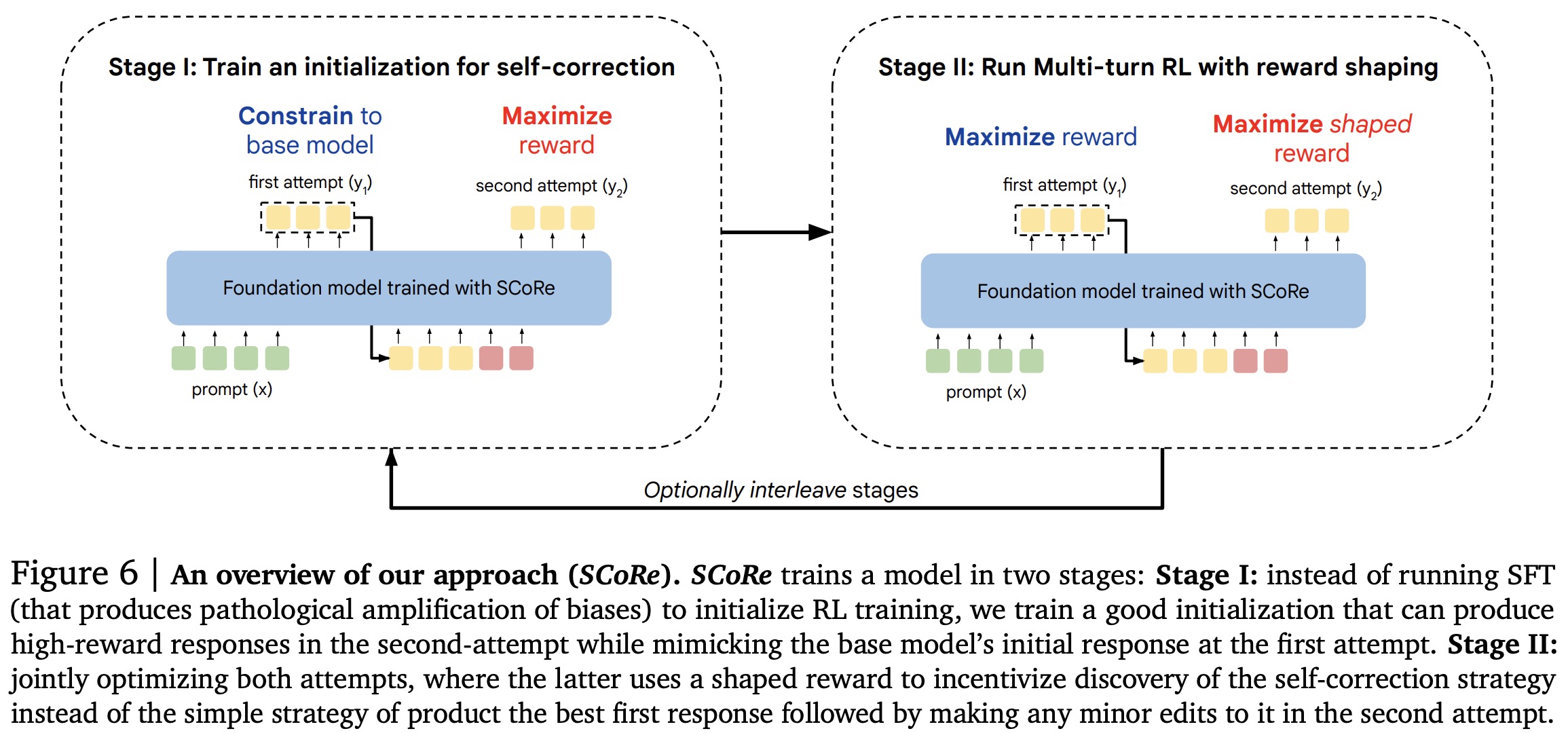
SCoRe addresses this challenge in two stages:
- Stage I explicitly trains the model to correct its second attempts based on a relatively static first attempt, encouraging high-reward responses and reducing the likelihood of mode collapse. At this stage, the authors apply a KL-divergence constraint to keep the first-attempt responses close to the base model’s distribution, preventing the first and second attempts from becoming too similar and falling into a local optimum.
- Stage II uses this trained initialization for multi-turn RL, applying a reward bonus to incentivize effective self-correction. This approach biases the model towards learning to improve its responses across attempts, rather than sticking with an initial response. The model is trained using a policy gradient approach with an objective that optimizes rewards for both attempts. To encourage self-correction, the authors use reward shaping: a bonus is added to the second attempt’s reward if it improves the correctness compared to the first attempt, while penalties are applied if the response degrades.
Experiments
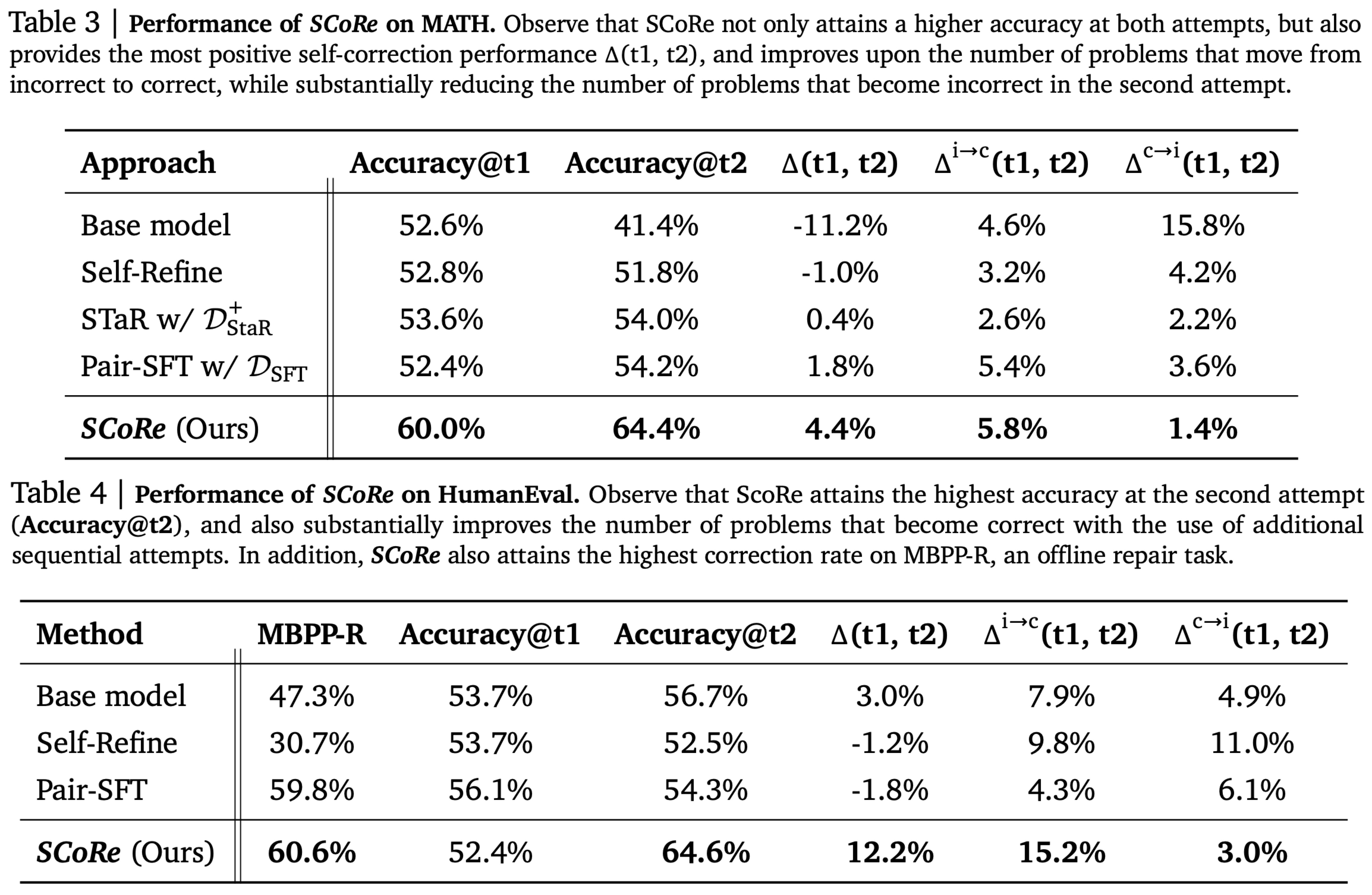
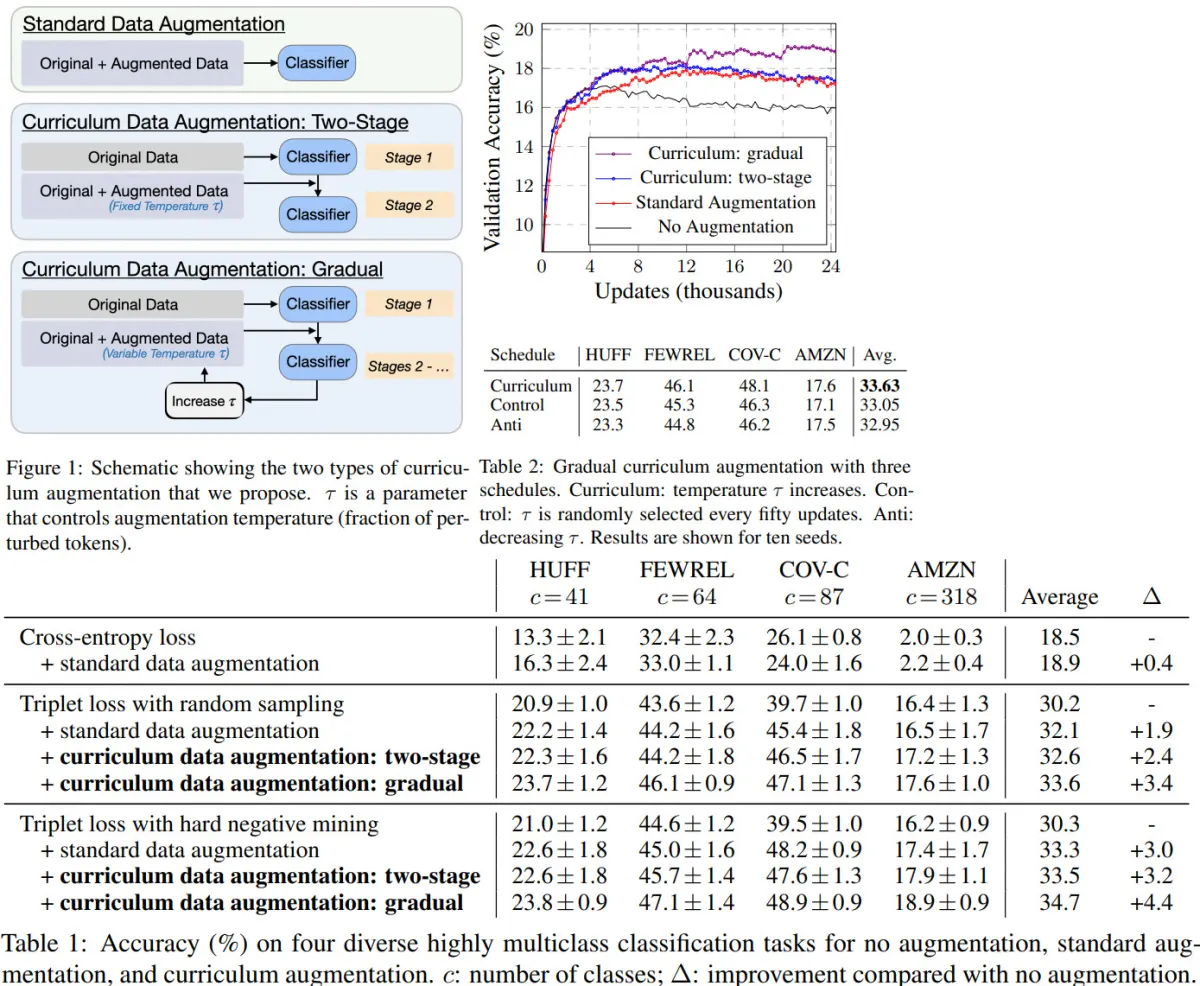
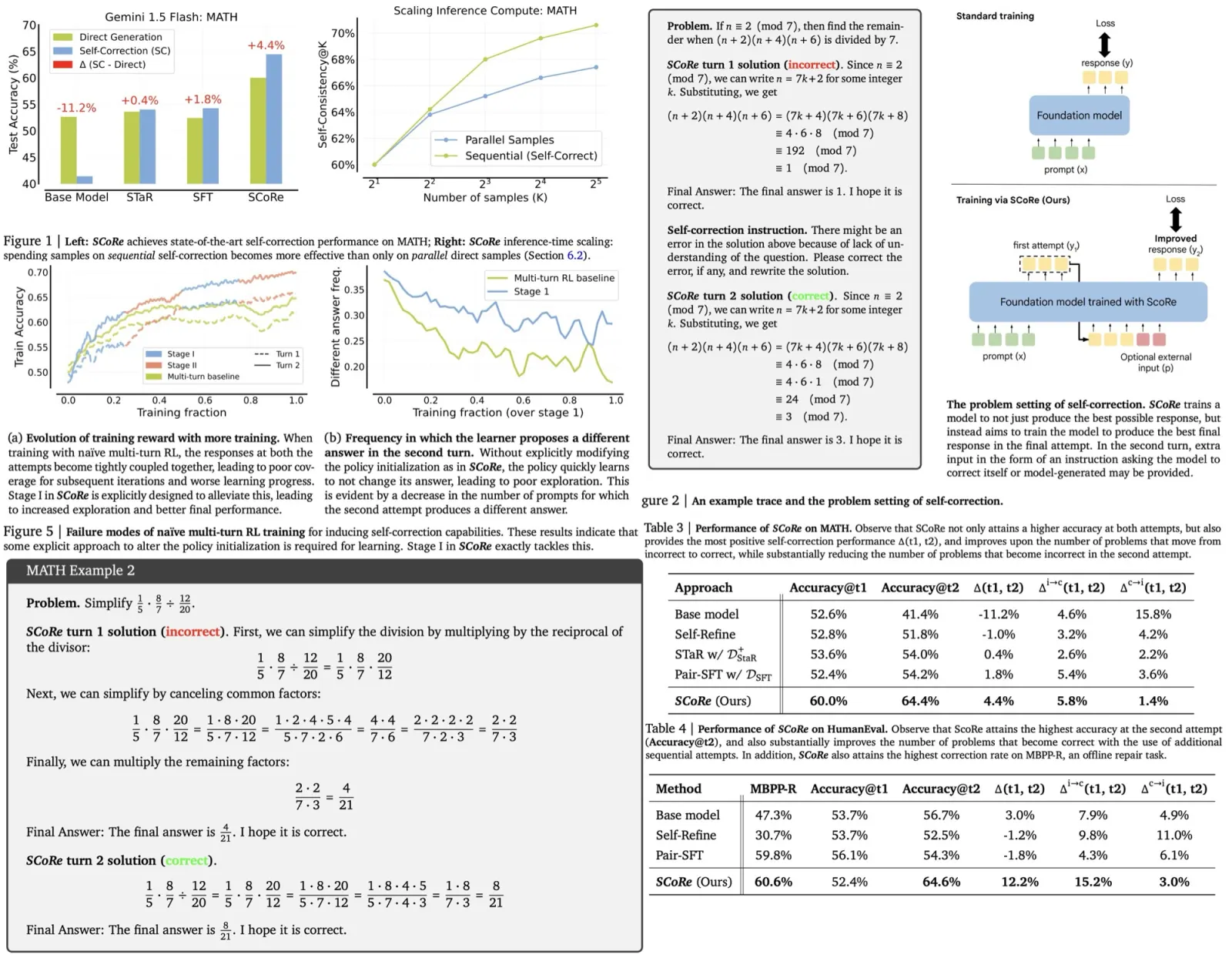
In the MATH benchmark, SCoRe achieves a 4.4% self-correction gain with overall Accuracy@t2 increasing by 23.0%, outperforming the base model by 15.6% and surpassing Pair-SFT by 10.2%. SCoRe also improves the rate of fixing incorrect responses and reduces the number of correct answers changed to incorrect.
For the code generation task, SCoRe boosts performance from 47.3% to 60.6% on MBPP-R, a gap similar to that between GPT-3.5 and GPT-4. It also generalizes well to the HumanEval dataset, achieving a 12.2% self-correction delta, outperforming the base model by 9%. While Pair-SFT performs well in static repair tasks, it degrades self-correction performance, highlighting the importance of on-policy sampling.
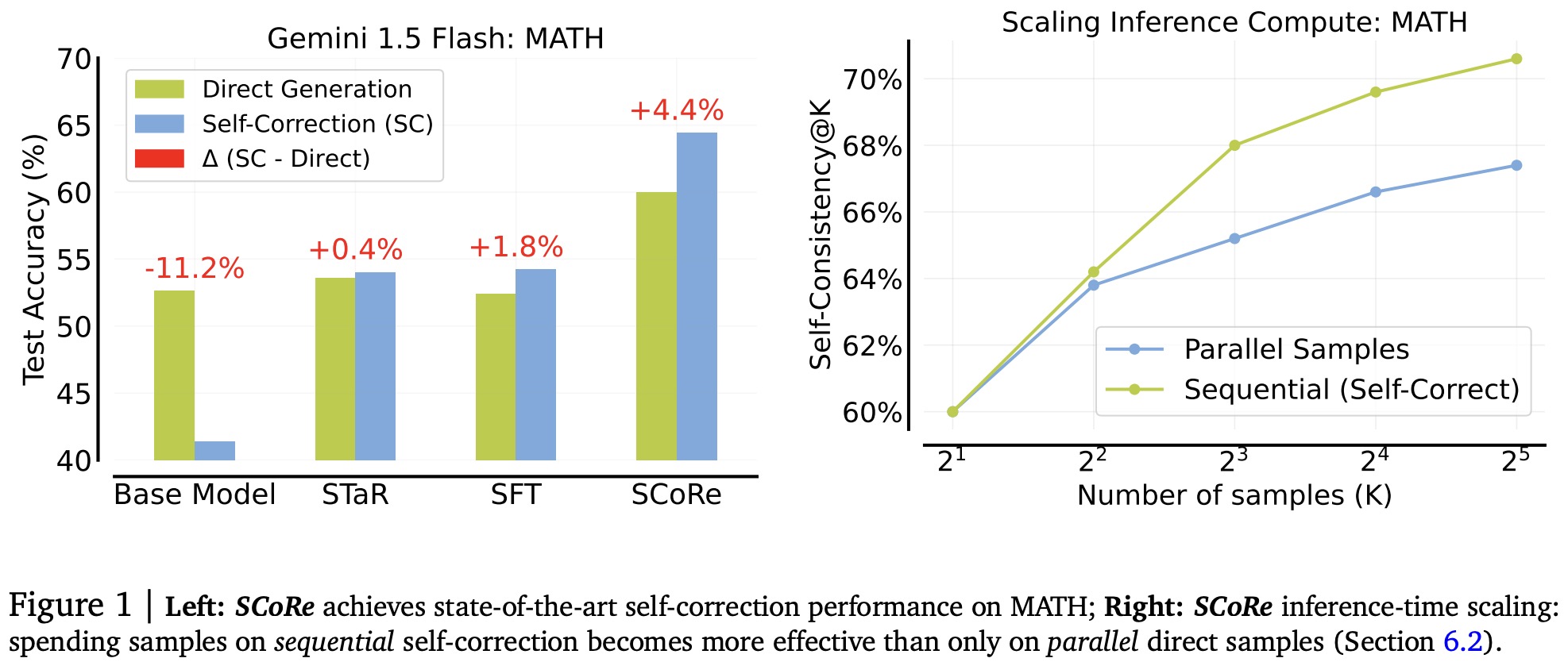
Additionally, SCoRe is effective when combined with inference-time compute scaling strategies like self-consistency decoding (majority voting). Combining parallel sampling with sequential self-correction yields a 10.5% improvement, compared to 7.4% from parallel sampling alone.

Ablation studies :
- Multi-turn training: Single-turn training improves first-turn performance but negatively impacts self-correction.
- Multi-stage training: Stage I is essential; skipping it leads to 2% lower self-correction gain and 3% lower accuracy on the second attempt.
- Reward shaping: Removing reward shaping reduces performance, highlighting its importance in guiding self-correction learning.
- On-policy RL: Replacing REINFORCE with STaR in Stage II significantly reduces performance, showing that on-policy sampling is critical for multi-turn self-correction, unlike in single-turn settings.