Paper Review: Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection

LLMs can produce inaccurate responses due to their fixed knowledge. RAG improves accuracy by retrieving relevant knowledge but can reduce versatility. The Self-Reflective Retrieval-Augmented Generation framework addresses these challenges by adaptively retrieving information and reflecting on its outputs using reflection tokens. This adaptability makes the model controllable for various tasks. Experiments show Self-RAG outperforms ChatGPT and Llama2-chat in tasks such as open-domain QA, reasoning, fact verification, and long-form content generation.
Self-RAG: learning to retrieve, generate and critique
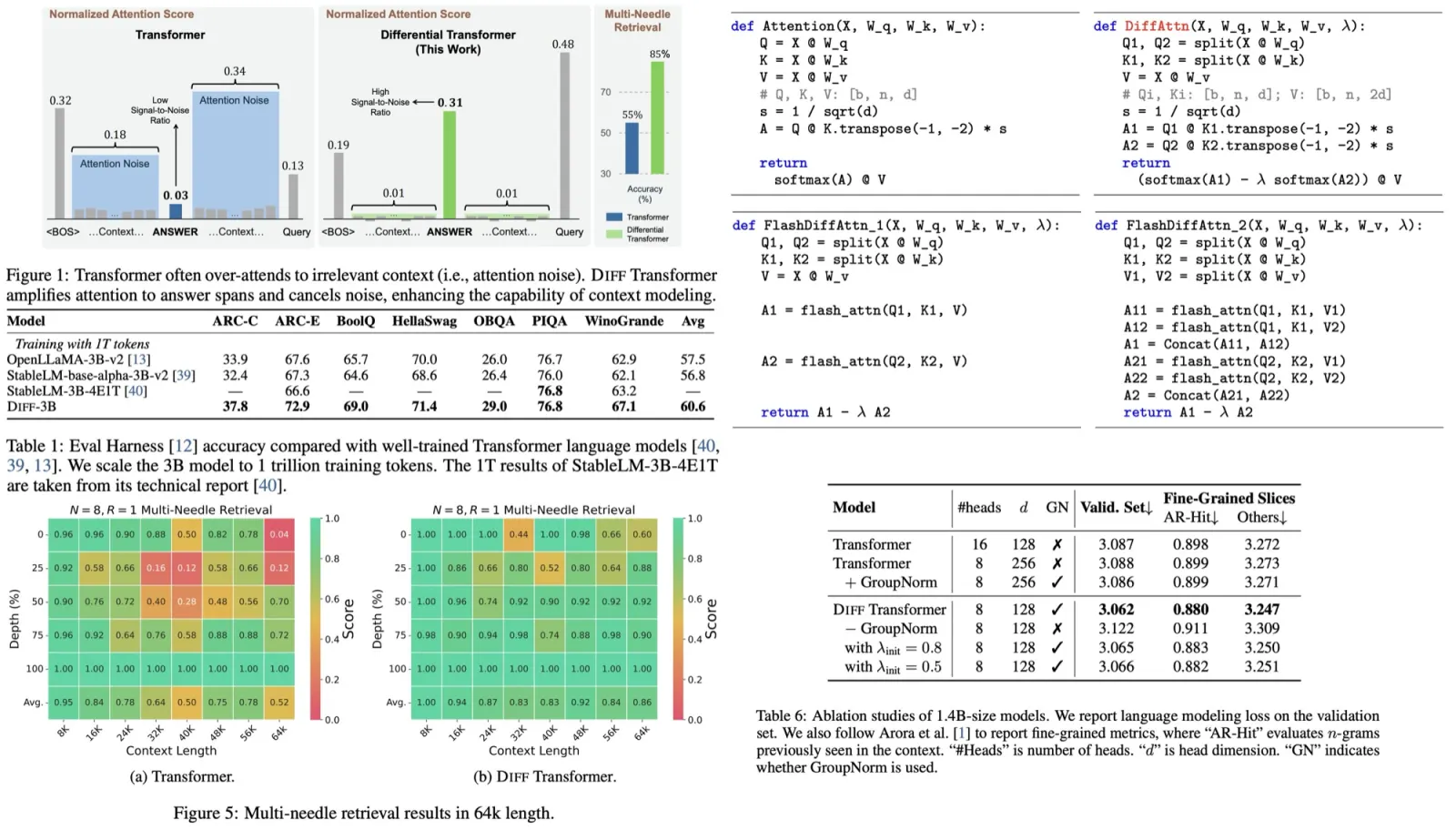
Problem formalization and overview

The Self-RAG model is trained to generate textual outputs with multiple segments (segment is a sentence). These segments include both original vocabulary and special reflection tokens. During inference, the model decides whether to retrieve additional information. If retrieval is unnecessary, it proceeds like a standard language model. If retrieval is needed, the model evaluates the relevance of the retrieved passage, the accuracy of the response segment, and the overall utility of the response using critique tokens. The model can process multiple passages simultaneously and uses reflection tokens for guidance.
For training, the model learns to generate text with reflection tokens by integrating them into its vocabulary. It’s trained on a corpus with retrieved passages and reflection tokens predicted by a critic model. This critic model evaluates the quality of retrieved passages and task outputs. The training corpus is updated with reflection tokens, and the final model is trained to generate these tokens independently during inference.
Self-RAG training
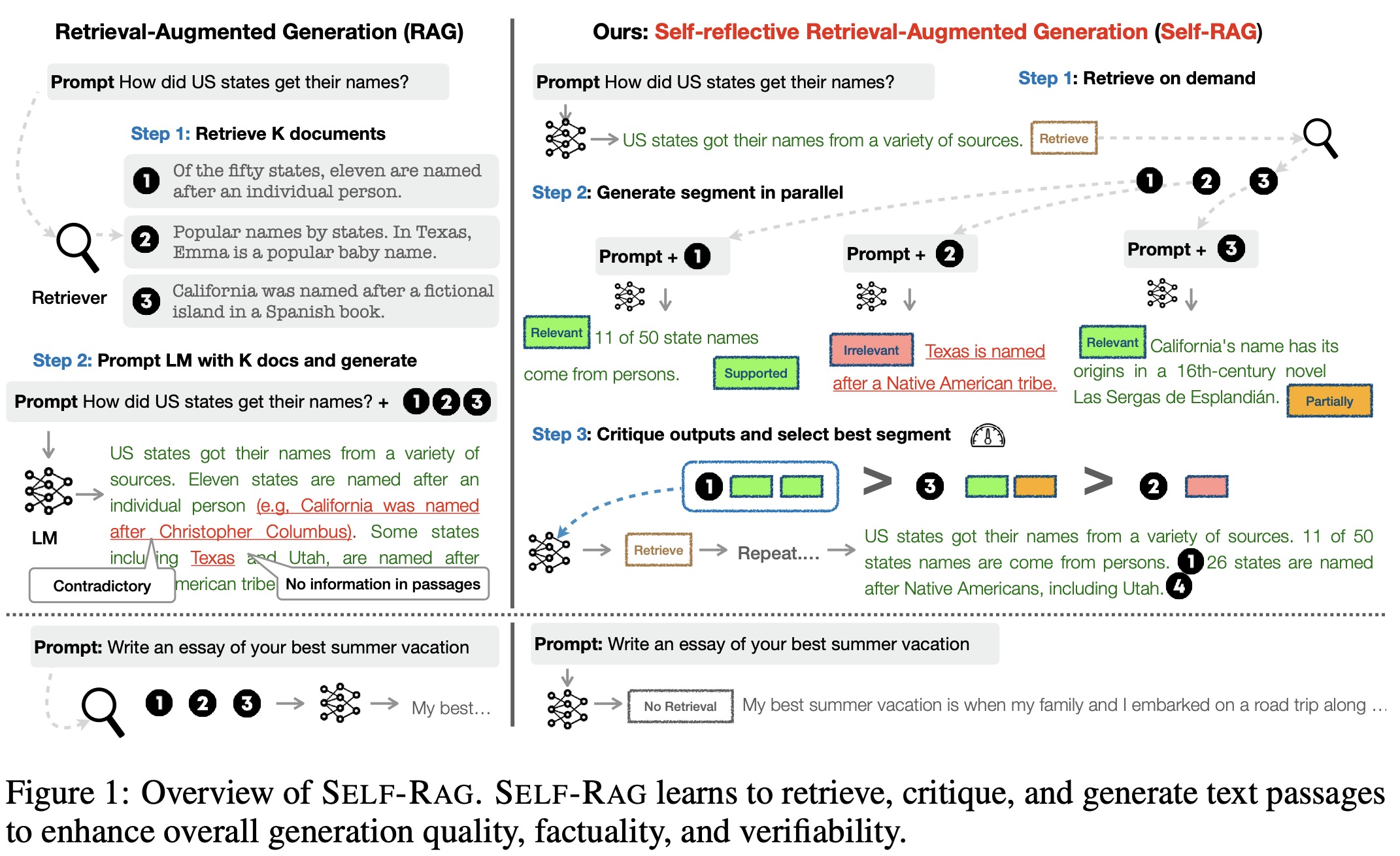
To train the critic model, manual annotation of reflection tokens is costly. Instead of relying on expensive proprietary models like GPT-4, the authors prompt GPT-4 to generate reflection tokens and then distill this knowledge into an in-house critic model. Different reflection token groups are prompted with specific instructions with few-shot demonstrations. For instance, the Retrieve token is prompted with an instruction to judge if external documents would improve a response.
Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.
GPT-4’s predictions of reflection tokens align well with human evaluations. Between 4k to 20k training data are collected for each token type. Once the training data is gathered, the critic model is initialized with a pre-trained language model and trained using a standard conditional language modeling objective. The initial model used for the critic is Llama 2-7B, and it achieves over 90% agreement with GPT-4 predictions for most reflection token categories.
To train the generator model, the original output is augmented using retrieval and critic models to simulate the inference process. For each segment, the critic model determines if additional passages would improve the generation. If so, a Retrieve=Yes token is added, and the top K passages are retrieved. The critic then assesses the relevance and supportiveness of each passage, appending critique tokens accordingly. The final output is augmented with reflection tokens.
The generator model is then trained on this augmented corpus using a standard next token objective, predicting both the target output and reflection tokens. During training, retrieved text chunks are masked out, and the vocabulary is expanded with reflection tokens Critique and Retrieve. This approach is more cost-effective than other methods like PPO, which rely on separate reward models. The Self-RAG model also incorporates special tokens to control and evaluate its own predictions, allowing for more refined output generation.
Self-RAG inference
Self-RAG uses reflection tokens to self-evaluate its outputs, making it adaptable during inference. Depending on the task, the model can be tailored to prioritize factual accuracy by retrieving more passages or emphasize creativity for open-ended tasks. The model can decide when to retrieve passages or use a set threshold to trigger retrieval.
When retrieval is needed, the generator processes multiple passages simultaneously, producing different continuation candidates. A segment-level beam search is conducted to get the top continuations, and the best sequence is returned. The score for each segment is updated using a critic score, which is a weighted sum of the normalized probability of each critique token type. These weights can be adjusted during inference to customize the model’s behavior. Unlike other methods that require additional training to change behaviors, Self-RAG can adapt without extra training.
Experiments
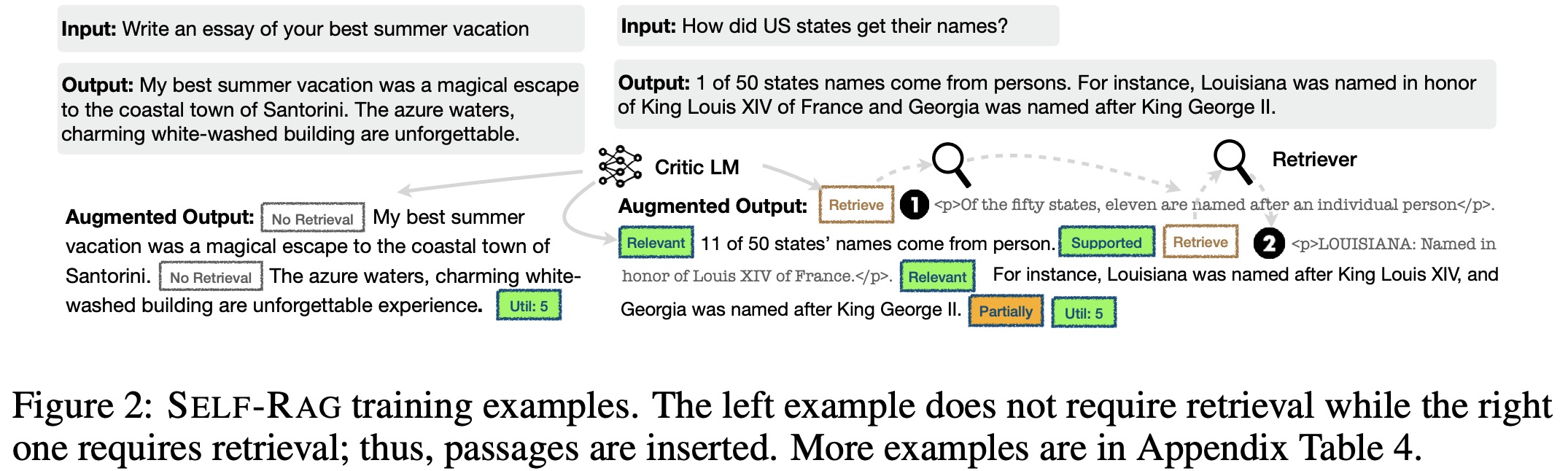
Self-RAG consistently outperforms various baselines in multiple tasks:
- Without Retrieval: Self-RAG significantly surpasses supervised fine-tuned LLMs in all tasks. It even outperforms ChatGPT in tasks like PubHealth, PopQA, biography generations, and ASQA. It also exceeds a concurrent method, CoVE, which uses prompt engineering, especially in the bio generation task.
- With Retrieval: Self-RAG tops existing RAG models in many tasks, achieving the best results among non-proprietary LM-based models. While some instruction-tuned LMs with retrieval show gains in tasks like PopQA or Bio, they fall short in tasks where direct extraction from retrieved passages isn’t feasible. Most retrieval baselines also struggle with citation accuracy. However, Self-RAG excels in citation precision and recall, even surpassing ChatGPT in citation precision. Interestingly, the smaller Self-RAG 7B sometimes outperforms the 13B version due to its tendency to produce more concise, grounded outputs.
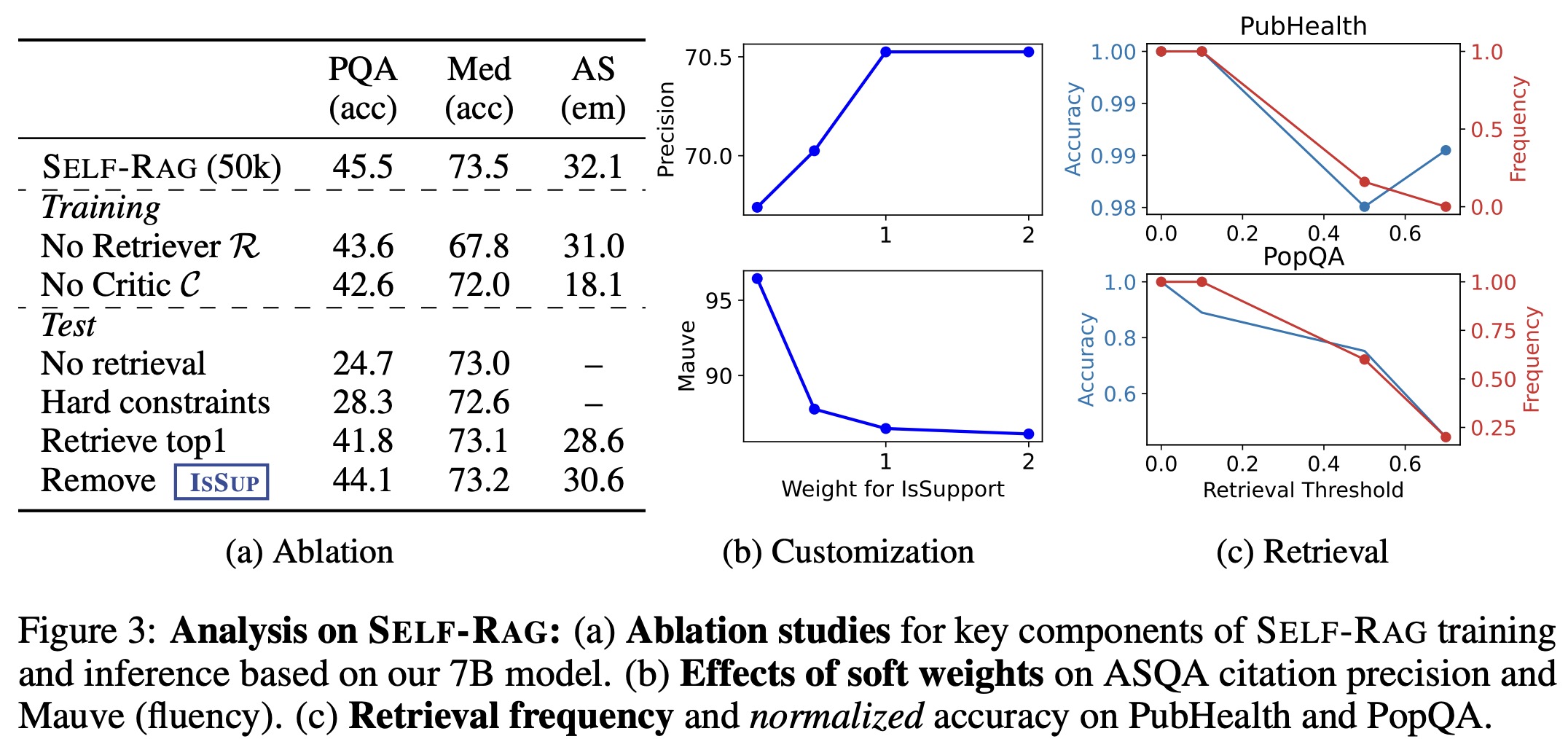
Results showed a significant performance gap between Self-RAG and the “No Retriever” or “No Critic” baselines, highlighting the importance of these components. Using only the top passages without considering relevance or solely relying on relevance scores was less effective than Self-RAG’s nuanced approach.
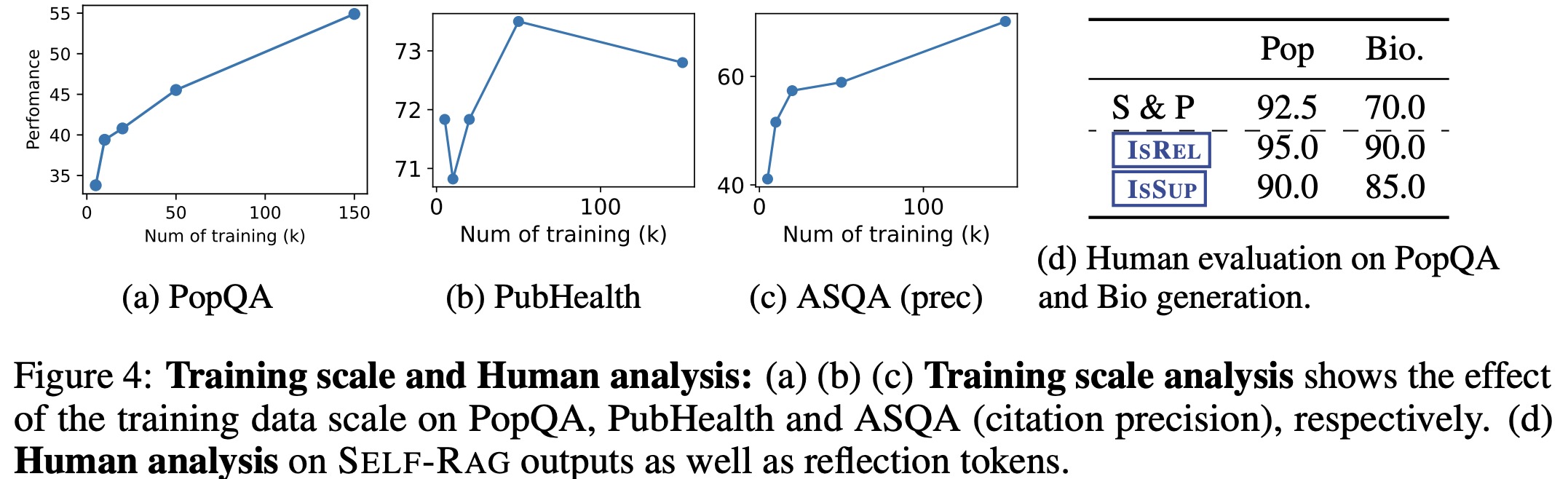
The impact of training data size on the performance of Self-RAG was explored by fine-tuning the model on subsets of 5k, 10k, 20k, and 50k from the original 150k instances. Performance generally improved with more data, especially in PopQA and ASQA. It is possible to get further potential benefits from expanding Self-RAG’s training data beyond 150k.
Human evaluations of Self-RAG show that Self-RAG’s answers are plausible and supported by relevant evidence.
paperreview deeplearning llm nlp