Paper Review: Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
The rapid advancement of foundation models has transformed the field of artificial intelligence, with large diffusion models gaining popularity for their photorealistic image generation capabilities. Deploying these models on devices can reduce server costs, enable offline functionality, and enhance user privacy. However, their large size (over 1 billion parameters) presents computational and memory challenges.
The authors from Google present a series of implementation optimizations that enable the fastest inference latency to date for large diffusion models on GPU-equipped mobile devices, making generative AI more accessible and improving user experience across various devices (under 12 seconds for Stable Diffusion 1.4 without INT8 quantization for a 512 × 512 image with 20 iterations).
GPU-Aware Optimizations
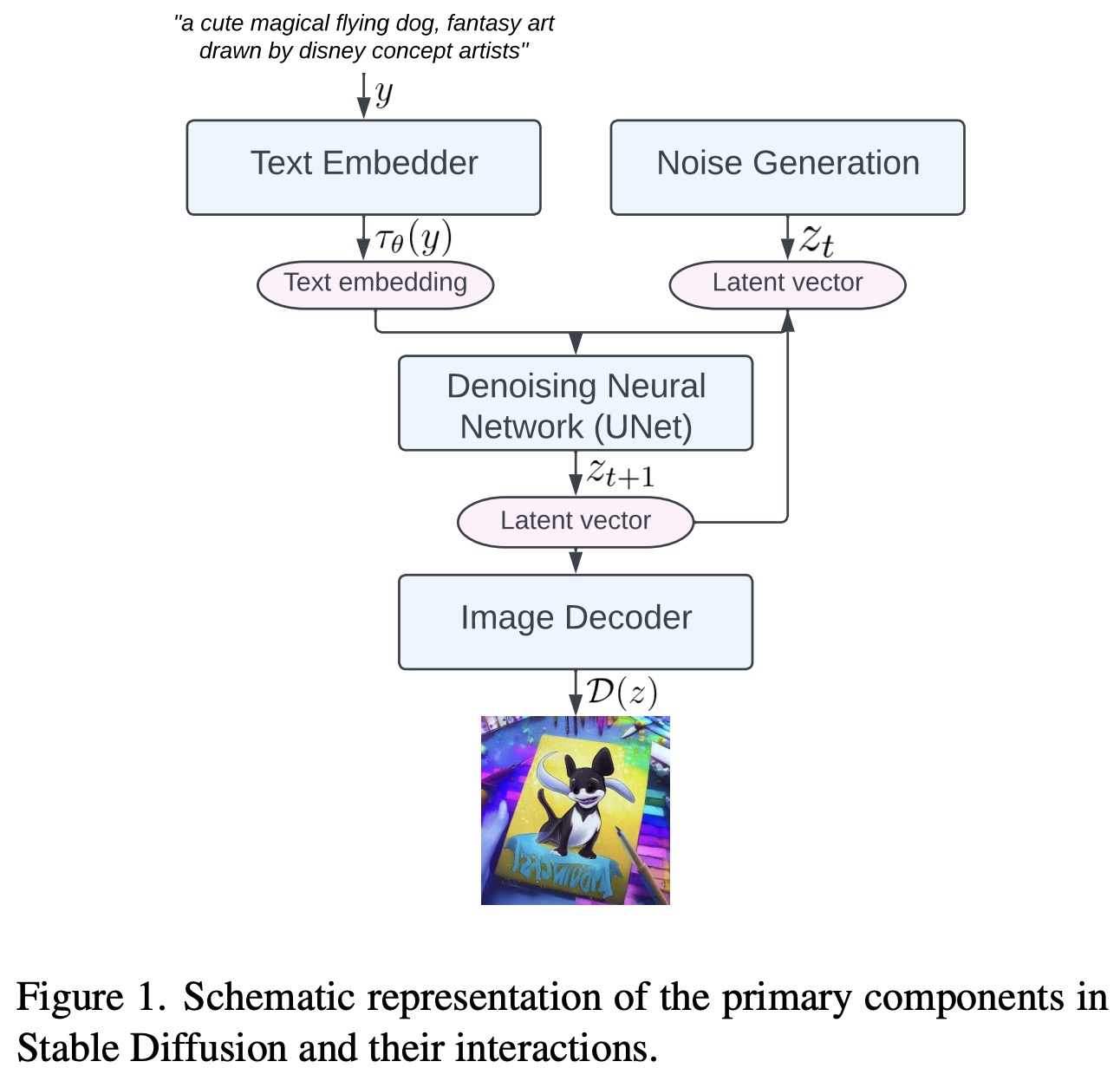
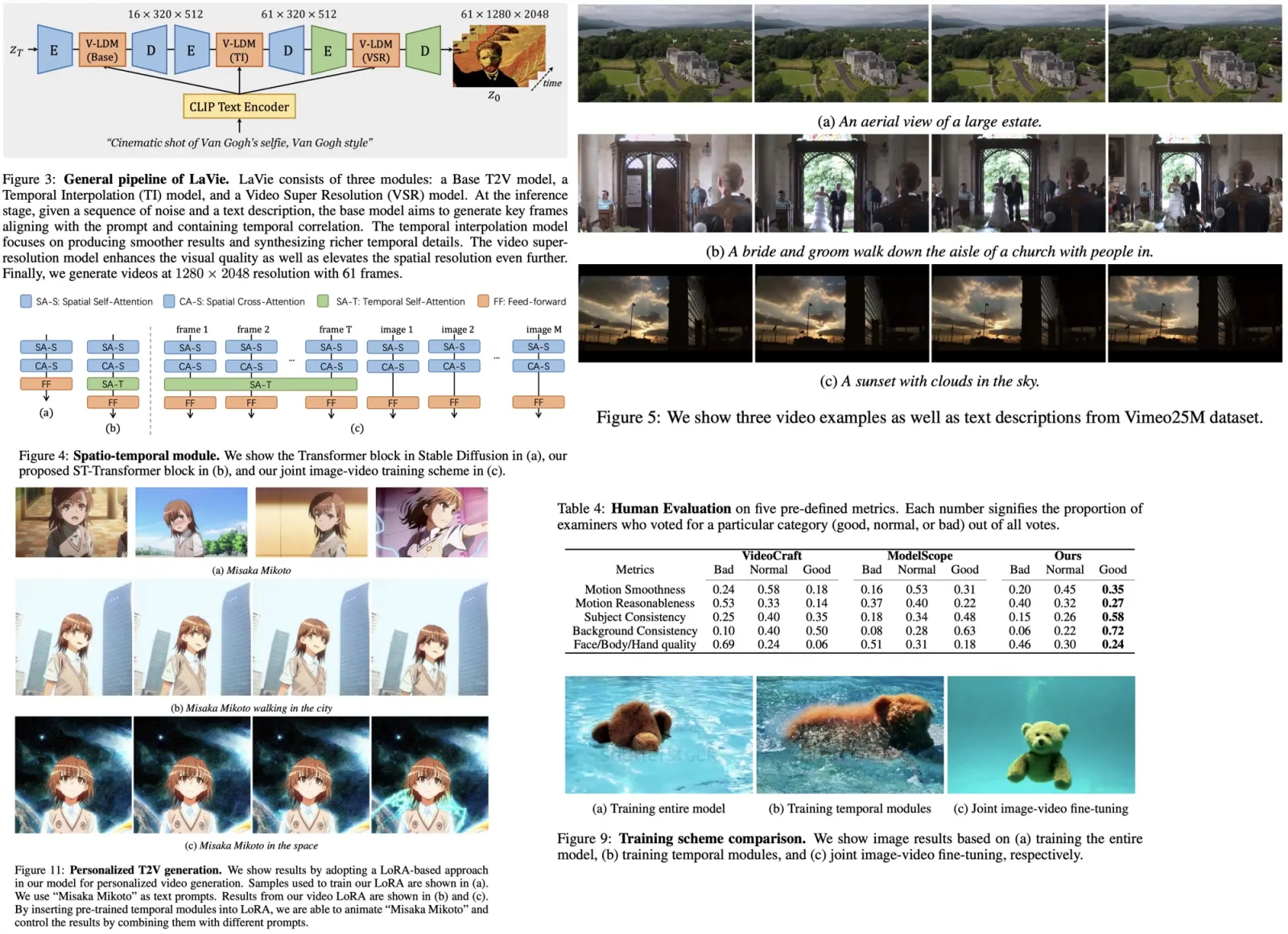
Stable Diffusion consists of four main components: a text embedder, noise generation, denoising neural network, and image decoder.
- The text embedder uses the CLIP model to encode text prompts into high-dimensional embedding vectors, which guide the reverse diffusion process.
- Noise generation provides random noise in the latent space, acting as the starting point for the process.
- The denoising neural network approximates conditional distributions using a conditional denoising autoencoder and the UNet architecture, with a cross-attention mechanism operating on the latent space and text embeddings.
- The image decoder reconstructs the RGB image from the latent vector after the reverse diffusion process is completed.
Specialized Kernels: Group Norm and GELU
The authors develop a unique GPU shader that combines multiple GN operations (reshape, mean, variance, normalize) into a single GPU command without intermediate tensors. The Gaussian Error Linear Unit (GELU) is used as the primary activation function in the model, and the authors create a dedicated shader to consolidate its numerical computations, allowing them to execute in a single draw call.
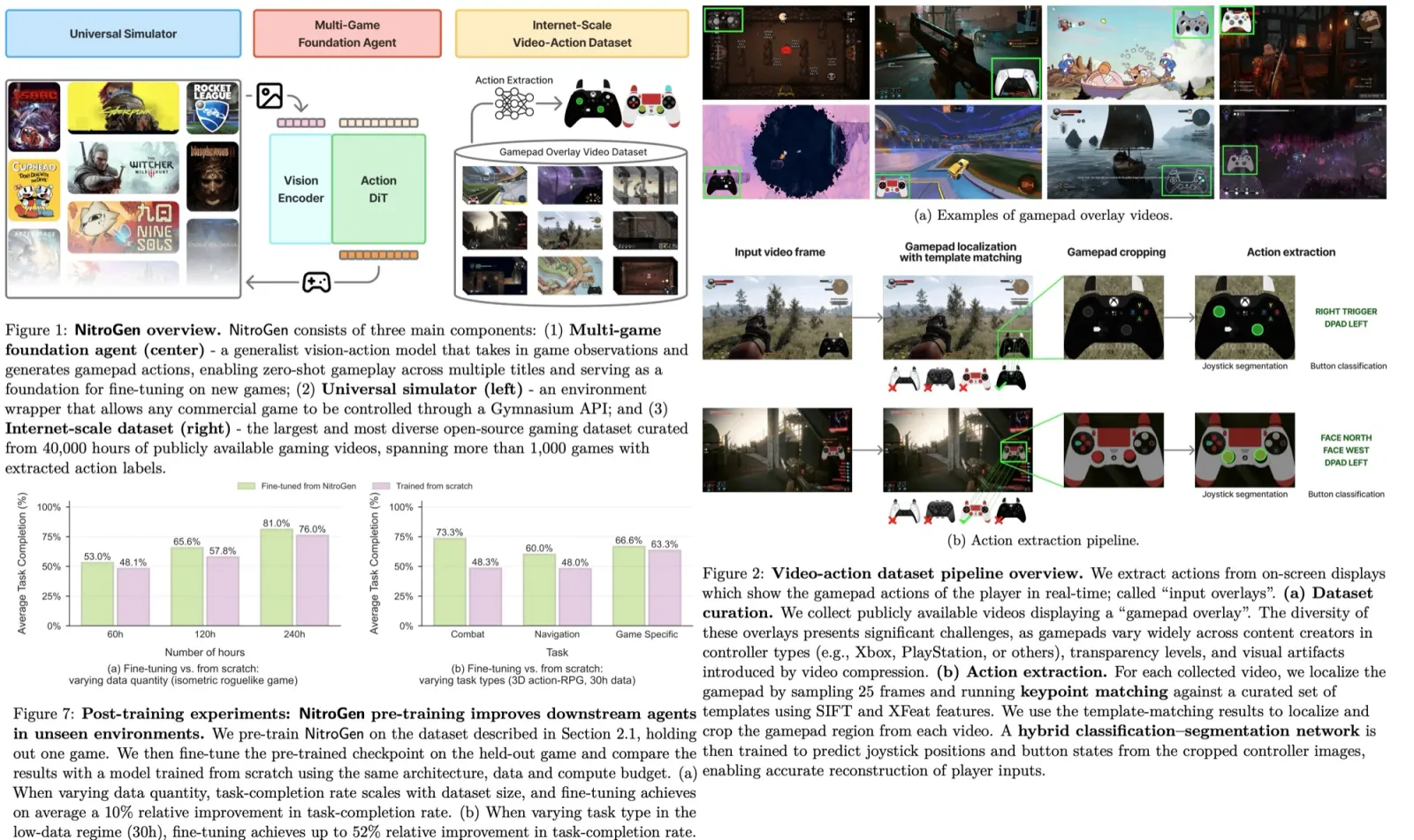
Partially Fused Softmax
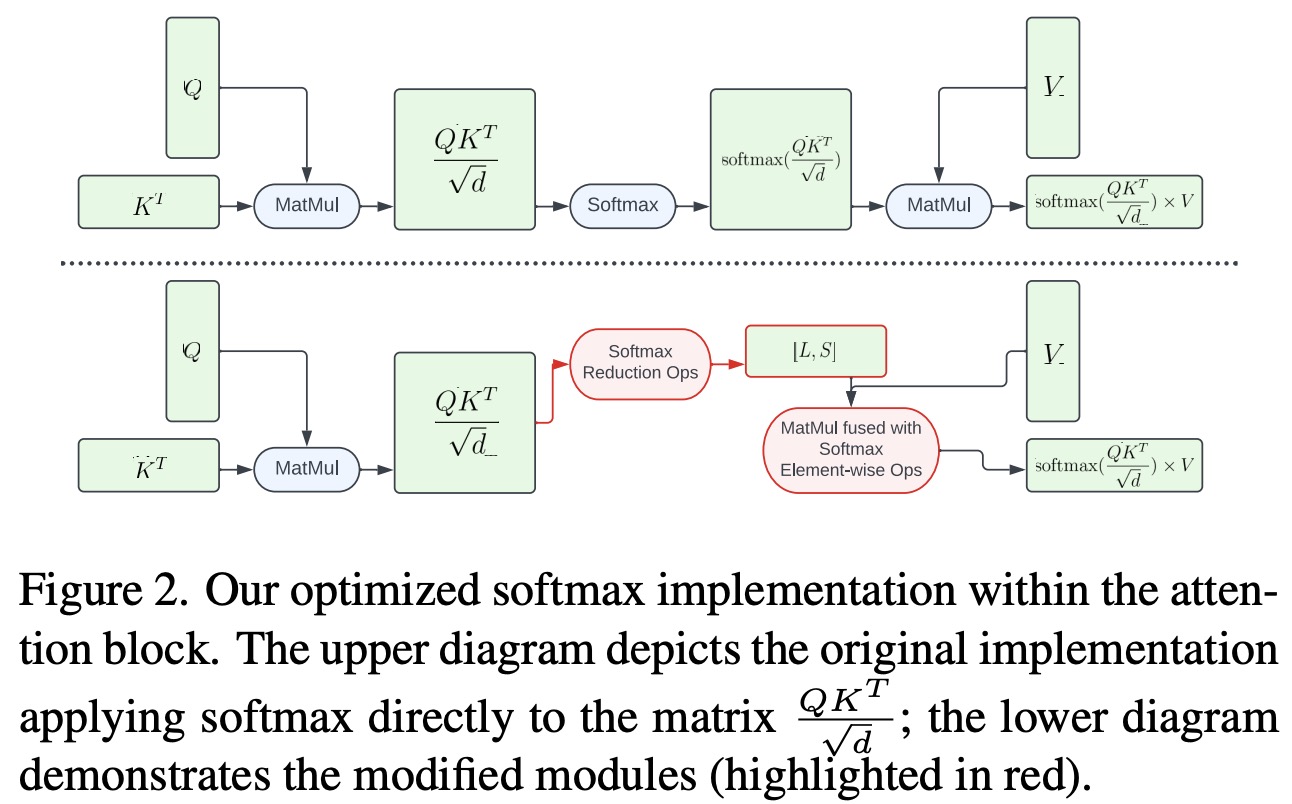
The attention computation is used in the intermediate layers of the UNet. It involves query, key, and value matrices (Q, K, and V) and a softmax operation on matrix A. The softmax operation can be partitioned into two steps: 1) reduction operations, which calculate the maximum values of each row in A and its modified exponential sum S; and 2) element-wise operations, which normalize the values in A using the vectors L and S.
The authors implement a GPU shader for reduction operations to compute L and S vectors from the large matrix A, reducing the memory footprint and overall latency. They fuse the element-wise softmax computation with the subsequent matrix multiplication involving matrix V. To improve parallelism and decrease latency, they partition the reduction operations into multiple stages by grouping elements in A into blocks. Calculations are performed on each block and then reduced to the final result. Through carefully designed threading and memory cache management, this multi-stage implementation can be executed with a single GPU command, leading to further latency reduction.
FlashAttention
Many approximate attention methods sacrifice model quality to reduce computational complexity and improve latency. In contrast, FlashAttention is an IO-aware, exact attention algorithm that minimizes memory reads/writes between GPU high bandwidth memory (HBM) and on-chip SRAM through tiling. This results in fewer HBM accesses and improved overall efficiency. However, FlashAttention has a highly register-intensive kernel. The authors selectively employ this technique for attention matrices with dimension d=40 on Adreno and Apple GPUs, while using the partially fused softmax in other cases.
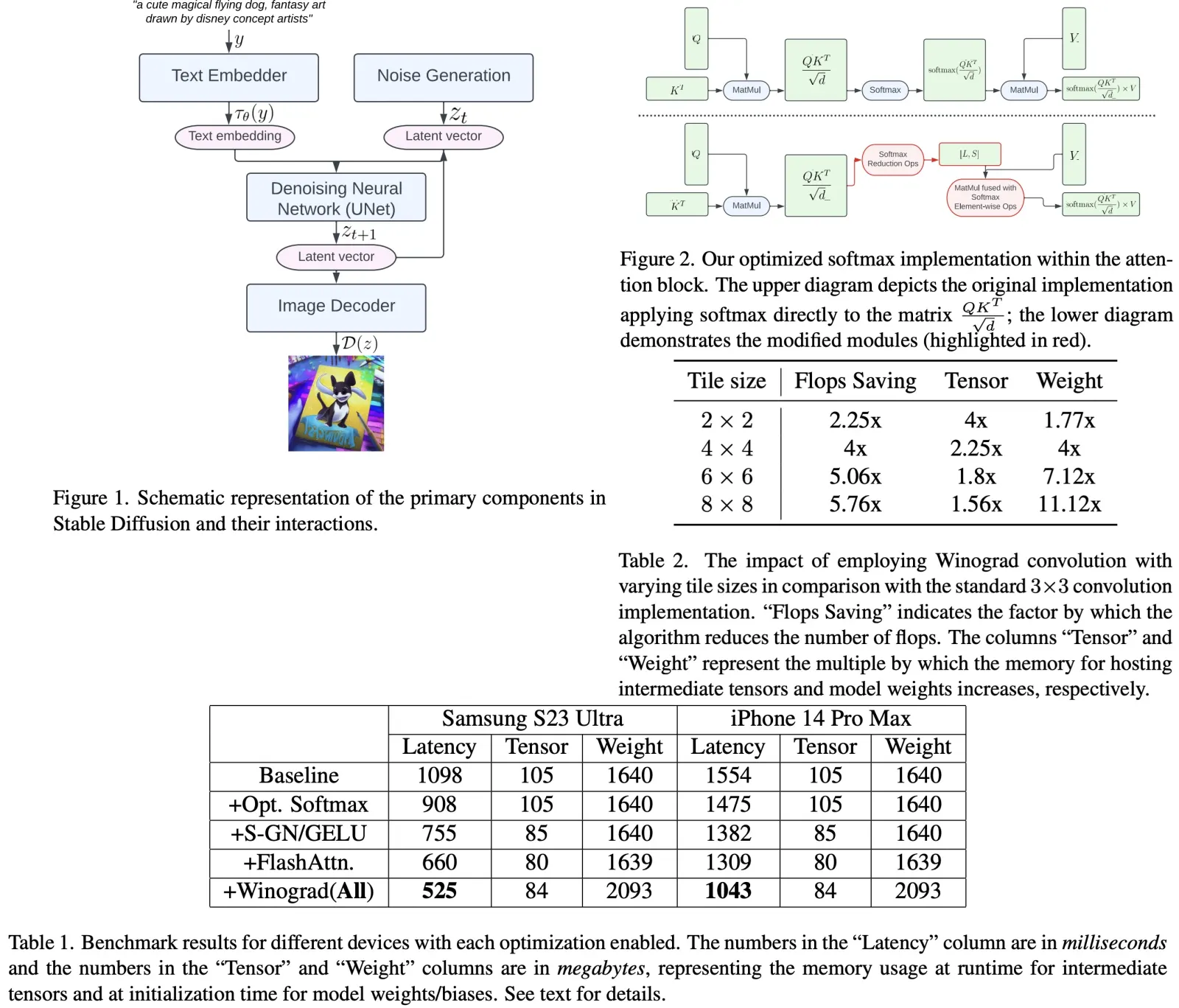
Winograd Convolution
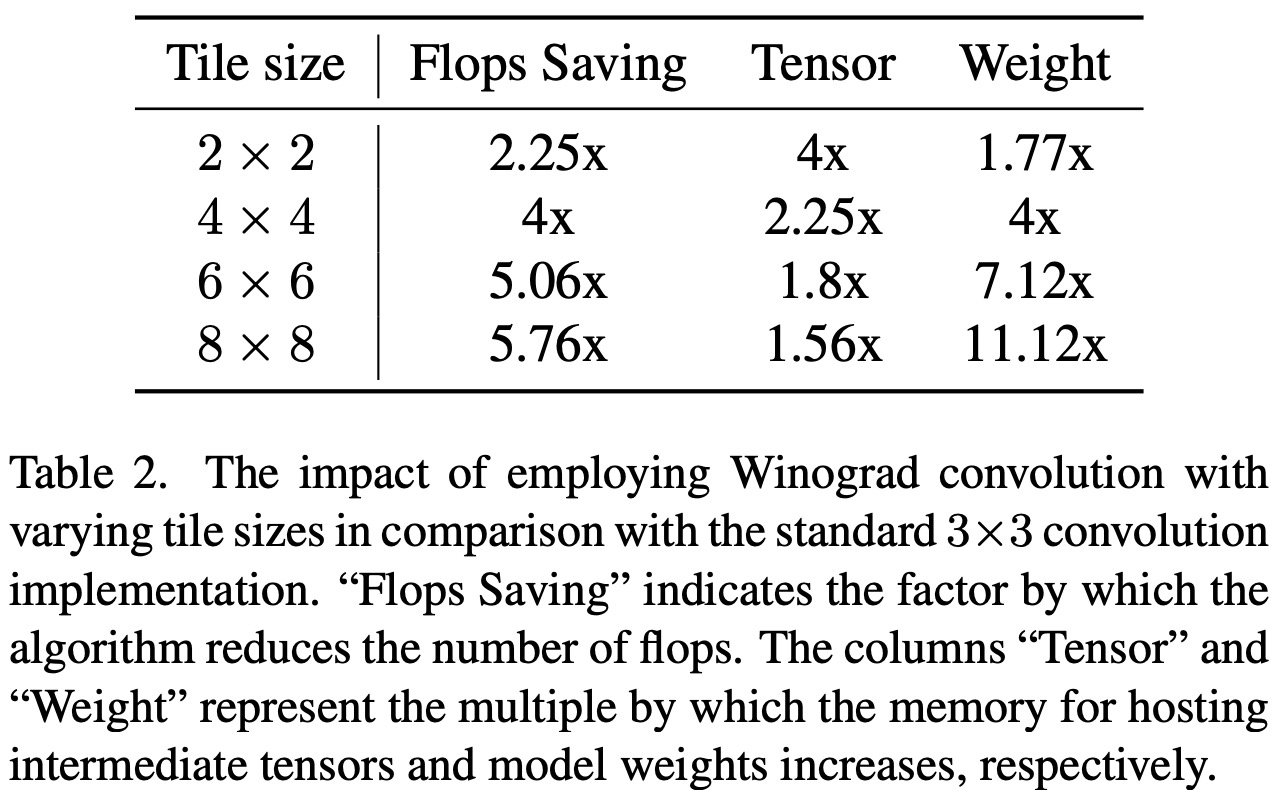
Winograd convolution transforms convolution operations into a series of matrix multiplications, reducing required multiplications and improving computational efficiency. However, it also increases memory consumption and numerical errors, especially with larger tile sizes. The backbone of Stable Diffusion relies heavily on 3x3 convolution layers, particularly in the image decoder. The authors analyze the benefits of using Winograd with varying tile sizes and choose a 4x4 tile size for optimal balance between computational efficiency and memory utilization. They apply Winograd based on heuristic rules to maximize its efficacy, only where it would produce improvement.
Results
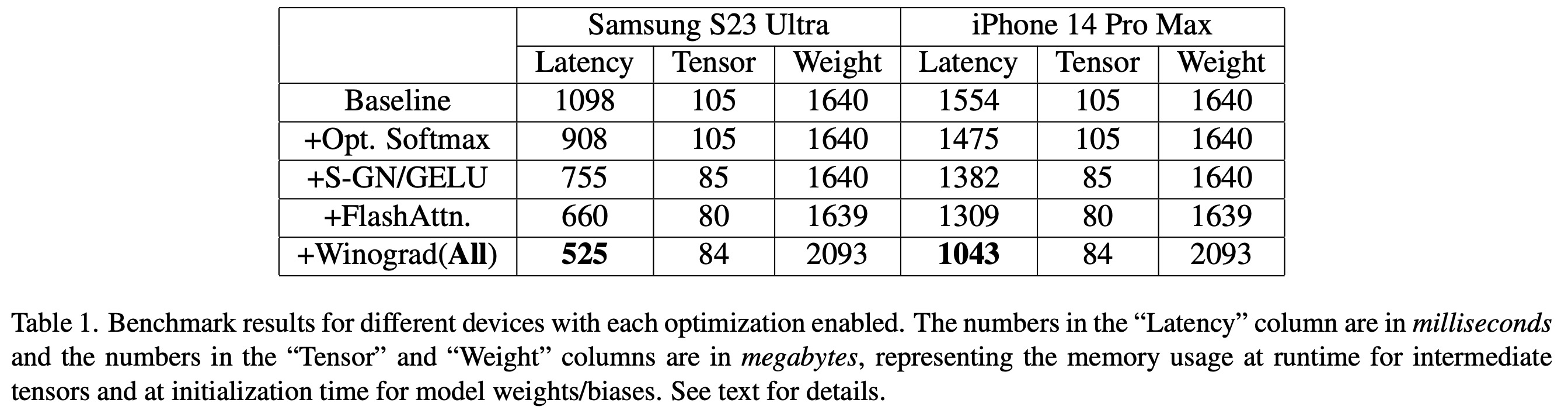
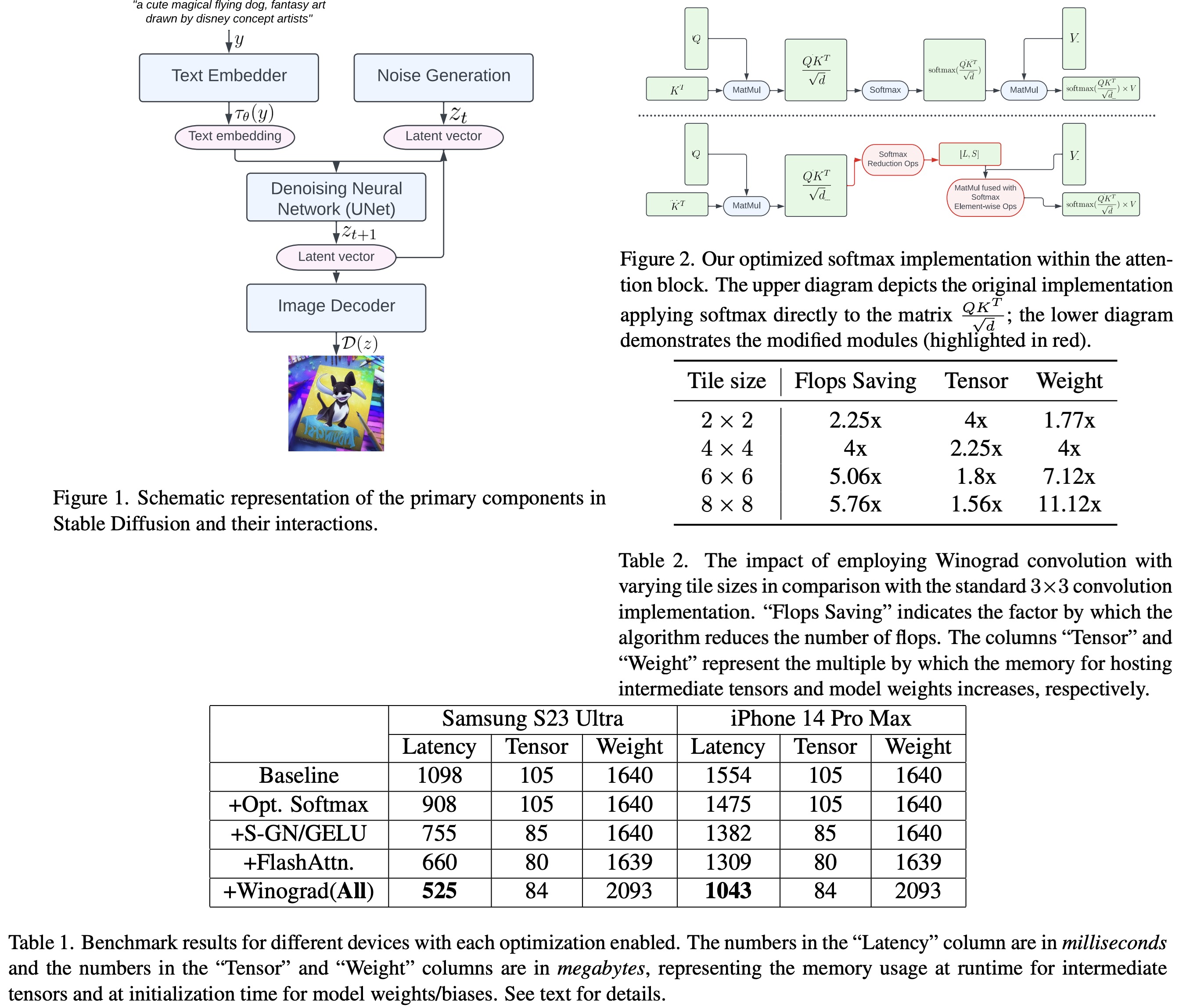
The authors evaluate the improvements by benchmarking various devices, focusing on the most computationally demanding component, the UNet. Latency figures and memory usage are provided for executing UNet for a single iteration with a 512x512 image resolution. The table in their study shows results for different optimization techniques, including partially fused softmax, specialized kernels for Group Normalization and GELU, FlashAttention, and Winograd convolution.
Latency decreases incrementally as each optimization is activated, with significant overall latency reductions compared to the baseline observed on both devices: Samsung S23 Ultra (-52.2%) and iPhone 14 Pro Max (-32.9%). The end-to-end latency on the Samsung S23 Ultra for 20 denoising iteration steps to generate a 512x512 pixel image is achieved in under 12 seconds, representing a state-of-the-art result.
paperreview deeplearning diffusion