Paper Review: σ-GPTs: A New Approach to Autoregressive Models
Autoregressive models, like GPT, typically generate sequences left-to-right, but this isn’t necessary. Adding a positional encoding for outputs allows modulating the order per sample, enabling flexible sampling and conditioning on arbitrary token subsets. It also supports dynamic multi-token sampling with a rejection strategy, reducing the number of model evaluations. This method is evaluated in language modeling, path-solving, and aircraft vertical rate prediction, significantly reducing the required generation steps.
Methodology
σ-GPTs: Shuffled Autoregression
σ-GPT shuffles the sequence randomly during training, requiring the model to predict the next token based on previously seen tokens. The training uses standard cross-entropy loss and includes a double positional encoding. No other changes to the model or training pipelines are necessary.
Double Positional Encodings
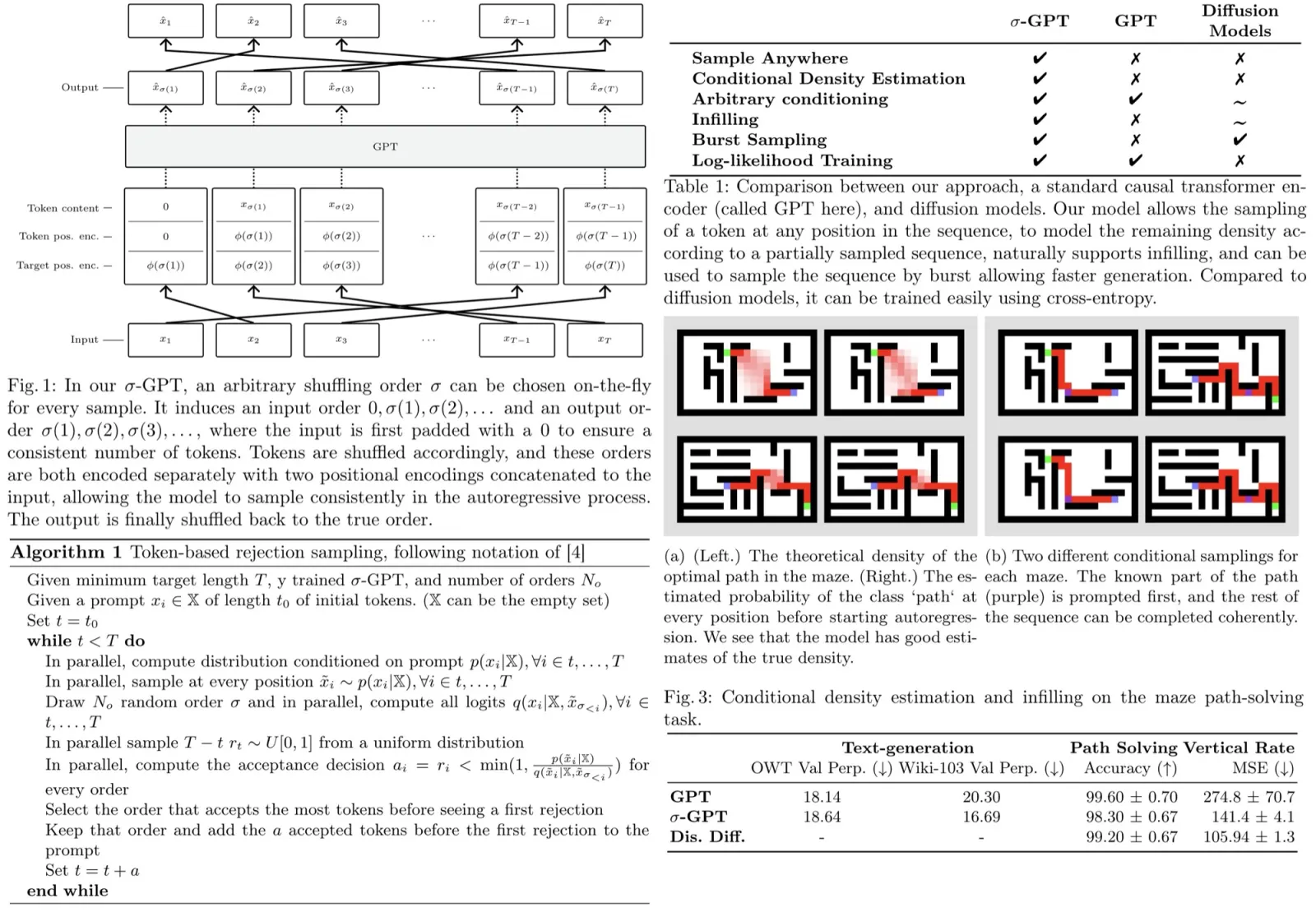
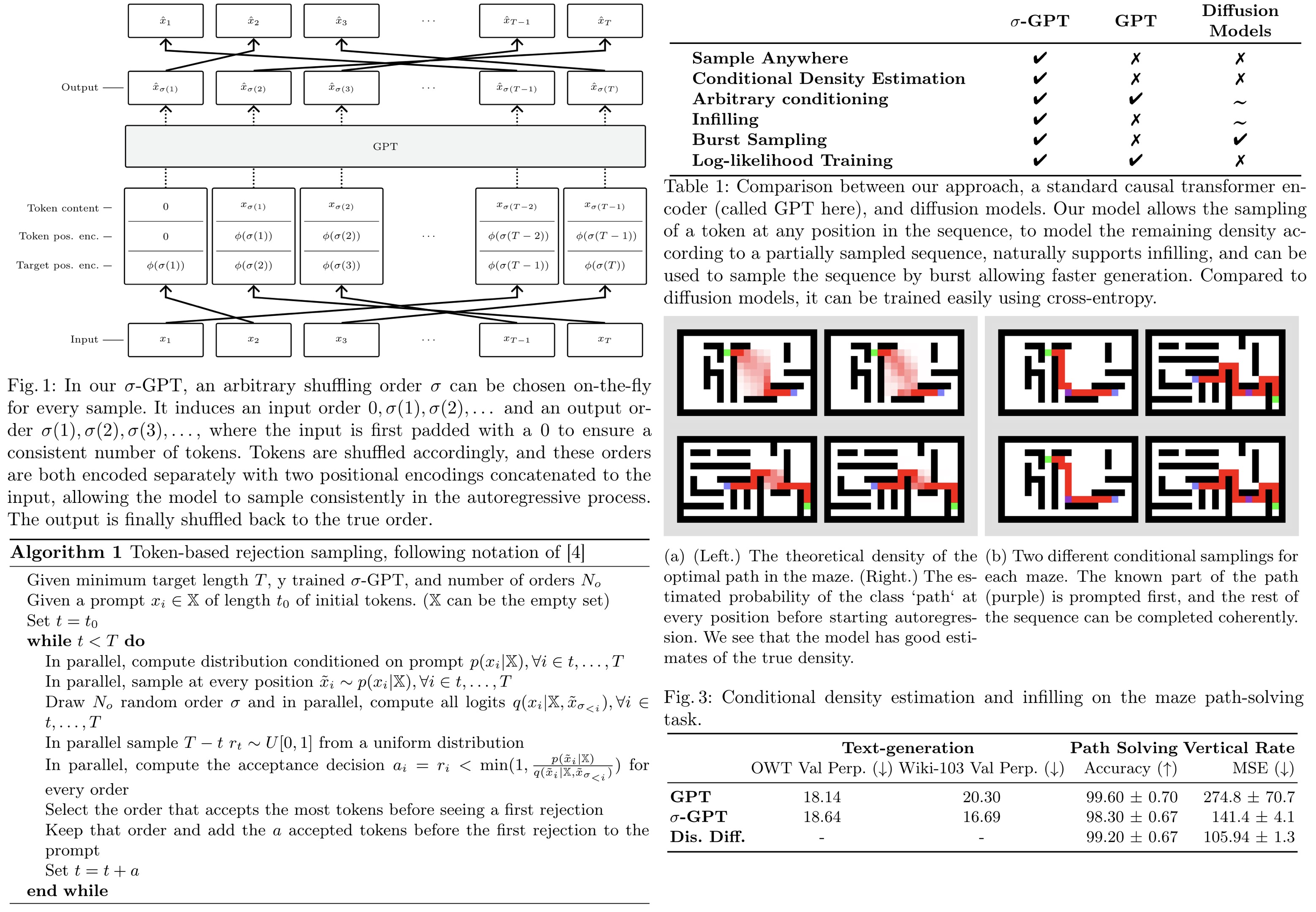
To model sequences in any order, each token must have information about its own position and the next token’s position in the shuffled sequence. Each token in a sequence, given a permutation σ, contains its value, its current position, and the position of the next token in the shuffled sequence. The only architectural change needed is this double positional encoding (necessary because transformers attend to tokens in a position-invariant manner), implemented using standard sinusoidal positional encoding for both input and output.
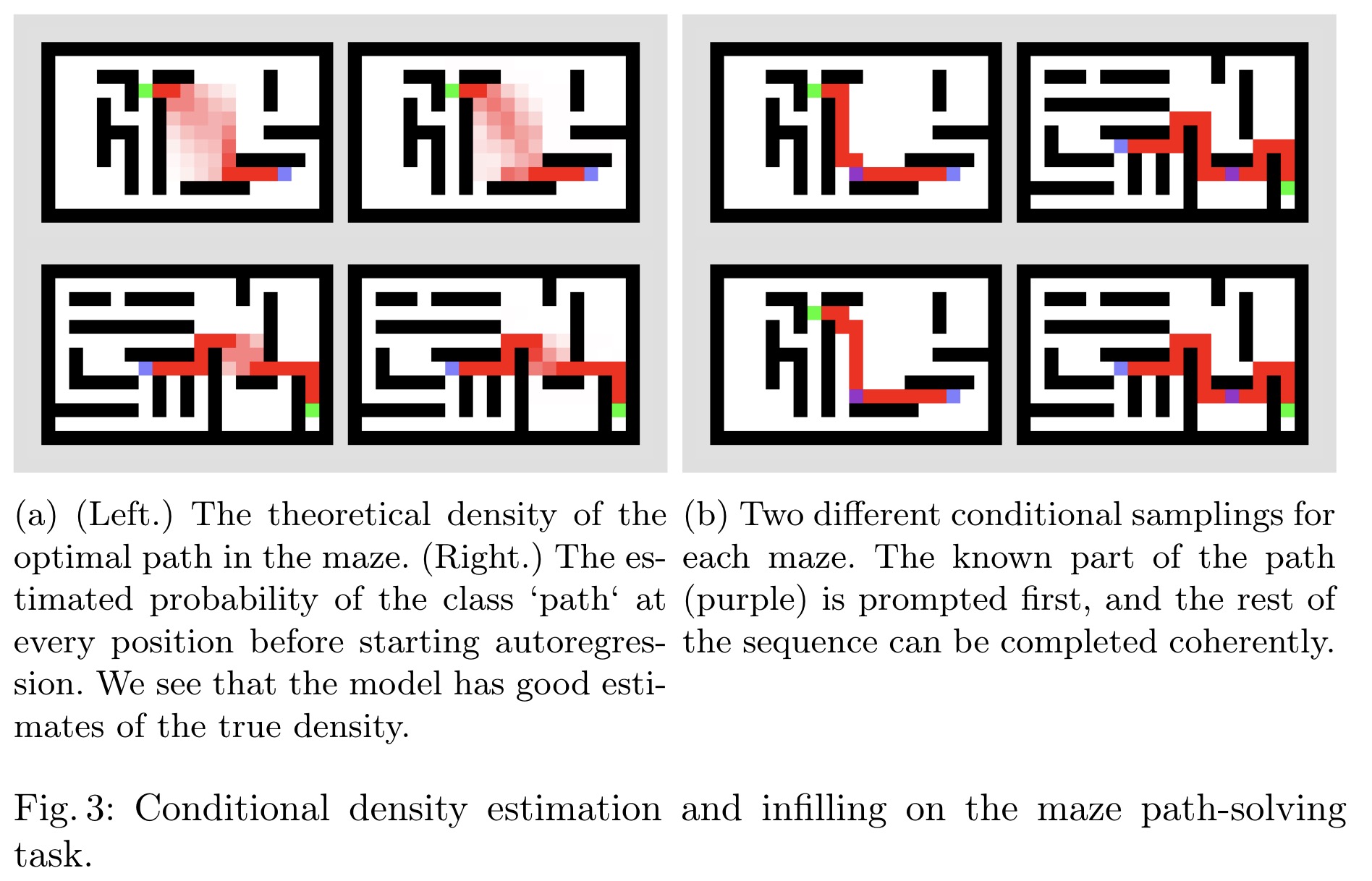
Conditional Probabilities and Infilling
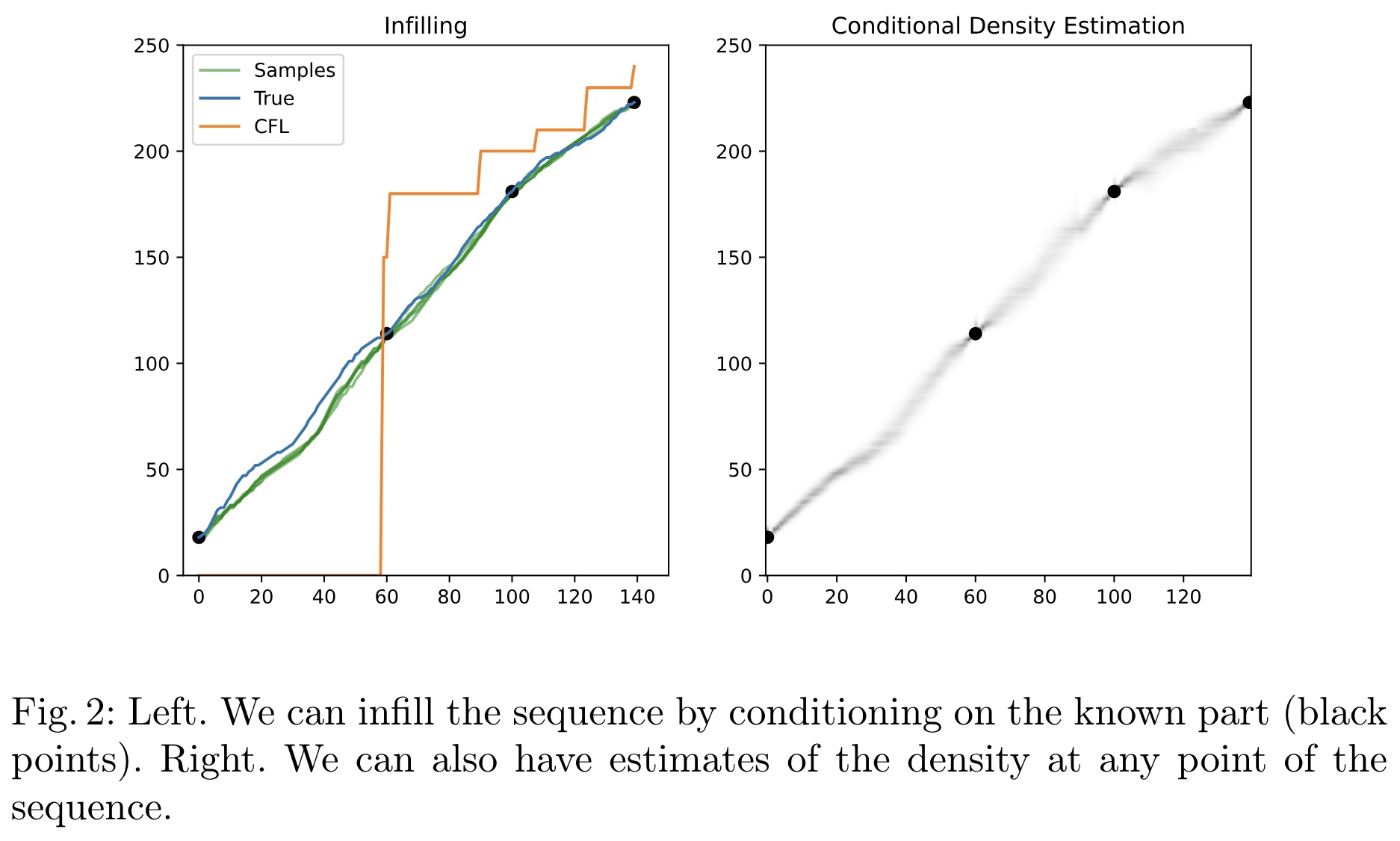
The suggested method enables conditional density estimation across the entire sequence, making predictions based on any known subsequence. By prompting the model with the known part and decoding the remaining tokens in parallel and in one pass, it overcomes the limitations of traditional left-to-right autoregressive models. This approach also supports infilling by prompting the model with the known part of a signal and decoding the rest either auto-regressively or in bursts.
Token-based Rejection Sampling

Autoregressive generation is slow because tokens are generated sequentially, making it inefficient for long sequences. σ-GPT generates tokens in any order, allowing parallel sampling at every position. This method evaluates candidate sequences in different orders, accepting multiple tokens in one pass, which runs efficiently on GPUs using an adapted KV-caching mechanism. When conditioned on partially completed sequences, the model outputs compatible distributions, rejecting incoherent tokens. This rejection sampling algorithm efficiently accepts tokens and can generate multiple samples simultaneously. Unlike other models like Mask Git or diffusion models, which require fixed steps or masking schedules, this method adapts dynamically to data statistics without needing extra hyper-parameters.
Other orders
The double positional encoding scheme allows training and evaluating models in any order. Randomized order during training enables conditional density estimation, infilling, and burst sampling during inference. The scheme also supports training models in deterministic orders, such as a ‘fractal’ order, which starts in the middle of the sequence and recursively visits all positions. However, this deterministic order, unlike left-to-right, may lead to more challenging training due to the lack of locality information. In theory, the order of modeling and decoding should not matter for perfect models due to the chain rule of probability.
Denoising diffusion models
Denoising diffusion models generate sequences in a few steps by reversing a diffusion process applied to the data. This process can be continuous or discrete; this work uses a discrete uniform diffusion process as a baseline. For fair comparison, both σ-GPT and the diffusion model use the same transformer architecture, differing only in the training objective. Unlike σ-GPT, diffusion models require a fixed number of steps for sequence generation and do not natively support conditional density estimation or infilling.
Experiments
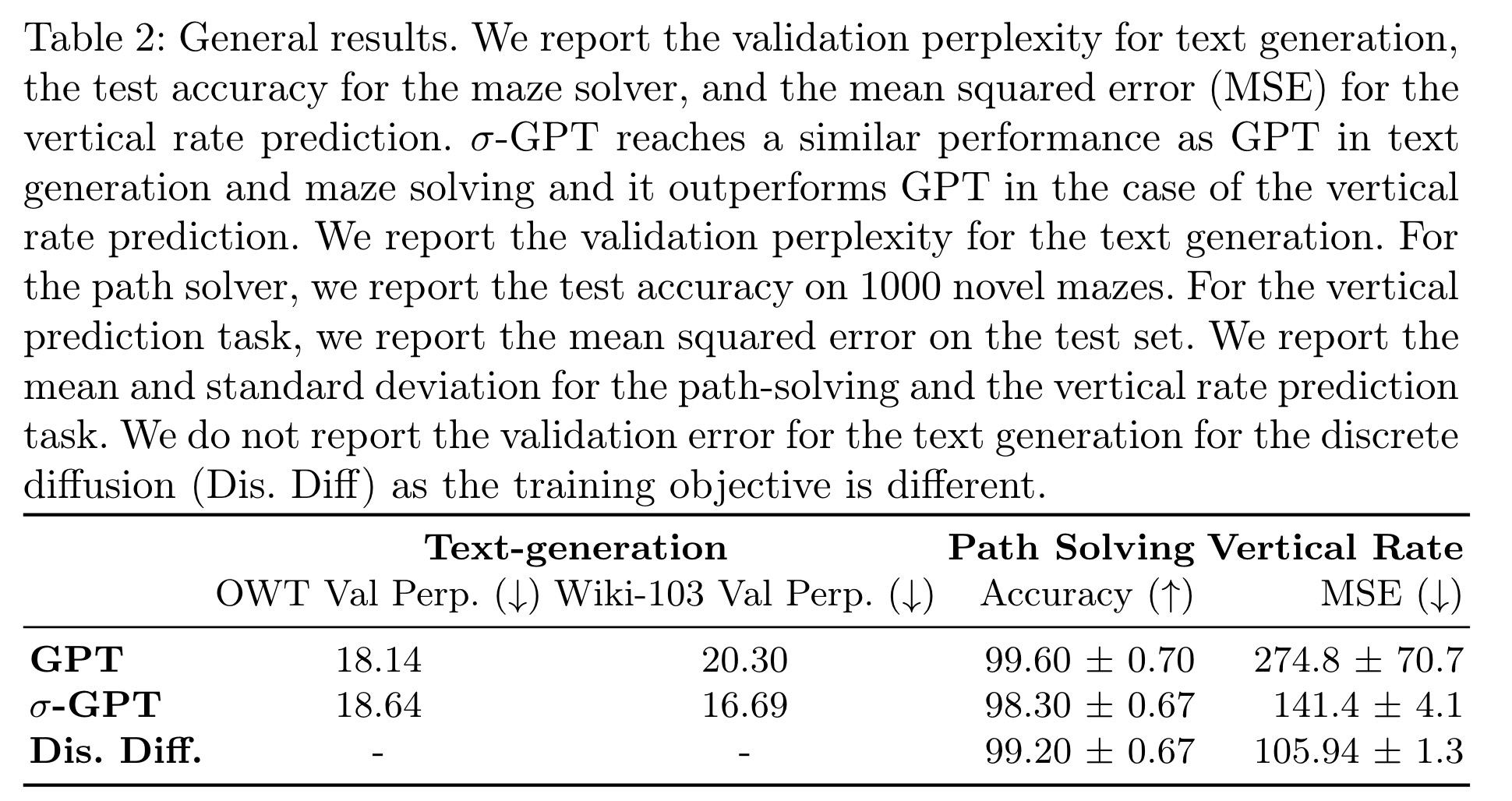
The results show that training models in a random order, despite requiring more compute time, achieves similar performance to left-to-right trained models. For text modeling, validation perplexity monitored in a left-to-right order plateaued higher with random order training, but using a curriculum scheme matched the performance of left-to-right training. For path solving and vertical rate prediction, models reached the same left-to-right validation loss. In inference, random order models had a 1% accuracy drop compared to diffusion models and left-to-right GPT. In vertical rate prediction, σ-GPT outperformed standard GPT, avoiding issues of repeating the same altitude and reducing MSE. This advantage is attributed to fixing some tokens early in the sequence generation, giving a preliminary sketch and then focusing on completing a coherent sample.

Modeling sequences in a random order is more challenging than left-to-right order due to the lack of adjacent tokens for educated guesses at the beginning and the inherent difficulty of some tasks in certain directions. This results in an increased number of steps or epochs required to learn a task.
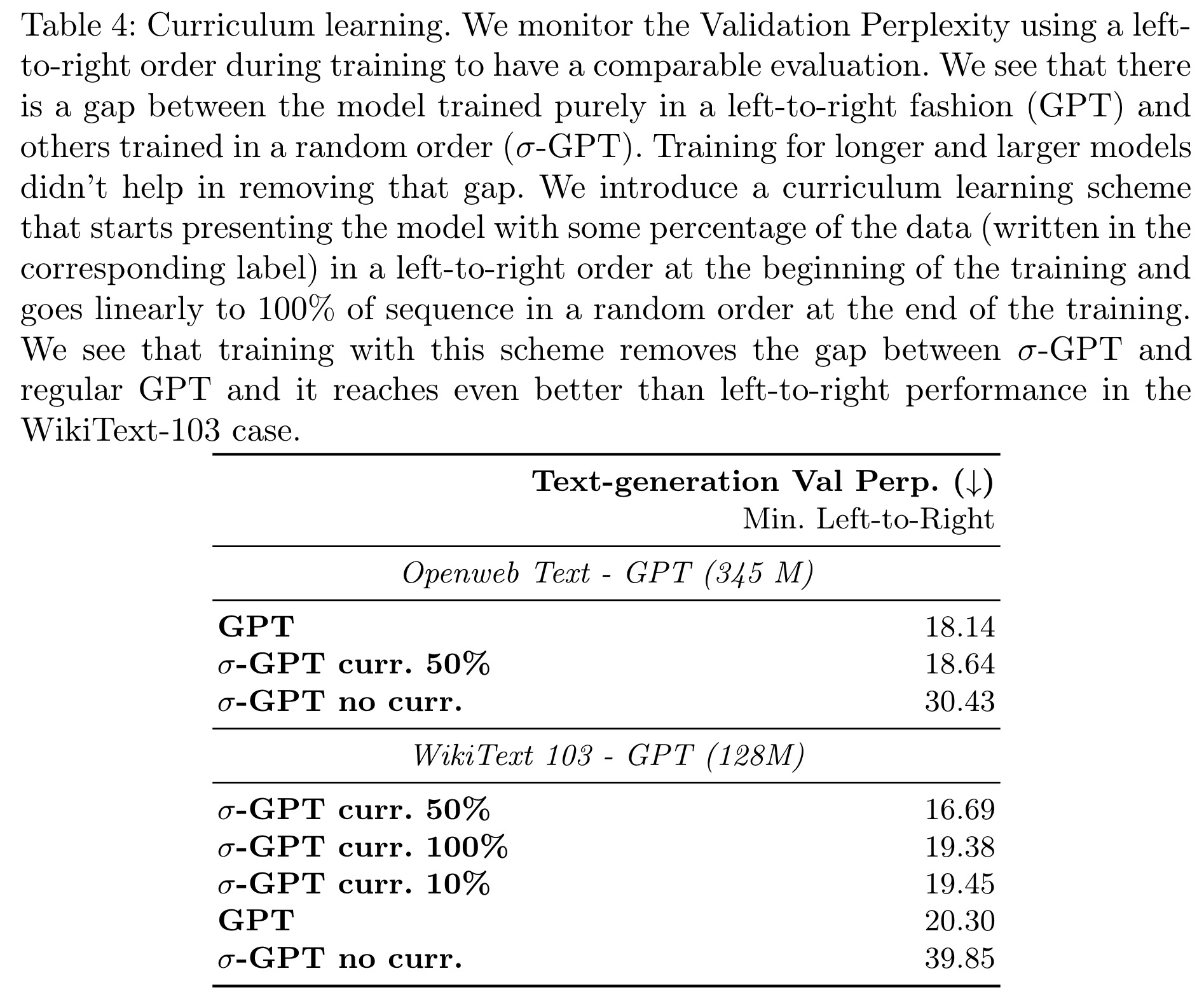
In text modeling, models trained purely in a random order had higher validation perplexity compared to those trained in a left-to-right order. Training for longer periods and using larger models did not reduce this gap. To address this, a curriculum learning scheme was introduced, starting with left-to-right sequences and gradually transitioning to random order. This approach significantly improved performance, with models achieving better results than left-to-right trained transformers on WikiText-103 and substantially reducing the gap on OpenWebText.
paperreview deeplearning nlp gpt textgeneration