Paper Review: Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding

The work introduces a method Skeleton-of-Thought (SoT) to decrease the generation latency in LLMs. The traditional sequential decoding approach in LLMs causes high latency, but SoT aims to mimic human thinking by first creating a skeleton of the answer and then completing the content in parallel. This technique provides a speed-up of up to 2.39 times across 11 different LLMs and may also improve the quality of answers in terms of diversity and relevance. SoT represents a move towards efficiency and human-like thinking in language model optimization.
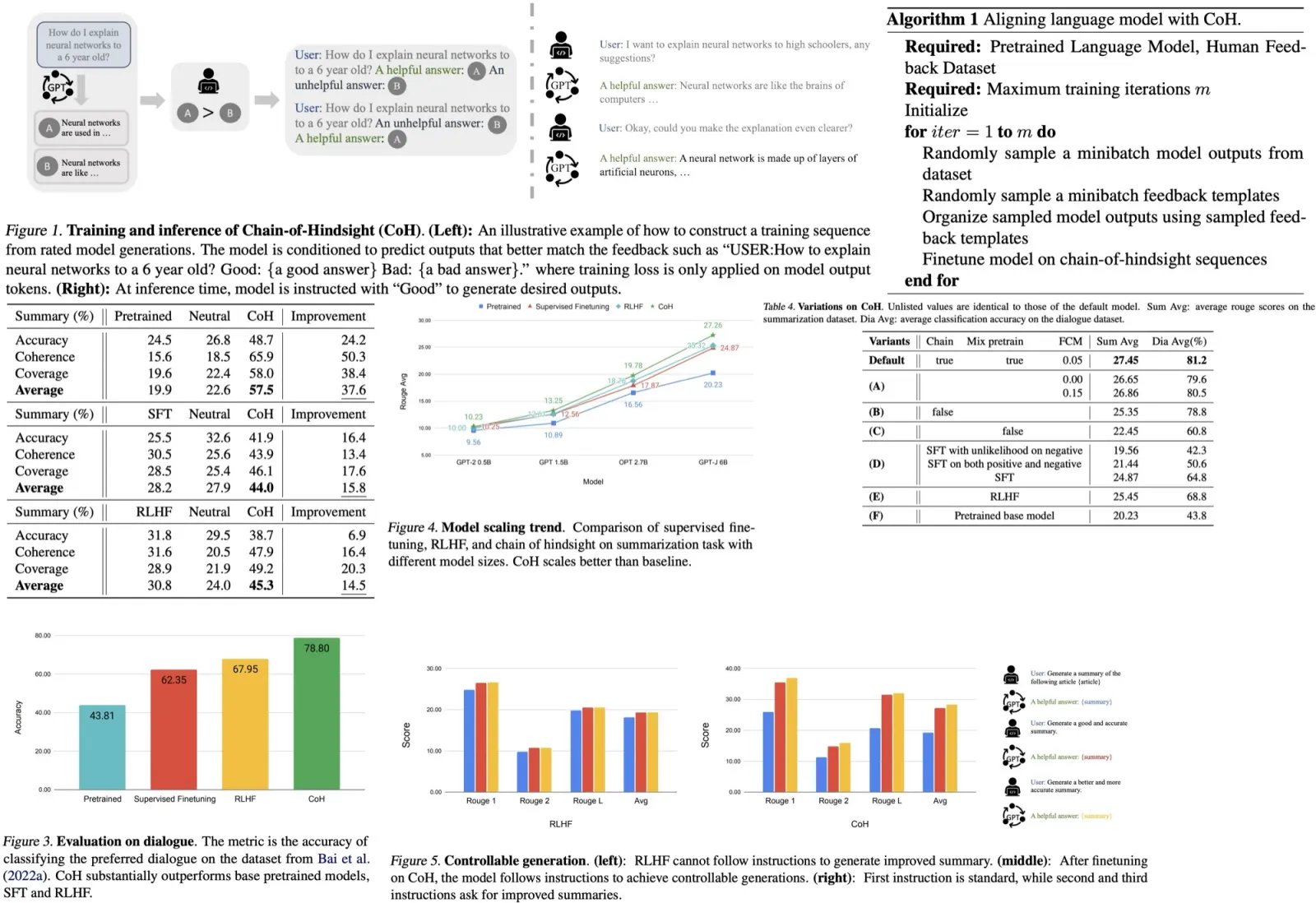
Skeleton-of-Thought
Method

The SoT process has two stages:
- Skeleton Stage: First, SoT assembles a skeleton request for a user question using a skeleton prompt template. This helps guide the LLM to create a concise skeleton of the answer, from which B points are extracted. The skeleton prompt template is crafted to ensure efficiency and ease of point extraction. It describes the task precisely, uses simple demonstrations, and provides a partial answer for the LLM to continue writing. Regular expressions are used to extract point indexes and point skeletons;
- Point-Expanding Stage: Each point from the skeleton is expanded upon in parallel by the LLM. Specific point-expanding request templates are used to expand on each point, and the responses are concatenated to form the final answer. The point-expanding prompt template instructs the LLM to keep answers concise and typically doesn’t need demonstrations for reasonable results;
Why SoT Reduces Decoding Latency

API-based Models:
- Traditional method: Sends one API request per question.
- SoT method: Sends multiple parallel API requests to retrieve different parts of answers. If not hitting the rate limit, SoT offers faster responses.
Open-source Models with Batched Decoding:
- Traditional method: Processes one question at a time and decodes sequentially.
- SoT method: Handles multiple point-expanding requests in batches.
The authors explore peak memory overhead and latency increase in parallel processing:
LLM Generative Process Phases:
- Prefilling phase: Parses the prompt to create a cache for further use.
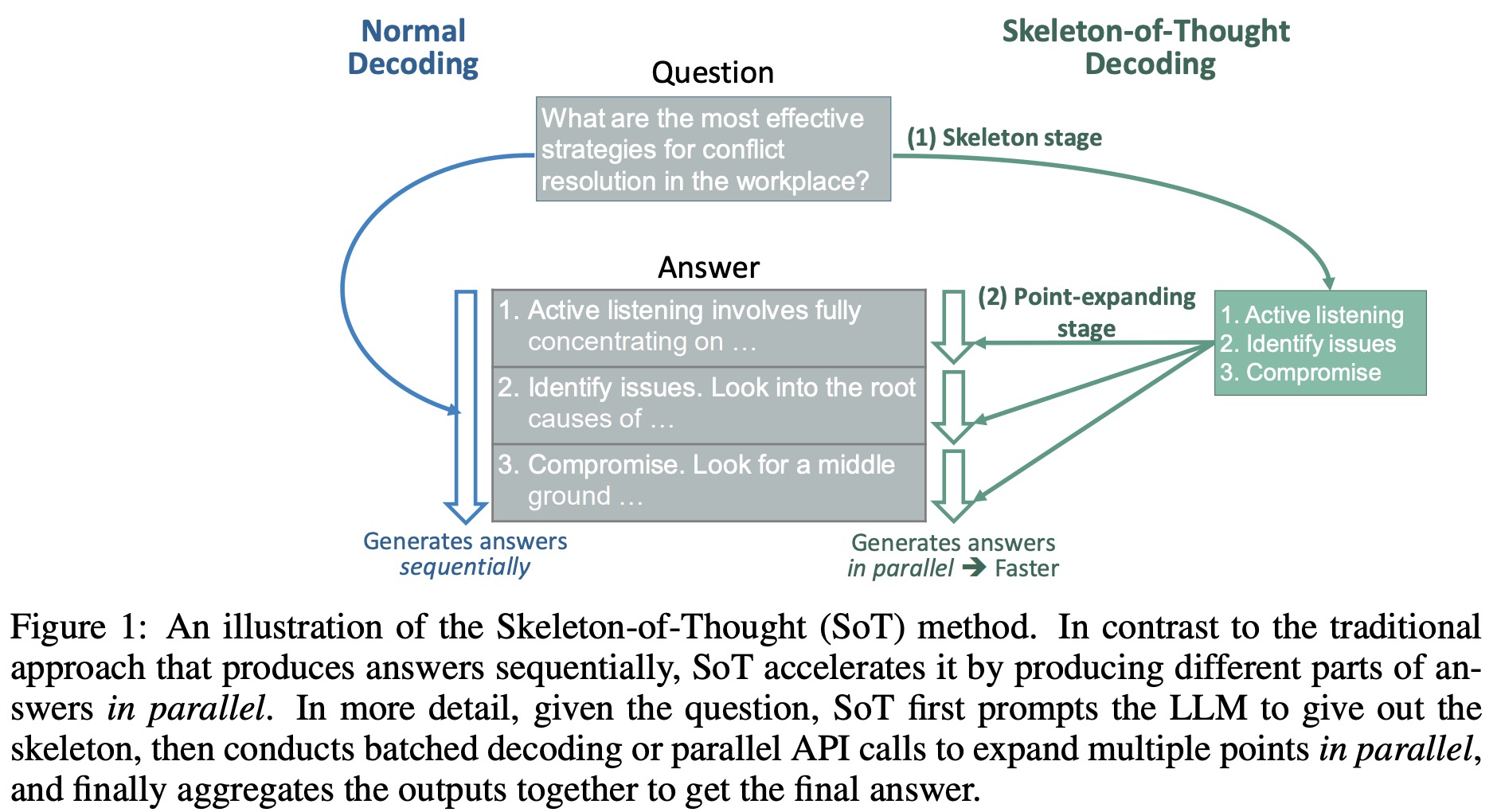
- Decoding phase: Generates tokens sequentially. This phase usually has the longest latency, especially for extended responses. For instance, when running the Vicuna-7B model on an NVIDIA A100-80G GPU, the actual computation performance is much lower in the decoding phase than in the prefilling phase. This inefficiency is due to the bottleneck created by loading all LLM weights onto the GPU for every single token’s decoding.
With SoT’s batched decoding, the latency of decoding one token for each sequence stays roughly the same as the batch size increases, resulting in almost linear GPU computation utilization. This means that by splitting an answer into multiple smaller segments and decoding them in a batch, a significant speed-up can be achieved, although it’s slightly less than the theoretical maximum.
The primary memory consumption comes from LLM weights. Memory overhead, due to increasing KV cache and activations, grows slowly as batch size increases. The experiments successfully ran SoT on a single GPU without needing additional memory optimization techniques.
Experiments
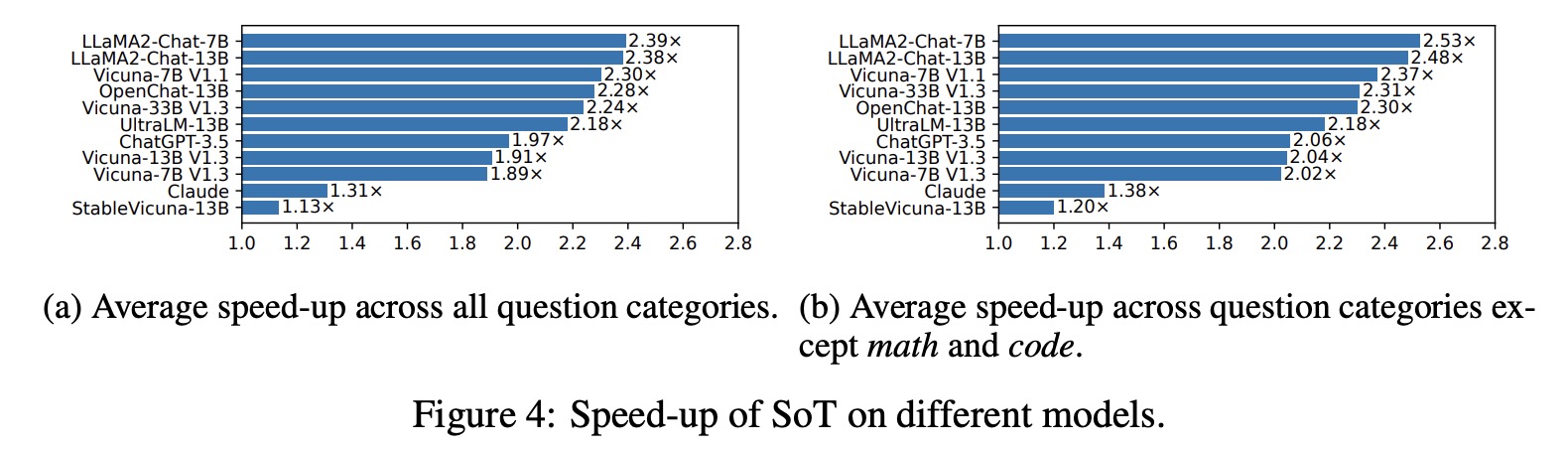
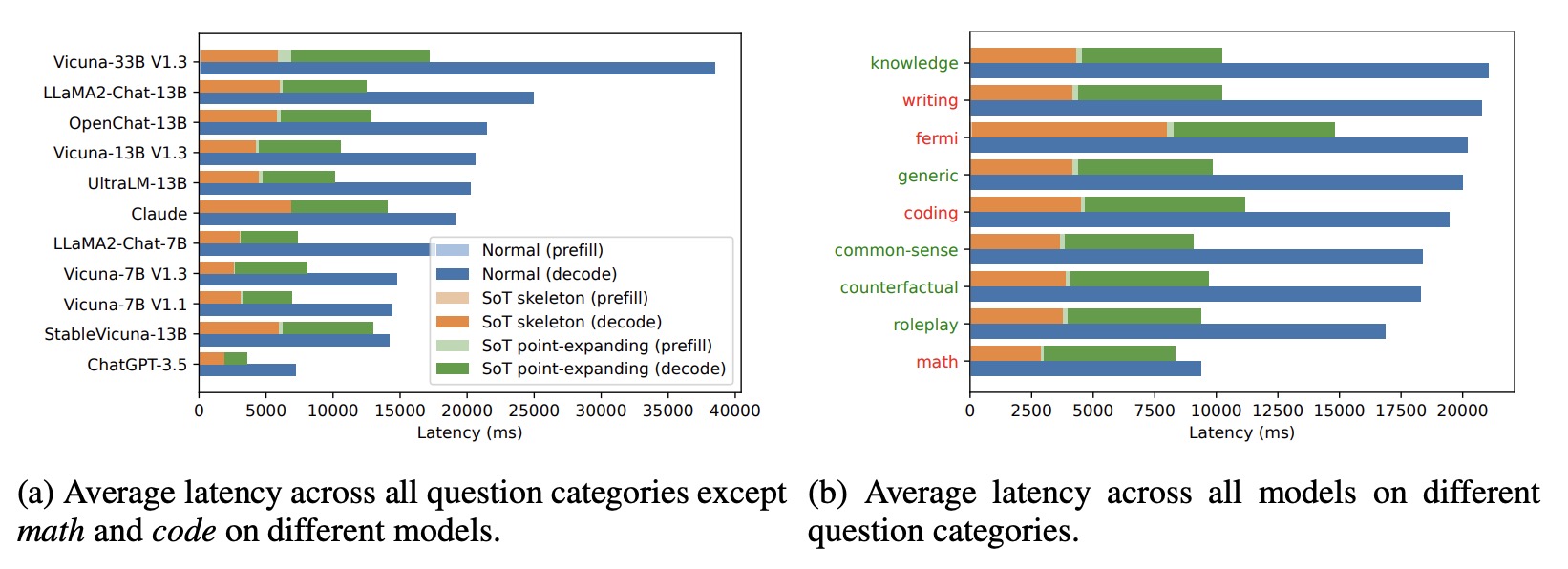
- Speed-up across Models: SoT achieves more than 2× speed-up on 6 out of 11 models, and more than 1.8× speed-up on others, except for StableVicuna-13B, where SoT achieves almost no speed-up.
- Point Number and Token Lengths: StableVicuna-13B is unique, producing the largest number of points and failing to adhere to short instruction in point-expanding requests, which affects the speed-up.
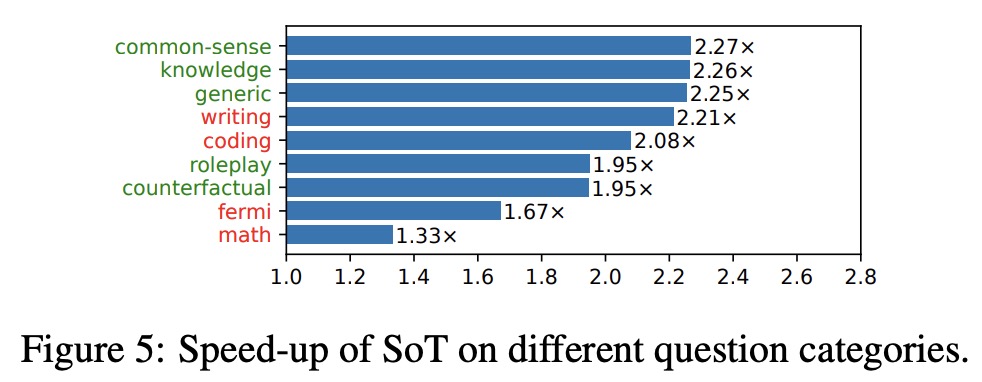
- End-to-End Latency Reduction across Categories: SoT obtains speed-up for all question categories. In categories where SoT provides high-quality answers (knowledge, common-sense, generic, roleplay, counterfactual), it speeds up the process by 1.95× to 2.27×. The decoding phase is the predominant factor in end-to-end latency.
- Absolute Latencies: Although SoT has higher prefilling latency in the skeleton stage and introduces additional latency, this has negligible impact on the overall speed-up.
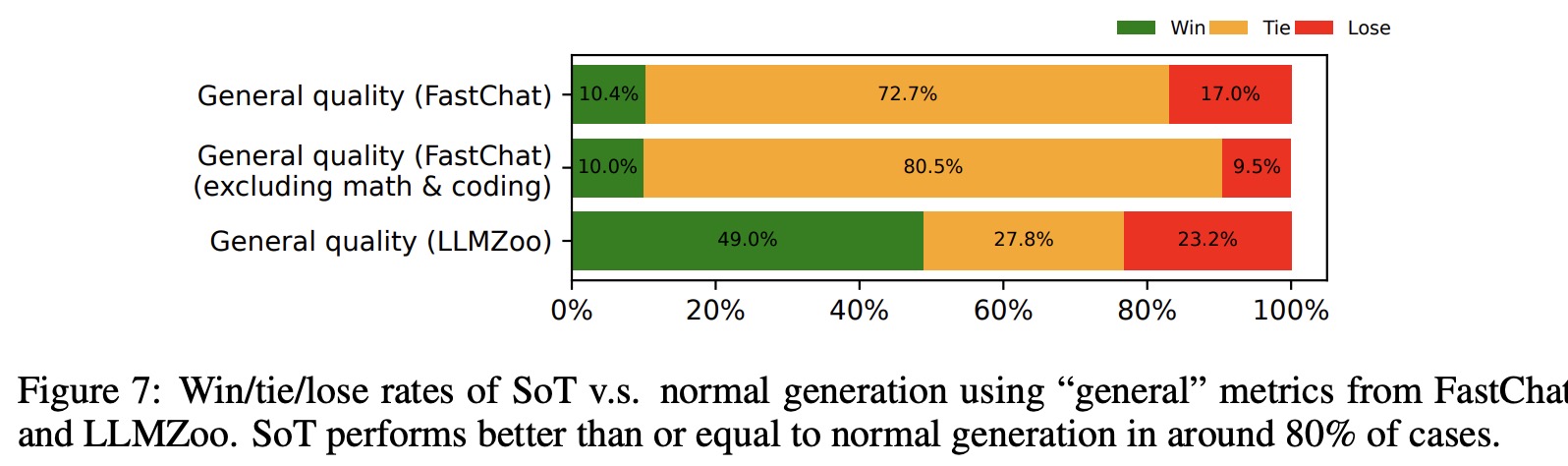
- Answer Quality Evaluation: Two LLM-based evaluation frameworks, FastChat and LLMZoo, are used to compare SoT and normal sequential generation. Metrics considered include general quality, coherence, diversity, immersion, integrity, and relevance. The evaluations are also extended to avoid bias. Across all models and questions, SoT is not worse than the baseline in more than 76% of the cases.
- There’s a discrepancy between FastChat and LLMZoo metrics (49.0% vs. 10.4%) when SoT is considered strictly better.
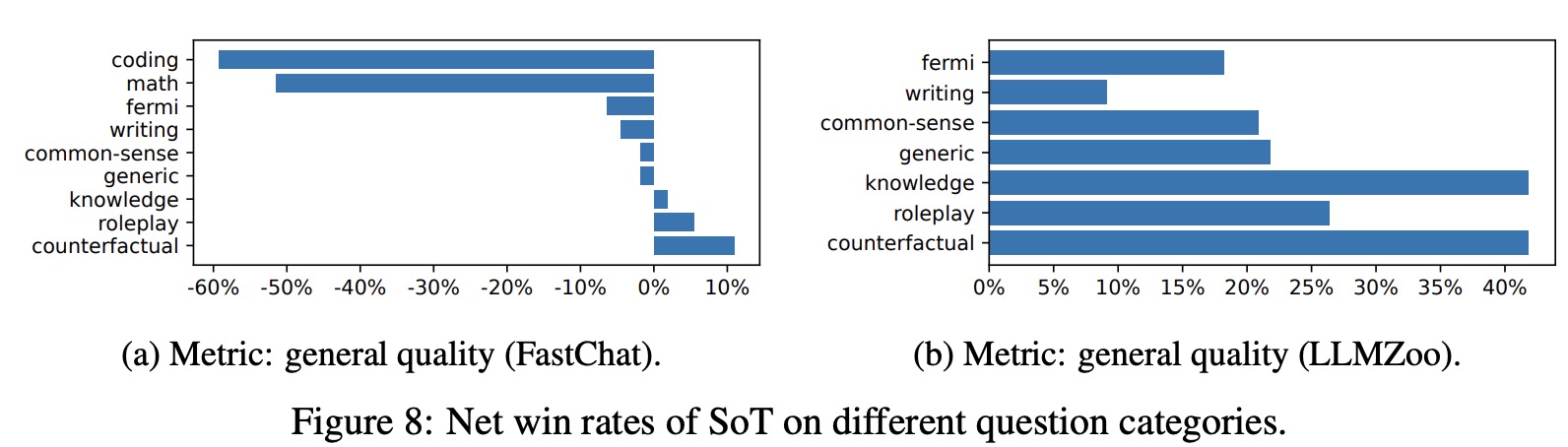
- SoT performs relatively well on generic, common-sense, knowledge, roleplay, and counterfactual categories but poorly on writing, Fermi, math, and coding.
Math, Fermi, coding and writing require step-by-step thinking, thus SoT with parallel processing performs worse on them. In coding questions sometimes SoT produces descriptions without the code, sometimes it generates the complete code several times for different points.
Limitations, Future Work, and Open Questions
Limitations:
- Evaluation of Answer Quality: The current evaluation is imperfect due to a limited prompt set, biases in current Language Model (LLM) judges, and inherent difficulties in evaluating LLM generations.
Future Work:
- Handling Different Questions: SoT struggles with math questions due to contradictions with CoT (Chain-of-Thought). SoT’s suitability for different question types requires designing a pipeline to trigger SoT selectively.
- Improving SoT Capability: By fine-tuning LLMs, SoT’s understanding of skeletons and instructions can be enhanced to generate more fluent and natural answers across various categories.
- Integration with Other Technologies: The potential of SoT can be further revealed by integrating it with existing throughput-oriented optimization techniques, inference engines, and serving systems.
Open Questions:
- Graph-of-Thoughts Concept: The current SoT solution forces fully parallelized decoding, ignoring possible sequential dependencies. A more sophisticated structure like a “Graph-of-Thoughts” could allow for dynamic adjustments, logical reasoning, and creative thinking.
- Data-Centric Engineering for Efficiency: While quality improvement has shifted towards data-centric engineering, efficiency has been less explored. SoT represents a beginning in this direction, and the text calls for more exploration of data-centric optimization for efficiency.