Paper Review: Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM
A novel approach adapts pre-trained LLMs for question answering and speech continuation by incorporating a pre-trained speech encoder. This enables the model to handle speech inputs and outputs. The model is trained end-to-end on spectrograms. The training objective jointly supervises speech recognition, text continuation, and speech synthesis using paired speech-text pairs. This allows for a “cross-modal” chain-of-thought in a single decoding pass. The method outperforms existing spoken language models in maintaining speaker characteristics and semantic coherence and shows improved retention of the original LLM’s knowledge in spoken QA tasks.
Approach
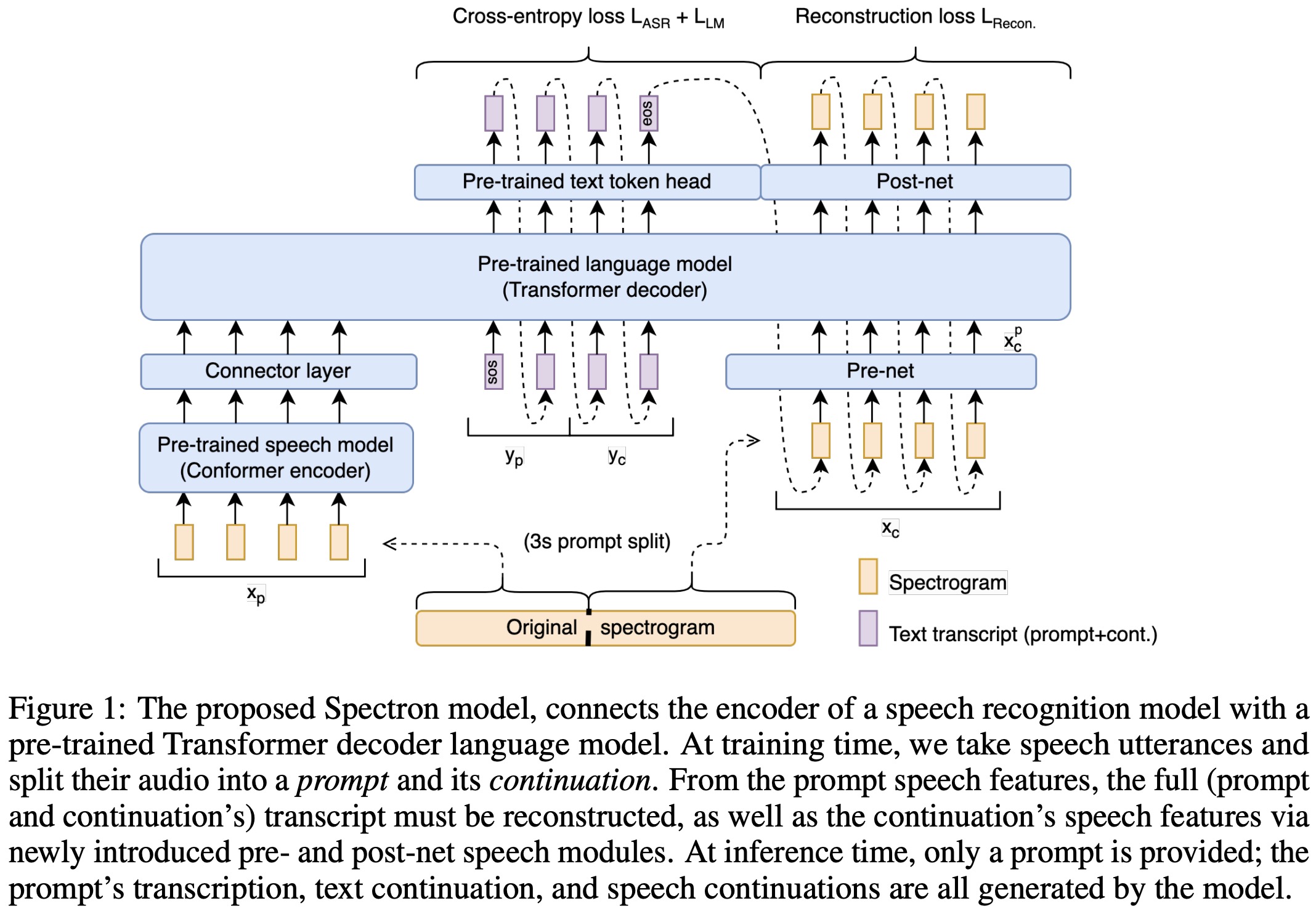
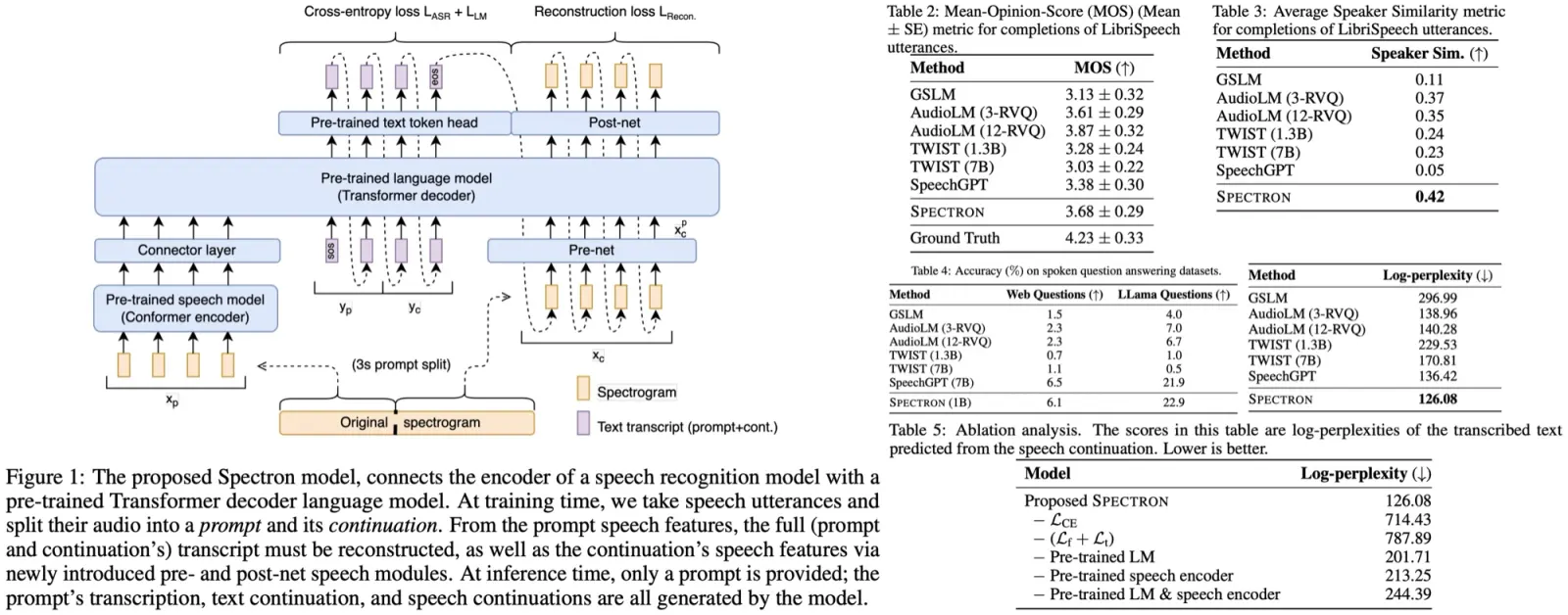
Architecture. The encoder processes a speech utterance into continuous linguistic features, which are then used as a prefix for the pre-trained language decoder. The model is optimized to minimize both a cross-entropy loss (for speech recognition and transcript continuation) and a novel reconstruction loss (for speech continuation). During inference, a spoken speech prompt is encoded and decoded to generate both text and speech continuations.
Input pre-processing. The model is trained with supervised speech utterances comprising paired speech spectrograms and transcripts. The spectrogram is split into a prompt segment for the speech encoder and a continuation segment for spectrogram reconstruction loss. SpecAugment is used for data augmentation. The transcript is divided similarly, with a mapping function aligning speech features with text tokens.
Speech encoder. A 600M-parameter Conformer encoder, pre-trained on 12M hours of data, processes speech spectrograms, generating representations with both linguistic and acoustic details. The process involves subsampling, followed by Conformer blocks containing feed-forward, self-attention, convolution, and additional feed-forward layers. The output is projected to the language model’s embedding dimension.
Language model. The model uses prefix decoder language models with either 350M or 1B parameters, trained like PaLM 2. The LM receives encoded features of the speech prompt as a prefix, with the speech encoder and LM decoder connected only at this point, without cross-attention. This late integration approach, similar to advancements in ASR, has shown to improve performance, indicating that additional layers are unnecessary due to the powerful text representations. During training, the decoder is teacher-forced to predict the text transcription, text continuation, and speech embeddings. The LM utilizes lightweight modules for converting between speech embeddings and spectrograms. This process benefits from the LM’s pre-training and intermediate text reasoning, enhancing speech synthesis quality.
Acoustic projection layers. A multi-layer perceptron adapts the LM decoder for speech features, compressing spectrogram continuations into the LM dimension to create a bottleneck, aiding decoding and preventing repetitive predictions. Another perceptron reconverts these projections to the spectrogram dimension.
Training objective. The training of the model uses two loss functions: cross-entropy loss (for speech recognition and transcript continuation) and regression loss (for speech continuation).
Inference. In the inference stage, the model encodes a speech prompt using a speech encoder and projects it to the language model’s dimension. The LM then autoregressively decodes this data to generate a text transcription and continuation, followed by decoding a spectrogram for speech continuation. This involves predicting and converting spectrogram features using past estimates and a post-net. Finally, a vocoder transforms the predicted spectrogram into a waveform, enabling the model to output both text and speech from the initial speech input.
Experiments
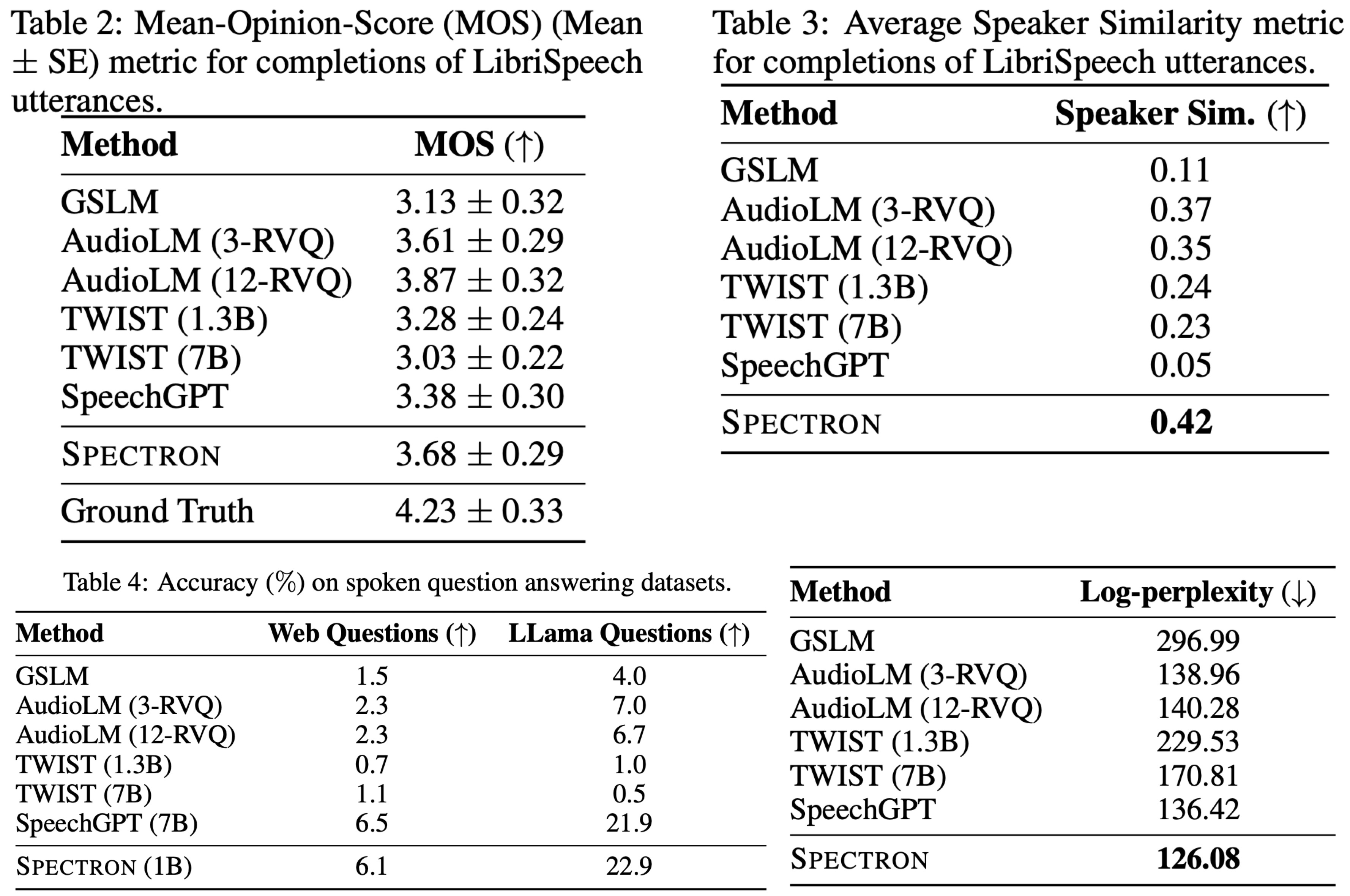
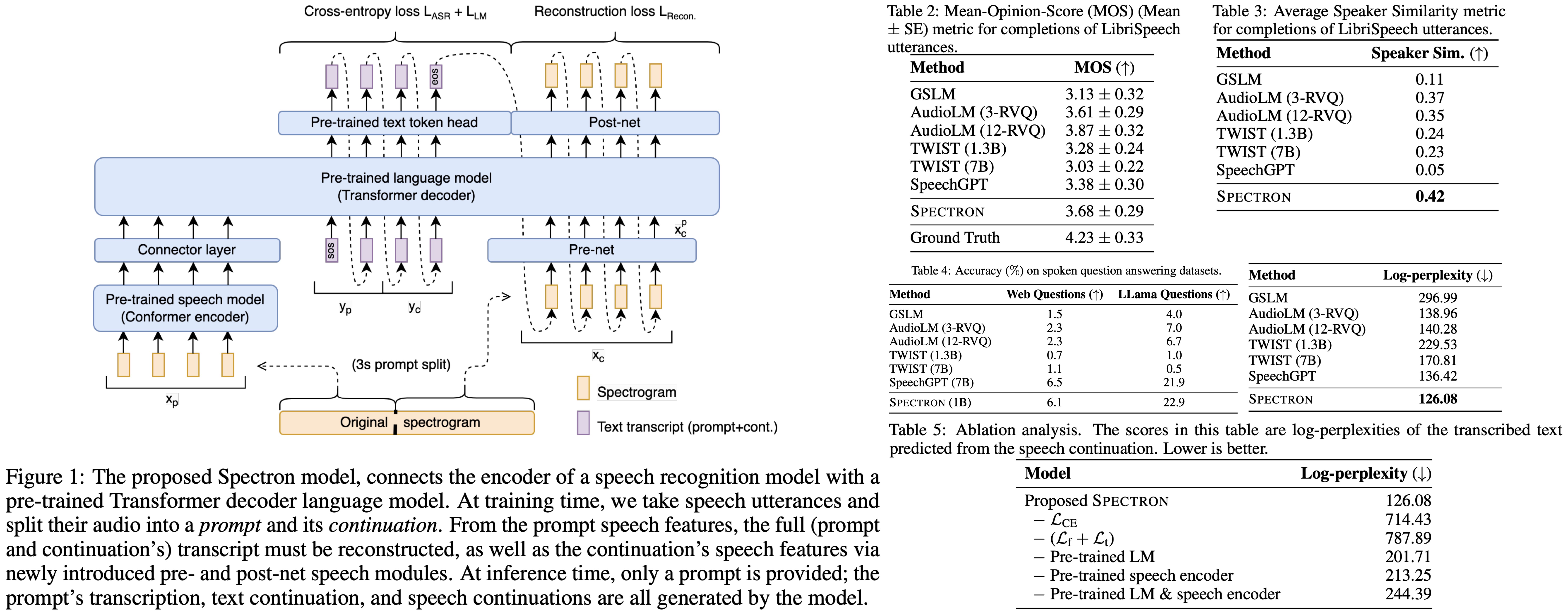
- Semantic Quality: The semantic quality of speech output was measured using log-perplexity. A Conformer ASR system transcribes speech continuations, and GPT-2 Medium calculates log-perplexity. Spectron outperforms previous approaches like GSLM and AudioLM.
- Acoustic Quality: Acoustic quality is assessed using Mean Opinion Score and average cosine distance between speaker embeddings. MOS rates the naturalness of speech utterances, while average speaker similarity measures the resemblance between the input prompt and its generated continuation. Spectron slightly outperforms GSLM in MOS and demonstrates significant improvement in average speaker similarity over GSLM and both AudioLM variants. However, it’s slightly inferior to AudioLM’s 12-RVQ variant in MOS.
- Question Answering: The model’s ability to continue spoken sentences or questions with appropriate answers is tested using synthesized questions from WebQuestions and a newly created LLama questions set. The performance is measured by the accuracy of answers transcribed by a Conformer ASR system. The proposed model shows competitive results against larger models like SpeechGPT on both LLama and Web Questions test sets despite having a smaller parameter size. Other models like TWIST and GSLM exhibit lower accuracies, suggesting a tendency towards generating completions rather than direct answers.

The ablations involved removing the following components from the model and measuring the log-perplexity on the LibriSpeech dataset: intermediate loss on text, spectrogram derivative loss, pre-training of the language model, and pre-training of the speech encoder. The results revealed that each component significantly contributes to the model’s performance. The removal of the ASR & LM cross-entropy loss and the spectrogram derivative loss had the most substantial impact, causing a substantial increase in log-perplexity. Additionally, the absence of pre-training for either the speech encoder or the language model also led to a notable decline in performance. The largest degradation in log-perplexity occurred when both the speech encoder and the pre-trained language model were removed, highlighting the importance of these components in the model’s effectiveness.
Limitations
- The main limitation is the high computational complexity in generating spectrogram frames, which limits the ability to produce long speech utterances due to the frame computation rate of 12.5 ms. A potential solution is to generate multiple spectrogram frames from each hidden representation.
- Another significant challenge is the non-parallelizability of text and spectrogram decoding processes, causing latency issues in streaming scenarios and delaying audio output.
- Additionally, there is a potential for biases in the pre-trained language model to be perpetuated in the new model.