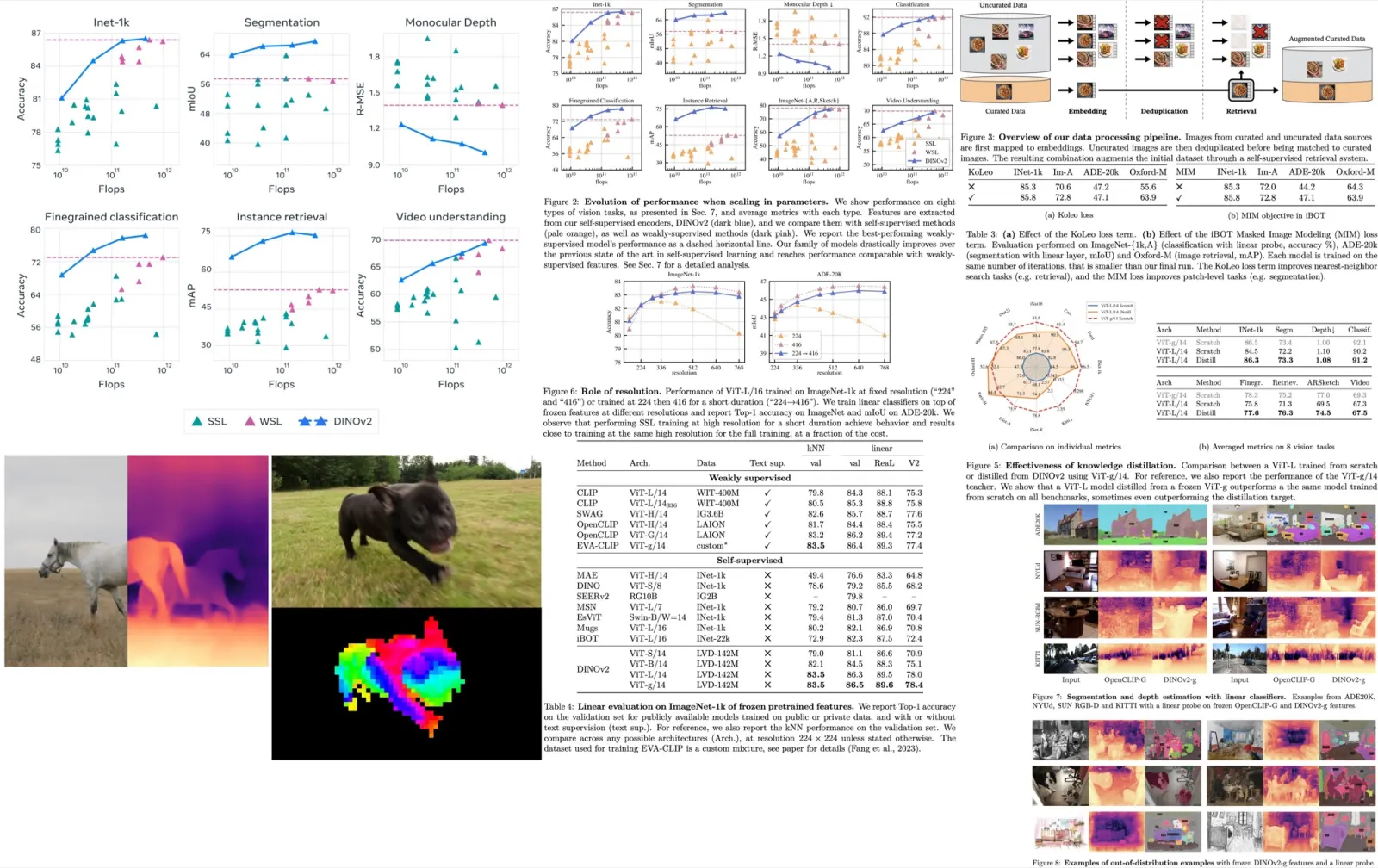
Paper Review: StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
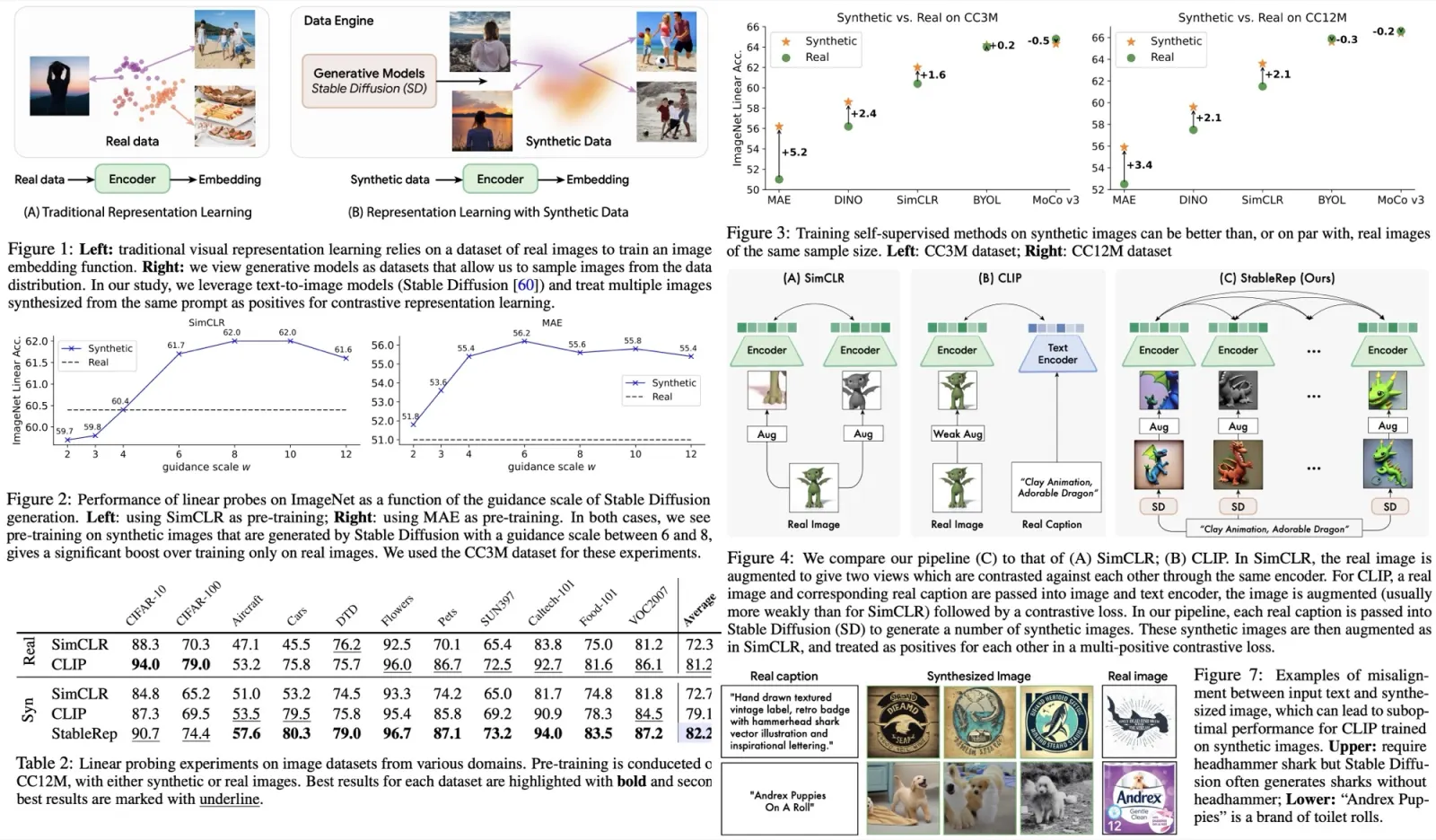
The authors explore the capability of text-to-image models, particularly the Stable Diffusion model, to learn visual representations using synthetic images. They found that, with the correct configuration, training self-supervised methods on synthetic images can rival or even surpass the performance of real images. Moreover, the researchers developed a multi-positive contrastive learning method named “StableRep” which treats multiple images derived from the same text prompt as positives for each other. The study concludes that StableRep, when trained solely on synthetic images, outperforms models like SimCLR and CLIP that use corresponding real images and the same text prompts on large scale datasets. Furthermore, when combined with language supervision, StableRep achieves better accuracy with 20M synthetic images compared to CLIP trained with 50M real images.
Standard Self-supervised Learning on Synthetic Images
In this paper, the authors use a generative model to produce a useful image encoder, F, which embeds an image (x) into a vector (e). Instead of utilizing a real image dataset, the authors focus on text-to-image generative models, G, that map a pair of text (t) and latent noise (z) to an image (x). Although there are many high-performing text-to-image models, the authors chose to work with the publicly available and widely used Stable Diffusion (v1-5) model for their research.
Self-supervised learning on synthetic images
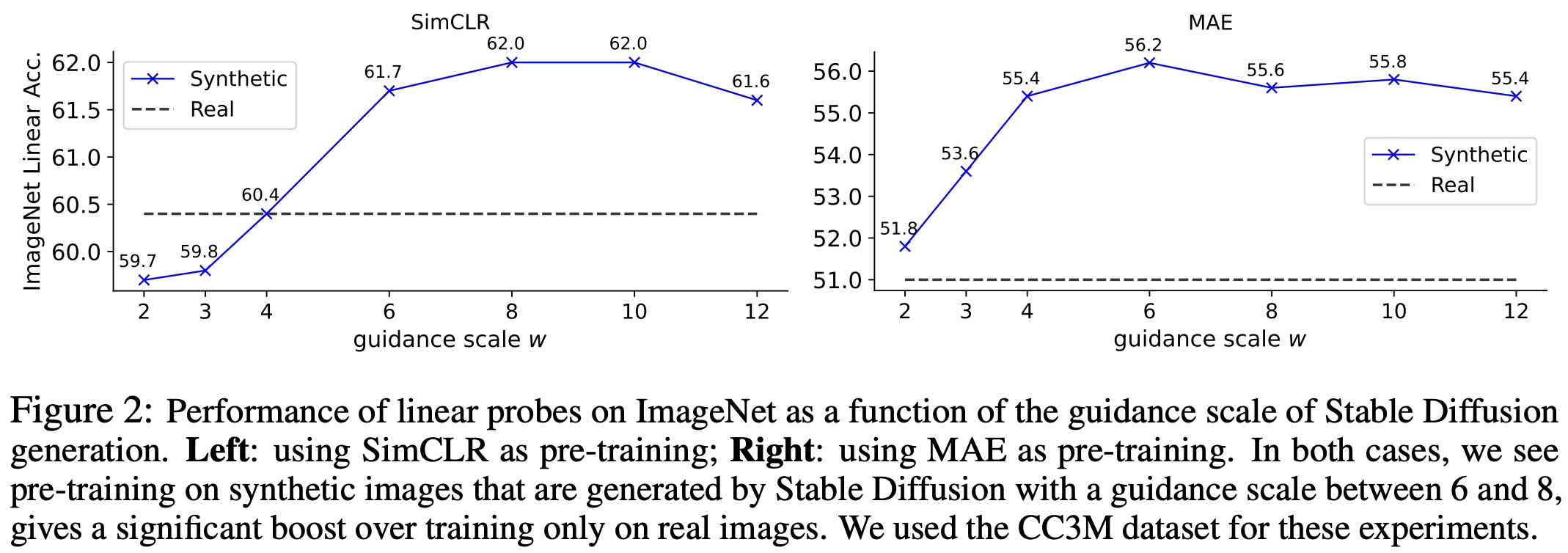
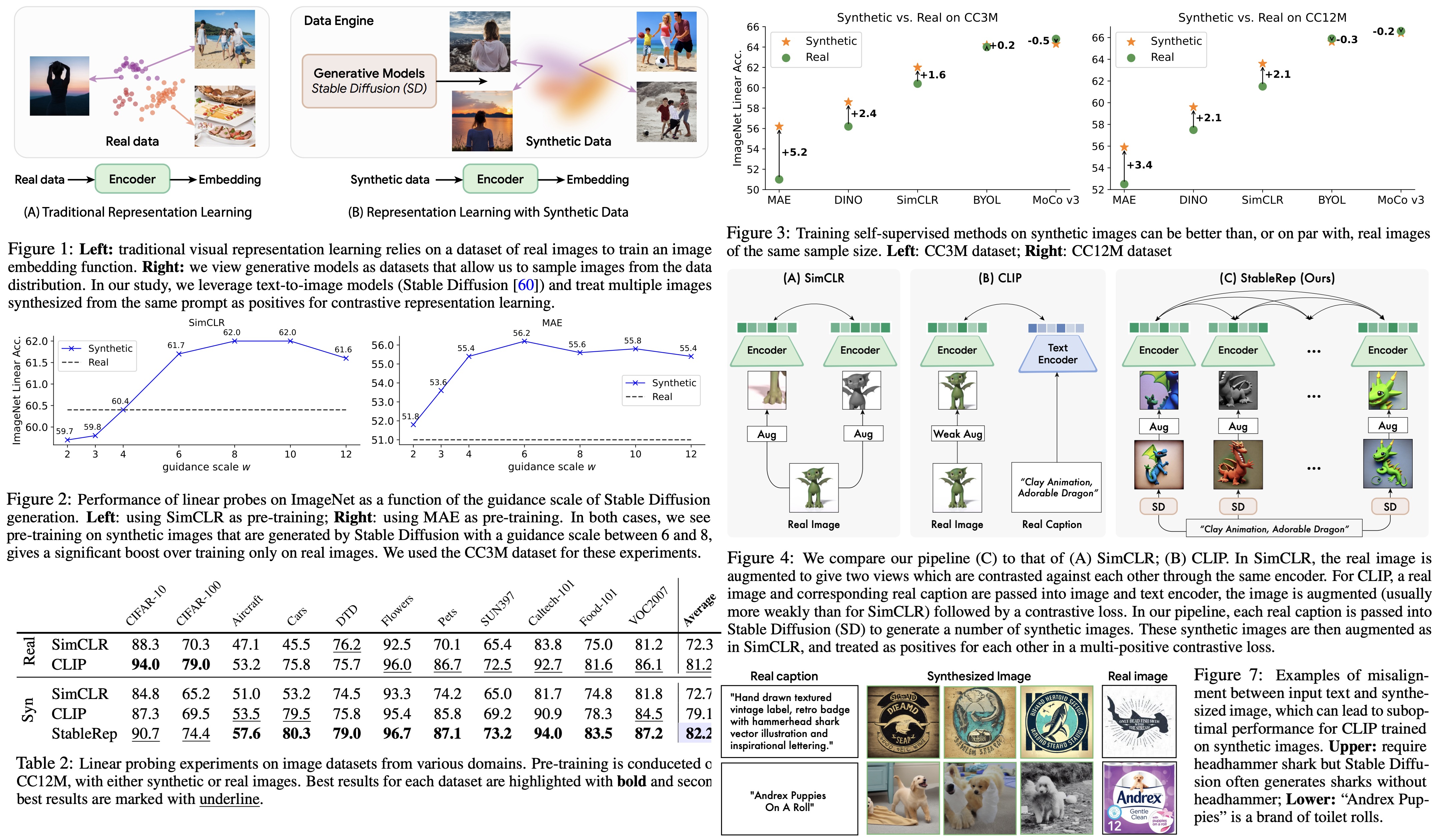
The authors utilize two notable self-supervised learning algorithms: contrastive learning, specifically SimCLR, and masked image modeling, specifically MAE, for their simplicity and performance. SimCLR and MAE models are trained on a synthetic image dataset, with the quality evaluated based on ImageNet. They optimize “guidance scale” (w) parameter which controls the trade-off between diversity and quality of synthetic images.
For SimCLR, the best results were achieved at w=8, with an accuracy of 62.0%, surpassing the 60.4% accuracy from training on real images. For MAE, optimal results occurred at w=6, achieving 4.2% better accuracy than its real image counterpart. Synthetic images also performed better in fine-tuning pre-trained MAE models.
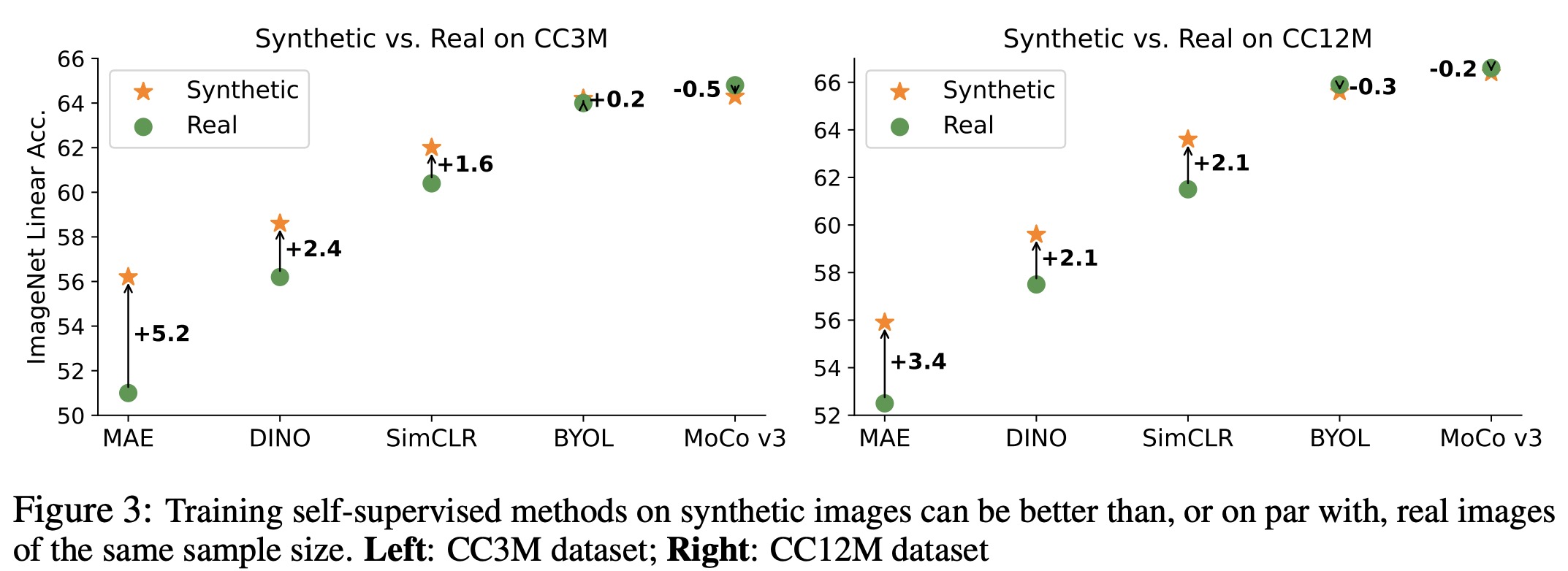
The authors also tested the application of synthetic images in other self-supervised learning methods like BYOL, MoCo-v3, and DINO. They generally found that synthetic images performed at least on par with or even better than real images, with the exception of MoCo-v3, which may have been due to not fine-tuning the guidance scale.
Multi-Positive Contrastive Learning with Synthetic Images
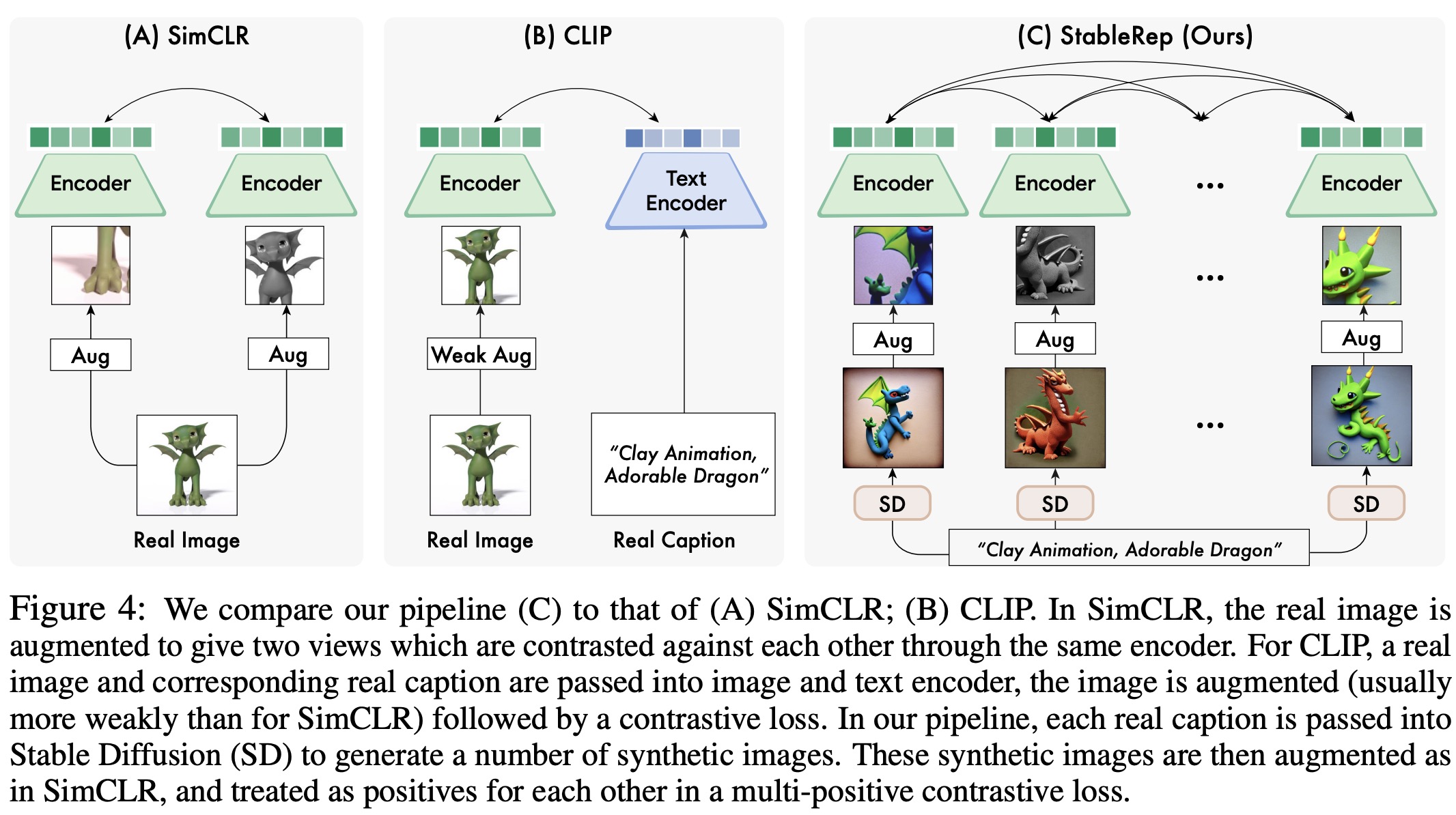
Given an image caption, the models can generate multiple diverse images by using different latent noise inputs, making these images good positive samples for each other. The authors introduce a multi-positive contrastive loss function, which is presented as a matching problem. They calculate a contrastive distribution that shows the likelihood of an anchor sample matching each candidate, and a ground-truth distribution, which is based on actual matches. The loss is the cross-entropy between these two distributions.
A batched multi-positive contrastive learning algorithm is provided in pseudocode. Each batch includes multiple images for each caption, and they still use data augmentation to prevent overfitting during training. StableRep is noted to be a generic version of the SimCLR algorithm, and only uses a single crop from each image, differentiating it from traditional methods.
# Multi-Pos CL: PyTorch-like Pseudocode
# f: encoder: backbone + proj mlp
# tau: temperature
# minibatch x: [n, m, 3, h, w]
# n captions, m images per caption
for x in loader:
x = augment(x)
x = cat(unbind(x, dim=1)) # [n*m, 3, h, w]
h = f(x)
# compute ground-truth distribution p
label = range(n * m) %
p = (label.view(-1, 1) == label.view(1, -1))
p.fill_diagonal(0) # self masking
p /= p.sum(1)
# compute contrastive distribution q
logits = h @ h.T / tau
logits.fill_diagonal(-1e9) # self masking
q = softmax(logits, dim=1)
H(p, q).backward()
def H(p, q): # cross-entropy
return - (p * log(q)).sum(1).mean()
Experiments
The authors use ViT models as a backbone, with a 3-layer MLP projection head on the top of the CLS token. In most cases they use the batch size of 8192.

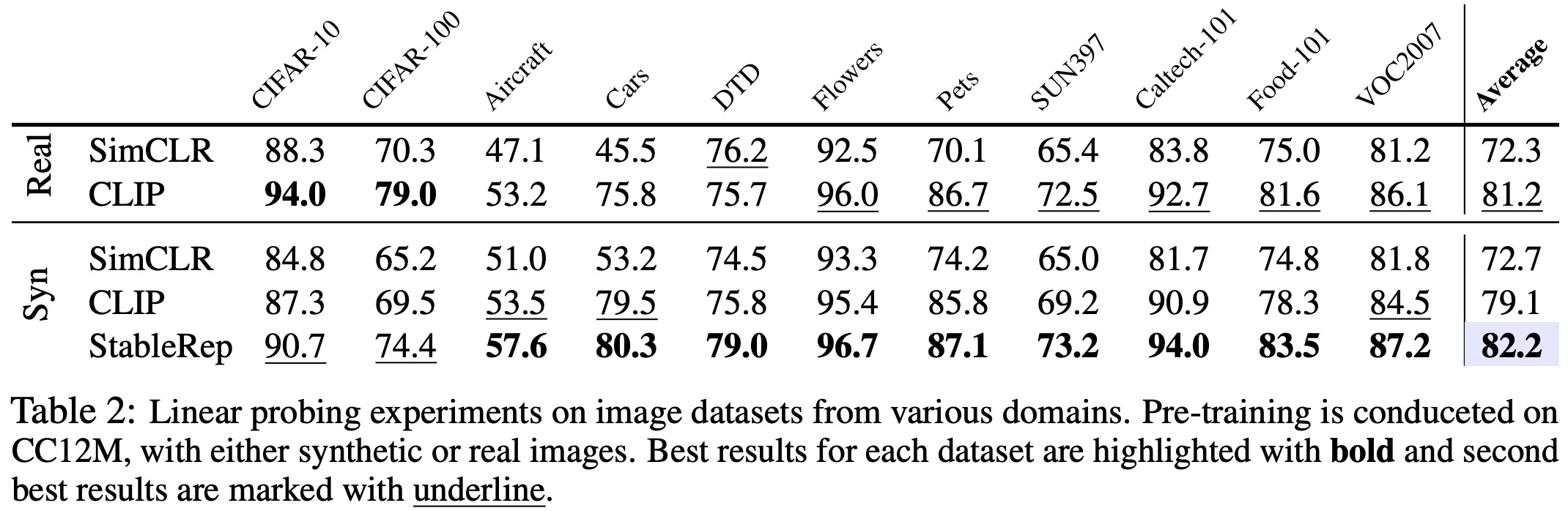
- Results showed that training SimCLR on synthetic images improved the top-1 accuracy on CC12M by 2.2% and on RedCaps by 1.0% compared to real images. However, CLIP’s accuracy dropped by 2.6% on CC12M and 2.7% on RedCaps when trained on synthetic images. StableRep outperformed CLIP trained on real images, improving by 2.5% and 1.8% for CC12M and RedCaps respectively.
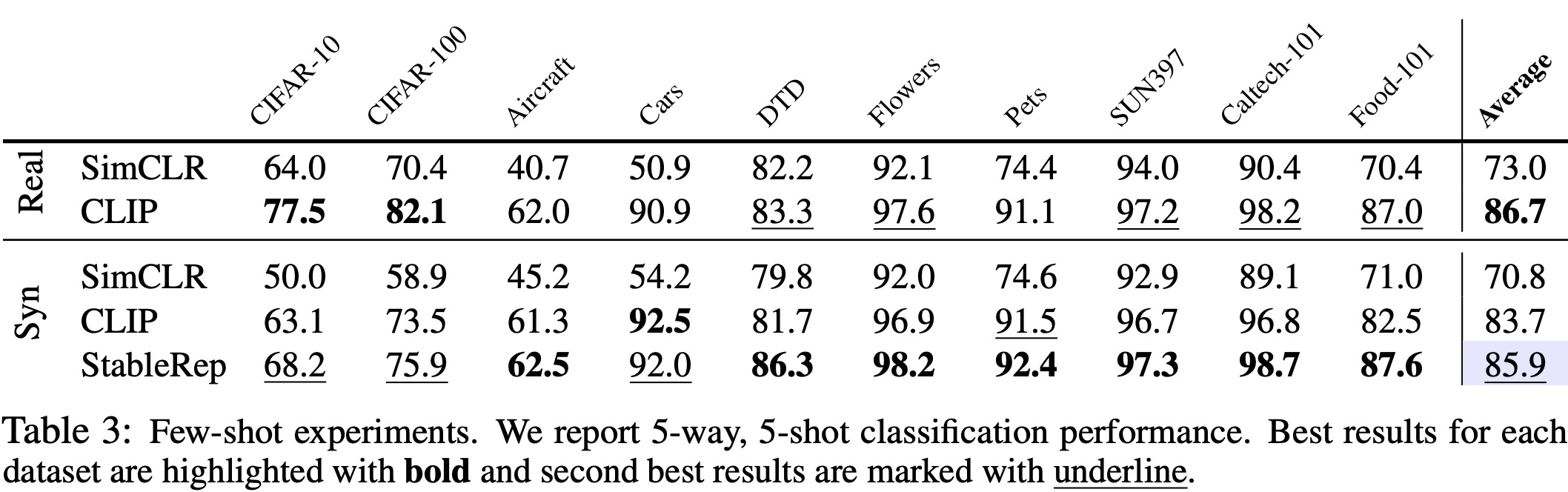
- Additional tests were conducted across different image domains, with StableRep achieving the highest accuracy on 9 out of the 11 datasets. StableRep also excelled in few-shot image classification tests, leading in 7 out of the 10 datasets, but it lagged behind CLIP on CIFAR-10 and CIFAR-100
Adding Language Supervision
The researchers explored training CLIP using synthetic images generated from each guidance scale. The study found that CLIP prefers a lower guidance scale, and with an optimal scale of 2, achieved 34.9% zero-shot accuracy, which is 5.4% lower than training on real images. The difference could be attributed to a misalignment between the generated images and the input text.
They also introduced language supervision to StableRep, creating StableRep+. This resulted in an improvement from 72.8% to 74.4% on CC12M and from 73.7% to 75.4% on RedCaps for ImageNet linear probing.
The researchers scaled StableRep+ to a randomly selected 50M subset of LAION-400M, and compared the performance of CLIP with real images and StableRep+ with synthetic images. StableRep+ consistently achieved better accuracy than CLIP. Notably, StableRep+ with 10M captions outperformed CLIP with 50M captions, providing a 5x caption efficiency (2.5x image efficiency).

Conclusion, Limitations and Broader Impact
The study demonstrated that synthetic data generated from advanced text-to-image models can effectively train robust visual representations. By using the Stable Diffusion model and a multi-positive contrastive loss, their method outperformed training with real data alone. It performed well across various tasks, including linear probing and few-shot classification. Notably, they found that even basic self-supervised methods trained on synthetic data can compete with or outdo those trained on real data.
However, the researchers also acknowledge limitations. The reasons behind the effectiveness of training self-supervised methods on synthetic images compared to real ones aren’t fully understood. Also, the current image generation process is slow, limiting the use of non-repetitive images synthesized online for StableRep models. Furthermore, issues such as semantic mismatch between input prompts and generated images, potential biases, and image attribution problems with synthetic data are yet to be addressed.
The research has broader implications, potentially reducing reliance on collecting vast amounts of real images for representation learning, which can be cost-effective and minimize biases from human curation. However, potential social biases and errors may still exist in the text-to-image generative models trained on large-scale, uncurated web data. The selection of prompts can also influence the images generated, introducing another potential source of bias.
paperreview deeplearning stablediffusion nlp cv