Paper Review: StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation

StreamDiffusion is a new real-time diffusion pipeline for interactive image generation, improving performance in live streaming and similar scenarios. It replaces traditional sequential denoising with a faster batching process and introduces a parallel input-output queue for smoother operation. The pipeline also features a novel Residual Classifier-Free Guidance method, reducing denoising steps and increasing speed. Additionally, it incorporates a Stochastic Similarity Filter for better power efficiency. Overall, StreamDiffusion achieves up to 1.5x faster processing and up to 2.05x speed increase with RCFG, reaching 91.07fps on an RTX4090 GPU. It also significantly lowers energy consumption, making it a more efficient solution for real-time image generation.
StreamDiffusion Pipeline
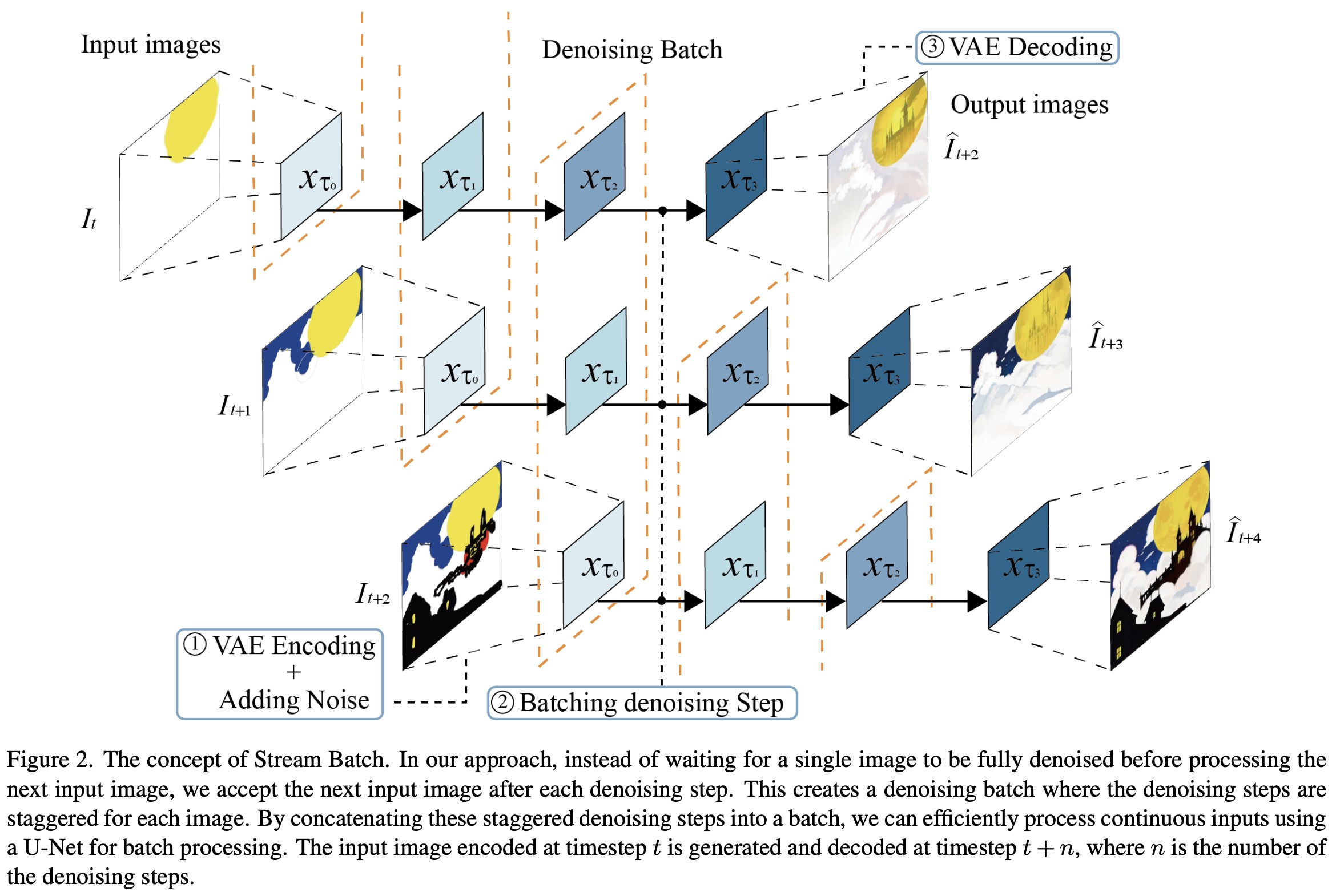
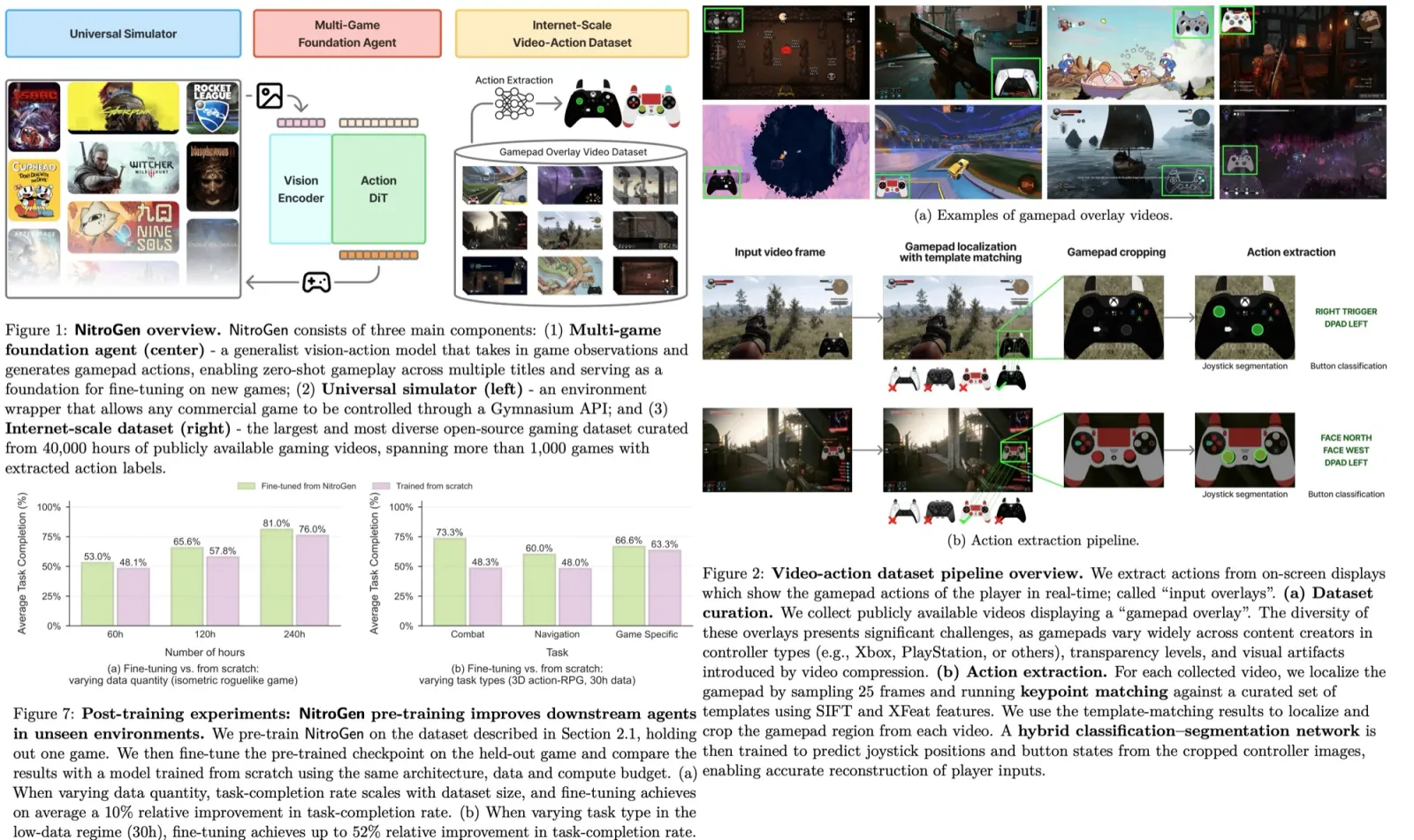
Batching the denoise step
Traditional diffusion models rely on sequential denoising steps, which increase processing time linearly with each additional step, especially in the U-Net framework. However, higher fidelity images require more denoising steps, leading to higher latency.
Stream Batch addresses this by restructuring the sequential denoising into a batched process. Each batch corresponds to a set number of denoising steps, allowing each element in the batch to progress one step in the denoising sequence with a single U-Net pass. This method transforms input images at a given timestep to their image-to-image results at a future timestep in a more streamlined manner.
This approach significantly reduces the need for multiple U-Net inferences and avoids the linear escalation of processing time with the number of steps. The key trade-off shifts from processing time versus generation quality to VRAM capacity versus generation quality. With sufficient VRAM, high-quality images can be produced in a single U-Net processing cycle, effectively mitigating the latency issues caused by increased denoising steps.
Residual Classifier-Free Guidance
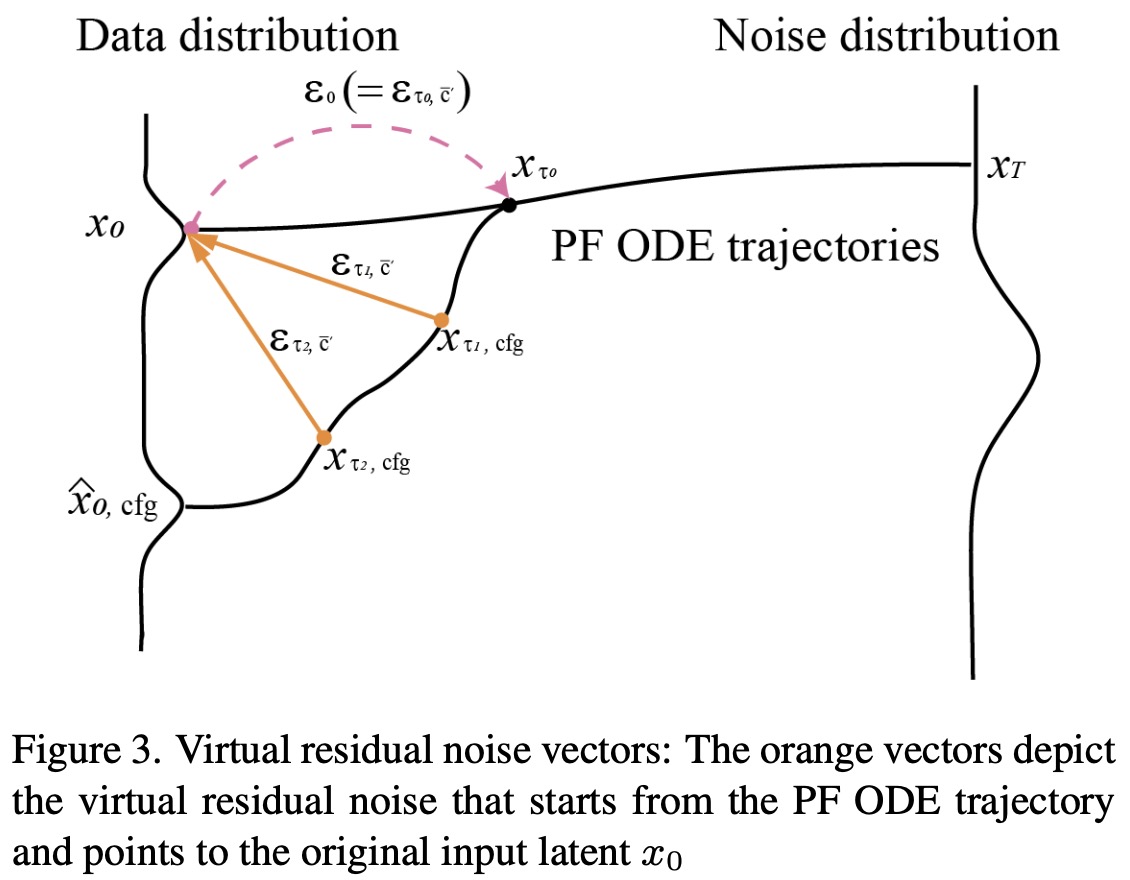
Traditional CFG improves image generation by adjusting the influence of conditioning terms, but it requires computationally expensive multiple passes through a U-Net model for each inference. RCFG addresses this issue by introducing a concept of virtual residual noise, which is used to predict the original input image’s latent representation from a given point in the generation process. This method allows for effective image generation that diverges from the original image based on the guidance scale, without the need for additional U-Net computations. This process is termed as Self-Negative RCFG.
Additionally, RCFG can also be used to diverge from any negative condition by calculating the negative conditioning residual noise just once at the first denoising step and using this throughout the process (Onetime-Negative RCFG). This method significantly reduces the computational burden, requiring only n or n+1 U-Net computations for Self-Negative and Onetime-Negative RCFG respectively, compared to the 2n computations required by conventional CFG. This makes RCFG more efficient while maintaining or enhancing the quality of the generated images.
Input-Output Queue
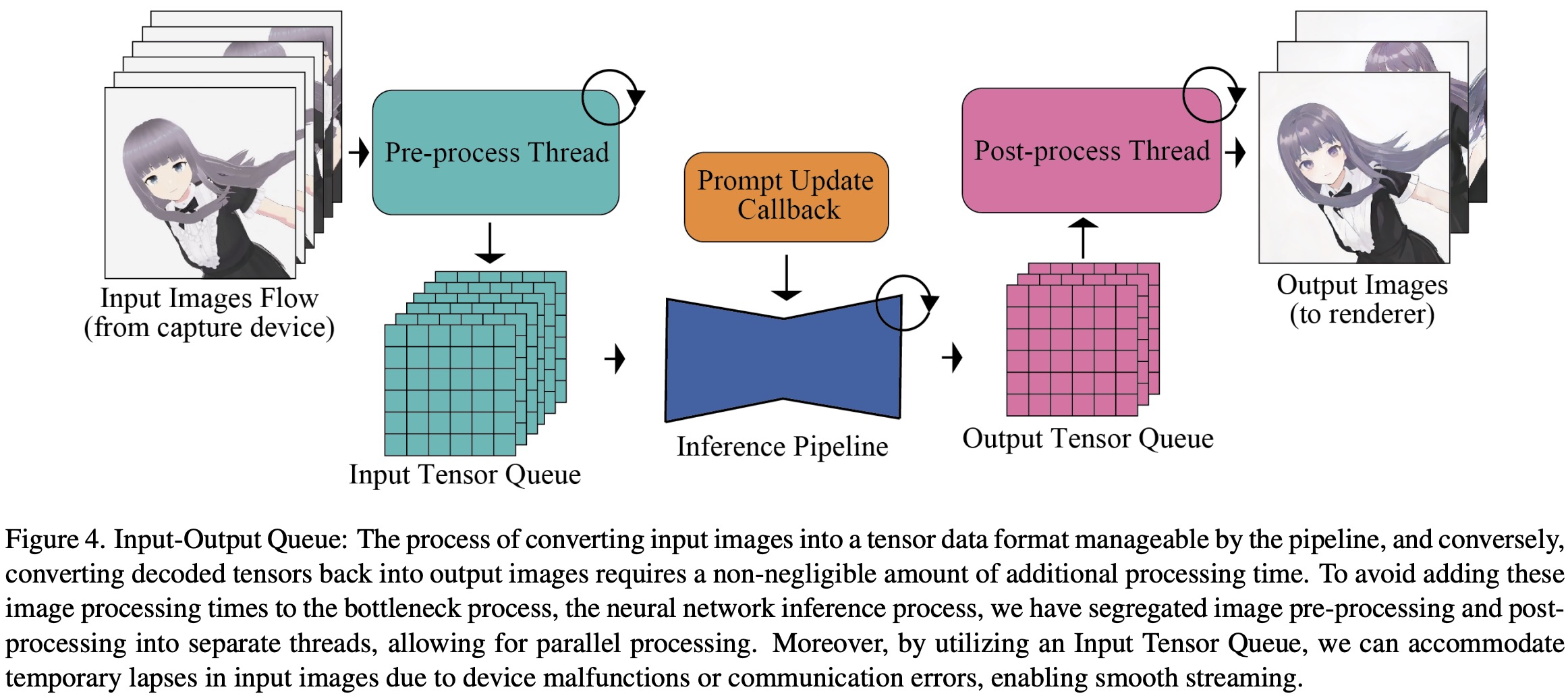
High-speed image generation systems are optimized by shifting tasks that don’t require neural network processing, such as pre-processing and post-processing of images, to be processed in parallel outside the main pipeline. Input images undergo operations like resizing, tensor conversion, and normalization. To align the different processing speeds of human inputs and model throughput, the authors implement an input-output queuing system. These queues process input tensors for Diffusion Models, which then pass through the VAE Encoder for image generation. Output tensors from the VAE Decoder enter an output queue for post-processing and format conversion, before being sent to the rendering client. This strategy enhances system efficiency and speeds up image generation.
Stochastic Similarity Filter
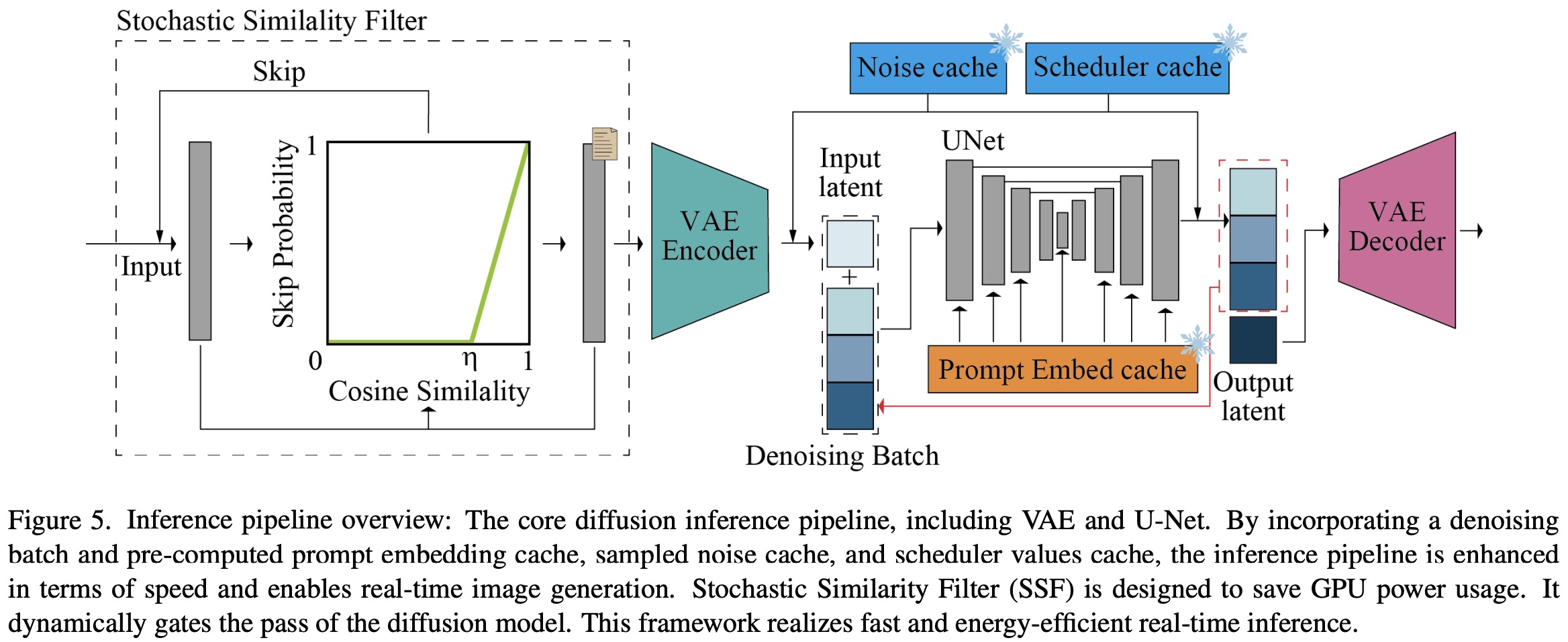
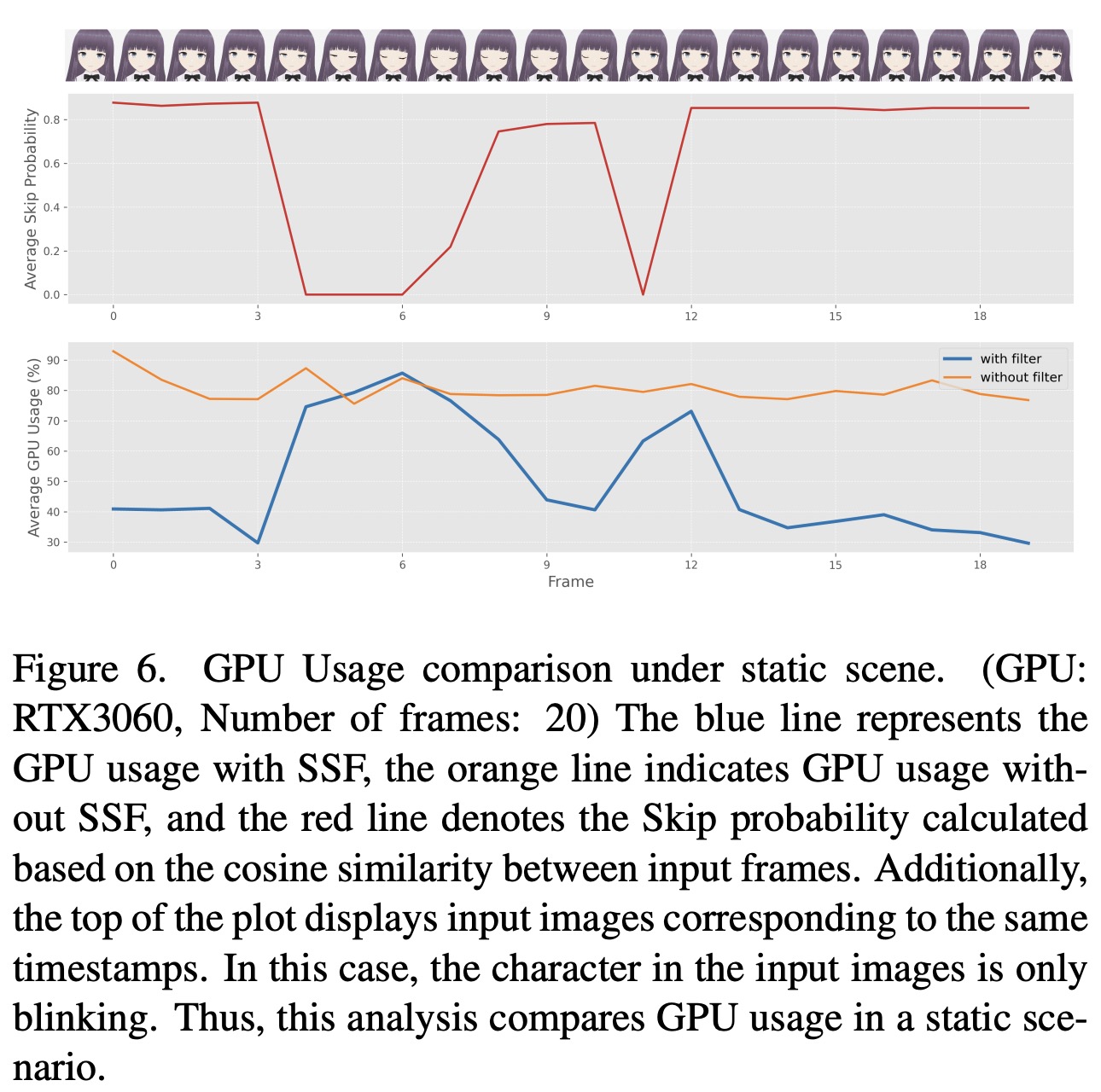
To address the issue of generating redundant images and wasting GPU resources in scenarios with minimal changes or static environments, a strategy called Stochastic Similarity Filter is proposed. SSF works by calculating the cosine similarity between the current input image and a past reference image. Based on this similarity, it computes the probability of skipping the VAE and U-Net processes to reduce unnecessary computations. When the similarity is high, indicating little change between frames, the pipeline is more likely to skip processing, conserving computational resources. This mechanism allows for efficient operation in dynamic scenes, where processing is fully engaged, and in static scenes, where processing rate decreases. Unlike a hard threshold method that might lead to choppy video generation, the probabilistic approach of SSF ensures smoother video generation by adapting to varying scene dynamics without compromising the viewing experience.
Pre-computation
Optimizations to the U-Net architecture in image generation systems, especially for interactive or streaming applications, include pre-computing and caching the prompt embedding, which remains constant across frames. This cached data is used to compute Key and Value pairs within U-Net, which are stored and only updated when the input prompt changes. Additionally, Gaussian noise for each denoising step is pre-sampled and cached, ensuring consistent noise across timesteps and improving efficiency in image-to-image tasks. Noise strength coefficients for each denoising step are also precomputed to reduce overhead in high frame rate scenarios. For Latent Consistency Models, the necessary functions are pre-computed for all denoising steps or set to constant values, avoiding repetitive computations during inference.
Model Acceleration and Tiny AutoEncoder
The U-Net and VAE engines are constructed using TensorRT. To further optimize speed, the authors use static batch sizes and fixed input dimensions, which optimizes the computational graph and memory allocation for specific input sizes, resulting in faster processing times. However, this approach limits flexibility, as processing images of different shapes or using different batch sizes would require building a new engine tailored to those specific dimensions.
Additionally, the system uses a tiny AutoEncoder, a streamlined and efficient alternative to the traditional Stable Diffusion AutoEncoder. TAESD is particularly effective at rapidly converting latents into full-size images and accomplishing decoding processes with significantly reduced computational demands.
Experiments
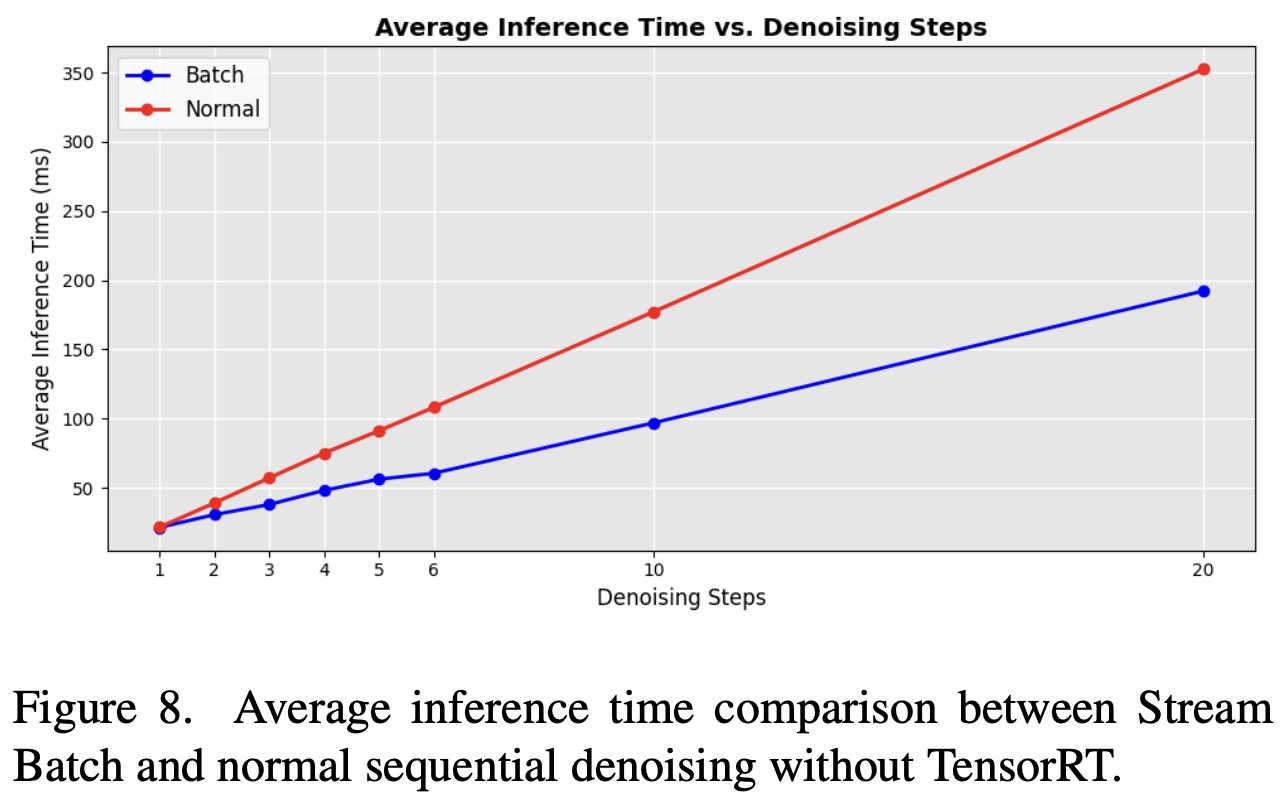
Denoising Batch vs. Sequential U-Net Loop: Implementing a denoising batch strategy significantly improves processing time, achieving a 50% reduction compared to the conventional sequential U-Net loop. This improvement is observed even when using TensorRT indicating that the Stream Batch approach enhances the efficiency of the original sequential diffusion pipeline across various denoising steps.

Comparison with AutoPipelineForImage2Image: The proposed pipeline, compared to Huggingface’s AutoPipelineForImage2Image, demonstrates a substantial speed increase. With TensorRT, StreamDiffusion achieves a speed-up of at least 13 times with 10 denoising steps, and up to 59.6 times with a single denoising step. Without TensorRT, the speed-up is still notable, reaching 29.7 times faster with one step denoising, and 8.3 times with 10 steps.
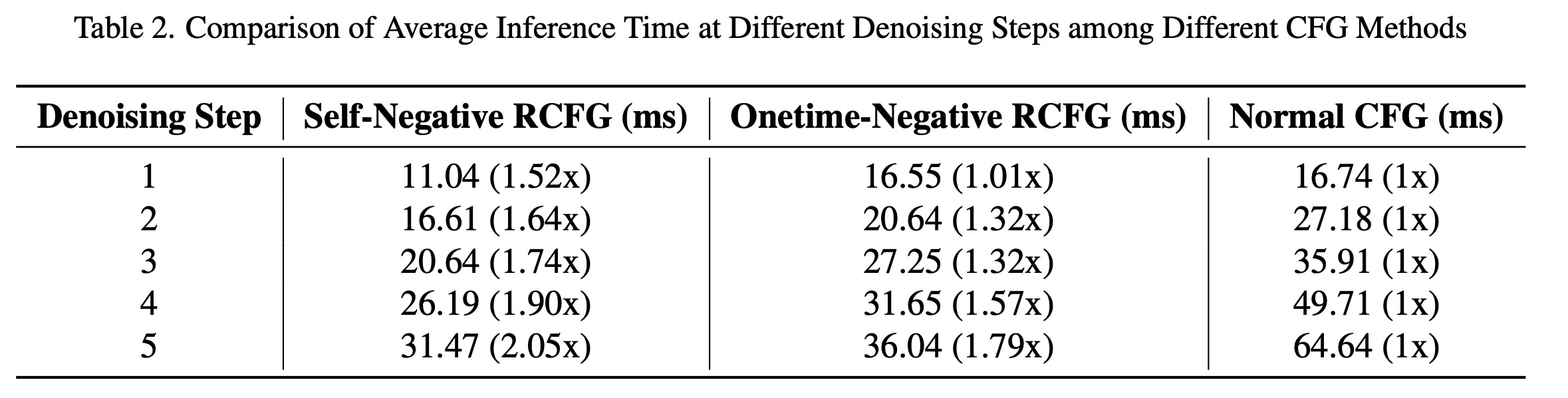
StreamDiffusion Pipelines with RCFG vs. Conventional CFG: Comparing StreamDiffusion with RCFG to conventional CFG, the additional computations for Self-Negative RCFG are minimal, resulting in little change in inference time. Onetime-Negative RCFG requires extra U-Net computations only in the first step, leading to similar inference times to conventional CFG for a single step but showing more advantage as the number of denoising steps increases. At five denoising steps, Self-Negative RCFG shows a 2.05x speed improvement and Onetime-Negative RCFG 1.79x compared to conventional CFG.
Ablation study
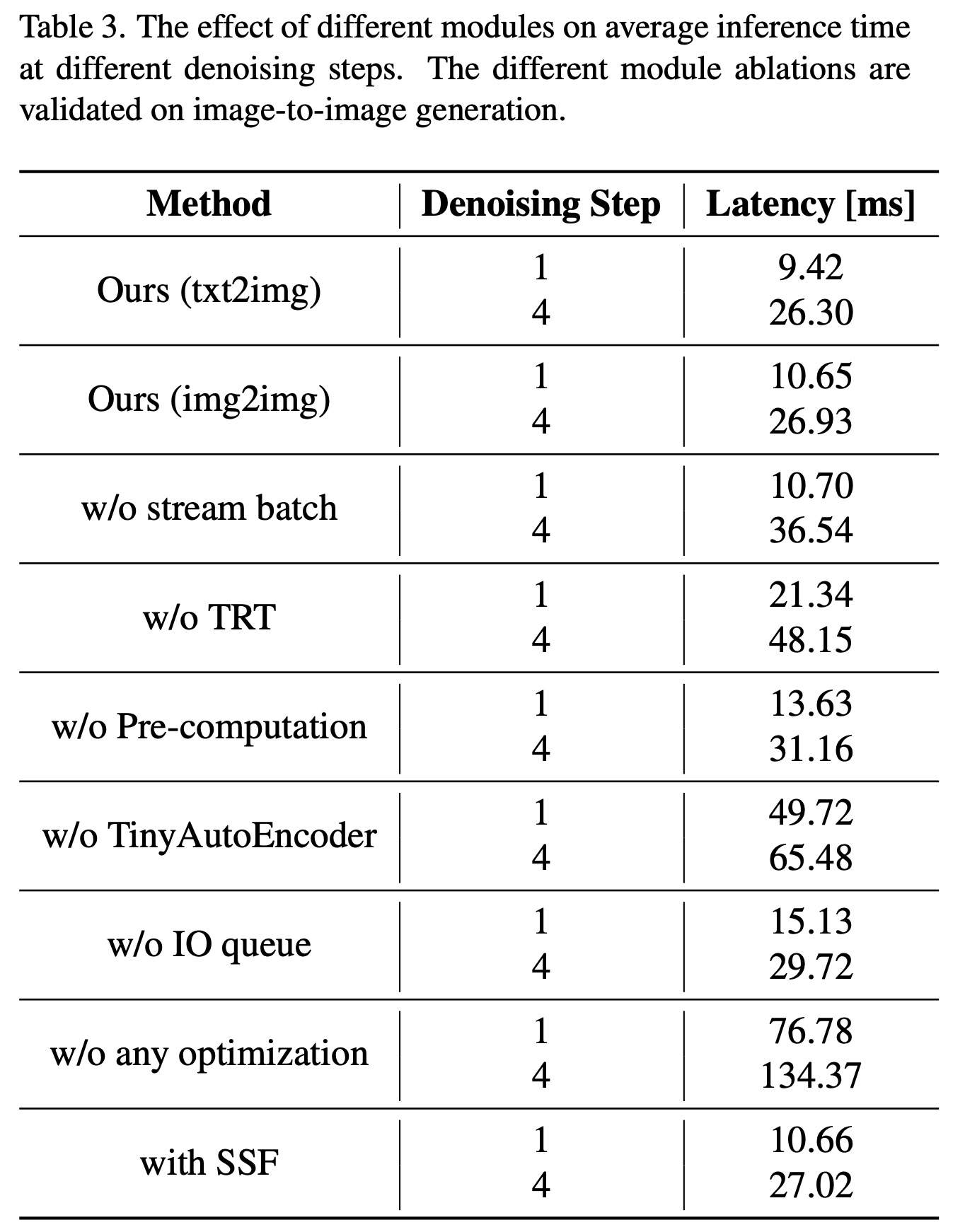
Qualitative Results

The StreamDiffusion pipeline demonstrates its effectiveness in real-time image-to-image transformation, suitable for various applications like real-time game graphics, camera filters, face conversion, and AI-assisted drawing. It achieves low throughput from real-time inputs like cameras or screen captures while maintaining high-quality image generation that aligns with specified prompts.

Using RCFG, the pipeline shows improved alignment of generated images to prompt conditions compared to CFG. RCFG enhances image modifications, such as color changes or adding elements, by continuously referencing the input image’s latent value and initially sampled noise. This results in stronger prompt influence and more pronounced changes, though it can increase image contrast. Adjusting the magnitude of the virtual residual noise vector can mitigate this.

The pipeline’s capability extends to standard text-to-image generation, demonstrated with high-quality images generated quickly using the sd-turbo model. On RTX 4090 with CPU Core i9-13900K, the pipeline can generate at a rate over 100fps, and up to 150 images per second with larger batch sizes. Although using community models merged with LCM-LoRA for more diverse expressions reduces speed to around 40fps, it still offers flexibility and high-quality generation.
paperreview deeplearning stablediffusion cv